 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Decidability-Based Loss Function
Sep 12, 2021
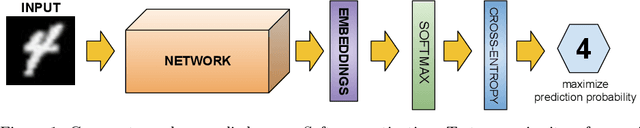
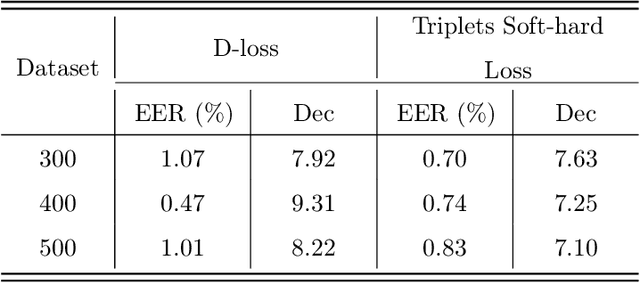
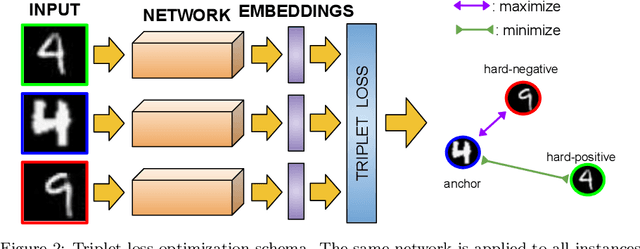

Nowadays, deep learning is the standard approach for a wide range of problems, including biometrics, such as face recognition and speech recognition, etc. Biometric problems often use deep learning models to extract features from images, also known as embeddings. Moreover, the loss function used during training strongly influences the quality of the generated embeddings. In this work, a loss function based on the decidability index is proposed to improve the quality of embeddings for the verification routine. Our proposal, the D-loss, avoids some Triplet-based loss disadvantages such as the use of hard samples and tricky parameter tuning, which can lead to slow convergence. The proposed approach is compared against the Softmax (cross-entropy), Triplets Soft-Hard, and the Multi Similarity losses in four different benchmarks: MNIST, Fashion-MNIST, CIFAR10 and CASIA-IrisV4. The achieved results show the efficacy of the proposal when compared to other popular metrics in the literature. The D-loss computation, besides being simple, non-parametric and easy to implement, favors both the inter-class and intra-class scenarios.
Loss Landscape Dependent Self-Adjusting Learning Rates in Decentralized Stochastic Gradient Descent
Dec 02, 2021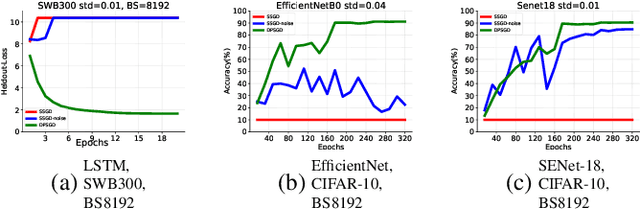
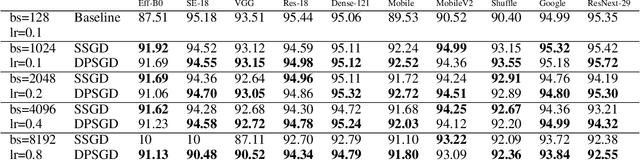
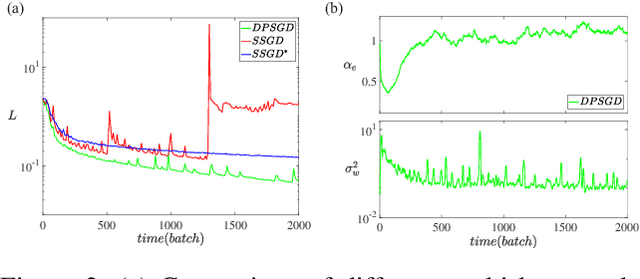
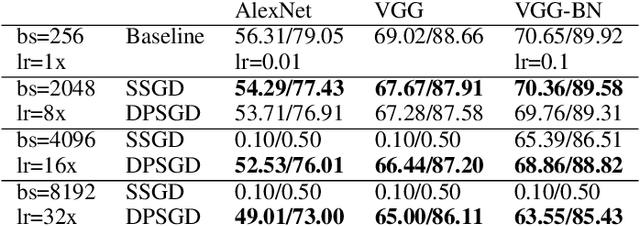
Distributed Deep Learning (DDL) is essential for large-scale Deep Learning (DL) training. Synchronous Stochastic Gradient Descent (SSGD) 1 is the de facto DDL optimization method. Using a sufficiently large batch size is critical to achieving DDL runtime speedup. In a large batch setting, the learning rate must be increased to compensate for the reduced number of parameter updates. However, a large learning rate may harm convergence in SSGD and training could easily diverge. Recently, Decentralized Parallel SGD (DPSGD) has been proposed to improve distributed training speed. In this paper, we find that DPSGD not only has a system-wise run-time benefit but also a significant convergence benefit over SSGD in the large batch setting. Based on a detailed analysis of the DPSGD learning dynamics, we find that DPSGD introduces additional landscape-dependent noise that automatically adjusts the effective learning rate to improve convergence. In addition, we theoretically show that this noise smoothes the loss landscape, hence allowing a larger learning rate. We conduct extensive studies over 18 state-of-the-art DL models/tasks and demonstrate that DPSGD often converges in cases where SSGD diverges for large learning rates in the large batch setting. Our findings are consistent across two different application domains: Computer Vision (CIFAR10 and ImageNet-1K) and Automatic Speech Recognition (SWB300 and SWB2000), and two different types of neural network models: Convolutional Neural Networks and Long Short-Term Memory Recurrent Neural Networks.
What does a network layer hear? Analyzing hidden representations of end-to-end ASR through speech synthesis
Nov 04, 2019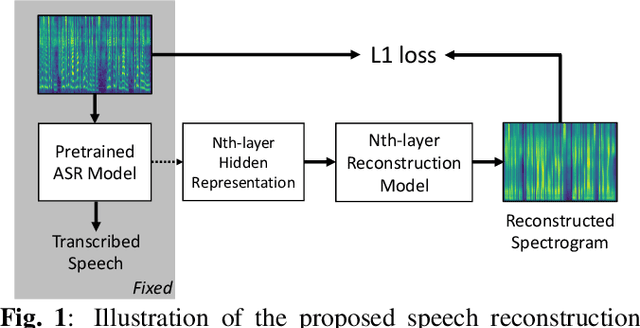
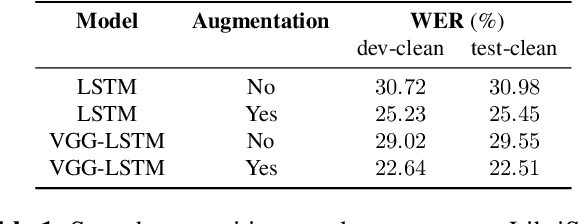
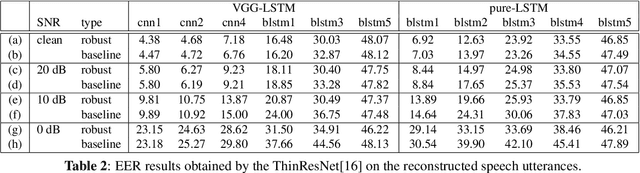
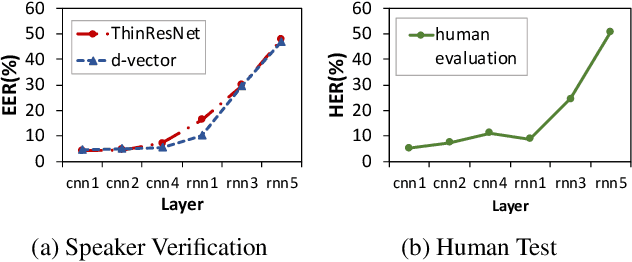
End-to-end speech recognition systems have achieved competitive results compared to traditional systems. However, the complex transformations involved between layers given highly variable acoustic signals are hard to analyze. In this paper, we present our ASR probing model, which synthesizes speech from hidden representations of end-to-end ASR to examine the information maintain after each layer calculation. Listening to the synthesized speech, we observe gradual removal of speaker variability and noise as the layer goes deeper, which aligns with the previous studies on how deep network functions in speech recognition. This paper is the first study analyzing the end-to-end speech recognition model by demonstrating what each layer hears. Speaker verification and speech enhancement measurements on synthesized speech are also conducted to confirm our observation further.
Multi-talker ASR for an unknown number of sources: Joint training of source counting, separation and ASR
Jun 04, 2020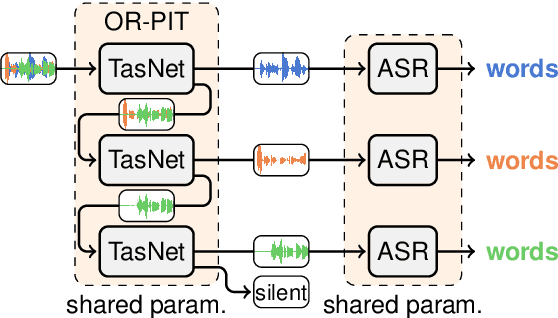
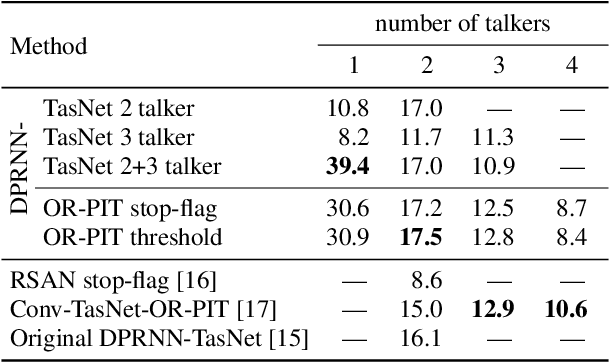
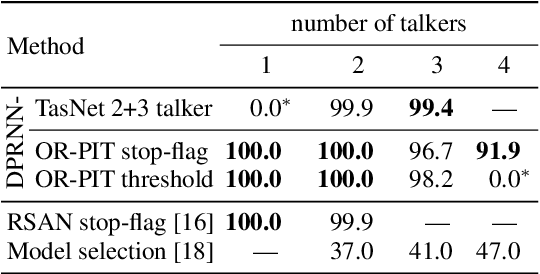
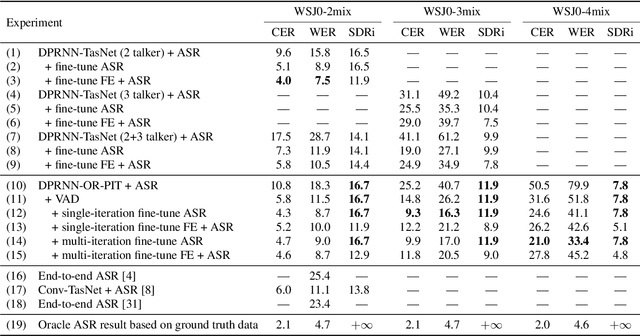
Most approaches to multi-talker overlapped speech separation and recognition assume that the number of simultaneously active speakers is given, but in realistic situations, it is typically unknown. To cope with this, we extend an iterative speech extraction system with mechanisms to count the number of sources and combine it with a single-talker speech recognizer to form the first end-to-end multi-talker automatic speech recognition system for an unknown number of active speakers. Our experiments show very promising performance in counting accuracy, source separation and speech recognition on simulated clean mixtures from WSJ0-2mix and WSJ0-3mix. Among others, we set a new state-of-the-art word error rate on the WSJ0-2mix database. Furthermore, our system generalizes well to a larger number of speakers than it ever saw during training, as shown in experiments with the WSJ0-4mix database.
Binary classification of spoken words with passive elastic metastructures
Nov 14, 2021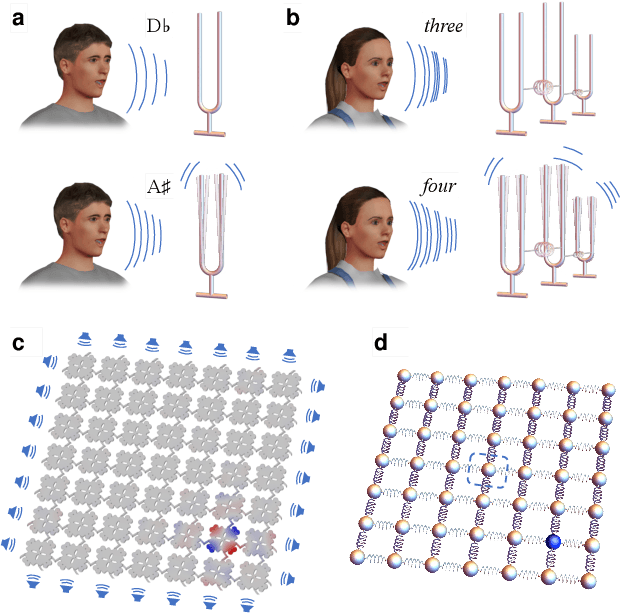
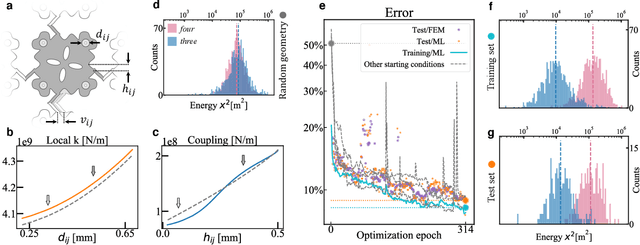
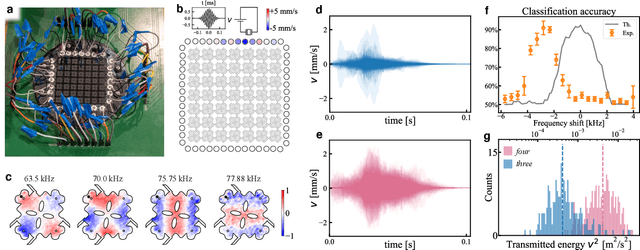
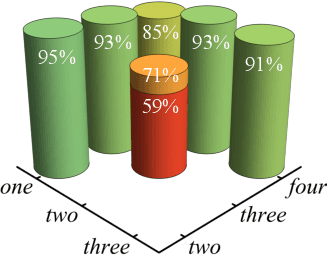
Many electronic devices spend most of their time waiting for a wake-up event: pacemakers waiting for an anomalous heartbeat, security systems on alert to detect an intruder, smartphones listening for the user to say a wake-up phrase. These devices continuously convert physical signals into electrical currents that are then analyzed on a digital computer -- leading to power consumption even when no event is taking place. Solving this problem requires the ability to passively distinguish relevant from irrelevant events (e.g. tell a wake-up phrase from a regular conversation). Here, we experimentally demonstrate an elastic metastructure, consisting of a network of coupled silicon resonators, that passively discriminates between pairs of spoken words -- solving the wake-up problem for scenarios where only two classes of events are possible. This passive speech recognition is demonstrated on a dataset from speakers with significant gender and accent diversity. The geometry of the metastructure is determined during the design process, in which the network of resonators ('mechanical neurones') learns to selectively respond to spoken words. Training is facilitated by a machine learning model that reduces the number of computationally expensive three-dimensional elastic wave simulations. By embedding event detection in the structural dynamics, mechanical neural networks thus enable novel classes of always-on smart devices with no standby power consumption.
Warped Language Models for Noise Robust Language Understanding
Nov 03, 2020
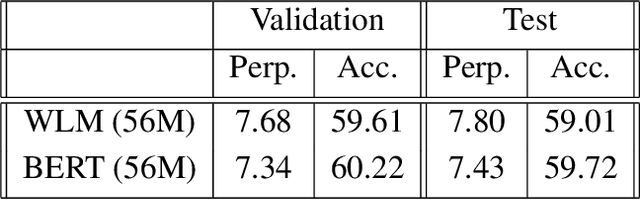
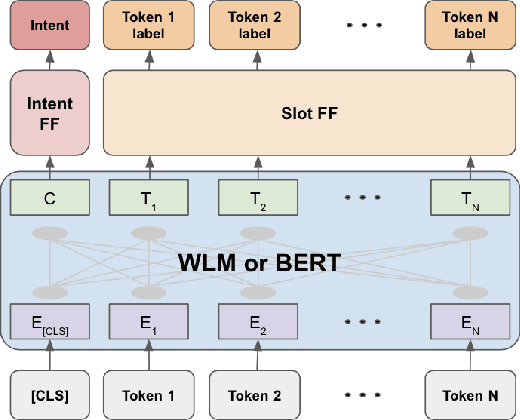
Masked Language Models (MLM) are self-supervised neural networks trained to fill in the blanks in a given sentence with masked tokens. Despite the tremendous success of MLMs for various text based tasks, they are not robust for spoken language understanding, especially for spontaneous conversational speech recognition noise. In this work we introduce Warped Language Models (WLM) in which input sentences at training time go through the same modifications as in MLM, plus two additional modifications, namely inserting and dropping random tokens. These two modifications extend and contract the sentence in addition to the modifications in MLMs, hence the word "warped" in the name. The insertion and drop modification of the input text during training of WLM resemble the types of noise due to Automatic Speech Recognition (ASR) errors, and as a result WLMs are likely to be more robust to ASR noise. Through computational results we show that natural language understanding systems built on top of WLMs perform better compared to those built based on MLMs, especially in the presence of ASR errors.
When Can Self-Attention Be Replaced by Feed Forward Layers?
May 28, 2020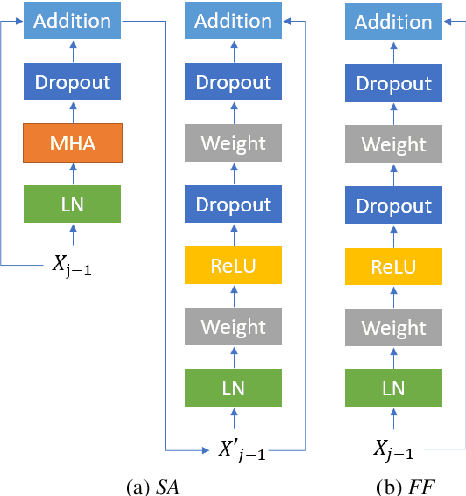
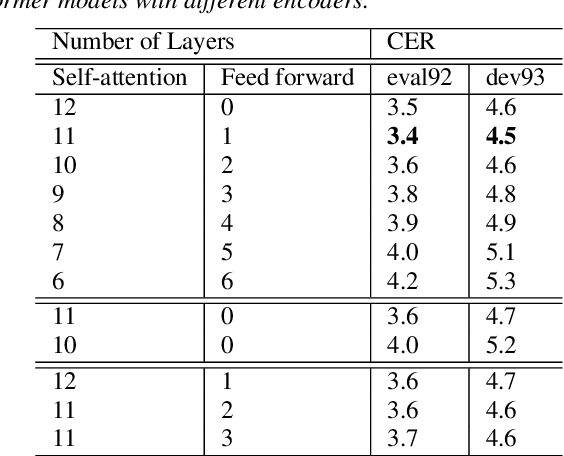

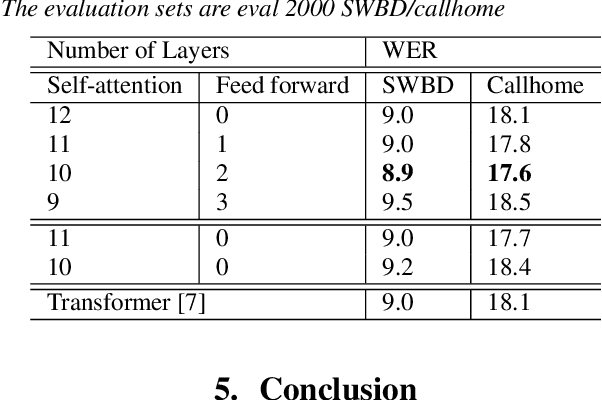
Recently, self-attention models such as Transformers have given competitive results compared to recurrent neural network systems in speech recognition. The key factor for the outstanding performance of self-attention models is their ability to capture temporal relationships without being limited by the distance between two related events. However, we note that the range of the learned context progressively increases from the lower to upper self-attention layers, whilst acoustic events often happen within short time spans in a left-to-right order. This leads to a question: for speech recognition, is a global view of the entire sequence still important for the upper self-attention layers in the encoder of Transformers? To investigate this, we replace these self-attention layers with feed forward layers. In our speech recognition experiments (Wall Street Journal and Switchboard), we indeed observe an interesting result: replacing the upper self-attention layers in the encoder with feed forward layers leads to no performance drop, and even minor gains. Our experiments offer insights to how self-attention layers process the speech signal, leading to the conclusion that the lower self-attention layers of the encoder encode a sufficiently wide range of inputs, hence learning further contextual information in the upper layers is unnecessary.
Cross-Attention End-to-End ASR for Two-Party Conversations
Jul 24, 2019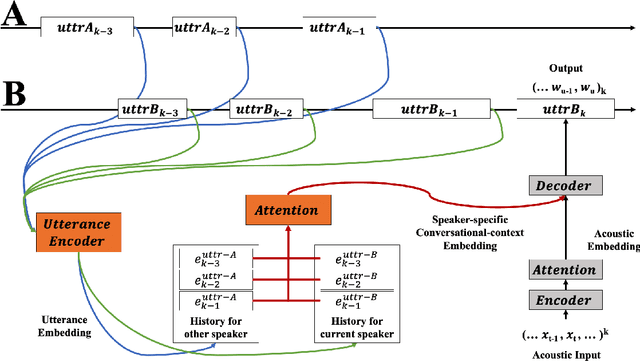
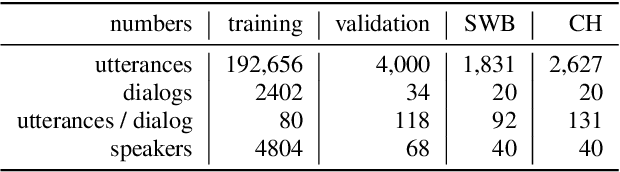
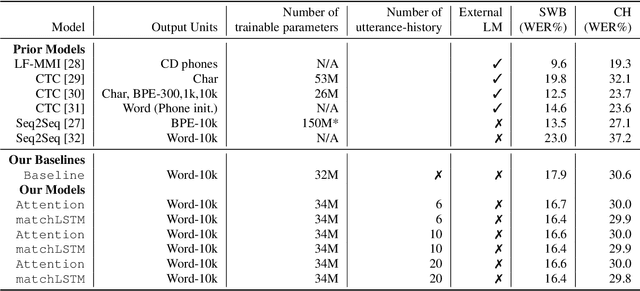
We present an end-to-end speech recognition model that learns interaction between two speakers based on the turn-changing information. Unlike conventional speech recognition models, our model exploits two speakers' history of conversational-context information that spans across multiple turns within an end-to-end framework. Specifically, we propose a speaker-specific cross-attention mechanism that can look at the output of the other speaker side as well as the one of the current speaker for better at recognizing long conversations. We evaluated the models on the Switchboard conversational speech corpus and show that our model outperforms standard end-to-end speech recognition models.
BSTC: A Large-Scale Chinese-English Speech Translation Dataset
Apr 27, 2021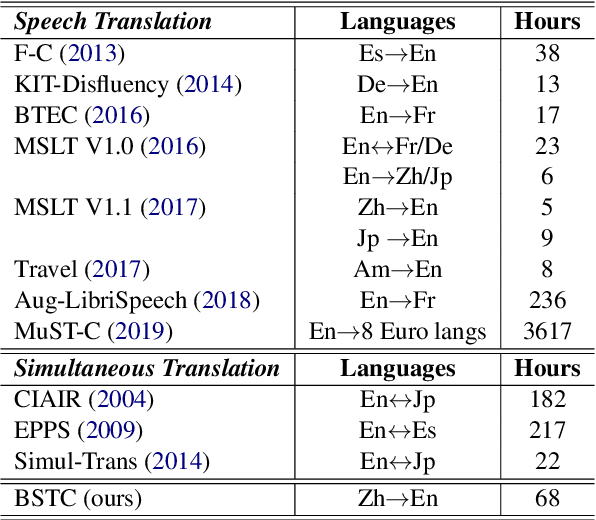
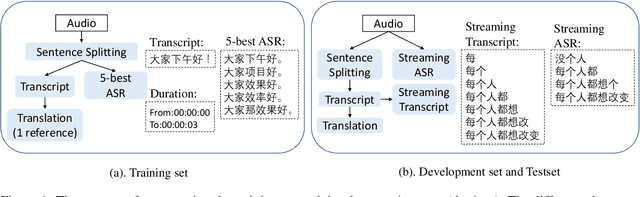

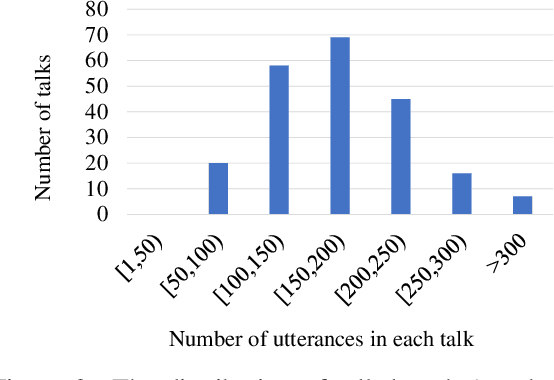
This paper presents BSTC (Baidu Speech Translation Corpus), a large-scale Chinese-English speech translation dataset. This dataset is constructed based on a collection of licensed videos of talks or lectures, including about 68 hours of Mandarin data, their manual transcripts and translations into English, as well as automated transcripts by an automatic speech recognition (ASR) model. We have further asked three experienced interpreters to simultaneously interpret the testing talks in a mock conference setting. This corpus is expected to promote the research of automatic simultaneous translation as well as the development of practical systems. We have organized simultaneous translation tasks and used this corpus to evaluate automatic simultaneous translation systems.
speechocean762: An Open-Source Non-native English Speech Corpus For Pronunciation Assessment
Apr 03, 2021
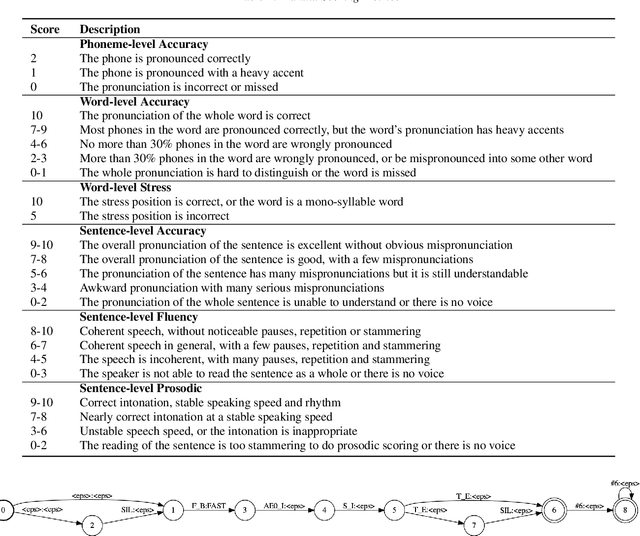
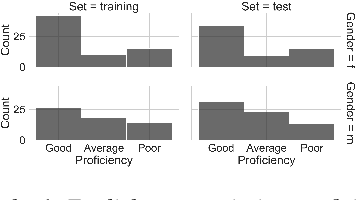

This paper introduces a new open-source speech corpus named "speechocean762" designed for pronunciation assessment use, consisting of 5000 English utterances from 250 non-native speakers, where half of the speakers are children. Five experts annotated each of the utterances at sentence-level, word-level and phoneme-level. A baseline system is released in open source to illustrate the phoneme-level pronunciation assessment workflow on this corpus. This corpus is allowed to be used freely for commercial and non-commercial purposes. It is available for free download from OpenSLR, and the corresponding baseline system is published in the Kaldi speech recognition toolkit.