 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Acoustic-to-Word Models with Conversational Context Information
May 21, 2019
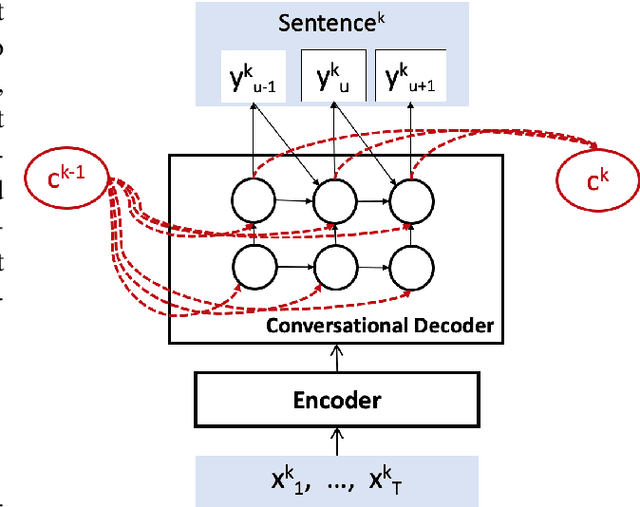
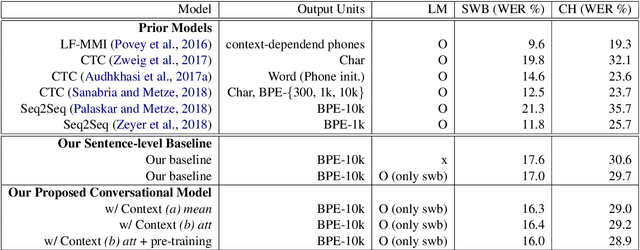
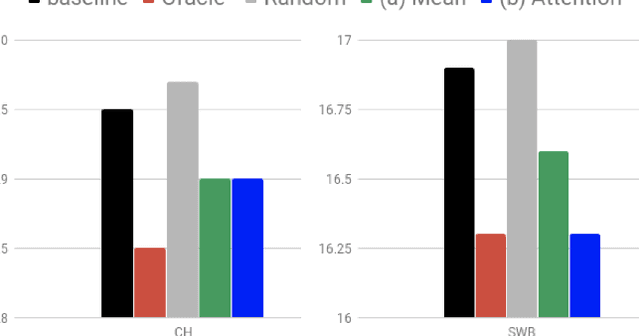
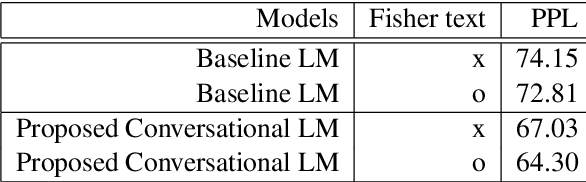
Conversational context information, higher-level knowledge that spans across sentences, can help to recognize a long conversation. However, existing speech recognition models are typically built at a sentence level, and thus it may not capture important conversational context information. The recent progress in end-to-end speech recognition enables integrating context with other available information (e.g., acoustic, linguistic resources) and directly recognizing words from speech. In this work, we present a direct acoustic-to-word, end-to-end speech recognition model capable of utilizing the conversational context to better process long conversations. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a standard end-to-end speech recognition system.
Simultaneous Speech-to-Speech Translation System with Neural Incremental ASR, MT, and TTS
Nov 11, 2020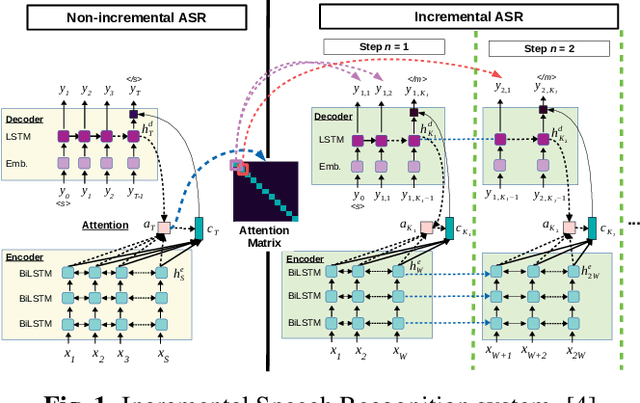
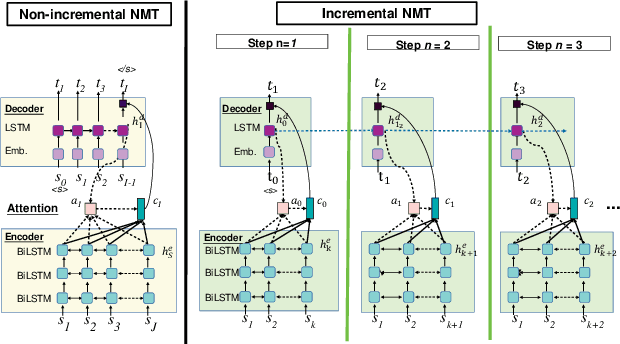
This paper presents a newly developed, simultaneous neural speech-to-speech translation system and its evaluation. The system consists of three fully-incremental neural processing modules for automatic speech recognition (ASR), machine translation (MT), and text-to-speech synthesis (TTS). We investigated its overall latency in the system's Ear-Voice Span and speaking latency along with module-level performance.
Towards Interpretable and Transferable Speech Emotion Recognition: Latent Representation Based Analysis of Features, Methods and Corpora
May 05, 2021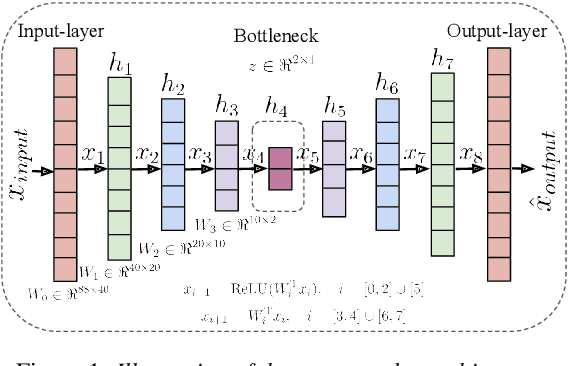
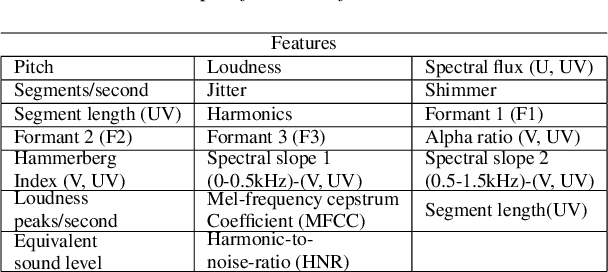
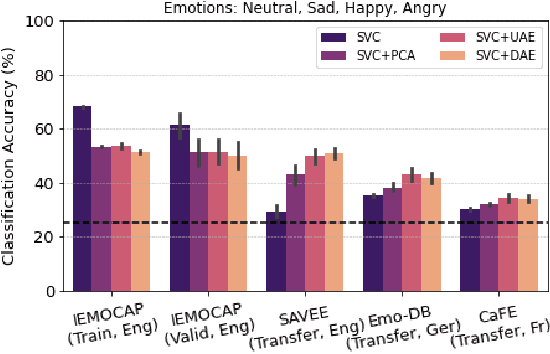
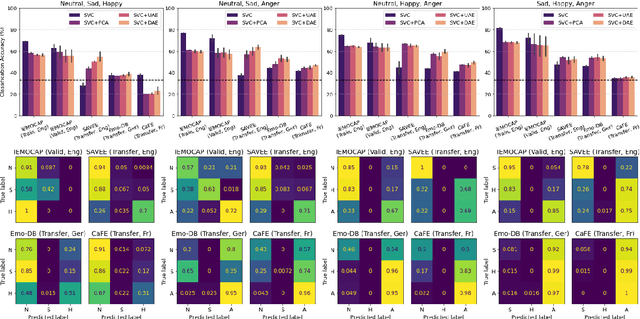
In recent years, speech emotion recognition (SER) has been used in wide ranging applications, from healthcare to the commercial sector. In addition to signal processing approaches, methods for SER now also use deep learning techniques. However, generalizing over languages, corpora and recording conditions is still an open challenge in the field. Furthermore, due to the black-box nature of deep learning algorithms, a newer challenge is the lack of interpretation and transparency in the models and the decision making process. This is critical when the SER systems are deployed in applications that influence human lives. In this work we address this gap by providing an in-depth analysis of the decision making process of the proposed SER system. Towards that end, we present low-complexity SER based on undercomplete- and denoising- autoencoders that achieve an average classification accuracy of over 55\% for four-class emotion classification. Following this, we investigate the clustering of emotions in the latent space to understand the influence of the corpora on the model behavior and to obtain a physical interpretation of the latent embedding. Lastly, we explore the role of each input feature towards the performance of the SER.
iRNN: Integer-only Recurrent Neural Network
Sep 20, 2021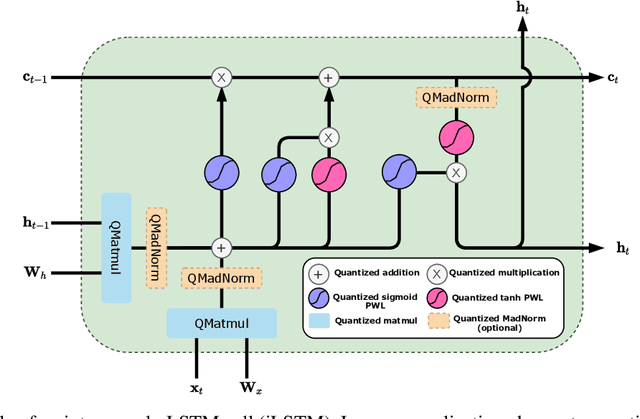

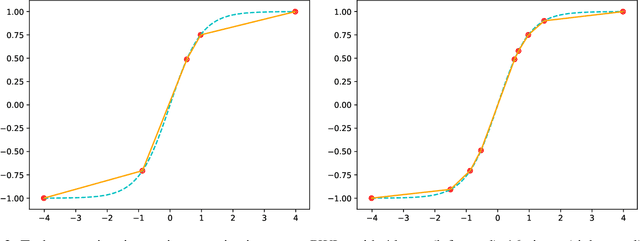

Recurrent neural networks (RNN) are used in many real-world text and speech applications. They include complex modules such as recurrence, exponential-based activation, gate interaction, unfoldable normalization, bi-directional dependence, and attention. The interaction between these elements prevents running them on integer-only operations without a significant performance drop. Deploying RNNs that include layer normalization and attention on integer-only arithmetic is still an open problem. We present a quantization-aware training method for obtaining a highly accurate integer-only recurrent neural network (iRNN). Our approach supports layer normalization, attention, and an adaptive piecewise linear approximation of activations, to serve a wide range of RNNs on various applications. The proposed method is proven to work on RNN-based language models and automatic speech recognition. Our iRNN maintains similar performance as its full-precision counterpart, their deployment on smartphones improves the runtime performance by $2\times$, and reduces the model size by $4\times$.
Omni-sparsity DNN: Fast Sparsity Optimization for On-Device Streaming E2E ASR via Supernet
Oct 15, 2021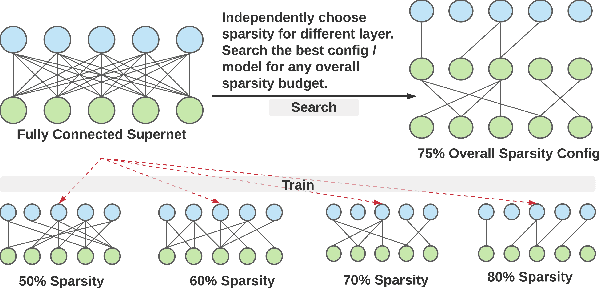
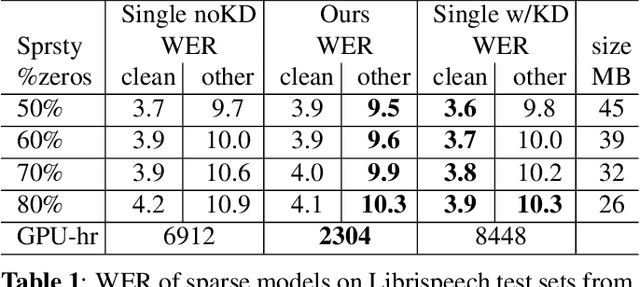
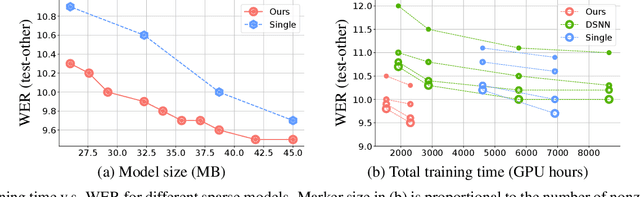
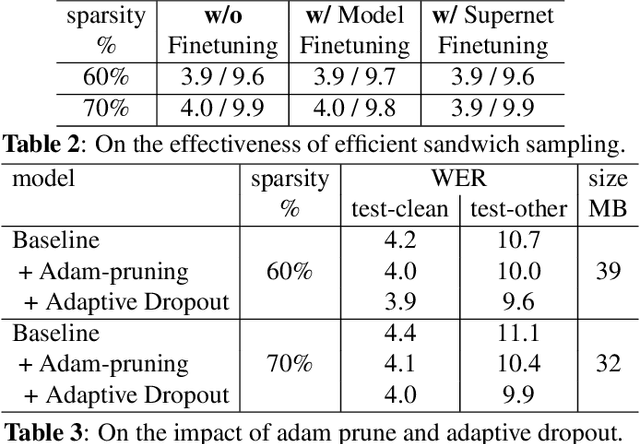
From wearables to powerful smart devices, modern automatic speech recognition (ASR) models run on a variety of edge devices with different computational budgets. To navigate the Pareto front of model accuracy vs model size, researchers are trapped in a dilemma of optimizing model accuracy by training and fine-tuning models for each individual edge device while keeping the training GPU-hours tractable. In this paper, we propose Omni-sparsity DNN, where a single neural network can be pruned to generate optimized model for a large range of model sizes. We develop training strategies for Omni-sparsity DNN that allows it to find models along the Pareto front of word-error-rate (WER) vs model size while keeping the training GPU-hours to no more than that of training one singular model. We demonstrate the Omni-sparsity DNN with streaming E2E ASR models. Our results show great saving on training time and resources with similar or better accuracy on LibriSpeech compared to individually pruned sparse models: 2%-6.6% better WER on Test-other.
Towards Unsupervised Speech Recognition and Synthesis with Quantized Speech Representation Learning
Oct 28, 2019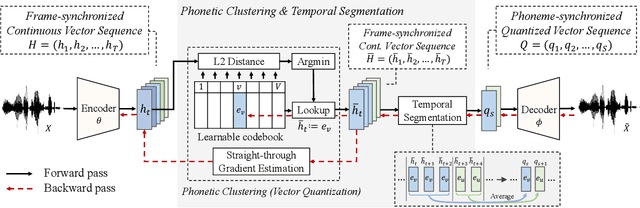
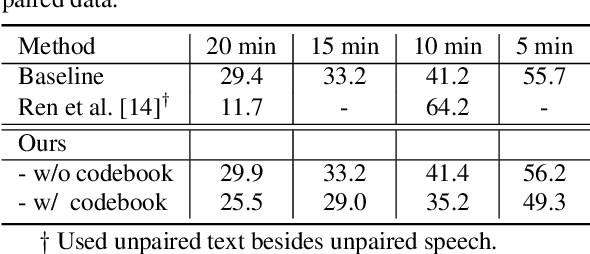
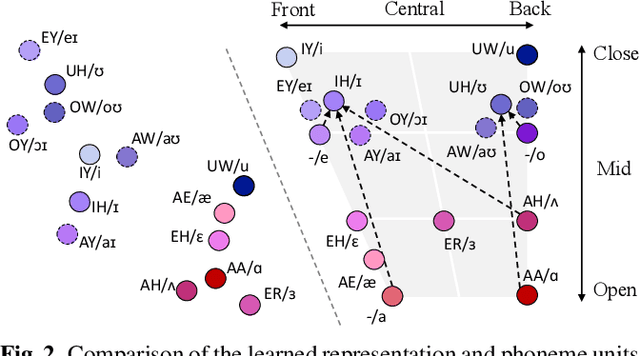
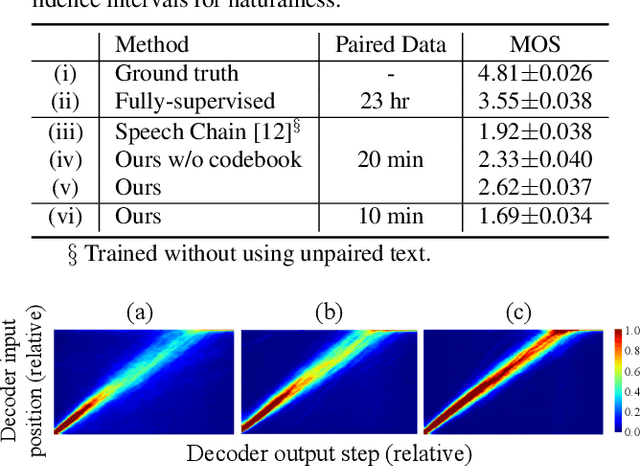
In this paper we propose a Sequential Representation Quantization AutoEncoder (SeqRQ-AE) to learn from primarily unpaired audio data and produce sequences of representations very close to phoneme sequences of speech utterances. This is achieved by proper temporal segmentation to make the representations phoneme-synchronized, and proper phonetic clustering to have total number of distinct representations close to the number of phonemes. Mapping between the distinct representations and phonemes is learned from a small amount of annotated paired data. Preliminary experiments on LJSpeech demonstrated the learned representations for vowels have relative locations in latent space in good parallel to that shown in the IPA vowel chart defined by linguistics experts. With less than 20 minutes of annotated speech, our method outperformed existing methods on phoneme recognition and is able to synthesize intelligible speech that beats our baseline model.
IMS' Systems for the IWSLT 2021 Low-Resource Speech Translation Task
Jun 30, 2021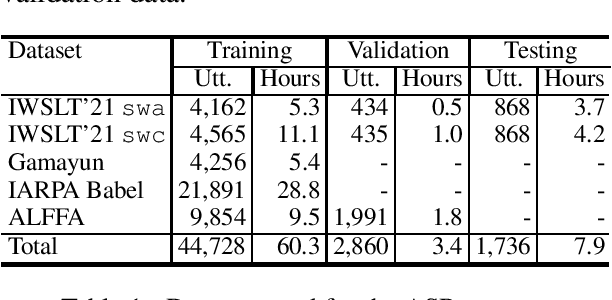
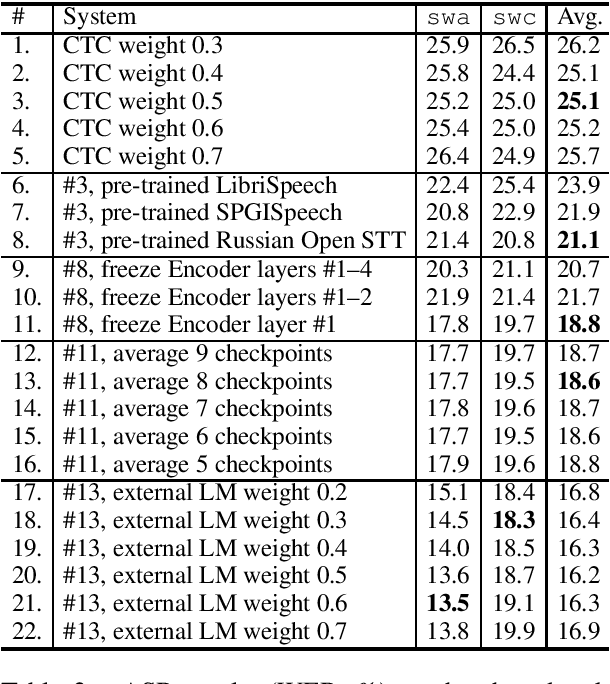
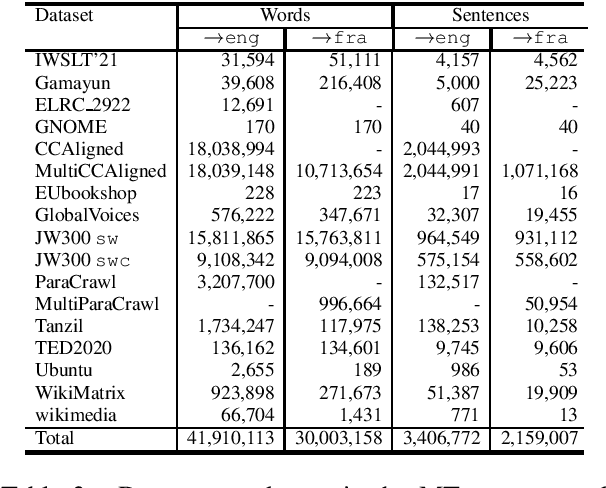
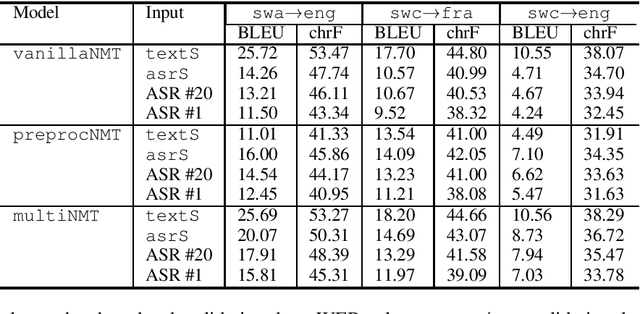
This paper describes the submission to the IWSLT 2021 Low-Resource Speech Translation Shared Task by IMS team. We utilize state-of-the-art models combined with several data augmentation, multi-task and transfer learning approaches for the automatic speech recognition (ASR) and machine translation (MT) steps of our cascaded system. Moreover, we also explore the feasibility of a full end-to-end speech translation (ST) model in the case of very constrained amount of ground truth labeled data. Our best system achieves the best performance among all submitted systems for Congolese Swahili to English and French with BLEU scores 7.7 and 13.7 respectively, and the second best result for Coastal Swahili to English with BLEU score 14.9.
On the Use of External Data for Spoken Named Entity Recognition
Dec 14, 2021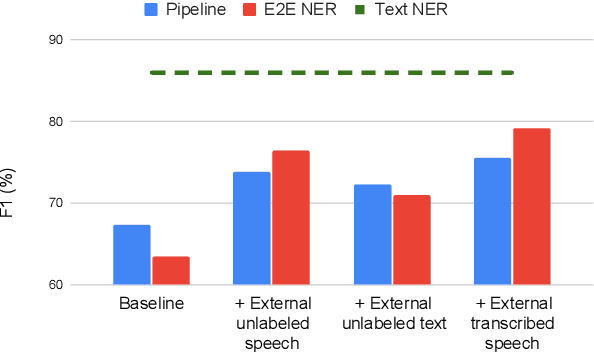

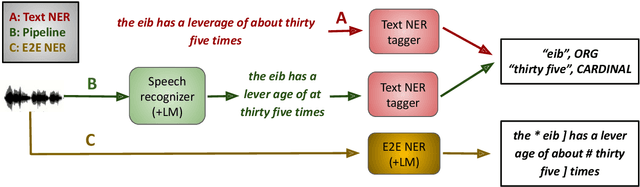
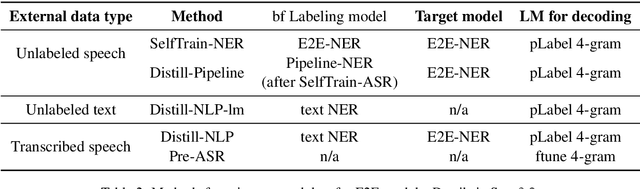
Spoken language understanding (SLU) tasks involve mapping from speech audio signals to semantic labels. Given the complexity of such tasks, good performance might be expected to require large labeled datasets, which are difficult to collect for each new task and domain. However, recent advances in self-supervised speech representations have made it feasible to consider learning SLU models with limited labeled data. In this work we focus on low-resource spoken named entity recognition (NER) and address the question: Beyond self-supervised pre-training, how can we use external speech and/or text data that are not annotated for the task? We draw on a variety of approaches, including self-training, knowledge distillation, and transfer learning, and consider their applicability to both end-to-end models and pipeline (speech recognition followed by text NER model) approaches. We find that several of these approaches improve performance in resource-constrained settings beyond the benefits from pre-trained representations alone. Compared to prior work, we find improved F1 scores of up to 16%. While the best baseline model is a pipeline approach, the best performance when using external data is ultimately achieved by an end-to-end model. We provide detailed comparisons and analyses, showing for example that end-to-end models are able to focus on the more NER-specific words.
From Semi-supervised to Almost-unsupervised Speech Recognition with Very-low Resource by Jointly Learning Phonetic Structures from Audio and Text Embeddings
Apr 10, 2019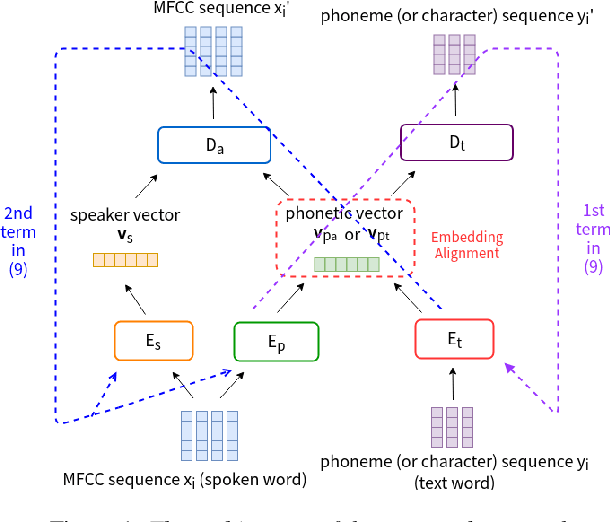
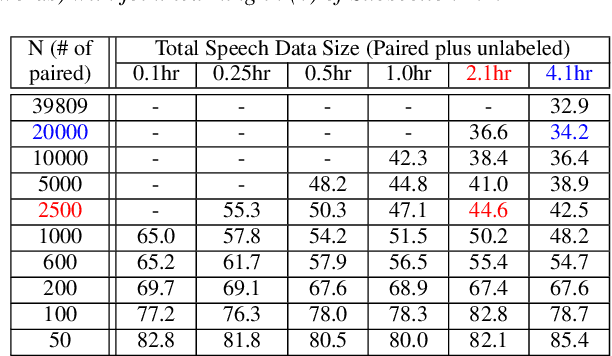
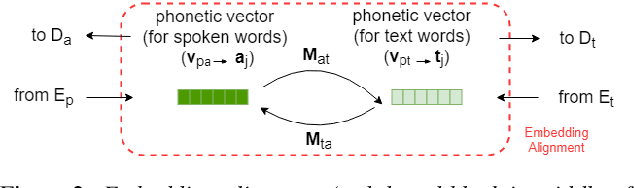

Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds (or phonetic structures) of a small number of exemplar words, and "generalize" such knowledge to other words without hearing a large amount of data. We initiate some preliminary work in this direction. Audio Word2Vec is used to learn the phonetic structures from spoken words (signal segments), while another autoencoder is used to learn the phonetic structures from text words. The relationships among the above two can be learned jointly, or separately after the above two are well trained. This relationship can be used in speech recognition with very low resource. In the initial experiments on the TIMIT dataset, only 2.1 hours of speech data (in which 2500 spoken words were annotated and the rest unlabeled) gave a word error rate of 44.6%, and this number can be reduced to 34.2% if 4.1 hr of speech data (in which 20000 spoken words were annotated) were given. These results are not satisfactory, but a good starting point.
Multilingual Speech Translation with Unified Transformer: Huawei Noah's Ark Lab at IWSLT 2021
Jun 01, 2021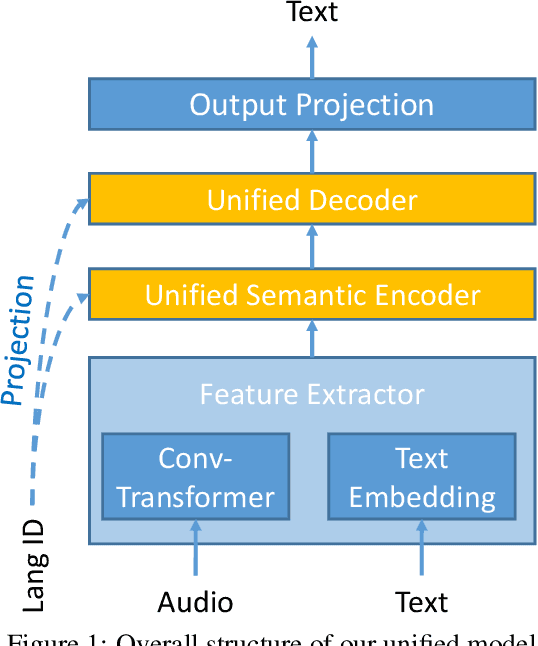
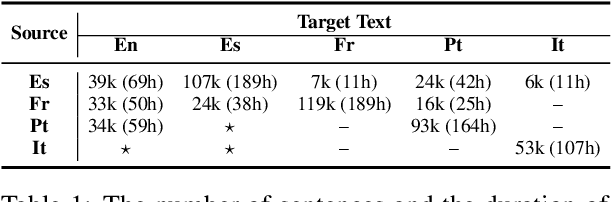
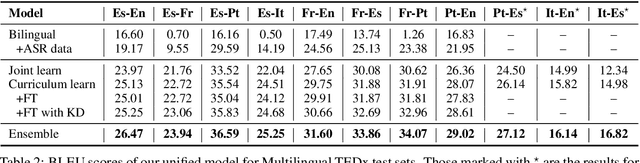
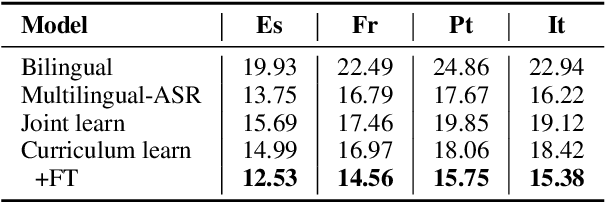
This paper describes the system submitted to the IWSLT 2021 Multilingual Speech Translation (MultiST) task from Huawei Noah's Ark Lab. We use a unified transformer architecture for our MultiST model, so that the data from different modalities (i.e., speech and text) and different tasks (i.e., Speech Recognition, Machine Translation, and Speech Translation) can be exploited to enhance the model's ability. Specifically, speech and text inputs are firstly fed to different feature extractors to extract acoustic and textual features, respectively. Then, these features are processed by a shared encoder--decoder architecture. We apply several training techniques to improve the performance, including multi-task learning, task-level curriculum learning, data augmentation, etc. Our final system achieves significantly better results than bilingual baselines on supervised language pairs and yields reasonable results on zero-shot language pairs.