 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Using Topological Framework for the Design of Activation Function and Model Pruning in Deep Neural Networks
Sep 03, 2021


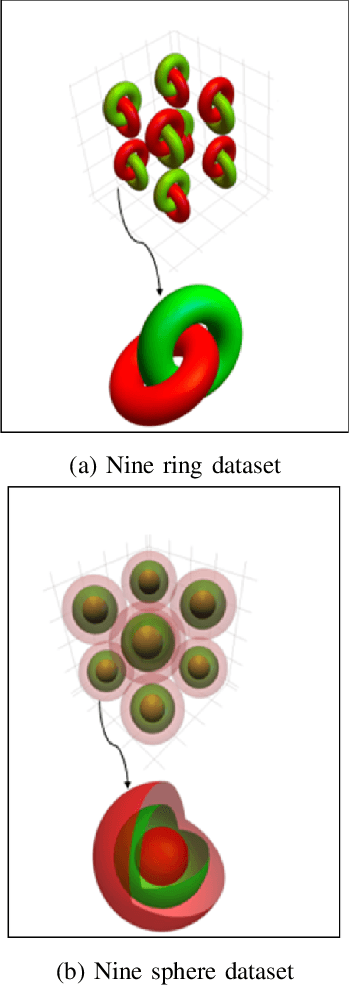
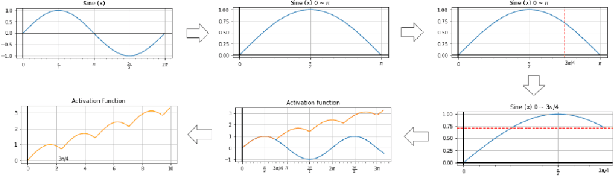
Success of deep neural networks in diverse tasks across domains of computer vision, speech recognition and natural language processing, has necessitated understanding the dynamics of training process and also working of trained models. Two independent contributions of this paper are 1) Novel activation function for faster training convergence 2) Systematic pruning of filters of models trained irrespective of activation function. We analyze the topological transformation of the space of training samples as it gets transformed by each successive layer during training, by changing the activation function. The impact of changing activation function on the convergence during training is reported for the task of binary classification. A novel activation function aimed at faster convergence for classification tasks is proposed. Here, Betti numbers are used to quantify topological complexity of data. Results of experiments on popular synthetic binary classification datasets with large Betti numbers(>150) using MLPs are reported. Results show that the proposed activation function results in faster convergence requiring fewer epochs by a factor of 1.5 to 2, since Betti numbers reduce faster across layers with the proposed activation function. The proposed methodology was verified on benchmark image datasets: fashion MNIST, CIFAR-10 and cat-vs-dog images, using CNNs. Based on empirical results, we propose a novel method for pruning a trained model. The trained model was pruned by eliminating filters that transform data to a topological space with large Betti numbers. All filters with Betti numbers greater than 300 were removed from each layer without significant reduction in accuracy. This resulted in faster prediction time and reduced memory size of the model.
Source and Target Bidirectional Knowledge Distillation for End-to-end Speech Translation
Apr 13, 2021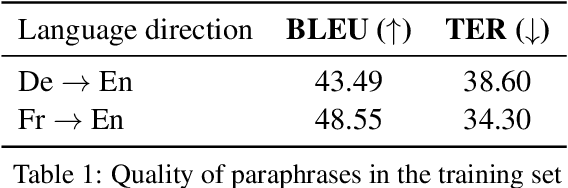
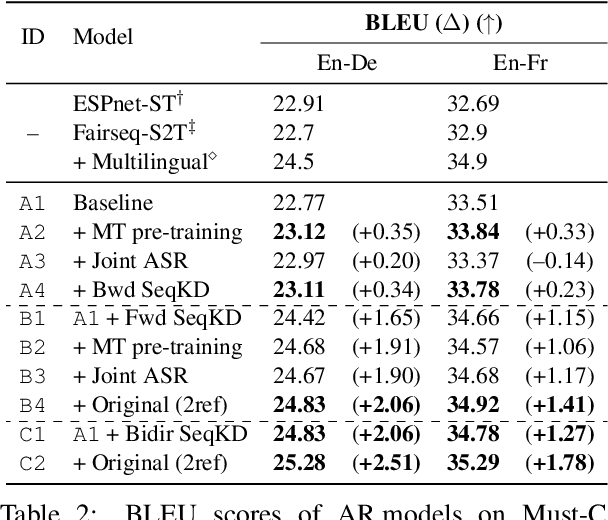
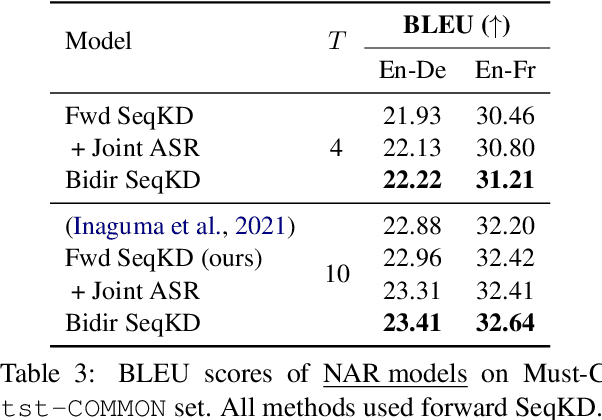
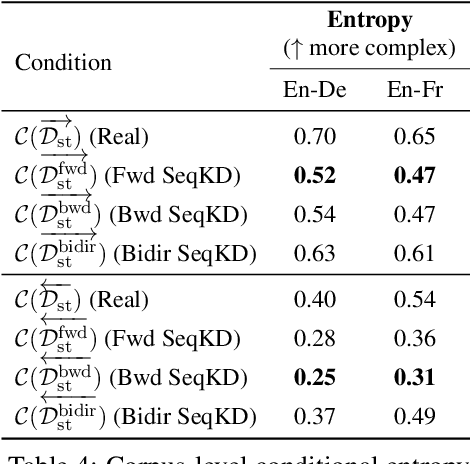
A conventional approach to improving the performance of end-to-end speech translation (E2E-ST) models is to leverage the source transcription via pre-training and joint training with automatic speech recognition (ASR) and neural machine translation (NMT) tasks. However, since the input modalities are different, it is difficult to leverage source language text successfully. In this work, we focus on sequence-level knowledge distillation (SeqKD) from external text-based NMT models. To leverage the full potential of the source language information, we propose backward SeqKD, SeqKD from a target-to-source backward NMT model. To this end, we train a bilingual E2E-ST model to predict paraphrased transcriptions as an auxiliary task with a single decoder. The paraphrases are generated from the translations in bitext via back-translation. We further propose bidirectional SeqKD in which SeqKD from both forward and backward NMT models is combined. Experimental evaluations on both autoregressive and non-autoregressive models show that SeqKD in each direction consistently improves the translation performance, and the effectiveness is complementary regardless of the model capacity.
Contrastive Semi-supervised Learning for ASR
Mar 09, 2021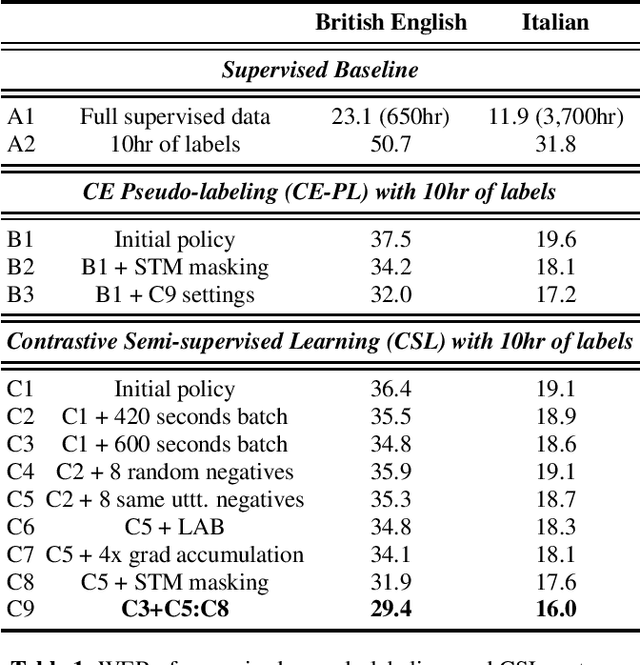
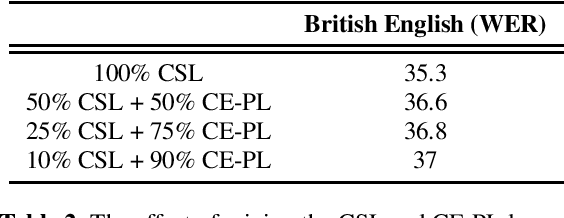
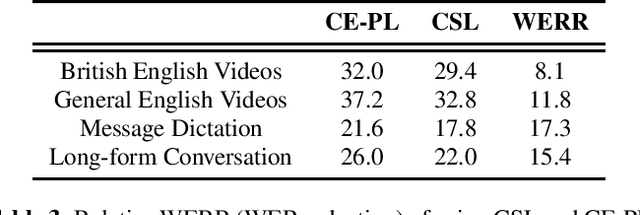
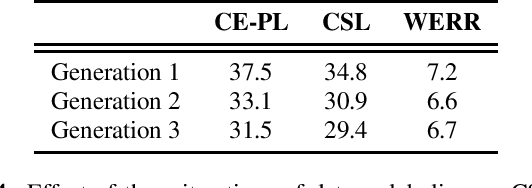
Pseudo-labeling is the most adopted method for pre-training automatic speech recognition (ASR) models. However, its performance suffers from the supervised teacher model's degrading quality in low-resource setups and under domain transfer. Inspired by the successes of contrastive representation learning for computer vision and speech applications, and more recently for supervised learning of visual objects, we propose Contrastive Semi-supervised Learning (CSL). CSL eschews directly predicting teacher-generated pseudo-labels in favor of utilizing them to select positive and negative examples. In the challenging task of transcribing public social media videos, using CSL reduces the WER by 8% compared to the standard Cross-Entropy pseudo-labeling (CE-PL) when 10hr of supervised data is used to annotate 75,000hr of videos. The WER reduction jumps to 19% under the ultra low-resource condition of using 1hr labels for teacher supervision. CSL generalizes much better in out-of-domain conditions, showing up to 17% WER reduction compared to the best CE-PL pre-trained model.
SVEva Fair: A Framework for Evaluating Fairness in Speaker Verification
Jul 26, 2021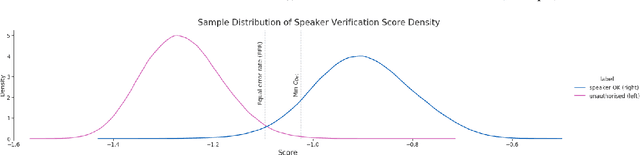
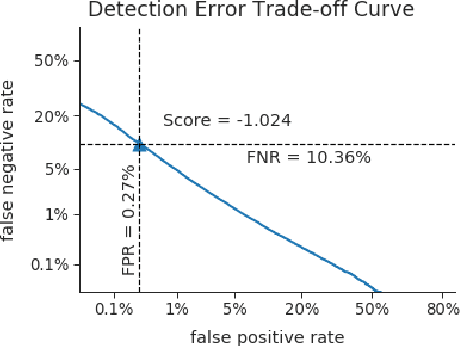
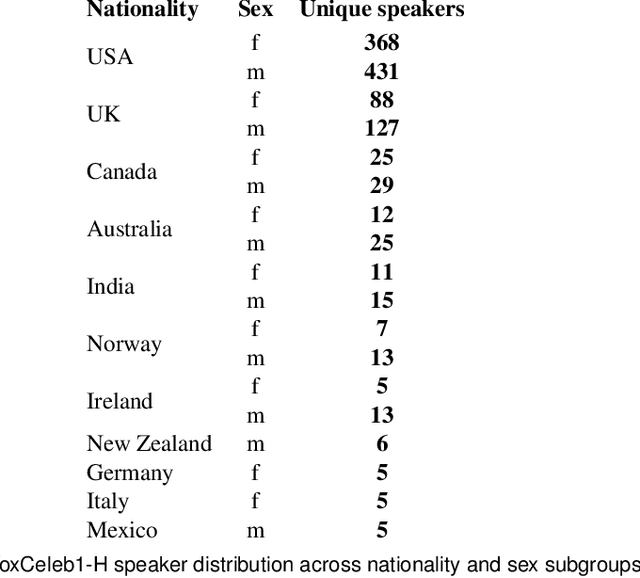
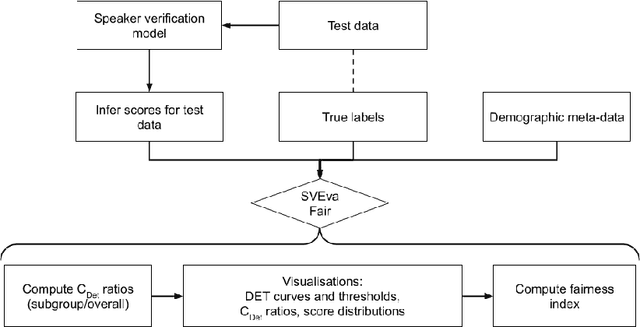
Despite the success of deep neural networks (DNNs) in enabling on-device voice assistants, increasing evidence of bias and discrimination in machine learning is raising the urgency of investigating the fairness of these systems. Speaker verification is a form of biometric identification that gives access to voice assistants. Due to a lack of fairness metrics and evaluation frameworks that are appropriate for testing the fairness of speaker verification components, little is known about how model performance varies across subgroups, and what factors influence performance variation. To tackle this emerging challenge, we design and develop SVEva Fair, an accessible, actionable and model-agnostic framework for evaluating the fairness of speaker verification components. The framework provides evaluation measures and visualisations to interrogate model performance across speaker subgroups and compare fairness between models. We demonstrate SVEva Fair in a case study with end-to-end DNNs trained on the VoxCeleb datasets to reveal potential bias in existing embedded speech recognition systems based on the demographic attributes of speakers. Our evaluation shows that publicly accessible benchmark models are not fair and consistently produce worse predictions for some nationalities, and for female speakers of most nationalities. To pave the way for fair and reliable embedded speaker verification, SVEva Fair has been implemented as an open-source python library and can be integrated into the embedded ML development pipeline to facilitate developers and researchers in troubleshooting unreliable speaker verification performance, and selecting high impact approaches for mitigating fairness challenges
Leveraging End-to-End ASR for Endangered Language Documentation: An Empirical Study on Yoloxóchitl Mixtec
Jan 26, 2021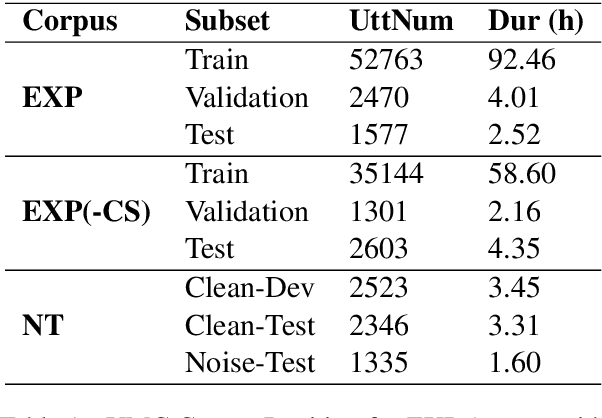
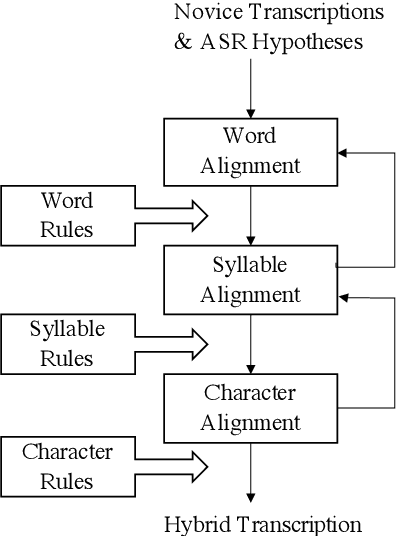

"Transcription bottlenecks", created by a shortage of effective human transcribers are one of the main challenges to endangered language (EL) documentation. Automatic speech recognition (ASR) has been suggested as a tool to overcome such bottlenecks. Following this suggestion, we investigated the effectiveness for EL documentation of end-to-end ASR, which unlike Hidden Markov Model ASR systems, eschews linguistic resources but is instead more dependent on large-data settings. We open source a Yolox\'ochitl Mixtec EL corpus. First, we review our method in building an end-to-end ASR system in a way that would be reproducible by the ASR community. We then propose a novice transcription correction task and demonstrate how ASR systems and novice transcribers can work together to improve EL documentation. We believe this combinatory methodology would mitigate the transcription bottleneck and transcriber shortage that hinders EL documentation.
Ene-to-end training of time domain audio separation and recognition
Dec 18, 2019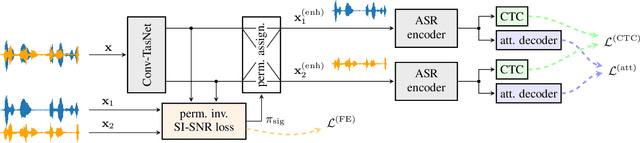


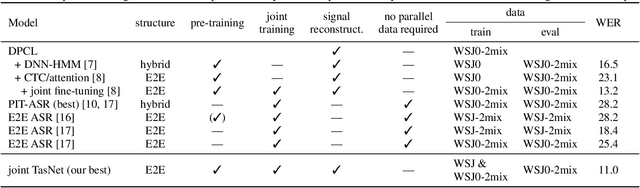
The rising interest in single-channel multi-speaker speech separation sparked development of End-to-End (E2E) approaches to multi-speaker speech recognition. However, up until now, state-of-the-art neural network-based time domain source separation has not yet been combined with E2E speech recognition. We here demonstrate how to combine a separation module based on a Convolutional Time domain Audio Separation Network (Conv-TasNet) with an E2E speech recognizer and how to train such a model jointly by distributing it over multiple GPUs or by approximating truncated back-propagation for the convolutional front-end. To put this work into perspective and illustrate the complexity of the design space, we provide a compact overview of single-channel multi-speaker recognition systems. Our experiments show a word error rate of 11.0% on WSJ0-2mix and indicate that our joint time domain model can yield substantial improvements over cascade DNN-HMM and monolithic E2E frequency domain systems proposed so far.
A Streaming End-to-End Framework For Spoken Language Understanding
Jun 08, 2021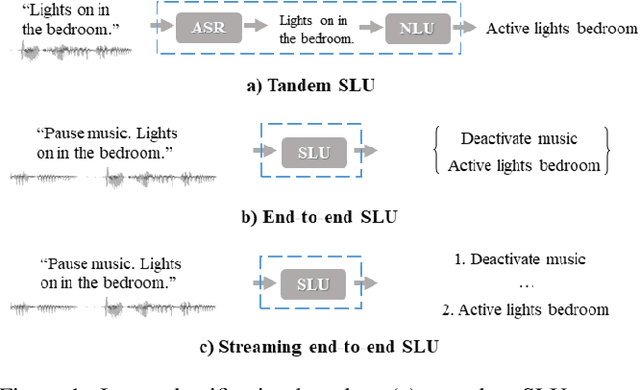
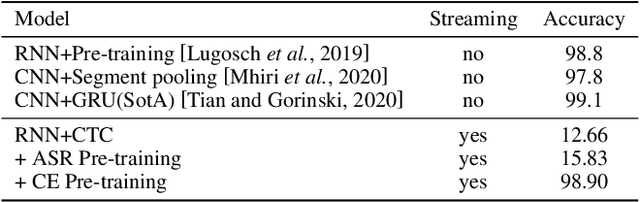
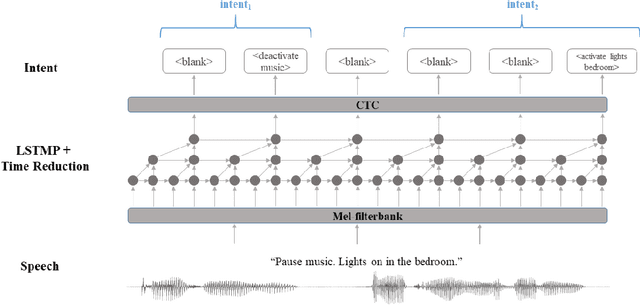

End-to-end spoken language understanding (SLU) has recently attracted increasing interest. Compared to the conventional tandem-based approach that combines speech recognition and language understanding as separate modules, the new approach extracts users' intentions directly from the speech signals, resulting in joint optimization and low latency. Such an approach, however, is typically designed to process one intention at a time, which leads users to take multiple rounds to fulfill their requirements while interacting with a dialogue system. In this paper, we propose a streaming end-to-end framework that can process multiple intentions in an online and incremental way. The backbone of our framework is a unidirectional RNN trained with the connectionist temporal classification (CTC) criterion. By this design, an intention can be identified when sufficient evidence has been accumulated, and multiple intentions can be identified sequentially. We evaluate our solution on the Fluent Speech Commands (FSC) dataset and the intent detection accuracy is about 97 % on all multi-intent settings. This result is comparable to the performance of the state-of-the-art non-streaming models, but is achieved in an online and incremental way. We also employ our model to a keyword spotting task using the Google Speech Commands dataset and the results are also highly promising.
Investigation of Large-Margin Softmax in Neural Language Modeling
May 20, 2020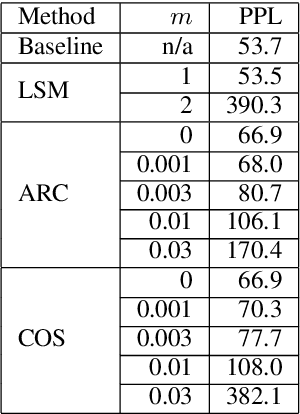
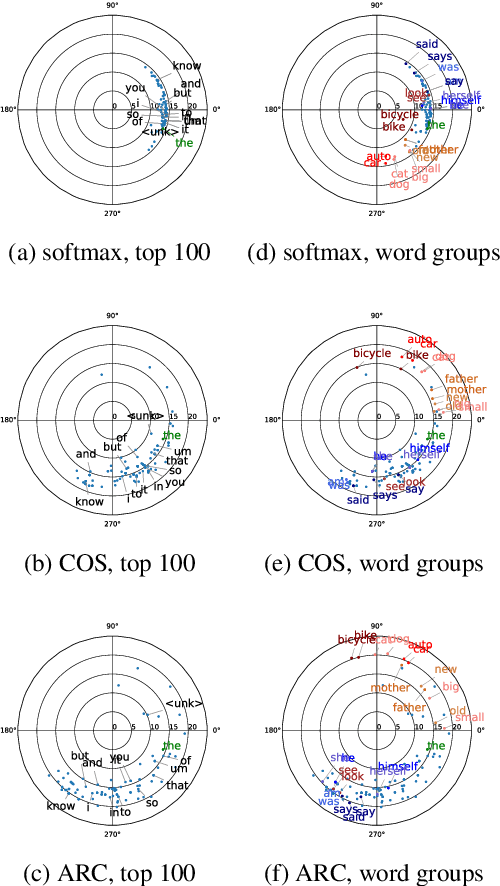
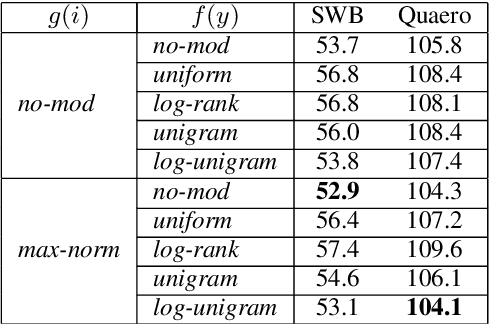
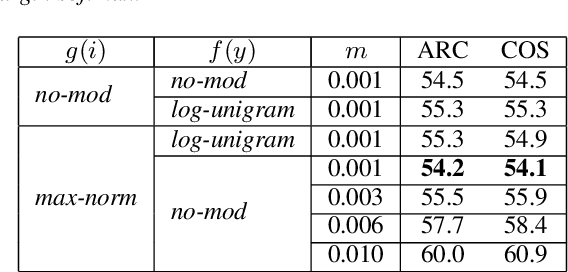
To encourage intra-class compactness and inter-class separability among trainable feature vectors, large-margin softmax methods are developed and widely applied in the face recognition community. The introduction of the large-margin concept into the softmax is reported to have good properties such as enhanced discriminative power, less overfitting and well-defined geometric intuitions. Nowadays, language modeling is commonly approached with neural networks using softmax and cross entropy. In this work, we are curious to see if introducing large-margins to neural language models would improve the perplexity and consequently word error rate in automatic speech recognition. Specifically, we first implement and test various types of conventional margins following the previous works in face recognition. To address the distribution of natural language data, we then compare different strategies for word vector norm-scaling. After that, we apply the best norm-scaling setup in combination with various margins and conduct neural language models rescoring experiments in automatic speech recognition. We find that although perplexity is slightly deteriorated, neural language models with large-margin softmax can yield word error rate similar to that of the standard softmax baseline. Finally, expected margins are analyzed through visualization of word vectors, showing that the syntactic and semantic relationships are also preserved.
DeepFry: Identifying Vocal Fry Using Deep Neural Networks
Mar 31, 2022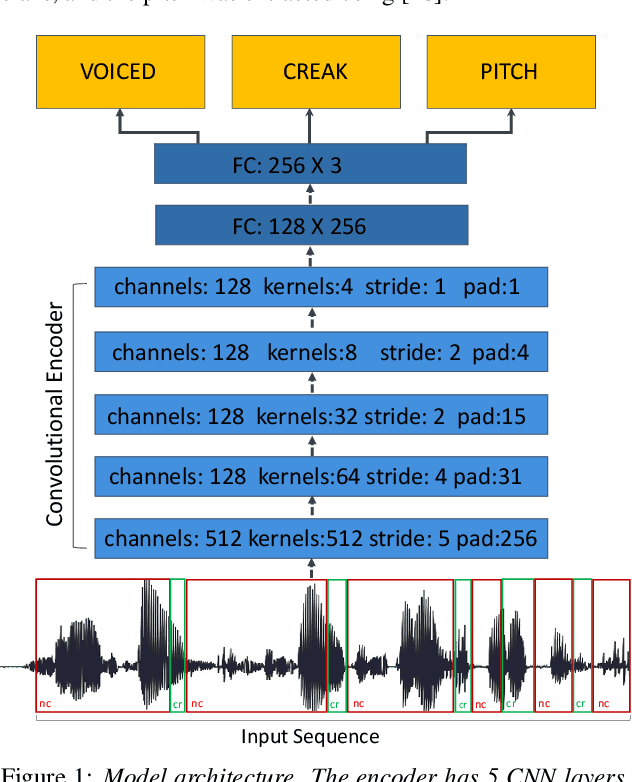
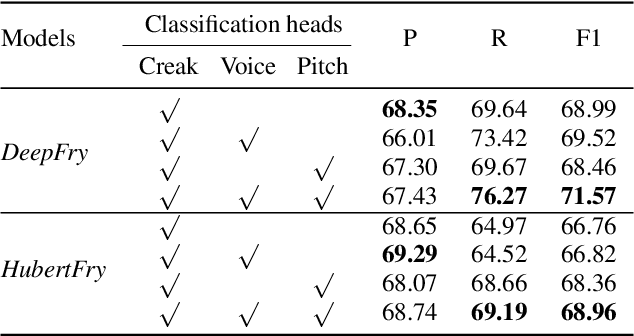

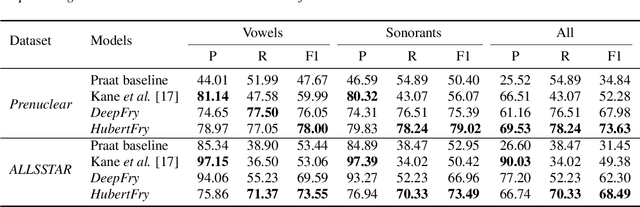
Vocal fry or creaky voice refers to a voice quality characterized by irregular glottal opening and low pitch. It occurs in diverse languages and is prevalent in American English, where it is used not only to mark phrase finality, but also sociolinguistic factors and affect. Due to its irregular periodicity, creaky voice challenges automatic speech processing and recognition systems, particularly for languages where creak is frequently used. This paper proposes a deep learning model to detect creaky voice in fluent speech. The model is composed of an encoder and a classifier trained together. The encoder takes the raw waveform and learns a representation using a convolutional neural network. The classifier is implemented as a multi-headed fully-connected network trained to detect creaky voice, voicing, and pitch, where the last two are used to refine creak prediction. The model is trained and tested on speech of American English speakers, annotated for creak by trained phoneticians. We evaluated the performance of our system using two encoders: one is tailored for the task, and the other is based on a state-of-the-art unsupervised representation. Results suggest our best-performing system has improved recall and F1 scores compared to previous methods on unseen data.
Boundary and Context Aware Training for CIF-based Non-Autoregressive End-to-end ASR
Apr 10, 2021Continuous integrate-and-fire (CIF) based models, which use a soft and monotonic alignment mechanism, have been well applied in non-autoregressive (NAR) speech recognition and achieved competitive performance compared with other NAR methods. However, such an alignment learning strategy may also result in inaccurate acoustic boundary estimation and deceleration in convergence speed. To eliminate these drawbacks and improve performance further, we incorporate an additional connectionist temporal classification (CTC) based alignment loss and a contextual decoder into the CIF-based NAR model. Specifically, we use the CTC spike information to guide the leaning of acoustic boundary and adopt a new contextual decoder to capture the linguistic dependencies within a sentence in the conventional CIF model. Besides, a recently proposed Conformer architecture is also employed to model both local and global acoustic dependencies. Experiments on the open-source Mandarin corpora AISHELL-1 show that the proposed method achieves a comparable character error rate (CER) of 4.9% with only 1/24 latency compared with a state-of-the-art autoregressive (AR) Conformer model.