 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Fine-grained Generalization Analysis of Structured Output Prediction
May 31, 2021
In machine learning we often encounter structured output prediction problems (SOPPs), i.e. problems where the output space admits a rich internal structure. Application domains where SOPPs naturally occur include natural language processing, speech recognition, and computer vision. Typical SOPPs have an extremely large label set, which grows exponentially as a function of the size of the output. Existing generalization analysis implies generalization bounds with at least a square-root dependency on the cardinality $d$ of the label set, which can be vacuous in practice. In this paper, we significantly improve the state of the art by developing novel high-probability bounds with a logarithmic dependency on $d$. Moreover, we leverage the lens of algorithmic stability to develop generalization bounds in expectation without any dependency on $d$. Our results therefore build a solid theoretical foundation for learning in large-scale SOPPs. Furthermore, we extend our results to learning with weakly dependent data.
Efficient Conformer with Prob-Sparse Attention Mechanism for End-to-EndSpeech Recognition
Jun 17, 2021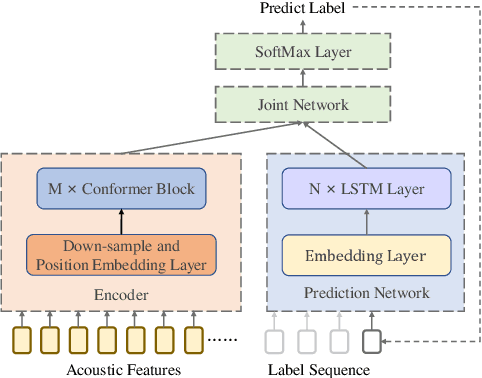
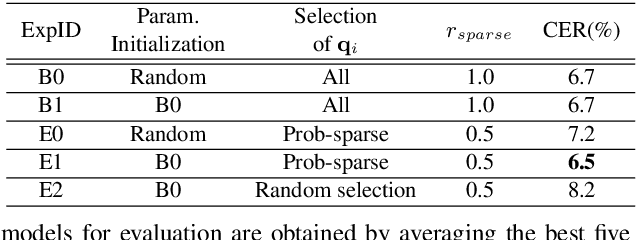
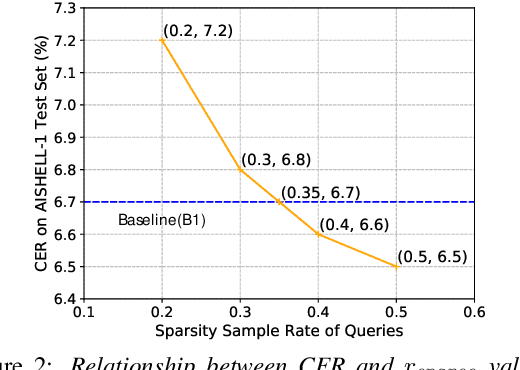
End-to-end models are favored in automatic speech recognition (ASR) because of their simplified system structure and superior performance. Among these models, Transformer and Conformer have achieved state-of-the-art recognition accuracy in which self-attention plays a vital role in capturing important global information. However, the time and memory complexity of self-attention increases squarely with the length of the sentence. In this paper, a prob-sparse self-attention mechanism is introduced into Conformer to sparse the computing process of self-attention in order to accelerate inference speed and reduce space consumption. Specifically, we adopt a Kullback-Leibler divergence based sparsity measurement for each query to decide whether we compute the attention function on this query. By using the prob-sparse attention mechanism, we achieve impressively 8% to 45% inference speed-up and 15% to 45% memory usage reduction of the self-attention module of Conformer Transducer while maintaining the same level of error rate.
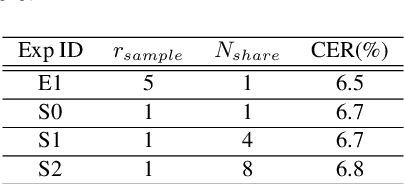
Layer Pruning on Demand with Intermediate CTC
Jun 17, 2021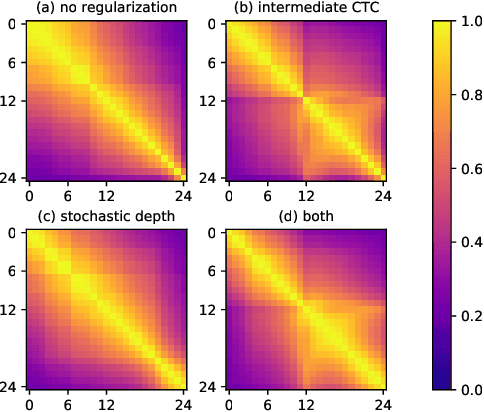
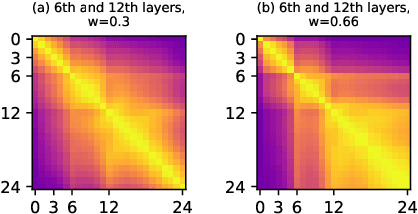
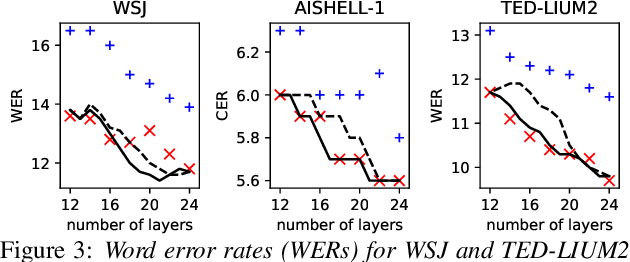
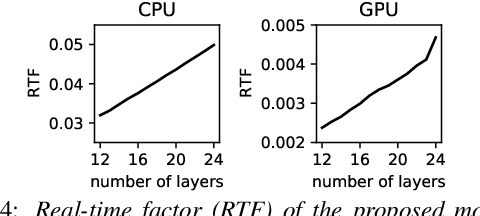
Deploying an end-to-end automatic speech recognition (ASR) model on mobile/embedded devices is a challenging task, since the device computational power and energy consumption requirements are dynamically changed in practice. To overcome the issue, we present a training and pruning method for ASR based on the connectionist temporal classification (CTC) which allows reduction of model depth at run-time without any extra fine-tuning. To achieve the goal, we adopt two regularization methods, intermediate CTC and stochastic depth, to train a model whose performance does not degrade much after pruning. We present an in-depth analysis of layer behaviors using singular vector canonical correlation analysis (SVCCA), and efficient strategies for finding layers which are safe to prune. Using the proposed method, we show that a Transformer-CTC model can be pruned in various depth on demand, improving real-time factor from 0.005 to 0.002 on GPU, while each pruned sub-model maintains the accuracy of individually trained model of the same depth.
RyanSpeech: A Corpus for Conversational Text-to-Speech Synthesis
Jun 15, 2021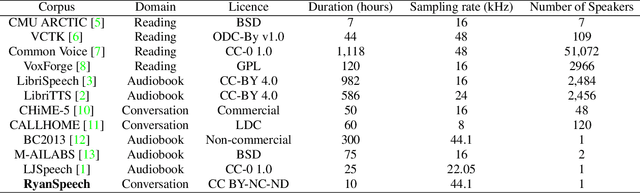
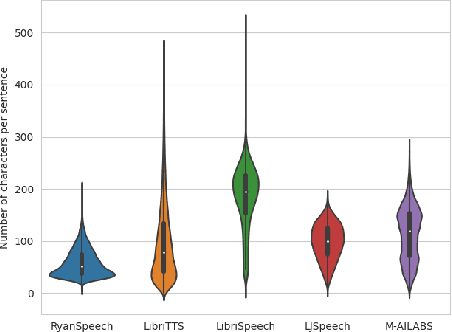
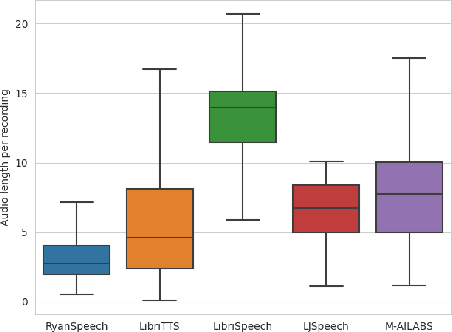
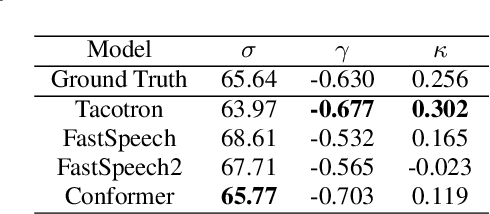
This paper introduces RyanSpeech, a new speech corpus for research on automated text-to-speech (TTS) systems. Publicly available TTS corpora are often noisy, recorded with multiple speakers, or lack quality male speech data. In order to meet the need for a high quality, publicly available male speech corpus within the field of speech recognition, we have designed and created RyanSpeech which contains textual materials from real-world conversational settings. These materials contain over 10 hours of a professional male voice actor's speech recorded at 44.1 kHz. This corpus's design and pipeline make RyanSpeech ideal for developing TTS systems in real-world applications. To provide a baseline for future research, protocols, and benchmarks, we trained 4 state-of-the-art speech models and a vocoder on RyanSpeech. The results show 3.36 in mean opinion scores (MOS) in our best model. We have made both the corpus and trained models for public use.
L3Cube-MahaNLP: Marathi Natural Language Processing Datasets, Models, and Library
May 31, 2022Despite being the third most popular language in India, the Marathi language lacks useful NLP resources. Moreover, popular NLP libraries do not have support for the Marathi language. With L3Cube-MahaNLP, we aim to build resources and a library for Marathi natural language processing. We present datasets and transformer models for supervised tasks like sentiment analysis, named entity recognition, and hate speech detection. We have also published a monolingual Marathi corpus for unsupervised language modeling tasks. Overall we present MahaCorpus, MahaSent, MahaNER, and MahaHate datasets and their corresponding MahaBERT models fine-tuned on these datasets. We aim to move ahead of benchmark datasets and prepare useful resources for Marathi. The resources are available at https://github.com/l3cube-pune/MarathiNLP.
Radically Old Way of Computing Spectra: Applications in End-to-End ASR
Apr 02, 2021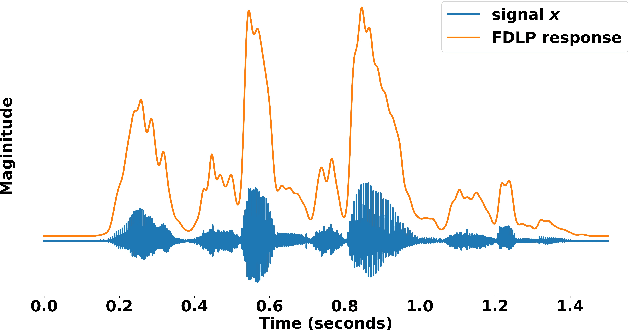

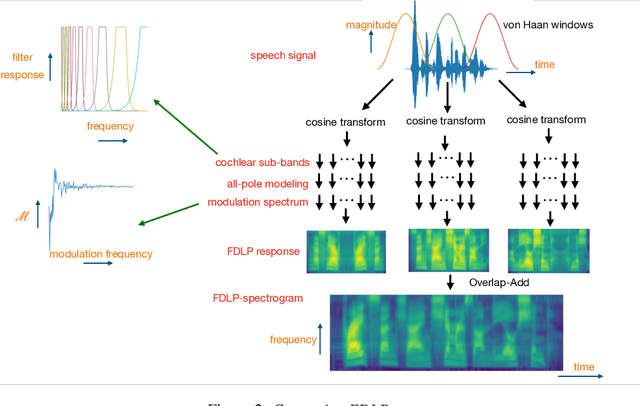

We propose a technique to compute spectrograms using Frequency Domain Linear Prediction (FDLP) that uses all-pole models to fit the squared Hilbert envelope of speech in different frequency sub-bands. The spectrogram of a complete speech utterance is computed by overlap-add of contiguous all-pole model responses. A long context window of 1.5 seconds allows us to capture the low frequency temporal modulations of speech in the spectrogram. For an end-to-end automatic speech recognition task, the FDLP spectrogram performs on par with the standard mel spectrogram features for clean read speech training and test data. For more realistic speech data with train-test domain mismatches or reverberations, FDLP spectrogram shows up to 25% and 22% relative WER improvements over mel spectrogram respectively.
Low Resource German ASR with Untranscribed Data Spoken by Non-native Children -- INTERSPEECH 2021 Shared Task SPAPL System
Jun 18, 2021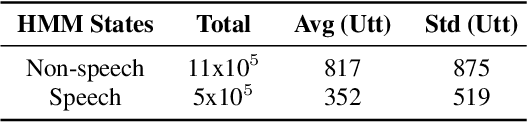
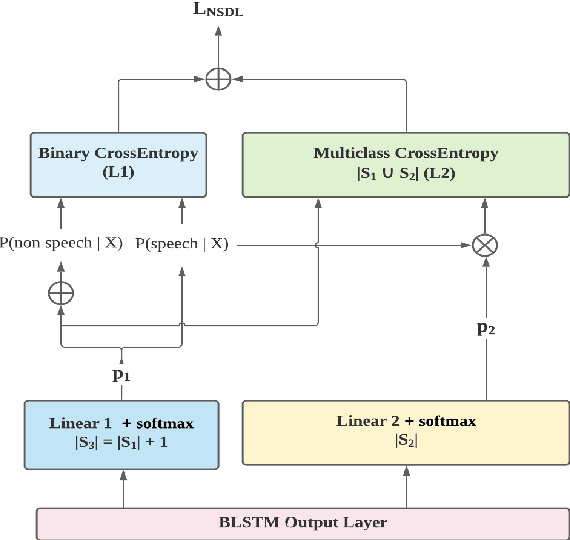
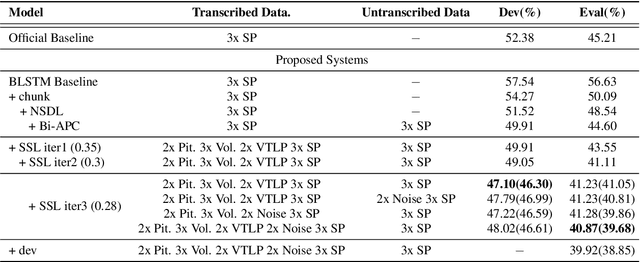
This paper describes the SPAPL system for the INTERSPEECH 2021 Challenge: Shared Task on Automatic Speech Recognition for Non-Native Children's Speech in German. ~ 5 hours of transcribed data and ~ 60 hours of untranscribed data are provided to develop a German ASR system for children. For the training of the transcribed data, we propose a non-speech state discriminative loss (NSDL) to mitigate the influence of long-duration non-speech segments within speech utterances. In order to explore the use of the untranscribed data, various approaches are implemented and combined together to incrementally improve the system performance. First, bidirectional autoregressive predictive coding (Bi-APC) is used to learn initial parameters for acoustic modelling using the provided untranscribed data. Second, incremental semi-supervised learning is further used to iteratively generate pseudo-transcribed data. Third, different data augmentation schemes are used at different training stages to increase the variability and size of the training data. Finally, a recurrent neural network language model (RNNLM) is used for rescoring. Our system achieves a word error rate (WER) of 39.68% on the evaluation data, an approximately 12% relative improvement over the official baseline (45.21%).
Dynamic Gradient Aggregation for Federated Domain Adaptation
Jun 14, 2021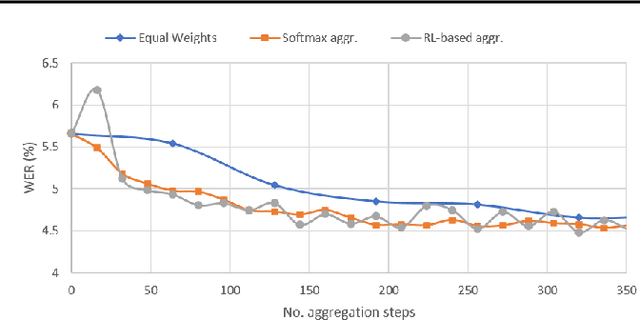
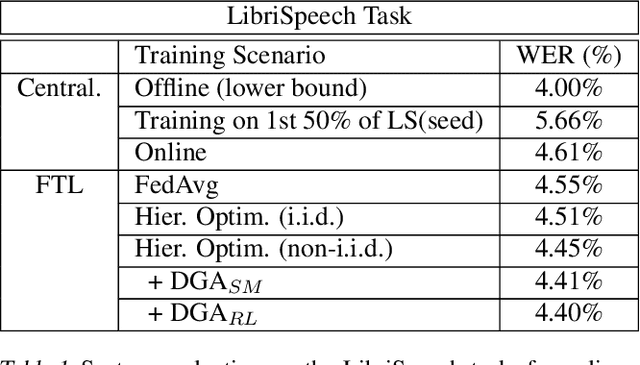
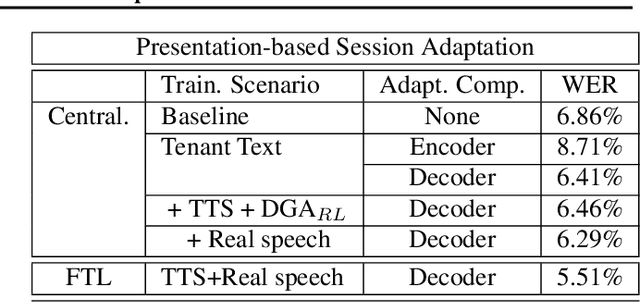
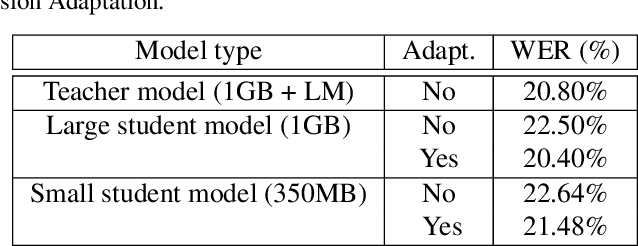
In this paper, a new learning algorithm for Federated Learning (FL) is introduced. The proposed scheme is based on a weighted gradient aggregation using two-step optimization to offer a flexible training pipeline. Herein, two different flavors of the aggregation method are presented, leading to an order of magnitude improvement in convergence speed compared to other distributed or FL training algorithms like BMUF and FedAvg. Further, the aggregation algorithm acts as a regularizer of the gradient quality. We investigate the effect of our FL algorithm in supervised and unsupervised Speech Recognition (SR) scenarios. The experimental validation is performed based on three tasks: first, the LibriSpeech task showing a speed-up of 7x and 6% word error rate reduction (WERR) compared to the baseline results. The second task is based on session adaptation providing 20% WERR over a powerful LAS model. Finally, our unsupervised pipeline is applied to the conversational SR task. The proposed FL system outperforms the baseline systems in both convergence speed and overall model performance.
Keyword Transformer: A Self-Attention Model for Keyword Spotting
Apr 01, 2021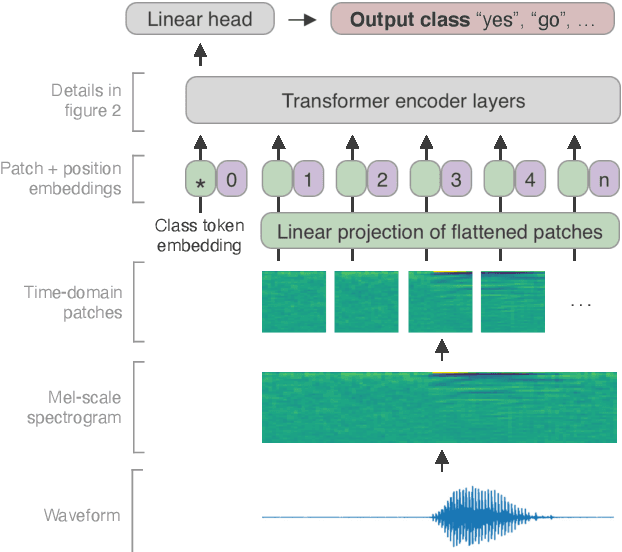

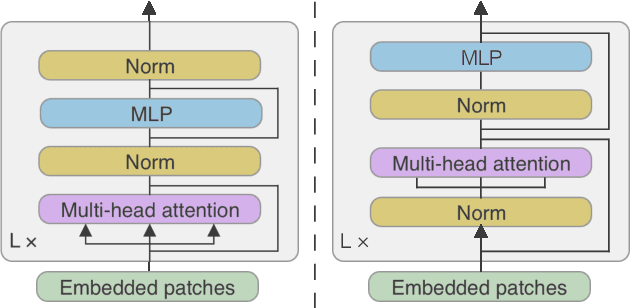

The Transformer architecture has been successful across many domains, including natural language processing, computer vision and speech recognition. In keyword spotting, self-attention has primarily been used on top of convolutional or recurrent encoders. We investigate a range of ways to adapt the Transformer architecture to keyword spotting and introduce the Keyword Transformer (KWT), a fully self-attentional architecture that exceeds state-of-the-art performance across multiple tasks without any pre-training or additional data. Surprisingly, this simple architecture outperforms more complex models that mix convolutional, recurrent and attentive layers. KWT can be used as a drop-in replacement for these models, setting two new benchmark records on the Google Speech Commands dataset with 98.6% and 97.7% accuracy on the 12 and 35-command tasks respectively.
Tiny Transducer: A Highly-efficient Speech Recognition Model on Edge Devices
Feb 07, 2021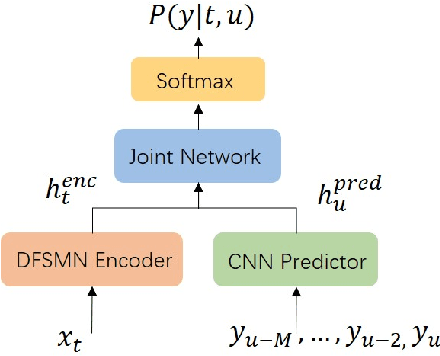

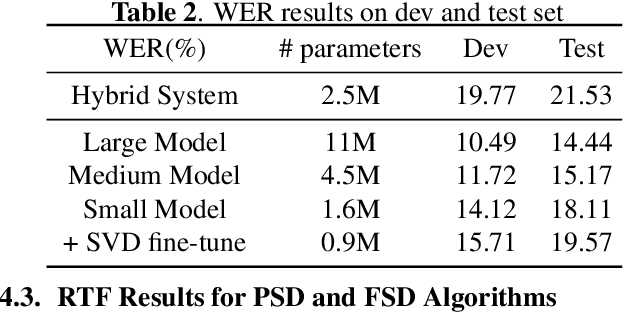
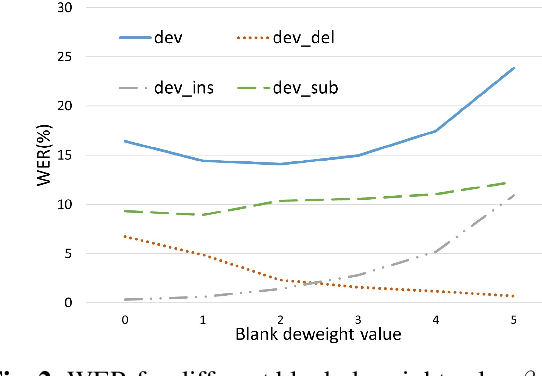
This paper proposes an extremely lightweight phone-based transducer model with a tiny decoding graph on edge devices. First, a phone synchronous decoding (PSD) algorithm based on blank label skipping is first used to speed up the transducer decoding process. Then, to decrease the deletion errors introduced by the high blank score, a blank label deweighting approach is proposed. To reduce parameters and computation, deep feedforward sequential memory network (DFSMN) layers are used in the transducer encoder, and a CNN-based stateless predictor is adopted. SVD technology compresses the model further. WFST-based decoding graph takes the context-independent (CI) phone posteriors as input and allows us to flexibly bias user-specific information. Finally, with only 0.9M parameters after SVD, our system could give a relative 9.1% - 20.5% improvement compared with a bigger conventional hybrid system on edge devices.