 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Localization Based Sequential Grouping for Continuous Speech Separation
Jul 14, 2021
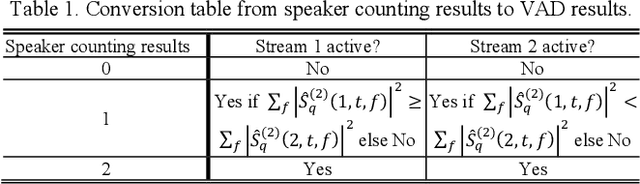
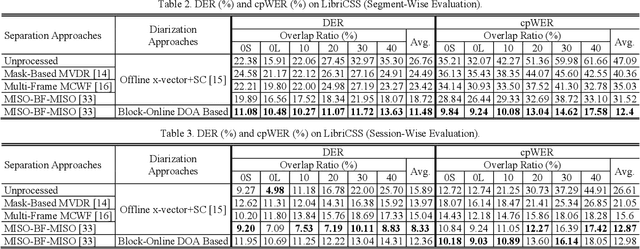
This study investigates robust speaker localization for con-tinuous speech separation and speaker diarization, where we use speaker directions to group non-contiguous segments of the same speaker. Assuming that speakers do not move and are located in different directions, the direction of arrival (DOA) information provides an informative cue for accurate sequential grouping and speaker diarization. Our system is block-online in the following sense. Given a block of frames with at most two speakers, we apply a two-speaker separa-tion model to separate (and enhance) the speakers, estimate the DOA of each separated speaker, and group the separation results across blocks based on the DOA estimates. Speaker diarization and speaker-attributed speech recognition results on the LibriCSS corpus demonstrate the effectiveness of the proposed algorithm.
On Prosody Modeling for ASR+TTS based Voice Conversion
Jul 20, 2021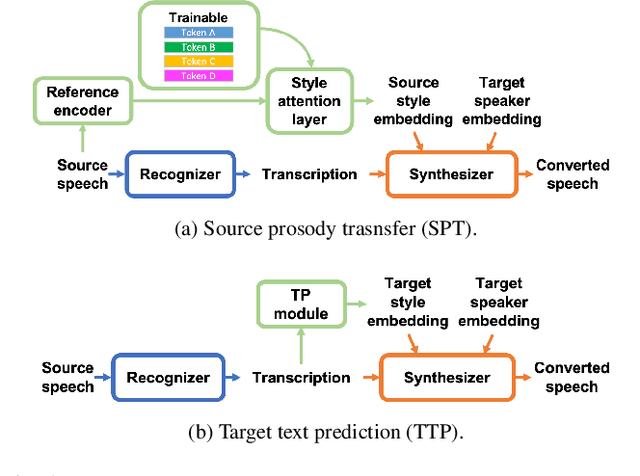

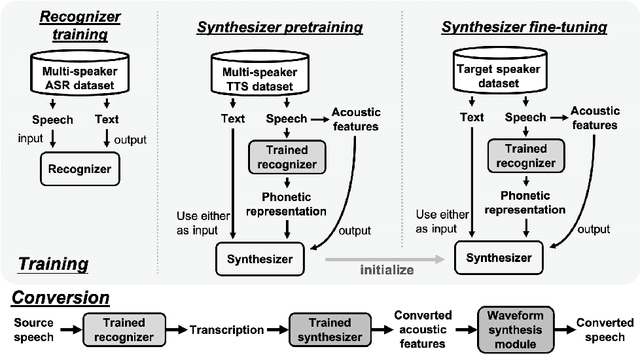

In voice conversion (VC), an approach showing promising results in the latest voice conversion challenge (VCC) 2020 is to first use an automatic speech recognition (ASR) model to transcribe the source speech into the underlying linguistic contents; these are then used as input by a text-to-speech (TTS) system to generate the converted speech. Such a paradigm, referred to as ASR+TTS, overlooks the modeling of prosody, which plays an important role in speech naturalness and conversion similarity. Although some researchers have considered transferring prosodic clues from the source speech, there arises a speaker mismatch during training and conversion. To address this issue, in this work, we propose to directly predict prosody from the linguistic representation in a target-speaker-dependent manner, referred to as target text prediction (TTP). We evaluate both methods on the VCC2020 benchmark and consider different linguistic representations. The results demonstrate the effectiveness of TTP in both objective and subjective evaluations.
DEXTER: Deep Encoding of External Knowledge for Named Entity Recognition in Virtual Assistants
Aug 15, 2021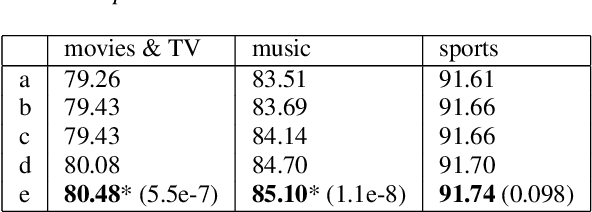
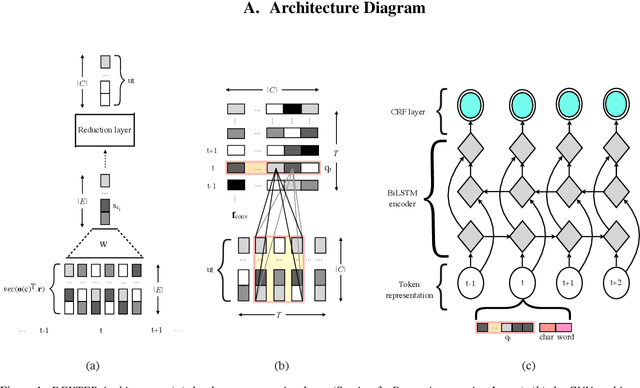
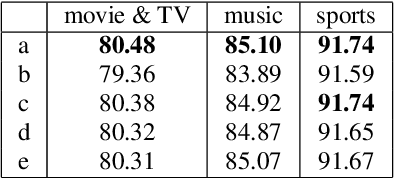
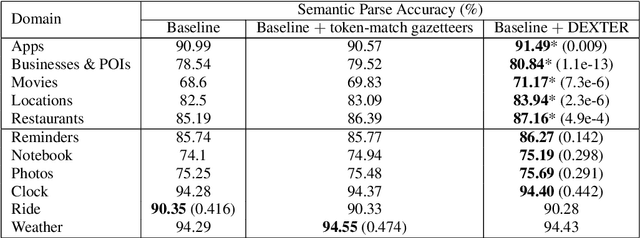
Named entity recognition (NER) is usually developed and tested on text from well-written sources. However, in intelligent voice assistants, where NER is an important component, input to NER may be noisy because of user or speech recognition error. In applications, entity labels may change frequently, and non-textual properties like topicality or popularity may be needed to choose among alternatives. We describe a NER system intended to address these problems. We test and train this system on a proprietary user-derived dataset. We compare with a baseline text-only NER system; the baseline enhanced with external gazetteers; and the baseline enhanced with the search and indirect labelling techniques we describe below. The final configuration gives around 6% reduction in NER error rate. We also show that this technique improves related tasks, such as semantic parsing, with an improvement of up to 5% in error rate.
Detecting Audio Adversarial Examples with Logit Noising
Dec 13, 2021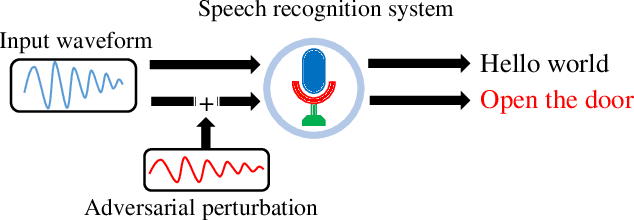


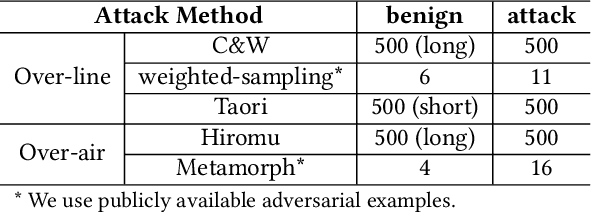
Automatic speech recognition (ASR) systems are vulnerable to audio adversarial examples that attempt to deceive ASR systems by adding perturbations to benign speech signals. Although an adversarial example and the original benign wave are indistinguishable to humans, the former is transcribed as a malicious target sentence by ASR systems. Several methods have been proposed to generate audio adversarial examples and feed them directly into the ASR system (over-line). Furthermore, many researchers have demonstrated the feasibility of robust physical audio adversarial examples(over-air). To defend against the attacks, several studies have been proposed. However, deploying them in a real-world situation is difficult because of accuracy drop or time overhead. In this paper, we propose a novel method to detect audio adversarial examples by adding noise to the logits before feeding them into the decoder of the ASR. We show that carefully selected noise can significantly impact the transcription results of the audio adversarial examples, whereas it has minimal impact on the transcription results of benign audio waves. Based on this characteristic, we detect audio adversarial examples by comparing the transcription altered by logit noising with its original transcription. The proposed method can be easily applied to ASR systems without any structural changes or additional training. The experimental results show that the proposed method is robust to over-line audio adversarial examples as well as over-air audio adversarial examples compared with state-of-the-art detection methods.
CoDERT: Distilling Encoder Representations with Co-learning for Transducer-based Speech Recognition
Jun 14, 2021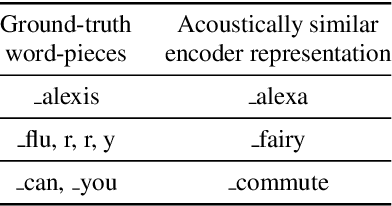
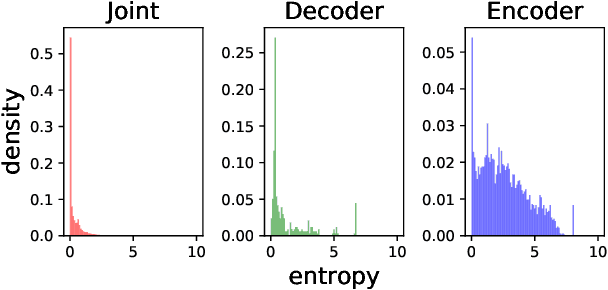
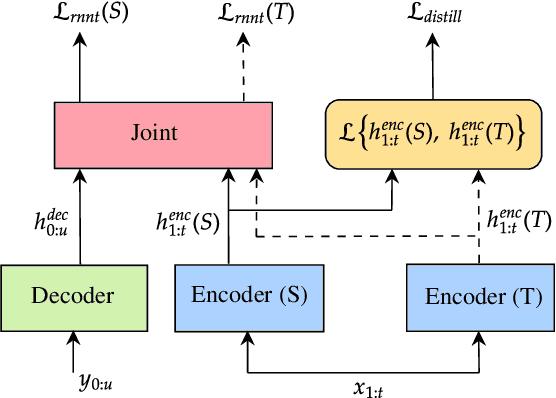
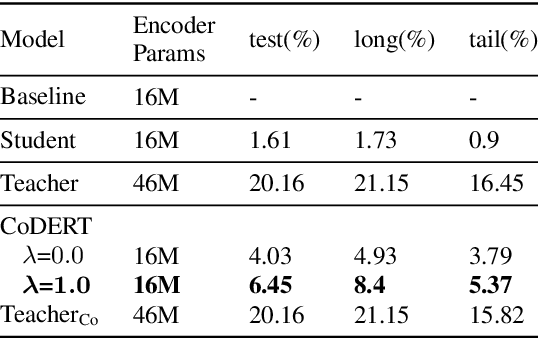
We propose a simple yet effective method to compress an RNN-Transducer (RNN-T) through the well-known knowledge distillation paradigm. We show that the transducer's encoder outputs naturally have a high entropy and contain rich information about acoustically similar word-piece confusions. This rich information is suppressed when combined with the lower entropy decoder outputs to produce the joint network logits. Consequently, we introduce an auxiliary loss to distill the encoder logits from a teacher transducer's encoder, and explore training strategies where this encoder distillation works effectively. We find that tandem training of teacher and student encoders with an inplace encoder distillation outperforms the use of a pre-trained and static teacher transducer. We also report an interesting phenomenon we refer to as implicit distillation, that occurs when the teacher and student encoders share the same decoder. Our experiments show 5.37-8.4% relative word error rate reductions (WERR) on in-house test sets, and 5.05-6.18% relative WERRs on LibriSpeech test sets.
Towards Resistant Audio Adversarial Examples
Oct 14, 2020
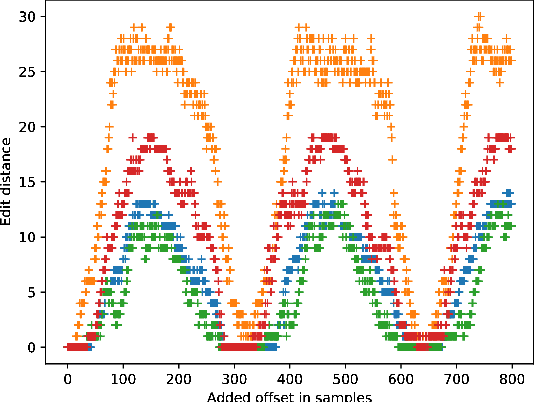

Adversarial examples tremendously threaten the availability and integrity of machine learning-based systems. While the feasibility of such attacks has been observed first in the domain of image processing, recent research shows that speech recognition is also susceptible to adversarial attacks. However, reliably bridging the air gap (i.e., making the adversarial examples work when recorded via a microphone) has so far eluded researchers. We find that due to flaws in the generation process, state-of-the-art adversarial example generation methods cause overfitting because of the binning operation in the target speech recognition system (e.g., Mozilla Deepspeech). We devise an approach to mitigate this flaw and find that our method improves generation of adversarial examples with varying offsets. We confirm the significant improvement with our approach by empirical comparison of the edit distance in a realistic over-the-air setting. Our approach states a significant step towards over-the-air attacks. We publish the code and an applicable implementation of our approach.
A Comprehensive Study of Deep Bidirectional LSTM RNNs for Acoustic Modeling in Speech Recognition
Mar 29, 2017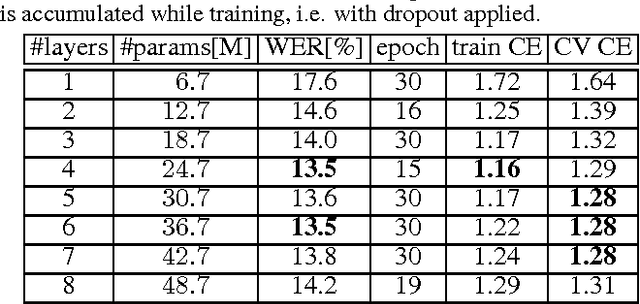
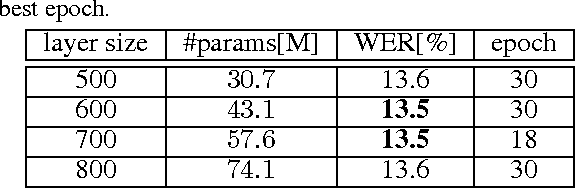
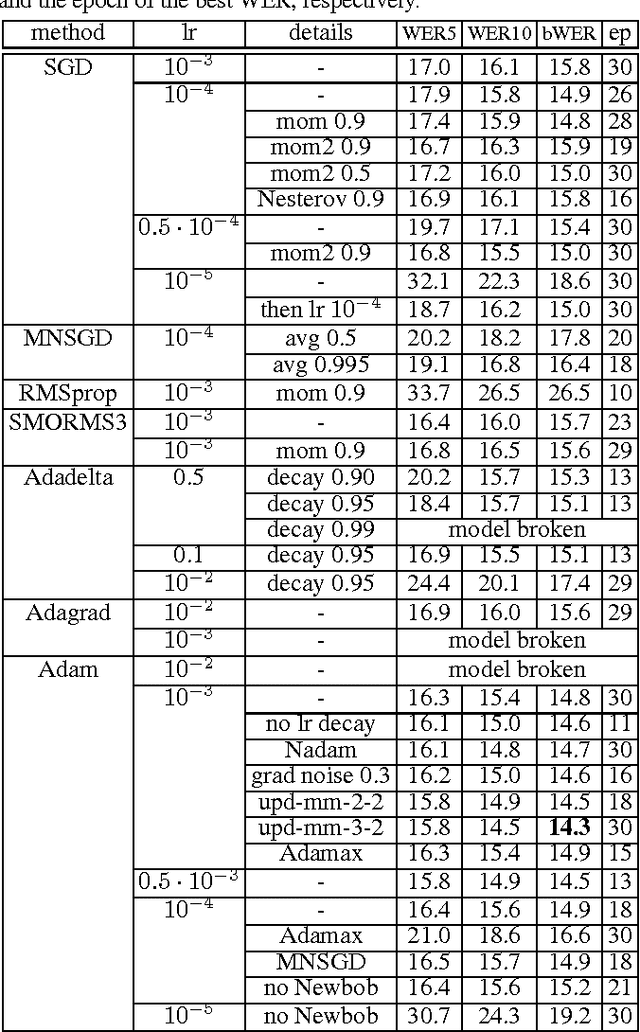
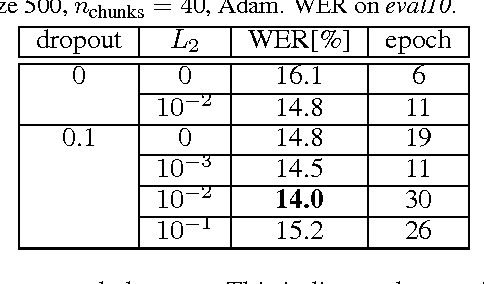
We present a comprehensive study of deep bidirectional long short-term memory (LSTM) recurrent neural network (RNN) based acoustic models for automatic speech recognition (ASR). We study the effect of size and depth and train models of up to 8 layers. We investigate the training aspect and study different variants of optimization methods, batching, truncated backpropagation, different regularization techniques such as dropout and $L_2$ regularization, and different gradient clipping variants. The major part of the experimental analysis was performed on the Quaero corpus. Additional experiments also were performed on the Switchboard corpus. Our best LSTM model has a relative improvement in word error rate of over 14\% compared to our best feed-forward neural network (FFNN) baseline on the Quaero task. On this task, we get our best result with an 8 layer bidirectional LSTM and we show that a pretraining scheme with layer-wise construction helps for deep LSTMs. Finally we compare the training calculation time of many of the presented experiments in relation with recognition performance. All the experiments were done with RETURNN, the RWTH extensible training framework for universal recurrent neural networks in combination with RASR, the RWTH ASR toolkit.
End to End ASR System with Automatic Punctuation Insertion
Dec 03, 2020


Recent Automatic Speech Recognition systems have been moving towards end-to-end systems that can be trained together. Numerous techniques that have been proposed recently enabled this trend, including feature extraction with CNNs, context capturing and acoustic feature modeling with RNNs, automatic alignment of input and output sequences using Connectionist Temporal Classifications, as well as replacing traditional n-gram language models with RNN Language Models. Historically, there has been a lot of interest in automatic punctuation in textual or speech to text context. However, there seems to be little interest in incorporating automatic punctuation into the emerging neural network based end-to-end speech recognition systems, partially due to the lack of English speech corpus with punctuated transcripts. In this study, we propose a method to generate punctuated transcript for the TEDLIUM dataset using transcripts available from ted.com. We also propose an end-to-end ASR system that outputs words and punctuations concurrently from speech signals. Combining Damerau Levenshtein Distance and slot error rate into DLev-SER, we enable measurement of punctuation error rate when the hypothesis text is not perfectly aligned with the reference. Compared with previous methods, our model reduces slot error rate from 0.497 to 0.341.
Cross-domain Single-channel Speech Enhancement Model with Bi-projection Fusion Module for Noise-robust ASR
Aug 26, 2021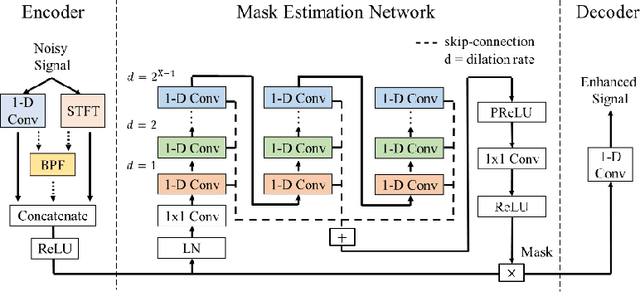
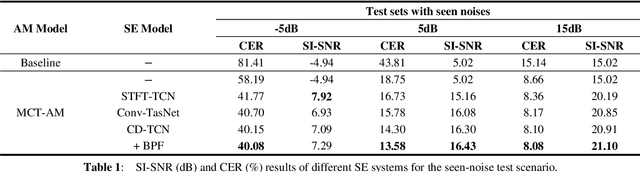
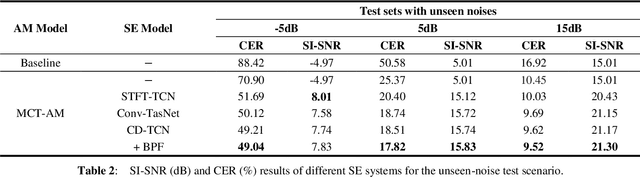
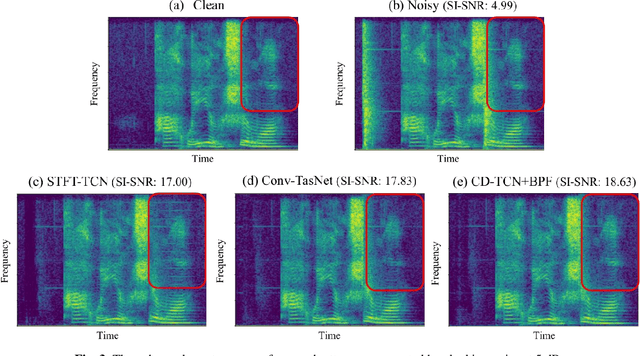
In recent decades, many studies have suggested that phase information is crucial for speech enhancement (SE), and time-domain single-channel speech enhancement techniques have shown promise in noise suppression and robust automatic speech recognition (ASR). This paper presents a continuation of the above lines of research and explores two effective SE methods that consider phase information in time domain and frequency domain of speech signals, respectively. Going one step further, we put forward a novel cross-domain speech enhancement model and a bi-projection fusion (BPF) mechanism for noise-robust ASR. To evaluate the effectiveness of our proposed method, we conduct an extensive set of experiments on the publicly-available Aishell-1 Mandarin benchmark speech corpus. The evaluation results confirm the superiority of our proposed method in relation to a few current top-of-the-line time-domain and frequency-domain SE methods in both enhancement and ASR evaluation metrics for the test set of scenarios contaminated with seen and unseen noise, respectively.
MT3: Multi-Task Multitrack Music Transcription
Nov 04, 2021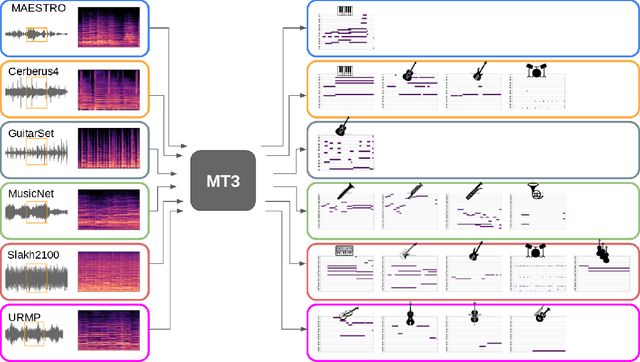

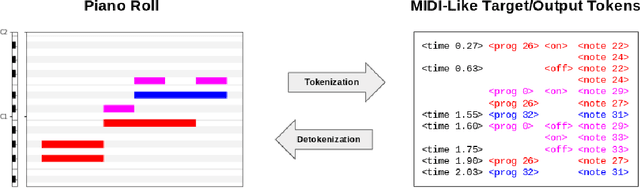
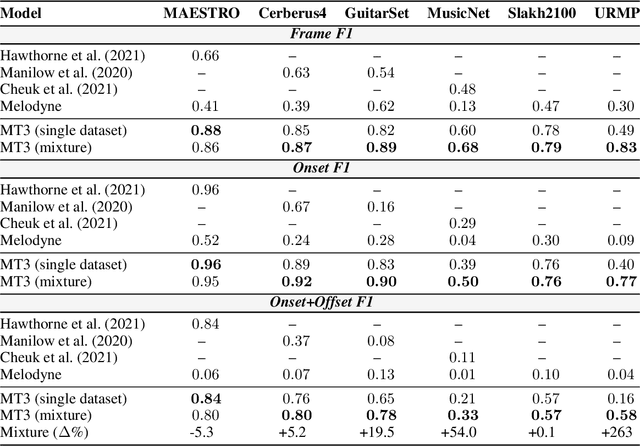
Automatic Music Transcription (AMT), inferring musical notes from raw audio, is a challenging task at the core of music understanding. Unlike Automatic Speech Recognition (ASR), which typically focuses on the words of a single speaker, AMT often requires transcribing multiple instruments simultaneously, all while preserving fine-scale pitch and timing information. Further, many AMT datasets are "low-resource", as even expert musicians find music transcription difficult and time-consuming. Thus, prior work has focused on task-specific architectures, tailored to the individual instruments of each task. In this work, motivated by the promising results of sequence-to-sequence transfer learning for low-resource Natural Language Processing (NLP), we demonstrate that a general-purpose Transformer model can perform multi-task AMT, jointly transcribing arbitrary combinations of musical instruments across several transcription datasets. We show this unified training framework achieves high-quality transcription results across a range of datasets, dramatically improving performance for low-resource instruments (such as guitar), while preserving strong performance for abundant instruments (such as piano). Finally, by expanding the scope of AMT, we expose the need for more consistent evaluation metrics and better dataset alignment, and provide a strong baseline for this new direction of multi-task AMT.