 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
StableEmit: Selection Probability Discount for Reducing Emission Latency of Streaming Monotonic Attention ASR
Jul 01, 2021
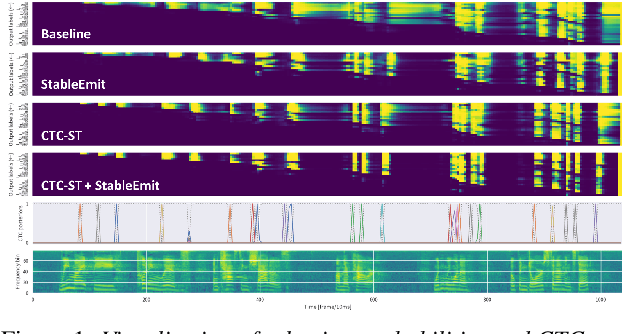

While attention-based encoder-decoder (AED) models have been successfully extended to the online variants for streaming automatic speech recognition (ASR), such as monotonic chunkwise attention (MoChA), the models still have a large label emission latency because of the unconstrained end-to-end training objective. Previous works tackled this problem by leveraging alignment information to control the timing to emit tokens during training. In this work, we propose a simple alignment-free regularization method, StableEmit, to encourage MoChA to emit tokens earlier. StableEmit discounts the selection probabilities in hard monotonic attention for token boundary detection by a constant factor and regularizes them to recover the total attention mass during training. As a result, the scale of the selection probabilities is increased, and the values can reach a threshold for token emission earlier, leading to a reduction of emission latency and deletion errors. Moreover, StableEmit can be combined with methods that constraint alignments to further improve the accuracy and latency. Experimental evaluations with LSTM and Conformer encoders demonstrate that StableEmit significantly reduces the recognition errors and the emission latency simultaneously. We also show that the use of alignment information is complementary in both metrics.
A Discussion On the Validity of Manifold Learning
Jun 03, 2021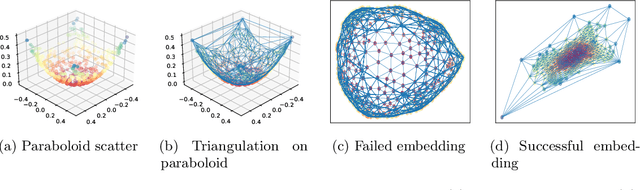
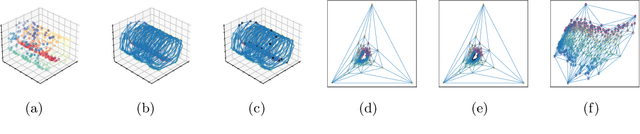
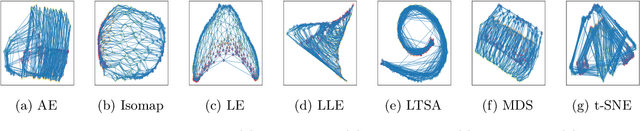
Dimensionality reduction (DR) and manifold learning (ManL) have been applied extensively in many machine learning tasks, including signal processing, speech recognition, and neuroinformatics. However, the understanding of whether DR and ManL models can generate valid learning results remains unclear. In this work, we investigate the validity of learning results of some widely used DR and ManL methods through the chart mapping function of a manifold. We identify a fundamental problem of these methods: the mapping functions induced by these methods violate the basic settings of manifolds, and hence they are not learning manifold in the mathematical sense. To address this problem, we provide a provably correct algorithm called fixed points Laplacian mapping (FPLM), that has the geometric guarantee to find a valid manifold representation (up to a homeomorphism). Combining one additional condition(orientation preserving), we discuss a sufficient condition for an algorithm to be bijective for any d-simplex decomposition result on a d-manifold. However, constructing such a mapping function and its computational method satisfying these conditions is still an open problem in mathematics.
Investigation of End-To-End Speaker-Attributed ASR for Continuous Multi-Talker Recordings
Aug 11, 2020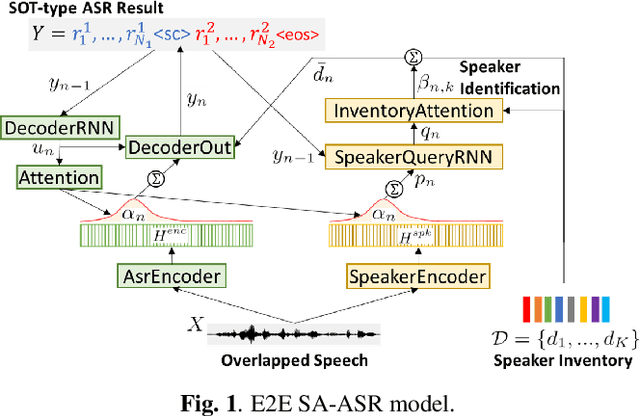
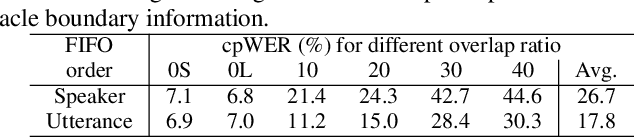
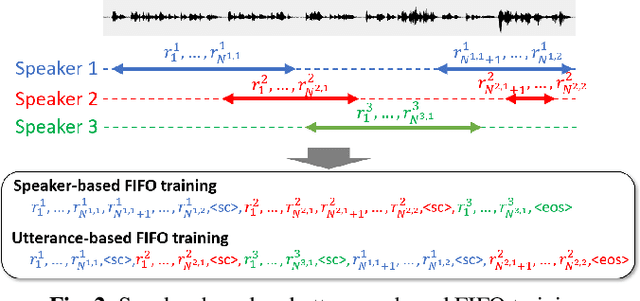
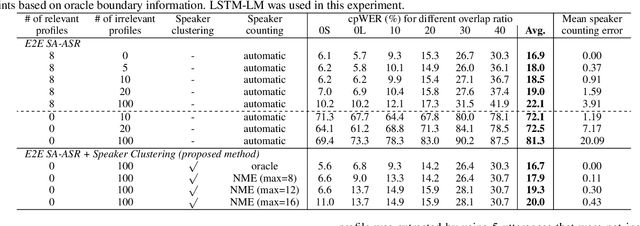
Recently, an end-to-end (E2E) speaker-attributed automatic speech recognition (SA-ASR) model was proposed as a joint model of speaker counting, speech recognition and speaker identification for monaural overlapped speech. It showed promising results for simulated speech mixtures consisting of various numbers of speakers. However, the model required prior knowledge of speaker profiles to perform speaker identification, which significantly limited the application of the model. In this paper, we extend the prior work by addressing the case where no speaker profile is available. Specifically, we perform speaker counting and clustering by using the internal speaker representations of the E2E SA-ASR model to diarize the utterances of the speakers whose profiles are missing from the speaker inventory. We also propose a simple modification to the reference labels of the E2E SA-ASR training which helps handle continuous multi-talker recordings well. We conduct a comprehensive investigation of the original E2E SA-ASR and the proposed method on the monaural LibriCSS dataset. Compared to the original E2E SA-ASR with relevant speaker profiles, the proposed method achieves a close performance without any prior speaker knowledge. We also show that the source-target attention in the E2E SA-ASR model provides information about the start and end times of the hypotheses.
Characterizing Types of Convolution in Deep Convolutional Recurrent Neural Networks for Robust Speech Emotion Recognition
Jan 13, 2018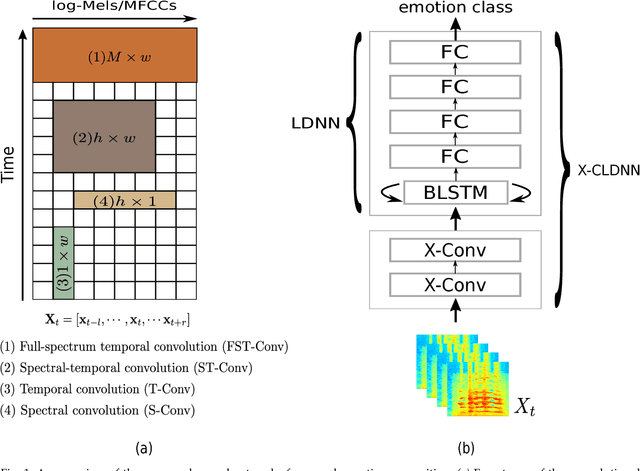

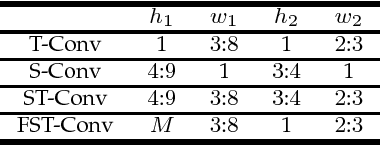
Deep convolutional neural networks are being actively investigated in a wide range of speech and audio processing applications including speech recognition, audio event detection and computational paralinguistics, owing to their ability to reduce factors of variations, for learning from speech. However, studies have suggested to favor a certain type of convolutional operations when building a deep convolutional neural network for speech applications although there has been promising results using different types of convolutional operations. In this work, we study four types of convolutional operations on different input features for speech emotion recognition under noisy and clean conditions in order to derive a comprehensive understanding. Since affective behavioral information has been shown to reflect temporally varying of mental state and convolutional operation are applied locally in time, all deep neural networks share a deep recurrent sub-network architecture for further temporal modeling. We present detailed quantitative module-wise performance analysis to gain insights into information flows within the proposed architectures. In particular, we demonstrate the interplay of affective information and the other irrelevant information during the progression from one module to another. Finally we show that all of our deep neural networks provide state-of-the-art performance on the eNTERFACE'05 corpus.
Do You Listen with One or Two Microphones? A Unified ASR Model for Single and Multi-Channel Audio
Jun 28, 2021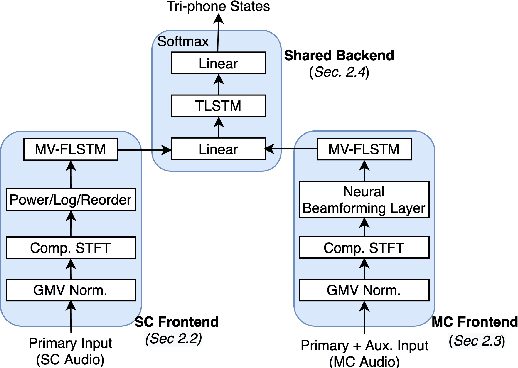
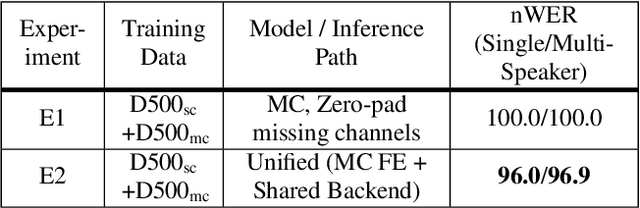
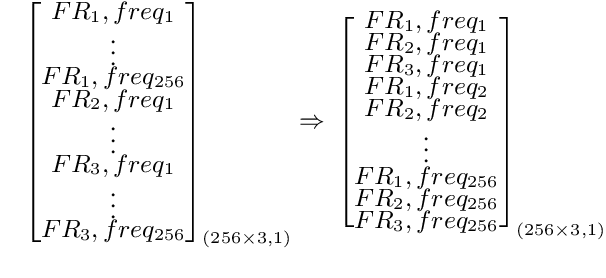
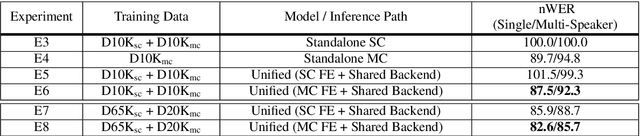
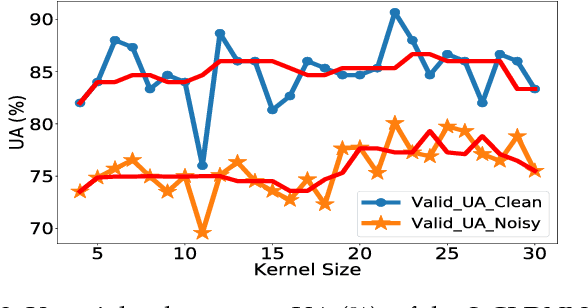
Automatic speech recognition (ASR) models are typically designed to operate on a single input data type, e.g. a single or multi-channel audio streamed from a device. This design decision assumes the primary input data source does not change and if an additional (auxiliary) data source is occasionally available, it cannot be used. An ASR model that operates on both primary and auxiliary data can achieve better accuracy compared to a primary-only solution; and a model that can serve both primary-only (PO) and primary-plus-auxiliary (PPA) modes is highly desirable. In this work, we propose a unified ASR model that can serve both modes. We demonstrate its efficacy in a realistic scenario where a set of devices typically stream a single primary audio channel, and two additional auxiliary channels only when upload bandwidth allows it. The architecture enables a unique methodology that uses both types of input audio during training time. Our proposed approach achieves up to 12.5% relative word-error-rate reduction (WERR) compared to a PO baseline, and up to 16.0% relative WERR in low-SNR conditions. The unique training methodology achieves up to 2.5% relative WERR compared to a PPA baseline.
TLT-school: a Corpus of Non Native Children Speech
Jan 22, 2020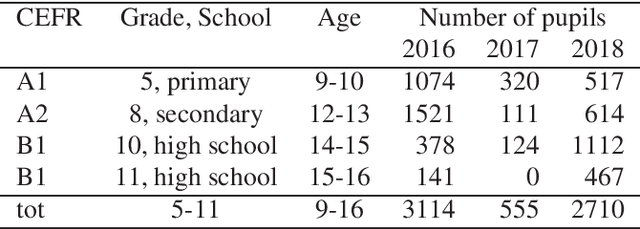
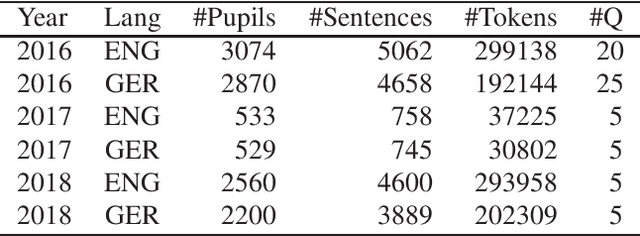
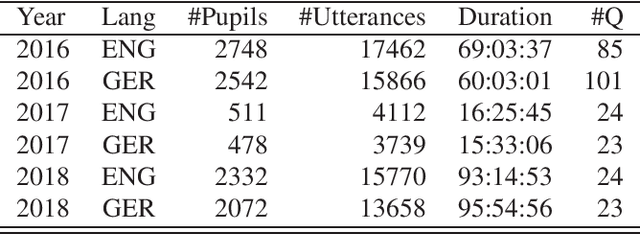
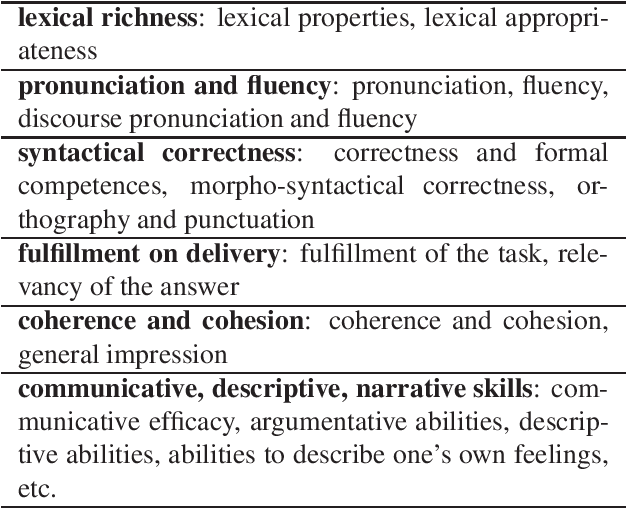
This paper describes "TLT-school" a corpus of speech utterances collected in schools of northern Italy for assessing the performance of students learning both English and German. The corpus was recorded in the years 2017 and 2018 from students aged between nine and sixteen years, attending primary, middle and high school. All utterances have been scored, in terms of some predefined proficiency indicators, by human experts. In addition, most of utterances recorded in 2017 have been manually transcribed carefully. Guidelines and procedures used for manual transcriptions of utterances will be described in detail, as well as results achieved by means of an automatic speech recognition system developed by us. Part of the corpus is going to be freely distributed to scientific community particularly interested both in non-native speech recognition and automatic assessment of second language proficiency.
Time-Domain Speech Extraction with Spatial Information and Multi Speaker Conditioning Mechanism
Feb 07, 2021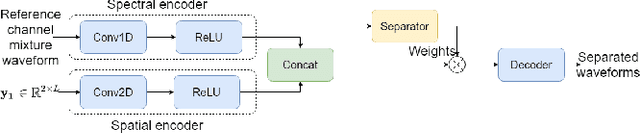
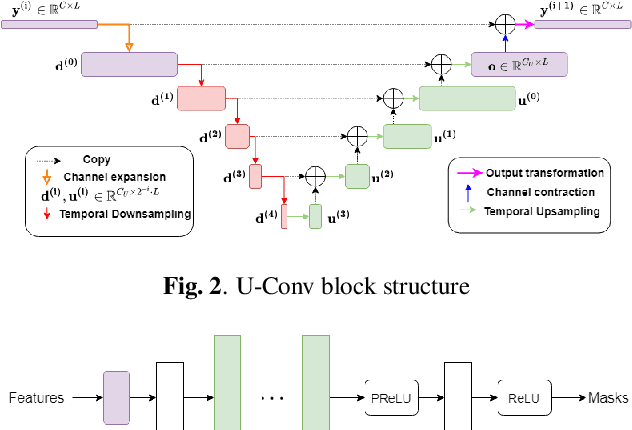
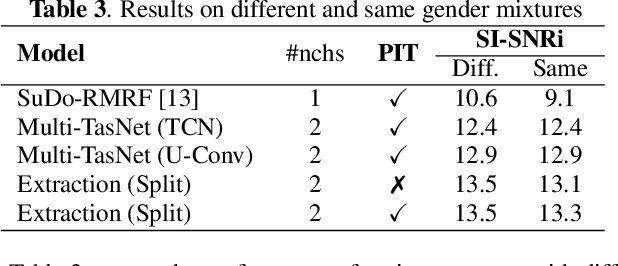

In this paper, we present a novel multi-channel speech extraction system to simultaneously extract multiple clean individual sources from a mixture in noisy and reverberant environments. The proposed method is built on an improved multi-channel time-domain speech separation network which employs speaker embeddings to identify and extract multiple targets without label permutation ambiguity. To efficiently inform the speaker information to the extraction model, we propose a new speaker conditioning mechanism by designing an additional speaker branch for receiving external speaker embeddings. Experiments on 2-channel WHAMR! data show that the proposed system improves by 9% relative the source separation performance over a strong multi-channel baseline, and it increases the speech recognition accuracy by more than 16% relative over the same baseline.
Context-Aware Task Handling in Resource-Constrained Robots with Virtualization
Apr 09, 2021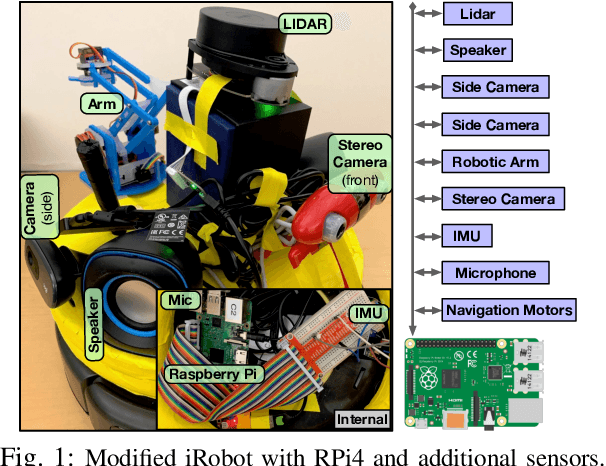
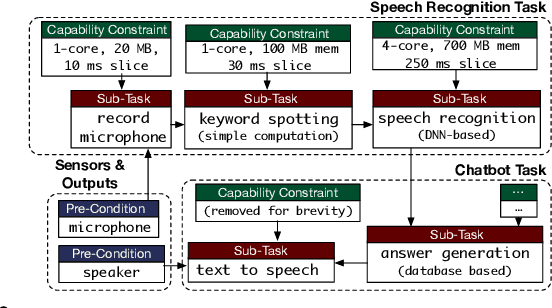
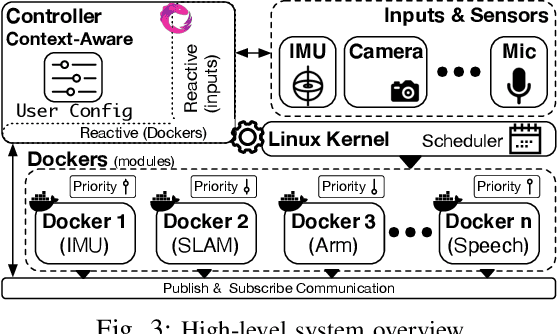
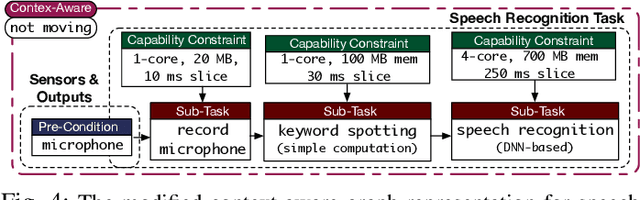
Intelligent mobile robots are critical in several scenarios. However, as their computational resources are limited, mobile robots struggle to handle several tasks concurrently and yet guaranteeing real-timeliness. To address this challenge and improve the real-timeliness of critical tasks under resource constraints, we propose a fast context-aware task handling technique. To effectively handling tasks in real-time, our proposed context-aware technique comprises of three main ingredients: (i) a dynamic time-sharing mechanism, coupled with (ii) an event-driven task scheduling using reactive programming paradigm to mindfully use the limited resources; and, (iii) a lightweight virtualized execution to easily integrate functionalities and their dependencies. We showcase our technique on a Raspberry-Pi-based robot with a variety of tasks such as Simultaneous localization and mapping (SLAM), sign detection, and speech recognition with a 42% speedup in total execution time compared to the common Linux scheduler.
Multimodal Speech Emotion Recognition and Ambiguity Resolution
Apr 12, 2019
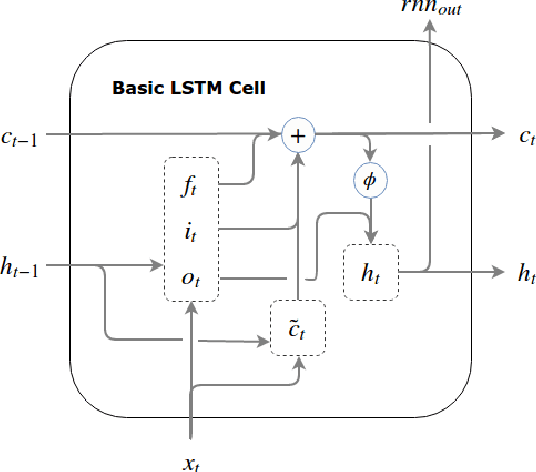
Identifying emotion from speech is a non-trivial task pertaining to the ambiguous definition of emotion itself. In this work, we adopt a feature-engineering based approach to tackle the task of speech emotion recognition. Formalizing our problem as a multi-class classification problem, we compare the performance of two categories of models. For both, we extract eight hand-crafted features from the audio signal. In the first approach, the extracted features are used to train six traditional machine learning classifiers, whereas the second approach is based on deep learning wherein a baseline feed-forward neural network and an LSTM-based classifier are trained over the same features. In order to resolve ambiguity in communication, we also include features from the text domain. We report accuracy, f-score, precision, and recall for the different experiment settings we evaluated our models in. Overall, we show that lighter machine learning based models trained over a few hand-crafted features are able to achieve performance comparable to the current deep learning based state-of-the-art method for emotion recognition.
MIMO Self-attentive RNN Beamformer for Multi-speaker Speech Separation
Apr 17, 2021
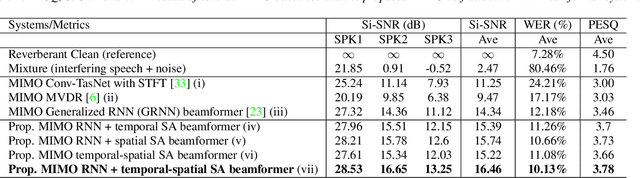

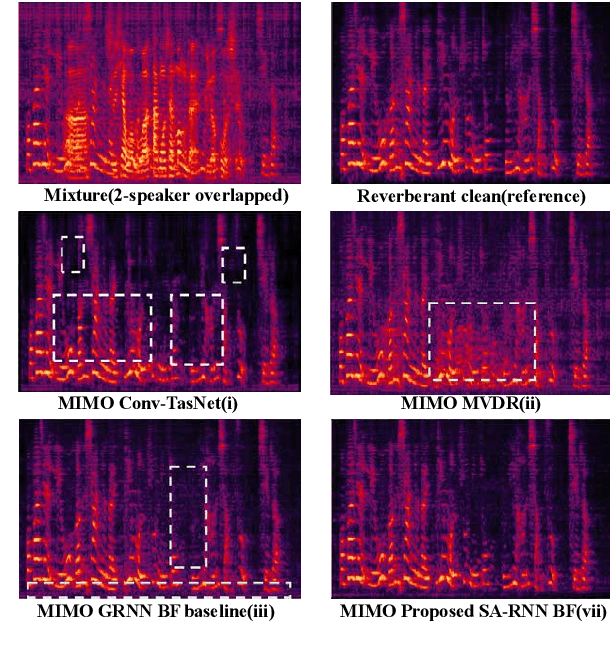
Recently, our proposed recurrent neural network (RNN) based all deep learning minimum variance distortionless response (ADL-MVDR) beamformer method yielded superior performance over the conventional MVDR by replacing the matrix inversion and eigenvalue decomposition with two RNNs.In this work, we present a self-attentive RNN beamformer to further improve our previous RNN-based beamformer by leveraging on the powerful modeling capability of self-attention. Temporal-spatial self-attention module is proposed to better learn the beamforming weights from the speech and noise spatial covariance matrices. The temporal self-attention module could help RNN to learn global statistics of covariance matrices. The spatial self-attention module is designed to attend on the cross-channel correlation in the covariance matrices. Furthermore, a multi-channel input with multi-speaker directional features and multi-speaker speech separation outputs (MIMO) model is developed to improve the inference efficiency.The evaluations demonstrate that our proposed MIMO self-attentive RNN beamformer improves both the automatic speech recognition (ASR) accuracy and the perceptual estimation of speech quality (PESQ) against prior arts.