 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Mixed Precision DNN Qunatization for Overlapped Speech Separation and Recognition
Nov 29, 2021
Recognition of overlapped speech has been a highly challenging task to date. State-of-the-art multi-channel speech separation system are becoming increasingly complex and expensive for practical applications. To this end, low-bit neural network quantization provides a powerful solution to dramatically reduce their model size. However, current quantization methods are based on uniform precision and fail to account for the varying performance sensitivity at different model components to quantization errors. In this paper, novel mixed precision DNN quantization methods are proposed by applying locally variable bit-widths to individual TCN components of a TF masking based multi-channel speech separation system. The optimal local precision settings are automatically learned using three techniques. The first two approaches utilize quantization sensitivity metrics based on either the mean square error (MSE) loss function curvature, or the KL-divergence measured between full precision and quantized separation models. The third approach is based on mixed precision neural architecture search. Experiments conducted on the LRS3-TED corpus simulated overlapped speech data suggest that the proposed mixed precision quantization techniques consistently outperform the uniform precision baseline speech separation systems of comparable bit-widths in terms of SI-SNR and PESQ scores as well as word error rate (WER) reductions up to 2.88% absolute (8% relative).
Attention-based Multi-hypothesis Fusion for Speech Summarization
Nov 16, 2021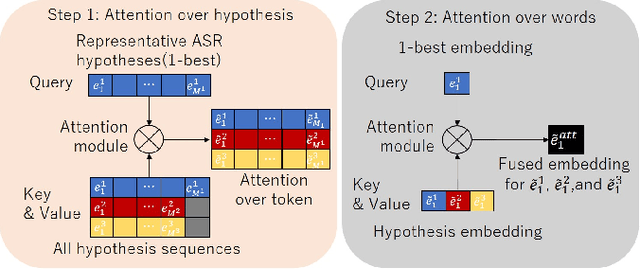

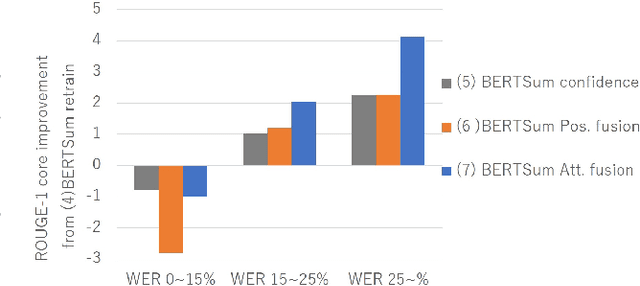

Speech summarization, which generates a text summary from speech, can be achieved by combining automatic speech recognition (ASR) and text summarization (TS). With this cascade approach, we can exploit state-of-the-art models and large training datasets for both subtasks, i.e., Transformer for ASR and Bidirectional Encoder Representations from Transformers (BERT) for TS. However, ASR errors directly affect the quality of the output summary in the cascade approach. We propose a cascade speech summarization model that is robust to ASR errors and that exploits multiple hypotheses generated by ASR to attenuate the effect of ASR errors on the summary. We investigate several schemes to combine ASR hypotheses. First, we propose using the sum of sub-word embedding vectors weighted by their posterior values provided by an ASR system as an input to a BERT-based TS system. Then, we introduce a more general scheme that uses an attention-based fusion module added to a pre-trained BERT module to align and combine several ASR hypotheses. Finally, we perform speech summarization experiments on the How2 dataset and a newly assembled TED-based dataset that we will release with this paper. These experiments show that retraining the BERT-based TS system with these schemes can improve summarization performance and that the attention-based fusion module is particularly effective.
Loss Landscape Dependent Self-Adjusting Learning Rates in Decentralized Stochastic Gradient Descent
Dec 02, 2021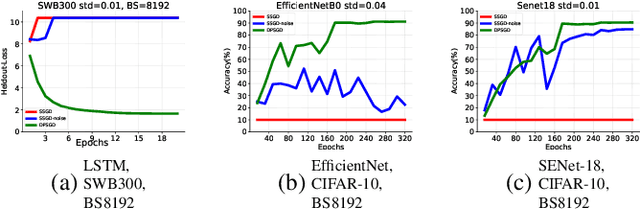
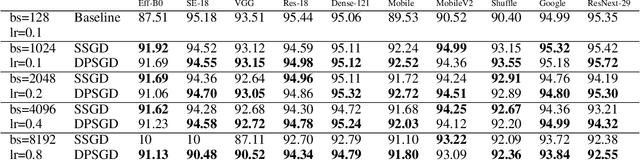
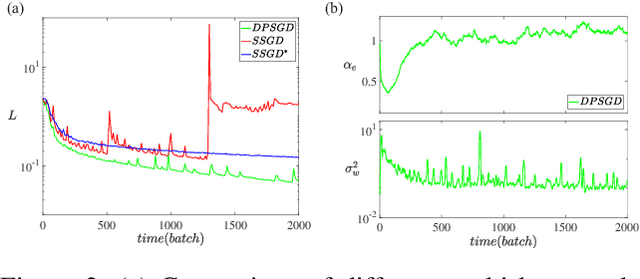
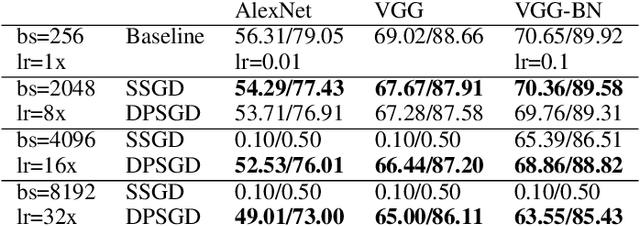
Distributed Deep Learning (DDL) is essential for large-scale Deep Learning (DL) training. Synchronous Stochastic Gradient Descent (SSGD) 1 is the de facto DDL optimization method. Using a sufficiently large batch size is critical to achieving DDL runtime speedup. In a large batch setting, the learning rate must be increased to compensate for the reduced number of parameter updates. However, a large learning rate may harm convergence in SSGD and training could easily diverge. Recently, Decentralized Parallel SGD (DPSGD) has been proposed to improve distributed training speed. In this paper, we find that DPSGD not only has a system-wise run-time benefit but also a significant convergence benefit over SSGD in the large batch setting. Based on a detailed analysis of the DPSGD learning dynamics, we find that DPSGD introduces additional landscape-dependent noise that automatically adjusts the effective learning rate to improve convergence. In addition, we theoretically show that this noise smoothes the loss landscape, hence allowing a larger learning rate. We conduct extensive studies over 18 state-of-the-art DL models/tasks and demonstrate that DPSGD often converges in cases where SSGD diverges for large learning rates in the large batch setting. Our findings are consistent across two different application domains: Computer Vision (CIFAR10 and ImageNet-1K) and Automatic Speech Recognition (SWB300 and SWB2000), and two different types of neural network models: Convolutional Neural Networks and Long Short-Term Memory Recurrent Neural Networks.
Binary classification of spoken words with passive elastic metastructures
Nov 14, 2021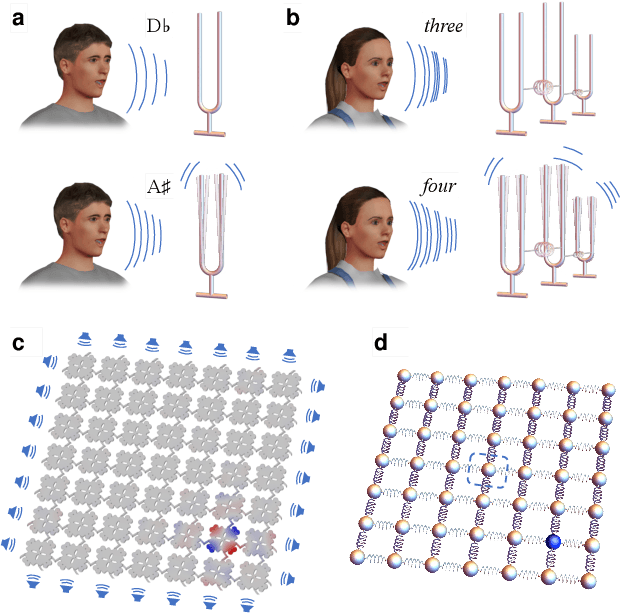
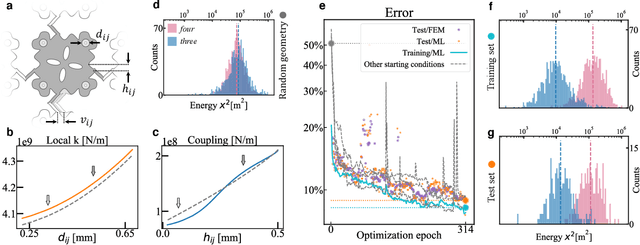
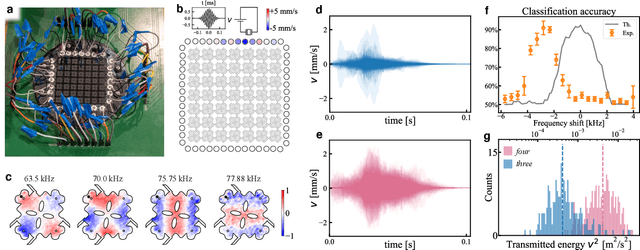
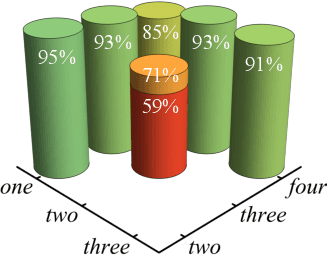
Many electronic devices spend most of their time waiting for a wake-up event: pacemakers waiting for an anomalous heartbeat, security systems on alert to detect an intruder, smartphones listening for the user to say a wake-up phrase. These devices continuously convert physical signals into electrical currents that are then analyzed on a digital computer -- leading to power consumption even when no event is taking place. Solving this problem requires the ability to passively distinguish relevant from irrelevant events (e.g. tell a wake-up phrase from a regular conversation). Here, we experimentally demonstrate an elastic metastructure, consisting of a network of coupled silicon resonators, that passively discriminates between pairs of spoken words -- solving the wake-up problem for scenarios where only two classes of events are possible. This passive speech recognition is demonstrated on a dataset from speakers with significant gender and accent diversity. The geometry of the metastructure is determined during the design process, in which the network of resonators ('mechanical neurones') learns to selectively respond to spoken words. Training is facilitated by a machine learning model that reduces the number of computationally expensive three-dimensional elastic wave simulations. By embedding event detection in the structural dynamics, mechanical neural networks thus enable novel classes of always-on smart devices with no standby power consumption.
Dynamic Layer Customization for Noise Robust Speech Emotion Recognition in Heterogeneous Condition Training
Oct 21, 2020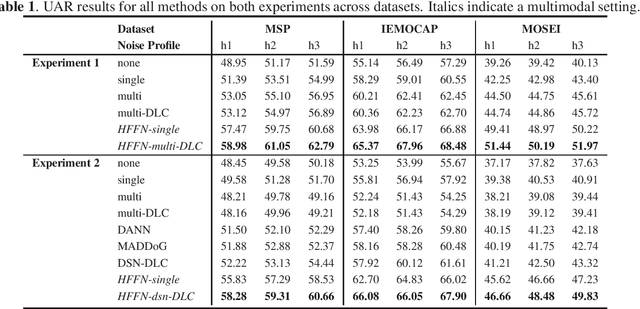
Robustness to environmental noise is important to creating automatic speech emotion recognition systems that are deployable in the real world. Prior work on noise robustness has assumed that systems would not make use of sample-by-sample training noise conditions, or that they would have access to unlabelled testing data to generalize across noise conditions. We avoid these assumptions and introduce the resulting task as heterogeneous condition training. We show that with full knowledge of the test noise conditions, we can improve performance by dynamically routing samples to specialized feature encoders for each noise condition, and with partial knowledge, we can use known noise conditions and domain adaptation algorithms to train systems that generalize well to unseen noise conditions. We then extend these improvements to the multimodal setting by dynamically routing samples to maintain temporal ordering, resulting in significant improvements over approaches that do not specialize or generalize based on noise type.
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 27, 2021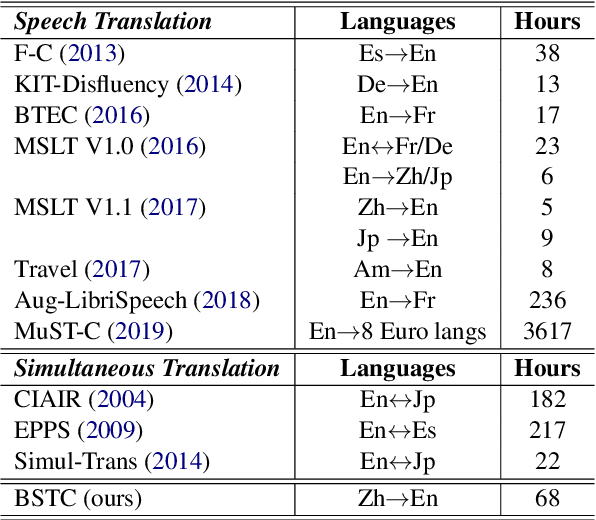
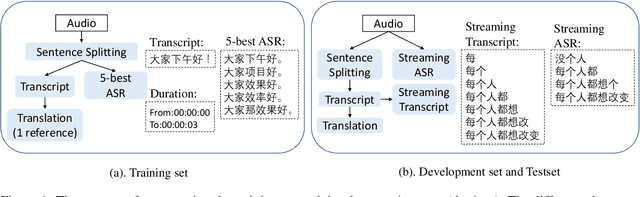

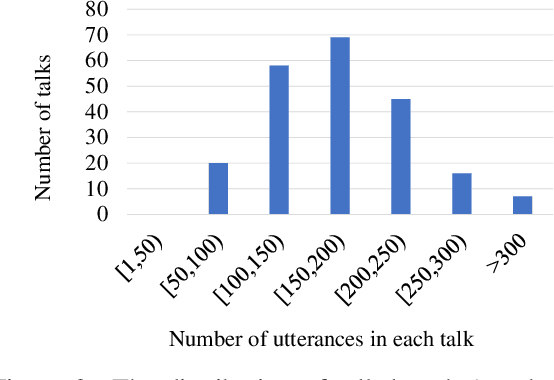
This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
speechocean762: An Open-Source Non-native English Speech Corpus For Pronunciation Assessment
Apr 03, 2021
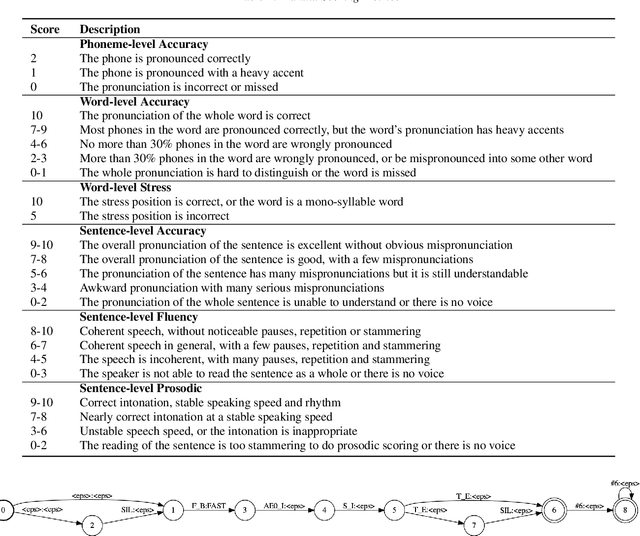
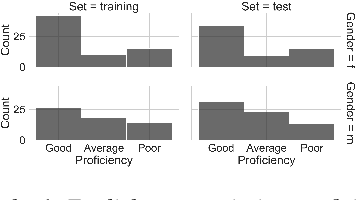

This paper introduces a new open-source speech corpus named "speechocean762" designed for pronunciation assessment use, consisting of 5000 English utterances from 250 non-native speakers, where half of the speakers are children. Five experts annotated each of the utterances at sentence-level, word-level and phoneme-level. A baseline system is released in open source to illustrate the phoneme-level pronunciation assessment workflow on this corpus. This corpus is allowed to be used freely for commercial and non-commercial purposes. It is available for free download from OpenSLR, and the corresponding baseline system is published in the Kaldi speech recognition toolkit.
Pretrained Semantic Speech Embeddings for End-to-End Spoken Language Understanding via Cross-Modal Teacher-Student Learning
Jul 03, 2020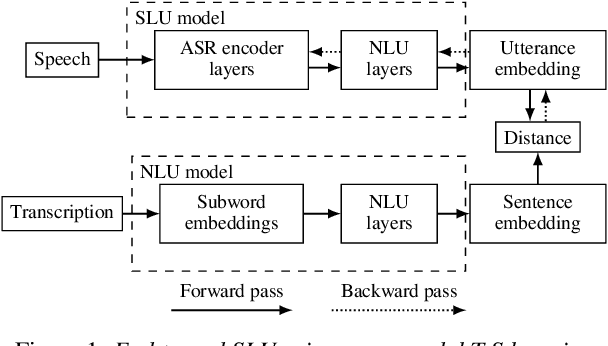
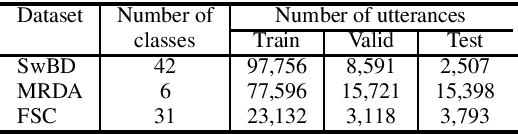

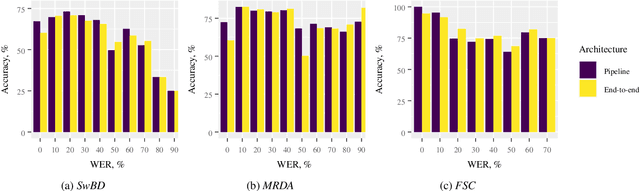
Spoken language understanding is typically based on pipeline architectures including speech recognition and natural language understanding steps. Therefore, these components are optimized independently from each other and the overall system suffers from error propagation. In this paper, we propose a novel training method that enables pretrained contextual embeddings such as BERT to process acoustic features. In particular, we extend it with an encoder of pretrained speech recognition systems in order to construct end-to-end spoken language understanding systems. Our proposed method is based on the teacher-student framework across speech and text modalities that aligns the acoustic and the semantic latent spaces. Experimental results in three benchmark datasets show that our system reaches the pipeline architecture performance without using any training data and outperforms it after fine-tuning with only a few examples.
Knowing What to Listen to: Early Attention for Deep Speech Representation Learning
Sep 03, 2020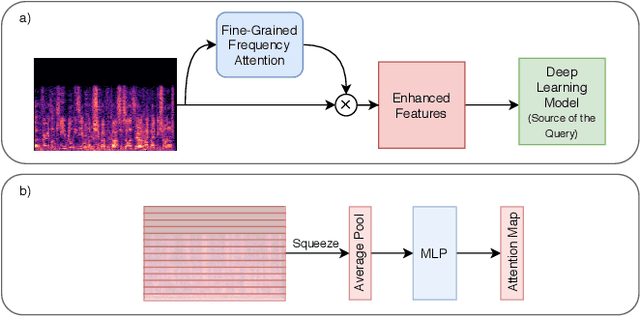
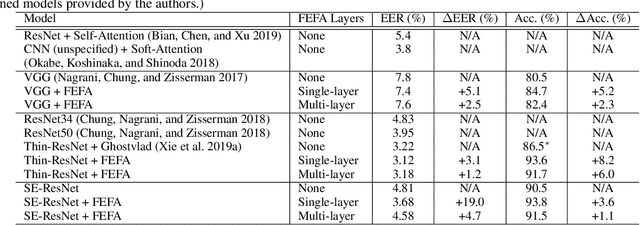
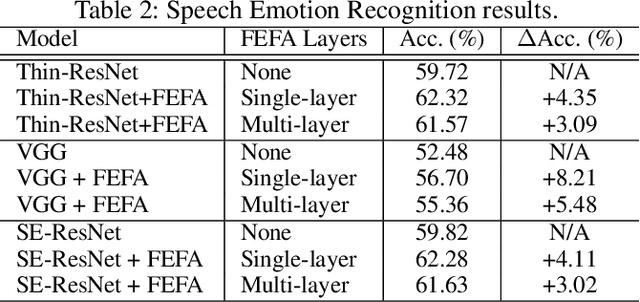
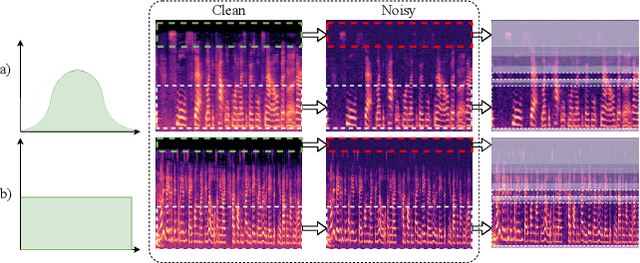
Deep learning techniques have considerably improved speech processing in recent years. Speech representations extracted by deep learning models are being used in a wide range of tasks such as speech recognition, speaker recognition, and speech emotion recognition. Attention models play an important role in improving deep learning models. However current attention mechanisms are unable to attend to fine-grained information items. In this paper we propose the novel Fine-grained Early Frequency Attention (FEFA) for speech signals. This model is capable of focusing on information items as small as frequency bins. We evaluate the proposed model on two popular tasks of speaker recognition and speech emotion recognition. Two widely used public datasets, VoxCeleb and IEMOCAP, are used for our experiments. The model is implemented on top of several prominent deep models as backbone networks to evaluate its impact on performance compared to the original networks and other related work. Our experiments show that by adding FEFA to different CNN architectures, performance is consistently improved by substantial margins, even setting a new state-of-the-art for the speaker recognition task. We also tested our model against different levels of added noise showing improvements in robustness and less sensitivity compared to the backbone networks.
Speech Emotion Recognition with Dual-Sequence LSTM Architecture
Oct 20, 2019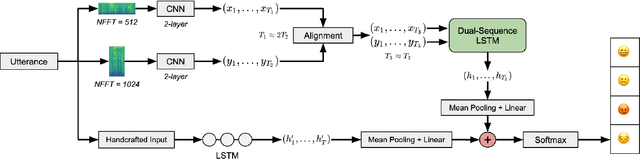
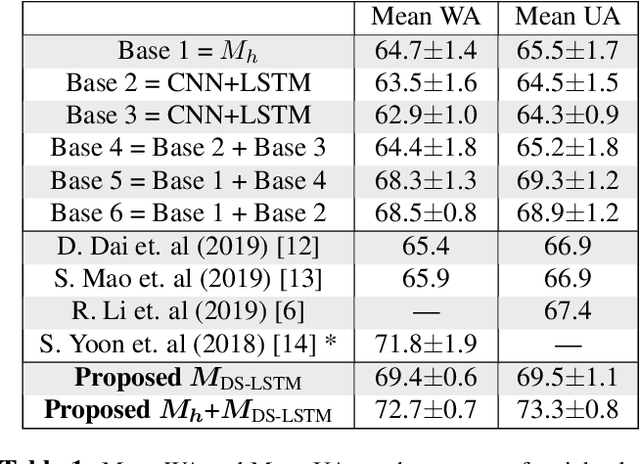
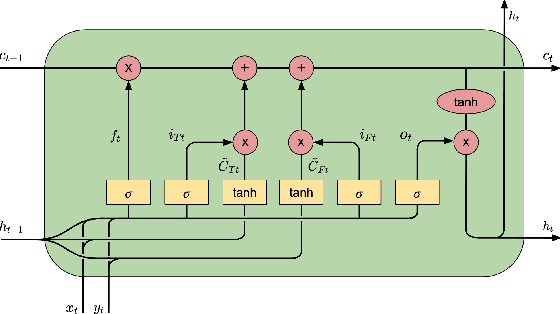
Speech Emotion Recognition (SER) has emerged as a critical component of the next generation of human-machine interfacing technologies. In this work, we propose a new dual-level model that combines handcrafted and raw features for audio signals. Each utterance is preprocessed into a handcrafted input and two mel-spectrograms at different time-frequency resolutions. An LSTM processes the handcrafted input, while a novel LSTM architecture, denoted as Dual-Sequence LSTM (DS-LSTM), processes the two mel-spectrograms simultaneously. The outputs are later averaged to produce a final classification of the utterance. Our proposed model achieves, on average, a weighted accuracy of 72.7% and an unweighted accuracy of 73.3% --- a 6% improvement over current state-of-the-art models --- and is comparable with multimodal SER models that leverage textual information.