 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
ESPnet-ST IWSLT 2021 Offline Speech Translation System
Jul 06, 2021
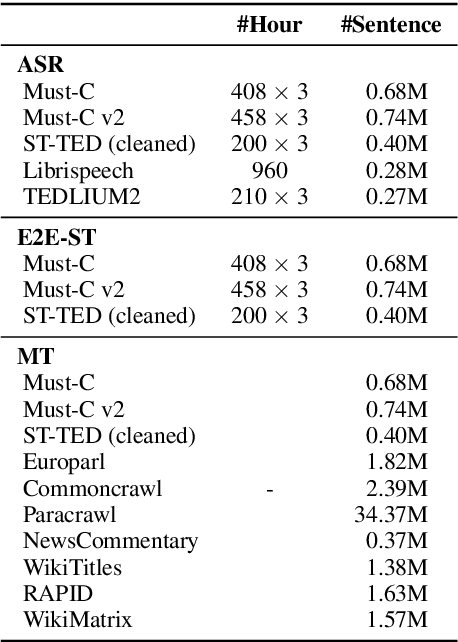
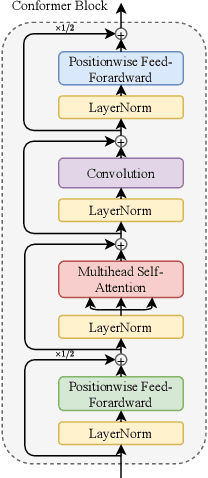
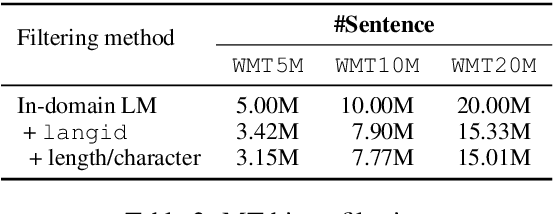
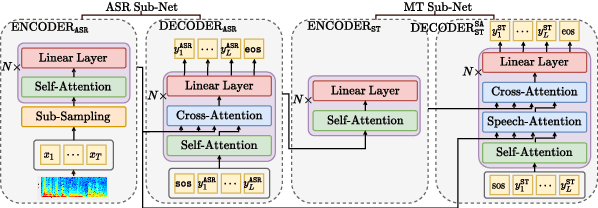
This paper describes the ESPnet-ST group's IWSLT 2021 submission in the offline speech translation track. This year we made various efforts on training data, architecture, and audio segmentation. On the data side, we investigated sequence-level knowledge distillation (SeqKD) for end-to-end (E2E) speech translation. Specifically, we used multi-referenced SeqKD from multiple teachers trained on different amounts of bitext. On the architecture side, we adopted the Conformer encoder and the Multi-Decoder architecture, which equips dedicated decoders for speech recognition and translation tasks in a unified encoder-decoder model and enables search in both source and target language spaces during inference. We also significantly improved audio segmentation by using the pyannote.audio toolkit and merging multiple short segments for long context modeling. Experimental evaluations showed that each of them contributed to large improvements in translation performance. Our best E2E system combined all the above techniques with model ensembling and achieved 31.4 BLEU on the 2-ref of tst2021 and 21.2 BLEU and 19.3 BLEU on the two single references of tst2021.
Predicting within and across language phoneme recognition performance of self-supervised learning speech pre-trained models
Jun 24, 2022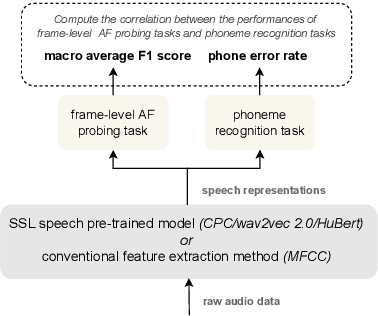
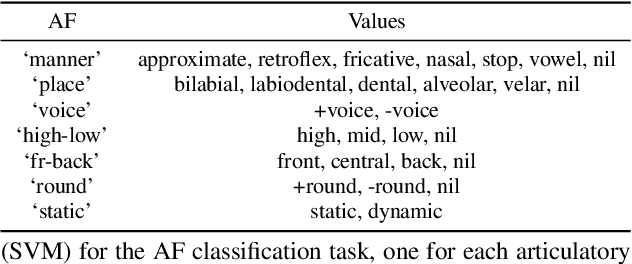

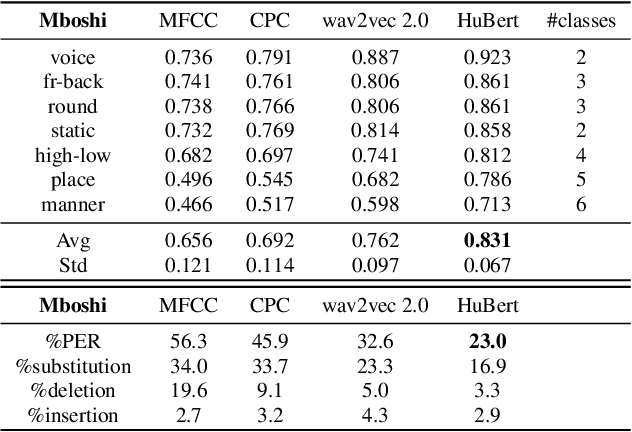
In this work, we analyzed and compared speech representations extracted from different frozen self-supervised learning (SSL) speech pre-trained models on their ability to capture articulatory features (AF) information and their subsequent prediction of phone recognition performance for within and across language scenarios. Specifically, we compared CPC, wav2vec 2.0, and HuBert. First, frame-level AF probing tasks were implemented. Subsequently, phone-level end-to-end ASR systems for phoneme recognition tasks were implemented, and the performance on the frame-level AF probing task and the phone accuracy were correlated. Compared to the conventional speech representation MFCC, all SSL pre-trained speech representations captured more AF information, and achieved better phoneme recognition performance within and across languages, with HuBert performing best. The frame-level AF probing task is a good predictor of phoneme recognition performance, showing the importance of capturing AF information in the speech representations. Compared with MFCC, in the within-language scenario, the performance of these SSL speech pre-trained models on AF probing tasks achieved a maximum relative increase of 34.4%, and it resulted in the lowest PER of 10.2%. In the cross-language scenario, the maximum relative increase of 26.7% also resulted in the lowest PER of 23.0%.
Improving a neural network model by explanation-guided training for glioma classification based on MRI data
Jul 05, 2021
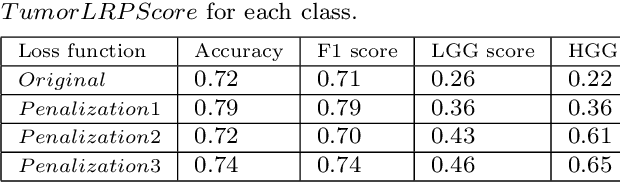
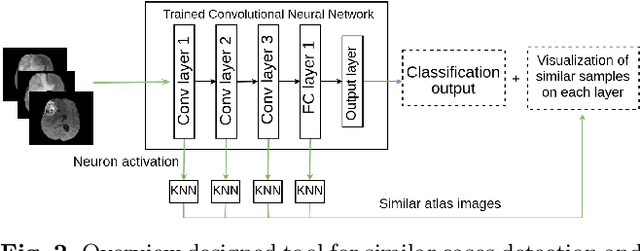
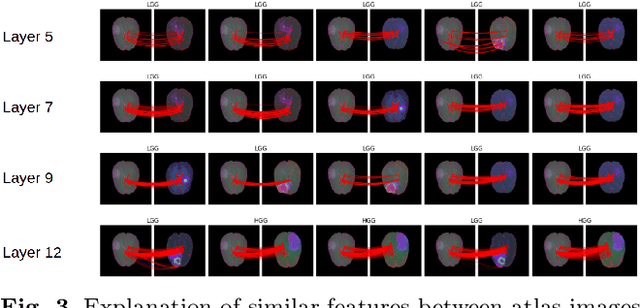
In recent years, artificial intelligence (AI) systems have come to the forefront. These systems, mostly based on Deep learning (DL), achieve excellent results in areas such as image processing, natural language processing, or speech recognition. Despite the statistically high accuracy of deep learning models, their output is often a decision of "black box". Thus, Interpretability methods have become a popular way to gain insight into the decision-making process of deep learning models. Explanation of a deep learning model is desirable in the medical domain since the experts have to justify their judgments to the patient. In this work, we proposed a method for explanation-guided training that uses a Layer-wise relevance propagation (LRP) technique to force the model to focus only on the relevant part of the image. We experimentally verified our method on a convolutional neural network (CNN) model for low-grade and high-grade glioma classification problems. Our experiments show promising results in a way to use interpretation techniques in the model training process.
Auxiliary Sequence Labeling Tasks for Disfluency Detection
Oct 24, 2020
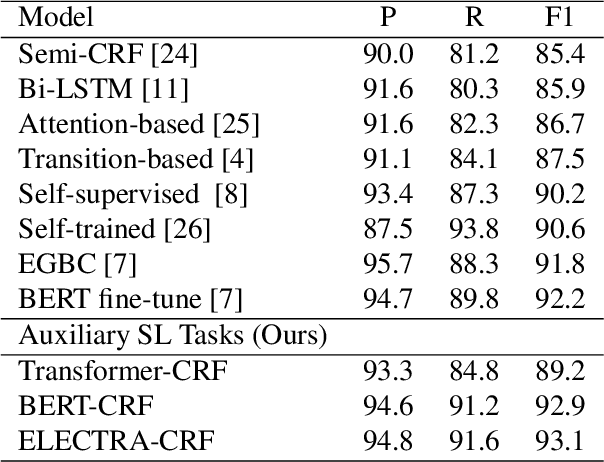
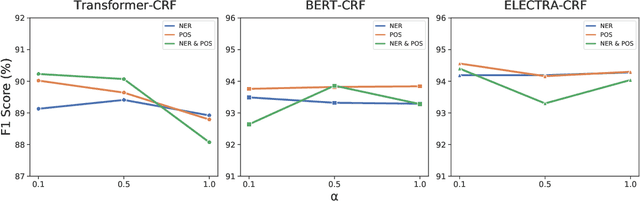
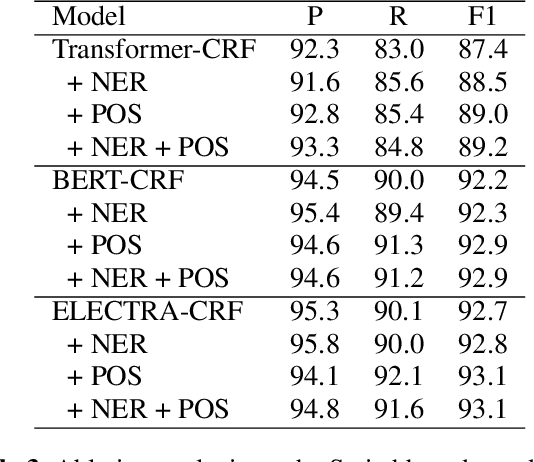
Detecting disfluencies in spontaneous speech is an important preprocessing step in natural language processing and speech recognition applications. In this paper, we propose a method utilizing named entity recognition (NER) and part-of-speech (POS) as auxiliary sequence labeling (SL) tasks for disfluency detection. First, we show that training a disfluency detection model with auxiliary SL tasks can improve its F-score in disfluency detection. Then, we analyze which auxiliary SL tasks are influential depending on baseline models. Experimental results on the widely used English Switchboard dataset show that our method outperforms the previous state-of-the-art in disfluency detection.
Graph Neural Networks: Methods, Applications, and Opportunities
Aug 24, 2021
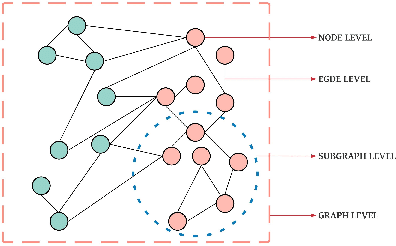
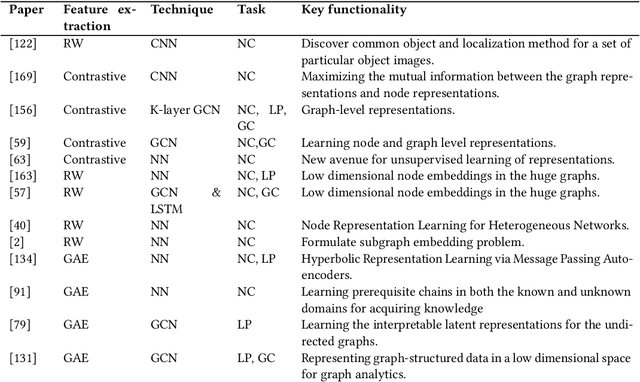
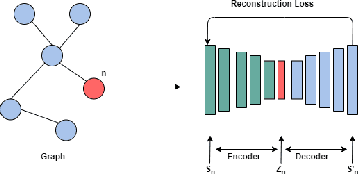
In the last decade or so, we have witnessed deep learning reinvigorating the machine learning field. It has solved many problems in the domains of computer vision, speech recognition, natural language processing, and various other tasks with state-of-the-art performance. The data is generally represented in the Euclidean space in these domains. Various other domains conform to non-Euclidean space, for which graph is an ideal representation. Graphs are suitable for representing the dependencies and interrelationships between various entities. Traditionally, handcrafted features for graphs are incapable of providing the necessary inference for various tasks from this complex data representation. Recently, there is an emergence of employing various advances in deep learning to graph data-based tasks. This article provides a comprehensive survey of graph neural networks (GNNs) in each learning setting: supervised, unsupervised, semi-supervised, and self-supervised learning. Taxonomy of each graph based learning setting is provided with logical divisions of methods falling in the given learning setting. The approaches for each learning task are analyzed from both theoretical as well as empirical standpoints. Further, we provide general architecture guidelines for building GNNs. Various applications and benchmark datasets are also provided, along with open challenges still plaguing the general applicability of GNNs.
Lightweight Adapter Tuning for Multilingual Speech Translation
Jun 02, 2021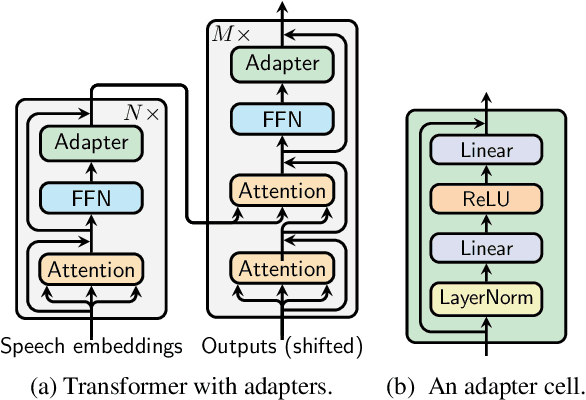
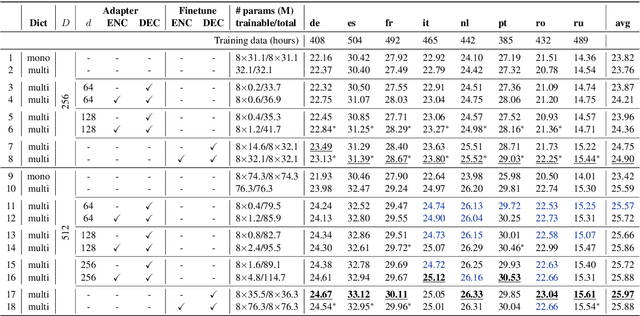
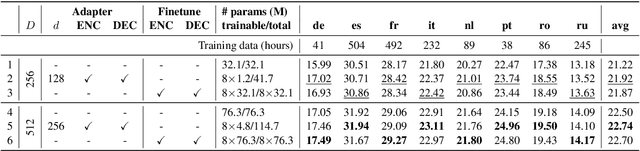
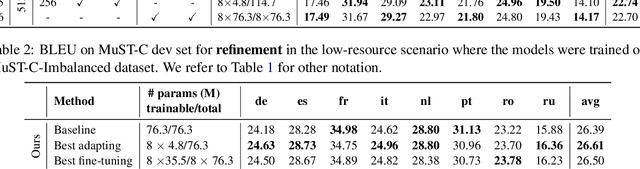
Adapter modules were recently introduced as an efficient alternative to fine-tuning in NLP. Adapter tuning consists in freezing pretrained parameters of a model and injecting lightweight modules between layers, resulting in the addition of only a small number of task-specific trainable parameters. While adapter tuning was investigated for multilingual neural machine translation, this paper proposes a comprehensive analysis of adapters for multilingual speech translation (ST). Starting from different pre-trained models (a multilingual ST trained on parallel data or a multilingual BART (mBART) trained on non-parallel multilingual data), we show that adapters can be used to: (a) efficiently specialize ST to specific language pairs with a low extra cost in terms of parameters, and (b) transfer from an automatic speech recognition (ASR) task and an mBART pre-trained model to a multilingual ST task. Experiments show that adapter tuning offer competitive results to full fine-tuning, while being much more parameter-efficient.
VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021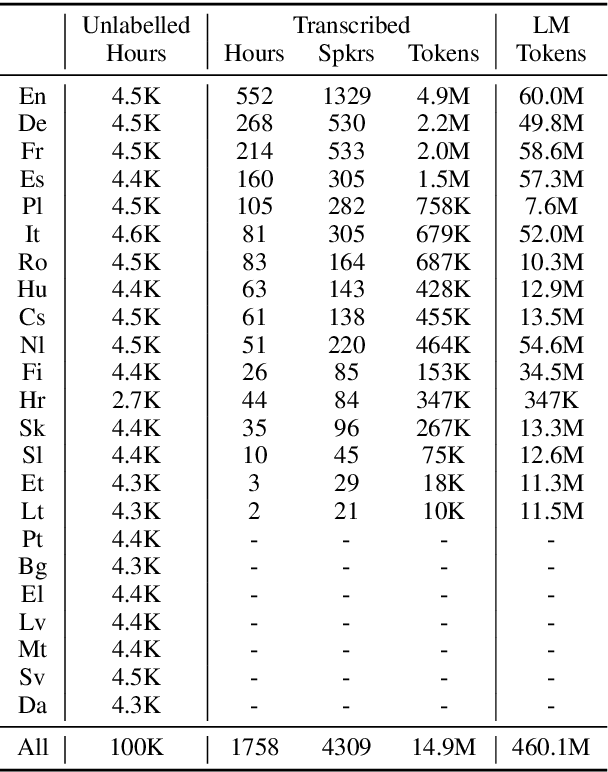
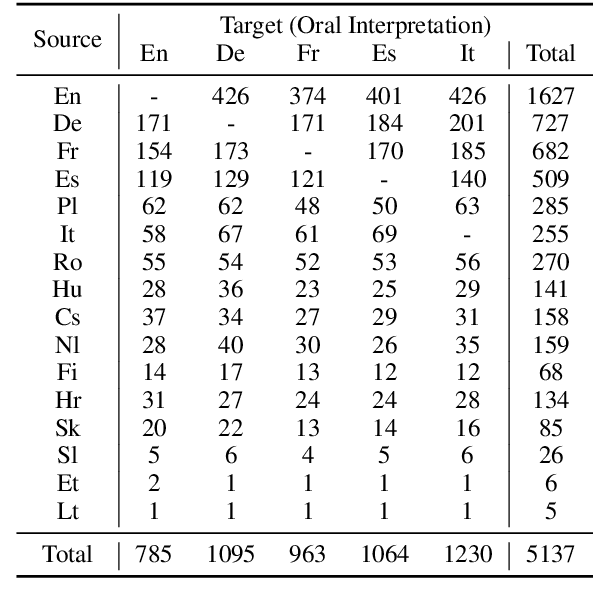

We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.
Low-Resource Spoken Language Identification Using Self-Attentive Pooling and Deep 1D Time-Channel Separable Convolutions
May 31, 2021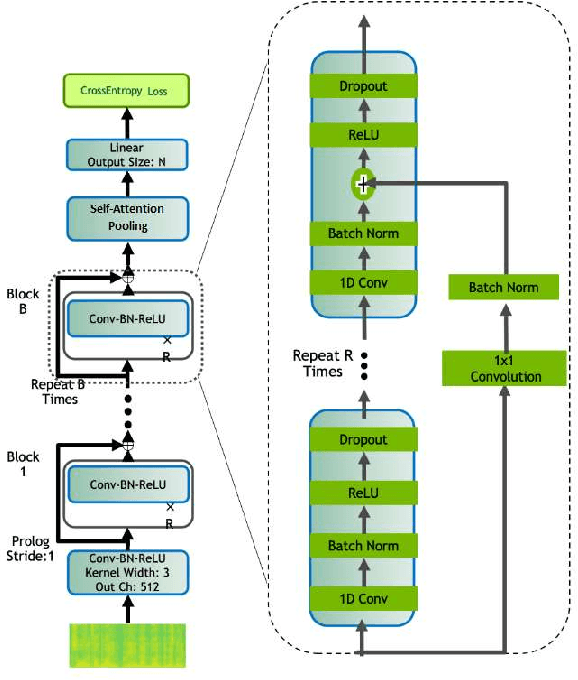

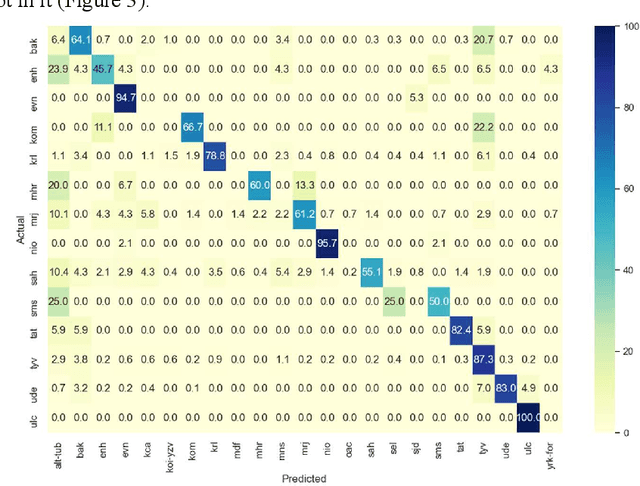
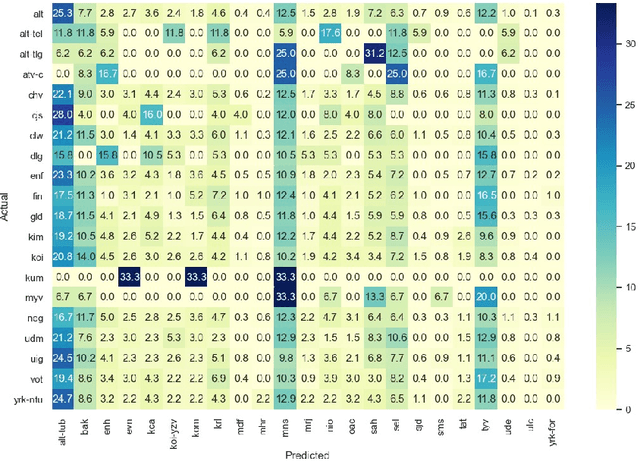
This memo describes NTR/TSU winning submission for Low Resource ASR challenge at Dialog2021 conference, language identification track. Spoken Language Identification (LID) is an important step in a multilingual Automated Speech Recognition (ASR) system pipeline. Traditionally, the ASR task requires large volumes of labeled data that are unattainable for most of the world's languages, including most of the languages of Russia. In this memo, we show that a convolutional neural network with a Self-Attentive Pooling layer shows promising results in low-resource setting for the language identification task and set up a SOTA for the Low Resource ASR challenge dataset. Additionally, we compare the structure of confusion matrices for this and significantly more diverse VoxForge dataset and state and substantiate the hypothesis that whenever the dataset is diverse enough so that the other classification factors, like gender, age etc. are well-averaged, the confusion matrix for LID system bears the language similarity measure.
Towards One Model to Rule All: Multilingual Strategy for Dialectal Code-Switching Arabic ASR
May 31, 2021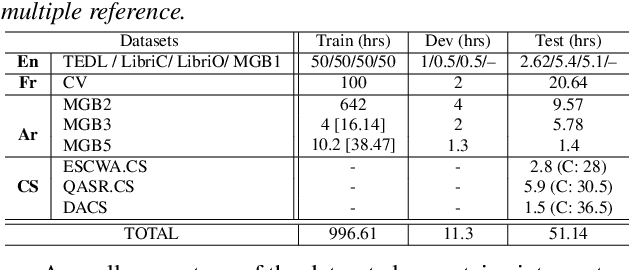
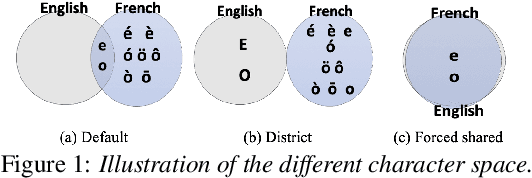
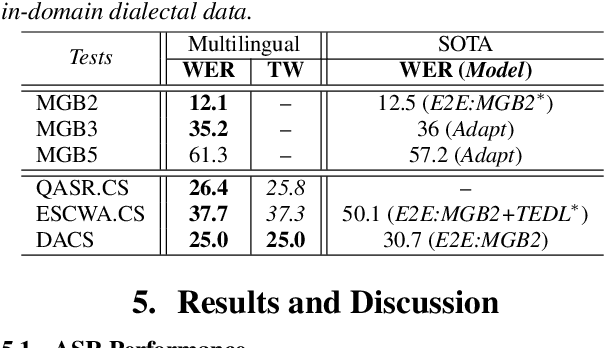
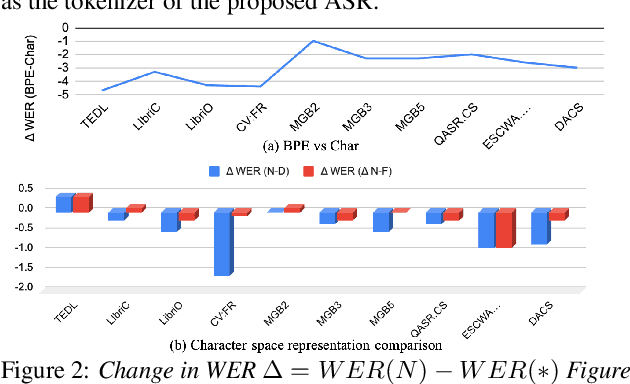
With the advent of globalization, there is an increasing demand for multilingual automatic speech recognition (ASR), handling language and dialectal variation of spoken content. Recent studies show its efficacy over monolingual systems. In this study, we design a large multilingual end-to-end ASR using self-attention based conformer architecture. We trained the system using Arabic (Ar), English (En) and French (Fr) languages. We evaluate the system performance handling: (i) monolingual (Ar, En and Fr); (ii) multi-dialectal (Modern Standard Arabic, along with dialectal variation such as Egyptian and Moroccan); (iii) code-switching -- cross-lingual (Ar-En/Fr) and dialectal (MSA-Egyptian dialect) test cases, and compare with current state-of-the-art systems. Furthermore, we investigate the influence of different embedding/character representations including character vs word-piece; shared vs distinct input symbol per language. Our findings demonstrate the strength of such a model by outperforming state-of-the-art monolingual dialectal Arabic and code-switching Arabic ASR.
Noise Robust IOA/CAS Speech Separation and Recognition System For The Third 'CHIME' Challenge
Sep 21, 2015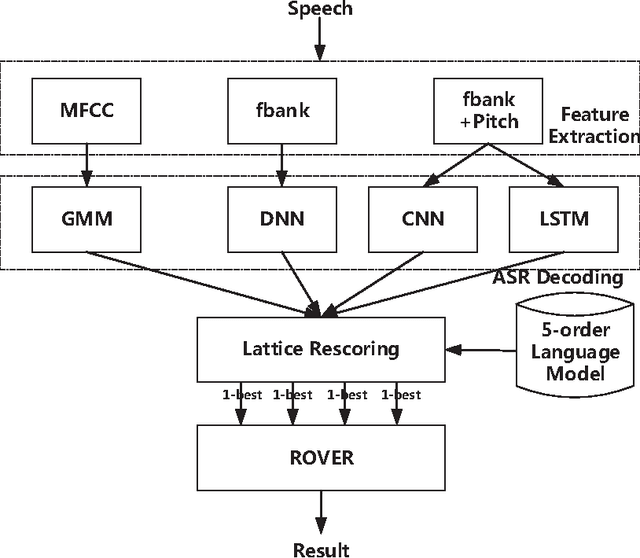
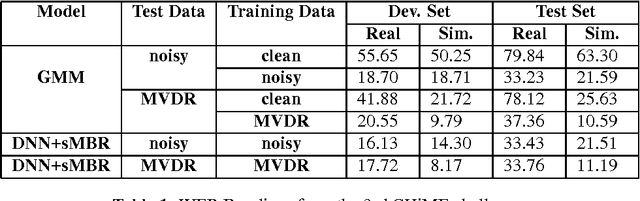

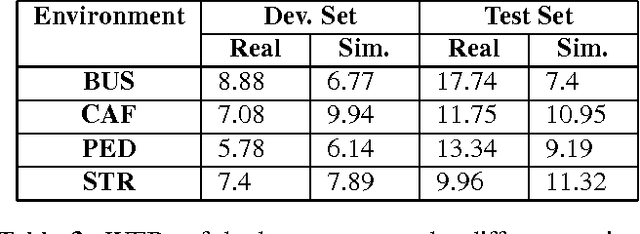
This paper presents the contribution to the third 'CHiME' speech separation and recognition challenge including both front-end signal processing and back-end speech recognition. In the front-end, Multi-channel Wiener filter (MWF) is designed to achieve background noise reduction. Different from traditional MWF, optimized parameter for the tradeoff between noise reduction and target signal distortion is built according to the desired noise reduction level. In the back-end, several techniques are taken advantage to improve the noisy Automatic Speech Recognition (ASR) performance including Deep Neural Network (DNN), Convolutional Neural Network (CNN) and Long short-term memory (LSTM) using medium vocabulary, Lattice rescoring with a big vocabulary language model finite state transducer, and ROVER scheme. Experimental results show the proposed system combining front-end and back-end is effective to improve the ASR performance.