 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023
Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.
Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults
Sep 18, 2023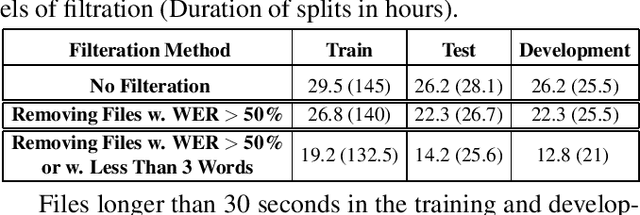
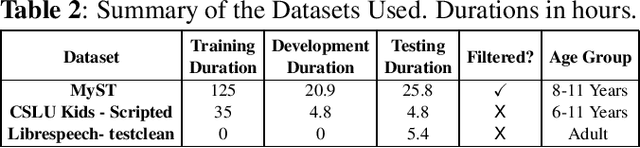
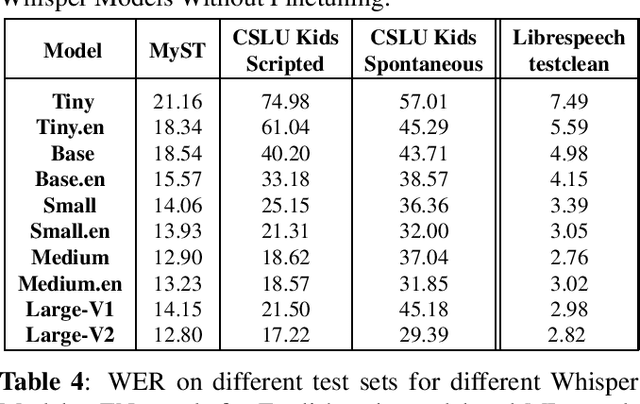
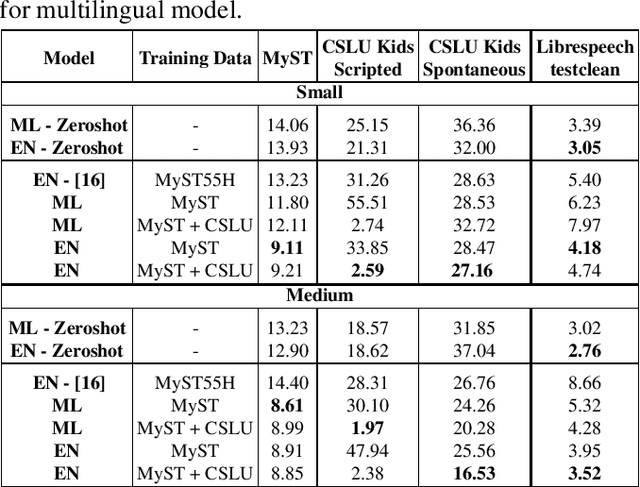
Recent advancements in Automatic Speech Recognition (ASR) systems, exemplified by Whisper, have demonstrated the potential of these systems to approach human-level performance given sufficient data. However, this progress doesn't readily extend to ASR for children due to the limited availability of suitable child-specific databases and the distinct characteristics of children's speech. A recent study investigated leveraging the My Science Tutor (MyST) children's speech corpus to enhance Whisper's performance in recognizing children's speech. They were able to demonstrate some improvement on a limited testset. This paper builds on these findings by enhancing the utility of the MyST dataset through more efficient data preprocessing. We reduce the Word Error Rate (WER) on the MyST testset 13.93% to 9.11% with Whisper-Small and from 13.23% to 8.61% with Whisper-Medium and show that this improvement can be generalized to unseen datasets. We also highlight important challenges towards improving children's ASR performance. The results showcase the viable and efficient integration of Whisper for effective children's speech recognition.
Key Frame Mechanism For Efficient Conformer Based End-to-end Speech Recognition
Oct 23, 2023Recently, Conformer as a backbone network for end-to-end automatic speech recognition achieved state-of-the-art performance. The Conformer block leverages a self-attention mechanism to capture global information, along with a convolutional neural network to capture local information, resulting in improved performance. However, the Conformer-based model encounters an issue with the self-attention mechanism, as computational complexity grows quadratically with the length of the input sequence. Inspired by previous Connectionist Temporal Classification (CTC) guided blank skipping during decoding, we introduce intermediate CTC outputs as guidance into the downsampling procedure of the Conformer encoder. We define the frame with non-blank output as key frame. Specifically, we introduce the key frame-based self-attention (KFSA) mechanism, a novel method to reduce the computation of the self-attention mechanism using key frames. The structure of our proposed approach comprises two encoders. Following the initial encoder, we introduce an intermediate CTC loss function to compute the label frame, enabling us to extract the key frames and blank frames for KFSA. Furthermore, we introduce the key frame-based downsampling (KFDS) mechanism to operate on high-dimensional acoustic features directly and drop the frames corresponding to blank labels, which results in new acoustic feature sequences as input to the second encoder. By using the proposed method, which achieves comparable or higher performance than vanilla Conformer and other similar work such as Efficient Conformer. Meantime, our proposed method can discard more than 60\% useless frames during model training and inference, which will accelerate the inference speed significantly. This work code is available in {https://github.com/scufan1990/Key-Frame-Mechanism-For-Efficient-Conformer}
Optimizing Convolutional Neural Network Architecture
Dec 17, 2023Convolutional Neural Networks (CNN) are widely used to face challenging tasks like speech recognition, natural language processing or computer vision. As CNN architectures get larger and more complex, their computational requirements increase, incurring significant energetic costs and challenging their deployment on resource-restricted devices. In this paper, we propose Optimizing Convolutional Neural Network Architecture (OCNNA), a novel CNN optimization and construction method based on pruning and knowledge distillation designed to establish the importance of convolutional layers. The proposal has been evaluated though a thorough empirical study including the best known datasets (CIFAR-10, CIFAR-100 and Imagenet) and CNN architectures (VGG-16, ResNet-50, DenseNet-40 and MobileNet), setting Accuracy Drop and Remaining Parameters Ratio as objective metrics to compare the performance of OCNNA against the other state-of-art approaches. Our method has been compared with more than 20 convolutional neural network simplification algorithms obtaining outstanding results. As a result, OCNNA is a competitive CNN constructing method which could ease the deployment of neural networks into IoT or resource-limited devices.
FastInject: Injecting Unpaired Text Data into CTC-based ASR training
Dec 14, 2023Recently, connectionist temporal classification (CTC)-based end-to-end (E2E) automatic speech recognition (ASR) models have achieved impressive results, especially with the development of self-supervised learning. However, E2E ASR models trained on paired speech-text data often suffer from domain shifts from training to testing. To alleviate this issue, this paper proposes a flat-start joint training method, named FastInject, which efficiently injects multi-domain unpaired text data into CTC-based ASR training. To maintain training efficiency, text units are pre-upsampled, and their representations are fed into the CTC model along with speech features. To bridge the modality gap between speech and text, an attention-based modality matching mechanism (AM3) is proposed, which retains the E2E flat-start training. Experiments show that the proposed FastInject gave a 22\% relative WER reduction (WERR) for intra-domain Librispeech-100h data and 20\% relative WERR on out-of-domain test sets.
Lattice Rescoring Based on Large Ensemble of Complementary Neural Language Models
Dec 20, 2023We investigate the effectiveness of using a large ensemble of advanced neural language models (NLMs) for lattice rescoring on automatic speech recognition (ASR) hypotheses. Previous studies have reported the effectiveness of combining a small number of NLMs. In contrast, in this study, we combine up to eight NLMs, i.e., forward/backward long short-term memory/Transformer-LMs that are trained with two different random initialization seeds. We combine these NLMs through iterative lattice generation. Since these NLMs work complementarily with each other, by combining them one by one at each rescoring iteration, language scores attached to given lattice arcs can be gradually refined. Consequently, errors of the ASR hypotheses can be gradually reduced. We also investigate the effectiveness of carrying over contextual information (previous rescoring results) across a lattice sequence of a long speech such as a lecture speech. In experiments using a lecture speech corpus, by combining the eight NLMs and using context carry-over, we obtained a 24.4% relative word error rate reduction from the ASR 1-best baseline. For further comparison, we performed simultaneous (i.e., non-iterative) NLM combination and 100-best rescoring using the large ensemble of NLMs, which confirmed the advantage of lattice rescoring with iterative NLM combination.
Iterative Shallow Fusion of Backward Language Model for End-to-End Speech Recognition
Oct 17, 2023We propose a new shallow fusion (SF) method to exploit an external backward language model (BLM) for end-to-end automatic speech recognition (ASR). The BLM has complementary characteristics with a forward language model (FLM), and the effectiveness of their combination has been confirmed by rescoring ASR hypotheses as post-processing. In the proposed SF, we iteratively apply the BLM to partial ASR hypotheses in the backward direction (i.e., from the possible next token to the start symbol) during decoding, substituting the newly calculated BLM scores for the scores calculated at the last iteration. To enhance the effectiveness of this iterative SF (ISF), we train a partial sentence-aware BLM (PBLM) using reversed text data including partial sentences, considering the framework of ISF. In experiments using an attention-based encoder-decoder ASR system, we confirmed that ISF using the PBLM shows comparable performance with SF using the FLM. By performing ISF, early pruning of prospective hypotheses can be prevented during decoding, and we can obtain a performance improvement compared to applying the PBLM as post-processing. Finally, we confirmed that, by combining SF and ISF, further performance improvement can be obtained thanks to the complementarity of the FLM and PBLM.
A Strong Baseline for Temporal Video-Text Alignment
Dec 21, 2023In this paper, we consider the problem of temporally aligning the video and texts from instructional videos, specifically, given a long-term video, and associated text sentences, our goal is to determine their corresponding timestamps in the video. To this end, we establish a simple, yet strong model that adopts a Transformer-based architecture with all texts as queries, iteratively attending to the visual features, to infer the optimal timestamp. We conduct thorough experiments to investigate: (i) the effect of upgrading ASR systems to reduce errors from speech recognition, (ii) the effect of various visual-textual backbones, ranging from CLIP to S3D, to the more recent InternVideo, (iii) the effect of transforming noisy ASR transcripts into descriptive steps by prompting a large language model (LLM), to summarize the core activities within the ASR transcript as a new training dataset. As a result, our proposed simple model demonstrates superior performance on both narration alignment and procedural step grounding tasks, surpassing existing state-of-the-art methods by a significant margin on three public benchmarks, namely, 9.3% on HT-Step, 3.4% on HTM-Align and 4.7% on CrossTask. We believe the proposed model and dataset with descriptive steps can be treated as a strong baseline for future research in temporal video-text alignment. All codes, models, and the resulting dataset will be publicly released to the research community.
Audio-visual fine-tuning of audio-only ASR models
Dec 14, 2023Audio-visual automatic speech recognition (AV-ASR) models are very effective at reducing word error rates on noisy speech, but require large amounts of transcribed AV training data. Recently, audio-visual self-supervised learning (SSL) approaches have been developed to reduce this dependence on transcribed AV data, but these methods are quite complex and computationally expensive. In this work, we propose replacing these expensive AV-SSL methods with a simple and fast \textit{audio-only} SSL method, and then performing AV supervised fine-tuning. We show that this approach is competitive with state-of-the-art (SOTA) AV-SSL methods on the LRS3-TED benchmark task (within 0.5% absolute WER), while being dramatically simpler and more efficient (12-30x faster to pre-train). Furthermore, we show we can extend this approach to convert a SOTA audio-only ASR model into an AV model. By doing so, we match SOTA AV-SSL results, even though no AV data was used during pre-training.
BA-MoE: Boundary-Aware Mixture-of-Experts Adapter for Code-Switching Speech Recognition
Oct 08, 2023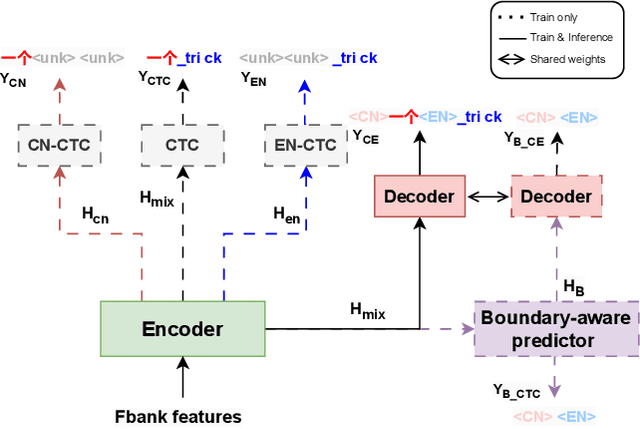
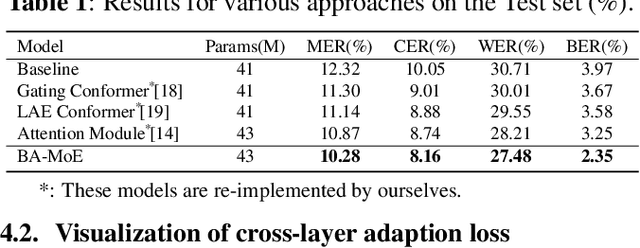
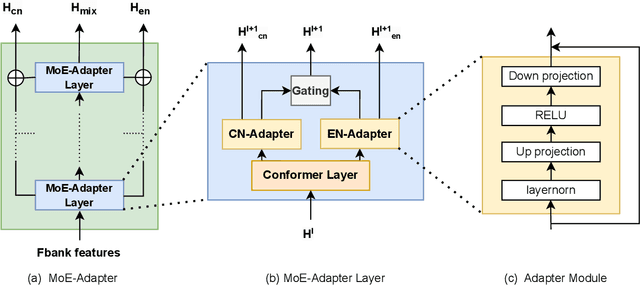
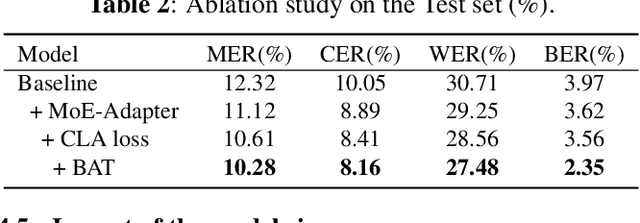
Mixture-of-experts based models, which use language experts to extract language-specific representations effectively, have been well applied in code-switching automatic speech recognition. However, there is still substantial space to improve as similar pronunciation across languages may result in ineffective multi-language modeling and inaccurate language boundary estimation. To eliminate these drawbacks, we propose a cross-layer language adapter and a boundary-aware training method, namely Boundary-Aware Mixture-of-Experts (BA-MoE). Specifically, we introduce language-specific adapters to separate language-specific representations and a unified gating layer to fuse representations within each encoder layer. Second, we compute language adaptation loss of the mean output of each language-specific adapter to improve the adapter module's language-specific representation learning. Besides, we utilize a boundary-aware predictor to learn boundary representations for dealing with language boundary confusion. Our approach achieves significant performance improvement, reducing the mixture error rate by 16.55\% compared to the baseline on the ASRU 2019 Mandarin-English code-switching challenge dataset.