 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
On the Compression of Recurrent Neural Networks with an Application to LVCSR acoustic modeling for Embedded Speech Recognition
May 02, 2016
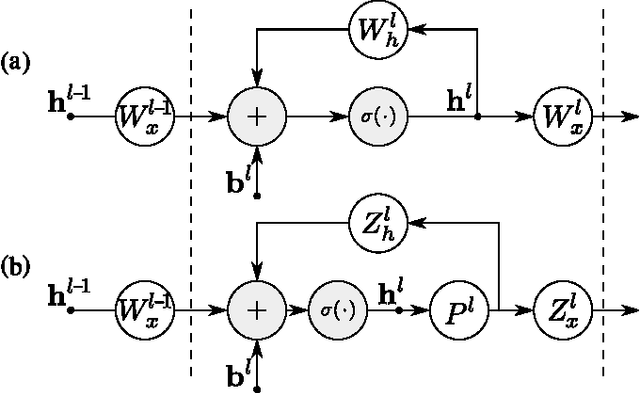
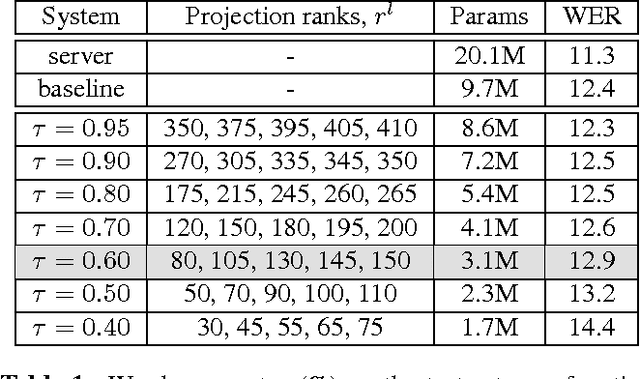
We study the problem of compressing recurrent neural networks (RNNs). In particular, we focus on the compression of RNN acoustic models, which are motivated by the goal of building compact and accurate speech recognition systems which can be run efficiently on mobile devices. In this work, we present a technique for general recurrent model compression that jointly compresses both recurrent and non-recurrent inter-layer weight matrices. We find that the proposed technique allows us to reduce the size of our Long Short-Term Memory (LSTM) acoustic model to a third of its original size with negligible loss in accuracy.
DeepTalk: Vocal Style Encoding for Speaker Recognition and Speech Synthesis
Dec 09, 2020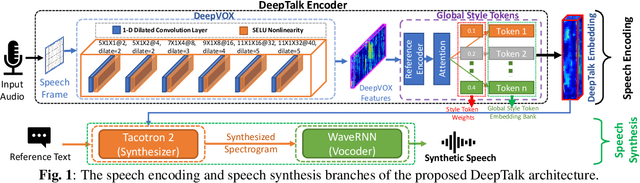
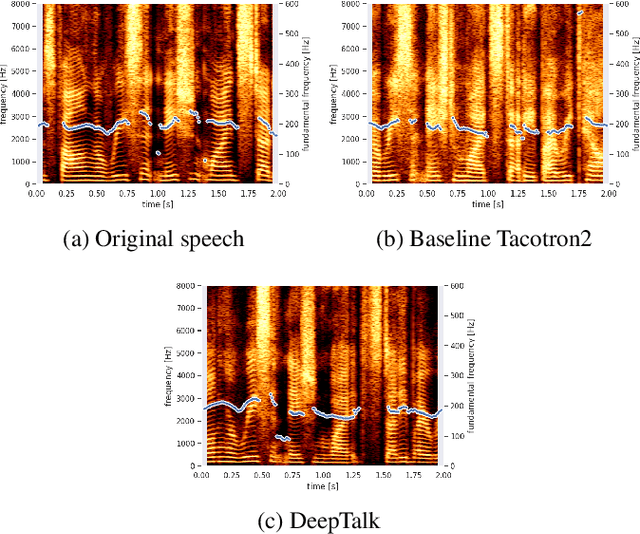
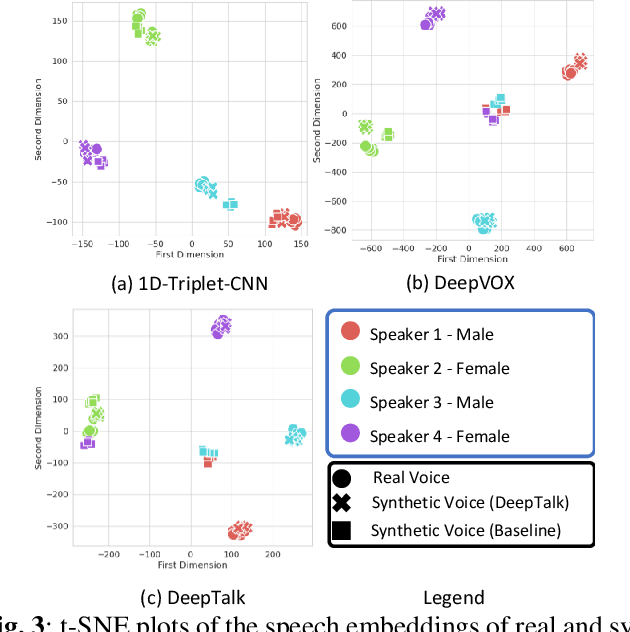
Automatic speaker recognition algorithms typically use physiological speech characteristics encoded in the short term spectral features for characterizing speech audio. Such algorithms do not capitalize on the complementary and discriminative speaker-dependent characteristics present in the behavioral speech features. In this work, we propose a prosody encoding network called DeepTalk for extracting vocal style features directly from raw audio data. The DeepTalk method outperforms several state-of-the-art physiological speech characteristics-based speaker recognition systems across multiple challenging datasets. The speaker recognition performance is further improved by combining DeepTalk with a state-of-the-art physiological speech feature-based speaker recognition system. We also integrate the DeepTalk method into a current state-of-the-art speech synthesizer to generate synthetic speech. A detailed analysis of the synthetic speech shows that the DeepTalk captures F0 contours essential for vocal style modeling. Furthermore, DeepTalk-based synthetic speech is shown to be almost indistinguishable from real speech in the context of speaker recognition.
An Online Multilingual Hate speech Recognition System
Nov 24, 2020

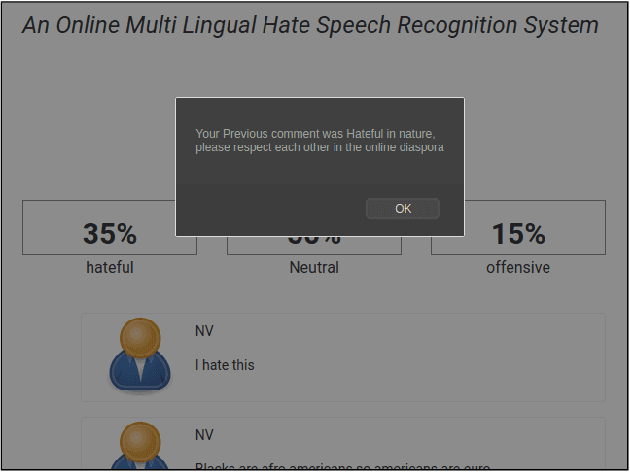
The exponential increase in the use of the Internet and social media over the last two decades has changed human interaction. This has led to many positive outcomes, but at the same time it has brought risks and harms. While the volume of harmful content online, such as hate speech, is not manageable by humans, interest in the academic community to investigate automated means for hate speech detection has increased. In this study, we analyse six publicly available datasets by combining them into a single homogeneous dataset and classify them into three classes, abusive, hateful or neither. We create a baseline model and we improve model performance scores using various optimisation techniques. After attaining a competitive performance score, we create a tool which identifies and scores a page with effective metric in near-real time and uses the same as feedback to re-train our model. We prove the competitive performance of our multilingual model on two langauges, English and Hindi, leading to comparable or superior performance to most monolingual models.
Prediction of Listener Perception of Argumentative Speech in a Crowdsourced Data Using (Psycho-)Linguistic and Fluency Features
Nov 13, 2021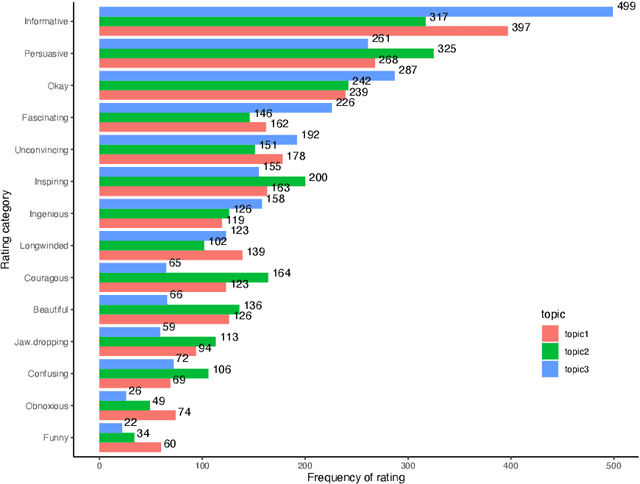
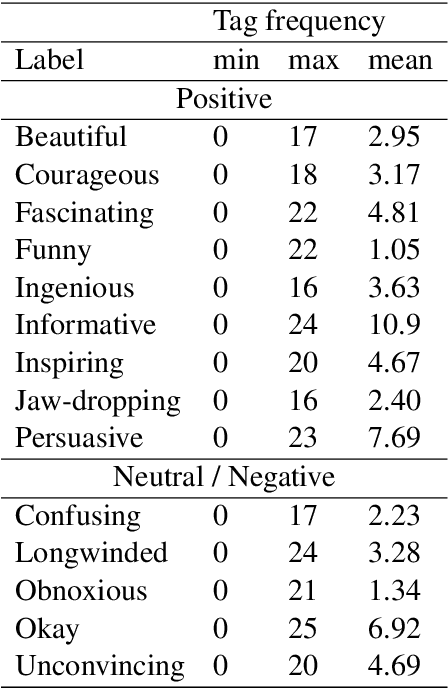
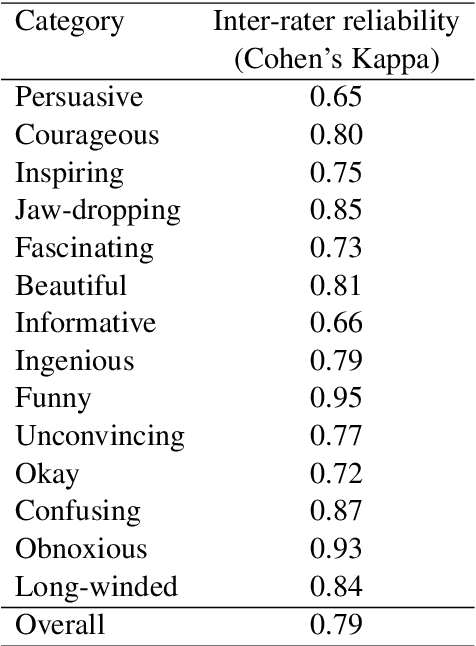

One of the key communicative competencies is the ability to maintain fluency in monologic speech and the ability to produce sophisticated language to argue a position convincingly. In this paper we aim to predict TED talk-style affective ratings in a crowdsourced dataset of argumentative speech consisting of 7 hours of speech from 110 individuals. The speech samples were elicited through task prompts relating to three debating topics. The samples received a total of 2211 ratings from 737 human raters pertaining to 14 affective categories. We present an effective approach to the classification task of predicting these categories through fine-tuning a model pre-trained on a large dataset of TED talks public speeches. We use a combination of fluency features derived from a state-of-the-art automatic speech recognition system and a large set of human-interpretable linguistic features obtained from an automatic text analysis system. Classification accuracy was greater than 60% for all 14 rating categories, with a peak performance of 72% for the rating category 'informative'. In a secondary experiment, we determined the relative importance of features from different groups using SP-LIME.
Bootstrap an end-to-end ASR system by multilingual training, transfer learning, text-to-text mapping and synthetic audio
Nov 25, 2020
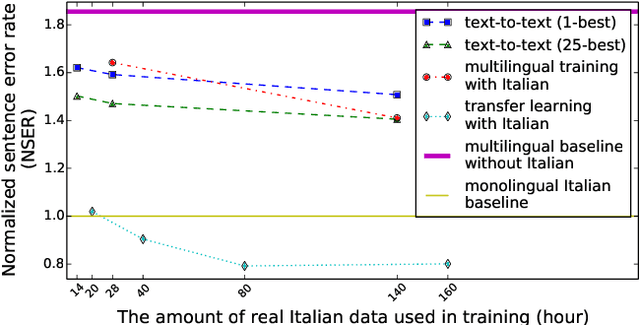
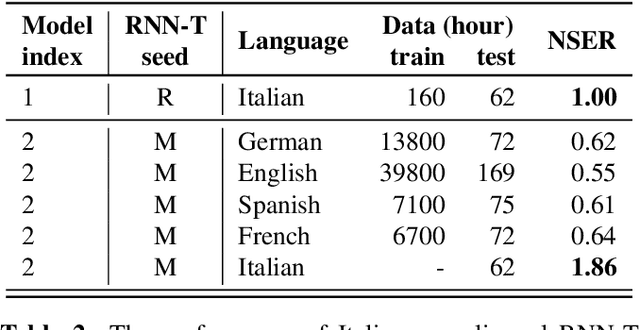
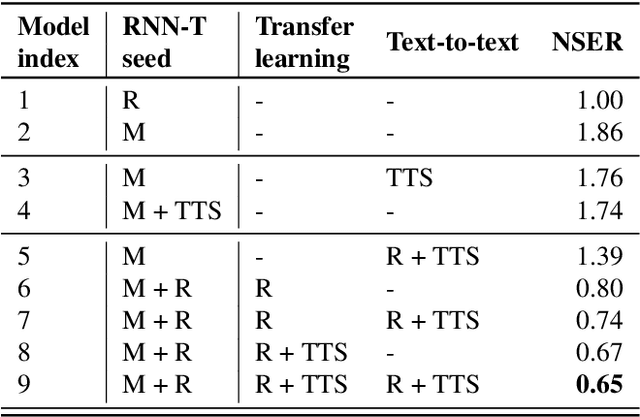
Bootstrapping speech recognition on limited data resources has been an area of active research for long. The recent transition to all-neural models and end-to-end (E2E) training brought along particular challenges as these models are known to be data hungry, but also came with opportunities around language-agnostic representations derived from multilingual data as well as shared word-piece output representations across languages that share script and roots.Here, we investigate the effectiveness of different strategies to bootstrap an RNN Transducer (RNN-T) based automatic speech recognition (ASR) system in the low resource regime,while exploiting the abundant resources available in other languages as well as the synthetic audio from a text-to-speech(TTS) engine. Experiments show that the combination of a multilingual RNN-T word-piece model, post-ASR text-to-text mapping, and synthetic audio can effectively bootstrap an ASR system for a new language in a scalable fashion with little target language data.
SD-QA: Spoken Dialectal Question Answering for the Real World
Sep 24, 2021

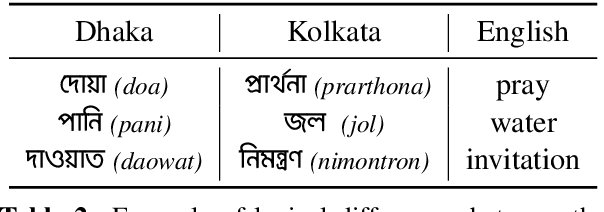
Question answering (QA) systems are now available through numerous commercial applications for a wide variety of domains, serving millions of users that interact with them via speech interfaces. However, current benchmarks in QA research do not account for the errors that speech recognition models might introduce, nor do they consider the language variations (dialects) of the users. To address this gap, we augment an existing QA dataset to construct a multi-dialect, spoken QA benchmark on five languages (Arabic, Bengali, English, Kiswahili, Korean) with more than 68k audio prompts in 24 dialects from 255 speakers. We provide baseline results showcasing the real-world performance of QA systems and analyze the effect of language variety and other sensitive speaker attributes on downstream performance. Last, we study the fairness of the ASR and QA models with respect to the underlying user populations. The dataset, model outputs, and code for reproducing all our experiments are available: https://github.com/ffaisal93/SD-QA.
Common Voice: A Massively-Multilingual Speech Corpus
Dec 13, 2019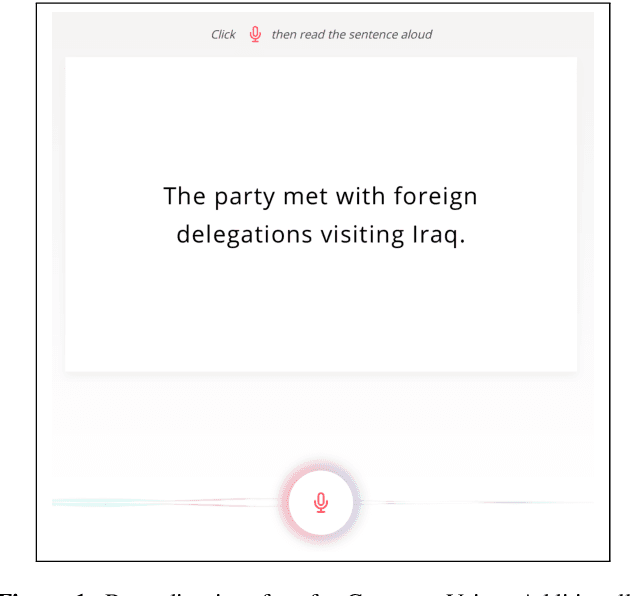
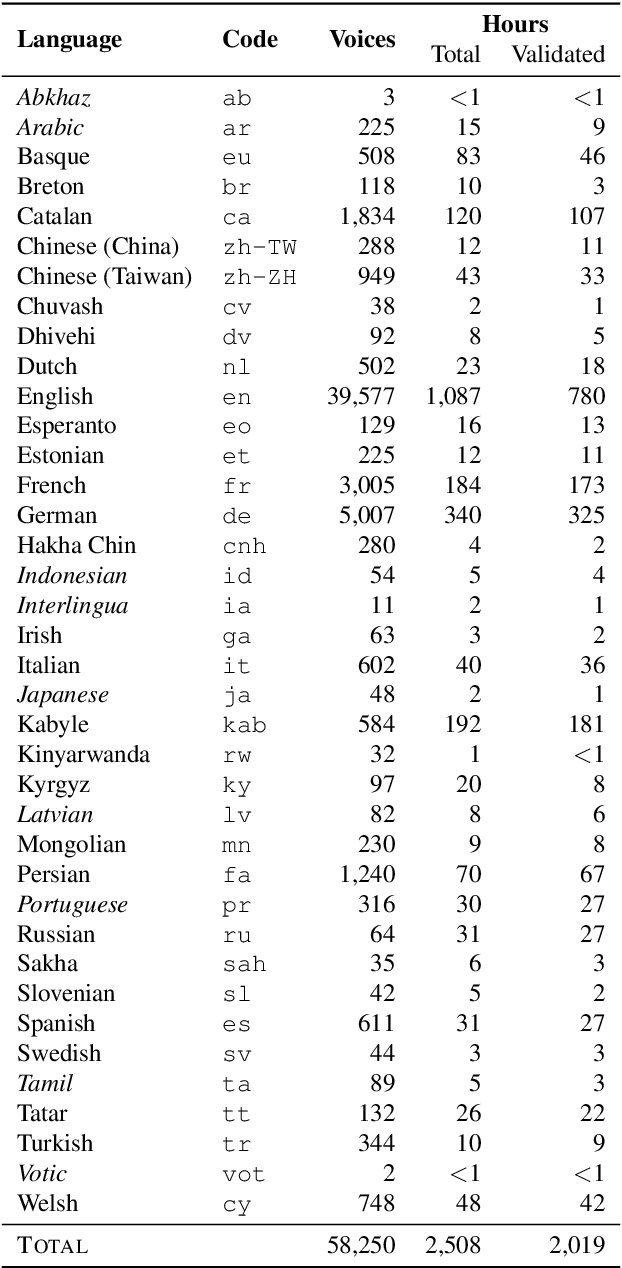
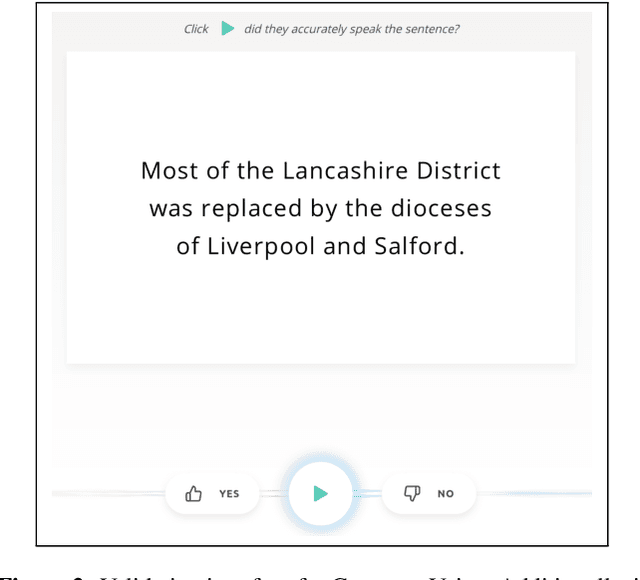
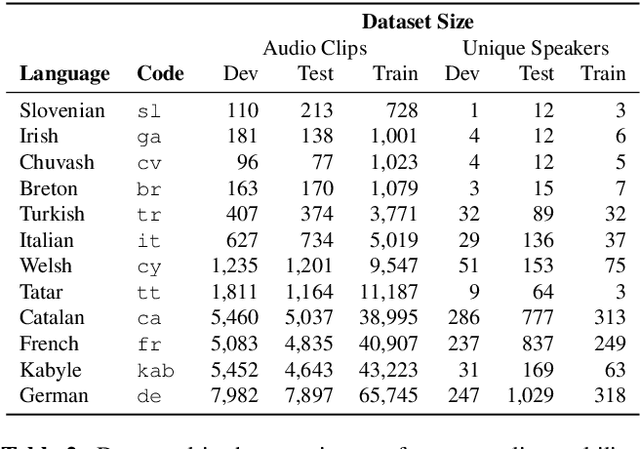
The Common Voice corpus is a massively-multilingual collection of transcribed speech intended for speech technology research and development. Common Voice is designed for Automatic Speech Recognition purposes but can be useful in other domains (e.g. language identification). To achieve scale and sustainability, the Common Voice project employs crowdsourcing for both data collection and data validation. The most recent release includes 29 languages, and as of November 2019 there are a total of 38 languages collecting data. Over 50,000 individuals have participated so far, resulting in 2,500 hours of collected audio. To our knowledge this is the largest audio corpus in the public domain for speech recognition, both in terms of number of hours and number of languages. As an example use case for Common Voice, we present speech recognition experiments using Mozilla's DeepSpeech Speech-to-Text toolkit. By applying transfer learning from a source English model, we find an average Character Error Rate improvement of 5.99 +/- 5.48 for twelve target languages (German, French, Italian, Turkish, Catalan, Slovenian, Welsh, Irish, Breton, Tatar, Chuvash, and Kabyle). For most of these languages, these are the first ever published results on end-to-end Automatic Speech Recognition.
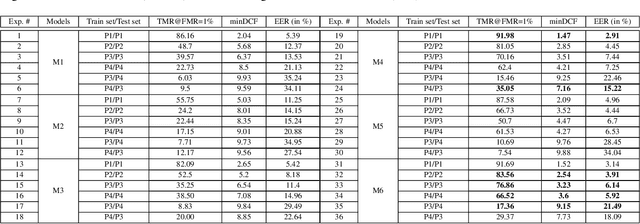
GIST-AiTeR System for the Diarization Task of the 2022 VoxCeleb Speaker Recognition Challenge
Sep 21, 2022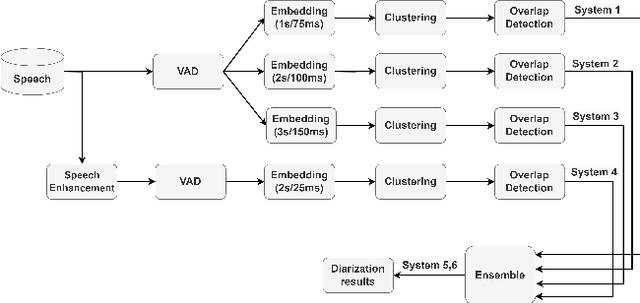
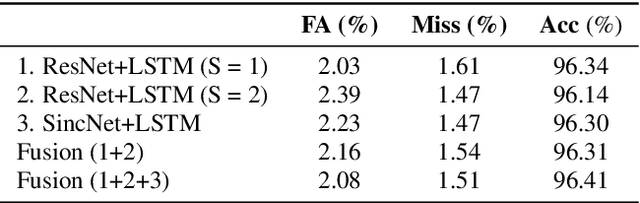
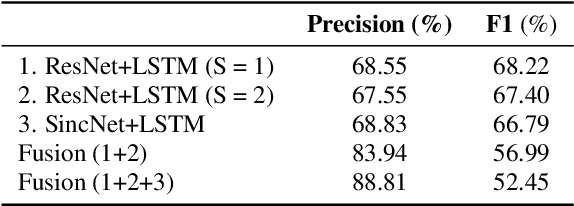
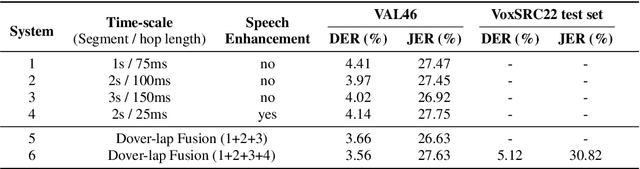
This report describes the submission system of the GIST-AiTeR team at the 2022 VoxCeleb Speaker Recognition Challenge (VoxSRC) Track 4. Our system mainly includes speech enhancement, voice activity detection , multi-scaled speaker embedding, probabilistic linear discriminant analysis-based speaker clustering, and overlapped speech detection models. We first construct four different diarization systems according to different model combinations with the best experimental efforts. Our final submission is an ensemble system of all the four systems and achieves a diarization error rate of 5.12\% on the challenge evaluation set, ranked third at the diarization track of the challenge.
Acoustic-to-Word Models with Conversational Context Information
May 21, 2019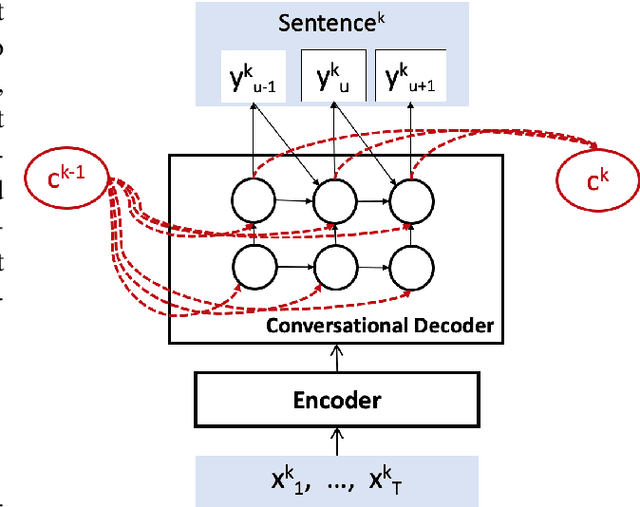
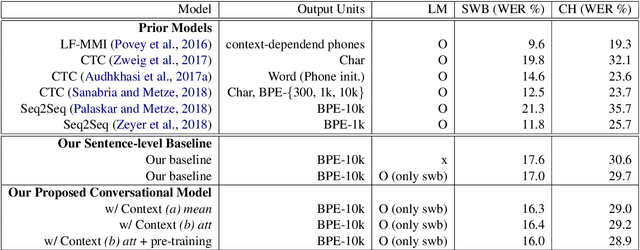
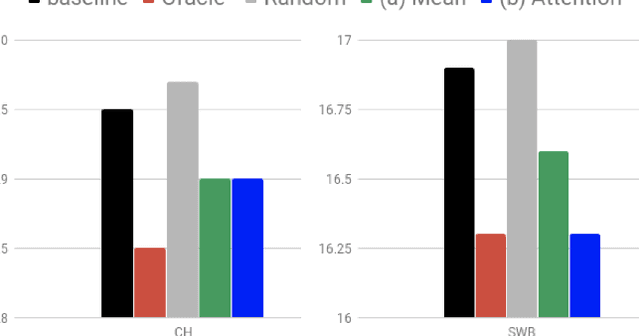
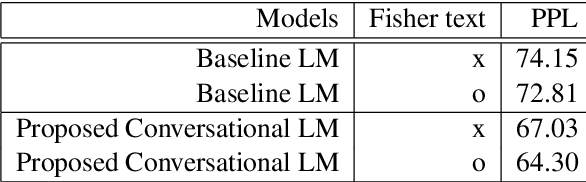
Conversational context information, higher-level knowledge that spans across sentences, can help to recognize a long conversation. However, existing speech recognition models are typically built at a sentence level, and thus it may not capture important conversational context information. The recent progress in end-to-end speech recognition enables integrating context with other available information (e.g., acoustic, linguistic resources) and directly recognizing words from speech. In this work, we present a direct acoustic-to-word, end-to-end speech recognition model capable of utilizing the conversational context to better process long conversations. We evaluate our proposed approach on the Switchboard conversational speech corpus and show that our system outperforms a standard end-to-end speech recognition system.