 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Capturing Multi-Resolution Context by Dilated Self-Attention
Apr 07, 2021
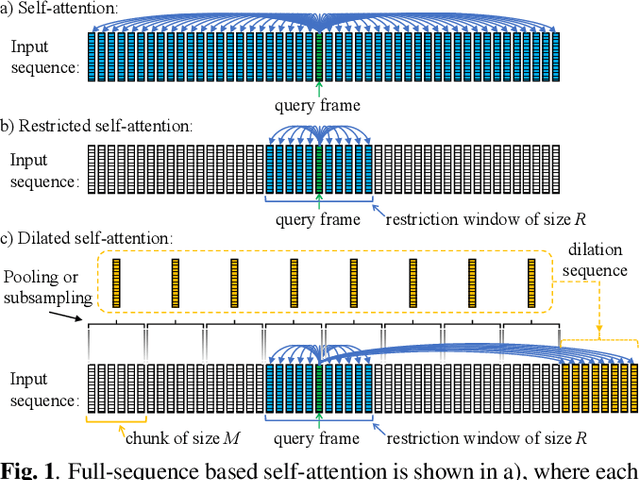
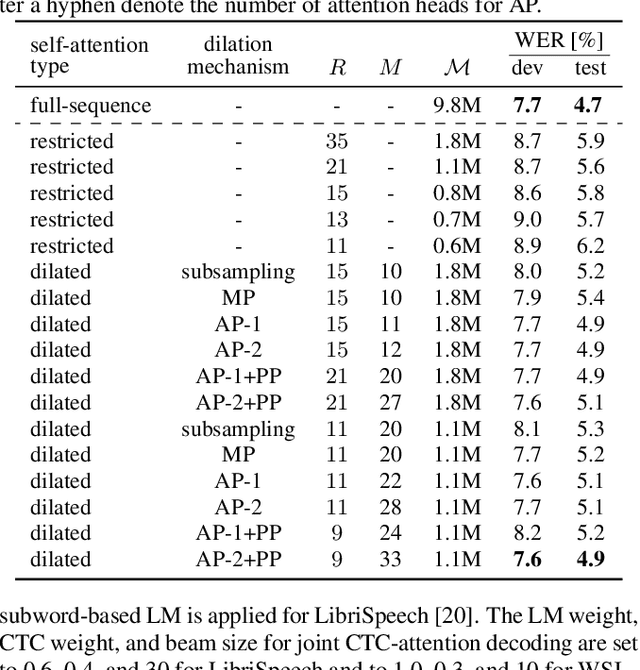
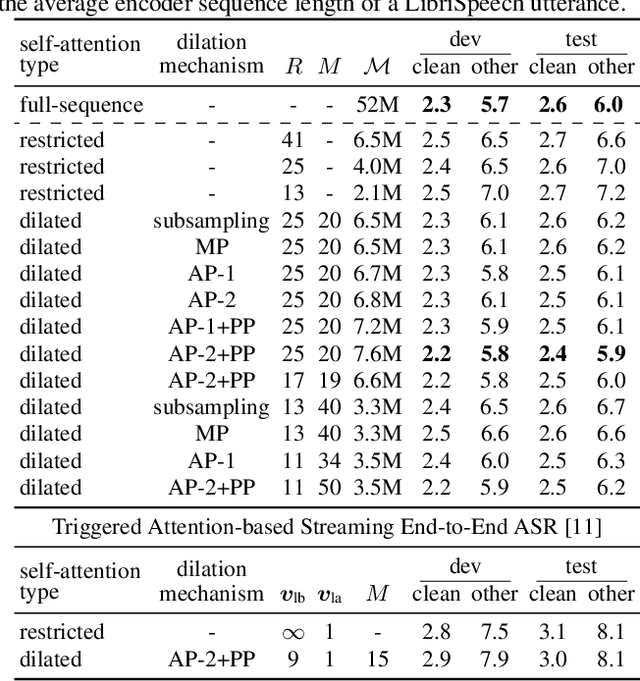
Self-attention has become an important and widely used neural network component that helped to establish new state-of-the-art results for various applications, such as machine translation and automatic speech recognition (ASR). However, the computational complexity of self-attention grows quadratically with the input sequence length. This can be particularly problematic for applications such as ASR, where an input sequence generated from an utterance can be relatively long. In this work, we propose a combination of restricted self-attention and a dilation mechanism, which we refer to as dilated self-attention. The restricted self-attention allows attention to neighboring frames of the query at a high resolution, and the dilation mechanism summarizes distant information to allow attending to it with a lower resolution. Different methods for summarizing distant frames are studied, such as subsampling, mean-pooling, and attention-based pooling. ASR results demonstrate substantial improvements compared to restricted self-attention alone, achieving similar results compared to full-sequence based self-attention with a fraction of the computational costs.
An Effective End-to-End Modeling Approach for Mispronunciation Detection
May 18, 2020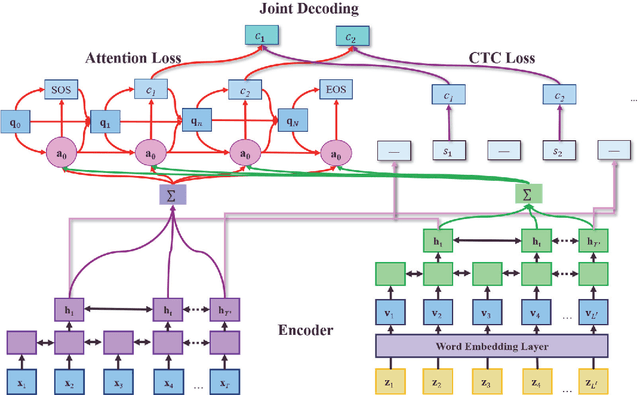
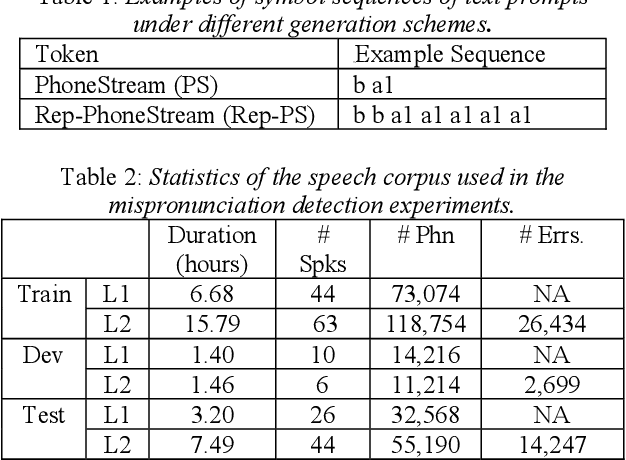
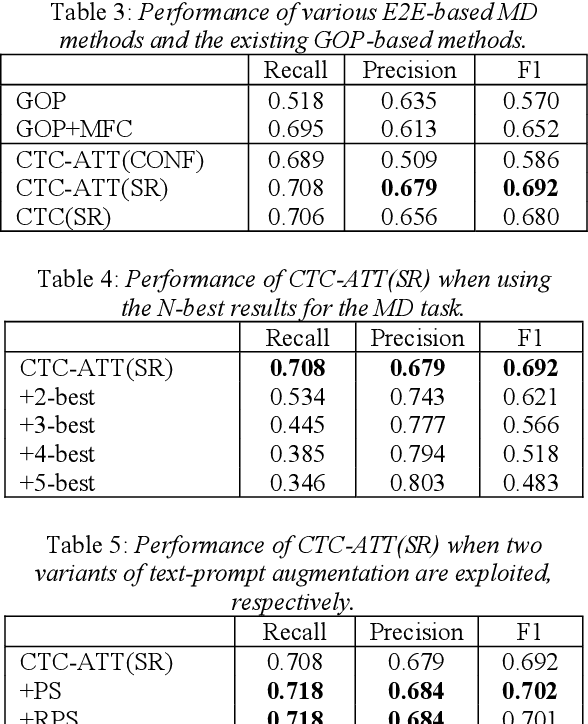
Recently, end-to-end (E2E) automatic speech recognition (ASR) systems have garnered tremendous attention because of their great success and unified modeling paradigms in comparison to conventional hybrid DNN-HMM ASR systems. Despite the widespread adoption of E2E modeling frameworks on ASR, there still is a dearth of work on investigating the E2E frameworks for use in computer-assisted pronunciation learning (CAPT), particularly for Mispronunciation detection (MD). In response, we first present a novel use of hybrid CTCAttention approach to the MD task, taking advantage of the strengths of both CTC and the attention-based model meanwhile getting around the need for phone-level forced alignment. Second, we perform input augmentation with text prompt information to make the resulting E2E model more tailored for the MD task. On the other hand, we adopt two MD decision methods so as to better cooperate with the proposed framework: 1) decision-making based on a recognition confidence measure or 2) simply based on speech recognition results. A series of Mandarin MD experiments demonstrate that our approach not only simplifies the processing pipeline of existing hybrid DNN-HMM systems but also brings about systematic and substantial performance improvements. Furthermore, input augmentation with text prompts seems to hold excellent promise for the E2E-based MD approach.
Relaxing the Conditional Independence Assumption of CTC-based ASR by Conditioning on Intermediate Predictions
Apr 06, 2021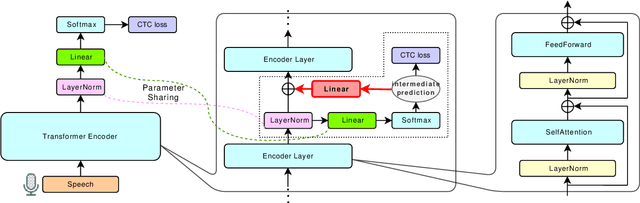
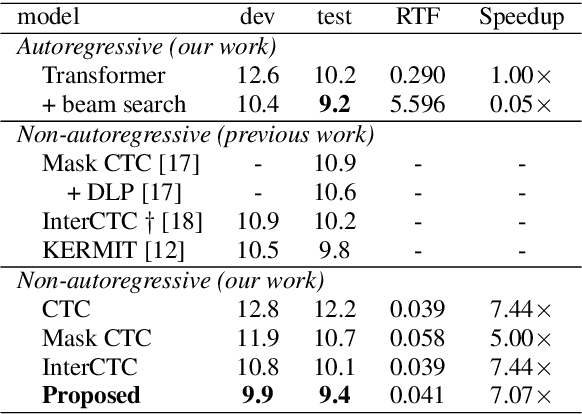
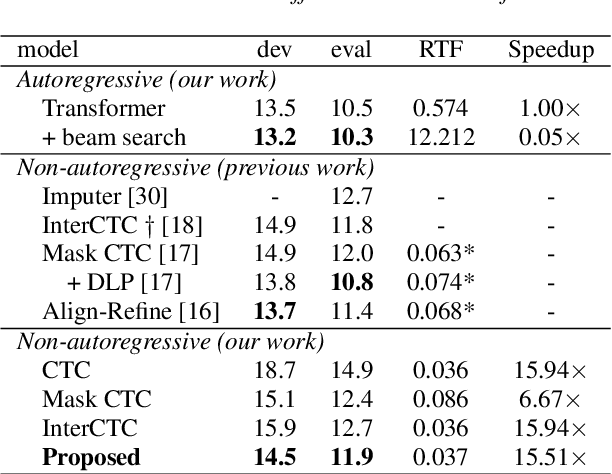

This paper proposes a method to relax the conditional independence assumption of connectionist temporal classification (CTC)-based automatic speech recognition (ASR) models. We train a CTC-based ASR model with auxiliary CTC losses in intermediate layers in addition to the original CTC loss in the last layer. During both training and inference, each generated prediction in the intermediate layers is summed to the input of the next layer to condition the prediction of the last layer on those intermediate predictions. Our method is easy to implement and retains the merits of CTC-based ASR: a simple model architecture and fast decoding speed. We conduct experiments on three different ASR corpora. Our proposed method improves a standard CTC model significantly (e.g., more than 20 % relative word error rate reduction on the WSJ corpus) with a little computational overhead. Moreover, for the TEDLIUM2 corpus and the AISHELL-1 corpus, it achieves a comparable performance to a strong autoregressive model with beam search, but the decoding speed is at least 30 times faster.
Noisy-target Training: A Training Strategy for DNN-based Speech Enhancement without Clean Speech
Jan 21, 2021

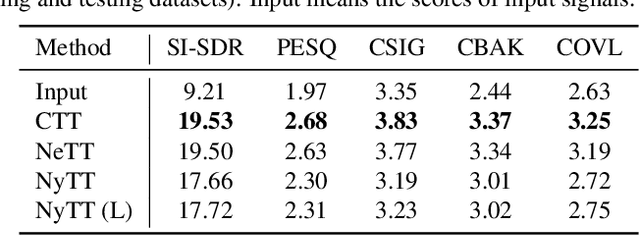
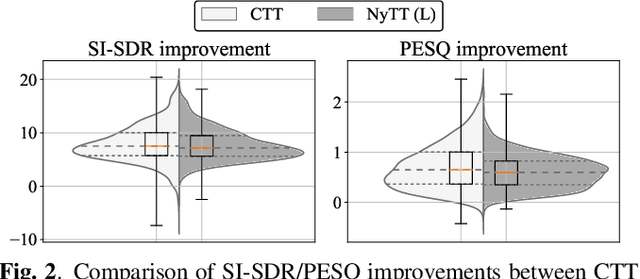
Deep neural network (DNN)-based speech enhancement ordinarily requires clean speech signals as the training target. However, collecting clean signals is very costly because they must be recorded in a studio. This requirement currently restricts the amount of training data for speech enhancement less than 1/1000 of that of speech recognition which does not need clean signals. Increasing the amount of training data is important for improving the performance, and hence the requirement of clean signals should be relaxed. In this paper, we propose a training strategy that does not require clean signals. The proposed method only utilizes noisy signals for training, which enables us to use a variety of speech signals in the wild. Our experimental results showed that the proposed method can achieve the performance similar to that of a DNN trained with clean signals.
Extremely Low Footprint End-to-End ASR System for Smart Device
Apr 06, 2021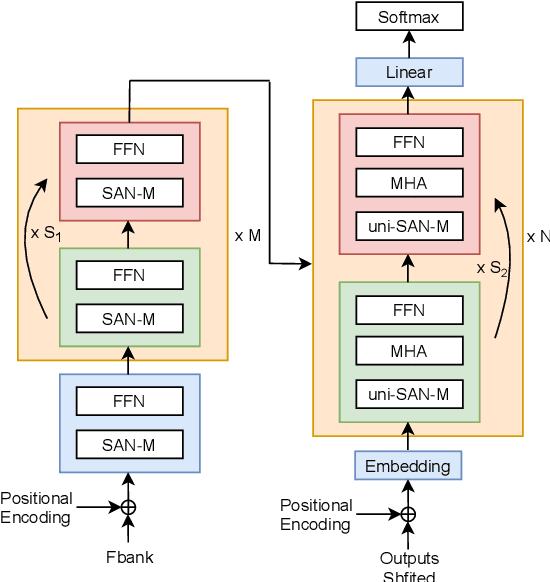
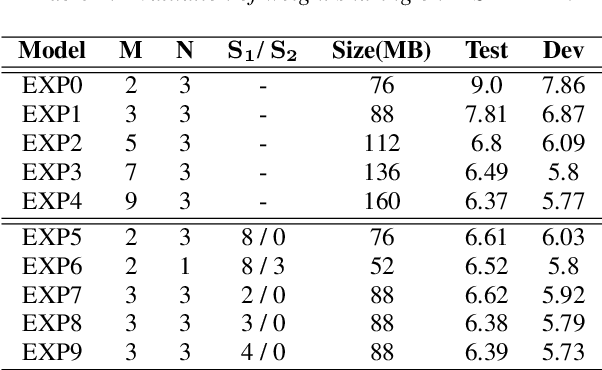
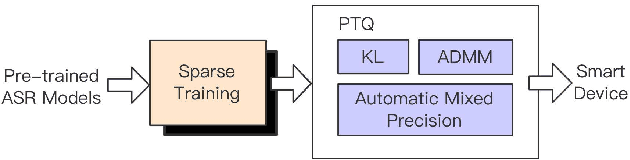
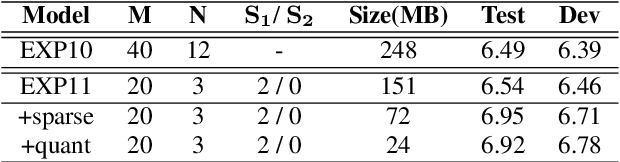
Recently, end-to-end (E2E) speech recognition has become popular, since it can integrate the acoustic, pronunciation and language models into a single neural network, as well as outperforms conventional models. Among E2E approaches, attention-based models, $e.g.$ Transformer, have emerged as being superior. The E2E models have opened the door of deployment of ASR on smart device, however it still suffers from large amount model parameters. This work proposes an extremely low footprint E2E ASR system for smart device, to achieve the goal of satisfying resource constraints without sacrificing recognition accuracy. We adopt cross-layer weight sharing to improve parameter-efficiency. We further exploit the model compression methods including sparsification and quantization, to reduce the memory storage and boost the decoding efficiency on smart device. We have evaluated our approach on the public AISHELL-1 and AISHELL-2 benchmarks. On the AISHELL-2 task, the proposed method achieves more than 10x compression (model size from 248MB to 24MB) while shuffer from small performance loss (CER from 6.49% to 6.92%).
Flexi-Transducer: Optimizing Latency, Accuracy and Compute forMulti-Domain On-Device Scenarios
Apr 06, 2021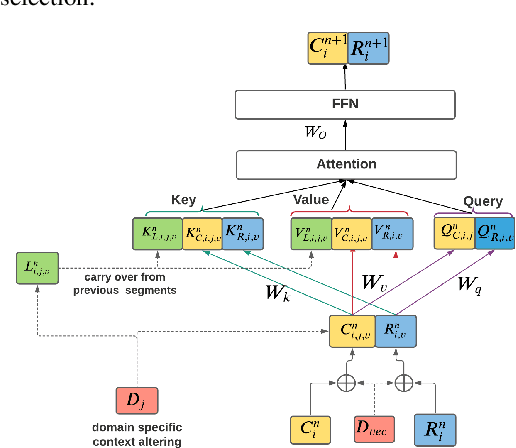
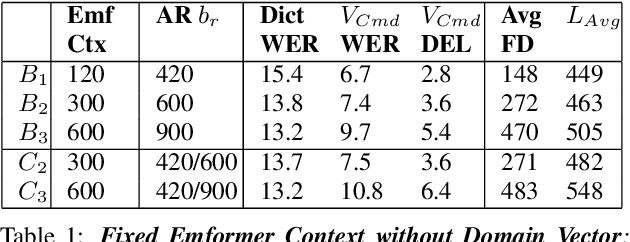
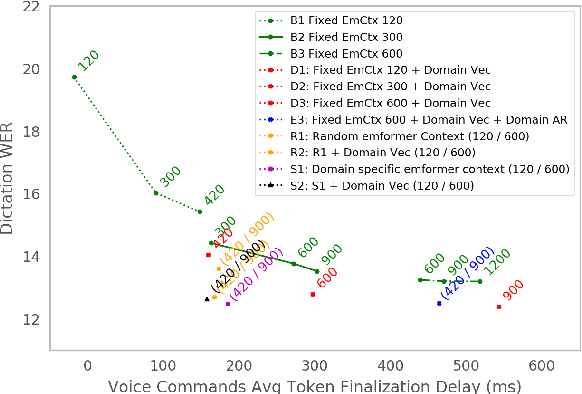
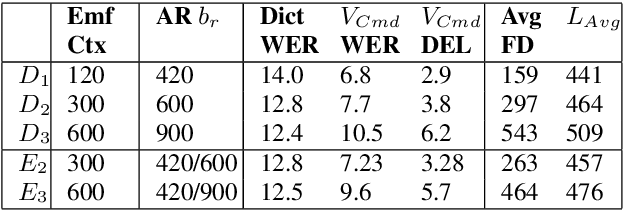
Often, the storage and computational constraints of embeddeddevices demand that a single on-device ASR model serve multiple use-cases / domains. In this paper, we propose aFlexibleTransducer(FlexiT) for on-device automatic speech recognition to flexibly deal with multiple use-cases / domains with different accuracy and latency requirements. Specifically, using a single compact model, FlexiT provides a fast response for voice commands, and accurate transcription but with more latency for dictation. In order to achieve flexible and better accuracy and latency trade-offs, the following techniques are used. Firstly, we propose using domain-specific altering of segment size for Emformer encoder that enables FlexiT to achieve flexible de-coding. Secondly, we use Alignment Restricted RNNT loss to achieve flexible fine-grained control on token emission latency for different domains. Finally, we add a domain indicator vector as an additional input to the FlexiT model. Using the combination of techniques, we show that a single model can be used to improve WERs and real time factor for dictation scenarios while maintaining optimal latency for voice commands use-cases
Dual Script E2E framework for Multilingual and Code-Switching ASR
Jun 02, 2021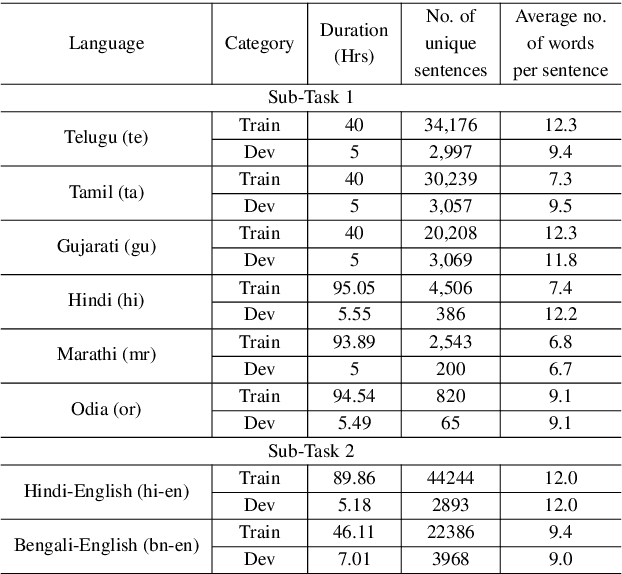
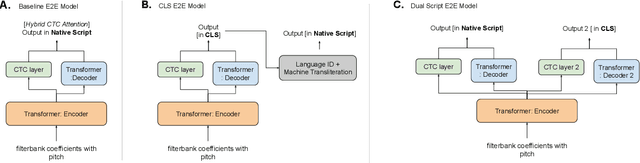
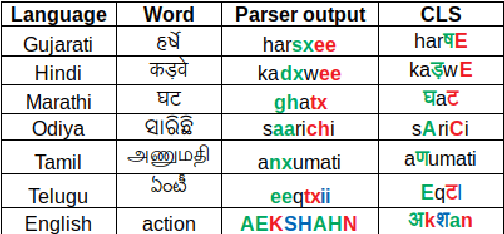
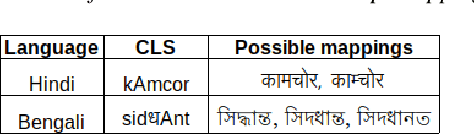
India is home to multiple languages, and training automatic speech recognition (ASR) systems for languages is challenging. Over time, each language has adopted words from other languages, such as English, leading to code-mixing. Most Indian languages also have their own unique scripts, which poses a major limitation in training multilingual and code-switching ASR systems. Inspired by results in text-to-speech synthesis, in this work, we use an in-house rule-based phoneme-level common label set (CLS) representation to train multilingual and code-switching ASR for Indian languages. We propose two end-to-end (E2E) ASR systems. In the first system, the E2E model is trained on the CLS representation, and we use a novel data-driven back-end to recover the native language script. In the second system, we propose a modification to the E2E model, wherein the CLS representation and the native language characters are used simultaneously for training. We show our results on the multilingual and code-switching tasks of the Indic ASR Challenge 2021. Our best results achieve 6% and 5% improvement (approx) in word error rate over the baseline system for the multilingual and code-switching tasks, respectively, on the challenge development data.
Phoneme Recognition through Fine Tuning of Phonetic Representations: a Case Study on Luhya Language Varieties
Apr 04, 2021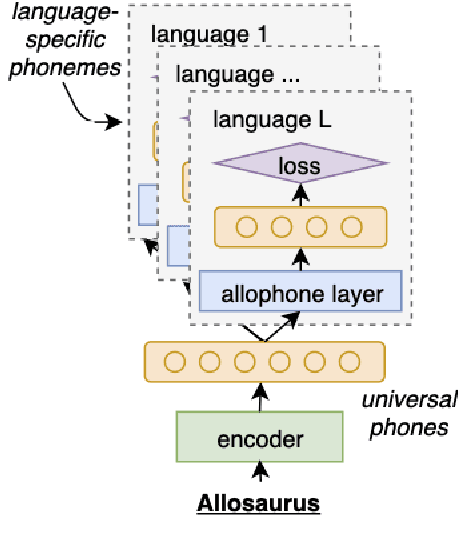
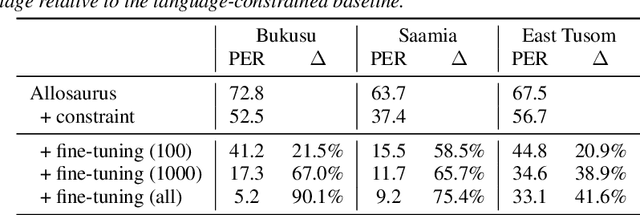
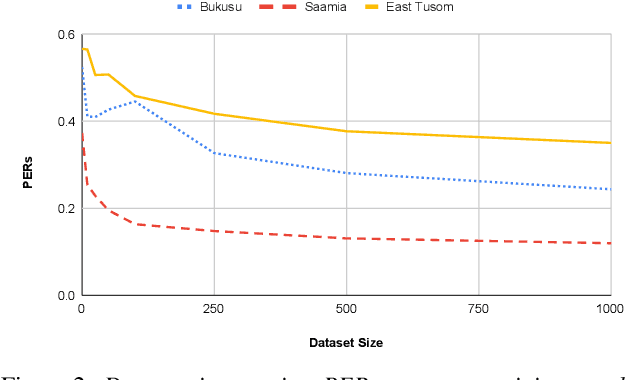
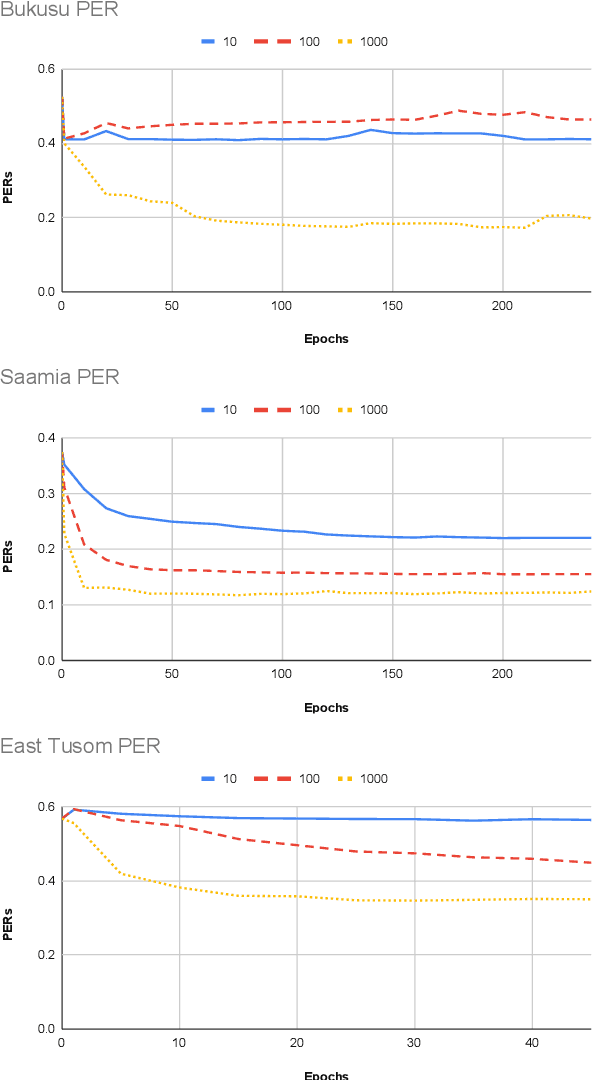
Models pre-trained on multiple languages have shown significant promise for improving speech recognition, particularly for low-resource languages. In this work, we focus on phoneme recognition using Allosaurus, a method for multilingual recognition based on phonetic annotation, which incorporates phonological knowledge through a language-dependent allophone layer that associates a universal narrow phone-set with the phonemes that appear in each language. To evaluate in a challenging real-world scenario, we curate phone recognition datasets for Bukusu and Saamia, two varieties of the Luhya language cluster of western Kenya and eastern Uganda. To our knowledge, these datasets are the first of their kind. We carry out similar experiments on the dataset of an endangered Tangkhulic language, East Tusom, a Tibeto-Burman language variety spoken mostly in India. We explore both zero-shot and few-shot recognition by fine-tuning using datasets of varying sizes (10 to 1000 utterances). We find that fine-tuning of Allosaurus, even with just 100 utterances, leads to significant improvements in phone error rates.
Learnable Frequency Filters for Speech Feature Extraction in Speaker Verification
Jun 15, 2022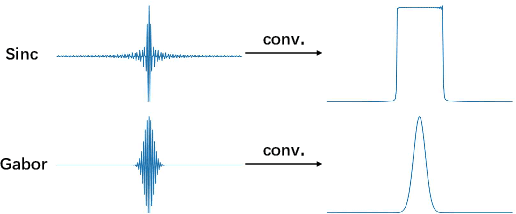
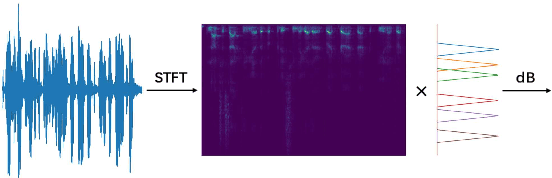
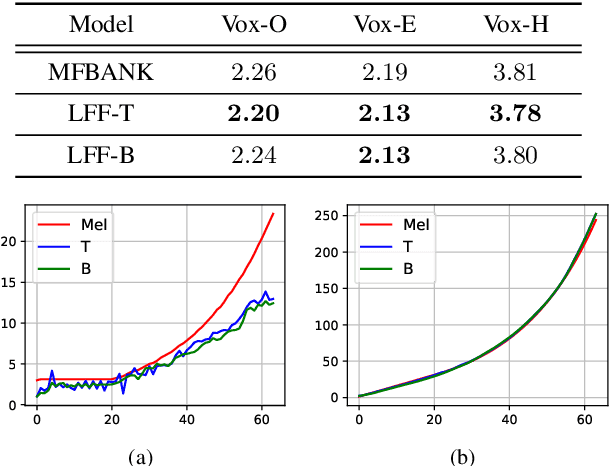
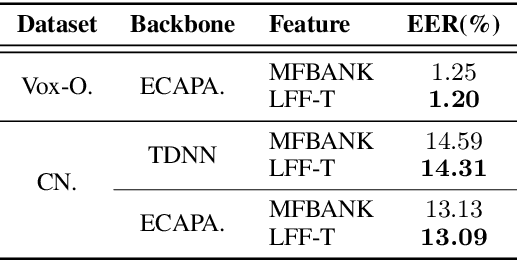
Mel-scale spectrum features are used in various recognition and classification tasks on speech signals. There is no reason to expect that these features are optimal for all different tasks, including speaker verification (SV). This paper describes a learnable front-end feature extraction model. The model comprises a group of filters to transform the Fourier spectrum. Model parameters that define these filters are trained end-to-end and optimized specifically for the task of speaker verification. Compared to the standard Mel-scale filter-bank, the filters' bandwidths and center frequencies are adjustable. Experimental results show that applying the learnable acoustic front-end improves speaker verification performance over conventional Mel-scale spectrum features. Analysis on the learned filter parameters suggests that narrow-band information benefits the SV system performance. The proposed model achieves a good balance between performance and computation cost. In resource-constrained computation settings, the model significantly outperforms CNN-based learnable front-ends. The generalization ability of the proposed model is also demonstrated on different embedding extraction models and datasets.
TransfoRNN: Capturing the Sequential Information in Self-Attention Representations for Language Modeling
Apr 04, 2021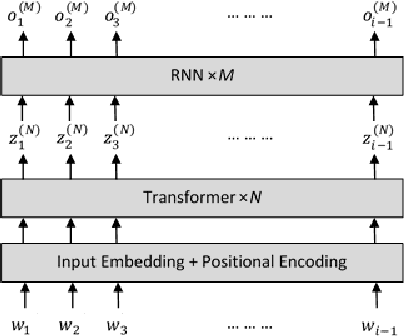
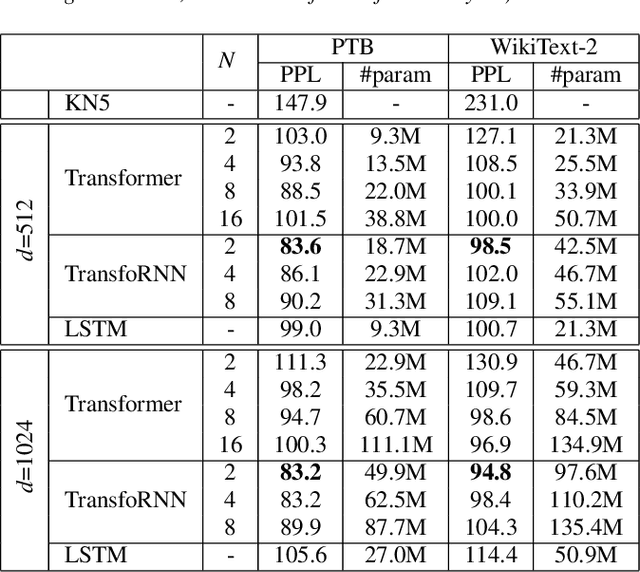
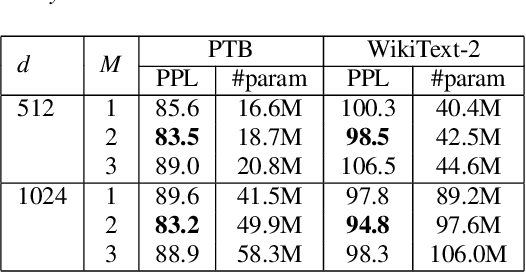
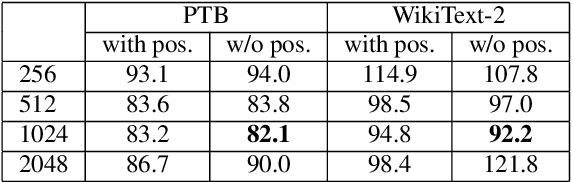
In this paper, we describe the use of recurrent neural networks to capture sequential information from the self-attention representations to improve the Transformers. Although self-attention mechanism provides a means to exploit long context, the sequential information, i.e. the arrangement of tokens, is not explicitly captured. We propose to cascade the recurrent neural networks to the Transformers, which referred to as the TransfoRNN model, to capture the sequential information. We found that the TransfoRNN models which consists of only shallow Transformers stack is suffice to give comparable, if not better, performance than a deeper Transformer model. Evaluated on the Penn Treebank and WikiText-2 corpora, the proposed TransfoRNN model has shown lower model perplexities with fewer number of model parameters. On the Penn Treebank corpus, the model perplexities were reduced up to 5.5% with the model size reduced up to 10.5%. On the WikiText-2 corpus, the model perplexity was reduced up to 2.2% with a 27.7% smaller model. Also, the TransfoRNN model was applied on the LibriSpeech speech recognition task and has shown comparable results with the Transformer models.