 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Large scale weakly and semi-supervised learning for low-resource video ASR
May 16, 2020
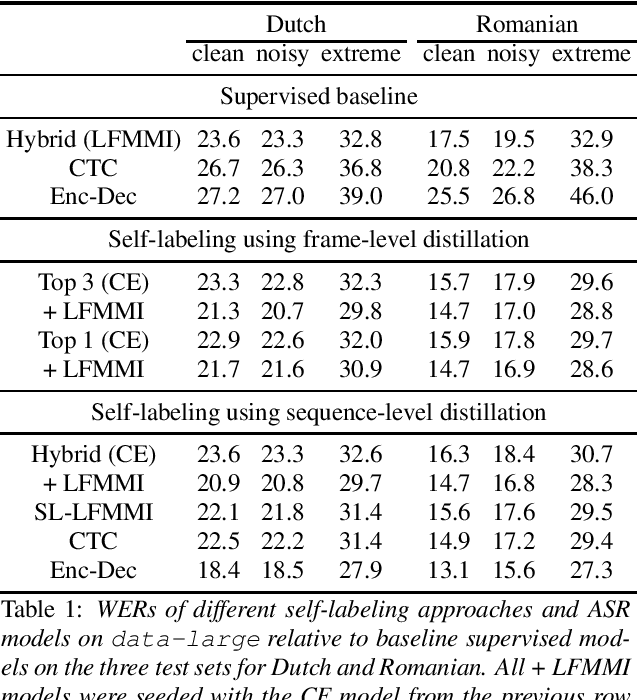
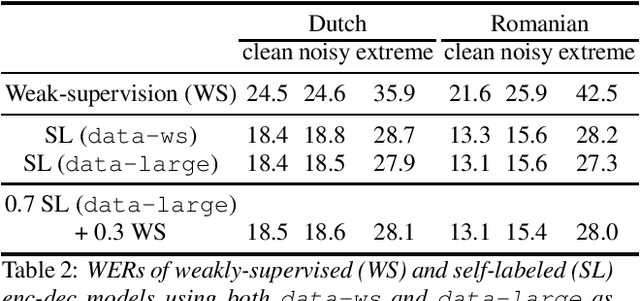
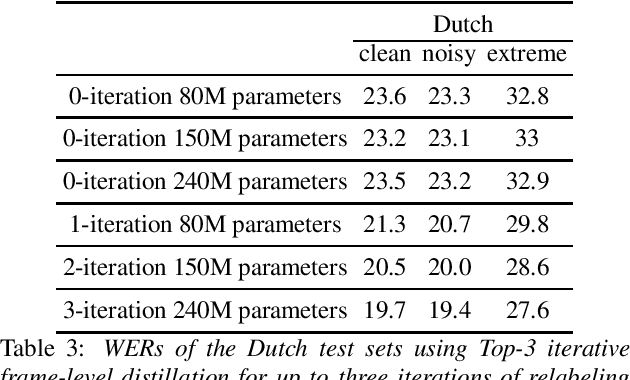
Many semi- and weakly-supervised approaches have been investigated for overcoming the labeling cost of building high quality speech recognition systems. On the challenging task of transcribing social media videos in low-resource conditions, we conduct a large scale systematic comparison between two self-labeling methods on one hand, and weakly-supervised pretraining using contextual metadata on the other. We investigate distillation methods at the frame level and the sequence level for hybrid, encoder-only CTC-based, and encoder-decoder speech recognition systems on Dutch and Romanian languages using 27,000 and 58,000 hours of unlabeled audio respectively. Although all approaches improved upon their respective baseline WERs by more than 8%, sequence-level distillation for encoder-decoder models provided the largest relative WER reduction of 20% compared to the strongest data-augmented supervised baseline.
Load-balanced Gather-scatter Patterns for Sparse Deep Neural Networks
Dec 20, 2021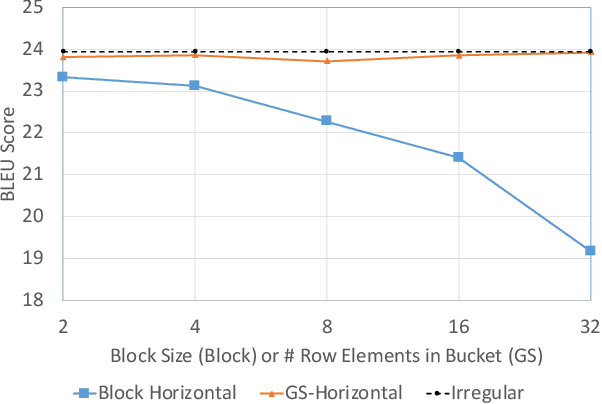
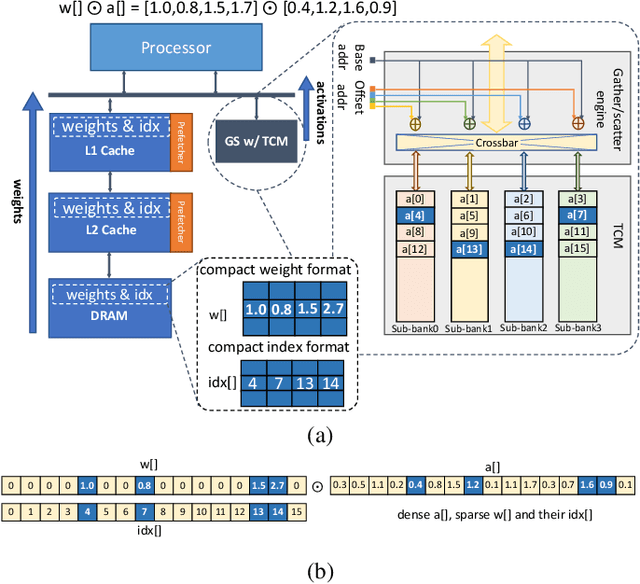

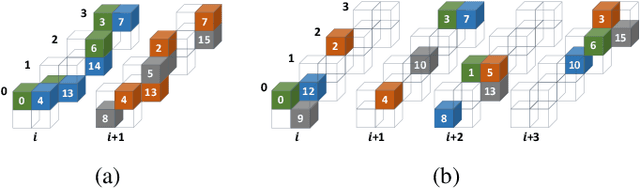
Deep neural networks (DNNs) have been proven to be effective in solving many real-life problems, but its high computation cost prohibits those models from being deployed to edge devices. Pruning, as a method to introduce zeros to model weights, has shown to be an effective method to provide good trade-offs between model accuracy and computation efficiency, and is a widely-used method to generate compressed models. However, the granularity of pruning makes important trade-offs. At the same sparsity level, a coarse-grained structured sparse pattern is more efficient on conventional hardware but results in worse accuracy, while a fine-grained unstructured sparse pattern can achieve better accuracy but is inefficient on existing hardware. On the other hand, some modern processors are equipped with fast on-chip scratchpad memories and gather/scatter engines that perform indirect load and store operations on such memories. In this work, we propose a set of novel sparse patterns, named gather-scatter (GS) patterns, to utilize the scratchpad memories and gather/scatter engines to speed up neural network inferences. Correspondingly, we present a compact sparse format. The proposed set of sparse patterns, along with a novel pruning methodology, address the load imbalance issue and result in models with quality close to unstructured sparse models and computation efficiency close to structured sparse models. Our experiments show that GS patterns consistently make better trade-offs between accuracy and computation efficiency compared to conventional structured sparse patterns. GS patterns can reduce the runtime of the DNN components by two to three times at the same accuracy levels. This is confirmed on three different deep learning tasks and popular models, namely, GNMT for machine translation, ResNet50 for image recognition, and Japser for acoustic speech recognition.
Speaker Diarization with Lexical Information
Apr 13, 2020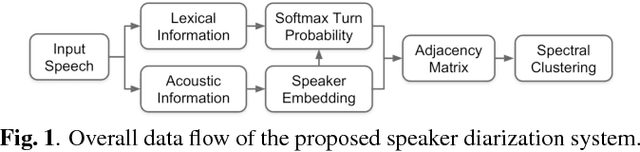
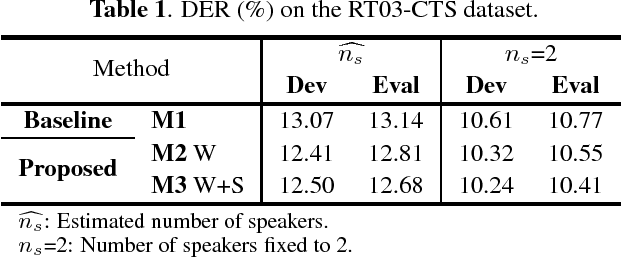
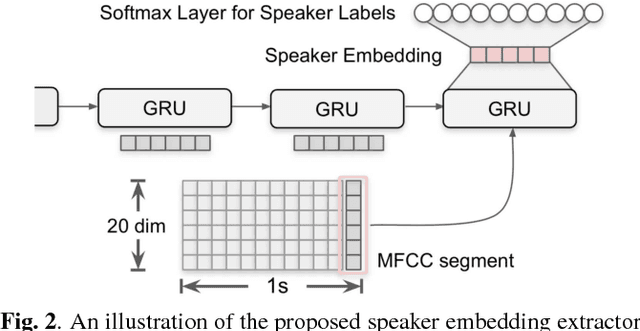
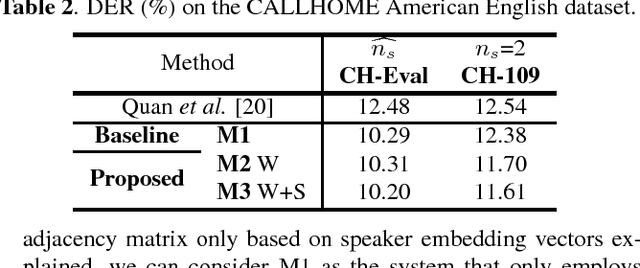
This work presents a novel approach for speaker diarization to leverage lexical information provided by automatic speech recognition. We propose a speaker diarization system that can incorporate word-level speaker turn probabilities with speaker embeddings into a speaker clustering process to improve the overall diarization accuracy. To integrate lexical and acoustic information in a comprehensive way during clustering, we introduce an adjacency matrix integration for spectral clustering. Since words and word boundary information for word-level speaker turn probability estimation are provided by a speech recognition system, our proposed method works without any human intervention for manual transcriptions. We show that the proposed method improves diarization performance on various evaluation datasets compared to the baseline diarization system using acoustic information only in speaker embeddings.
Fast-MD: Fast Multi-Decoder End-to-End Speech Translation with Non-Autoregressive Hidden Intermediates
Sep 27, 2021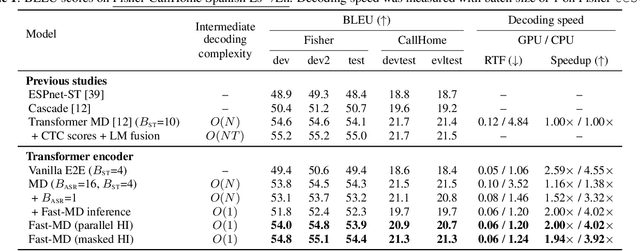
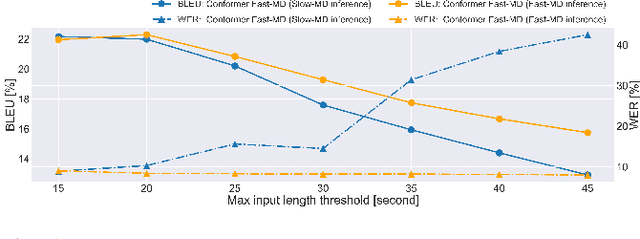
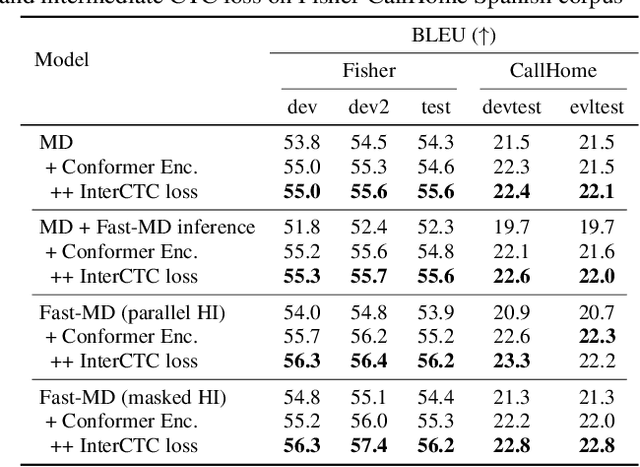
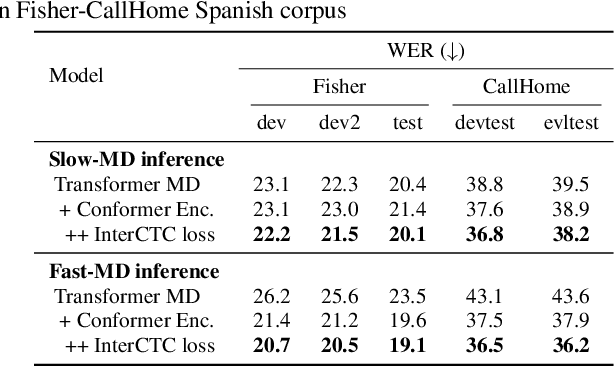
The multi-decoder (MD) end-to-end speech translation model has demonstrated high translation quality by searching for better intermediate automatic speech recognition (ASR) decoder states as hidden intermediates (HI). It is a two-pass decoding model decomposing the overall task into ASR and machine translation sub-tasks. However, the decoding speed is not fast enough for real-world applications because it conducts beam search for both sub-tasks during inference. We propose Fast-MD, a fast MD model that generates HI by non-autoregressive (NAR) decoding based on connectionist temporal classification (CTC) outputs followed by an ASR decoder. We investigated two types of NAR HI: (1) parallel HI by using an autoregressive Transformer ASR decoder and (2) masked HI by using Mask-CTC, which combines CTC and the conditional masked language model. To reduce a mismatch in the ASR decoder between teacher-forcing during training and conditioning on CTC outputs during testing, we also propose sampling CTC outputs during training. Experimental evaluations on three corpora show that Fast-MD achieved about 2x and 4x faster decoding speed than that of the na\"ive MD model on GPU and CPU with comparable translation quality. Adopting the Conformer encoder and intermediate CTC loss further boosts its quality without sacrificing decoding speed.
NeMo Inverse Text Normalization: From Development To Production
Apr 11, 2021
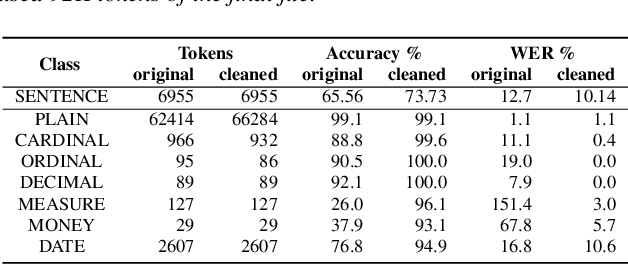
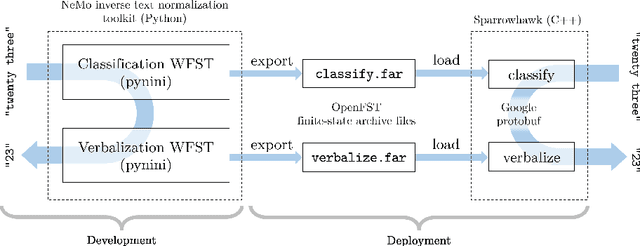

Inverse text normalization (ITN) converts spoken-domain automatic speech recognition (ASR) output into written-domain text to improve the readability of the ASR output. Many state-of-the-art ITN systems use hand-written weighted finite-state transducer(WFST) grammars since this task has extremely low tolerance to unrecoverable errors. We introduce an open-source Python WFST-based library for ITN which enables a seamless path from development to production. We describe the specification of ITN grammar rules for English, but the library can be adapted for other languages. It can also be used for written-to-spoken text normalization. We evaluate the NeMo ITN library using a modified version of the Google Text normalization dataset.
End-to-end Named Entity Recognition from English Speech
May 22, 2020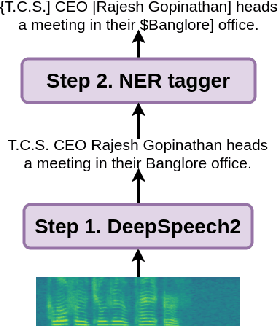

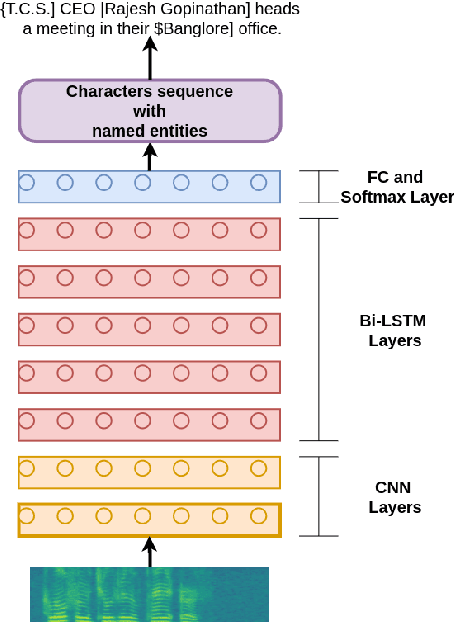
Named entity recognition (NER) from text has been a widely studied problem and usually extracts semantic information from text. Until now, NER from speech is mostly studied in a two-step pipeline process that includes first applying an automatic speech recognition (ASR) system on an audio sample and then passing the predicted transcript to a NER tagger. In such cases, the error does not propagate from one step to another as both the tasks are not optimized in an end-to-end (E2E) fashion. Recent studies confirm that integrated approaches (e.g., E2E ASR) outperform sequential ones (e.g., phoneme based ASR). In this paper, we introduce a first publicly available NER annotated dataset for English speech and present an E2E approach, which jointly optimizes the ASR and NER tagger components. Experimental results show that the proposed E2E approach outperforms the classical two-step approach. We also discuss how NER from speech can be used to handle out of vocabulary (OOV) words in an ASR system.
Sequence-to-Sequence Modeling for Action Identification at High Temporal Resolution
Nov 03, 2021

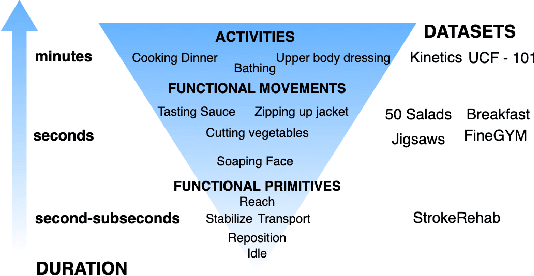
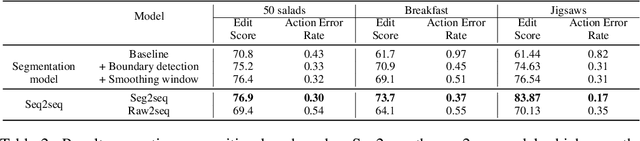
Automatic action identification from video and kinematic data is an important machine learning problem with applications ranging from robotics to smart health. Most existing works focus on identifying coarse actions such as running, climbing, or cutting a vegetable, which have relatively long durations. This is an important limitation for applications that require the identification of subtle motions at high temporal resolution. For example, in stroke recovery, quantifying rehabilitation dose requires differentiating motions with sub-second durations. Our goal is to bridge this gap. To this end, we introduce a large-scale, multimodal dataset, StrokeRehab, as a new action-recognition benchmark that includes subtle short-duration actions labeled at a high temporal resolution. These short-duration actions are called functional primitives, and consist of reaches, transports, repositions, stabilizations, and idles. The dataset consists of high-quality Inertial Measurement Unit sensors and video data of 41 stroke-impaired patients performing activities of daily living like feeding, brushing teeth, etc. We show that current state-of-the-art models based on segmentation produce noisy predictions when applied to these data, which often leads to overcounting of actions. To address this, we propose a novel approach for high-resolution action identification, inspired by speech-recognition techniques, which is based on a sequence-to-sequence model that directly predicts the sequence of actions. This approach outperforms current state-of-the-art methods on the StrokeRehab dataset, as well as on the standard benchmark datasets 50Salads, Breakfast, and Jigsaws.
Topic Classification on Spoken Documents Using Deep Acoustic and Linguistic Features
Jun 16, 2021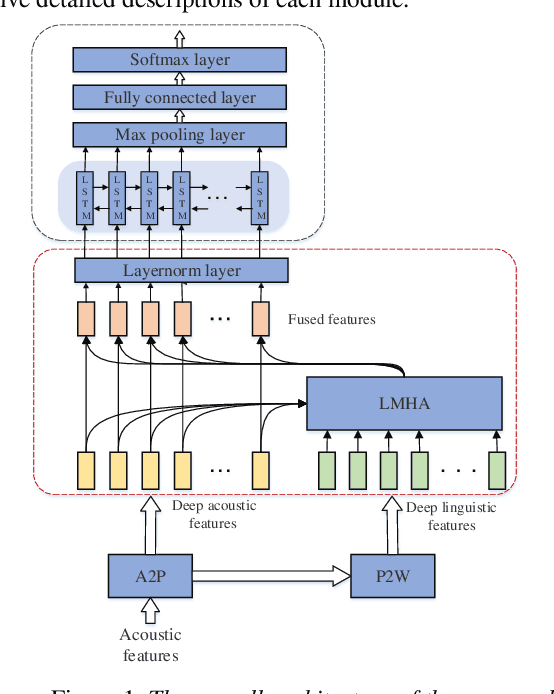

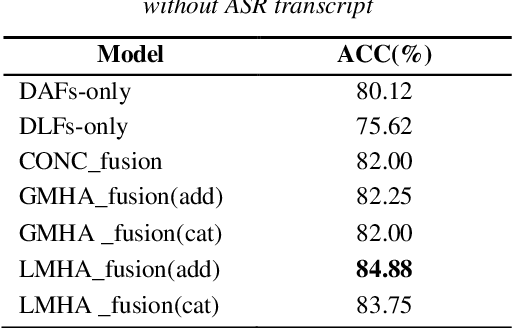
Topic classification systems on spoken documents usually consist of two modules: an automatic speech recognition (ASR) module to convert speech into text and a text topic classification (TTC) module to predict the topic class from the decoded text. In this paper, instead of using the ASR transcripts, the fusion of deep acoustic and linguistic features is used for topic classification on spoken documents. More specifically, a conventional CTC-based acoustic model (AM) using phonemes as output units is first trained, and the outputs of the layer before the linear phoneme classifier in the trained AM are used as the deep acoustic features of spoken documents. Furthermore, these deep acoustic features are fed to a phoneme-to-word (P2W) module to obtain deep linguistic features. Finally, a local multi-head attention module is proposed to fuse these two types of deep features for topic classification. Experiments conducted on a subset selected from Switchboard corpus show that our proposed framework outperforms the conventional ASR+TTC systems and achieves a 3.13% improvement in ACC.
Towards Transferable Speech Emotion Representation: On loss functions for cross-lingual latent representations
Mar 28, 2022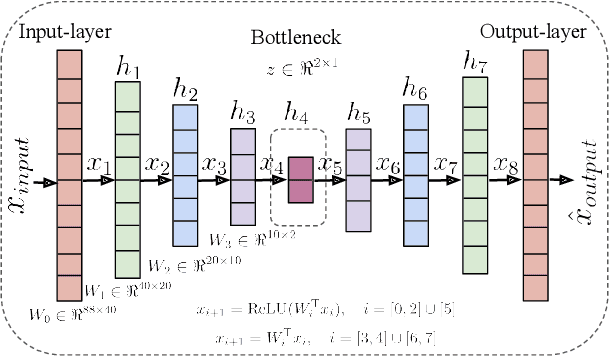

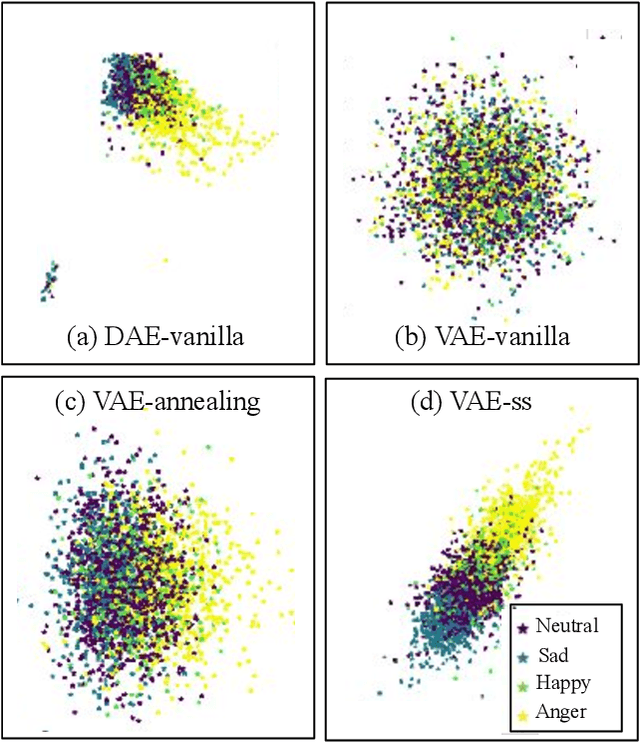
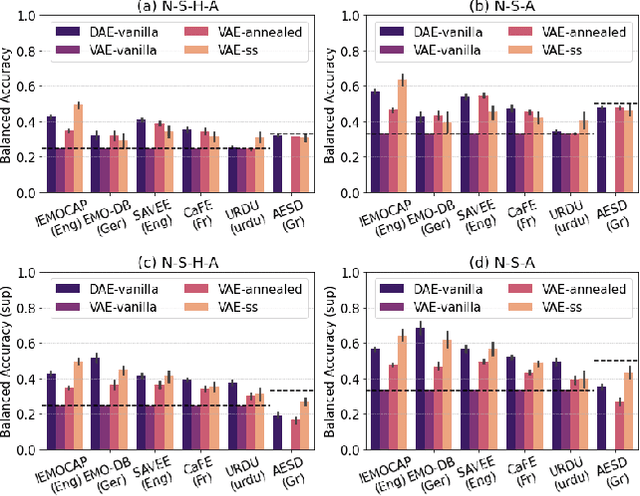
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques which provide transfer learning possibilities. However, generalizing over languages, corpora and recording conditions is still an open challenge. In this work we address this gap by exploring loss functions that aid in transferability, specifically to non-tonal languages. We propose a variational autoencoder (VAE) with KL annealing and a semi-supervised VAE to obtain more consistent latent embedding distributions across data sets. To ensure transferability, the distribution of the latent embedding should be similar across non-tonal languages (data sets). We start by presenting a low-complexity SER based on a denoising-autoencoder, which achieves an unweighted classification accuracy of over 52.09% for four-class emotion classification. This performance is comparable to that of similar baseline methods. Following this, we employ a VAE, the semi-supervised VAE and the VAE with KL annealing to obtain a more regularized latent space. We show that while the DAE has the highest classification accuracy among the methods, the semi-supervised VAE has a comparable classification accuracy and a more consistent latent embedding distribution over data sets.
Noisy Training Improves E2E ASR for the Edge
Jul 09, 2021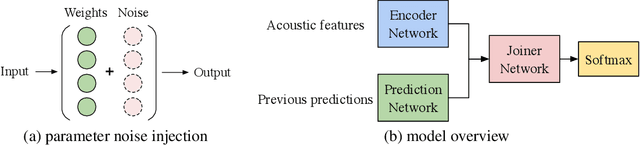
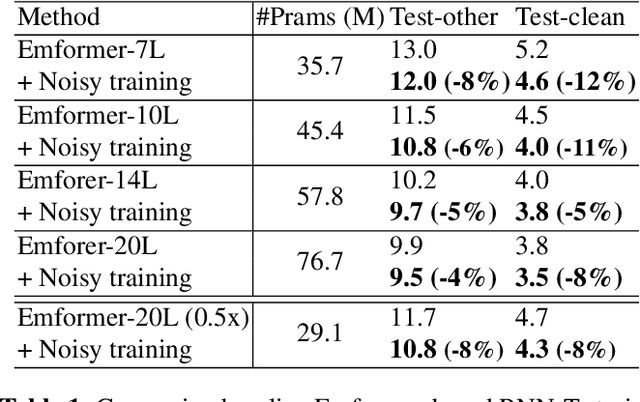
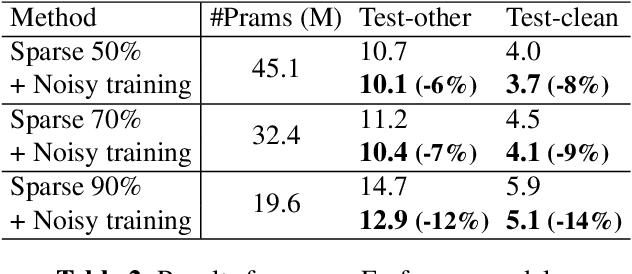
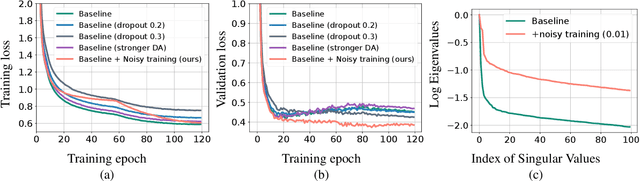
Automatic speech recognition (ASR) has become increasingly ubiquitous on modern edge devices. Past work developed streaming End-to-End (E2E) all-neural speech recognizers that can run compactly on edge devices. However, E2E ASR models are prone to overfitting and have difficulties in generalizing to unseen testing data. Various techniques have been proposed to regularize the training of ASR models, including layer normalization, dropout, spectrum data augmentation and speed distortions in the inputs. In this work, we present a simple yet effective noisy training strategy to further improve the E2E ASR model training. By introducing random noise to the parameter space during training, our method can produce smoother models at convergence that generalize better. We apply noisy training to improve both dense and sparse state-of-the-art Emformer models and observe consistent WER reduction. Specifically, when training Emformers with 90% sparsity, we achieve 12% and 14% WER improvements on the LibriSpeech Test-other and Test-clean data set, respectively.