 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Correlation based Multi-phasal models for improved imagined speech EEG recognition
Nov 04, 2020
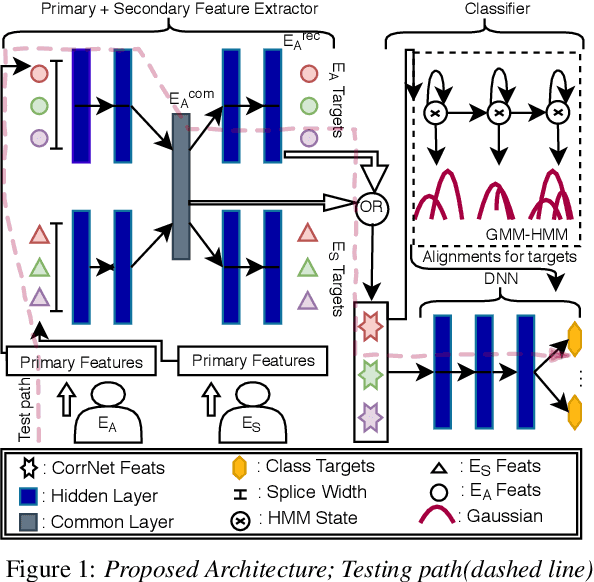
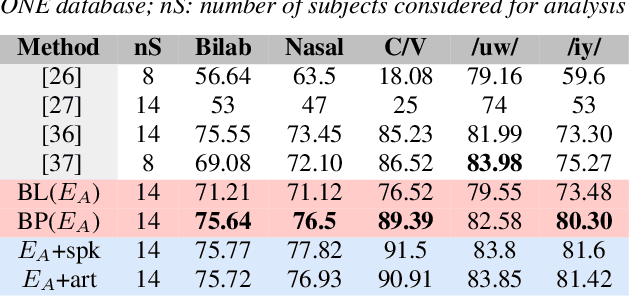
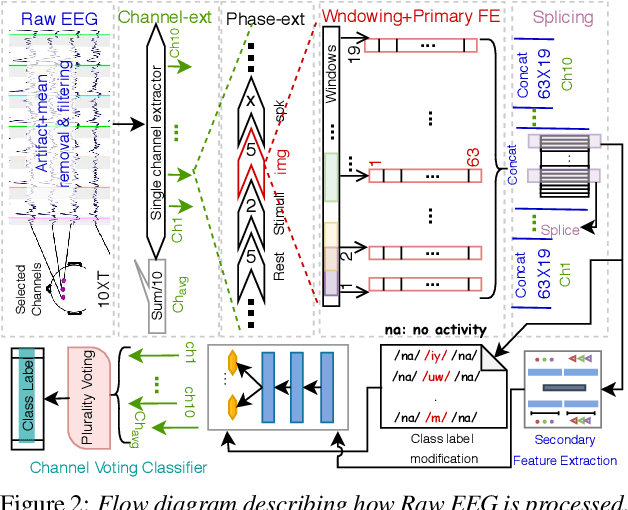
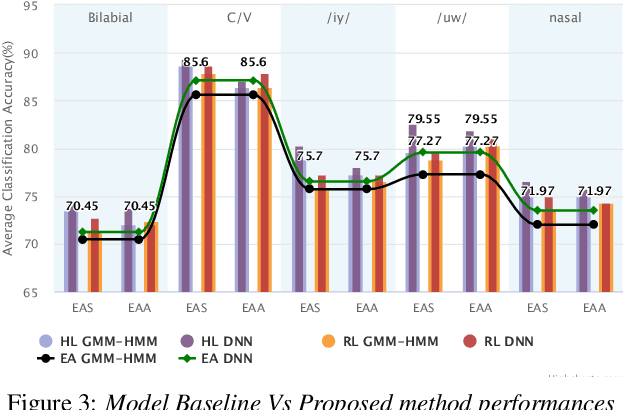
Translation of imagined speech electroencephalogram(EEG) into human understandable commands greatly facilitates the design of naturalistic brain computer interfaces. To achieve improved imagined speech unit classification, this work aims to profit from the parallel information contained in multi-phasal EEG data recorded while speaking, imagining and performing articulatory movements corresponding to specific speech units. A bi-phase common representation learning module using neural networks is designed to model the correlation and reproducibility between an analysis phase and a support phase. The trained Correlation Network is then employed to extract discriminative features of the analysis phase. These features are further classified into five binary phonological categories using machine learning models such as Gaussian mixture based hidden Markov model and deep neural networks. The proposed approach further handles the non-availability of multi-phasal data during decoding. Topographic visualizations along with result-based inferences suggest that the multi-phasal correlation modelling approach proposed in the paper enhances imagined-speech EEG recognition performance.
Word-Free Spoken Language Understanding for Mandarin-Chinese
Jul 01, 2021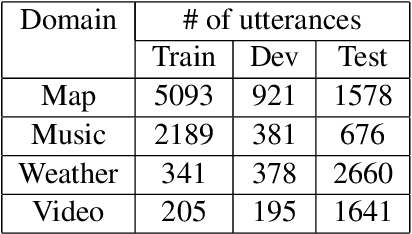
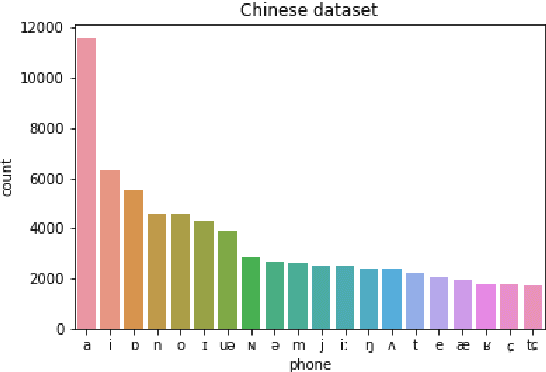
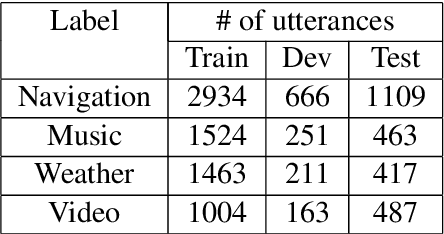
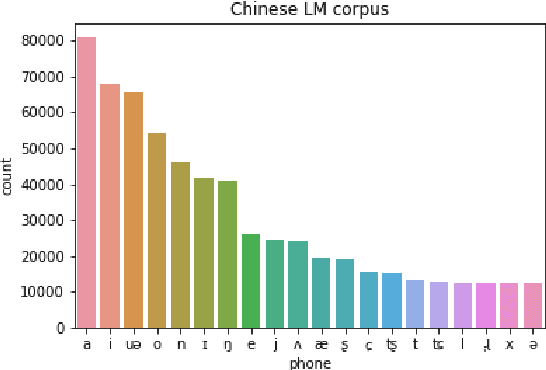
Spoken dialogue systems such as Siri and Alexa provide great convenience to people's everyday life. However, current spoken language understanding (SLU) pipelines largely depend on automatic speech recognition (ASR) modules, which require a large amount of language-specific training data. In this paper, we propose a Transformer-based SLU system that works directly on phones. This acoustic-based SLU system consists of only two blocks and does not require the presence of ASR module. The first block is a universal phone recognition system, and the second block is a Transformer-based language model for phones. We verify the effectiveness of the system on an intent classification dataset in Mandarin Chinese.
A brief history of AI: how to prevent another winter (a critical review)
Sep 08, 2021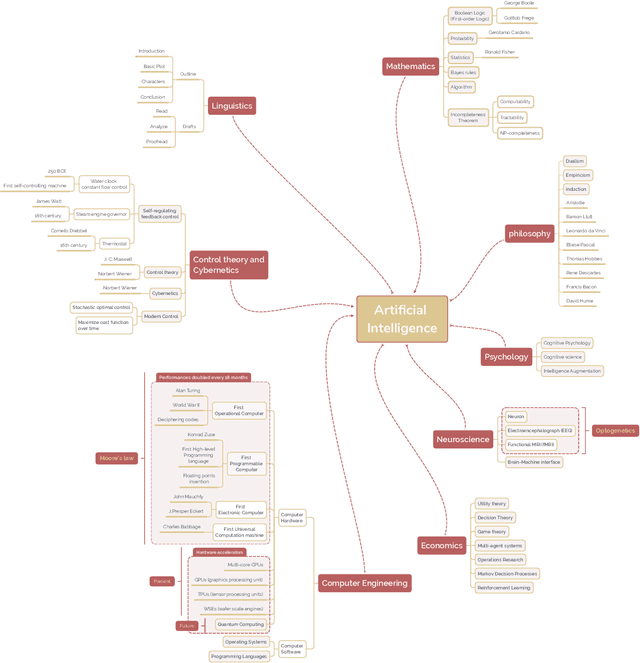
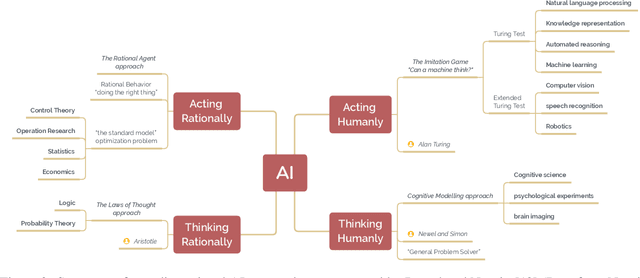
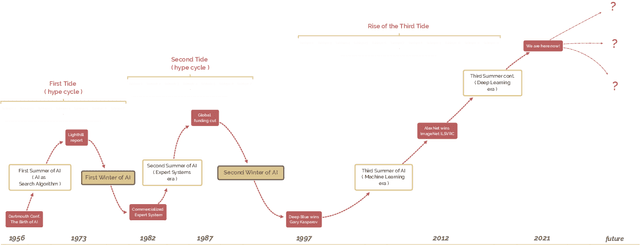

The field of artificial intelligence (AI), regarded as one of the most enigmatic areas of science, has witnessed exponential growth in the past decade including a remarkably wide array of applications, having already impacted our everyday lives. Advances in computing power and the design of sophisticated AI algorithms have enabled computers to outperform humans in a variety of tasks, especially in the areas of computer vision and speech recognition. Yet, AI's path has never been smooth, having essentially fallen apart twice in its lifetime ('winters' of AI), both after periods of popular success ('summers' of AI). We provide a brief rundown of AI's evolution over the course of decades, highlighting its crucial moments and major turning points from inception to the present. In doing so, we attempt to learn, anticipate the future, and discuss what steps may be taken to prevent another 'winter'.
Revealing and Protecting Labels in Distributed Training
Oct 31, 2021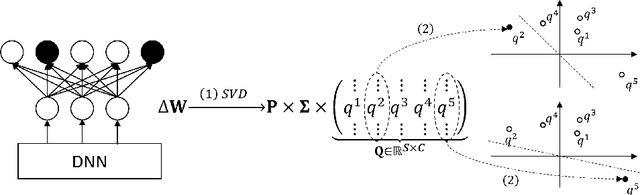
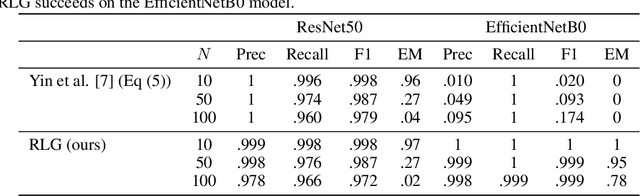
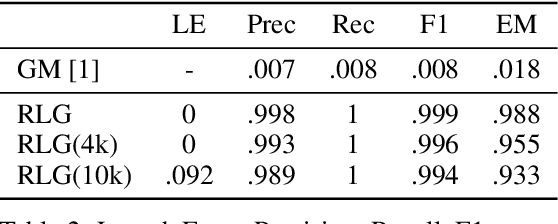
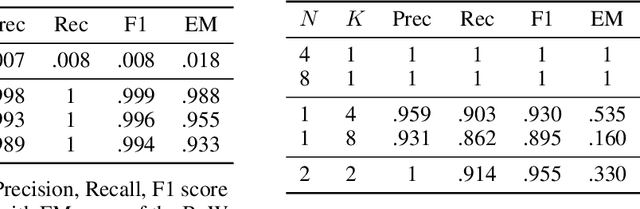
Distributed learning paradigms such as federated learning often involve transmission of model updates, or gradients, over a network, thereby avoiding transmission of private data. However, it is possible for sensitive information about the training data to be revealed from such gradients. Prior works have demonstrated that labels can be revealed analytically from the last layer of certain models (e.g., ResNet), or they can be reconstructed jointly with model inputs by using Gradients Matching [Zhu et al'19] with additional knowledge about the current state of the model. In this work, we propose a method to discover the set of labels of training samples from only the gradient of the last layer and the id to label mapping. Our method is applicable to a wide variety of model architectures across multiple domains. We demonstrate the effectiveness of our method for model training in two domains - image classification, and automatic speech recognition. Furthermore, we show that existing reconstruction techniques improve their efficacy when used in conjunction with our method. Conversely, we demonstrate that gradient quantization and sparsification can significantly reduce the success of the attack.
Learning to retrieve out-of-vocabulary words in speech recognition
Mar 01, 2016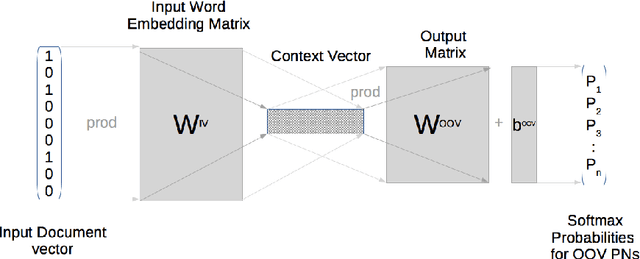
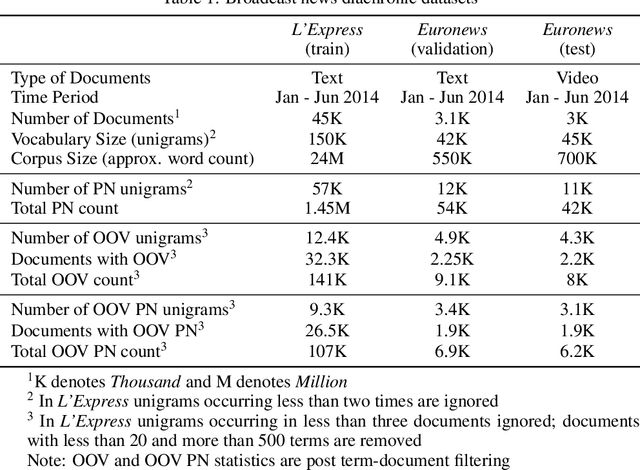
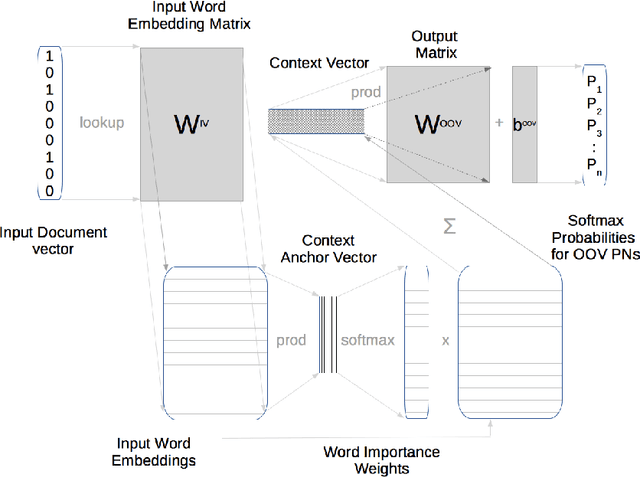
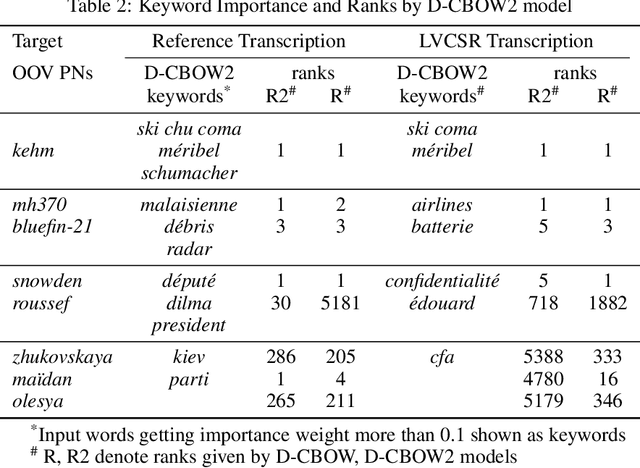
Many Proper Names (PNs) are Out-Of-Vocabulary (OOV) words for speech recognition systems used to process diachronic audio data. To help recovery of the PNs missed by the system, relevant OOV PNs can be retrieved out of the many OOVs by exploiting semantic context of the spoken content. In this paper, we propose two neural network models targeted to retrieve OOV PNs relevant to an audio document: (a) Document level Continuous Bag of Words (D-CBOW), (b) Document level Continuous Bag of Weighted Words (D-CBOW2). Both these models take document words as input and learn with an objective to maximise the retrieval of co-occurring OOV PNs. With the D-CBOW2 model we propose a new approach in which the input embedding layer is augmented with a context anchor layer. This layer learns to assign importance to input words and has the ability to capture (task specific) key-words in a bag-of-word neural network model. With experiments on French broadcast news videos we show that these two models outperform the baseline methods based on raw embeddings from LDA, Skip-gram and Paragraph Vectors. Combining the D-CBOW and D-CBOW2 models gives faster convergence during training.
Token-Level Supervised Contrastive Learning for Punctuation Restoration
Jul 19, 2021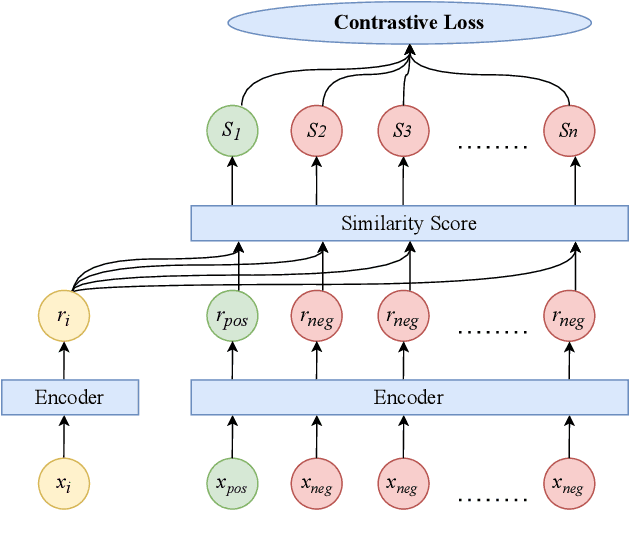
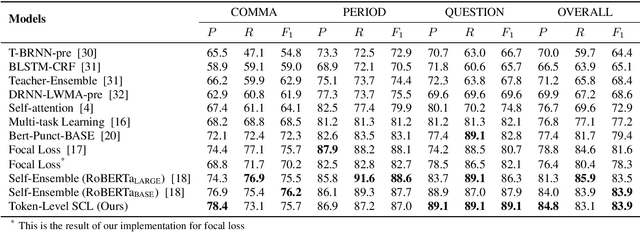
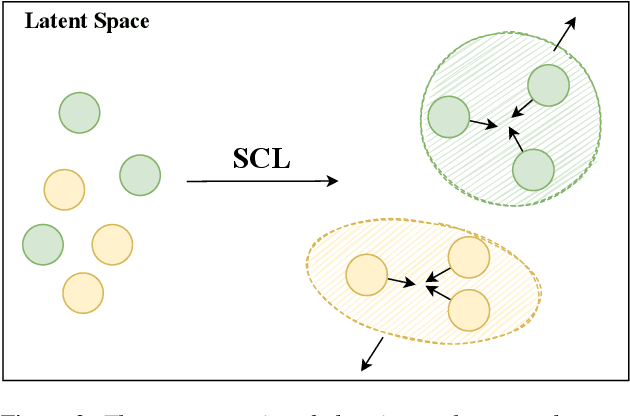

Punctuation is critical in understanding natural language text. Currently, most automatic speech recognition (ASR) systems do not generate punctuation, which affects the performance of downstream tasks, such as intent detection and slot filling. This gives rise to the need for punctuation restoration. Recent work in punctuation restoration heavily utilizes pre-trained language models without considering data imbalance when predicting punctuation classes. In this work, we address this problem by proposing a token-level supervised contrastive learning method that aims at maximizing the distance of representation of different punctuation marks in the embedding space. The result shows that training with token-level supervised contrastive learning obtains up to 3.2% absolute F1 improvement on the test set.
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021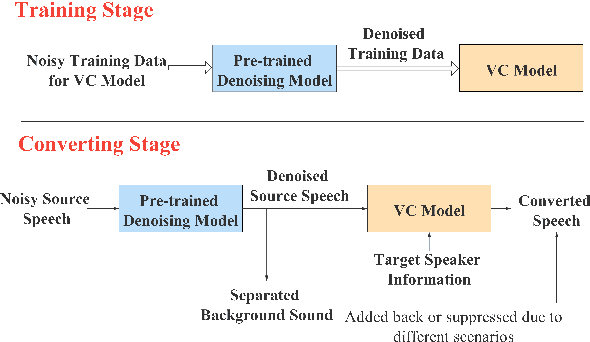
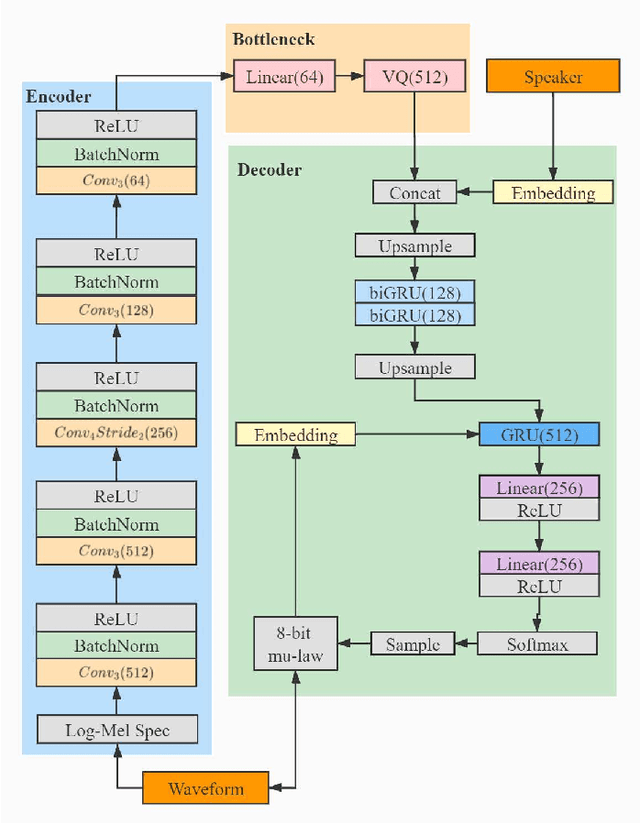
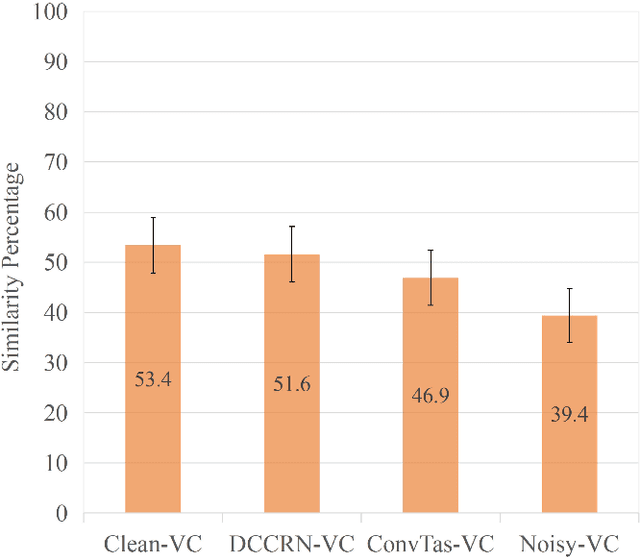
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.
Advances in Joint CTC-Attention based End-to-End Speech Recognition with a Deep CNN Encoder and RNN-LM
Jun 08, 2017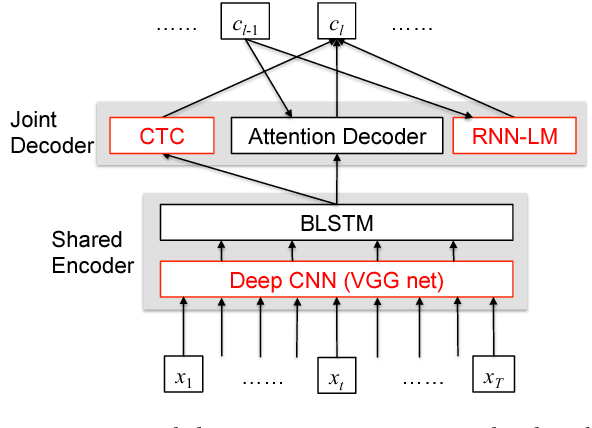
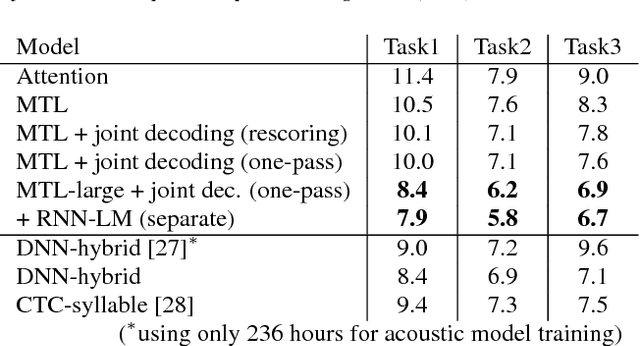
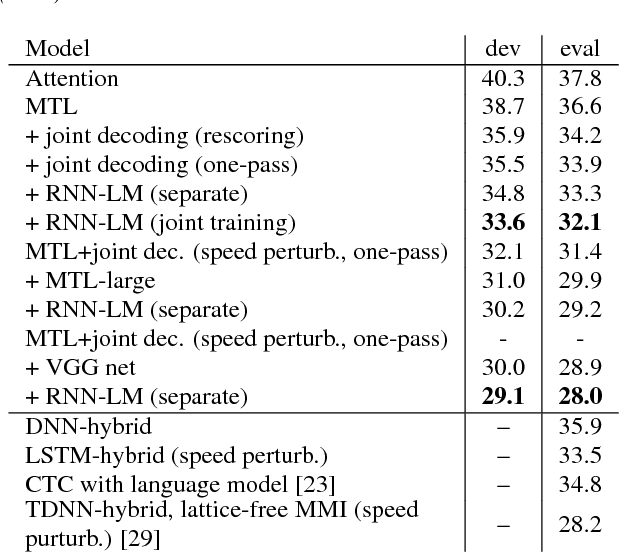
We present a state-of-the-art end-to-end Automatic Speech Recognition (ASR) model. We learn to listen and write characters with a joint Connectionist Temporal Classification (CTC) and attention-based encoder-decoder network. The encoder is a deep Convolutional Neural Network (CNN) based on the VGG network. The CTC network sits on top of the encoder and is jointly trained with the attention-based decoder. During the beam search process, we combine the CTC predictions, the attention-based decoder predictions and a separately trained LSTM language model. We achieve a 5-10\% error reduction compared to prior systems on spontaneous Japanese and Chinese speech, and our end-to-end model beats out traditional hybrid ASR systems.
FlowSense: Monitoring Airflow in Building Ventilation Systems Using Audio Sensing
Feb 22, 2022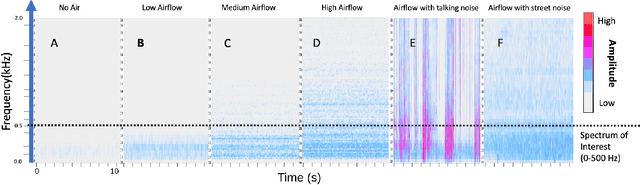
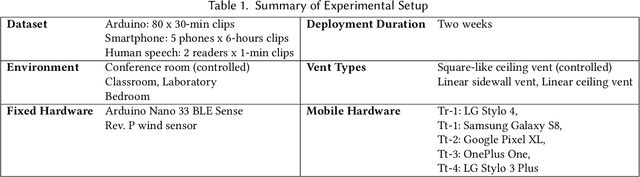
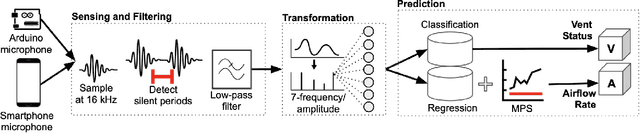
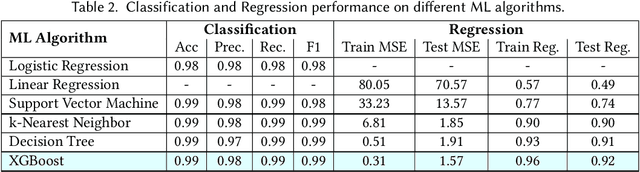
Proper indoor ventilation through buildings' heating, ventilation, and air conditioning (HVAC) systems has become an increasing public health concern that significantly impacts individuals' health and safety at home, work, and school. While much work has progressed in providing energy-efficient and user comfort for HVAC systems through IoT devices and mobile-sensing approaches, ventilation is an aspect that has received lesser attention despite its importance. With a motivation to monitor airflow from building ventilation systems through commodity sensing devices, we present FlowSense, a machine learning-based algorithm to predict airflow rate from sensed audio data in indoor spaces. Our ML technique can predict the state of an air vent-whether it is on or off-as well as the rate of air flowing through active vents. By exploiting a low-pass filter to obtain low-frequency audio signals, we put together a privacy-preserving pipeline that leverages a silence detection algorithm to only sense for sounds of air from HVAC air vent when no human speech is detected. We also propose the Minimum Persistent Sensing (MPS) as a post-processing algorithm to reduce interference from ambient noise, including ongoing human conversation, office machines, and traffic noises. Together, these techniques ensure user privacy and improve the robustness of FlowSense. We validate our approach yielding over 90% accuracy in predicting vent status and 0.96 MSE in predicting airflow rate when the device is placed within 2.25 meters away from an air vent. Additionally, we demonstrate how our approach as a mobile audio-sensing platform is robust to smartphone models, distance, and orientation. Finally, we evaluate FlowSense privacy-preserving pipeline through a user study and a Google Speech Recognition service, confirming that the audio signals we used as input data are inaudible and inconstructible.
Multilingual Speech Translation with Unified Transformer: Huawei Noah's Ark Lab at IWSLT 2021
Jun 22, 2021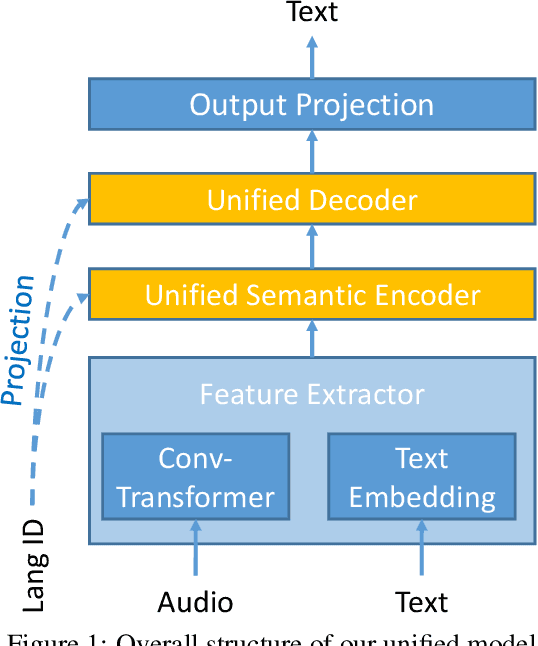
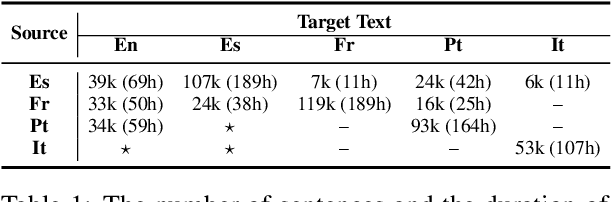
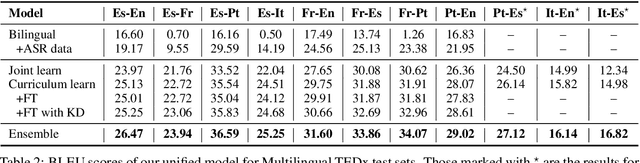
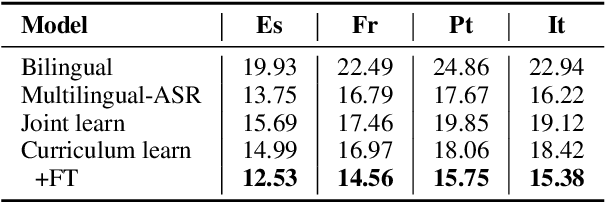
This paper describes the system submitted to the IWSLT 2021 Multilingual Speech Translation (MultiST) task from Huawei Noah's Ark Lab. We use a unified transformer architecture for our MultiST model, so that the data from different modalities (i.e., speech and text) and different tasks (i.e., Speech Recognition, Machine Translation, and Speech Translation) can be exploited to enhance the model's ability. Specifically, speech and text inputs are firstly fed to different feature extractors to extract acoustic and textual features, respectively. Then, these features are processed by a shared encoder--decoder architecture. We apply several training techniques to improve the performance, including multi-task learning, task-level curriculum learning, data augmentation, etc. Our final system achieves significantly better results than bilingual baselines on supervised language pairs and yields reasonable results on zero-shot language pairs.