 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Speaker diarization assisted ASR for multi-speaker conversations
Apr 05, 2021
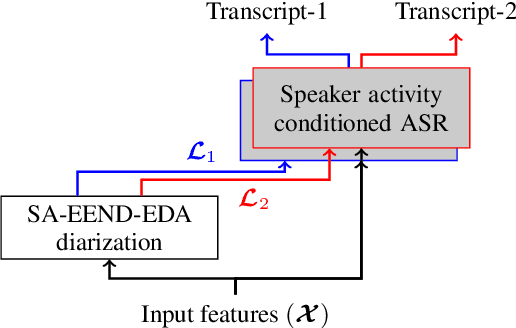
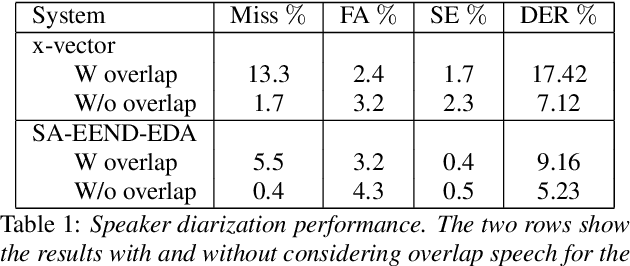
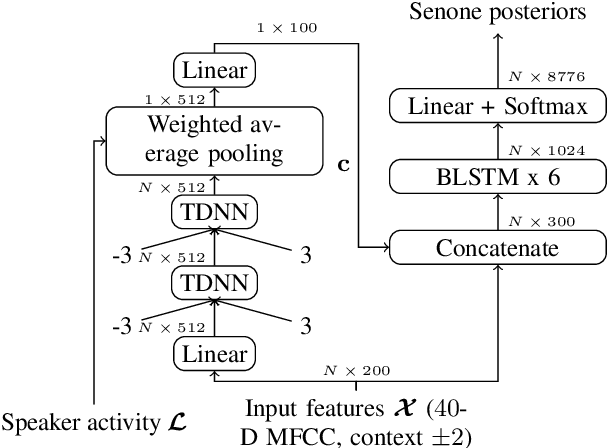

In this paper, we propose a novel approach for the transcription of speech conversations with natural speaker overlap, from single channel recordings. We propose a combination of a speaker diarization system and a hybrid automatic speech recognition (ASR) system with speaker activity assisted acoustic model (AM). An end-to-end neural network system is used for speaker diarization. Two architectures, (i) input conditioned AM, and (ii) gated features AM, are explored to incorporate the speaker activity information. The models output speaker specific senones. The experiments on Switchboard telephone conversations show the advantage of incorporating speaker activity information in the ASR system for recordings with overlapped speech. In particular, an absolute improvement of $11\%$ in word error rate (WER) is seen for the proposed approach on natural conversation speech with automatic diarization.
Google Crowdsourced Speech Corpora and Related Open-Source Resources for Low-Resource Languages and Dialects: An Overview
Oct 14, 2020This paper presents an overview of a program designed to address the growing need for developing freely available speech resources for under-represented languages. At present we have released 38 datasets for building text-to-speech and automatic speech recognition applications for languages and dialects of South and Southeast Asia, Africa, Europe and South America. The paper describes the methodology used for developing such corpora and presents some of our findings that could benefit under-represented language communities.
Spartus: A 9.4 TOp/s FPGA-based LSTM Accelerator Exploiting Spatio-temporal Sparsity
Aug 20, 2021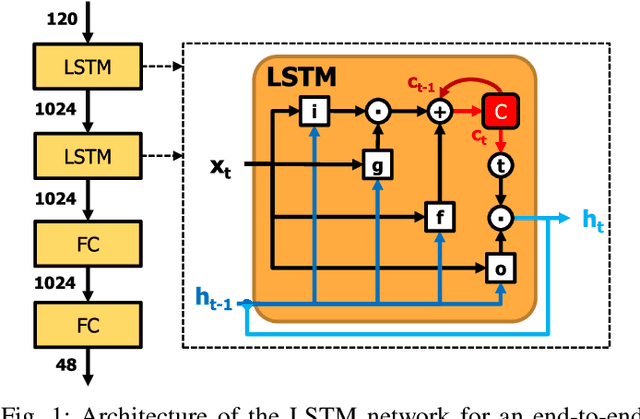
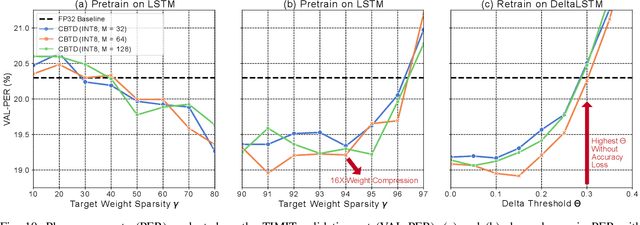
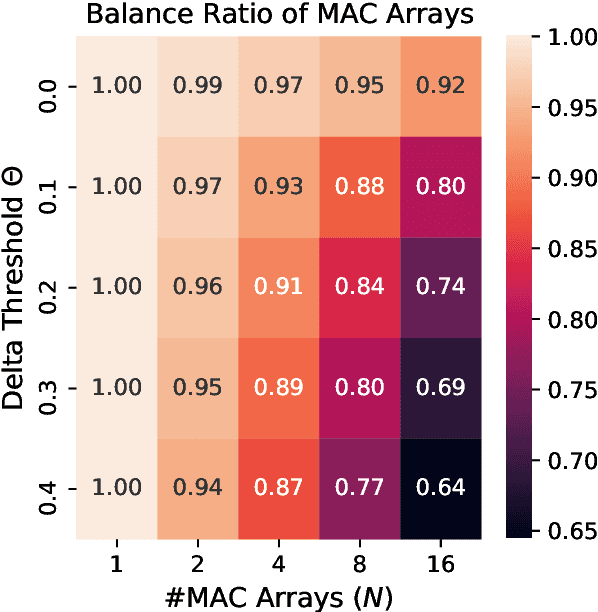
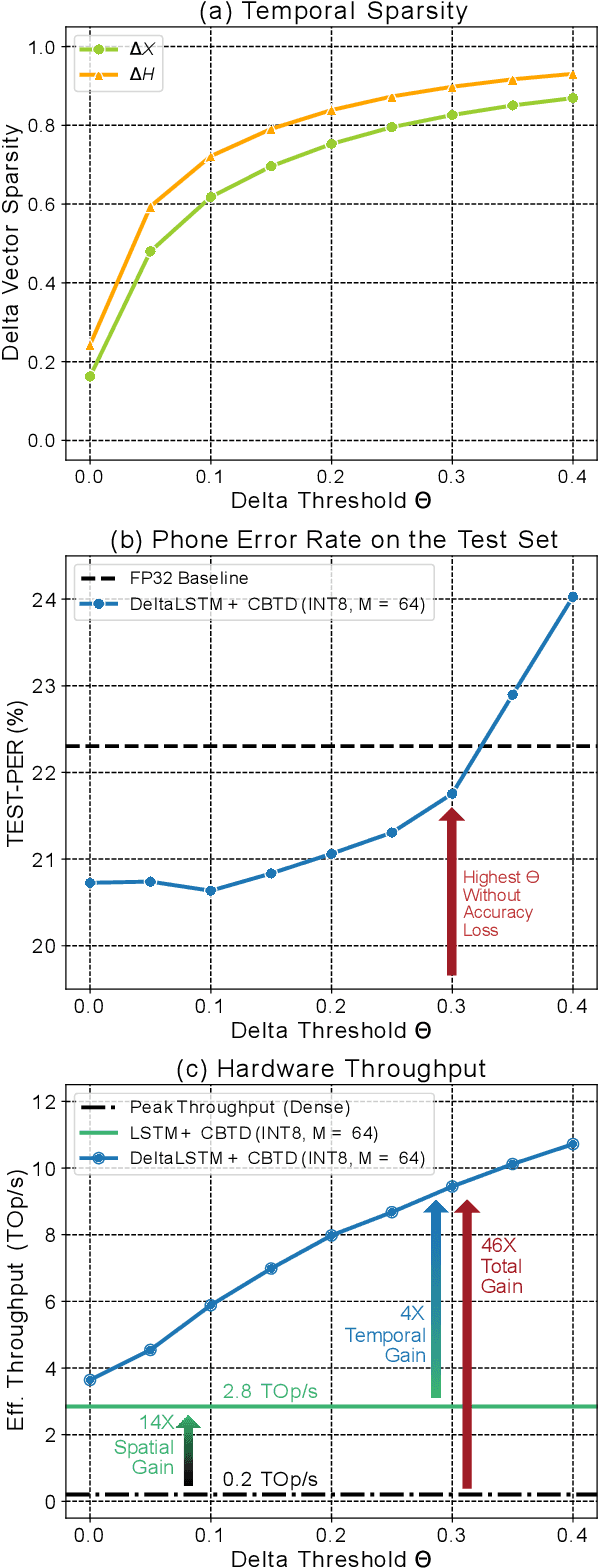
Long Short-Term Memory (LSTM) recurrent networks are frequently used for tasks involving time-sequential data such as speech recognition. However, it is difficult to deploy these networks on hardware to achieve high throughput and low latency because the fully connected structure makes LSTM networks a memory-bounded algorithm. Previous LSTM accelerators either exploited weight spatial sparsity or temporal activation sparsity. This paper proposes a new accelerator called "Spartus" that exploits spatio-temporal sparsity to achieve ultra-low latency inference. The spatial sparsity is induced using our proposed pruning method called Column-Balanced Targeted Dropout (CBTD), which structures sparse weight matrices for balanced workload. It achieved up to 96% weight sparsity with negligible accuracy difference for an LSTM network trained on a TIMIT phone recognition task. To induce temporal sparsity in LSTM, we create the DeltaLSTM by extending the previous DeltaGRU method to the LSTM network. This combined sparsity simultaneously saves on the weight memory access and associated arithmetic operations. Spartus was implemented on a Xilinx Zynq-7100 FPGA. The Spartus per-sample latency for a single DeltaLSTM layer of 1024 neurons averages 1 us. Spartus achieved 9.4 TOp/s effective batch-1 throughput and 1.1 TOp/J energy efficiency, which, respectively, are 4X and 7X higher than the previous state-of-the-art.
What can predictive speech coders learn from speaker recognizers?
Apr 05, 2022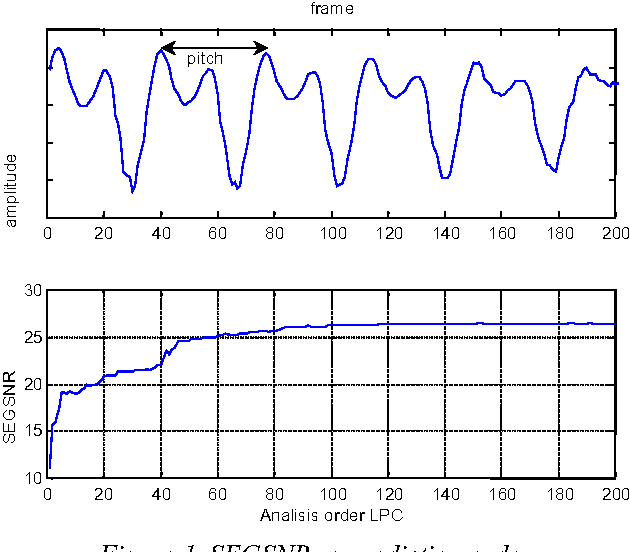
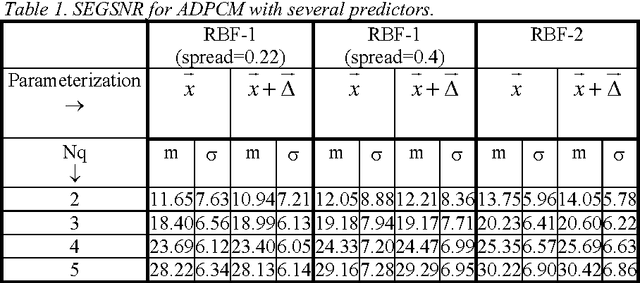
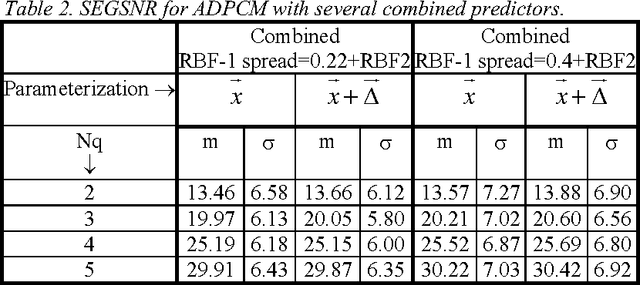
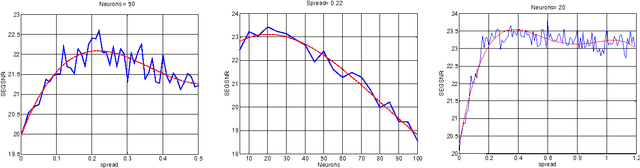
This paper compares the speech coder and speaker recognizer applications, showing some parallelism between them. In this paper, some approaches used for speaker recognition are applied to speech coding in order to improve the prediction accuracy. Experimental results show an improvement in Segmental SNR (SEGSNR).
* 7 pages, published in ITRW on Non-Linear Speech Processing (NOLISP 03), May 20-23, 2003, Le Croisic, France, paper 001. arXiv admin note: text overlap with arXiv:2204.02101
Tiny Transducer: A Highly-efficient Speech Recognition Model on Edge Devices
Jan 18, 2021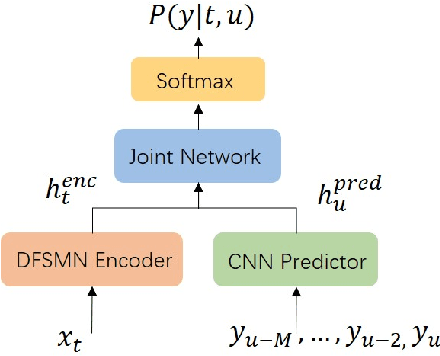

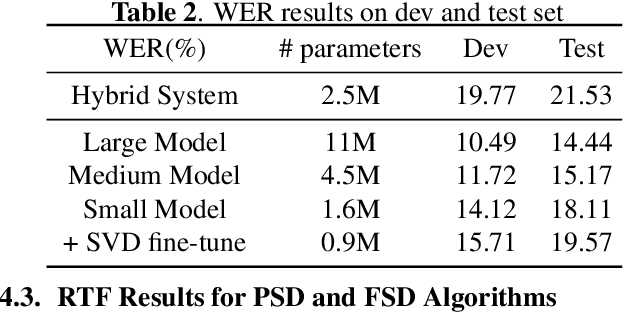
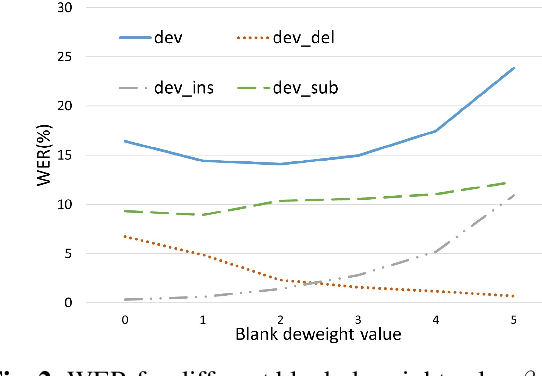
This paper proposes an extremely lightweight phone-based transducer model with a tiny decoding graph on edge devices. First, a phone synchronous decoding (PSD) algorithm based on blank label skipping is first used to speed up the transducer decoding process. Then, to decrease the deletion errors introduced by the high blank score, a blank label deweighting approach is proposed. To reduce parameters and computation, deep feedforward sequential memory network (DFSMN) layers are used in the transducer encoder, and a CNN-based stateless predictor is adopted. SVD technology compresses the model further. WFST-based decoding graph takes the context-independent (CI) phone posteriors as input and allows us to flexibly bias user-specific information. Finally, with only 0.9M parameters after SVD, our system could give a relative 9.1% - 20.5% improvement compared with a bigger conventional hybrid system on edge devices.
Facetron: Multi-speaker Face-to-Speech Model based on Cross-modal Latent Representations
Jul 26, 2021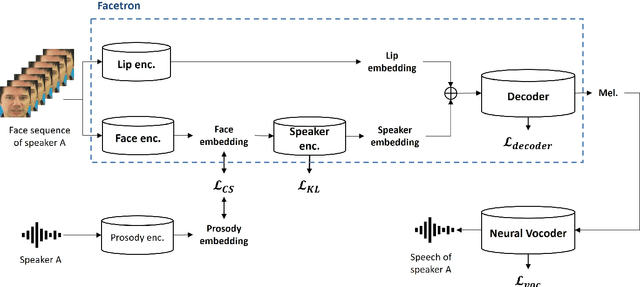
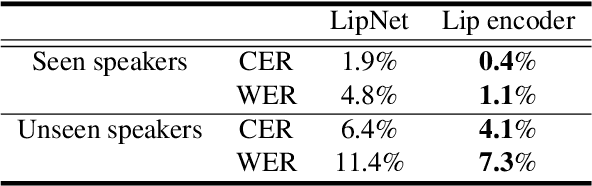
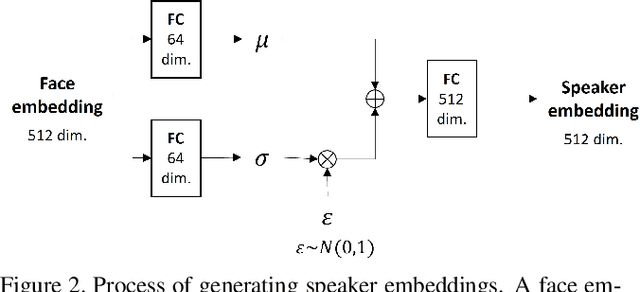
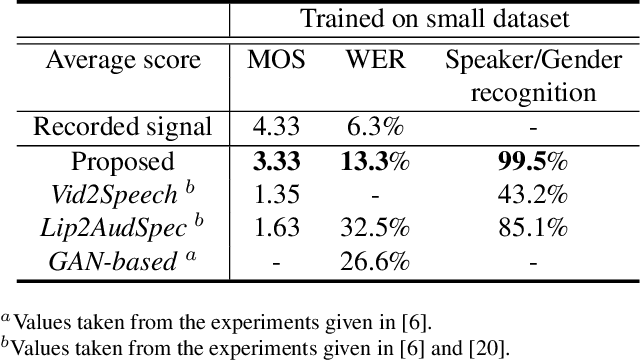
In this paper, we propose an effective method to synthesize speaker-specific speech waveforms by conditioning on videos of an individual's face. Using a generative adversarial network (GAN) with linguistic and speaker characteristic features as auxiliary conditions, our method directly converts face images into speech waveforms under an end-to-end training framework. The linguistic features are extracted from lip movements using a lip-reading model, and the speaker characteristic features are predicted from face images using cross-modal learning with a pre-trained acoustic model. Since these two features are uncorrelated and controlled independently, we can flexibly synthesize speech waveforms whose speaker characteristics vary depending on the input face images. Therefore, our method can be regarded as a multi-speaker face-to-speech waveform model. We show the superiority of our proposed model over conventional methods in terms of both objective and subjective evaluation results. Specifically, we evaluate the performances of the linguistic feature and the speaker characteristic generation modules by measuring the accuracy of automatic speech recognition and automatic speaker/gender recognition tasks, respectively. We also evaluate the naturalness of the synthesized speech waveforms using a mean opinion score (MOS) test.
A Unified Speaker Adaptation Approach for ASR
Oct 16, 2021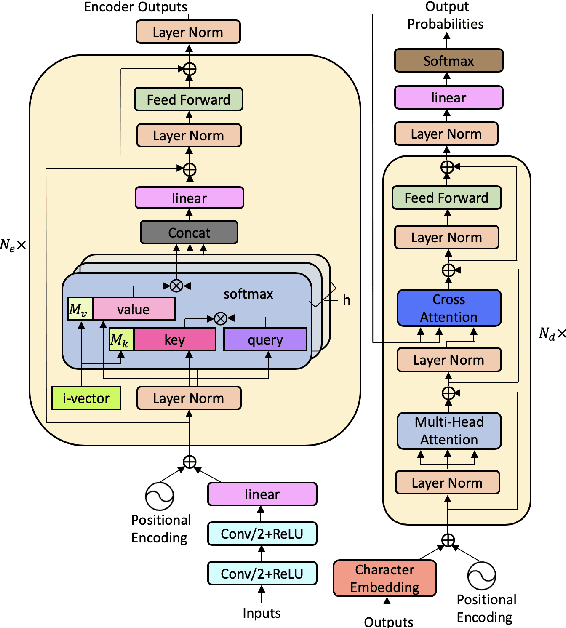

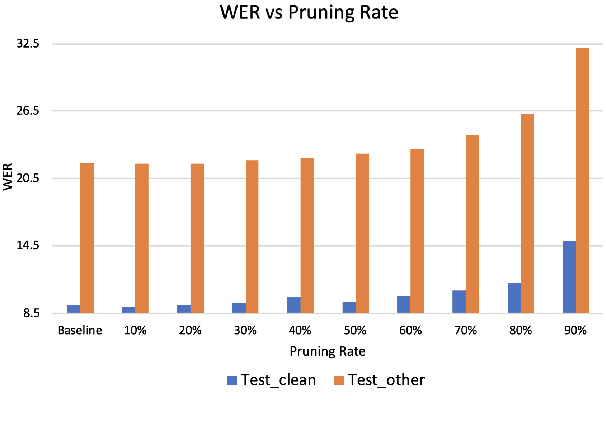
Transformer models have been used in automatic speech recognition (ASR) successfully and yields state-of-the-art results. However, its performance is still affected by speaker mismatch between training and test data. Further finetuning a trained model with target speaker data is the most natural approach for adaptation, but it takes a lot of compute and may cause catastrophic forgetting to the existing speakers. In this work, we propose a unified speaker adaptation approach consisting of feature adaptation and model adaptation. For feature adaptation, we employ a speaker-aware persistent memory model which generalizes better to unseen test speakers by making use of speaker i-vectors to form a persistent memory. For model adaptation, we use a novel gradual pruning method to adapt to target speakers without changing the model architecture, which to the best of our knowledge, has never been explored in ASR. Specifically, we gradually prune less contributing parameters on model encoder to a certain sparsity level, and use the pruned parameters for adaptation, while freezing the unpruned parameters to keep the original model performance. We conduct experiments on the Librispeech dataset. Our proposed approach brings relative 2.74-6.52% word error rate (WER) reduction on general speaker adaptation. On target speaker adaptation, our method outperforms the baseline with up to 20.58% relative WER reduction, and surpasses the finetuning method by up to relative 2.54%. Besides, with extremely low-resource adaptation data (e.g., 1 utterance), our method could improve the WER by relative 6.53% with only a few epochs of training.
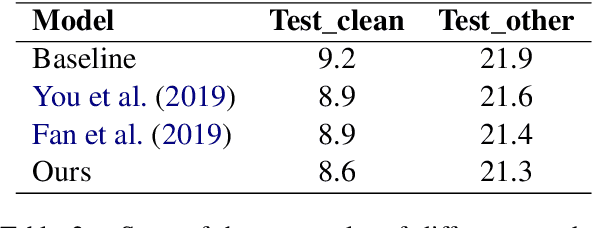
Modified SPLICE and its Extension to Non-Stereo Data for Noise Robust Speech Recognition
Jul 15, 2013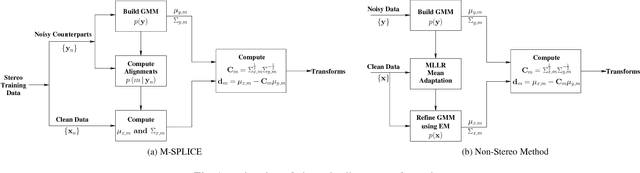
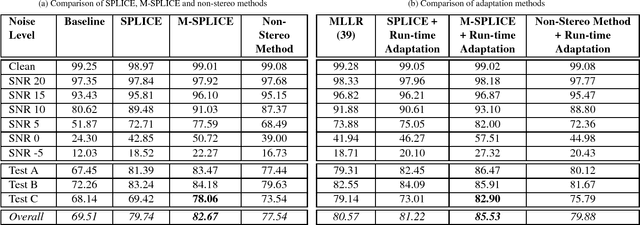
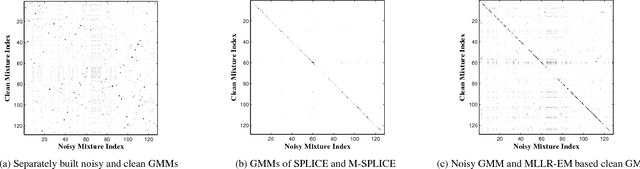

In this paper, a modification to the training process of the popular SPLICE algorithm has been proposed for noise robust speech recognition. The modification is based on feature correlations, and enables this stereo-based algorithm to improve the performance in all noise conditions, especially in unseen cases. Further, the modified framework is extended to work for non-stereo datasets where clean and noisy training utterances, but not stereo counterparts, are required. Finally, an MLLR-based computationally efficient run-time noise adaptation method in SPLICE framework has been proposed. The modified SPLICE shows 8.6% absolute improvement over SPLICE in Test C of Aurora-2 database, and 2.93% overall. Non-stereo method shows 10.37% and 6.93% absolute improvements over Aurora-2 and Aurora-4 baseline models respectively. Run-time adaptation shows 9.89% absolute improvement in modified framework as compared to SPLICE for Test C, and 4.96% overall w.r.t. standard MLLR adaptation on HMMs.
Multi-mode Transformer Transducer with Stochastic Future Context
Jun 17, 2021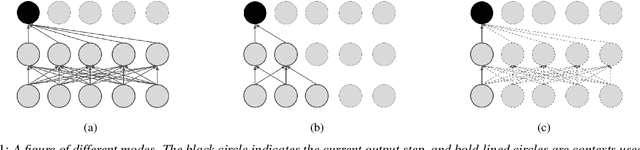
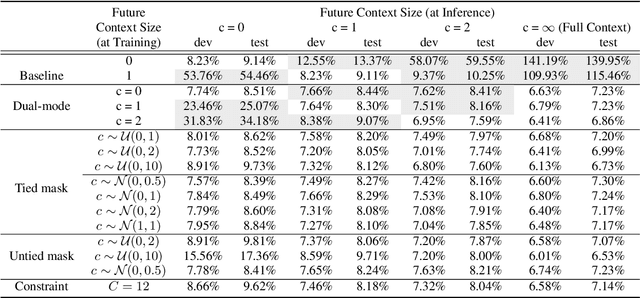
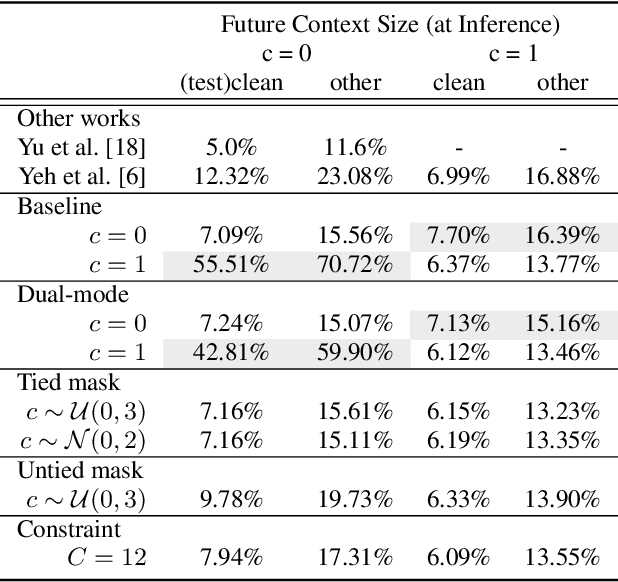
Automatic speech recognition (ASR) models make fewer errors when more surrounding speech information is presented as context. Unfortunately, acquiring a larger future context leads to higher latency. There exists an inevitable trade-off between speed and accuracy. Naively, to fit different latency requirements, people have to store multiple models and pick the best one under the constraints. Instead, a more desirable approach is to have a single model that can dynamically adjust its latency based on different constraints, which we refer to as Multi-mode ASR. A Multi-mode ASR model can fulfill various latency requirements during inference -- when a larger latency becomes acceptable, the model can process longer future context to achieve higher accuracy and when a latency budget is not flexible, the model can be less dependent on future context but still achieve reliable accuracy. In pursuit of Multi-mode ASR, we propose Stochastic Future Context, a simple training procedure that samples one streaming configuration in each iteration. Through extensive experiments on AISHELL-1 and LibriSpeech datasets, we show that a Multi-mode ASR model rivals, if not surpasses, a set of competitive streaming baselines trained with different latency budgets.
Challenges and Obstacles Towards Deploying Deep Learning Models on Mobile Devices
May 06, 2021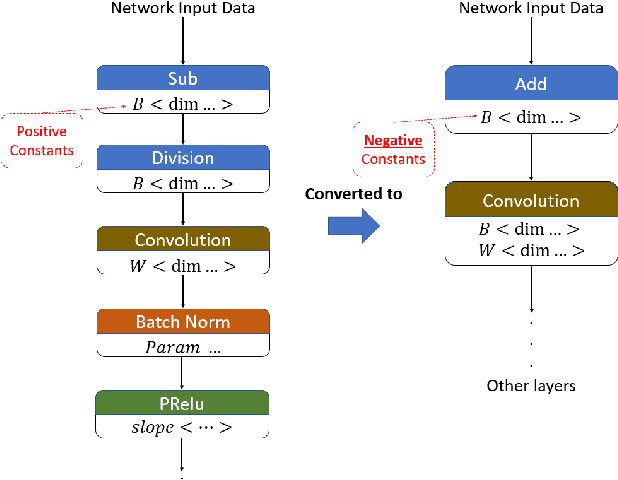
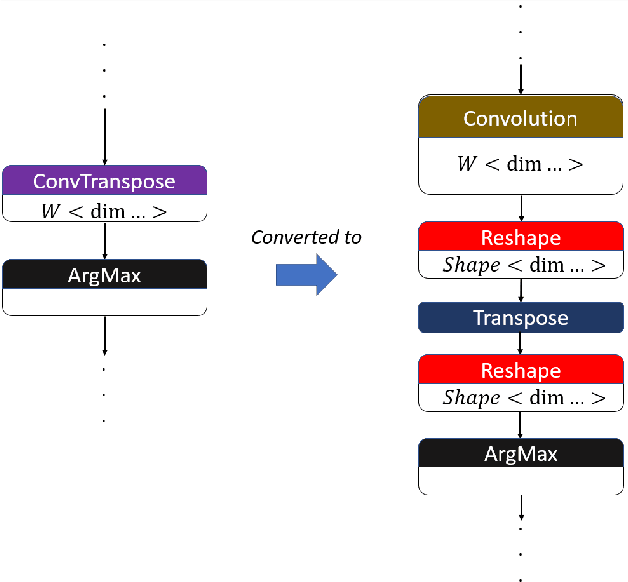
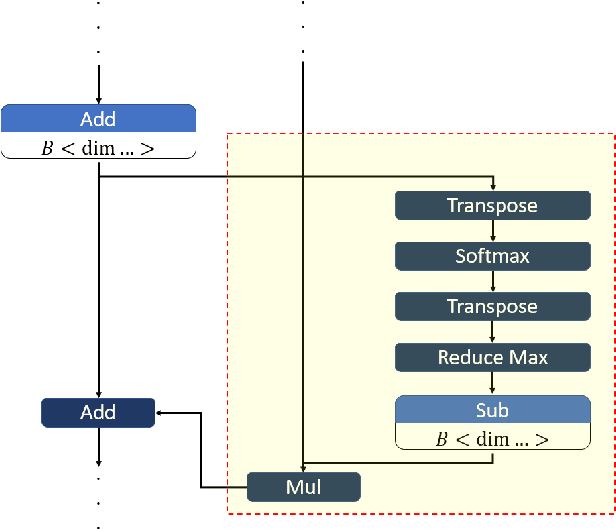
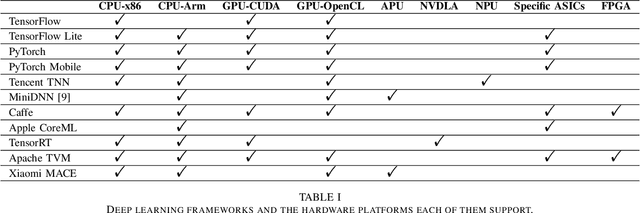
From computer vision and speech recognition to forecasting trajectories in autonomous vehicles, deep learning approaches are at the forefront of so many domains. Deep learning models are developed using plethora of high-level, generic frameworks and libraries. Running those models on the mobile devices require hardware-aware optimizations and in most cases converting the models to other formats or using a third-party framework. In reality, most of the developed models need to undergo a process of conversion, adaptation, and, in some cases, full retraining to match the requirements and features of the framework that is deploying the model on the target platform. Variety of hardware platforms with heterogeneous computing elements, from wearable devices to high-performance GPU clusters are used to run deep learning models. In this paper, we present the existing challenges, obstacles, and practical solutions towards deploying deep learning models on mobile devices.