 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
General-Purpose Speech Representation Learning through a Self-Supervised Multi-Granularity Framework
Feb 03, 2021
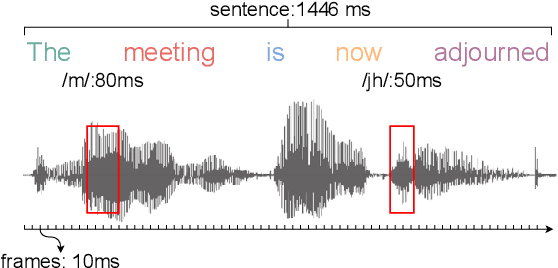
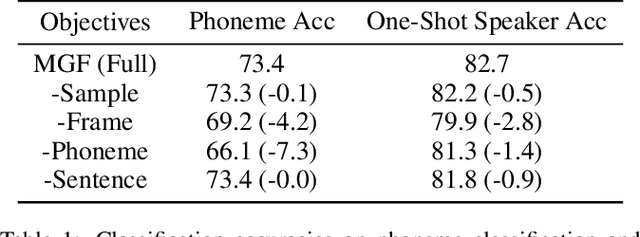
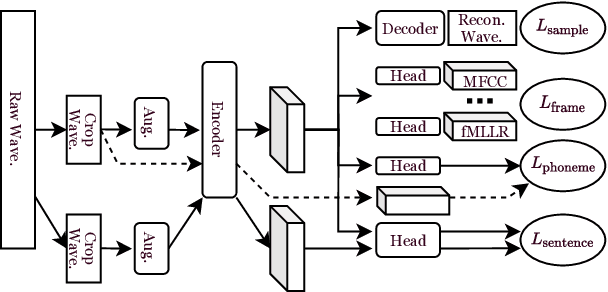
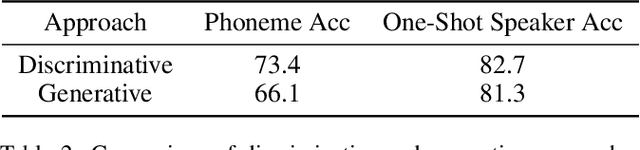
This paper presents a self-supervised learning framework, named MGF, for general-purpose speech representation learning. In the design of MGF, speech hierarchy is taken into consideration. Specifically, we propose to use generative learning approaches to capture fine-grained information at small time scales and use discriminative learning approaches to distill coarse-grained or semantic information at large time scales. For phoneme-scale learning, we borrow idea from the masked language model but tailor it for the continuous speech signal by replacing classification loss with a contrastive loss. We corroborate our design by evaluating MGF representation on various downstream tasks, including phoneme classification, speaker classification, speech recognition, and emotion classification. Experiments verify that training at different time scales needs different training targets and loss functions, which in general complement each other and lead to a better performance.
Data Fusion for Audiovisual Speaker Localization: Extending Dynamic Stream Weights to the Spatial Domain
Feb 23, 2021
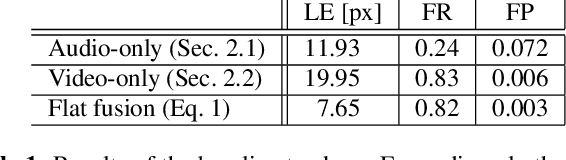
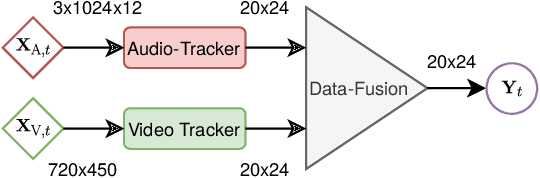
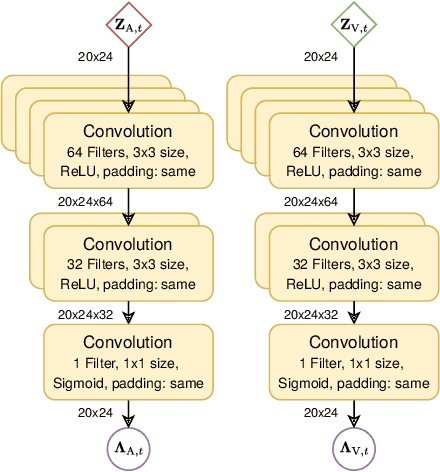
Estimating the positions of multiple speakers can be helpful for tasks like automatic speech recognition or speaker diarization. Both applications benefit from a known speaker position when, for instance, applying beamforming or assigning unique speaker identities. Recently, several approaches utilizing acoustic signals augmented with visual data have been proposed for this task. However, both the acoustic and the visual modality may be corrupted in specific spatial regions, for instance due to poor lighting conditions or to the presence of background noise. This paper proposes a novel audiovisual data fusion framework for speaker localization by assigning individual dynamic stream weights to specific regions in the localization space. This fusion is achieved via a neural network, which combines the predictions of individual audio and video trackers based on their time- and location-dependent reliability. A performance evaluation using audiovisual recordings yields promising results, with the proposed fusion approach outperforming all baseline models.
Overcoming Domain Mismatch in Low Resource Sequence-to-Sequence ASR Models using Hybrid Generated Pseudotranscripts
Jun 14, 2021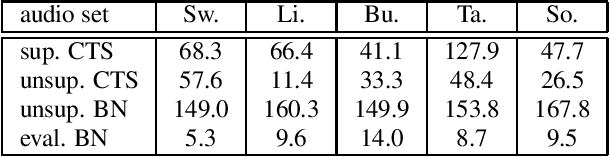
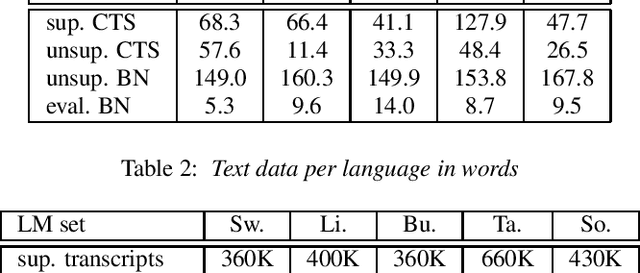
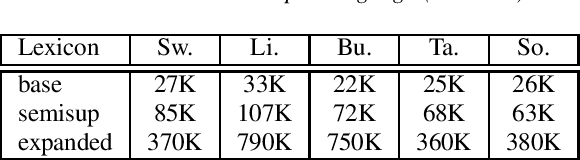
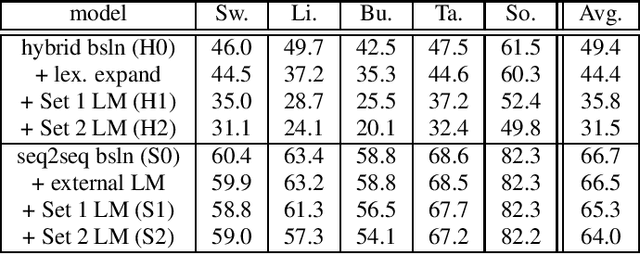
Sequence-to-sequence (seq2seq) models are competitive with hybrid models for automatic speech recognition (ASR) tasks when large amounts of training data are available. However, data sparsity and domain adaptation are more problematic for seq2seq models than their hybrid counterparts. We examine corpora of five languages from the IARPA MATERIAL program where the transcribed data is conversational telephone speech (CTS) and evaluation data is broadcast news (BN). We show that there is a sizable initial gap in such a data condition between hybrid and seq2seq models, and the hybrid model is able to further improve through the use of additional language model (LM) data. We use an additional set of untranscribed data primarily in the BN domain for semisupervised training. In semisupervised training, a seed model trained on transcribed data generates hypothesized transcripts for unlabeled domain-matched data for further training. By using a hybrid model with an expanded language model for pseudotranscription, we are able to improve our seq2seq model from an average word error rate (WER) of 66.7% across all five languages to 29.0% WER. While this puts the seq2seq model at a competitive operating point, hybrid models are still able to use additional LM data to maintain an advantage.
Uncertainty-guided Model Generalization to Unseen Domains
Mar 12, 2021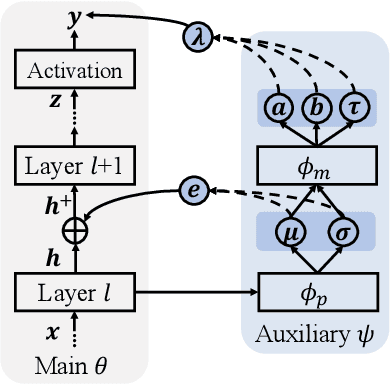
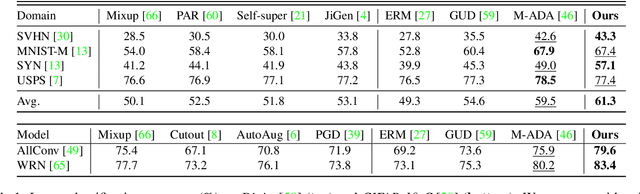
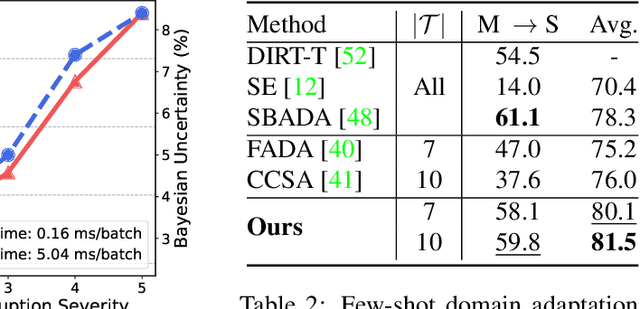
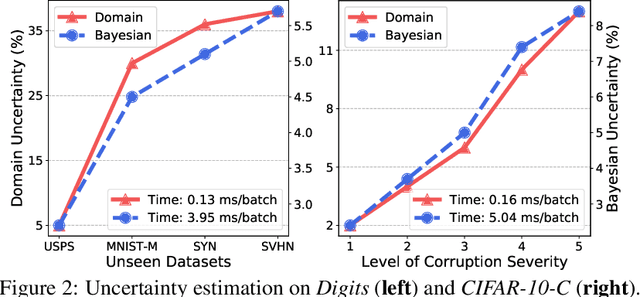
We study a worst-case scenario in generalization: Out-of-domain generalization from a single source. The goal is to learn a robust model from a single source and expect it to generalize over many unknown distributions. This challenging problem has been seldom investigated while existing solutions suffer from various limitations. In this paper, we propose a new solution. The key idea is to augment the source capacity in both input and label spaces, while the augmentation is guided by uncertainty assessment. To the best of our knowledge, this is the first work to (1) access the generalization uncertainty from a single source and (2) leverage it to guide both input and label augmentation for robust generalization. The model training and deployment are effectively organized in a Bayesian meta-learning framework. We conduct extensive comparisons and ablation study to validate our approach. The results prove our superior performance in a wide scope of tasks including image classification, semantic segmentation, text classification, and speech recognition.
Improving N-gram Language Models with Pre-trained Deep Transformer
Nov 22, 2019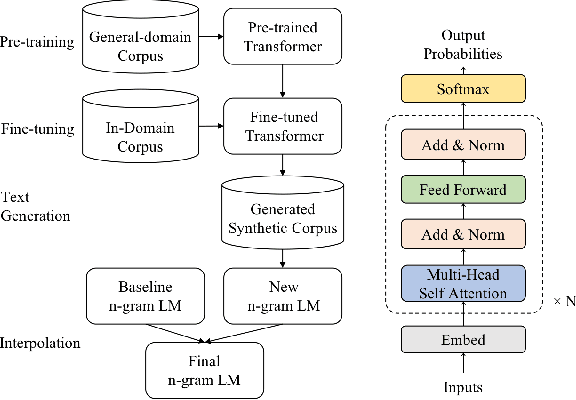

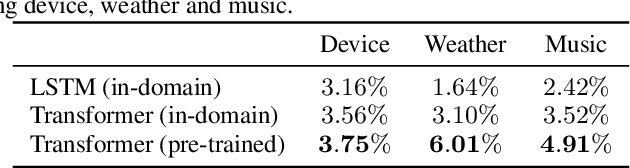
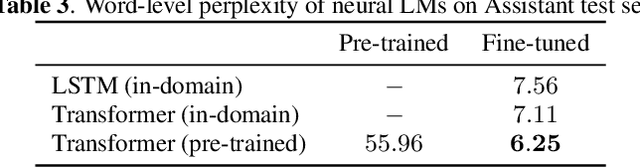
Although n-gram language models (LMs) have been outperformed by the state-of-the-art neural LMs, they are still widely used in speech recognition due to its high efficiency in inference. In this paper, we demonstrate that n-gram LM can be improved by neural LMs through a text generation based data augmentation method. In contrast to previous approaches, we employ a large-scale general domain pre-training followed by in-domain fine-tuning strategy to construct deep Transformer based neural LMs. Large amount of in-domain text data is generated with the well trained deep Transformer to construct new n-gram LMs, which are then interpolated with baseline n-gram systems. Empirical studies on different speech recognition tasks show that the proposed approach can effectively improve recognition accuracy. In particular, our proposed approach brings significant relative word error rate reduction up to 6.0% for domains with limited in-domain data.
A Method to Reveal Speaker Identity in Distributed ASR Training, and How to Counter It
Apr 15, 2021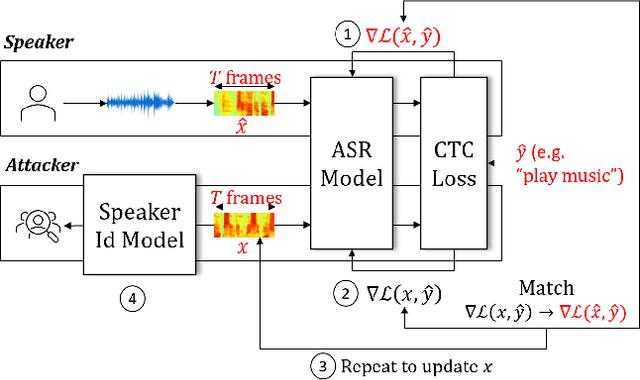

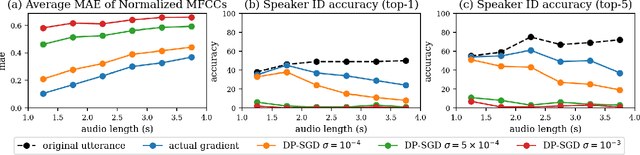
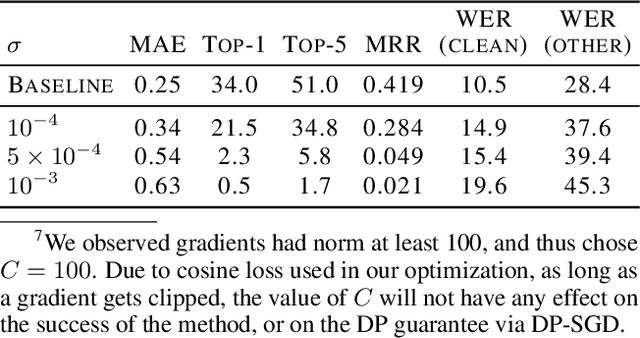
End-to-end Automatic Speech Recognition (ASR) models are commonly trained over spoken utterances using optimization methods like Stochastic Gradient Descent (SGD). In distributed settings like Federated Learning, model training requires transmission of gradients over a network. In this work, we design the first method for revealing the identity of the speaker of a training utterance with access only to a gradient. We propose Hessian-Free Gradients Matching, an input reconstruction technique that operates without second derivatives of the loss function (required in prior works), which can be expensive to compute. We show the effectiveness of our method using the DeepSpeech model architecture, demonstrating that it is possible to reveal the speaker's identity with 34% top-1 accuracy (51% top-5 accuracy) on the LibriSpeech dataset. Further, we study the effect of two well-known techniques, Differentially Private SGD and Dropout, on the success of our method. We show that a dropout rate of 0.2 can reduce the speaker identity accuracy to 0% top-1 (0.5% top-5).
Sentence Boundary Augmentation For Neural Machine Translation Robustness
Oct 21, 2020
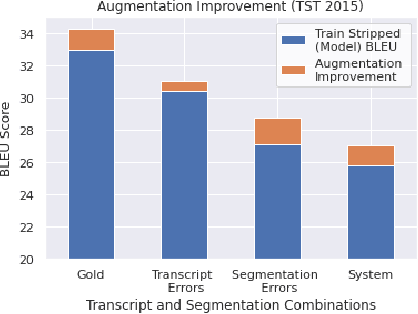

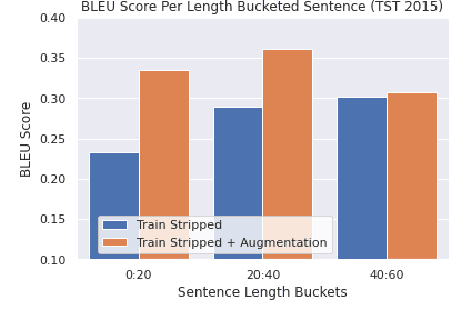
Neural Machine Translation (NMT) models have demonstrated strong state of the art performance on translation tasks where well-formed training and evaluation data are provided, but they remain sensitive to inputs that include errors of various types. Specifically, in the context of long-form speech translation systems, where the input transcripts come from Automatic Speech Recognition (ASR), the NMT models have to handle errors including phoneme substitutions, grammatical structure, and sentence boundaries, all of which pose challenges to NMT robustness. Through in-depth error analysis, we show that sentence boundary segmentation has the largest impact on quality, and we develop a simple data augmentation strategy to improve segmentation robustness.
End-to-end training of time domain audio separation and recognition
Dec 25, 2019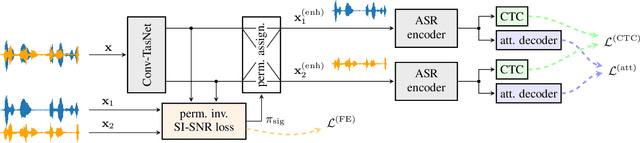


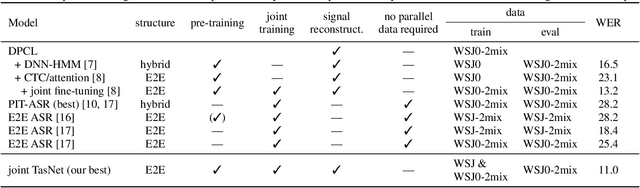
The rising interest in single-channel multi-speaker speech separation sparked development of End-to-End (E2E) approaches to multi-speaker speech recognition. However, up until now, state-of-the-art neural network-based time domain source separation has not yet been combined with E2E speech recognition. We here demonstrate how to combine a separation module based on a Convolutional Time domain Audio Separation Network (Conv-TasNet) with an E2E speech recognizer and how to train such a model jointly by distributing it over multiple GPUs or by approximating truncated back-propagation for the convolutional front-end. To put this work into perspective and illustrate the complexity of the design space, we provide a compact overview of single-channel multi-speaker recognition systems. Our experiments show a word error rate of 11.0% on WSJ0-2mix and indicate that our joint time domain model can yield substantial improvements over cascade DNN-HMM and monolithic E2E frequency domain systems proposed so far.
Large-scale Transfer Learning for Low-resource Spoken Language Understanding
Aug 13, 2020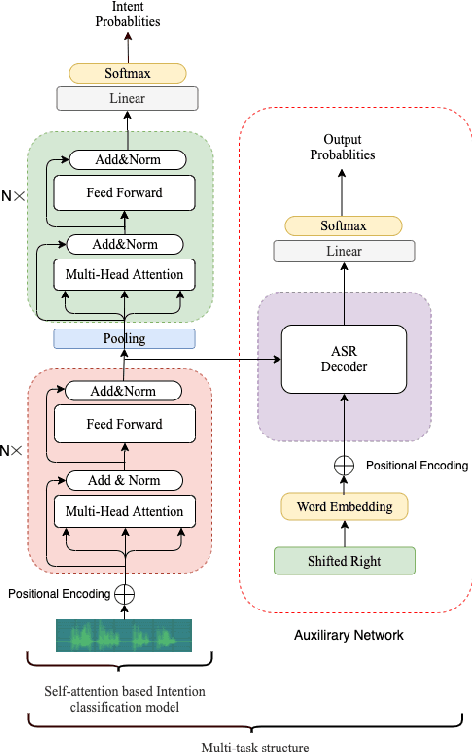
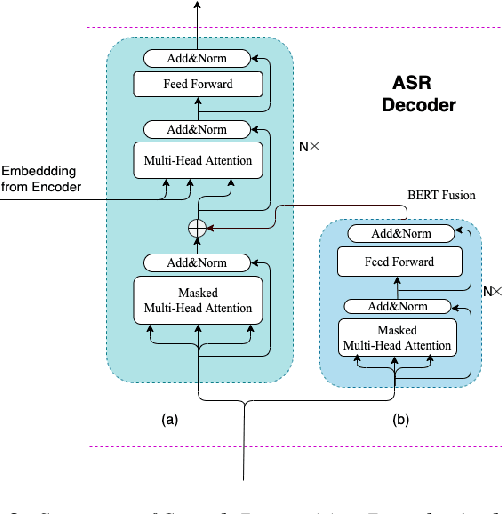
End-to-end Spoken Language Understanding (SLU) models are made increasingly large and complex to achieve the state-ofthe-art accuracy. However, the increased complexity of a model can also introduce high risk of over-fitting, which is a major challenge in SLU tasks due to the limitation of available data. In this paper, we propose an attention-based SLU model together with three encoder enhancement strategies to overcome data sparsity challenge. The first strategy focuses on the transferlearning approach to improve feature extraction capability of the encoder. It is implemented by pre-training the encoder component with a quantity of Automatic Speech Recognition annotated data relying on the standard Transformer architecture and then fine-tuning the SLU model with a small amount of target labelled data. The second strategy adopts multitask learning strategy, the SLU model integrates the speech recognition model by sharing the same underlying encoder, such that improving robustness and generalization ability. The third strategy, learning from Component Fusion (CF) idea, involves a Bidirectional Encoder Representation from Transformer (BERT) model and aims to boost the capability of the decoder with an auxiliary network. It hence reduces the risk of over-fitting and augments the ability of the underlying encoder, indirectly. Experiments on the FluentAI dataset show that cross-language transfer learning and multi-task strategies have been improved by up to 4:52% and 3:89% respectively, compared to the baseline.
Using Topological Framework for the Design of Activation Function and Model Pruning in Deep Neural Networks
Sep 03, 2021

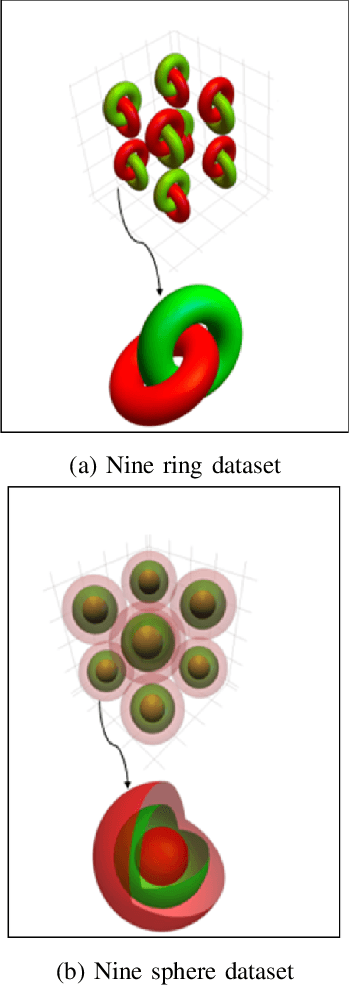
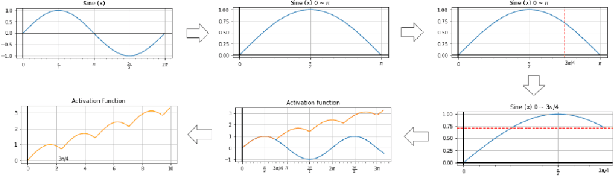
Success of deep neural networks in diverse tasks across domains of computer vision, speech recognition and natural language processing, has necessitated understanding the dynamics of training process and also working of trained models. Two independent contributions of this paper are 1) Novel activation function for faster training convergence 2) Systematic pruning of filters of models trained irrespective of activation function. We analyze the topological transformation of the space of training samples as it gets transformed by each successive layer during training, by changing the activation function. The impact of changing activation function on the convergence during training is reported for the task of binary classification. A novel activation function aimed at faster convergence for classification tasks is proposed. Here, Betti numbers are used to quantify topological complexity of data. Results of experiments on popular synthetic binary classification datasets with large Betti numbers(>150) using MLPs are reported. Results show that the proposed activation function results in faster convergence requiring fewer epochs by a factor of 1.5 to 2, since Betti numbers reduce faster across layers with the proposed activation function. The proposed methodology was verified on benchmark image datasets: fashion MNIST, CIFAR-10 and cat-vs-dog images, using CNNs. Based on empirical results, we propose a novel method for pruning a trained model. The trained model was pruned by eliminating filters that transform data to a topological space with large Betti numbers. All filters with Betti numbers greater than 300 were removed from each layer without significant reduction in accuracy. This resulted in faster prediction time and reduced memory size of the model.