 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Robust Classification using Hidden Markov Models and Mixtures of Normalizing Flows
Feb 15, 2021


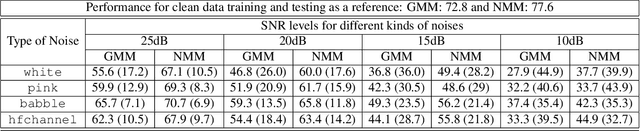
We test the robustness of a maximum-likelihood (ML) based classifier where sequential data as observation is corrupted by noise. The hypothesis is that a generative model, that combines the state transitions of a hidden Markov model (HMM) and the neural network based probability distributions for the hidden states of the HMM, can provide a robust classification performance. The combined model is called normalizing-flow mixture model based HMM (NMM-HMM). It can be trained using a combination of expectation-maximization (EM) and backpropagation. We verify the improved robustness of NMM-HMM classifiers in an application to speech recognition.
Grammar Based Identification Of Speaker Role For Improving ATCO And Pilot ASR
Aug 27, 2021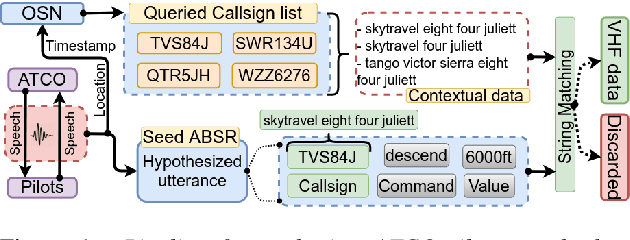



Assistant Based Speech Recognition (ABSR) for air traffic control is generally trained by pooling both Air Traffic Controller (ATCO) and pilot data. In practice, this is motivated by the fact that the proportion of pilot data is lesser compared to ATCO while their standard language of communication is similar. However, due to data imbalance of ATCO and pilot and their varying acoustic conditions, the ASR performance is usually significantly better for ATCOs than pilots. In this paper, we propose to (1) split the ATCO and pilot data using an automatic approach exploiting ASR transcripts, and (2) consider ATCO and pilot ASR as two separate tasks for Acoustic Model (AM) training. For speaker role classification of ATCO and pilot data, a hypothesized ASR transcript is generated with a seed model, subsequently used to classify the speaker role based on the knowledge extracted from grammar defined by International Civil Aviation Organization (ICAO). This approach provides an average speaker role identification accuracy of 83% for ATCO and pilot. Finally, we show that training AMs separately for each task, or using a multitask approach is well suited for this data compared to AM trained by pooling all data.
Improving Vietnamese Named Entity Recognition from Speech Using Word Capitalization and Punctuation Recovery Models
Oct 01, 2020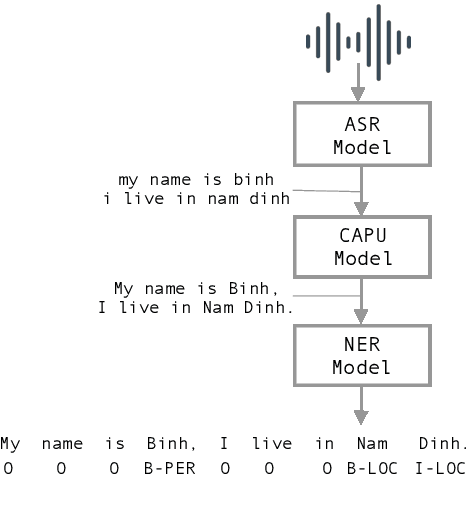

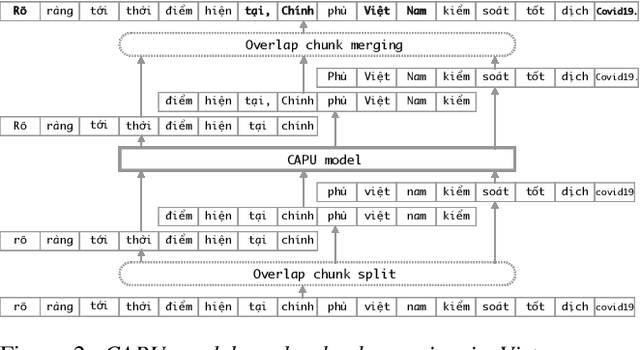
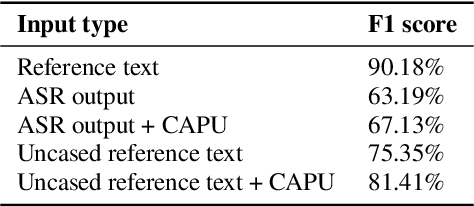
Studies on the Named Entity Recognition (NER) task have shown outstanding results that reach human parity on input texts with correct text formattings, such as with proper punctuation and capitalization. However, such conditions are not available in applications where the input is speech, because the text is generated from a speech recognition system (ASR), and that the system does not consider the text formatting. In this paper, we (1) presented the first Vietnamese speech dataset for NER task, and (2) the first pre-trained public large-scale monolingual language model for Vietnamese that achieved the new state-of-the-art for the Vietnamese NER task by 1.3% absolute F1 score comparing to the latest study. And finally, (3) we proposed a new pipeline for NER task from speech that overcomes the text formatting problem by introducing a text capitalization and punctuation recovery model (CaPu) into the pipeline. The model takes input text from an ASR system and performs two tasks at the same time, producing proper text formatting that helps to improve NER performance. Experimental results indicated that the CaPu model helps to improve by nearly 4% of F1-score.
StutterNet: Stuttering Detection Using Time Delay Neural Network
May 12, 2021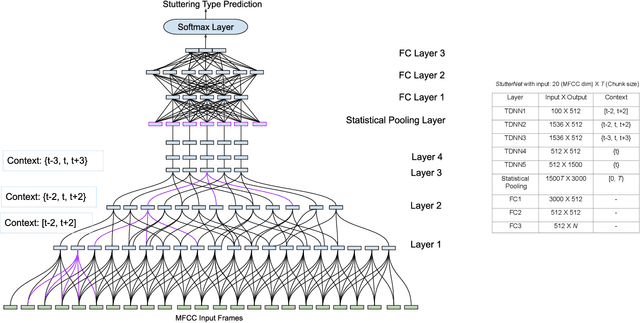
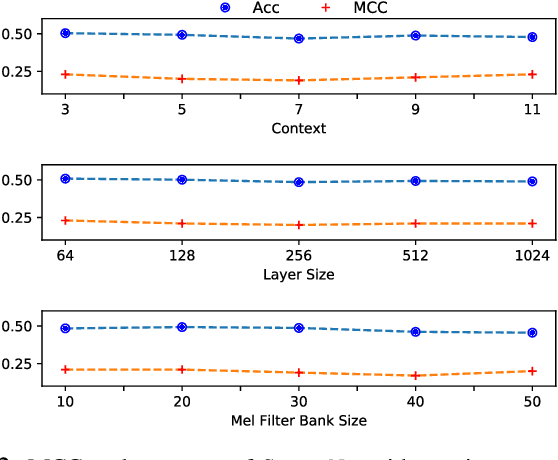
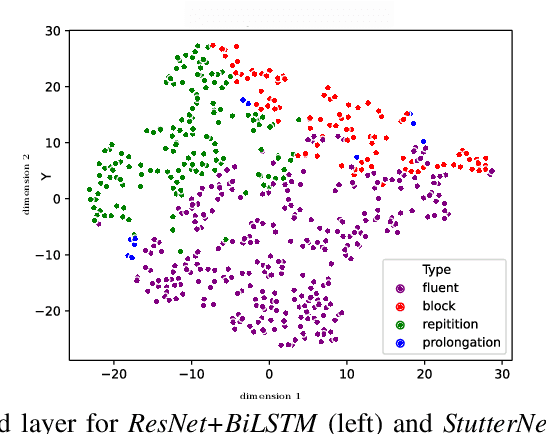

This paper introduce StutterNet, a novel deep learning based stuttering detection capable of detecting and identifying various types of disfluencies. Most of the existing work in this domain uses automatic speech recognition (ASR) combined with language models for stuttering detection. Compared to the existing work, which depends on the ASR module, our method relies solely on the acoustic signal. We use a time-delay neural network (TDNN) suitable for capturing contextual aspects of the disfluent utterances. We evaluate our system on the UCLASS stuttering dataset consisting of more than 100 speakers. Our method achieves promising results and outperforms the state-of-the-art residual neural network based method. The number of trainable parameters of the proposed method is also substantially less due to the parameter sharing scheme of TDNN.
Semantic sentence similarity: size does not always matter
Jun 16, 2021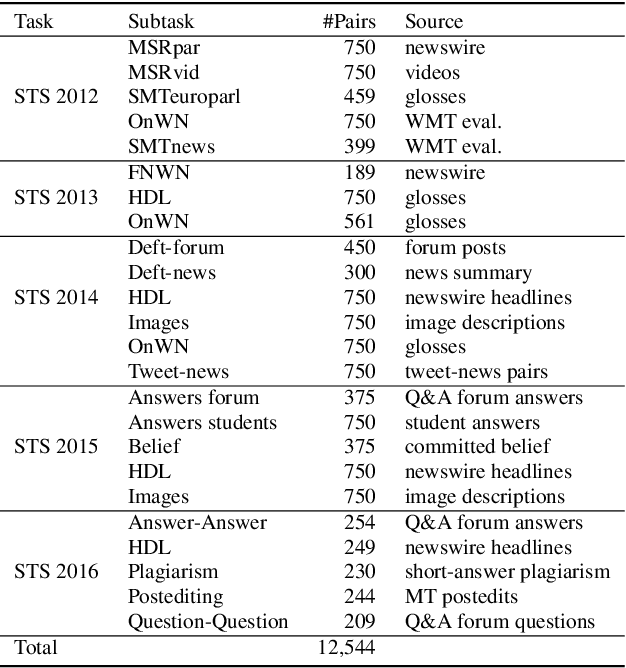
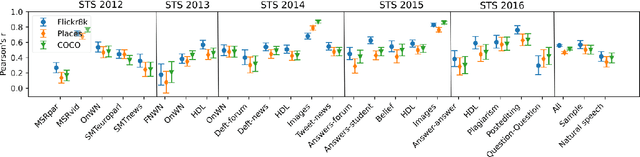
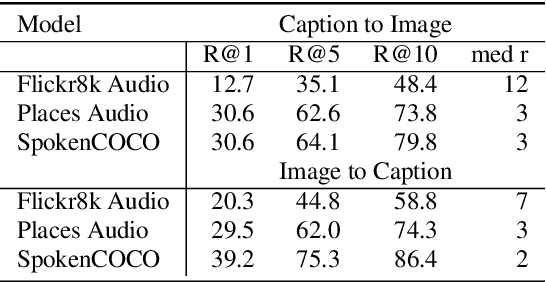
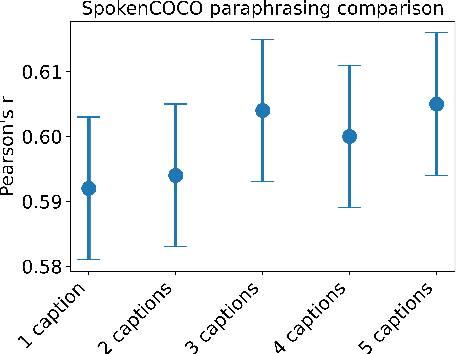
This study addresses the question whether visually grounded speech recognition (VGS) models learn to capture sentence semantics without access to any prior linguistic knowledge. We produce synthetic and natural spoken versions of a well known semantic textual similarity database and show that our VGS model produces embeddings that correlate well with human semantic similarity judgements. Our results show that a model trained on a small image-caption database outperforms two models trained on much larger databases, indicating that database size is not all that matters. We also investigate the importance of having multiple captions per image and find that this is indeed helpful even if the total number of images is lower, suggesting that paraphrasing is a valuable learning signal. While the general trend in the field is to create ever larger datasets to train models on, our findings indicate other characteristics of the database can just as important important.
Integrating Recurrence Dynamics for Speech Emotion Recognition
Nov 09, 2018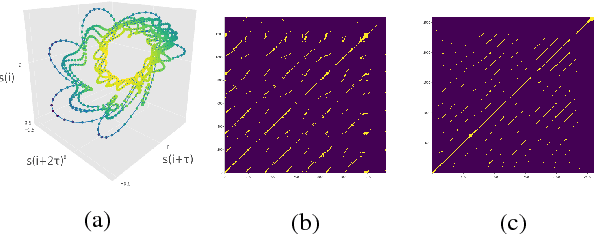

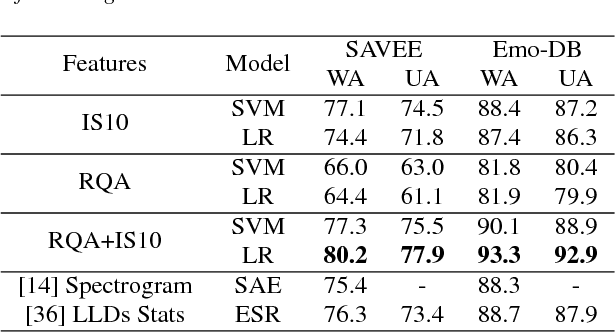
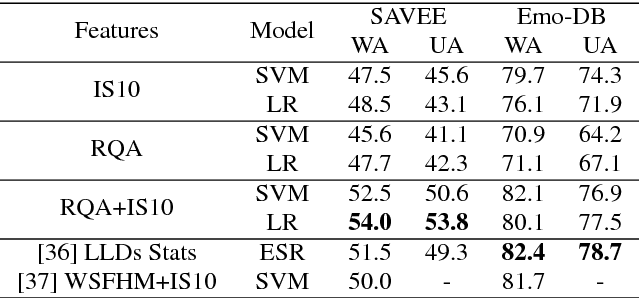
We investigate the performance of features that can capture nonlinear recurrence dynamics embedded in the speech signal for the task of Speech Emotion Recognition (SER). Reconstruction of the phase space of each speech frame and the computation of its respective Recurrence Plot (RP) reveals complex structures which can be measured by performing Recurrence Quantification Analysis (RQA). These measures are aggregated by using statistical functionals over segment and utterance periods. We report SER results for the proposed feature set on three databases using different classification methods. When fusing the proposed features with traditional feature sets, we show an improvement in unweighted accuracy of up to 5.7% and 10.7% on Speaker-Dependent (SD) and Speaker-Independent (SI) SER tasks, respectively, over the baseline. Following a segment-based approach we demonstrate state-of-the-art performance on IEMOCAP using a Bidirectional Recurrent Neural Network.
XY Neural Networks
Mar 31, 2021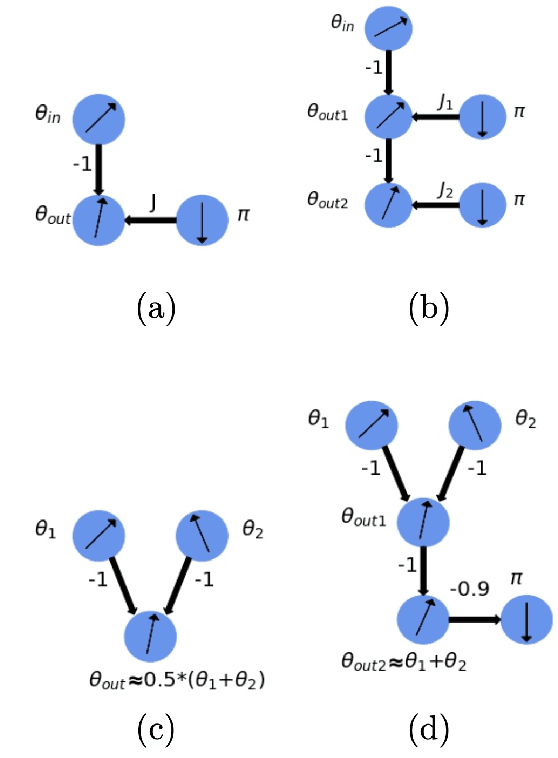
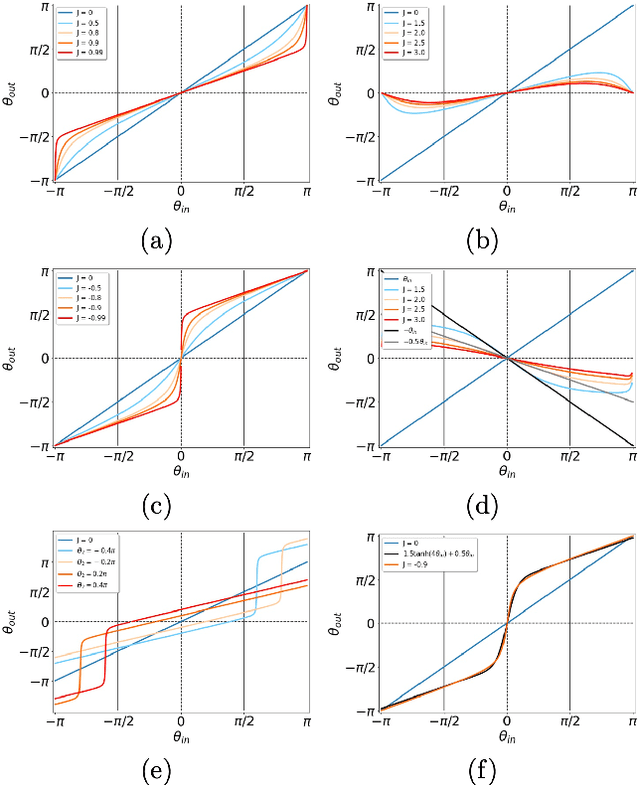
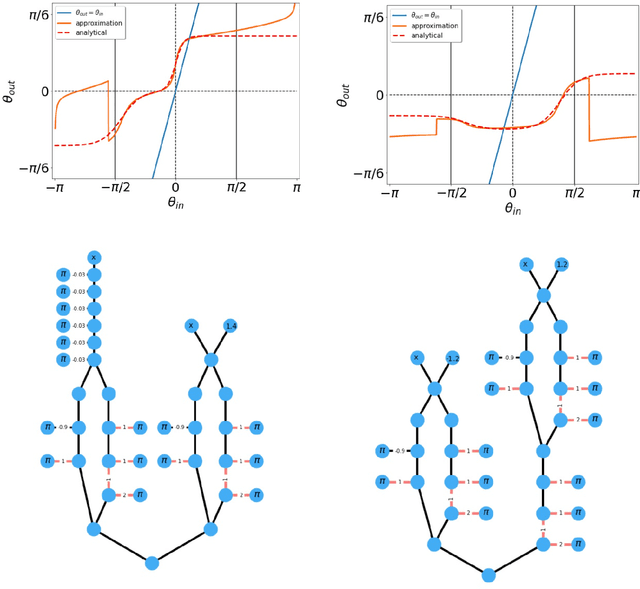
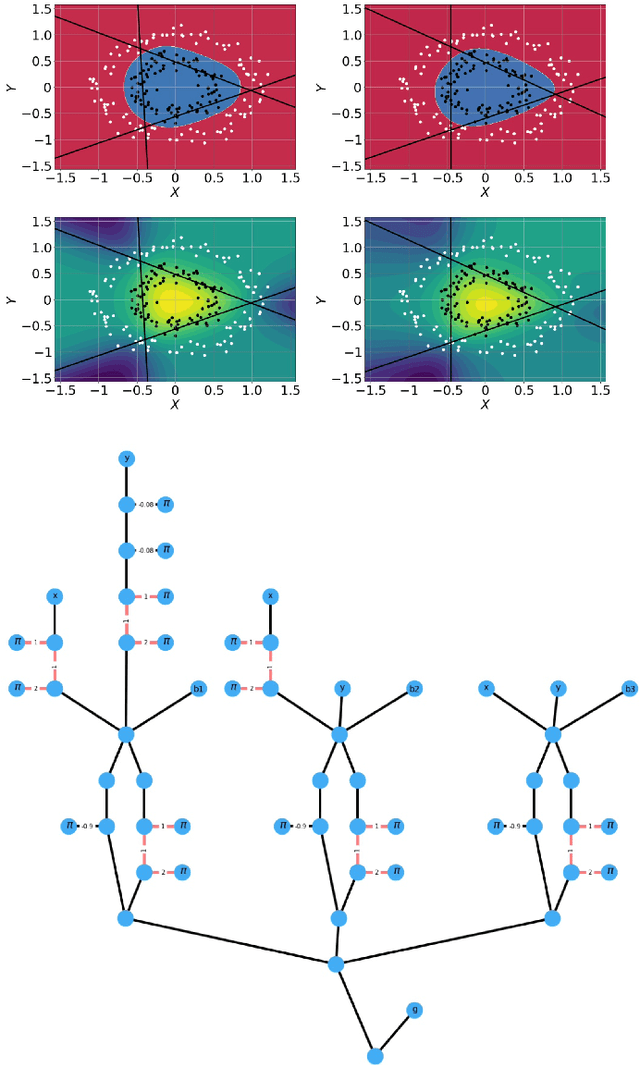
The classical XY model is a lattice model of statistical mechanics notable for its universality in the rich hierarchy of the optical, laser and condensed matter systems. We show how to build complex structures for machine learning based on the XY model's nonlinear blocks. The final target is to reproduce the deep learning architectures, which can perform complicated tasks usually attributed to such architectures: speech recognition, visual processing, or other complex classification types with high quality. We developed the robust and transparent approach for the construction of such models, which has universal applicability (i.e. does not strongly connect to any particular physical system), allows many possible extensions while at the same time preserving the simplicity of the methodology.
On the Relevance of Auditory-Based Gabor Features for Deep Learning in Automatic Speech Recognition
Feb 14, 2017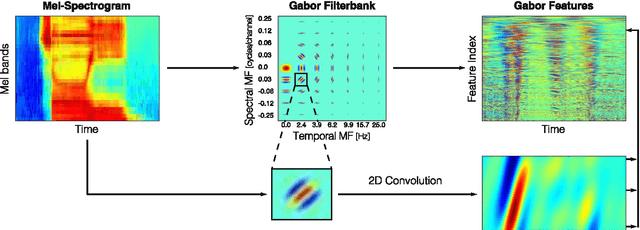
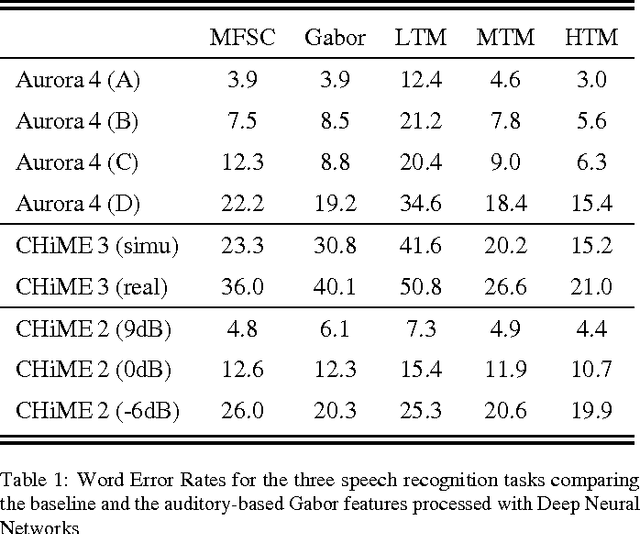
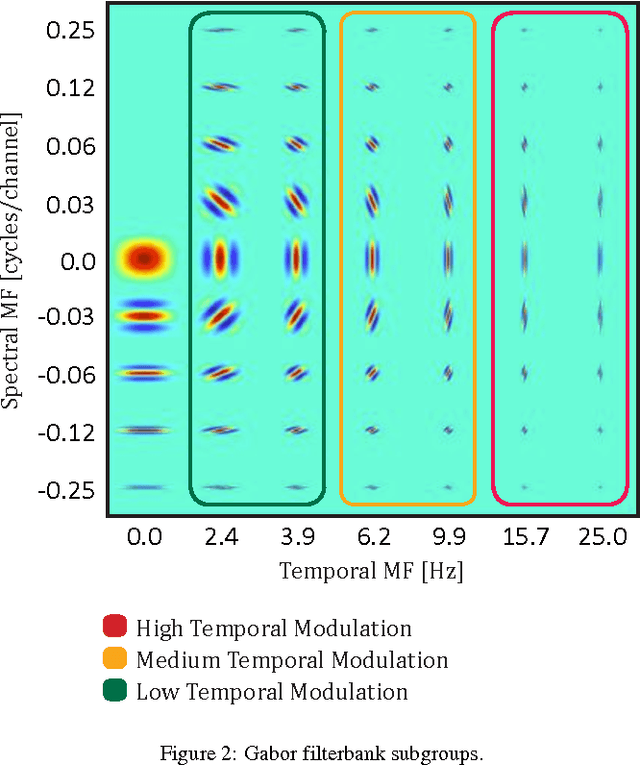

Previous studies support the idea of merging auditory-based Gabor features with deep learning architectures to achieve robust automatic speech recognition, however, the cause behind the gain of such combination is still unknown. We believe these representations provide the deep learning decoder with more discriminable cues. Our aim with this paper is to validate this hypothesis by performing experiments with three different recognition tasks (Aurora 4, CHiME 2 and CHiME 3) and assess the discriminability of the information encoded by Gabor filterbank features. Additionally, to identify the contribution of low, medium and high temporal modulation frequencies subsets of the Gabor filterbank were used as features (dubbed LTM, MTM and HTM respectively). With temporal modulation frequencies between 16 and 25 Hz, HTM consistently outperformed the remaining ones in every condition, highlighting the robustness of these representations against channel distortions, low signal-to-noise ratios and acoustically challenging real-life scenarios with relative improvements from 11 to 56% against a Mel-filterbank-DNN baseline. To explain the results, a measure of similarity between phoneme classes from DNN activations is proposed and linked to their acoustic properties. We find this measure to be consistent with the observed error rates and highlight specific differences on phoneme level to pinpoint the benefit of the proposed features.
PDAugment: Data Augmentation by Pitch and Duration Adjustments for Automatic Lyrics Transcription
Sep 17, 2021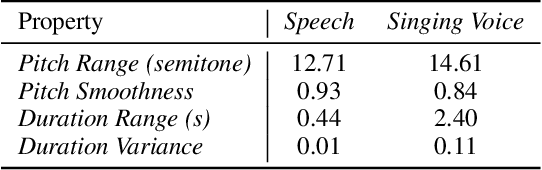
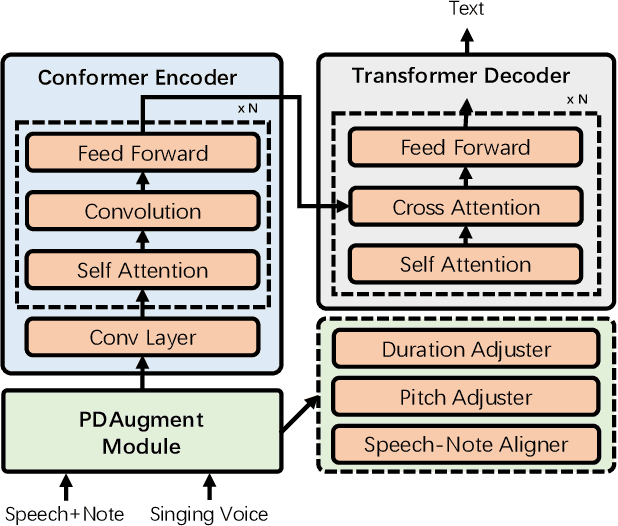
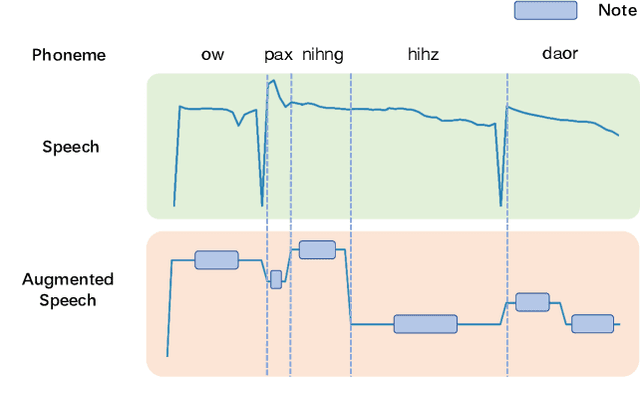

Automatic lyrics transcription (ALT), which can be regarded as automatic speech recognition (ASR) on singing voice, is an interesting and practical topic in academia and industry. ALT has not been well developed mainly due to the dearth of paired singing voice and lyrics datasets for model training. Considering that there is a large amount of ASR training data, a straightforward method is to leverage ASR data to enhance ALT training. However, the improvement is marginal when training the ALT system directly with ASR data, because of the gap between the singing voice and standard speech data which is rooted in music-specific acoustic characteristics in singing voice. In this paper, we propose PDAugment, a data augmentation method that adjusts pitch and duration of speech at syllable level under the guidance of music scores to help ALT training. Specifically, we adjust the pitch and duration of each syllable in natural speech to those of the corresponding note extracted from music scores, so as to narrow the gap between natural speech and singing voice. Experiments on DSing30 and Dali corpus show that the ALT system equipped with our PDAugment outperforms previous state-of-the-art systems by 5.9% and 18.1% WERs respectively, demonstrating the effectiveness of PDAugment for ALT.
Unsupervised Domain Adaptation Schemes for Building ASR in Low-resource Languages
Sep 16, 2021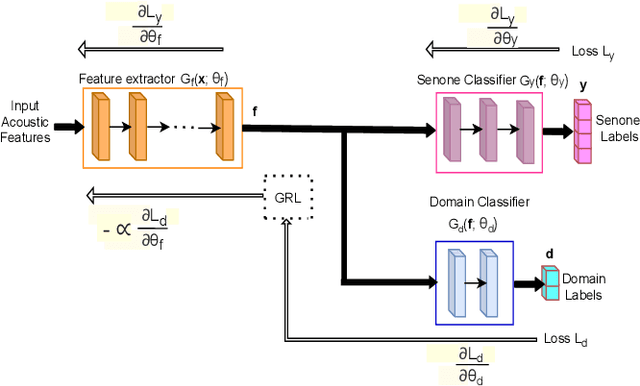
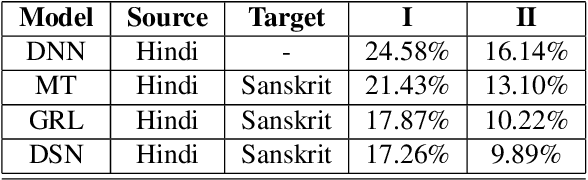
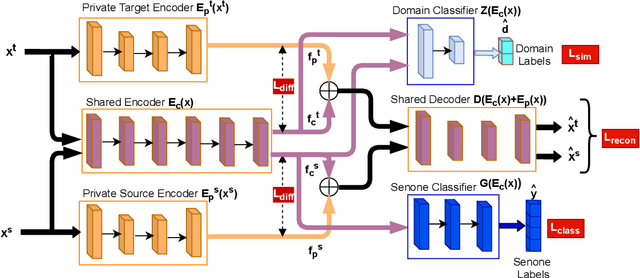
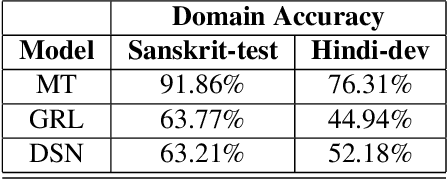
Building an automatic speech recognition (ASR) system from scratch requires a large amount of annotated speech data, which is difficult to collect in many languages. However, there are cases where the low-resource language shares a common acoustic space with a high-resource language having enough annotated data to build an ASR. In such cases, we show that the domain-independent acoustic models learned from the high-resource language through unsupervised domain adaptation (UDA) schemes can enhance the performance of the ASR in the low-resource language. We use the specific example of Hindi in the source domain and Sanskrit in the target domain. We explore two architectures: i) domain adversarial training using gradient reversal layer (GRL) and ii) domain separation networks (DSN). The GRL and DSN architectures give absolute improvements of 6.71% and 7.32%, respectively, in word error rate over the baseline deep neural network model when trained on just 5.5 hours of data in the target domain. We also show that choosing a proper language (Telugu) in the source domain can bring further improvement. The results suggest that UDA schemes can be helpful in the development of ASR systems for low-resource languages, mitigating the hassle of collecting large amounts of annotated speech data.