 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
SLUE: New Benchmark Tasks for Spoken Language Understanding Evaluation on Natural Speech
Nov 19, 2021
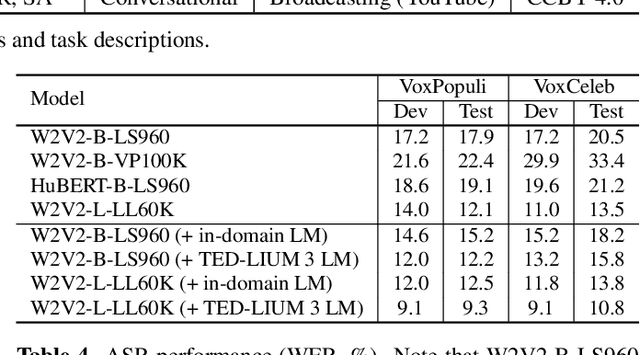
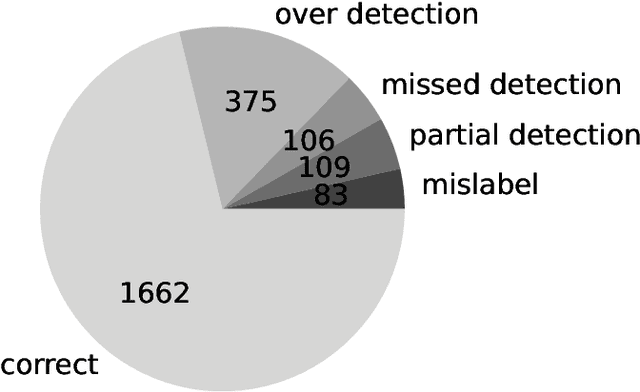
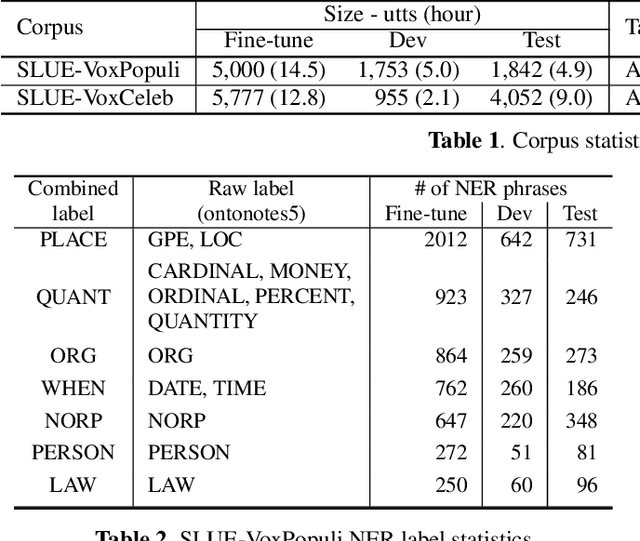
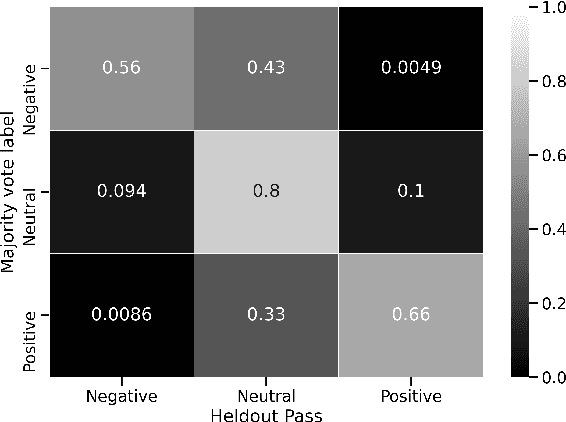
Progress in speech processing has been facilitated by shared datasets and benchmarks. Historically these have focused on automatic speech recognition (ASR), speaker identification, or other lower-level tasks. Interest has been growing in higher-level spoken language understanding tasks, including using end-to-end models, but there are fewer annotated datasets for such tasks. At the same time, recent work shows the possibility of pre-training generic representations and then fine-tuning for several tasks using relatively little labeled data. We propose to create a suite of benchmark tasks for Spoken Language Understanding Evaluation (SLUE) consisting of limited-size labeled training sets and corresponding evaluation sets. This resource would allow the research community to track progress, evaluate pre-trained representations for higher-level tasks, and study open questions such as the utility of pipeline versus end-to-end approaches. We present the first phase of the SLUE benchmark suite, consisting of named entity recognition, sentiment analysis, and ASR on the corresponding datasets. We focus on naturally produced (not read or synthesized) speech, and freely available datasets. We provide new transcriptions and annotations on subsets of the VoxCeleb and VoxPopuli datasets, evaluation metrics and results for baseline models, and an open-source toolkit to reproduce the baselines and evaluate new models.
A Conformer-based ASR Frontend for Joint Acoustic Echo Cancellation, Speech Enhancement and Speech Separation
Nov 18, 2021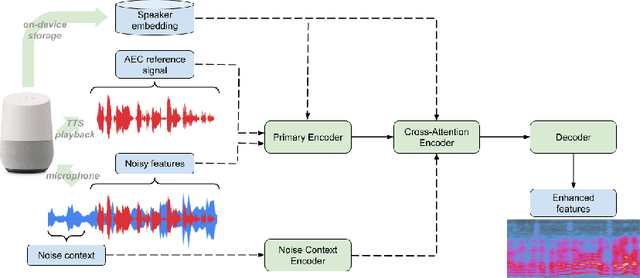
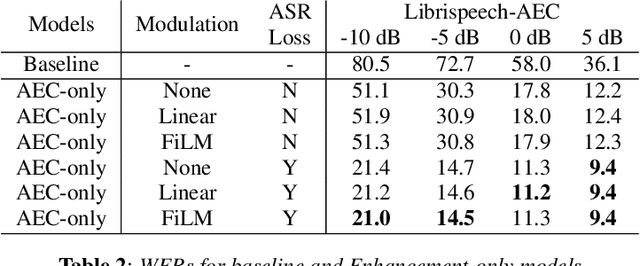
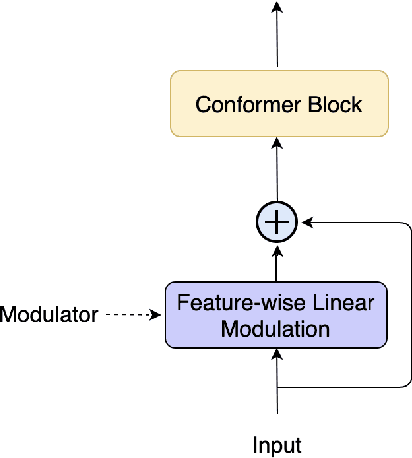
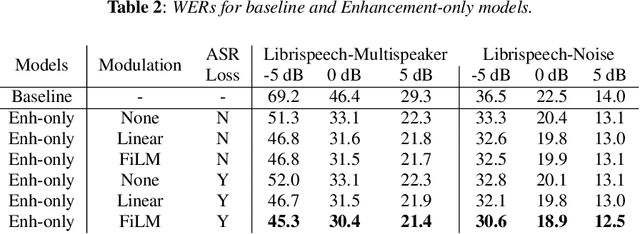
We present a frontend for improving robustness of automatic speech recognition (ASR), that jointly implements three modules within a single model: acoustic echo cancellation, speech enhancement, and speech separation. This is achieved by using a contextual enhancement neural network that can optionally make use of different types of side inputs: (1) a reference signal of the playback audio, which is necessary for echo cancellation; (2) a noise context, which is useful for speech enhancement; and (3) an embedding vector representing the voice characteristic of the target speaker of interest, which is not only critical in speech separation, but also helpful for echo cancellation and speech enhancement. We present detailed evaluations to show that the joint model performs almost as well as the task-specific models, and significantly reduces word error rate in noisy conditions even when using a large-scale state-of-the-art ASR model. Compared to the noisy baseline, the joint model reduces the word error rate in low signal-to-noise ratio conditions by at least 71% on our echo cancellation dataset, 10% on our noisy dataset, and 26% on our multi-speaker dataset. Compared to task-specific models, the joint model performs within 10% on our echo cancellation dataset, 2% on the noisy dataset, and 3% on the multi-speaker dataset.
ASL Trigger Recognition in Mixed Activity/Signing Sequences for RF Sensor-Based User Interfaces
Nov 18, 2021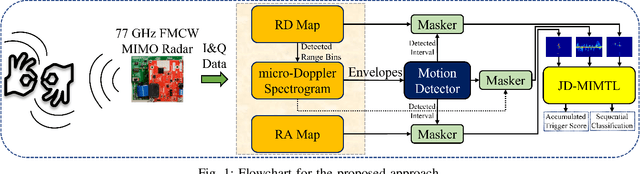

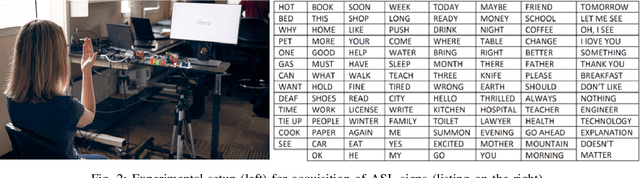
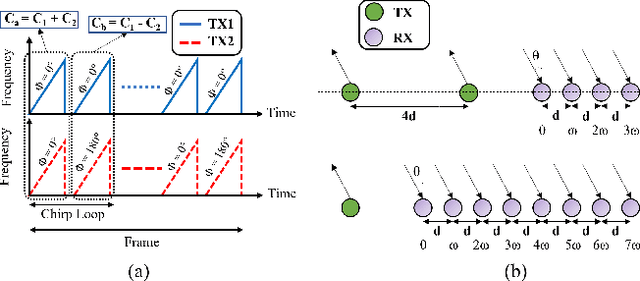
The past decade has seen great advancements in speech recognition for control of interactive devices, personal assistants, and computer interfaces. However, Deaf and hard-ofhearing (HoH) individuals, whose primary mode of communication is sign language, cannot use voice-controlled interfaces. Although there has been significant work in video-based sign language recognition, video is not effective in the dark and has raised privacy concerns in the Deaf community when used in the context of human ambient intelligence. RF sensors have been recently proposed as a new modality that can be effective under the circumstances where video is not. This paper considers the problem of recognizing a trigger sign (wake word) in the context of daily living, where gross motor activities are interwoven with signing sequences. The proposed approach exploits multiple RF data domain representations (time-frequency, range-Doppler, and range-angle) for sequential classification of mixed motion data streams. The recognition accuracy of signs with varying kinematic properties is compared and used to make recommendations on appropriate trigger sign selection for RFsensor based user interfaces. The proposed approach achieves a trigger sign detection rate of 98.9% and a classification accuracy of 92% for 15 ASL words and 3 gross motor activities.
Dual-Encoder Architecture with Encoder Selection for Joint Close-Talk and Far-Talk Speech Recognition
Sep 17, 2021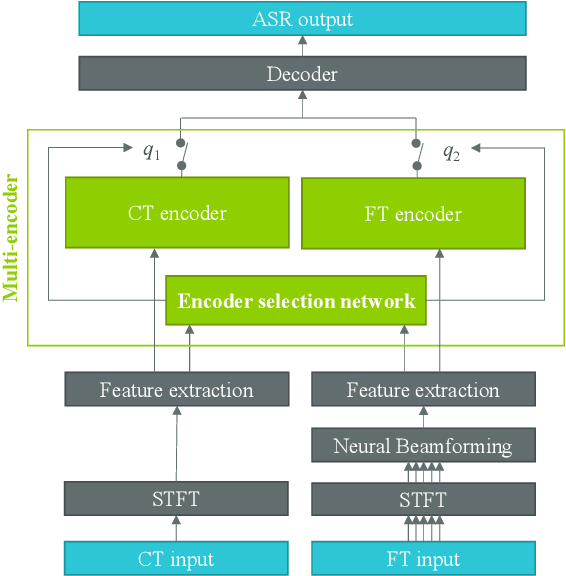

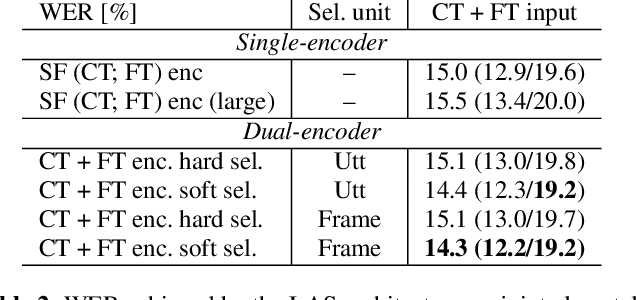
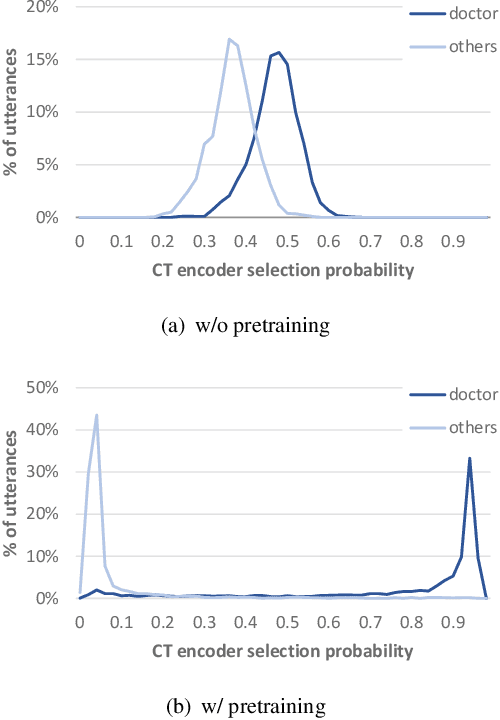
In this paper, we propose a dual-encoder ASR architecture for joint modeling of close-talk (CT) and far-talk (FT) speech, in order to combine the advantages of CT and FT devices for better accuracy. The key idea is to add an encoder selection network to choose the optimal input source (CT or FT) and the corresponding encoder. We use a single-channel encoder for CT speech and a multi-channel encoder with Spatial Filtering neural beamforming for FT speech, which are jointly trained with the encoder selection. We validate our approach on both attention-based and RNN Transducer end-to-end ASR systems. The experiments are done with conversational speech from a medical use case, which is recorded simultaneously with a CT device and a microphone array. Our results show that the proposed dual-encoder architecture obtains up to 9% relative WER reduction when using both CT and FT input, compared to the best single-encoder system trained and tested in matched condition.
Speech Command Recognition in Computationally Constrained Environments with a Quadratic Self-organized Operational Layer
Nov 23, 2020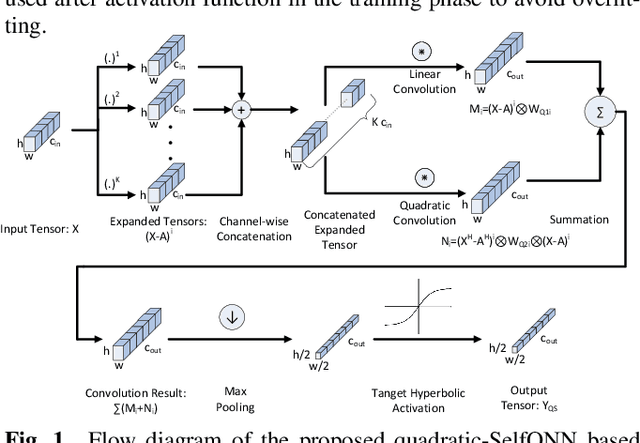
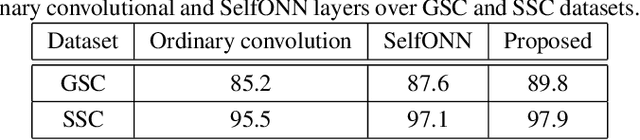
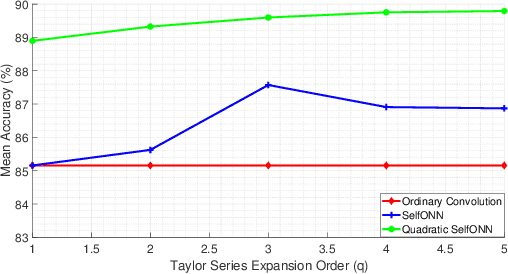
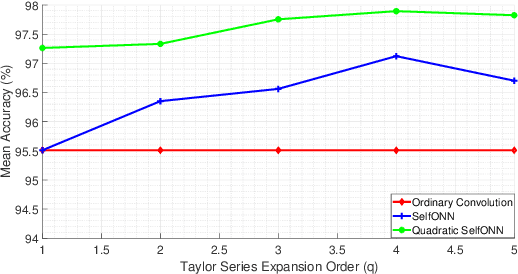
Automatic classification of speech commands has revolutionized human computer interactions in robotic applications. However, employed recognition models usually follow the methodology of deep learning with complicated networks which are memory and energy hungry. So, there is a need to either squeeze these complicated models or use more efficient light-weight models in order to be able to implement the resulting classifiers on embedded devices. In this paper, we pick the second approach and propose a network layer to enhance the speech command recognition capability of a lightweight network and demonstrate the result via experiments. The employed method borrows the ideas of Taylor expansion and quadratic forms to construct a better representation of features in both input and hidden layers. This richer representation results in recognition accuracy improvement as shown by extensive experiments on Google speech commands (GSC) and synthetic speech commands (SSC) datasets.
Reducing Exposure Bias in Training Recurrent Neural Network Transducers
Aug 24, 2021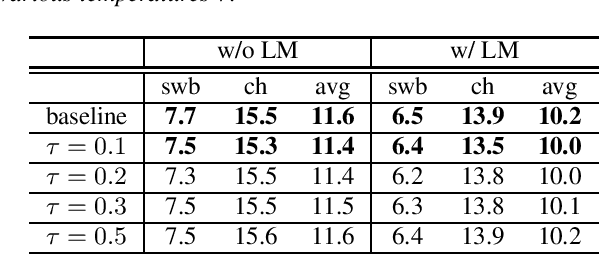
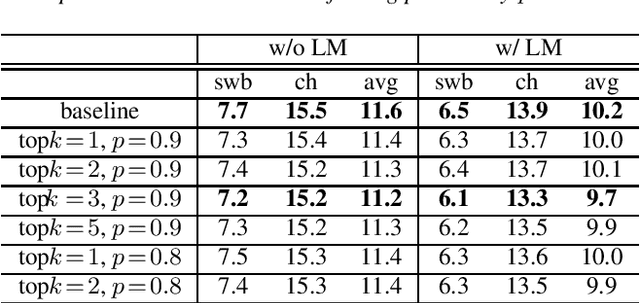
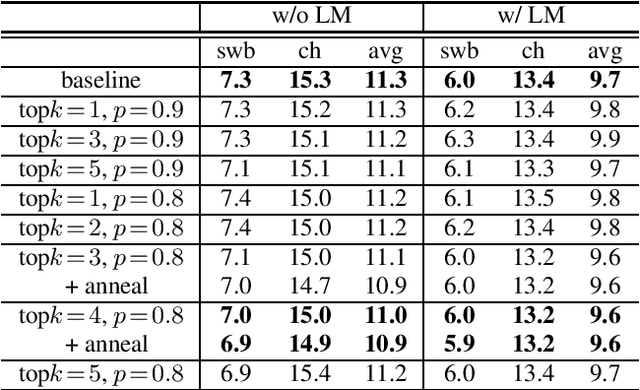
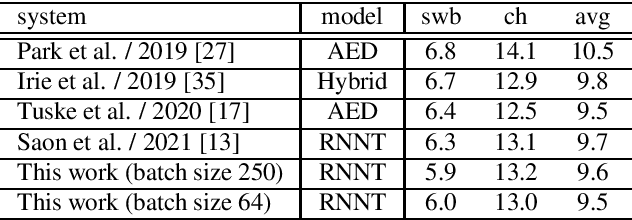
When recurrent neural network transducers (RNNTs) are trained using the typical maximum likelihood criterion, the prediction network is trained only on ground truth label sequences. This leads to a mismatch during inference, known as exposure bias, when the model must deal with label sequences containing errors. In this paper we investigate approaches to reducing exposure bias in training to improve the generalization of RNNT models for automatic speech recognition (ASR). A label-preserving input perturbation to the prediction network is introduced. The input token sequences are perturbed using SwitchOut and scheduled sampling based on an additional token language model. Experiments conducted on the 300-hour Switchboard dataset demonstrate their effectiveness. By reducing the exposure bias, we show that we can further improve the accuracy of a high-performance RNNT ASR model and obtain state-of-the-art results on the 300-hour Switchboard dataset.
Joint Unsupervised and Supervised Training for Multilingual ASR
Nov 15, 2021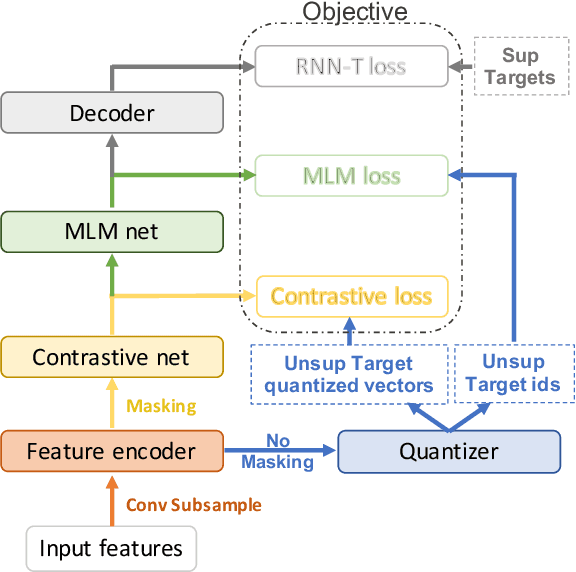
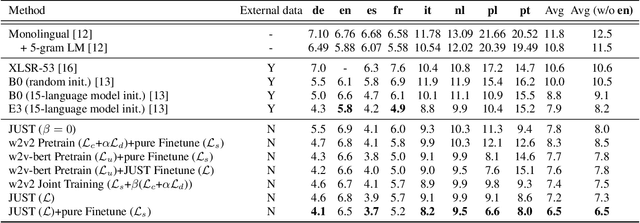
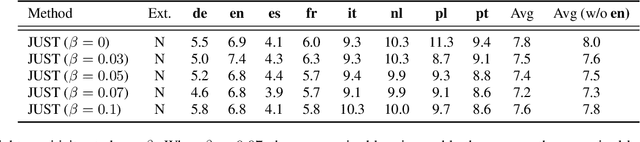
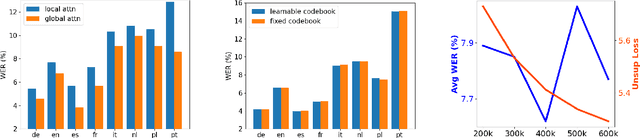
Self-supervised training has shown promising gains in pretraining models and facilitating the downstream finetuning for speech recognition, like multilingual ASR. Most existing methods adopt a 2-stage scheme where the self-supervised loss is optimized in the first pretraining stage, and the standard supervised finetuning resumes in the second stage. In this paper, we propose an end-to-end (E2E) Joint Unsupervised and Supervised Training (JUST) method to combine the supervised RNN-T loss and the self-supervised contrastive and masked language modeling (MLM) losses. We validate its performance on the public dataset Multilingual LibriSpeech (MLS), which includes 8 languages and is extremely imbalanced. On MLS, we explore (1) JUST trained from scratch, and (2) JUST finetuned from a pretrained checkpoint. Experiments show that JUST can consistently outperform other existing state-of-the-art methods, and beat the monolingual baseline by a significant margin, demonstrating JUST's capability of handling low-resource languages in multilingual ASR. Our average WER of all languages outperforms average monolingual baseline by 33.3%, and the state-of-the-art 2-stage XLSR by 32%. On low-resource languages like Polish, our WER is less than half of the monolingual baseline and even beats the supervised transfer learning method which uses external supervision.
Regularizing End-to-End Speech Translation with Triangular Decomposition Agreement
Dec 21, 2021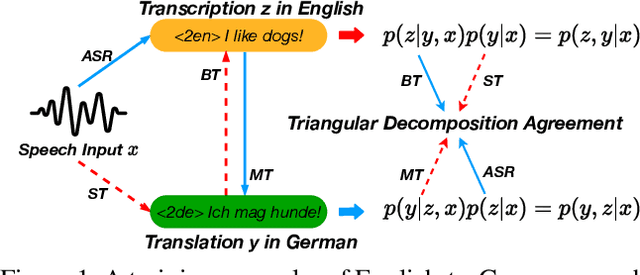
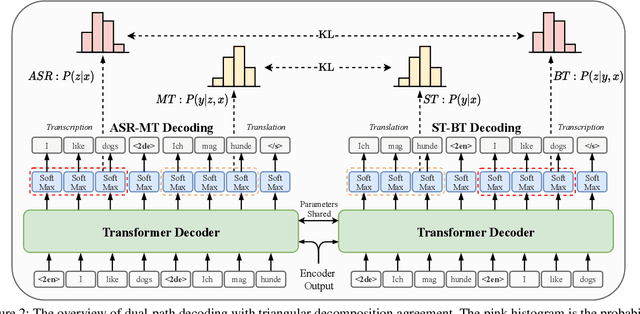
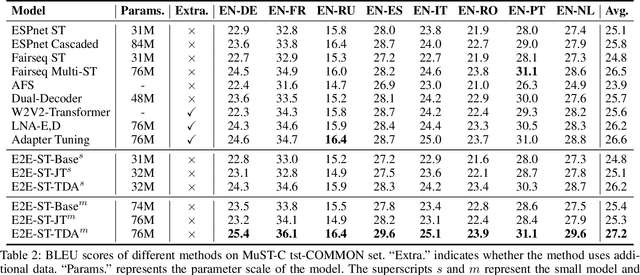
End-to-end speech-to-text translation~(E2E-ST) is becoming increasingly popular due to the potential of its less error propagation, lower latency, and fewer parameters. Given the triplet training corpus $\langle speech, transcription, translation\rangle$, the conventional high-quality E2E-ST system leverages the $\langle speech, transcription\rangle$ pair to pre-train the model and then utilizes the $\langle speech, translation\rangle$ pair to optimize it further. However, this process only involves two-tuple data at each stage, and this loose coupling fails to fully exploit the association between triplet data. In this paper, we attempt to model the joint probability of transcription and translation based on the speech input to directly leverage such triplet data. Based on that, we propose a novel regularization method for model training to improve the agreement of dual-path decomposition within triplet data, which should be equal in theory. To achieve this goal, we introduce two Kullback-Leibler divergence regularization terms into the model training objective to reduce the mismatch between output probabilities of dual-path. Then the well-trained model can be naturally transformed as the E2E-ST models by the pre-defined early stop tag. Experiments on the MuST-C benchmark demonstrate that our proposed approach significantly outperforms state-of-the-art E2E-ST baselines on all 8 language pairs, while achieving better performance in the automatic speech recognition task. Our code is open-sourced at https://github.com/duyichao/E2E-ST-TDA.
Findings from Experiments of On-line Joint Reinforcement Learning of Semantic Parser and Dialogue Manager with real Users
Oct 25, 2021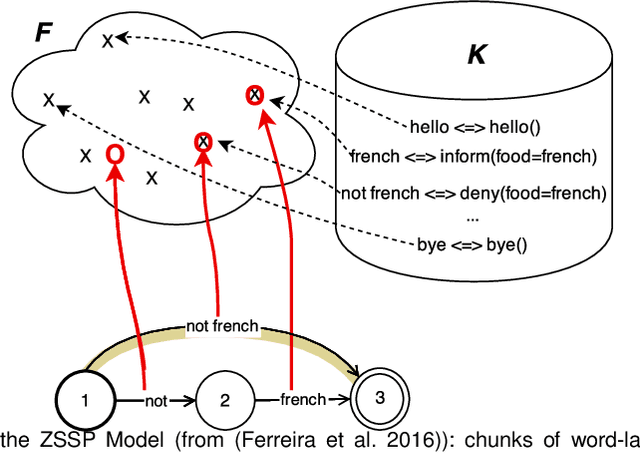
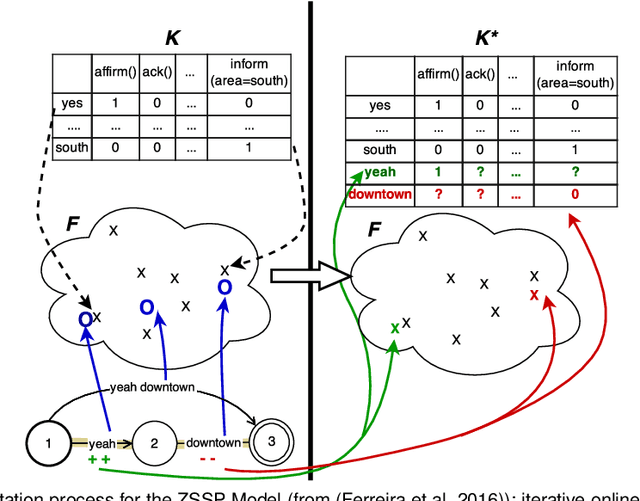

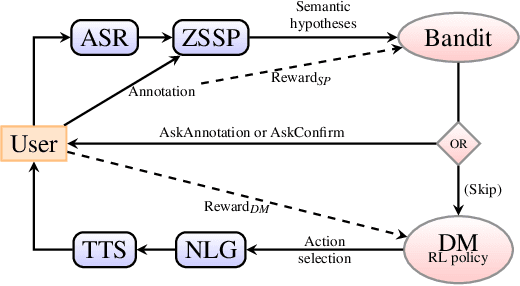
Design of dialogue systems has witnessed many advances lately, yet acquiring huge set of data remains an hindrance to their fast development for a new task or language. Besides, training interactive systems with batch data is not satisfactory. On-line learning is pursued in this paper as a convenient way to alleviate these difficulties. After the system modules are initiated, a single process handles data collection, annotation and use in training algorithms. A new challenge is to control the cost of the on-line learning borne by the user. Our work focuses on learning the semantic parsing and dialogue management modules (speech recognition and synthesis offer ready-for-use solutions). In this context we investigate several variants of simultaneous learning which are tested in user trials. In our experiments, with varying merits, they can all achieve good performance with only a few hundreds of training dialogues and overstep a handcrafted system. The analysis of these experiments gives us some insights, discussed in the paper, into the difficulty for the system's trainers to establish a coherent and constant behavioural strategy to enable a fast and good-quality training phase.
Assessing the Use of Prosody in Constituency Parsing of Imperfect Transcripts
Jun 14, 2021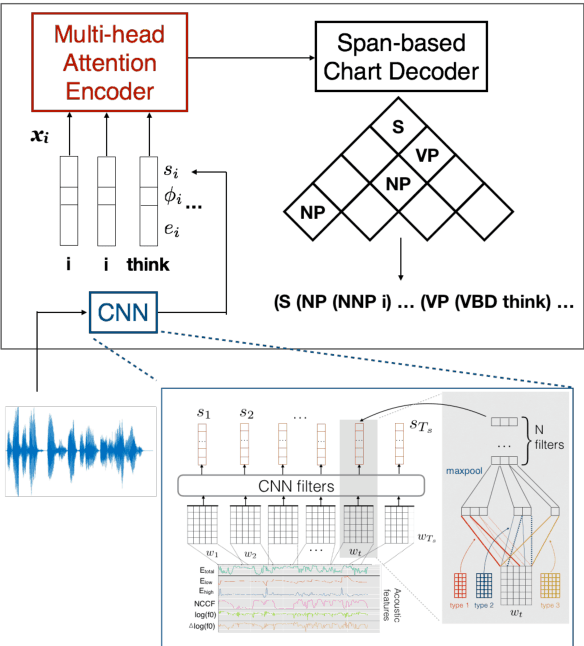
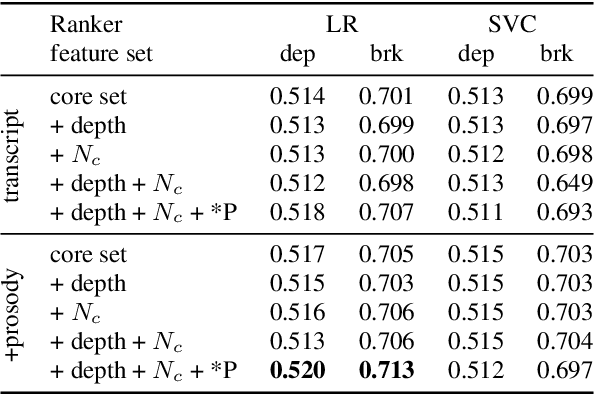
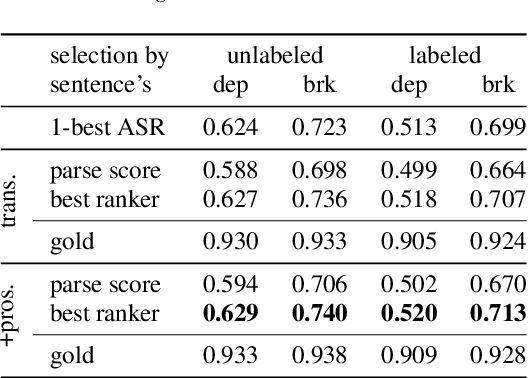
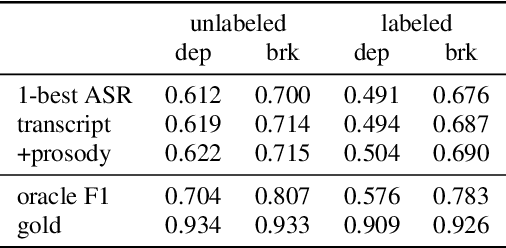
This work explores constituency parsing on automatically recognized transcripts of conversational speech. The neural parser is based on a sentence encoder that leverages word vectors contextualized with prosodic features, jointly learning prosodic feature extraction with parsing. We assess the utility of the prosody in parsing on imperfect transcripts, i.e. transcripts with automatic speech recognition (ASR) errors, by applying the parser in an N-best reranking framework. In experiments on Switchboard, we obtain 13-15% of the oracle N-best gain relative to parsing the 1-best ASR output, with insignificant impact on word recognition error rate. Prosody provides a significant part of the gain, and analyses suggest that it leads to more grammatical utterances via recovering function words.