 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
StableEmit: Selection Probability Discount for Reducing Emission Latency of Streaming Monotonic Attention ASR
Jul 15, 2021
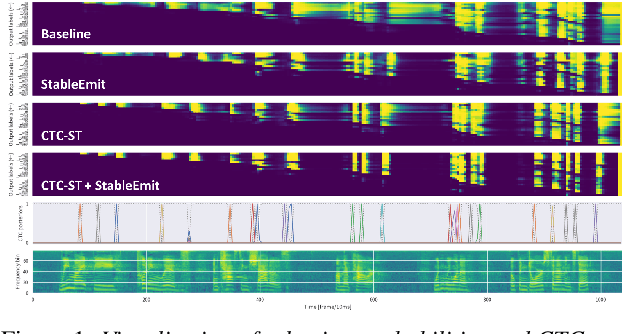

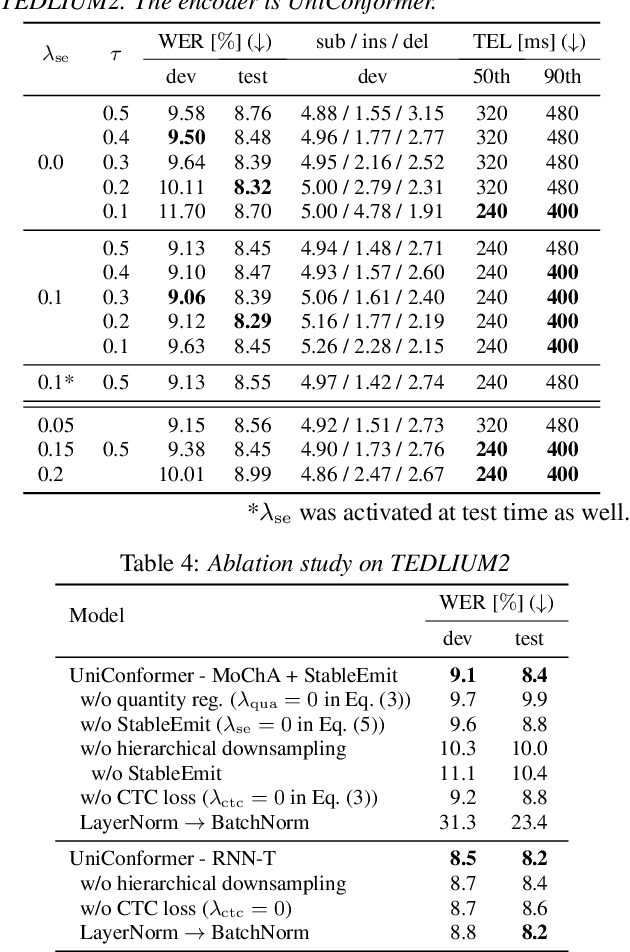
While attention-based encoder-decoder (AED) models have been successfully extended to the online variants for streaming automatic speech recognition (ASR), such as monotonic chunkwise attention (MoChA), the models still have a large label emission latency because of the unconstrained end-to-end training objective. Previous works tackled this problem by leveraging alignment information to control the timing to emit tokens during training. In this work, we propose a simple alignment-free regularization method, StableEmit, to encourage MoChA to emit tokens earlier. StableEmit discounts the selection probabilities in hard monotonic attention for token boundary detection by a constant factor and regularizes them to recover the total attention mass during training. As a result, the scale of the selection probabilities is increased, and the values can reach a threshold for token emission earlier, leading to a reduction of emission latency and deletion errors. Moreover, StableEmit can be combined with methods that constraint alignments to further improve the accuracy and latency. Experimental evaluations with LSTM and Conformer encoders demonstrate that StableEmit significantly reduces the recognition errors and the emission latency simultaneously. We also show that the use of alignment information is complementary in both metrics.
Game of Gradients: Mitigating Irrelevant Clients in Federated Learning
Oct 23, 2021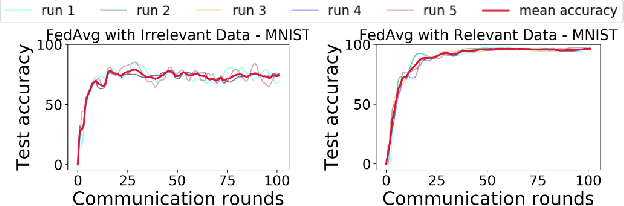
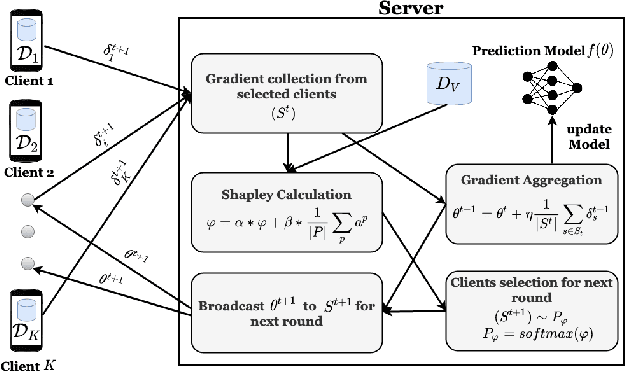
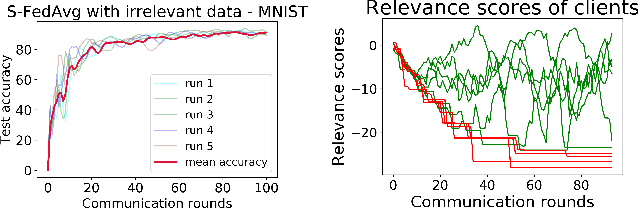
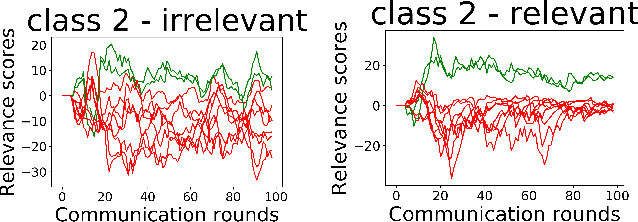
The paradigm of Federated learning (FL) deals with multiple clients participating in collaborative training of a machine learning model under the orchestration of a central server. In this setup, each client's data is private to itself and is not transferable to other clients or the server. Though FL paradigm has received significant interest recently from the research community, the problem of selecting the relevant clients w.r.t. the central server's learning objective is under-explored. We refer to these problems as Federated Relevant Client Selection (FRCS). Because the server doesn't have explicit control over the nature of data possessed by each client, the problem of selecting relevant clients is significantly complex in FL settings. In this paper, we resolve important and related FRCS problems viz., selecting clients with relevant data, detecting clients that possess data relevant to a particular target label, and rectifying corrupted data samples of individual clients. We follow a principled approach to address the above FRCS problems and develop a new federated learning method using the Shapley value concept from cooperative game theory. Towards this end, we propose a cooperative game involving the gradients shared by the clients. Using this game, we compute Shapley values of clients and then present Shapley value based Federated Averaging (S-FedAvg) algorithm that empowers the server to select relevant clients with high probability. S-FedAvg turns out to be critical in designing specific algorithms to address the FRCS problems. We finally conduct a thorough empirical analysis on image classification and speech recognition tasks to show the superior performance of S-FedAvg than the baselines in the context of supervised federated learning settings.
ASR Adaptation for E-commerce Chatbots using Cross-Utterance Context and Multi-Task Language Modeling
Jun 15, 2021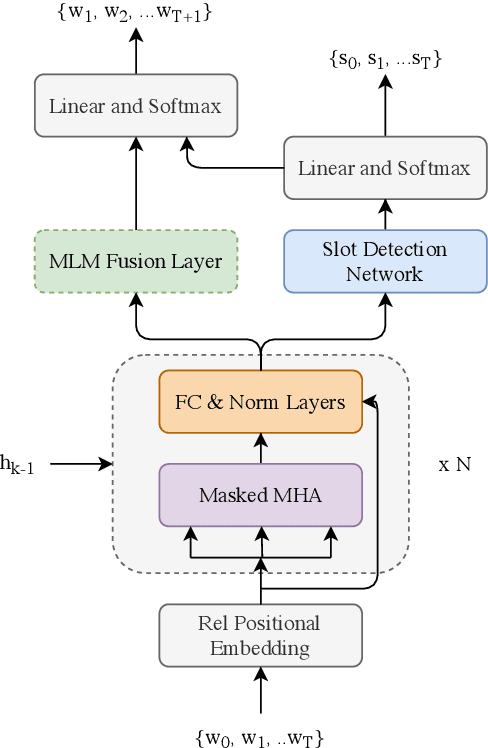
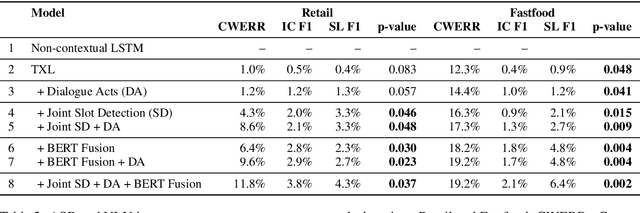
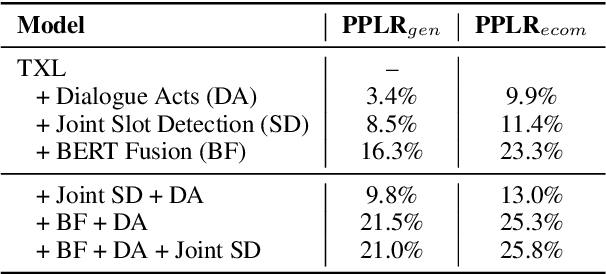
Automatic Speech Recognition (ASR) robustness toward slot entities are critical in e-commerce voice assistants that involve monetary transactions and purchases. Along with effective domain adaptation, it is intuitive that cross utterance contextual cues play an important role in disambiguating domain specific content words from speech. In this paper, we investigate various techniques to improve contextualization, content word robustness and domain adaptation of a Transformer-XL neural language model (NLM) to rescore ASR N-best hypotheses. To improve contextualization, we utilize turn level dialogue acts along with cross utterance context carry over. Additionally, to adapt our domain-general NLM towards e-commerce on-the-fly, we use embeddings derived from a finetuned masked LM on in-domain data. Finally, to improve robustness towards in-domain content words, we propose a multi-task model that can jointly perform content word detection and language modeling tasks. Compared to a non-contextual LSTM LM baseline, our best performing NLM rescorer results in a content WER reduction of 19.2% on e-commerce audio test set and a slot labeling F1 improvement of 6.4%.
A Study into Pre-training Strategies for Spoken Language Understanding on Dysarthric Speech
Jun 15, 2021
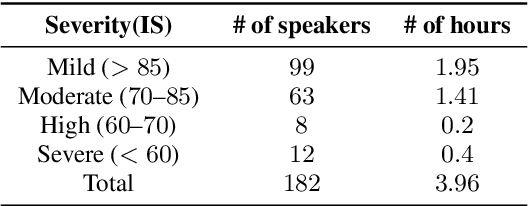

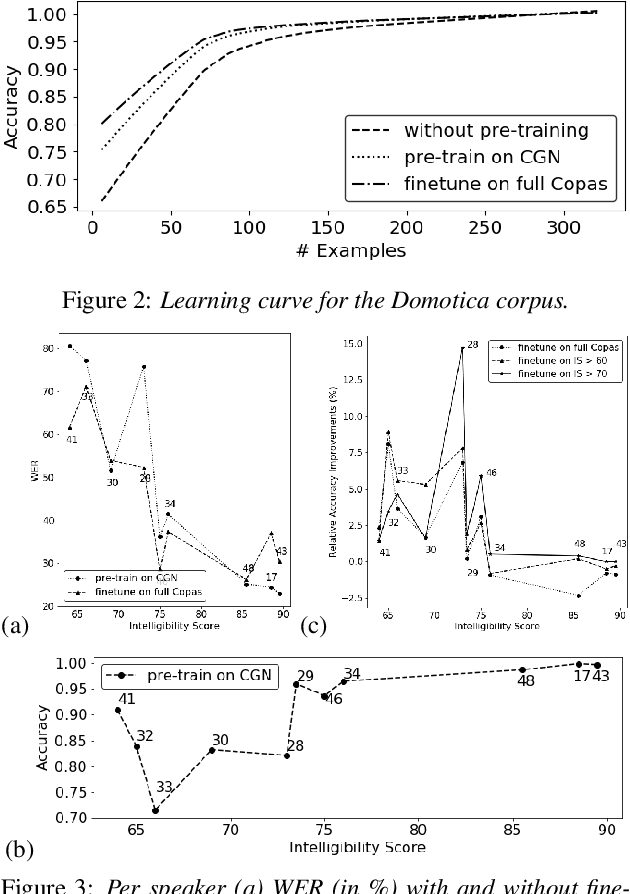
End-to-end (E2E) spoken language understanding (SLU) systems avoid an intermediate textual representation by mapping speech directly into intents with slot values. This approach requires considerable domain-specific training data. In low-resource scenarios this is a major concern, e.g., in the present study dealing with SLU for dysarthric speech. Pretraining part of the SLU model for automatic speech recognition targets helps but no research has shown to which extent SLU on dysarthric speech benefits from knowledge transferred from other dysarthric speech tasks. This paper investigates the efficiency of pre-training strategies for SLU tasks on dysarthric speech. The designed SLU system consists of a TDNN acoustic model for feature encoding and a capsule network for intent and slot decoding. The acoustic model is pre-trained in two stages: initialization with a corpus of normal speech and finetuning on a mixture of dysarthric and normal speech. By introducing the intelligibility score as a metric of the impairment severity, this paper quantitatively analyzes the relation between generalization and pathology severity for dysarthric speech.
Streaming Transformer for Hardware Efficient Voice Trigger Detection and False Trigger Mitigation
May 14, 2021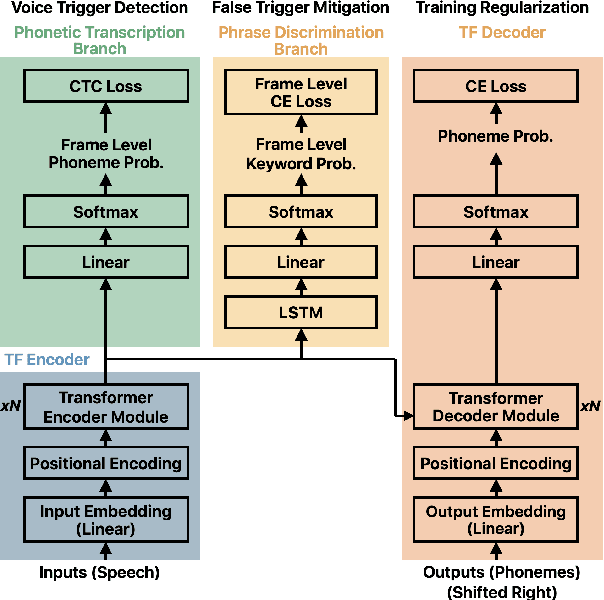
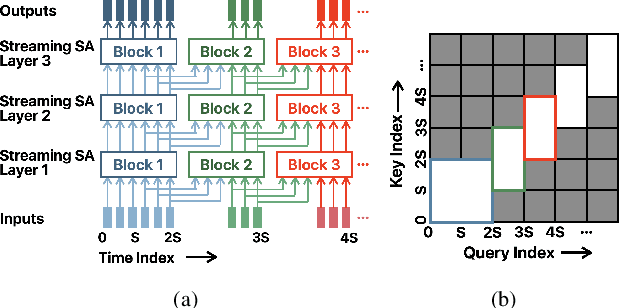

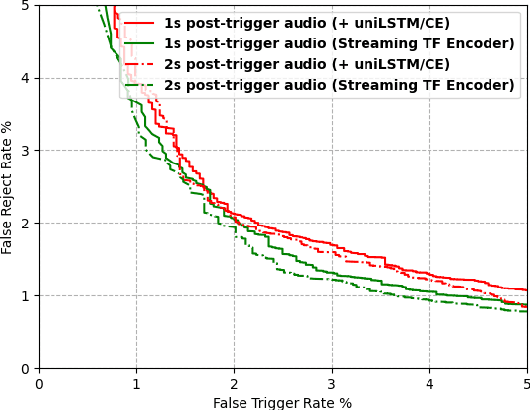
We present a unified and hardware efficient architecture for two stage voice trigger detection (VTD) and false trigger mitigation (FTM) tasks. Two stage VTD systems of voice assistants can get falsely activated to audio segments acoustically similar to the trigger phrase of interest. FTM systems cancel such activations by using post trigger audio context. Traditional FTM systems rely on automatic speech recognition lattices which are computationally expensive to obtain on device. We propose a streaming transformer (TF) encoder architecture, which progressively processes incoming audio chunks and maintains audio context to perform both VTD and FTM tasks using only acoustic features. The proposed joint model yields an average 18% relative reduction in false reject rate (FRR) for the VTD task at a given false alarm rate. Moreover, our model suppresses 95% of the false triggers with an additional one second of post-trigger audio. Finally, on-device measurements show 32% reduction in runtime memory and 56% reduction in inference time compared to non-streaming version of the model.
Data augmentation using prosody and false starts to recognize non-native children's speech
Aug 29, 2020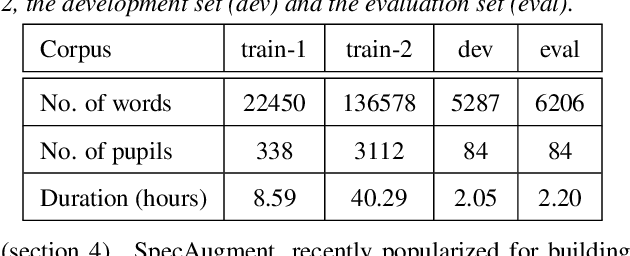
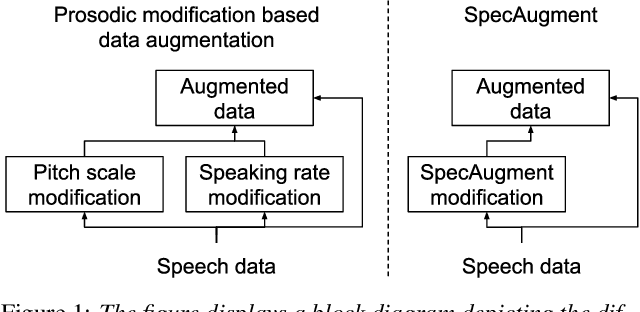
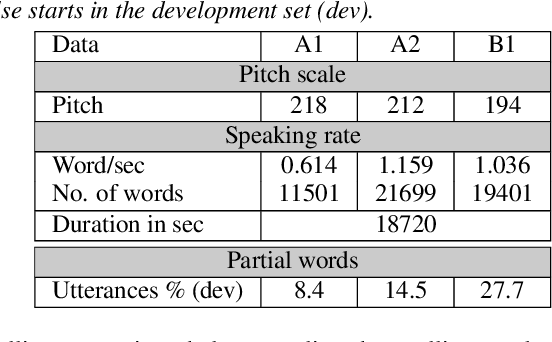
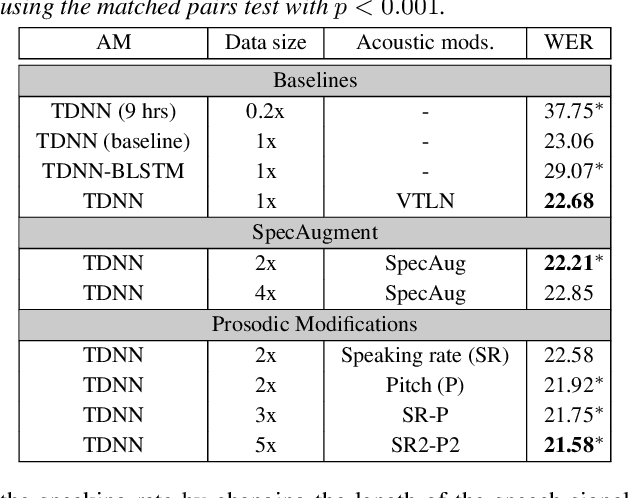
This paper describes AaltoASR's speech recognition system for the INTERSPEECH 2020 shared task on Automatic Speech Recognition (ASR) for non-native children's speech. The task is to recognize non-native speech from children of various age groups given a limited amount of speech. Moreover, the speech being spontaneous has false starts transcribed as partial words, which in the test transcriptions leads to unseen partial words. To cope with these two challenges, we investigate a data augmentation-based approach. Firstly, we apply the prosody-based data augmentation to supplement the audio data. Secondly, we simulate false starts by introducing partial-word noise in the language modeling corpora creating new words. Acoustic models trained on prosody-based augmented data outperform the models using the baseline recipe or the SpecAugment-based augmentation. The partial-word noise also helps to improve the baseline language model. Our ASR system, a combination of these schemes, is placed third in the evaluation period and achieves the word error rate of 18.71%. Post-evaluation period, we observe that increasing the amounts of prosody-based augmented data leads to better performance. Furthermore, removing low-confidence-score words from hypotheses can lead to further gains. These two improvements lower the ASR error rate to 17.99%.
Low-activity supervised convolutional spiking neural networks applied to speech commands recognition
Nov 13, 2020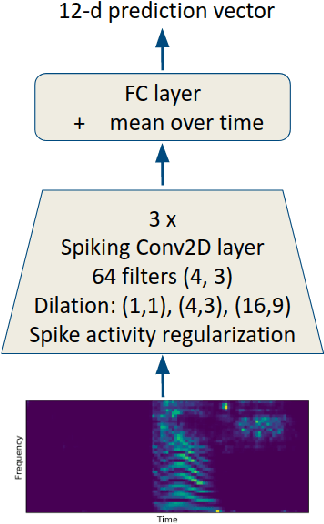
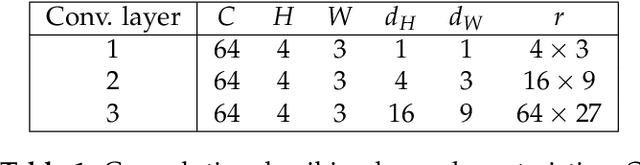

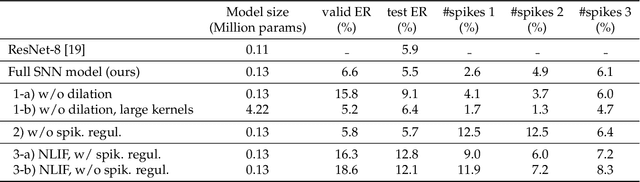
Deep Neural Networks (DNNs) are the current state-of-the-art models in many speech related tasks. There is a growing interest, though, for more biologically realistic, hardware friendly and energy efficient models, named Spiking Neural Networks (SNNs). Recently, it has been shown that SNNs can be trained efficiently, in a supervised manner, using backpropagation with a surrogate gradient trick. In this work, we report speech command (SC) recognition experiments using supervised SNNs. We explored the Leaky-Integrate-Fire (LIF) neuron model for this task, and show that a model comprised of stacked dilated convolution spiking layers can reach an error rate very close to standard DNNs on the Google SC v1 dataset: 5.5%, while keeping a very sparse spiking activity, below 5%, thank to a new regularization term. We also show that modeling the leakage of the neuron membrane potential is useful, since the LIF model outperformed its non-leaky model counterpart significantly.
Part-of-Speech Tagging of Odia Language Using statistical and Deep Learning-Based Approaches
Jul 07, 2022



Automatic Part-of-speech (POS) tagging is a preprocessing step of many natural language processing (NLP) tasks such as name entity recognition (NER), speech processing, information extraction, word sense disambiguation, and machine translation. It has already gained a promising result in English and European languages, but in Indian languages, particularly in Odia language, it is not yet well explored because of the lack of supporting tools, resources, and morphological richness of language. Unfortunately, we were unable to locate an open source POS tagger for Odia, and only a handful of attempts have been made to develop POS taggers for Odia language. The main contribution of this research work is to present a conditional random field (CRF) and deep learning-based approaches (CNN and Bidirectional Long Short-Term Memory) to develop Odia part-of-speech tagger. We used a publicly accessible corpus and the dataset is annotated with the Bureau of Indian Standards (BIS) tagset. However, most of the languages around the globe have used the dataset annotated with Universal Dependencies (UD) tagset. Hence, to maintain uniformity Odia dataset should use the same tagset. So we have constructed a simple mapping from BIS tagset to UD tagset. We experimented with various feature set inputs to the CRF model, observed the impact of constructed feature set. The deep learning-based model includes Bi-LSTM network, CNN network, CRF layer, character sequence information, and pre-trained word vector. Character sequence information was extracted by using convolutional neural network (CNN) and Bi-LSTM network. Six different combinations of neural sequence labelling models are implemented, and their performance measures are investigated. It has been observed that Bi-LSTM model with character sequence feature and pre-trained word vector achieved a significant state-of-the-art result.
Quantization of Deep Neural Networks for Accurate EdgeComputing
Apr 25, 2021


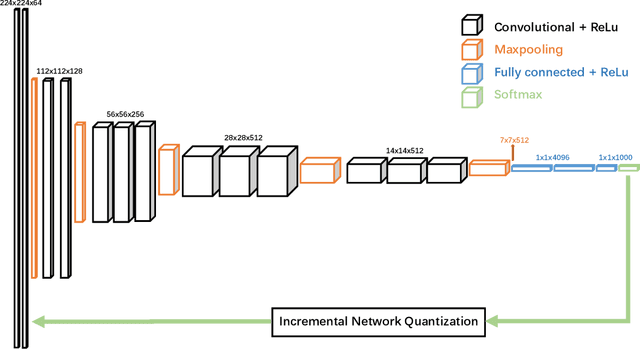
Deep neural networks (DNNs) have demonstrated their great potential in recent years, exceeding the per-formance of human experts in a wide range of applications. Due to their large sizes, however, compressiontechniques such as weight quantization and pruning are usually applied before they can be accommodated onthe edge. It is generally believed that quantization leads to performance degradation, and plenty of existingworks have explored quantization strategies aiming at minimum accuracy loss. In this paper, we argue thatquantization, which essentially imposes regularization on weight representations, can sometimes help toimprove accuracy. We conduct comprehensive experiments on three widely used applications: fully con-nected network (FCN) for biomedical image segmentation, convolutional neural network (CNN) for imageclassification on ImageNet, and recurrent neural network (RNN) for automatic speech recognition, and experi-mental results show that quantization can improve the accuracy by 1%, 1.95%, 4.23% on the three applicationsrespectively with 3.5x-6.4x memory reduction.
Improving Distinction between ASR Errors and Speech Disfluencies with Feature Space Interpolation
Aug 04, 2021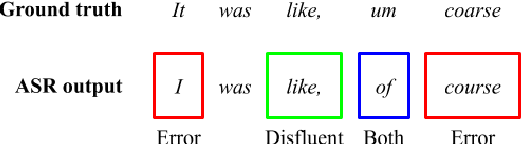
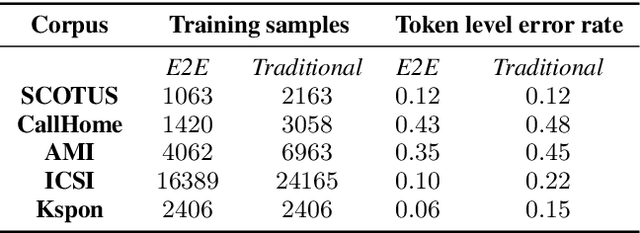
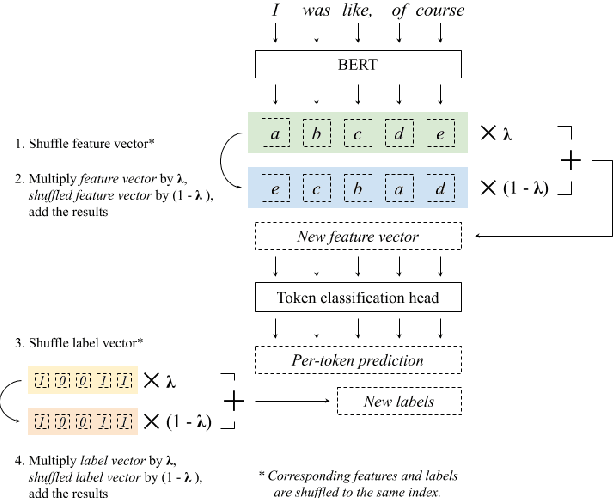
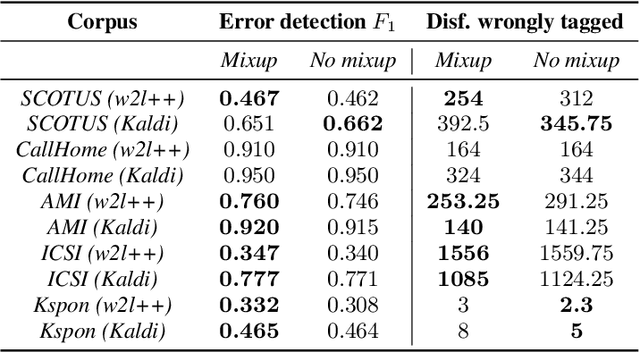
Fine-tuning pretrained language models (LMs) is a popular approach to automatic speech recognition (ASR) error detection during post-processing. While error detection systems often take advantage of statistical language archetypes captured by LMs, at times the pretrained knowledge can hinder error detection performance. For instance, presence of speech disfluencies might confuse the post-processing system into tagging disfluent but accurate transcriptions as ASR errors. Such confusion occurs because both error detection and disfluency detection tasks attempt to identify tokens at statistically unlikely positions. This paper proposes a scheme to improve existing LM-based ASR error detection systems, both in terms of detection scores and resilience to such distracting auxiliary tasks. Our approach adopts the popular mixup method in text feature space and can be utilized with any black-box ASR output. To demonstrate the effectiveness of our method, we conduct post-processing experiments with both traditional and end-to-end ASR systems (both for English and Korean languages) with 5 different speech corpora. We find that our method improves both ASR error detection F 1 scores and reduces the number of correctly transcribed disfluencies wrongly detected as ASR errors. Finally, we suggest methods to utilize resulting LMs directly in semi-supervised ASR training.