 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Label Smoothing for Enhanced Text Sentiment Classification
Dec 11, 2023
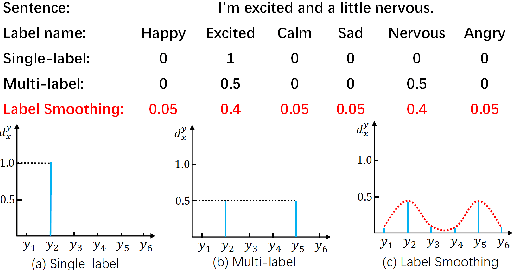

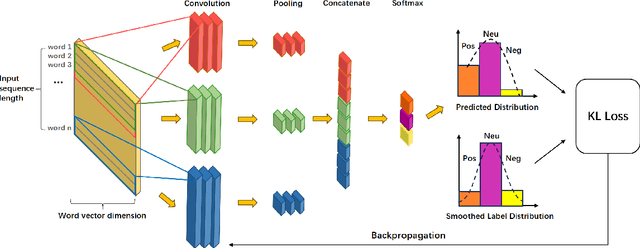
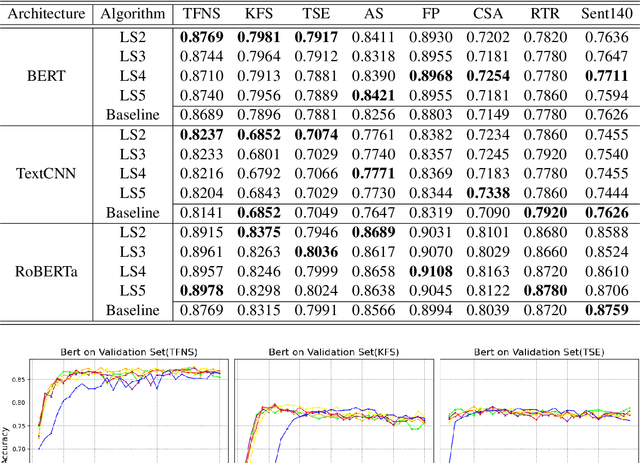
Label smoothing is a widely used technique in various domains, such as image classification and speech recognition, known for effectively combating model overfitting. However, there is few research on its application to text sentiment classification. To fill in the gap, this study investigates the implementation of label smoothing for sentiment classification by utilizing different levels of smoothing. The primary objective is to enhance sentiment classification accuracy by transforming discrete labels into smoothed label distributions. Through extensive experiments, we demonstrate the superior performance of label smoothing in text sentiment classification tasks across eight diverse datasets and deep learning architectures: TextCNN, BERT, and RoBERTa, under two learning schemes: training from scratch and fine-tuning.
Kid-Whisper: Towards Bridging the Performance Gap in Automatic Speech Recognition for Children VS. Adults
Sep 12, 2023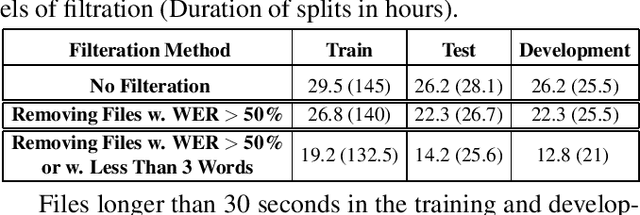
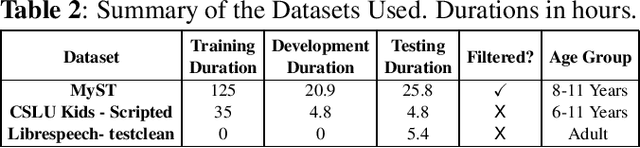
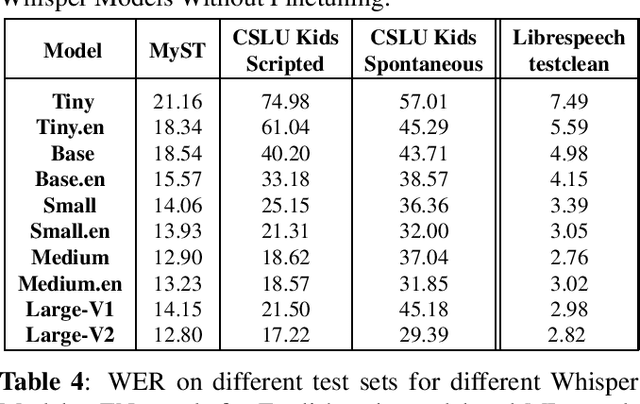
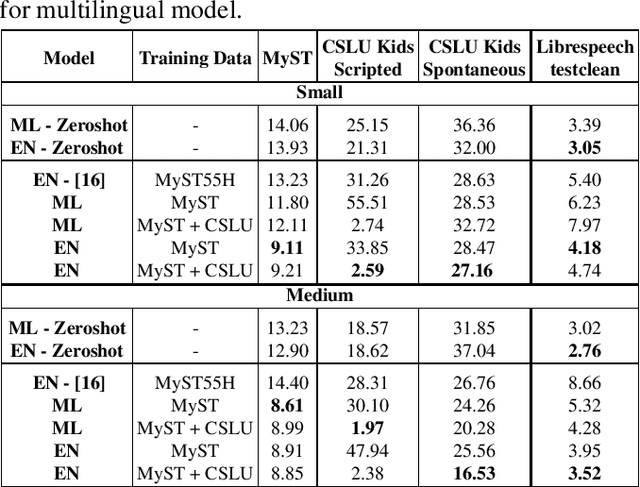
Recent advancements in Automatic Speech Recognition (ASR) systems, exemplified by Whisper, have demonstrated the potential of these systems to approach human-level performance given sufficient data. However, this progress doesn't readily extend to ASR for children due to the limited availability of suitable child-specific databases and the distinct characteristics of children's speech. A recent study investigated leveraging the My Science Tutor (MyST) children's speech corpus to enhance Whisper's performance in recognizing children's speech. This paper builds on these findings by enhancing the utility of the MyST dataset through more efficient data preprocessing. We also highlight important challenges towards improving children's ASR performance. The results showcase the viable and efficient integration of Whisper for effective children's speech recognition.
Generative error correction for code-switching speech recognition using large language models
Oct 17, 2023
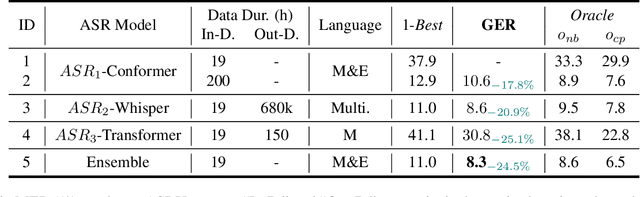
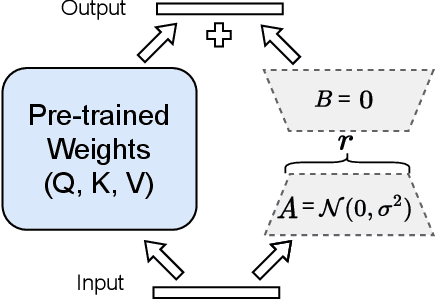
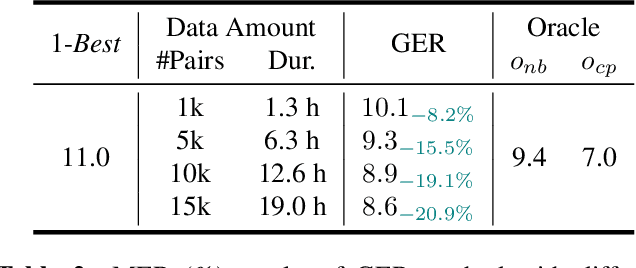
Code-switching (CS) speech refers to the phenomenon of mixing two or more languages within the same sentence. Despite the recent advances in automatic speech recognition (ASR), CS-ASR is still a challenging task ought to the grammatical structure complexity of the phenomenon and the data scarcity of specific training corpus. In this work, we propose to leverage large language models (LLMs) and lists of hypotheses generated by an ASR to address the CS problem. Specifically, we first employ multiple well-trained ASR models for N-best hypotheses generation, with the aim of increasing the diverse and informative elements in the set of hypotheses. Next, we utilize the LLMs to learn the hypotheses-to-transcription (H2T) mapping by adding a trainable low-rank adapter. Such a generative error correction (GER) method directly predicts the accurate transcription according to its expert linguistic knowledge and N-best hypotheses, resulting in a paradigm shift from the traditional language model rescoring or error correction techniques. Experimental evidence demonstrates that GER significantly enhances CS-ASR accuracy, in terms of reduced mixed error rate (MER). Furthermore, LLMs show remarkable data efficiency for H2T learning, providing a potential solution to the data scarcity problem of CS-ASR in low-resource languages.
Unimodal Aggregation for CTC-based Speech Recognition
Sep 15, 2023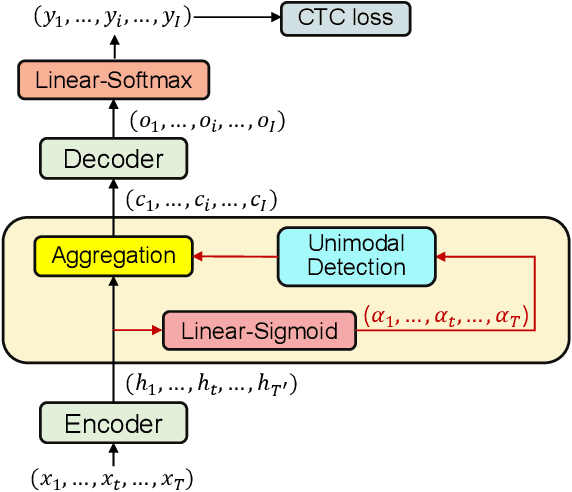
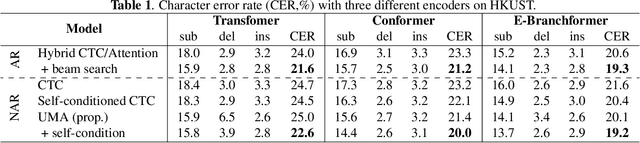
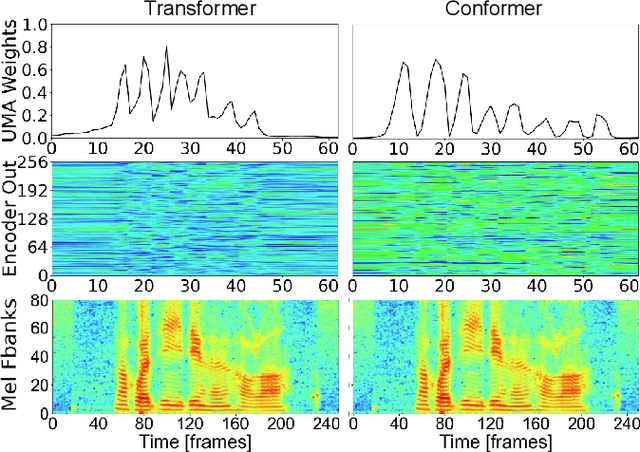
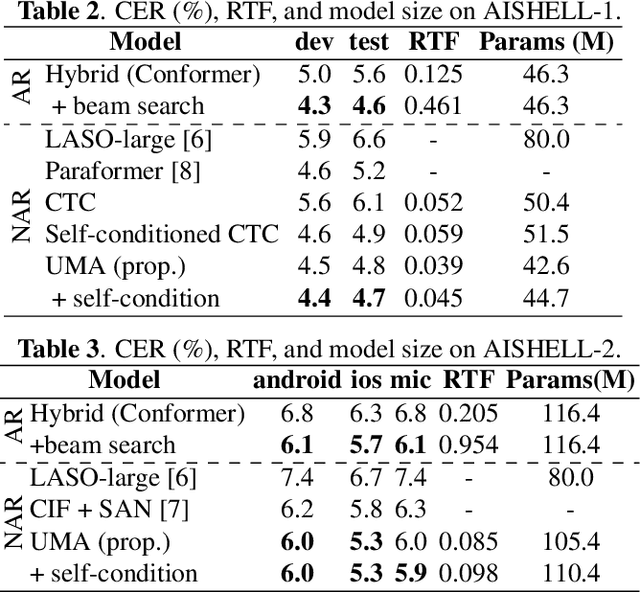
This paper works on non-autoregressive automatic speech recognition. A unimodal aggregation (UMA) is proposed to segment and integrate the feature frames that belong to the same text token, and thus to learn better feature representations for text tokens. The frame-wise features and weights are both derived from an encoder. Then, the feature frames with unimodal weights are integrated and further processed by a decoder. Connectionist temporal classification (CTC) loss is applied for training. Compared to the regular CTC, the proposed method learns better feature representations and shortens the sequence length, resulting in lower recognition error and computational complexity. Experiments on three Mandarin datasets show that UMA demonstrates superior or comparable performance to other advanced non-autoregressive methods, such as self-conditioned CTC. Moreover, by integrating self-conditioned CTC into the proposed framework, the performance can be further noticeably improved.
Exploring Speech Recognition, Translation, and Understanding with Discrete Speech Units: A Comparative Study
Sep 27, 2023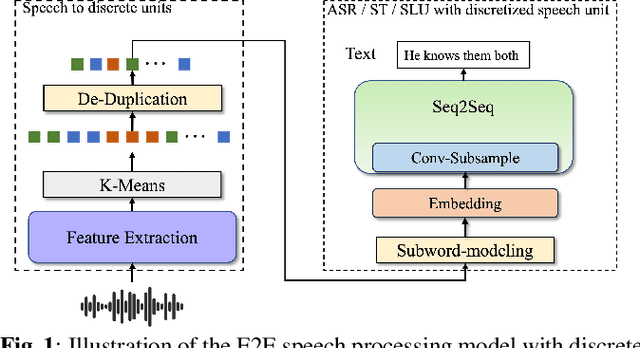
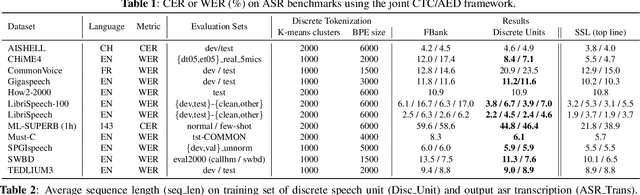
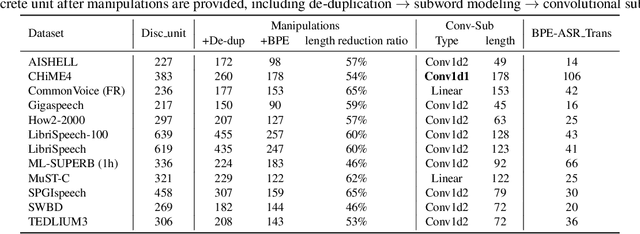
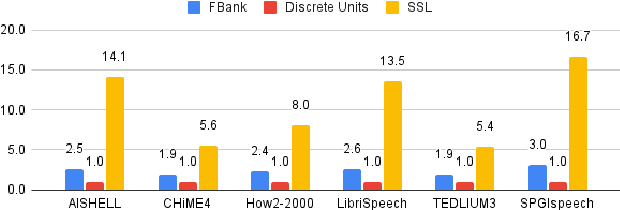
Speech signals, typically sampled at rates in the tens of thousands per second, contain redundancies, evoking inefficiencies in sequence modeling. High-dimensional speech features such as spectrograms are often used as the input for the subsequent model. However, they can still be redundant. Recent investigations proposed the use of discrete speech units derived from self-supervised learning representations, which significantly compresses the size of speech data. Applying various methods, such as de-duplication and subword modeling, can further compress the speech sequence length. Hence, training time is significantly reduced while retaining notable performance. In this study, we undertake a comprehensive and systematic exploration into the application of discrete units within end-to-end speech processing models. Experiments on 12 automatic speech recognition, 3 speech translation, and 1 spoken language understanding corpora demonstrate that discrete units achieve reasonably good results in almost all the settings. We intend to release our configurations and trained models to foster future research efforts.
Speech and Text-Based Emotion Recognizer
Dec 10, 2023Affective computing is a field of study that focuses on developing systems and technologies that can understand, interpret, and respond to human emotions. Speech Emotion Recognition (SER), in particular, has got a lot of attention from researchers in the recent past. However, in many cases, the publicly available datasets, used for training and evaluation, are scarce and imbalanced across the emotion labels. In this work, we focused on building a balanced corpus from these publicly available datasets by combining these datasets as well as employing various speech data augmentation techniques. Furthermore, we experimented with different architectures for speech emotion recognition. Our best system, a multi-modal speech, and text-based model, provides a performance of UA(Unweighed Accuracy) + WA (Weighed Accuracy) of 157.57 compared to the baseline algorithm performance of 119.66
Efficiency-oriented approaches for self-supervised speech representation learning
Dec 18, 2023Self-supervised learning enables the training of large neural models without the need for large, labeled datasets. It has been generating breakthroughs in several fields, including computer vision, natural language processing, biology, and speech. In particular, the state-of-the-art in several speech processing applications, such as automatic speech recognition or speaker identification, are models where the latent representation is learned using self-supervised approaches. Several configurations exist in self-supervised learning for speech, including contrastive, predictive, and multilingual approaches. There is, however, a crucial limitation in most existing approaches: their high computational costs. These costs limit the deployment of models, the size of the training dataset, and the number of research groups that can afford research with large self-supervised models. Likewise, we should consider the environmental costs that high energy consumption implies. Efforts in this direction comprise optimization of existing models, neural architecture efficiency, improvements in finetuning for speech processing tasks, and data efficiency. But despite current efforts, more work could be done to address high computational costs in self-supervised representation learning.
Phoneme-aware Encoding for Prefix-tree-based Contextual ASR
Dec 15, 2023In speech recognition applications, it is important to recognize context-specific rare words, such as proper nouns. Tree-constrained Pointer Generator (TCPGen) has shown promise for this purpose, which efficiently biases such words with a prefix tree. While the original TCPGen relies on grapheme-based encoding, we propose extending it with phoneme-aware encoding to better recognize words of unusual pronunciations. As TCPGen handles biasing words as subword units, we propose obtaining subword-level phoneme-aware encoding by using alignment between phonemes and subwords. Furthermore, we propose injecting phoneme-level predictions from CTC into queries of TCPGen so that the model better interprets the phoneme-aware encodings. We conducted ASR experiments with TCPGen for RNN transducer. We observed that proposed phoneme-aware encoding outperformed ordinary grapheme-based encoding on both the English LibriSpeech and Japanese CSJ datasets, demonstrating the robustness of our approach across linguistically diverse languages.
KinSPEAK: Improving speech recognition for Kinyarwanda via semi-supervised learning methods
Aug 23, 2023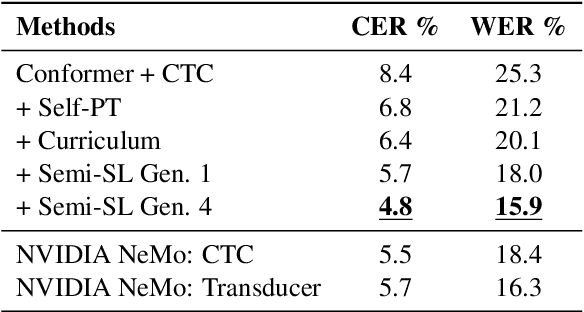
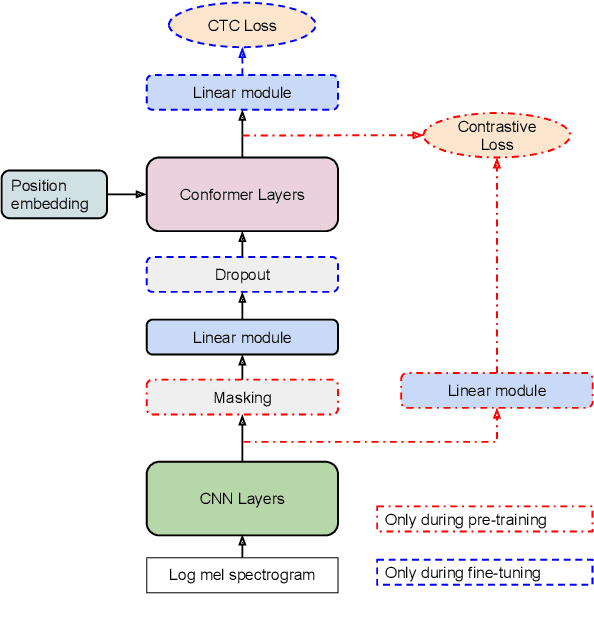

Despite recent availability of large transcribed Kinyarwanda speech data, achieving robust speech recognition for Kinyarwanda is still challenging. In this work, we show that using self-supervised pre-training, following a simple curriculum schedule during fine-tuning and using semi-supervised learning to leverage large unlabelled speech data significantly improve speech recognition performance for Kinyarwanda. Our approach focuses on using public domain data only. A new studio-quality speech dataset is collected from a public website, then used to train a clean baseline model. The clean baseline model is then used to rank examples from a more diverse and noisy public dataset, defining a simple curriculum training schedule. Finally, we apply semi-supervised learning to label and learn from large unlabelled data in four successive generations. Our final model achieves 3.2% word error rate (WER) on the new dataset and 15.9% WER on Mozilla Common Voice benchmark, which is state-of-the-art to the best of our knowledge. Our experiments also indicate that using syllabic rather than character-based tokenization results in better speech recognition performance for Kinyarwanda.
Seq2seq for Automatic Paraphasia Detection in Aphasic Speech
Dec 16, 2023Paraphasias are speech errors that are often characteristic of aphasia and they represent an important signal in assessing disease severity and subtype. Traditionally, clinicians manually identify paraphasias by transcribing and analyzing speech-language samples, which can be a time-consuming and burdensome process. Identifying paraphasias automatically can greatly help clinicians with the transcription process and ultimately facilitate more efficient and consistent aphasia assessment. Previous research has demonstrated the feasibility of automatic paraphasia detection by training an automatic speech recognition (ASR) model to extract transcripts and then training a separate paraphasia detection model on a set of hand-engineered features. In this paper, we propose a novel, sequence-to-sequence (seq2seq) model that is trained end-to-end (E2E) to perform both ASR and paraphasia detection tasks. We show that the proposed model outperforms the previous state-of-the-art approach for both word-level and utterance-level paraphasia detection tasks and provide additional follow-up evaluations to further understand the proposed model behavior.