 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
On lattice-free boosted MMI training of HMM and CTC-based full-context ASR models
Jul 09, 2021
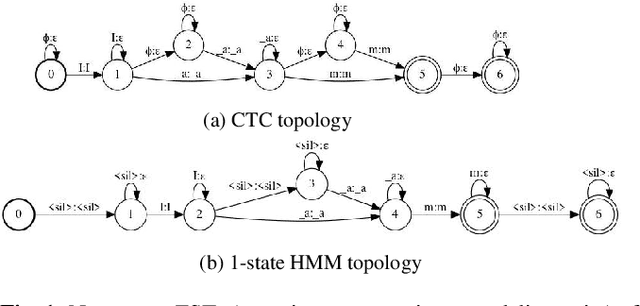
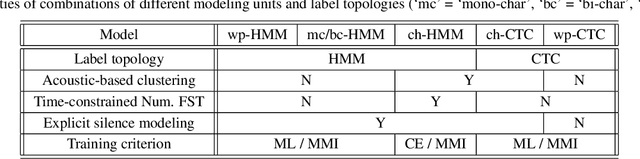
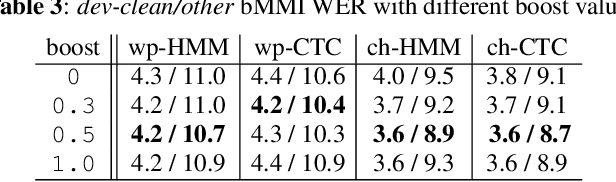
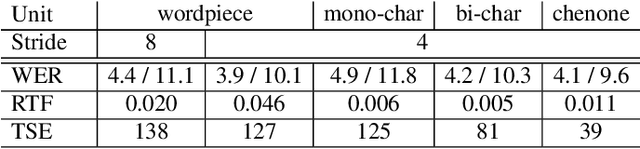
Hybrid automatic speech recognition (ASR) models are typically sequentially trained with CTC or LF-MMI criteria. However, they have vastly different legacies and are usually implemented in different frameworks. In this paper, by decoupling the concepts of modeling units and label topologies and building proper numerator/denominator graphs accordingly, we establish a generalized framework for hybrid acoustic modeling (AM). In this framework, we show that LF-MMI is a powerful training criterion applicable to both limited-context and full-context models, for wordpiece/mono-char/bi-char/chenone units, with both HMM/CTC topologies. From this framework, we propose three novel training schemes: chenone(ch)/wordpiece(wp)-CTC-bMMI, and wordpiece(wp)-HMM-bMMI with different advantages in training performance, decoding efficiency and decoding time-stamp accuracy. The advantages of different training schemes are evaluated comprehensively on Librispeech, and wp-CTC-bMMI and ch-CTC-bMMI are evaluated on two real world ASR tasks to show their effectiveness. Besides, we also show bi-char(bc) HMM-MMI models can serve as better alignment models than traditional non-neural GMM-HMMs.
Muddling Label Regularization: Deep Learning for Tabular Datasets
Jun 08, 2021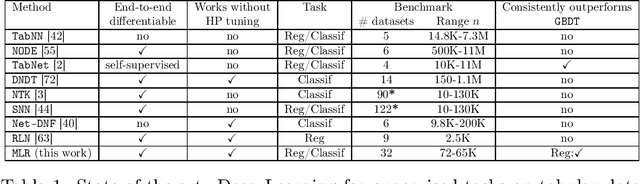


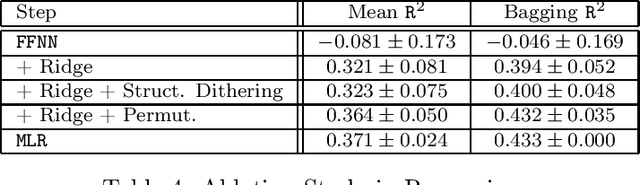
Deep Learning (DL) is considered the state-of-the-art in computer vision, speech recognition and natural language processing. Until recently, it was also widely accepted that DL is irrelevant for learning tasks on tabular data, especially in the small sample regime where ensemble methods are acknowledged as the gold standard. We present a new end-to-end differentiable method to train a standard FFNN. Our method, \textbf{Muddling labels for Regularization} (\texttt{MLR}), penalizes memorization through the generation of uninformative labels and the application of a differentiable close-form regularization scheme on the last hidden layer during training. \texttt{MLR} outperforms classical NN and the gold standard (GBDT, RF) for regression and classification tasks on several datasets from the UCI database and Kaggle covering a large range of sample sizes and feature to sample ratios. Researchers and practitioners can use \texttt{MLR} on its own as an off-the-shelf \DL{} solution or integrate it into the most advanced ML pipelines.
Predicting within and across language phoneme recognition performance of self-supervised learning speech pre-trained models
Jun 24, 2022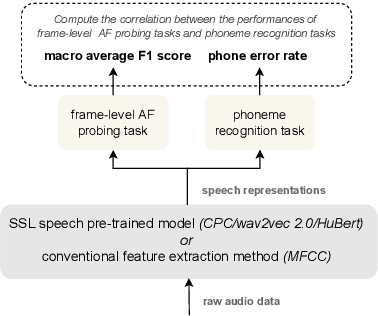
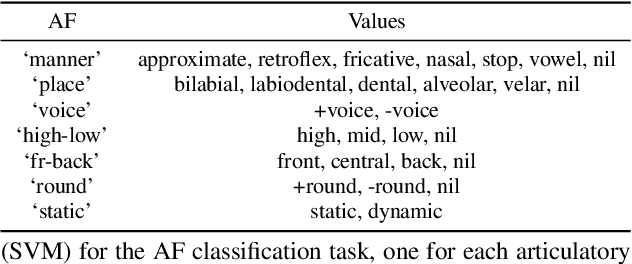

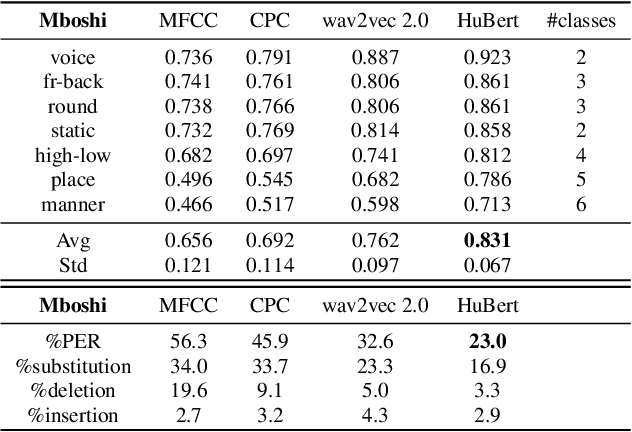
In this work, we analyzed and compared speech representations extracted from different frozen self-supervised learning (SSL) speech pre-trained models on their ability to capture articulatory features (AF) information and their subsequent prediction of phone recognition performance for within and across language scenarios. Specifically, we compared CPC, wav2vec 2.0, and HuBert. First, frame-level AF probing tasks were implemented. Subsequently, phone-level end-to-end ASR systems for phoneme recognition tasks were implemented, and the performance on the frame-level AF probing task and the phone accuracy were correlated. Compared to the conventional speech representation MFCC, all SSL pre-trained speech representations captured more AF information, and achieved better phoneme recognition performance within and across languages, with HuBert performing best. The frame-level AF probing task is a good predictor of phoneme recognition performance, showing the importance of capturing AF information in the speech representations. Compared with MFCC, in the within-language scenario, the performance of these SSL speech pre-trained models on AF probing tasks achieved a maximum relative increase of 34.4%, and it resulted in the lowest PER of 10.2%. In the cross-language scenario, the maximum relative increase of 26.7% also resulted in the lowest PER of 23.0%.
Injecting Text in Self-Supervised Speech Pretraining
Aug 27, 2021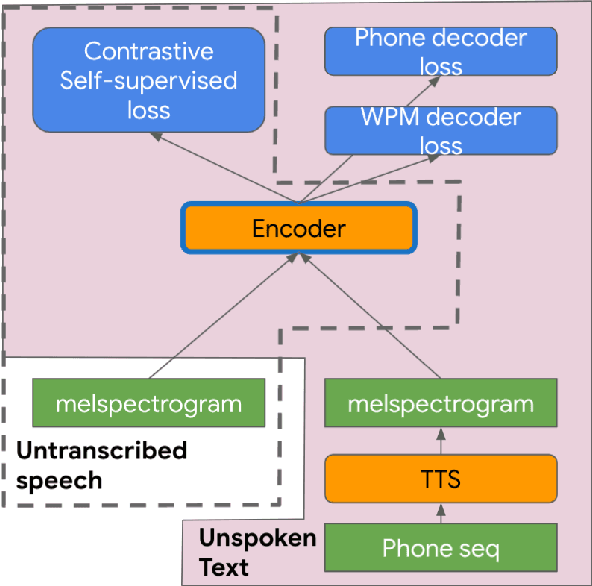

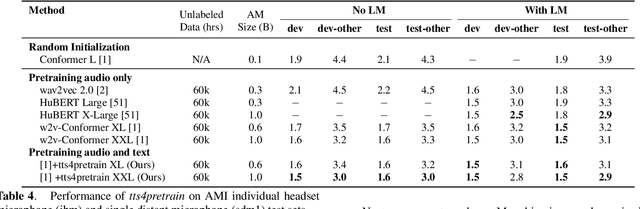
Self-supervised pretraining for Automated Speech Recognition (ASR) has shown varied degrees of success. In this paper, we propose to jointly learn representations during pretraining from two different modalities: speech and text. The proposed method, tts4pretrain complements the power of contrastive learning in self-supervision with linguistic/lexical representations derived from synthesized speech, effectively learning from untranscribed speech and unspoken text. Lexical learning in the speech encoder is enforced through an additional sequence loss term that is coupled with contrastive loss during pretraining. We demonstrate that this novel pretraining method yields Word Error Rate (WER) reductions of 10% relative on the well-benchmarked, Librispeech task over a state-of-the-art baseline pretrained with wav2vec2.0 only. The proposed method also serves as an effective strategy to compensate for the lack of transcribed speech, effectively matching the performance of 5000 hours of transcribed speech with just 100 hours of transcribed speech on the AMI meeting transcription task. Finally, we demonstrate WER reductions of up to 15% on an in-house Voice Search task over traditional pretraining. Incorporating text into encoder pretraining is complimentary to rescoring with a larger or in-domain language model, resulting in additional 6% relative reduction in WER.
Exploring Machine Speech Chain for Domain Adaptation and Few-Shot Speaker Adaptation
Apr 08, 2021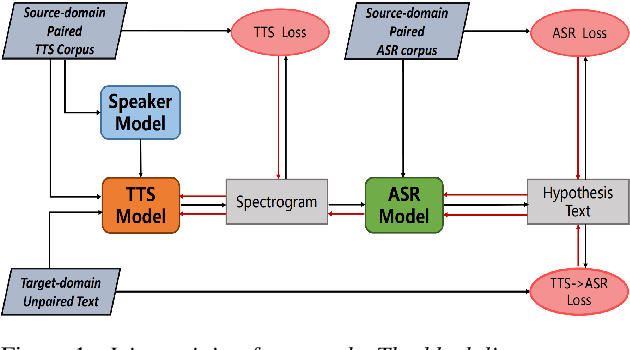
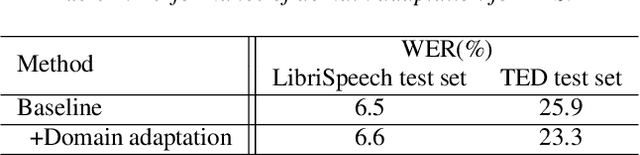
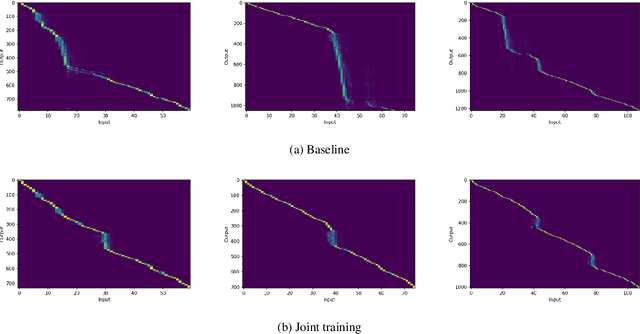
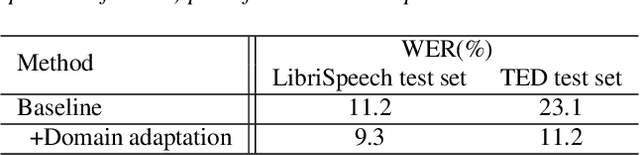
Machine Speech Chain, which integrates both end-to-end (E2E) automatic speech recognition (ASR) and text-to-speech (TTS) into one circle for joint training, has been proven to be effective in data augmentation by leveraging large amounts of unpaired data. In this paper, we explore the TTS->ASR pipeline in speech chain to do domain adaptation for both neural TTS and E2E ASR models, with only text data from target domain. We conduct experiments by adapting from audiobook domain (LibriSpeech) to presentation domain (TED-LIUM), there is a relative word error rate (WER) reduction of 10% for the E2E ASR model on the TED-LIUM test set, and a relative WER reduction of 51.5% in synthetic speech generated by neural TTS in the presentation domain. Further, we apply few-shot speaker adaptation for the E2E ASR by using a few utterances from target speakers in an unsupervised way, results in additional gains.
ESPnet-ST IWSLT 2021 Offline Speech Translation System
Jul 06, 2021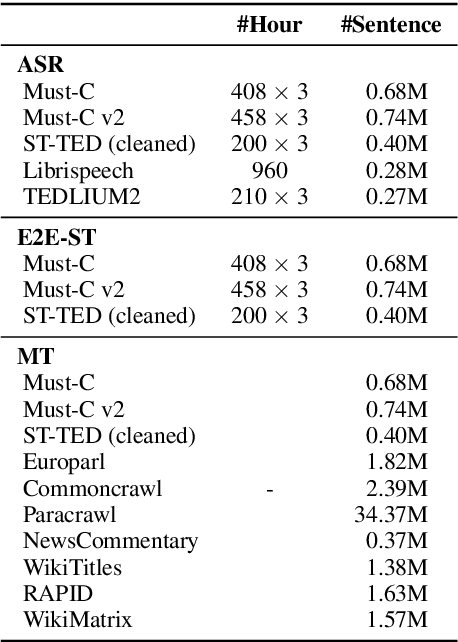
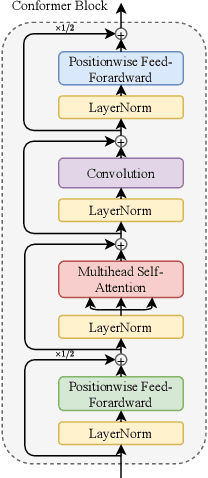
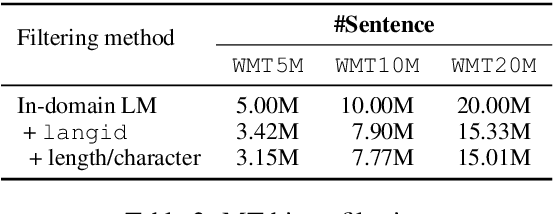
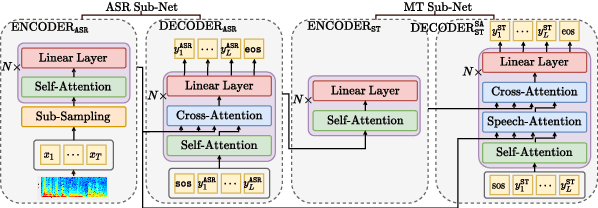
This paper describes the ESPnet-ST group's IWSLT 2021 submission in the offline speech translation track. This year we made various efforts on training data, architecture, and audio segmentation. On the data side, we investigated sequence-level knowledge distillation (SeqKD) for end-to-end (E2E) speech translation. Specifically, we used multi-referenced SeqKD from multiple teachers trained on different amounts of bitext. On the architecture side, we adopted the Conformer encoder and the Multi-Decoder architecture, which equips dedicated decoders for speech recognition and translation tasks in a unified encoder-decoder model and enables search in both source and target language spaces during inference. We also significantly improved audio segmentation by using the pyannote.audio toolkit and merging multiple short segments for long context modeling. Experimental evaluations showed that each of them contributed to large improvements in translation performance. Our best E2E system combined all the above techniques with model ensembling and achieved 31.4 BLEU on the 2-ref of tst2021 and 21.2 BLEU and 19.3 BLEU on the two single references of tst2021.
Improving a neural network model by explanation-guided training for glioma classification based on MRI data
Jul 05, 2021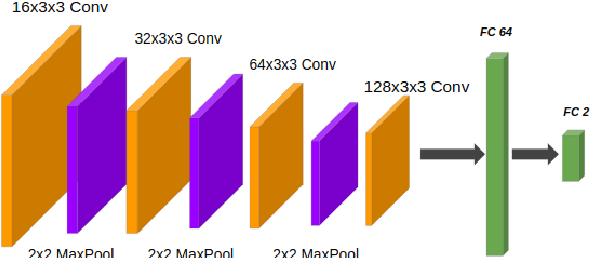
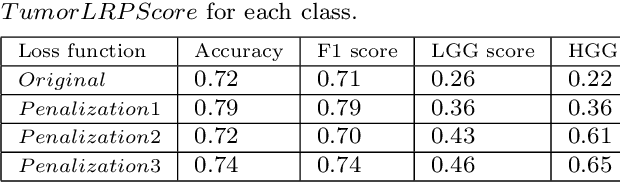
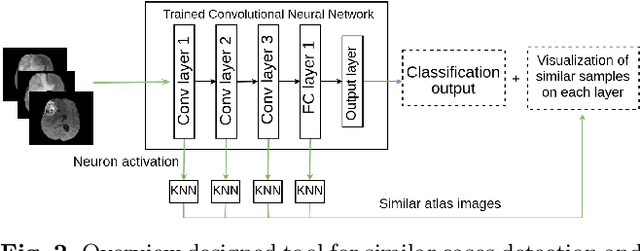
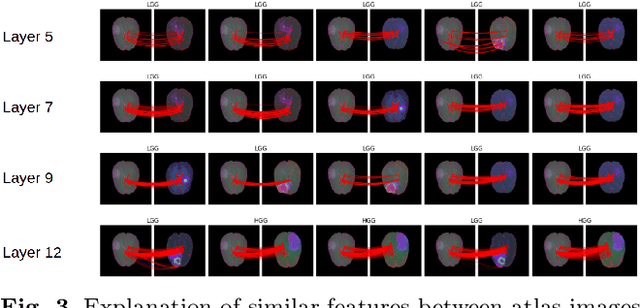
In recent years, artificial intelligence (AI) systems have come to the forefront. These systems, mostly based on Deep learning (DL), achieve excellent results in areas such as image processing, natural language processing, or speech recognition. Despite the statistically high accuracy of deep learning models, their output is often a decision of "black box". Thus, Interpretability methods have become a popular way to gain insight into the decision-making process of deep learning models. Explanation of a deep learning model is desirable in the medical domain since the experts have to justify their judgments to the patient. In this work, we proposed a method for explanation-guided training that uses a Layer-wise relevance propagation (LRP) technique to force the model to focus only on the relevant part of the image. We experimentally verified our method on a convolutional neural network (CNN) model for low-grade and high-grade glioma classification problems. Our experiments show promising results in a way to use interpretation techniques in the model training process.
Graph Neural Networks: Methods, Applications, and Opportunities
Aug 24, 2021
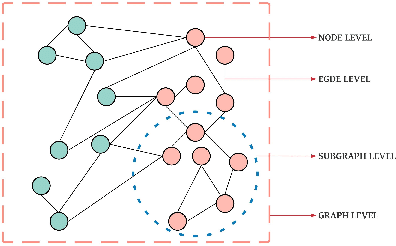
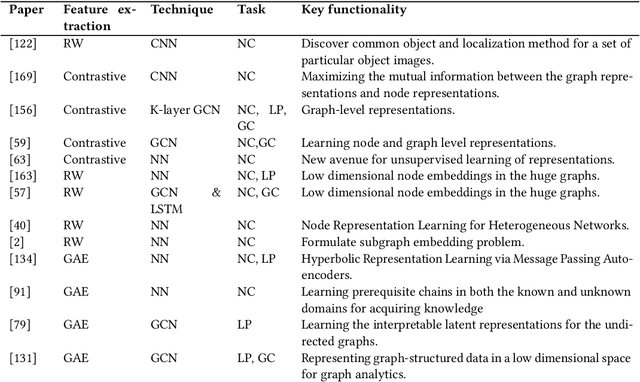
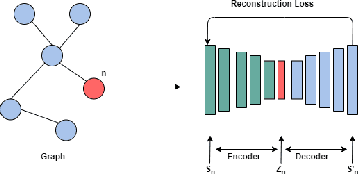
In the last decade or so, we have witnessed deep learning reinvigorating the machine learning field. It has solved many problems in the domains of computer vision, speech recognition, natural language processing, and various other tasks with state-of-the-art performance. The data is generally represented in the Euclidean space in these domains. Various other domains conform to non-Euclidean space, for which graph is an ideal representation. Graphs are suitable for representing the dependencies and interrelationships between various entities. Traditionally, handcrafted features for graphs are incapable of providing the necessary inference for various tasks from this complex data representation. Recently, there is an emergence of employing various advances in deep learning to graph data-based tasks. This article provides a comprehensive survey of graph neural networks (GNNs) in each learning setting: supervised, unsupervised, semi-supervised, and self-supervised learning. Taxonomy of each graph based learning setting is provided with logical divisions of methods falling in the given learning setting. The approaches for each learning task are analyzed from both theoretical as well as empirical standpoints. Further, we provide general architecture guidelines for building GNNs. Various applications and benchmark datasets are also provided, along with open challenges still plaguing the general applicability of GNNs.
Auxiliary Sequence Labeling Tasks for Disfluency Detection
Oct 24, 2020
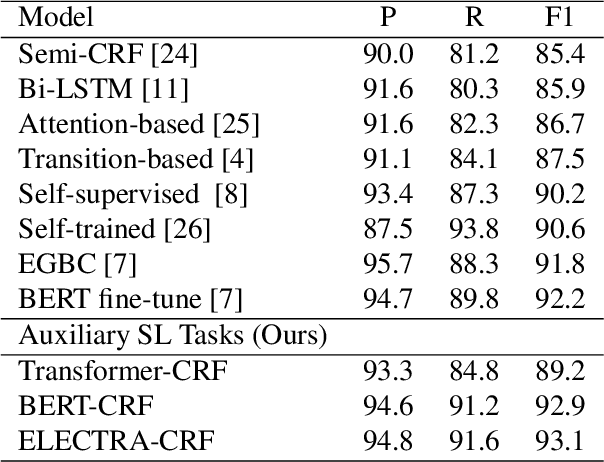
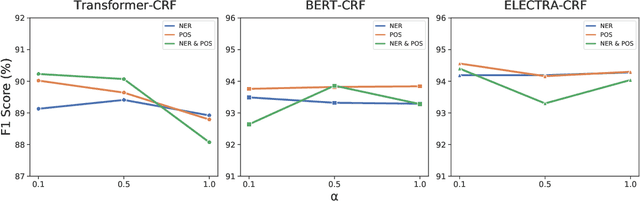
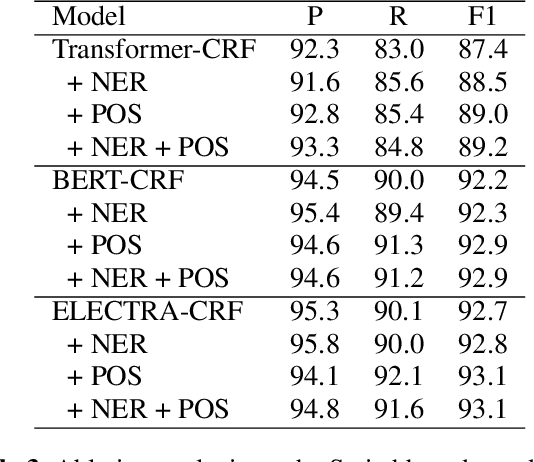
Detecting disfluencies in spontaneous speech is an important preprocessing step in natural language processing and speech recognition applications. In this paper, we propose a method utilizing named entity recognition (NER) and part-of-speech (POS) as auxiliary sequence labeling (SL) tasks for disfluency detection. First, we show that training a disfluency detection model with auxiliary SL tasks can improve its F-score in disfluency detection. Then, we analyze which auxiliary SL tasks are influential depending on baseline models. Experimental results on the widely used English Switchboard dataset show that our method outperforms the previous state-of-the-art in disfluency detection.
Lightweight Adapter Tuning for Multilingual Speech Translation
Jun 02, 2021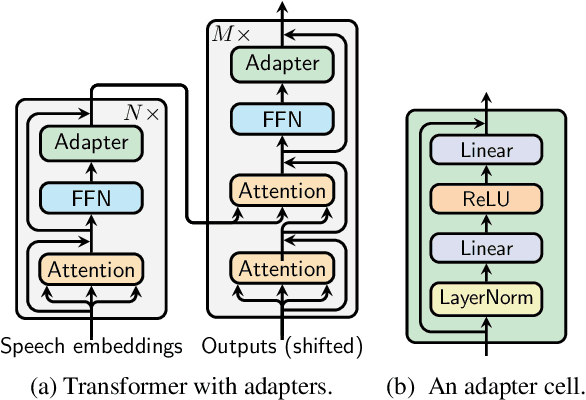
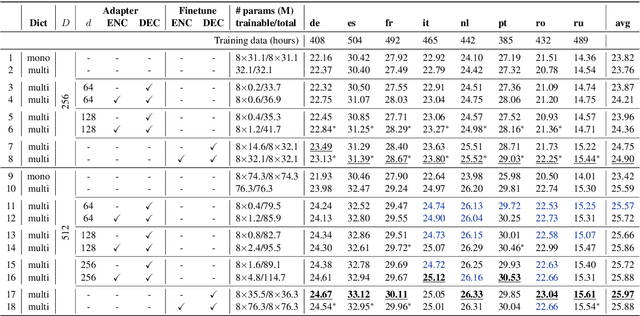
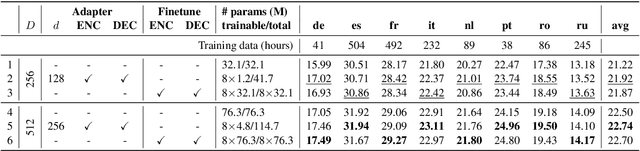
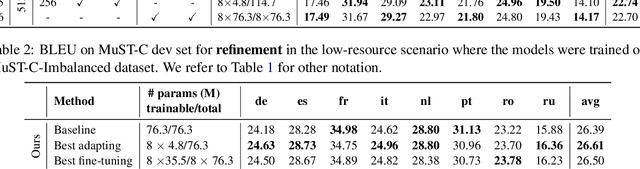
Adapter modules were recently introduced as an efficient alternative to fine-tuning in NLP. Adapter tuning consists in freezing pretrained parameters of a model and injecting lightweight modules between layers, resulting in the addition of only a small number of task-specific trainable parameters. While adapter tuning was investigated for multilingual neural machine translation, this paper proposes a comprehensive analysis of adapters for multilingual speech translation (ST). Starting from different pre-trained models (a multilingual ST trained on parallel data or a multilingual BART (mBART) trained on non-parallel multilingual data), we show that adapters can be used to: (a) efficiently specialize ST to specific language pairs with a low extra cost in terms of parameters, and (b) transfer from an automatic speech recognition (ASR) task and an mBART pre-trained model to a multilingual ST task. Experiments show that adapter tuning offer competitive results to full fine-tuning, while being much more parameter-efficient.