 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
On Neural Phone Recognition of Mixed-Source ECoG Signals
Dec 12, 2019
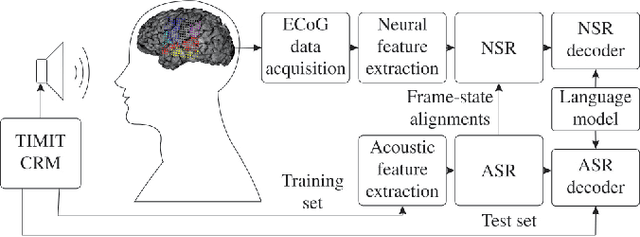

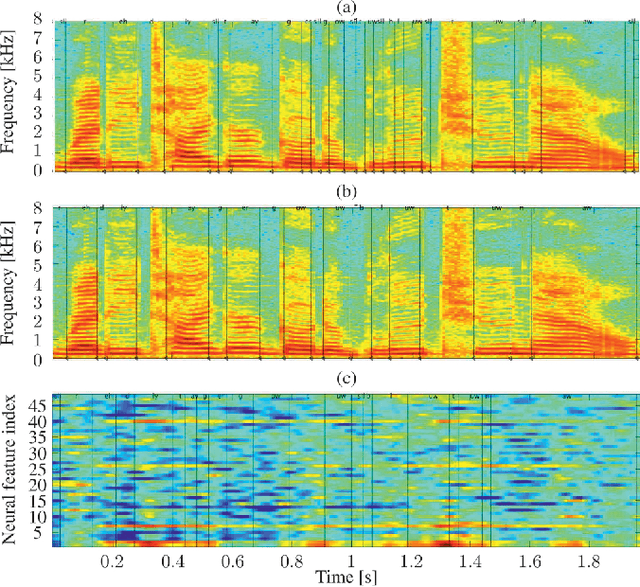
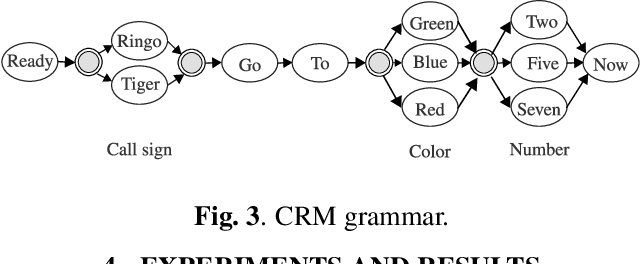
The emerging field of neural speech recognition (NSR) using electrocorticography has recently attracted remarkable research interest for studying how human brains recognize speech in quiet and noisy surroundings. In this study, we demonstrate the utility of NSR systems to objectively prove the ability of human beings to attend to a single speech source while suppressing the interfering signals in a simulated cocktail party scenario. The experimental results show that the relative degradation of the NSR system performance when tested in a mixed-source scenario is significantly lower than that of automatic speech recognition (ASR). In this paper, we have significantly enhanced the performance of our recently published framework by using manual alignments for initialization instead of the flat start technique. We have also improved the NSR system performance by accounting for the possible transcription mismatch between the acoustic and neural signals.
Deploying Technology to Save Endangered Languages
Sep 01, 2019Computer scientists working on natural language processing, native speakers of endangered languages, and field linguists to discuss ways to harness Automatic Speech Recognition, especially neural networks, to automate annotation, speech tagging, and text parsing on endangered languages.
Breaking the Data Barrier: Towards Robust Speech Translation via Adversarial Stability Training
Oct 28, 2019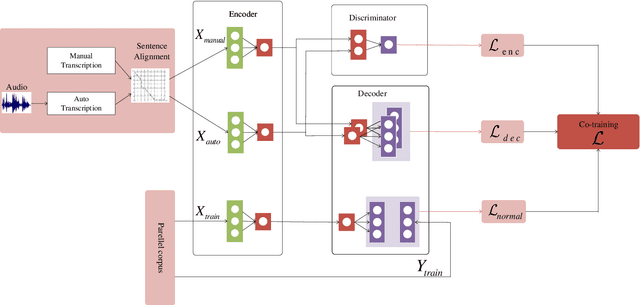
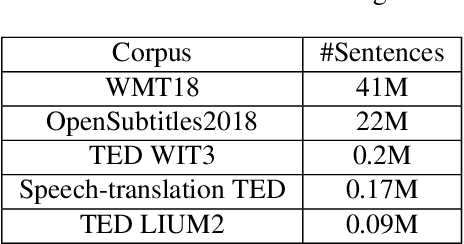
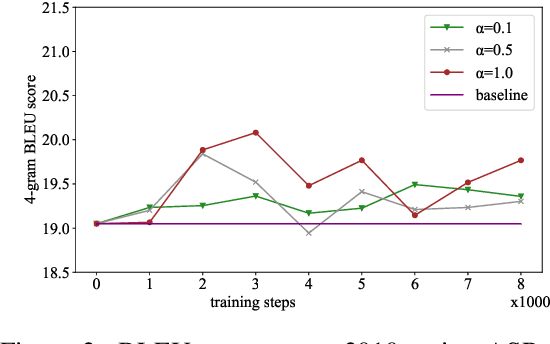
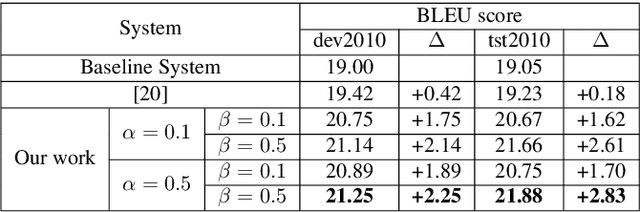
In a pipeline speech translation system, automatic speech recognition (ASR) system will transmit errors in recognition to the downstream machine translation (MT) system. A standard machine translation system is usually trained on parallel corpus composed of clean text and will perform poorly on text with recognition noise, a gap well known in speech translation community. In this paper, we propose a training architecture which aims at making a neural machine translation model more robust against speech recognition errors. Our approach addresses the encoder and the decoder simultaneously using adversarial learning and data augmentation, respectively. Experimental results on IWSLT2018 speech translation task show that our approach can bridge the gap between the ASR output and the MT input, outperforms the baseline by up to 2.83 BLEU on noisy ASR output, while maintaining close performance on clean text.
XLST: Cross-lingual Self-training to Learn Multilingual Representation for Low Resource Speech Recognition
Mar 15, 2021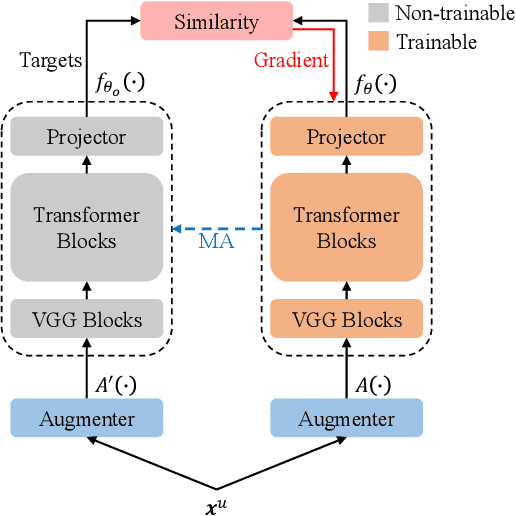
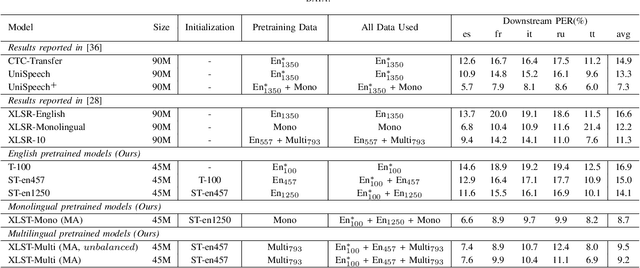
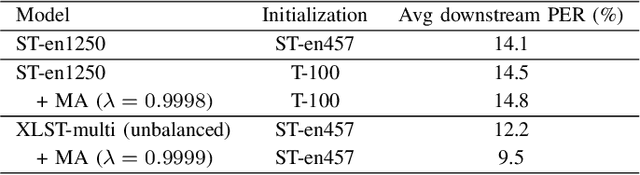

In this paper, we propose a weakly supervised multilingual representation learning framework, called cross-lingual self-training (XLST). XLST is able to utilize a small amount of annotated data from high-resource languages to improve the representation learning on multilingual un-annotated data. Specifically, XLST uses a supervised trained model to produce initial representations and another model to learn from them, by maximizing the similarity between output embeddings of these two models. Furthermore, the moving average mechanism and multi-view data augmentation are employed, which are experimentally shown to be crucial to XLST. Comprehensive experiments have been conducted on the CommonVoice corpus to evaluate the effectiveness of XLST. Results on 5 downstream low-resource ASR tasks shows that our multilingual pretrained model achieves relatively 18.6% PER reduction over the state-of-the-art self-supervised method, with leveraging additional 100 hours of annotated English data.
On-the-Fly Aligned Data Augmentation for Sequence-to-Sequence ASR
Apr 03, 2021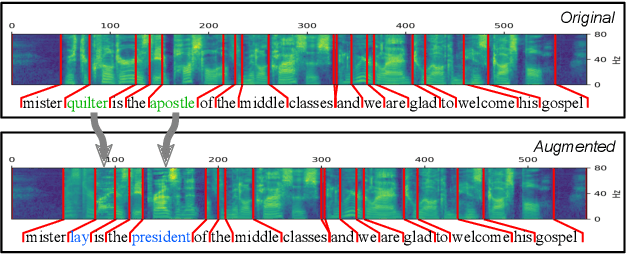
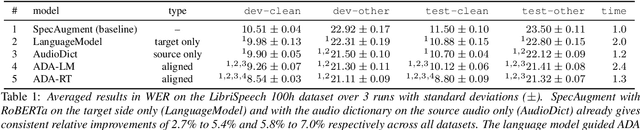
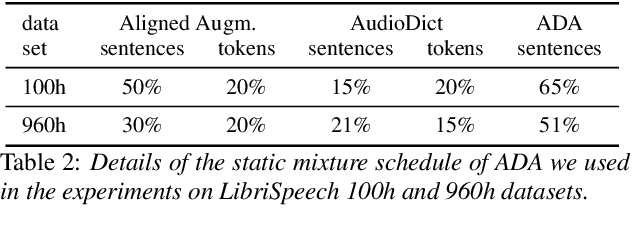

We propose an on-the-fly data augmentation method for automatic speech recognition (ASR) that uses alignment information to generate effective training samples. Our method, called Aligned Data Augmentation (ADA) for ASR, replaces transcribed tokens and the speech representations in an aligned manner to generate previously unseen training pairs. The speech representations are sampled from an audio dictionary that has been extracted from the training corpus and inject speaker variations into the training examples. The transcribed tokens are either predicted by a language model such that the augmented data pairs are semantically close to the original data, or randomly sampled. Both strategies result in training pairs that improve robustness in ASR training. Our experiments on a Seq-to-Seq architecture show that ADA can be applied on top of SpecAugment, and achieves about 9-23% and 4-15% relative improvements in WER over SpecAugment alone on LibriSpeech 100h and LibriSpeech 960h test datasets, respectively.
Speaker Separation Using Speaker Inventories and Estimated Speech
Oct 20, 2020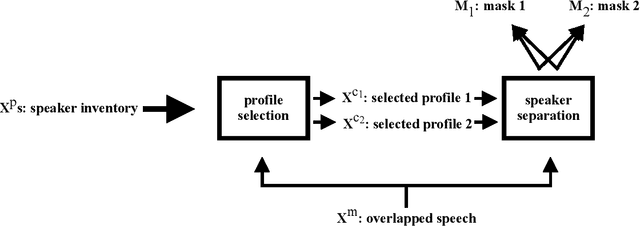
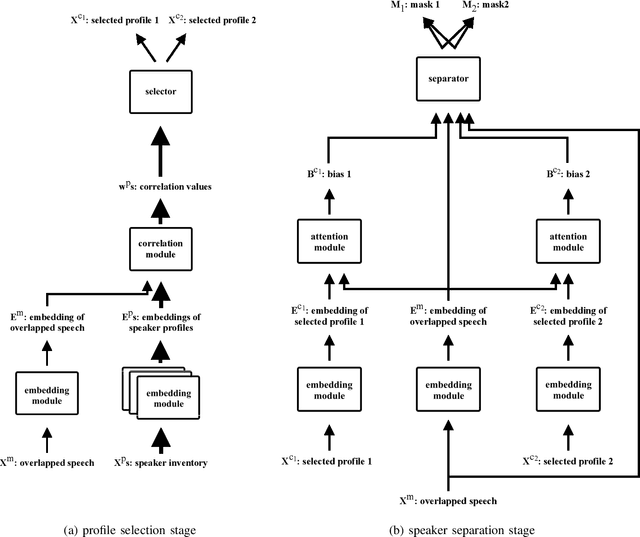
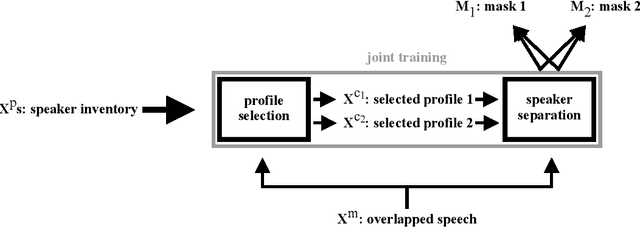
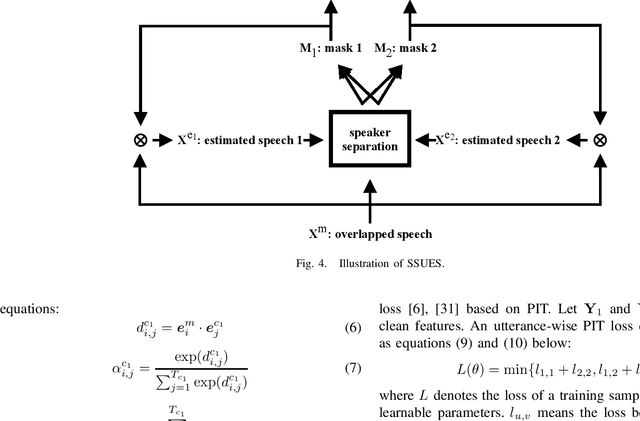
We propose speaker separation using speaker inventories and estimated speech (SSUSIES), a framework leveraging speaker profiles and estimated speech for speaker separation. SSUSIES contains two methods, speaker separation using speaker inventories (SSUSI) and speaker separation using estimated speech (SSUES). SSUSI performs speaker separation with the help of speaker inventory. By combining the advantages of permutation invariant training (PIT) and speech extraction, SSUSI significantly outperforms conventional approaches. SSUES is a widely applicable technique that can substantially improve speaker separation performance using the output of first-pass separation. We evaluate the models on both speaker separation and speech recognition metrics.
Sequence-level Confidence Classifier for ASR Utterance Accuracy and Application to Acoustic Models
Jun 30, 2021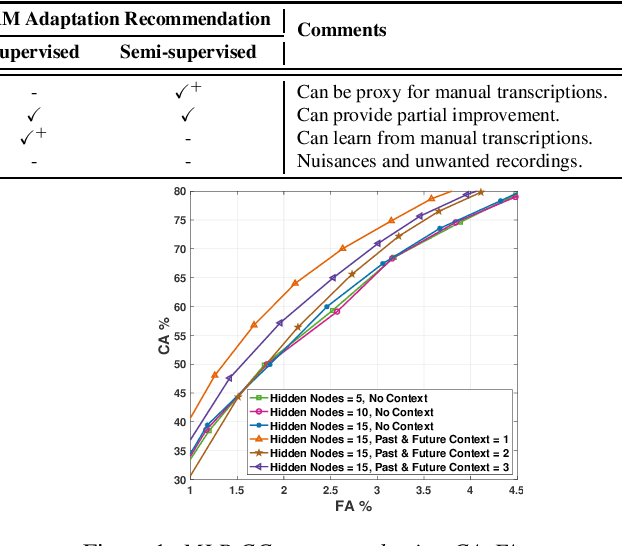
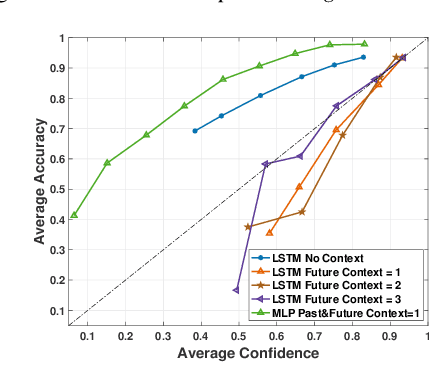

Scores from traditional confidence classifiers (CCs) in automatic speech recognition (ASR) systems lack universal interpretation and vary with updates to the underlying confidence or acoustic models (AMs). In this work, we build interpretable confidence scores with an objective to closely align with ASR accuracy. We propose a new sequence-level CC with a richer context providing CC scores highly correlated with ASR accuracy and scores stable across CC updates. Hence, expanding CC applications. Recently, AM customization has gained traction with the widespread use of unified models. Conventional adaptation strategies that customize AM expect well-matched data for the target domain with gold-standard transcriptions. We propose a cost-effective method of using CC scores to select an optimal adaptation data set, where we maximize ASR gains from minimal data. We study data in various confidence ranges and optimally choose data for AM adaptation with KL-Divergence regularization. On the Microsoft voice search task, data selection for supervised adaptation using the sequence-level confidence scores achieves word error rate reduction (WERR) of 8.5% for row-convolution LSTM (RC-LSTM) and 5.2% for latency-controlled bidirectional LSTM (LC-BLSTM). In the semi-supervised case, with ASR hypotheses as labels, our method provides WERR of 5.9% and 2.8% for RC-LSTM and LC-BLSTM, respectively.
Towards Abstractive Grounded Summarization of Podcast Transcripts
Mar 22, 2022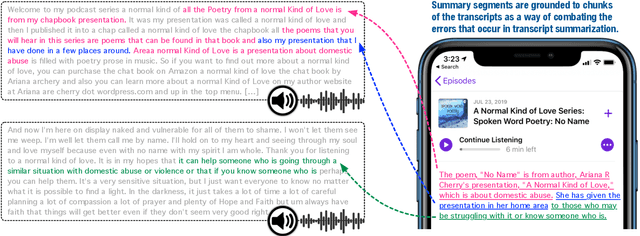

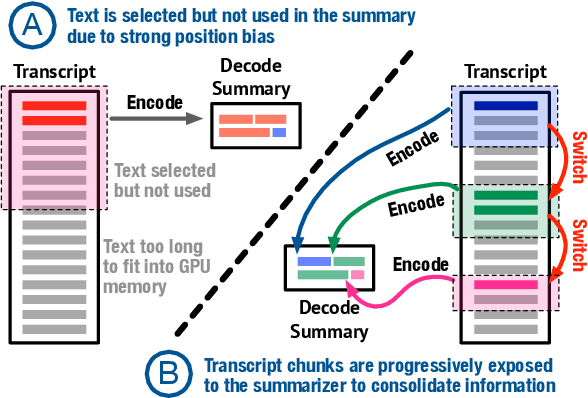
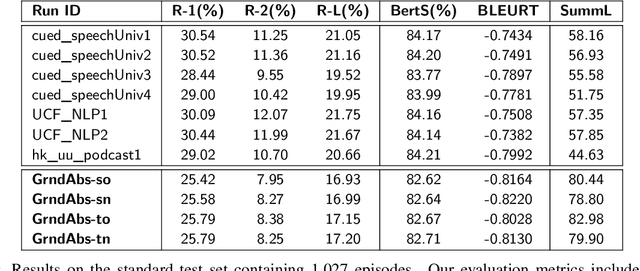
Podcasts have recently shown a rapid rise in popularity. Summarization of podcast transcripts is of practical benefit to both content providers and consumers. It helps consumers to quickly decide whether they will listen to the podcasts and reduces the cognitive load of content providers to write summaries. Nevertheless, podcast summarization faces significant challenges including factual inconsistencies with respect to the inputs. The problem is exacerbated by speech disfluencies and recognition errors in transcripts of spoken language. In this paper, we explore a novel abstractive summarization method to alleviate these challenges. Specifically, our approach learns to produce an abstractive summary while grounding summary segments in specific portions of the transcript to allow for full inspection of summary details. We conduct a series of analyses of the proposed approach on a large podcast dataset and show that the approach can achieve promising results. Grounded summaries bring clear benefits in locating the summary and transcript segments that contain inconsistent information, and hence significantly improve summarization quality in both automatic and human evaluation metrics.
On Addressing Practical Challenges for RNN-Transducer
May 04, 2021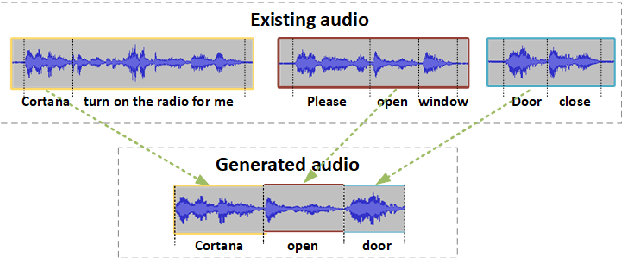

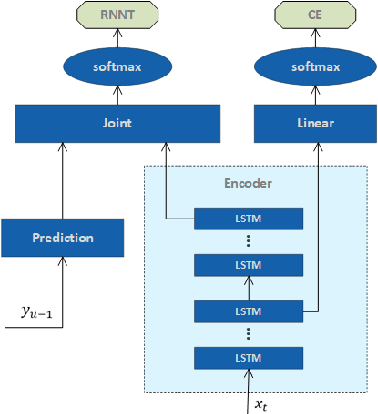

In this paper, several works are proposed to address practical challenges for deploying RNN Transducer (RNN-T) based speech recognition system. These challenges are adapting a well-trained RNN-T model to a new domain without collecting the audio data, obtaining time stamps and confidence scores at word level. The first challenge is solved with a splicing data method which concatenates the speech segments extracted from the source domain data. To get the time stamp, a phone prediction branch is added to the RNN-T model by sharing the encoder for the purpose of force alignment. Finally, we obtain word-level confidence scores by utilizing several types of features calculated during decoding and from confusion network. Evaluated with Microsoft production data, the splicing data adaptation method improves the baseline and adaption with the text to speech method by 58.03% and 15.25% relative word error rate reduction, respectively. The proposed time stamping method can get less than 50ms word timing difference on average while maintaining the recognition accuracy of the RNN-T model. We also obtain high confidence annotation performance with limited computation cost.
Speech frame implementation for speech analysis and recognition
Dec 15, 2021
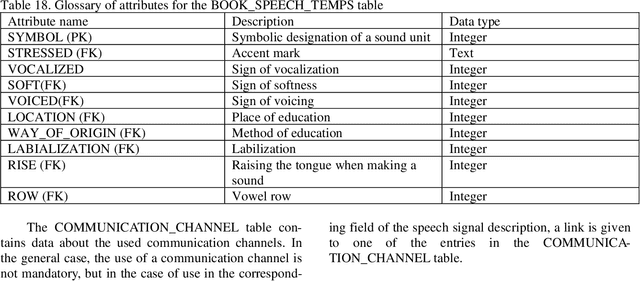

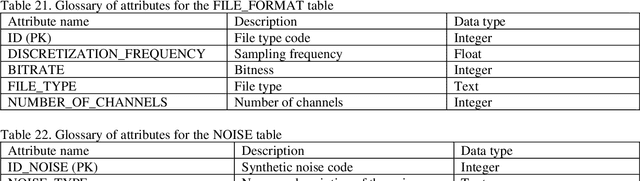
Distinctive features of the created speech frame are: the ability to take into account the emotional state of the speaker, sup-port for working with diseases of the speech-forming tract of speakers and the presence of manual segmentation of a num-ber of speech signals. In addition, the system is focused on Russian-language speech material, unlike most analogs.