 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Adaptive Computation Modules: Granular Conditional Computation For Efficient Inference
Dec 15, 2023
The computational cost of transformer models makes them inefficient in low-latency or low-power applications. While techniques such as quantization or linear attention can reduce the computational load, they may incur a reduction in accuracy. In addition, globally reducing the cost for all inputs may be sub-optimal. We observe that for each layer, the full width of the layer may be needed only for a small subset of tokens inside a batch and that the "effective" width needed to process a token can vary from layer to layer. Motivated by this observation, we introduce the Adaptive Computation Module (ACM), a generic module that dynamically adapts its computational load to match the estimated difficulty of the input on a per-token basis. An ACM consists of a sequence of learners that progressively refine the output of their preceding counterparts. An additional gating mechanism determines the optimal number of learners to execute for each token. We also describe a distillation technique to replace any pre-trained model with an "ACMized" variant. The distillation phase is designed to be highly parallelizable across layers while being simple to plug-and-play into existing networks. Our evaluation of transformer models in computer vision and speech recognition demonstrates that substituting layers with ACMs significantly reduces inference costs without degrading the downstream accuracy for a wide interval of user-defined budgets.
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 21, 2023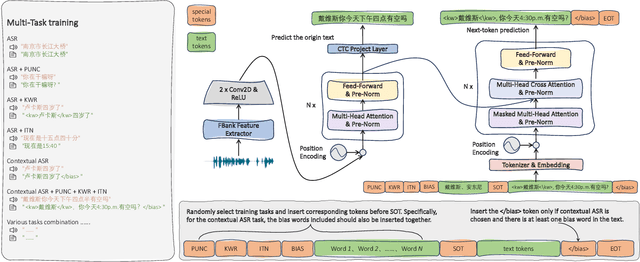
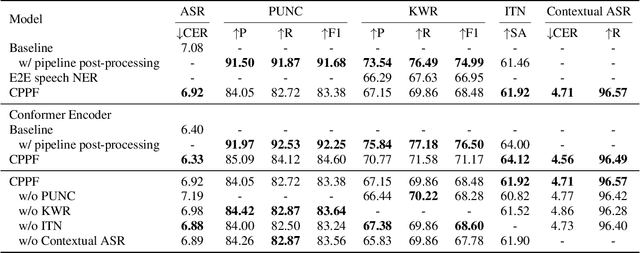

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.
Efficient Representation of the Activation Space in Deep Neural Networks
Dec 13, 2023The representations of the activation space of deep neural networks (DNNs) are widely utilized for tasks like natural language processing, anomaly detection and speech recognition. Due to the diverse nature of these tasks and the large size of DNNs, an efficient and task-independent representation of activations becomes crucial. Empirical p-values have been used to quantify the relative strength of an observed node activation compared to activations created by already-known inputs. Nonetheless, keeping raw data for these calculations increases memory resource consumption and raises privacy concerns. To this end, we propose a model-agnostic framework for creating representations of activations in DNNs using node-specific histograms to compute p-values of observed activations without retaining already-known inputs. Our proposed approach demonstrates promising potential when validated with multiple network architectures across various downstream tasks and compared with the kernel density estimates and brute-force empirical baselines. In addition, the framework reduces memory usage by 30% with up to 4 times faster p-value computing time while maintaining state of-the-art detection power in downstream tasks such as the detection of adversarial attacks and synthesized content. Moreover, as we do not persist raw data at inference time, we could potentially reduce susceptibility to attacks and privacy issues.
Augmenting conformers with structured state space models for online speech recognition
Sep 15, 2023
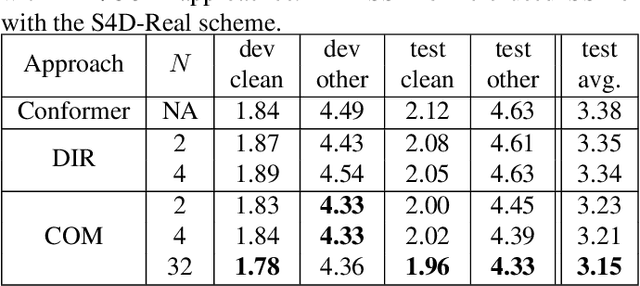
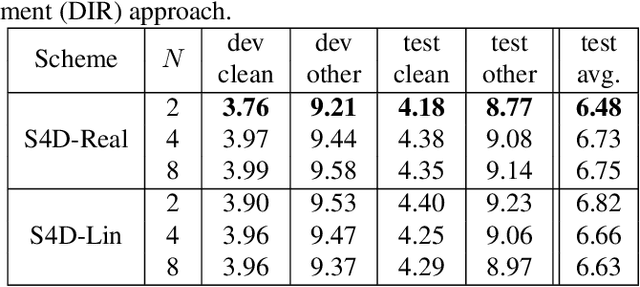
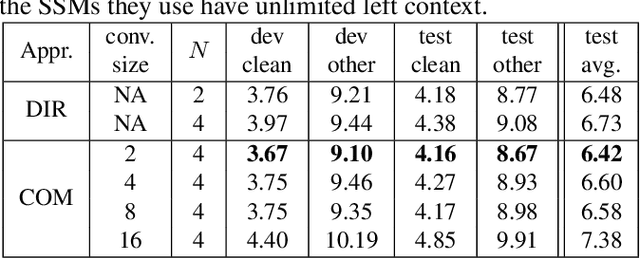
Online speech recognition, where the model only accesses context to the left, is an important and challenging use case for ASR systems. In this work, we investigate augmenting neural encoders for online ASR by incorporating structured state-space sequence models (S4), which are a family of models that provide a parameter-efficient way of accessing arbitrarily long left context. We perform systematic ablation studies to compare variants of S4 models and propose two novel approaches that combine them with convolutions. We find that the most effective design is to stack a small S4 using real-valued recurrent weights with a local convolution, allowing them to work complementarily. Our best model achieves WERs of 4.01%/8.53% on test sets from Librispeech, outperforming Conformers with extensively tuned convolution.
Are Soft Prompts Good Zero-shot Learners for Speech Recognition?
Sep 18, 2023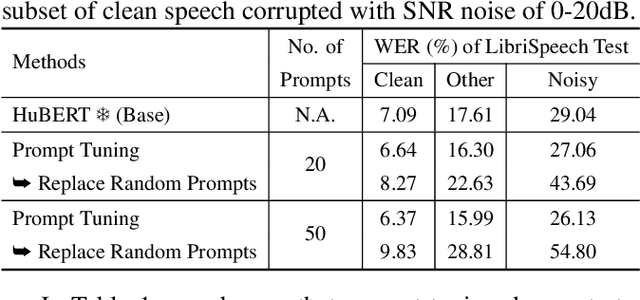
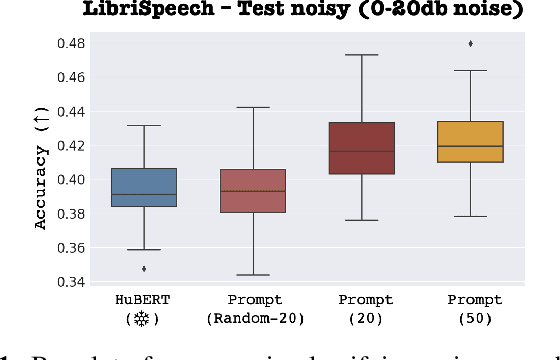
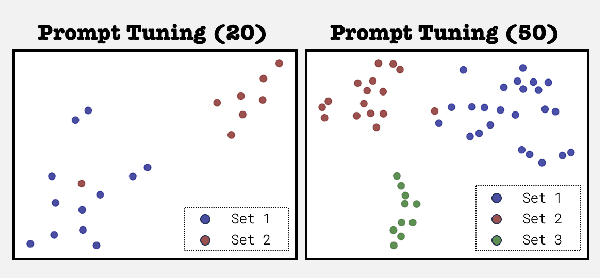
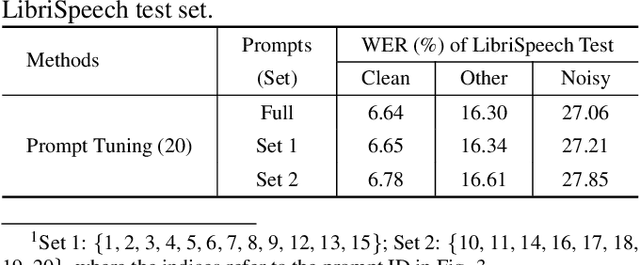
Large self-supervised pre-trained speech models require computationally expensive fine-tuning for downstream tasks. Soft prompt tuning offers a simple parameter-efficient alternative by utilizing minimal soft prompt guidance, enhancing portability while also maintaining competitive performance. However, not many people understand how and why this is so. In this study, we aim to deepen our understanding of this emerging method by investigating the role of soft prompts in automatic speech recognition (ASR). Our findings highlight their role as zero-shot learners in improving ASR performance but also make them vulnerable to malicious modifications. Soft prompts aid generalization but are not obligatory for inference. We also identify two primary roles of soft prompts: content refinement and noise information enhancement, which enhances robustness against background noise. Additionally, we propose an effective modification on noise prompts to show that they are capable of zero-shot learning on adapting to out-of-distribution noise environments.
SECap: Speech Emotion Captioning with Large Language Model
Dec 23, 2023Speech emotions are crucial in human communication and are extensively used in fields like speech synthesis and natural language understanding. Most prior studies, such as speech emotion recognition, have categorized speech emotions into a fixed set of classes. Yet, emotions expressed in human speech are often complex, and categorizing them into predefined groups can be insufficient to adequately represent speech emotions. On the contrary, describing speech emotions directly by means of natural language may be a more effective approach. Regrettably, there are not many studies available that have focused on this direction. Therefore, this paper proposes a speech emotion captioning framework named SECap, aiming at effectively describing speech emotions using natural language. Owing to the impressive capabilities of large language models in language comprehension and text generation, SECap employs LLaMA as the text decoder to allow the production of coherent speech emotion captions. In addition, SECap leverages HuBERT as the audio encoder to extract general speech features and Q-Former as the Bridge-Net to provide LLaMA with emotion-related speech features. To accomplish this, Q-Former utilizes mutual information learning to disentangle emotion-related speech features and speech contents, while implementing contrastive learning to extract more emotion-related speech features. The results of objective and subjective evaluations demonstrate that: 1) the SECap framework outperforms the HTSAT-BART baseline in all objective evaluations; 2) SECap can generate high-quality speech emotion captions that attain performance on par with human annotators in subjective mean opinion score tests.
Creating Spoken Dialog Systems in Ultra-Low Resourced Settings
Dec 11, 2023Automatic Speech Recognition (ASR) systems are a crucial technology that is used today to design a wide variety of applications, most notably, smart assistants, such as Alexa. ASR systems are essentially dialogue systems that employ Spoken Language Understanding (SLU) to extract meaningful information from speech. The main challenge with designing such systems is that they require a huge amount of labeled clean data to perform competitively, such data is extremely hard to collect and annotate to respective SLU tasks, furthermore, when designing such systems for low resource languages, where data is extremely limited, the severity of the problem intensifies. In this paper, we focus on a fairly popular SLU task, that is, Intent Classification while working with a low resource language, namely, Flemish. Intent Classification is a task concerned with understanding the intents of the user interacting with the system. We build on existing light models for intent classification in Flemish, and our main contribution is applying different augmentation techniques on two levels -- the voice level, and the phonetic transcripts level -- to the existing models to counter the problem of scarce labeled data in low-resource languages. We find that our data augmentation techniques, on both levels, have improved the model performance on a number of tasks.
Radio2Text: Streaming Speech Recognition Using mmWave Radio Signals
Aug 16, 2023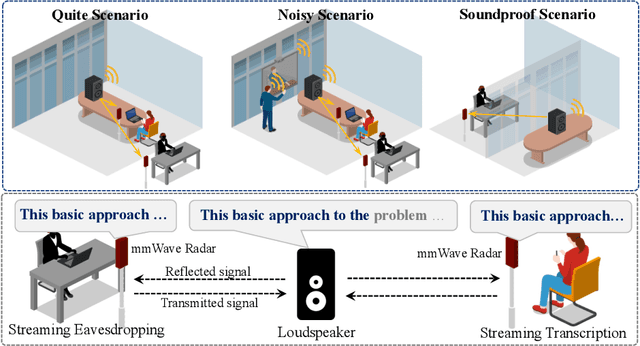


Millimeter wave (mmWave) based speech recognition provides more possibility for audio-related applications, such as conference speech transcription and eavesdropping. However, considering the practicality in real scenarios, latency and recognizable vocabulary size are two critical factors that cannot be overlooked. In this paper, we propose Radio2Text, the first mmWave-based system for streaming automatic speech recognition (ASR) with a vocabulary size exceeding 13,000 words. Radio2Text is based on a tailored streaming Transformer that is capable of effectively learning representations of speech-related features, paving the way for streaming ASR with a large vocabulary. To alleviate the deficiency of streaming networks unable to access entire future inputs, we propose the Guidance Initialization that facilitates the transfer of feature knowledge related to the global context from the non-streaming Transformer to the tailored streaming Transformer through weight inheritance. Further, we propose a cross-modal structure based on knowledge distillation (KD), named cross-modal KD, to mitigate the negative effect of low quality mmWave signals on recognition performance. In the cross-modal KD, the audio streaming Transformer provides feature and response guidance that inherit fruitful and accurate speech information to supervise the training of the tailored radio streaming Transformer. The experimental results show that our Radio2Text can achieve a character error rate of 5.7% and a word error rate of 9.4% for the recognition of a vocabulary consisting of over 13,000 words.
One model to rule them all ? Towards End-to-End Joint Speaker Diarization and Speech Recognition
Oct 02, 2023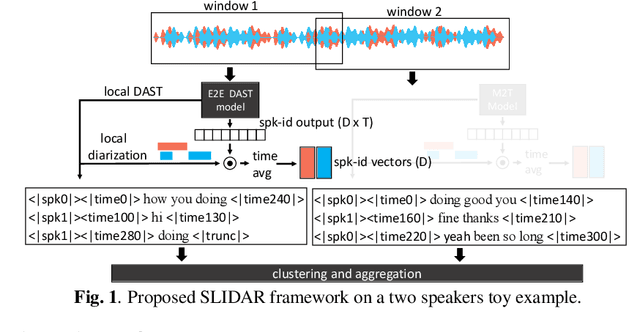

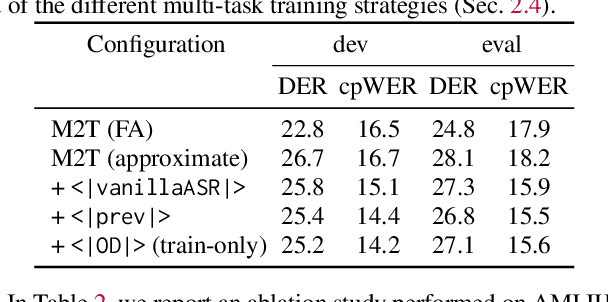
This paper presents a novel framework for joint speaker diarization (SD) and automatic speech recognition (ASR), named SLIDAR (sliding-window diarization-augmented recognition). SLIDAR can process arbitrary length inputs and can handle any number of speakers, effectively solving ``who spoke what, when'' concurrently. SLIDAR leverages a sliding window approach and consists of an end-to-end diarization-augmented speech transcription (E2E DAST) model which provides, locally, for each window: transcripts, diarization and speaker embeddings. The E2E DAST model is based on an encoder-decoder architecture and leverages recent techniques such as serialized output training and ``Whisper-style" prompting. The local outputs are then combined to get the final SD+ASR result by clustering the speaker embeddings to get global speaker identities. Experiments performed on monaural recordings from the AMI corpus confirm the effectiveness of the method in both close-talk and far-field speech scenarios.
Mavericks at NADI 2023 Shared Task: Unravelling Regional Nuances through Dialect Identification using Transformer-based Approach
Nov 30, 2023In this paper, we present our approach for the "Nuanced Arabic Dialect Identification (NADI) Shared Task 2023". We highlight our methodology for subtask 1 which deals with country-level dialect identification. Recognizing dialects plays an instrumental role in enhancing the performance of various downstream NLP tasks such as speech recognition and translation. The task uses the Twitter dataset (TWT-2023) that encompasses 18 dialects for the multi-class classification problem. Numerous transformer-based models, pre-trained on Arabic language, are employed for identifying country-level dialects. We fine-tune these state-of-the-art models on the provided dataset. The ensembling method is leveraged to yield improved performance of the system. We achieved an F1-score of 76.65 (11th rank on the leaderboard) on the test dataset.