 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Speech SIMCLR: Combining Contrastive and Reconstruction Objective for Self-supervised Speech Representation Learning
Oct 27, 2020
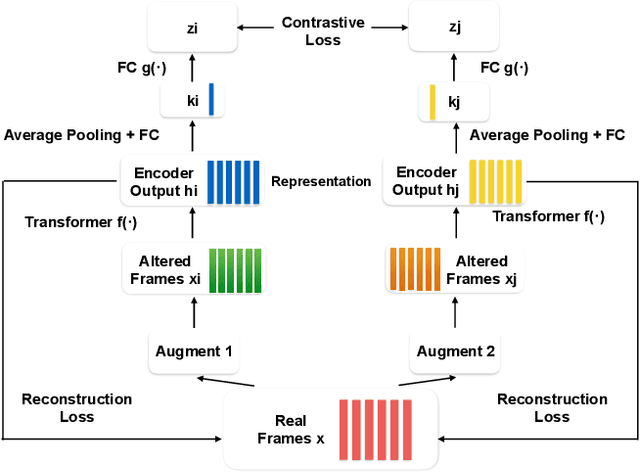

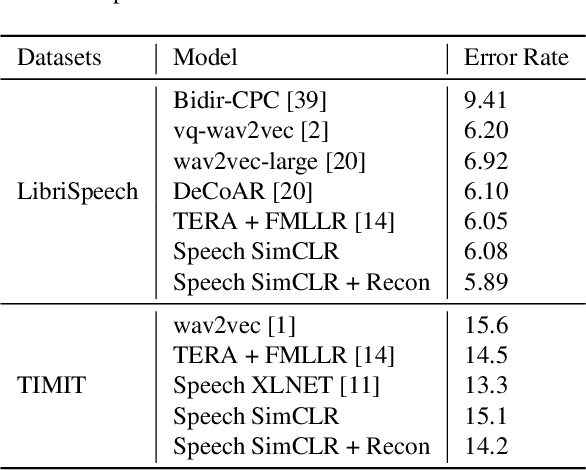

Self-supervised visual pretraining has shown significant progress recently. Among those methods, SimCLR greatly advanced the state of the art in self-supervised and semi-supervised learning on ImageNet. The input feature representations for speech and visual tasks are both continuous, so it is natural to consider applying similar objective on speech representation learning. In this paper, we propose Speech SimCLR, a new self-supervised objective for speech representation learning. During training, Speech SimCLR applies augmentation on raw speech and its spectrogram. Its objective is the combination of contrastive loss that maximizes agreement between differently augmented samples in the latent space and reconstruction loss of input representation. The proposed method achieved competitive results on speech emotion recognition and speech recognition. When used as feature extractor, our best model achieved 5.89% word error rate on LibriSpeech test-clean set using LibriSpeech 960 hours as pretraining data and LibriSpeech train-clean-100 set as fine-tuning data, which is the lowest error rate obtained in this setup to the best of our knowledge.
Transfer Learning and SpecAugment applied to SSVEP Based BCI Classification
Oct 08, 2020
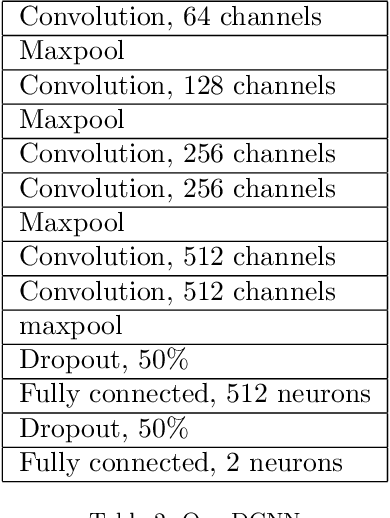
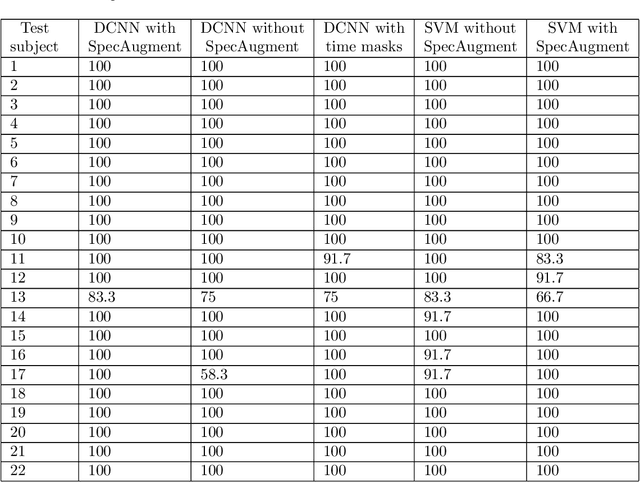
In this work, we used a deep convolutional neural network (DCNN) to classify electroencephalography (EEG) signals in a steady-state visually evoked potentials (SSVEP) based brain-computer interface (BCI). The raw EEG signals were converted to spectrograms and served as input to train a DCNN using the transfer learning technique. We applied a second technique, data augmentation, mostly SpecAugment, generally employed to speech recognition. The results, when excluding the evaluated user's data from the fine-tuning process, reached 99.3% mean test accuracy and 0.992 mean F1 score on 35 subjects from an open dataset.
Multilingual and Cross-Lingual Intent Detection from Spoken Data
Apr 17, 2021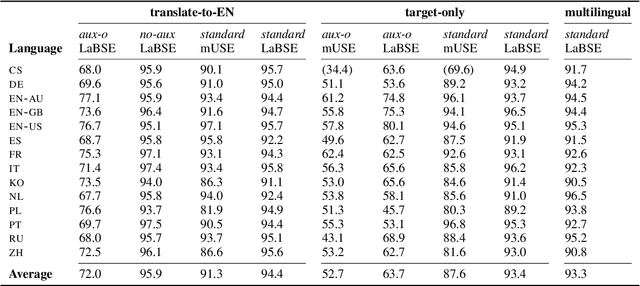
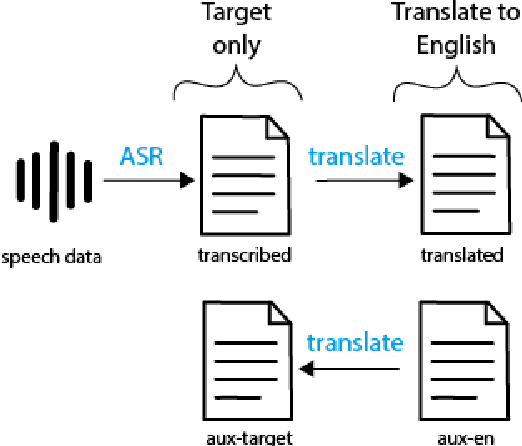
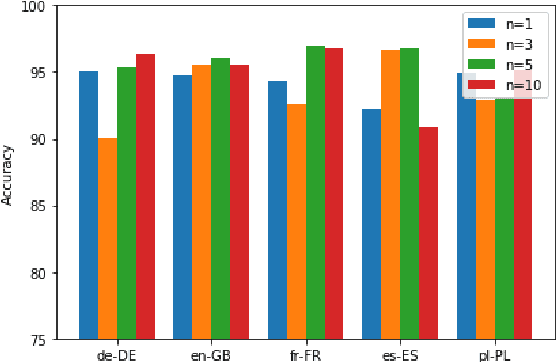
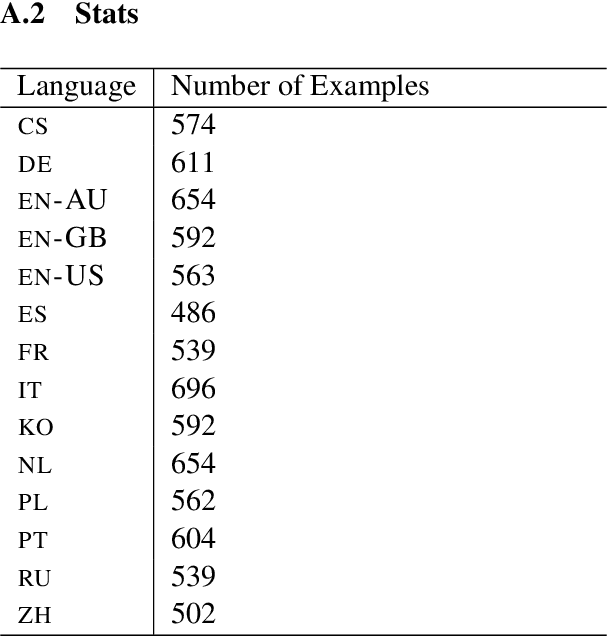
We present a systematic study on multilingual and cross-lingual intent detection from spoken data. The study leverages a new resource put forth in this work, termed MInDS-14, a first training and evaluation resource for the intent detection task with spoken data. It covers 14 intents extracted from a commercial system in the e-banking domain, associated with spoken examples in 14 diverse language varieties. Our key results indicate that combining machine translation models with state-of-the-art multilingual sentence encoders (e.g., LaBSE) can yield strong intent detectors in the majority of target languages covered in MInDS-14, and offer comparative analyses across different axes: e.g., zero-shot versus few-shot learning, translation direction, and impact of speech recognition. We see this work as an important step towards more inclusive development and evaluation of multilingual intent detectors from spoken data, in a much wider spectrum of languages compared to prior work.
ASR is all you need: cross-modal distillation for lip reading
Nov 28, 2019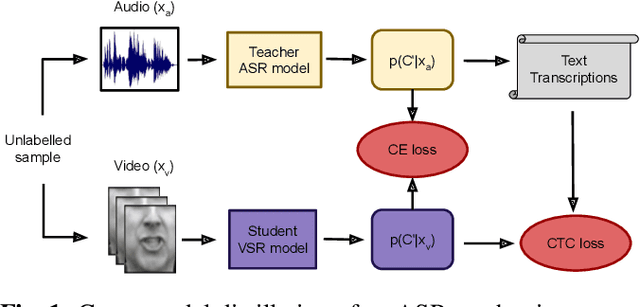
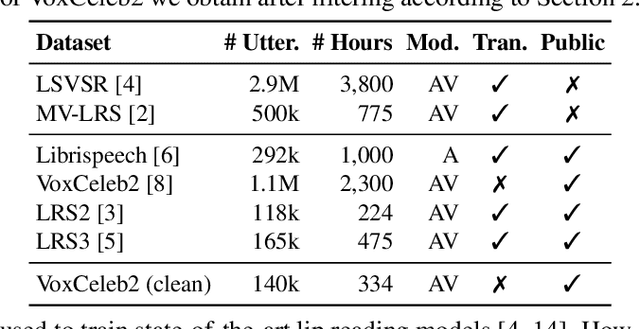
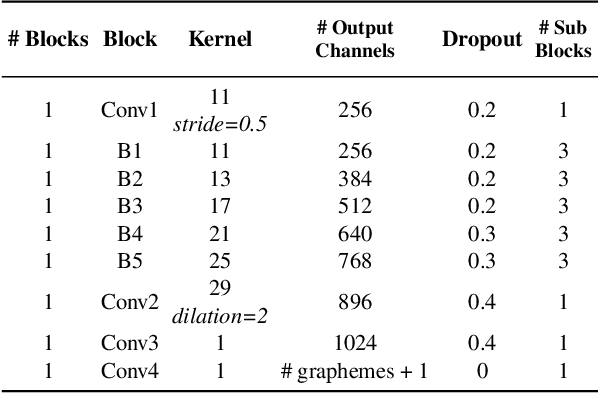
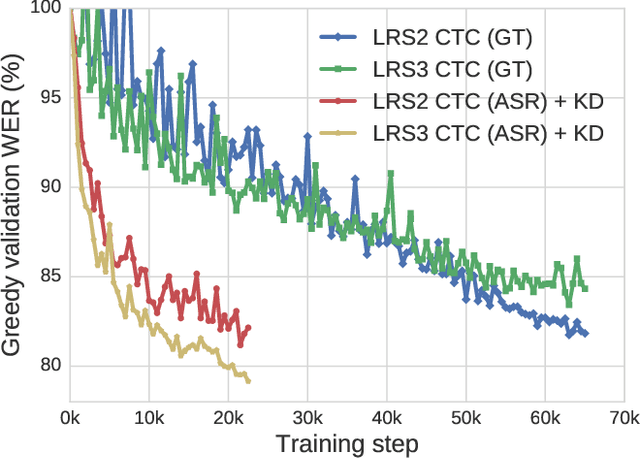
The goal of this work is to train strong models for visual speech recognition without requiring human annotated ground truth data. We achieve this by distilling from an Automatic Speech Recognition (ASR) model that has been trained on a large-scale audio-only corpus. We use a cross-modal distillation method that combines CTC with a frame-wise cross-entropy loss. Our contributions are fourfold: (i) we show that ground truth transcriptions are not necessary to train a lip reading system; (ii) we show how arbitrary amounts of unlabelled video data can be leveraged to improve performance; (iii) we demonstrate that distillation significantly speeds up training; and, (iv) we obtain state-of-the-art results on the challenging LRS2 and LRS3 datasets for training only on publicly available data.
Task-aware Warping Factors in Mask-based Speech Enhancement
Aug 27, 2021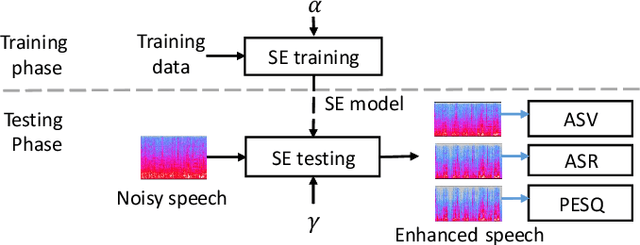
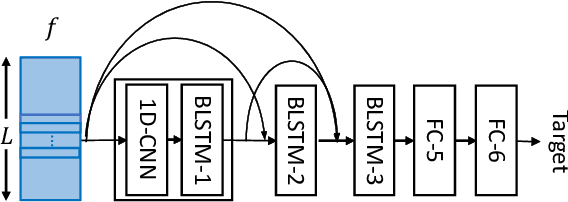
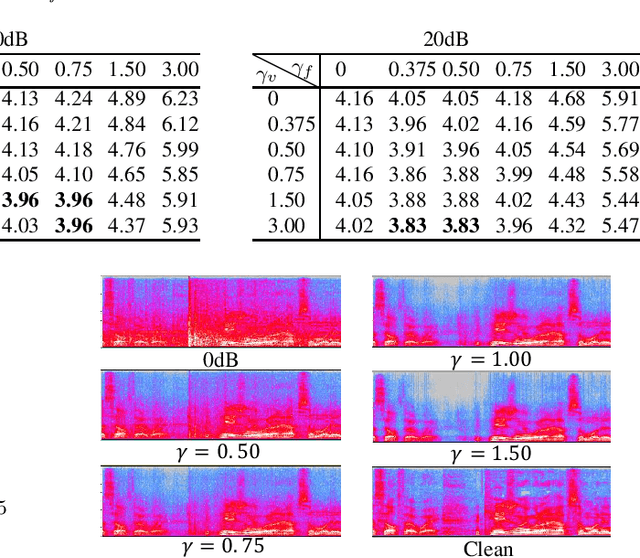
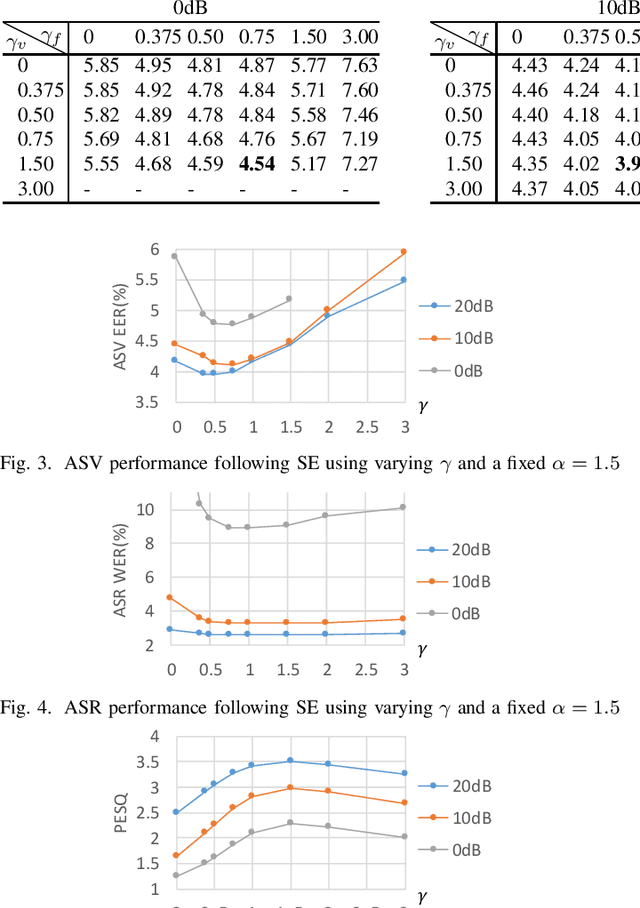
This paper proposes the use of two task-aware warping factors in mask-based speech enhancement (SE). One controls the balance between speech-maintenance and noise-removal in training phases, while the other controls SE power applied to specific downstream tasks in testing phases. Our intention is to alleviate the problem that SE systems trained to improve speech quality often fail to improve other downstream tasks, such as automatic speaker verification (ASV) and automatic speech recognition (ASR), because they do not share the same objects. It is easy to apply the proposed dual-warping factors approach to any mask-based SE method, and it allows a single SE system to handle multiple tasks without task-dependent training. The effectiveness of our proposed approach has been confirmed on the SITW dataset for ASV evaluation and the LibriSpeech dataset for ASR and speech quality evaluations of 0-20dB. We show that different warping values are necessary for a single SE to achieve optimal performance w.r.t. the three tasks. With the use of task-dependent warping factors, speech quality was improved by an 84.7% PESQ increase, ASV had a 22.4% EER reduction, and ASR had a 52.2% WER reduction, on 0dB speech. The effectiveness of the task-dependent warping factors were also cross-validated on VoxCeleb-1 test set for ASV and LibriSpeech dev-clean set for ASV and quality evaluations. The proposed method is highly effective and easy to apply in practice.
Post-Editing Error Correction Algorithm for Speech Recognition using Bing Spelling Suggestion
Mar 23, 2012
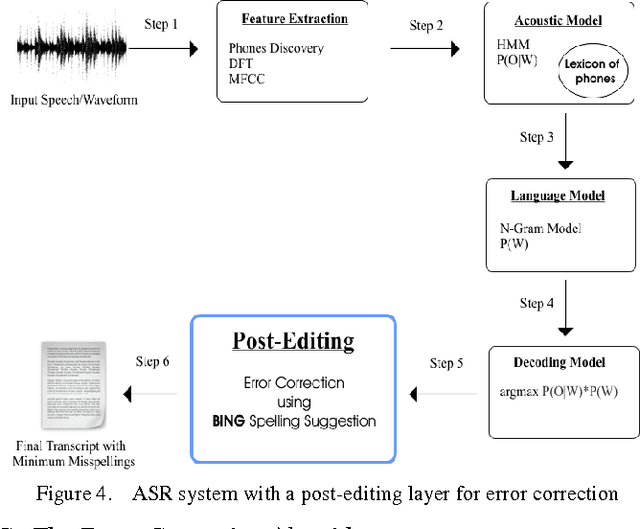
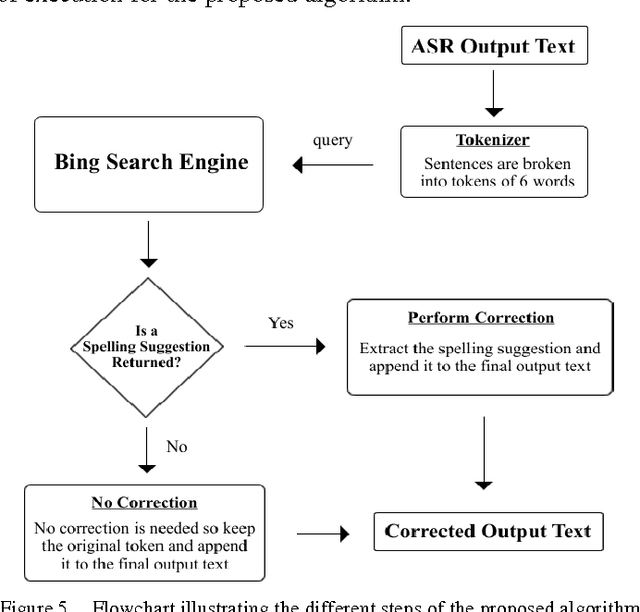
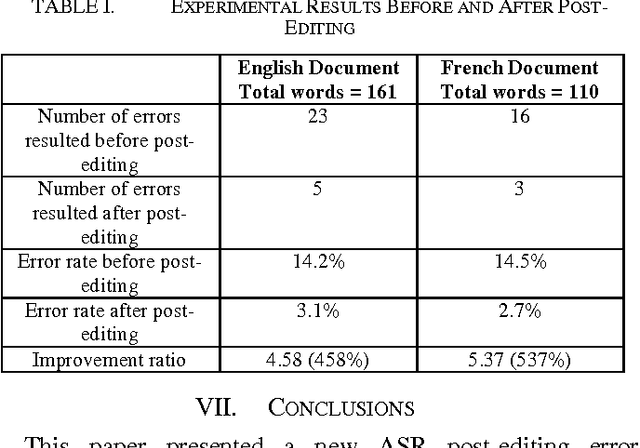
ASR short for Automatic Speech Recognition is the process of converting a spoken speech into text that can be manipulated by a computer. Although ASR has several applications, it is still erroneous and imprecise especially if used in a harsh surrounding wherein the input speech is of low quality. This paper proposes a post-editing ASR error correction method and algorithm based on Bing's online spelling suggestion. In this approach, the ASR recognized output text is spell-checked using Bing's spelling suggestion technology to detect and correct misrecognized words. More specifically, the proposed algorithm breaks down the ASR output text into several word-tokens that are submitted as search queries to Bing search engine. A returned spelling suggestion implies that a query is misspelled; and thus it is replaced by the suggested correction; otherwise, no correction is performed and the algorithm continues with the next token until all tokens get validated. Experiments carried out on various speeches in different languages indicated a successful decrease in the number of ASR errors and an improvement in the overall error correction rate. Future research can improve upon the proposed algorithm so much so that it can be parallelized to take advantage of multiprocessor computers.
* LACSC - Lebanese Association for Computational Sciences - http://www.lacsc.org
A Configurable Multilingual Model is All You Need to Recognize All Languages
Jul 13, 2021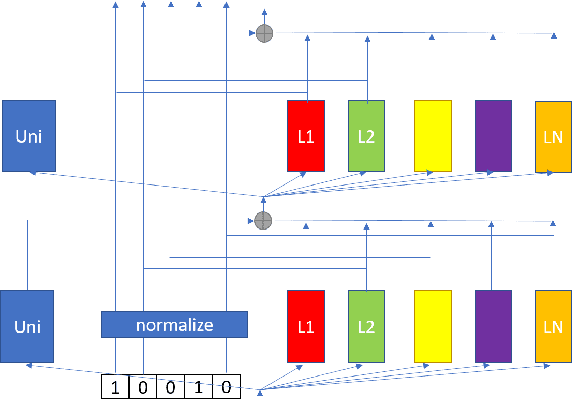
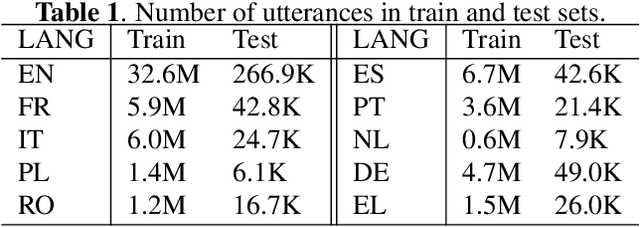
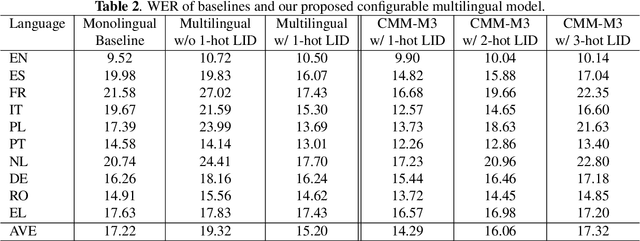
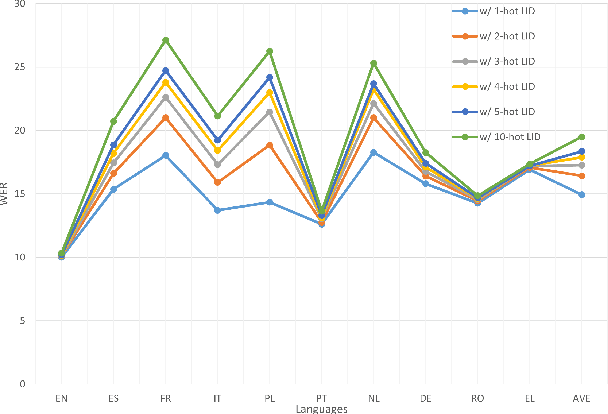
Multilingual automatic speech recognition (ASR) models have shown great promise in recent years because of the simplified model training and deployment process. Conventional methods either train a universal multilingual model without taking any language information or with a 1-hot language ID (LID) vector to guide the recognition of the target language. In practice, the user can be prompted to pre-select several languages he/she can speak. The multilingual model without LID cannot well utilize the language information set by the user while the multilingual model with LID can only handle one pre-selected language. In this paper, we propose a novel configurable multilingual model (CMM) which is trained only once but can be configured as different models based on users' choices by extracting language-specific modules together with a universal model from the trained CMM. Particularly, a single CMM can be deployed to any user scenario where the users can pre-select any combination of languages. Trained with 75K hours of transcribed anonymized Microsoft multilingual data and evaluated with 10-language test sets, the proposed CMM improves from the universal multilingual model by 26.0%, 16.9%, and 10.4% relative word error reduction when the user selects 1, 2, or 3 languages, respectively. CMM also performs significantly better on code-switching test sets.
Spartus: A 9.4 TOp/s FPGA-based LSTM Accelerator Exploiting Spatio-temporal Sparsity
Aug 04, 2021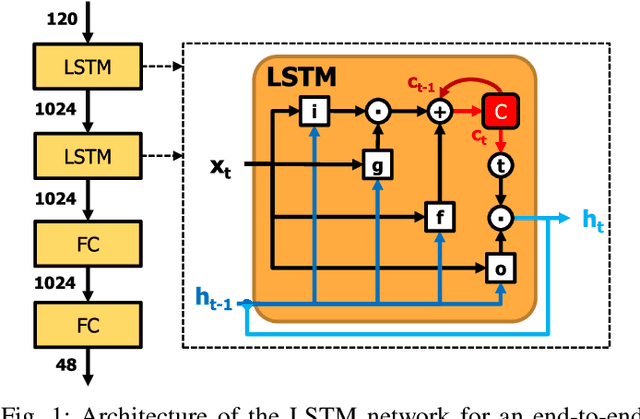
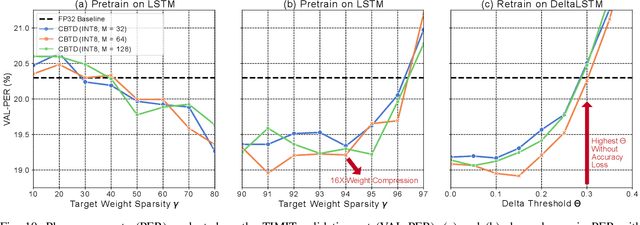
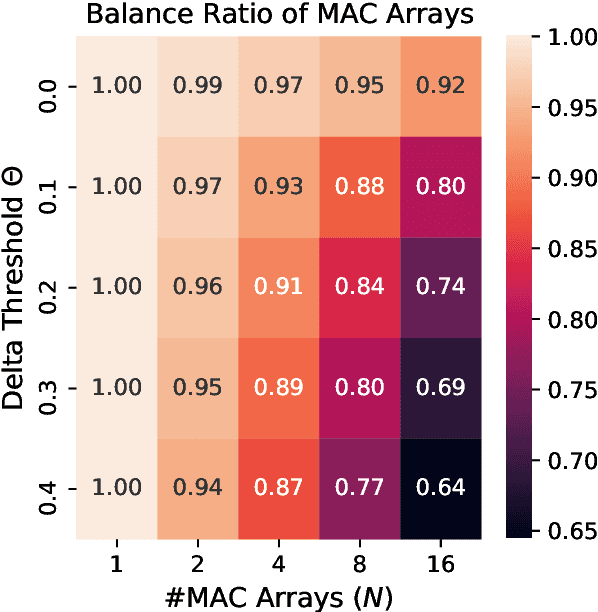
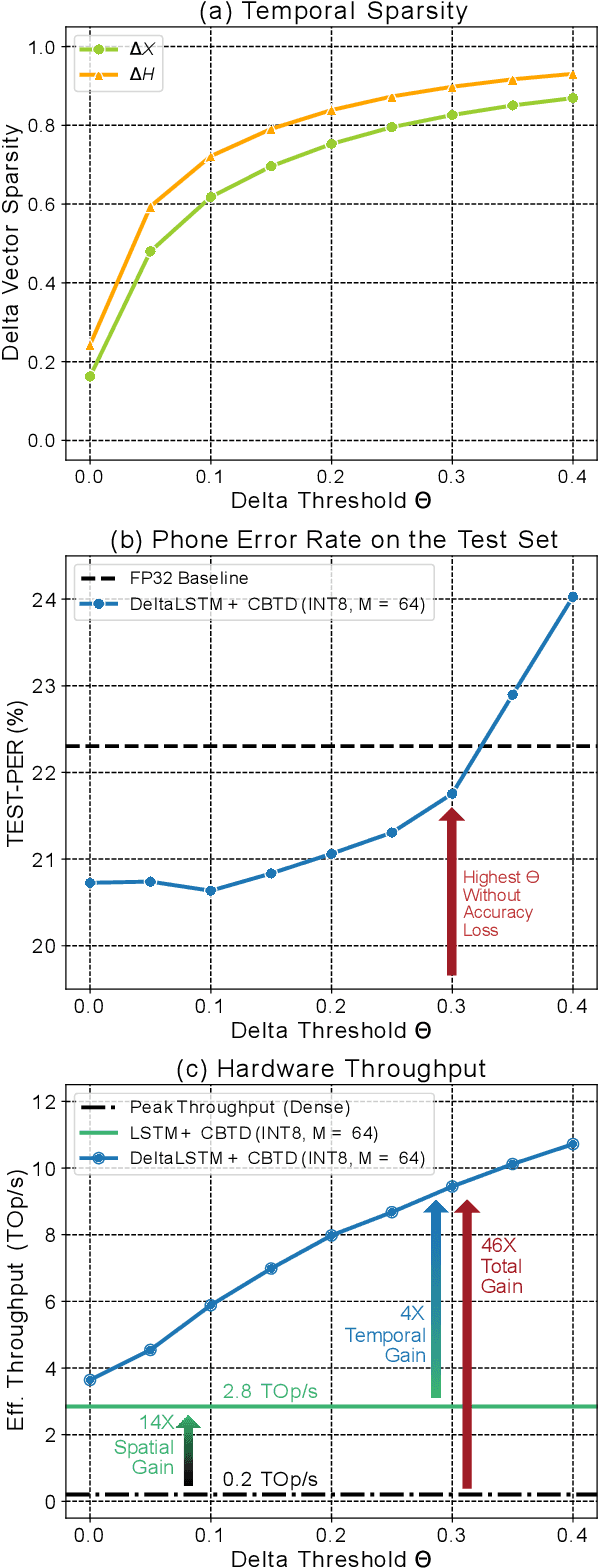
Long Short-Term Memory (LSTM) recurrent networks are frequently used for tasks involving time sequential data such as speech recognition. However, it is difficult to deploy these networks on hardware to achieve high throughput and low latency because the fully-connected structure makes LSTM networks a memory-bounded algorithm. Previous work in LSTM accelerators either exploited weight spatial sparsity or temporal sparsity. In this paper, we present a new accelerator called "Spartus" that exploits spatio-temporal sparsity to achieve ultra-low latency inference. The spatial sparsity was induced using our proposed pruning method called Column-Balanced Targeted Dropout (CBTD) that leads to structured sparse weight matrices benefiting workload balance. It achieved up to 96% weight sparsity with negligible accuracy difference for an LSTM network trained on a TIMIT phone recognition task. To induce temporal sparsity in LSTM, we create the DeltaLSTM by extending the previous DeltaGRU method to the LSTM network. This combined sparsity saves on weight memory access and associated arithmetic operations simultaneously. Spartus was implemented on a Xilinx Zynq-7100 FPGA. The per-sample latency for a single DeltaLSTM layer of 1024 neurons running on Spartus is 1 us. Spartus achieved 9.4 TOp/s effective batch-1 throughput and 1.1 TOp/J energy efficiency, which are respectively 4X and 7X higher than the previous state-of-the-art.
Efficient Deep Learning: A Survey on Making Deep Learning Models Smaller, Faster, and Better
Jun 16, 2021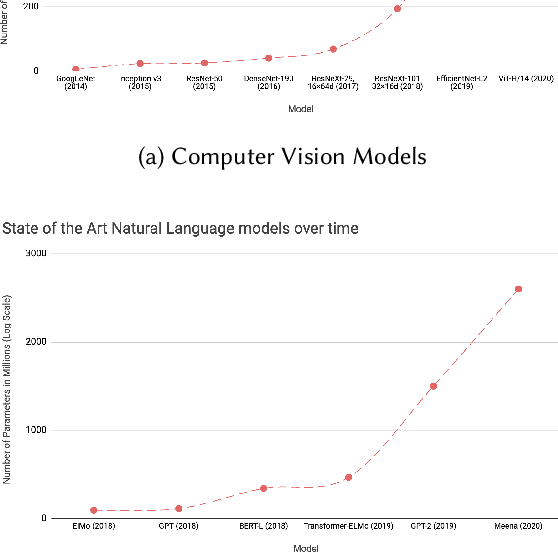
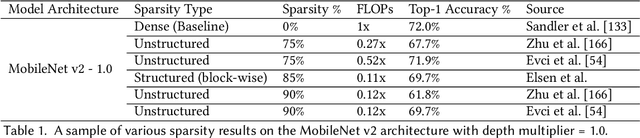

Deep Learning has revolutionized the fields of computer vision, natural language understanding, speech recognition, information retrieval and more. However, with the progressive improvements in deep learning models, their number of parameters, latency, resources required to train, etc. have all have increased significantly. Consequently, it has become important to pay attention to these footprint metrics of a model as well, not just its quality. We present and motivate the problem of efficiency in deep learning, followed by a thorough survey of the five core areas of model efficiency (spanning modeling techniques, infrastructure, and hardware) and the seminal work there. We also present an experiment-based guide along with code, for practitioners to optimize their model training and deployment. We believe this is the first comprehensive survey in the efficient deep learning space that covers the landscape of model efficiency from modeling techniques to hardware support. Our hope is that this survey would provide the reader with the mental model and the necessary understanding of the field to apply generic efficiency techniques to immediately get significant improvements, and also equip them with ideas for further research and experimentation to achieve additional gains.
Equivalence of Segmental and Neural Transducer Modeling: A Proof of Concept
Apr 13, 2021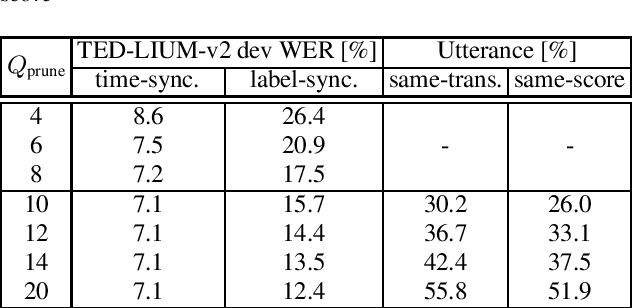
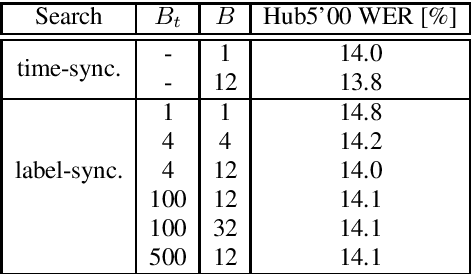
With the advent of direct models in automatic speech recognition (ASR), the formerly prevalent frame-wise acoustic modeling based on hidden Markov models (HMM) diversified into a number of modeling architectures like encoder-decoder attention models, transducer models and segmental models (direct HMM). While transducer models stay with a frame-level model definition, segmental models are defined on the level of label segments, directly. While (soft-)attention-based models avoid explicit alignment, transducer and segmental approach internally do model alignment, either by segment hypotheses or, more implicitly, by emitting so-called blank symbols. In this work, we prove that the widely used class of RNN-Transducer models and segmental models (direct HMM) are equivalent and therefore show equal modeling power. It is shown that blank probabilities translate into segment length probabilities and vice versa. In addition, we provide initial experiments investigating decoding and beam-pruning, comparing time-synchronous and label-/segment-synchronous search strategies and their properties using the same underlying model.