 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Low-rank Adaptation of Large Language Model Rescoring for Parameter-Efficient Speech Recognition
Sep 26, 2023
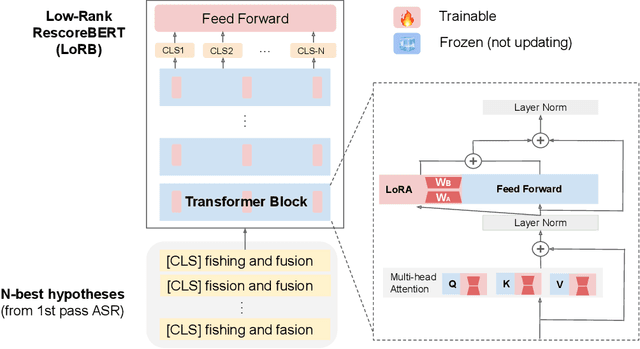
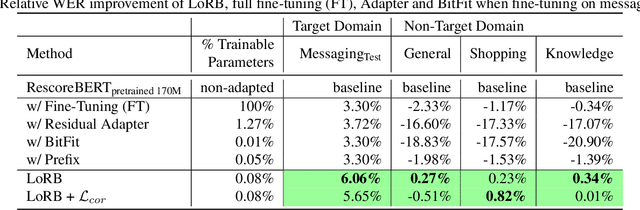
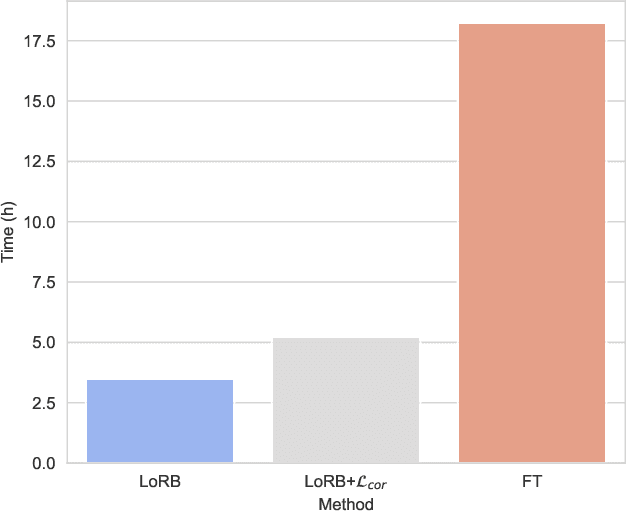
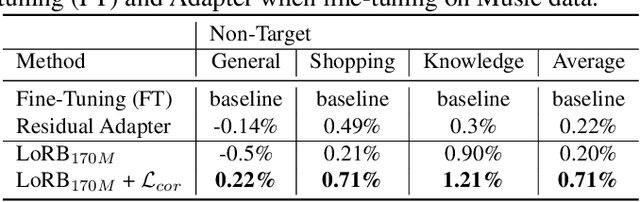
We propose a neural language modeling system based on low-rank adaptation (LoRA) for speech recognition output rescoring. Although pretrained language models (LMs) like BERT have shown superior performance in second-pass rescoring, the high computational cost of scaling up the pretraining stage and adapting the pretrained models to specific domains limit their practical use in rescoring. Here we present a method based on low-rank decomposition to train a rescoring BERT model and adapt it to new domains using only a fraction (0.08%) of the pretrained parameters. These inserted matrices are optimized through a discriminative training objective along with a correlation-based regularization loss. The proposed low-rank adaptation Rescore-BERT (LoRB) architecture is evaluated on LibriSpeech and internal datasets with decreased training times by factors between 5.4 and 3.6.
A Review of Hybrid and Ensemble in Deep Learning for Natural Language Processing
Dec 09, 2023This review presents a comprehensive exploration of hybrid and ensemble deep learning models within Natural Language Processing (NLP), shedding light on their transformative potential across diverse tasks such as Sentiment Analysis, Named Entity Recognition, Machine Translation, Question Answering, Text Classification, Generation, Speech Recognition, Summarization, and Language Modeling. The paper systematically introduces each task, delineates key architectures from Recurrent Neural Networks (RNNs) to Transformer-based models like BERT, and evaluates their performance, challenges, and computational demands. The adaptability of ensemble techniques is emphasized, highlighting their capacity to enhance various NLP applications. Challenges in implementation, including computational overhead, overfitting, and model interpretation complexities, are addressed alongside the trade-off between interpretability and performance. Serving as a concise yet invaluable guide, this review synthesizes insights into tasks, architectures, and challenges, offering a holistic perspective for researchers and practitioners aiming to advance language-driven applications through ensemble deep learning in NLP.
Large Language Models for Autonomous Driving: Real-World Experiments
Dec 14, 2023Autonomous driving systems are increasingly popular in today's technological landscape, where vehicles with partial automation have already been widely available on the market, and the full automation era with ``driverless'' capabilities is near the horizon. However, accurately understanding humans' commands, particularly for autonomous vehicles that have only passengers instead of drivers, and achieving a high level of personalization remain challenging tasks in the development of autonomous driving systems. In this paper, we introduce a Large Language Model (LLM)-based framework Talk-to-Drive (Talk2Drive) to process verbal commands from humans and make autonomous driving decisions with contextual information, satisfying their personalized preferences for safety, efficiency, and comfort. First, a speech recognition module is developed for Talk2Drive to interpret verbal inputs from humans to textual instructions, which are then sent to LLMs for reasoning. Then, appropriate commands for the Electrical Control Unit (ECU) are generated, achieving a 100\% success rate in executing codes. Real-world experiments show that our framework can substantially reduce the takeover rate for a diverse range of drivers by up to 90.1\%. To the best of our knowledge, Talk2Drive marks the first instance of employing an LLM-based system in a real-world autonomous driving environment.
Advanced accent/dialect identification and accentedness assessment with multi-embedding models and automatic speech recognition
Oct 17, 2023Accurately classifying accents and assessing accentedness in non-native speakers are both challenging tasks due to the complexity and diversity of accent and dialect variations. In this study, embeddings from advanced pre-trained language identification (LID) and speaker identification (SID) models are leveraged to improve the accuracy of accent classification and non-native accentedness assessment. Findings demonstrate that employing pre-trained LID and SID models effectively encodes accent/dialect information in speech. Furthermore, the LID and SID encoded accent information complement an end-to-end accent identification (AID) model trained from scratch. By incorporating all three embeddings, the proposed multi-embedding AID system achieves superior accuracy in accent identification. Next, we investigate leveraging automatic speech recognition (ASR) and accent identification models to explore accentedness estimation. The ASR model is an end-to-end connectionist temporal classification (CTC) model trained exclusively with en-US utterances. The ASR error rate and en-US output of the AID model are leveraged as objective accentedness scores. Evaluation results demonstrate a strong correlation between the scores estimated by the two models. Additionally, a robust correlation between the objective accentedness scores and subjective scores based on human perception is demonstrated, providing evidence for the reliability and validity of utilizing AID-based and ASR-based systems for accentedness assessment in non-native speech.
Directional Source Separation for Robust Speech Recognition on Smart Glasses
Sep 20, 2023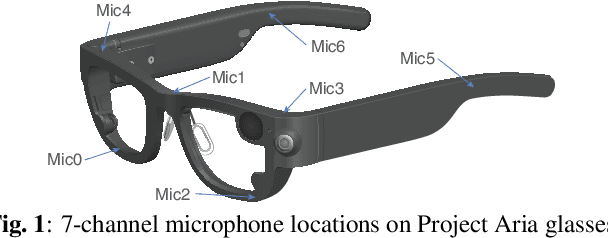
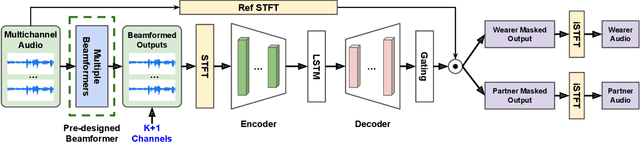
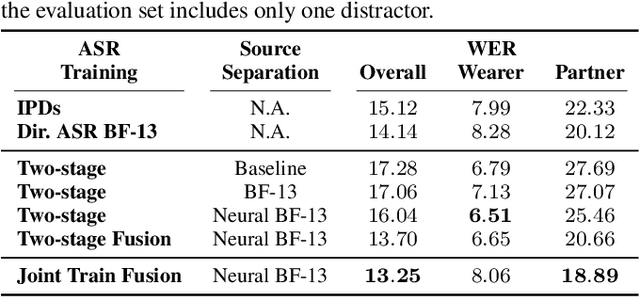
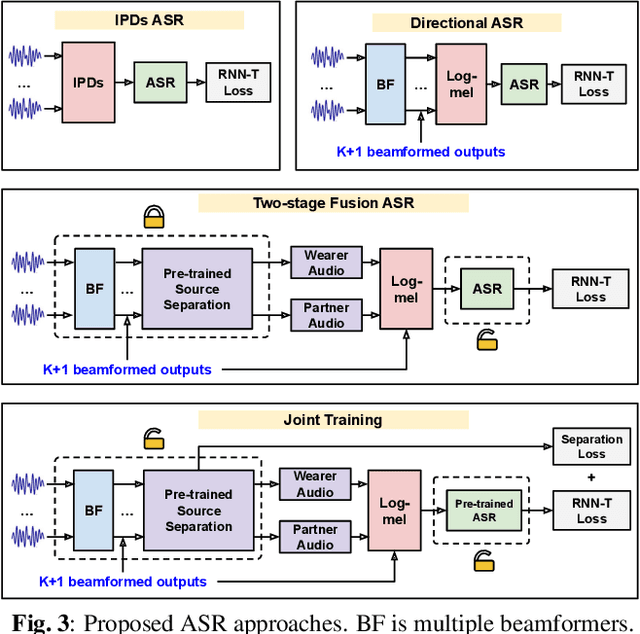
Modern smart glasses leverage advanced audio sensing and machine learning technologies to offer real-time transcribing and captioning services, considerably enriching human experiences in daily communications. However, such systems frequently encounter challenges related to environmental noises, resulting in degradation to speech recognition and speaker change detection. To improve voice quality, this work investigates directional source separation using the multi-microphone array. We first explore multiple beamformers to assist source separation modeling by strengthening the directional properties of speech signals. In addition to relying on predetermined beamformers, we investigate neural beamforming in multi-channel source separation, demonstrating that automatic learning directional characteristics effectively improves separation quality. We further compare the ASR performance leveraging separated outputs to noisy inputs. Our results show that directional source separation benefits ASR for the wearer but not for the conversation partner. Lastly, we perform the joint training of the directional source separation and ASR model, achieving the best overall ASR performance.
Collaborative Learning with Artificial Intelligence Speakers (CLAIS): Pre-Service Elementary Science Teachers' Responses to the Prototype
Dec 20, 2023This research aims to demonstrate that AI can function not only as a tool for learning, but also as an intelligent agent with which humans can engage in collaborative learning (CL) to change epistemic practices in science classrooms. We adopted a design and development research approach, following the Analysis, Design, Development, Implementation and Evaluation (ADDIE) model, to prototype a tangible instructional system called Collaborative Learning with AI Speakers (CLAIS). The CLAIS system is designed to have 3-4 human learners join an AI speaker to form a small group, where humans and AI are considered as peers participating in the Jigsaw learning process. The development was carried out using the NUGU AI speaker platform. The CLAIS system was successfully implemented in a Science Education course session with 15 pre-service elementary science teachers. The participants evaluated the CLAIS system through mixed methods surveys as teachers, learners, peers, and users. Quantitative data showed that the participants' Intelligent-Technological, Pedagogical, And Content Knowledge was significantly increased after the CLAIS session, the perception of the CLAIS learning experience was positive, the peer assessment on AI speakers and human peers was different, and the user experience was ambivalent. Qualitative data showed that the participants anticipated future changes in the epistemic process in science classrooms, while acknowledging technical issues such as speech recognition performance and response latency. This study highlights the potential of Human-AI Collaboration for knowledge co-construction in authentic classroom settings and exemplify how AI could shape the future landscape of epistemic practices in the classroom.
LIP-RTVE: An Audiovisual Database for Continuous Spanish in the Wild
Nov 21, 2023Speech is considered as a multi-modal process where hearing and vision are two fundamentals pillars. In fact, several studies have demonstrated that the robustness of Automatic Speech Recognition systems can be improved when audio and visual cues are combined to represent the nature of speech. In addition, Visual Speech Recognition, an open research problem whose purpose is to interpret speech by reading the lips of the speaker, has been a focus of interest in the last decades. Nevertheless, in order to estimate these systems in the currently Deep Learning era, large-scale databases are required. On the other hand, while most of these databases are dedicated to English, other languages lack sufficient resources. Thus, this paper presents a semi-automatically annotated audiovisual database to deal with unconstrained natural Spanish, providing 13 hours of data extracted from Spanish television. Furthermore, baseline results for both speaker-dependent and speaker-independent scenarios are reported using Hidden Markov Models, a traditional paradigm that has been widely used in the field of Speech Technologies.
CPPF: A contextual and post-processing-free model for automatic speech recognition
Sep 21, 2023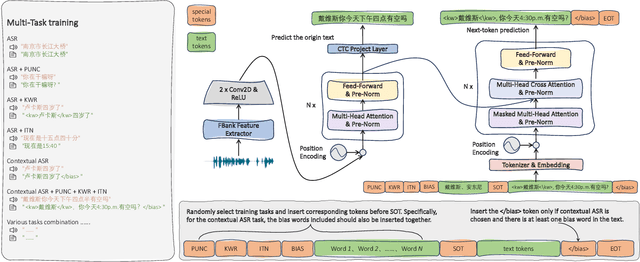
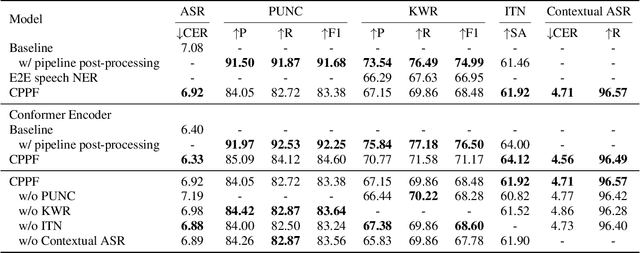

ASR systems have become increasingly widespread in recent years. However, their textual outputs often require post-processing tasks before they can be practically utilized. To address this issue, we draw inspiration from the multifaceted capabilities of LLMs and Whisper, and focus on integrating multiple ASR text processing tasks related to speech recognition into the ASR model. This integration not only shortens the multi-stage pipeline, but also prevents the propagation of cascading errors, resulting in direct generation of post-processed text. In this study, we focus on ASR-related processing tasks, including Contextual ASR and multiple ASR post processing tasks. To achieve this objective, we introduce the CPPF model, which offers a versatile and highly effective alternative to ASR processing. CPPF seamlessly integrates these tasks without any significant loss in recognition performance.
Partial Rewriting for Multi-Stage ASR
Dec 08, 2023For many streaming automatic speech recognition tasks, it is important to provide timely intermediate streaming results, while refining a high quality final result. This can be done using a multi-stage architecture, where a small left-context only model creates streaming results and a larger left- and right-context model produces a final result at the end. While this significantly improves the quality of the final results without compromising the streaming emission latency of the system, streaming results do not benefit from the quality improvements. Here, we propose using a text manipulation algorithm that merges the streaming outputs of both models. We improve the quality of streaming results by around 10%, without altering the final results. Our approach introduces no additional latency and reduces flickering. It is also lightweight, does not require retraining the model, and it can be applied to a wide variety of multi-stage architectures.
A Multi-Task, Multi-Modal Approach for Predicting Categorical and Dimensional Emotions
Dec 31, 2023Speech emotion recognition (SER) has received a great deal of attention in recent years in the context of spontaneous conversations. While there have been notable results on datasets like the well known corpus of naturalistic dyadic conversations, IEMOCAP, for both the case of categorical and dimensional emotions, there are few papers which try to predict both paradigms at the same time. Therefore, in this work, we aim to highlight the performance contribution of multi-task learning by proposing a multi-task, multi-modal system that predicts categorical and dimensional emotions. The results emphasise the importance of cross-regularisation between the two types of emotions. Our approach consists of a multi-task, multi-modal architecture that uses parallel feature refinement through self-attention for the feature of each modality. In order to fuse the features, our model introduces a set of learnable bridge tokens that merge the acoustic and linguistic features with the help of cross-attention. Our experiments for categorical emotions on 10-fold validation yield results comparable to the current state-of-the-art. In our configuration, our multi-task approach provides better results compared to learning each paradigm separately. On top of that, our best performing model achieves a high result for valence compared to the previous multi-task experiments.