 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Speech Emotion Recognition Using Deep Sparse Auto-Encoder Extreme Learning Machine with a New Weighting Scheme and Spectro-Temporal Features Along with Classical Feature Selection and A New Quantum-Inspired Dimension Reduction Method
Nov 13, 2021
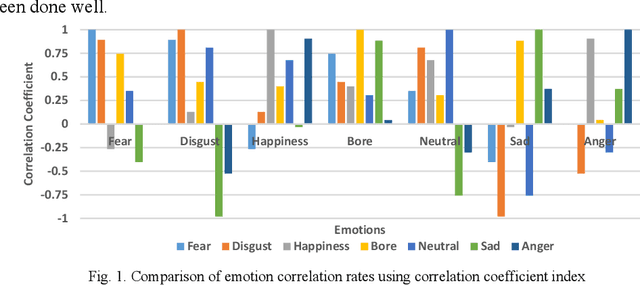
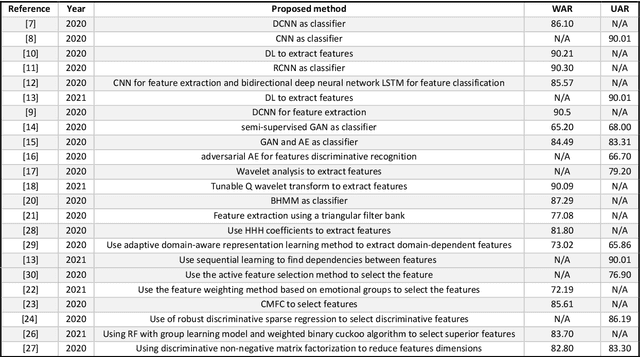
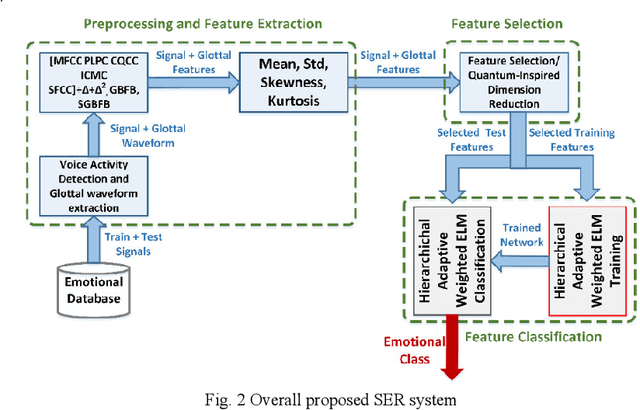

Affective computing is very important in the relationship between man and machine. In this paper, a system for speech emotion recognition (SER) based on speech signal is proposed, which uses new techniques in different stages of processing. The system consists of three stages: feature extraction, feature selection, and finally feature classification. In the first stage, a complex set of long-term statistics features is extracted from both the speech signal and the glottal-waveform signal using a combination of new and diverse features such as prosodic, spectral, and spectro-temporal features. One of the challenges of the SER systems is to distinguish correlated emotions. These features are good discriminators for speech emotions and increase the SER's ability to recognize similar and different emotions. This feature vector with a large number of dimensions naturally has redundancy. In the second stage, using classical feature selection techniques as well as a new quantum-inspired technique to reduce the feature vector dimensionality, the number of feature vector dimensions is reduced. In the third stage, the optimized feature vector is classified by a weighted deep sparse extreme learning machine (ELM) classifier. The classifier performs classification in three steps: sparse random feature learning, orthogonal random projection using the singular value decomposition (SVD) technique, and discriminative classification in the last step using the generalized Tikhonov regularization technique. Also, many existing emotional datasets suffer from the problem of data imbalanced distribution, which in turn increases the classification error and decreases system performance. In this paper, a new weighting method has also been proposed to deal with class imbalance, which is more efficient than existing weighting methods. The proposed method is evaluated on three standard emotional databases.
Speech Enhancement Using Multi-Stage Self-Attentive Temporal Convolutional Networks
Feb 24, 2021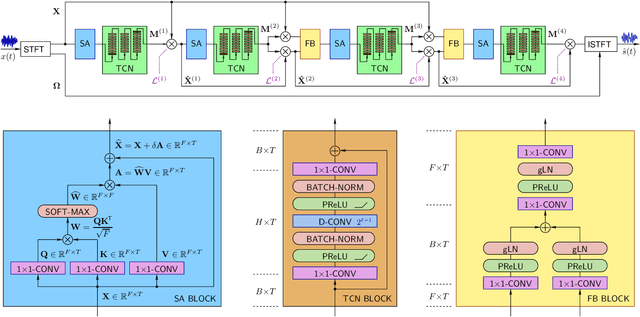
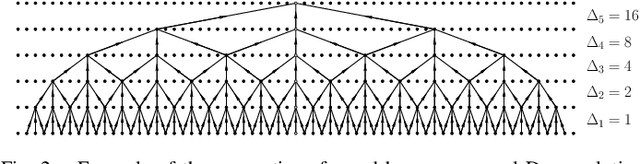
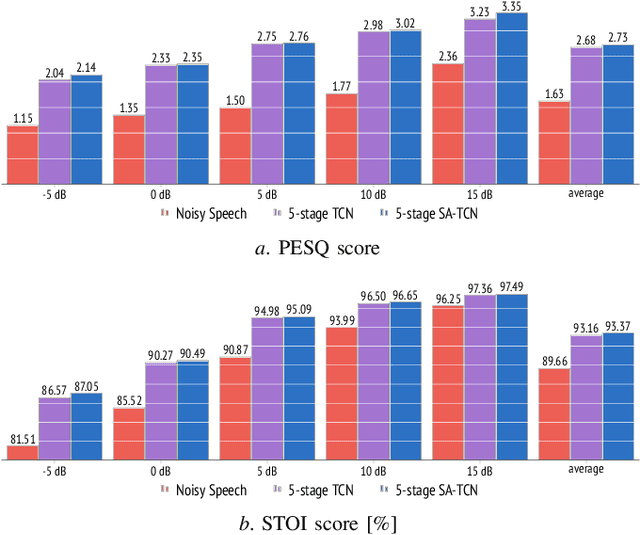
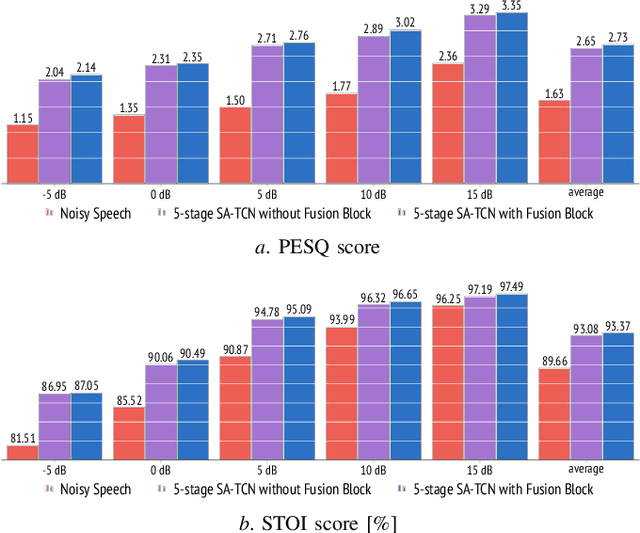
Multi-stage learning is an effective technique to invoke multiple deep-learning modules sequentially. This paper applies multi-stage learning to speech enhancement by using a multi-stage structure, where each stage comprises a self-attention (SA) block followed by stacks of temporal convolutional network (TCN) blocks with doubling dilation factors. Each stage generates a prediction that is refined in a subsequent stage. A fusion block is inserted at the input of later stages to re-inject original information. The resulting multi-stage speech enhancement system, in short, multi-stage SA-TCN, is compared with state-of-the-art deep-learning speech enhancement methods using the LibriSpeech and VCTK data sets. The multi-stage SA-TCN system's hyper-parameters are fine-tuned, and the impact of the SA block, the fusion block and the number of stages are determined. The use of a multi-stage SA-TCN system as a front-end for automatic speech recognition systems is investigated as well. It is shown that the multi-stage SA-TCN systems perform well relative to other state-of-the-art systems in terms of speech enhancement and speech recognition scores.
Language ID Prediction from Speech Using Self-Attentive Pooling and 1D-Convolutions
Apr 24, 2021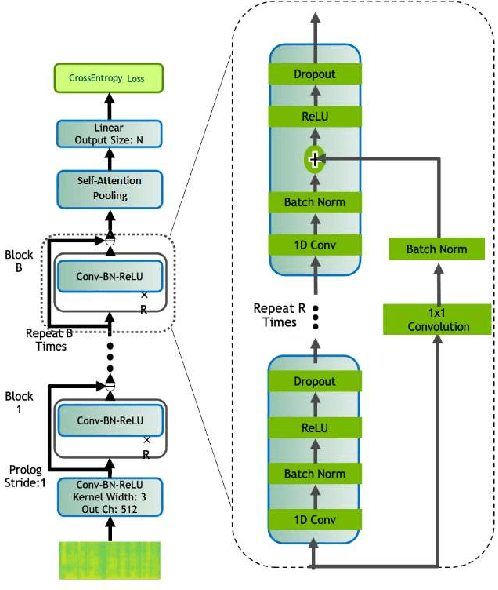
This memo describes NTR-TSU submission for SIGTYP 2021 Shared Task on predicting language IDs from speech. Spoken Language Identification (LID) is an important step in a multilingual Automated Speech Recognition (ASR) system pipeline. For many low-resource and endangered languages, only single-speaker recordings may be available, demanding a need for domain and speaker-invariant language ID systems. In this memo, we show that a convolutional neural network with a Self-Attentive Pooling layer shows promising results for the language identification task.
Revealing and Protecting Labels in Distributed Training
Oct 31, 2021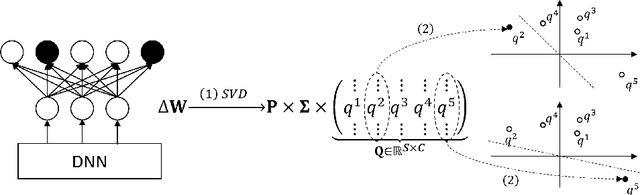
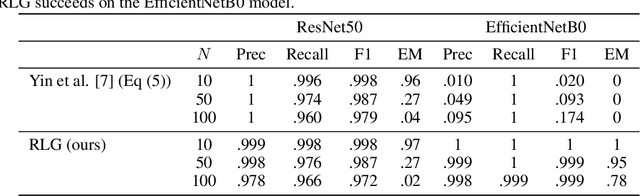
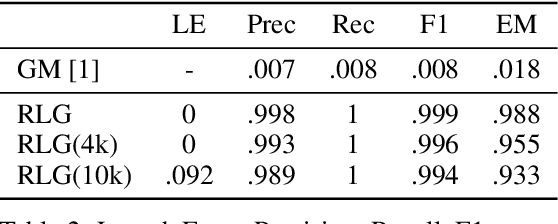
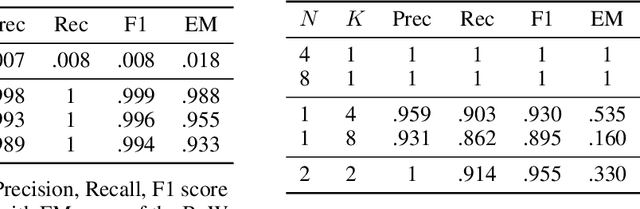
Distributed learning paradigms such as federated learning often involve transmission of model updates, or gradients, over a network, thereby avoiding transmission of private data. However, it is possible for sensitive information about the training data to be revealed from such gradients. Prior works have demonstrated that labels can be revealed analytically from the last layer of certain models (e.g., ResNet), or they can be reconstructed jointly with model inputs by using Gradients Matching [Zhu et al'19] with additional knowledge about the current state of the model. In this work, we propose a method to discover the set of labels of training samples from only the gradient of the last layer and the id to label mapping. Our method is applicable to a wide variety of model architectures across multiple domains. We demonstrate the effectiveness of our method for model training in two domains - image classification, and automatic speech recognition. Furthermore, we show that existing reconstruction techniques improve their efficacy when used in conjunction with our method. Conversely, we demonstrate that gradient quantization and sparsification can significantly reduce the success of the attack.
A brief history of AI: how to prevent another winter (a critical review)
Sep 08, 2021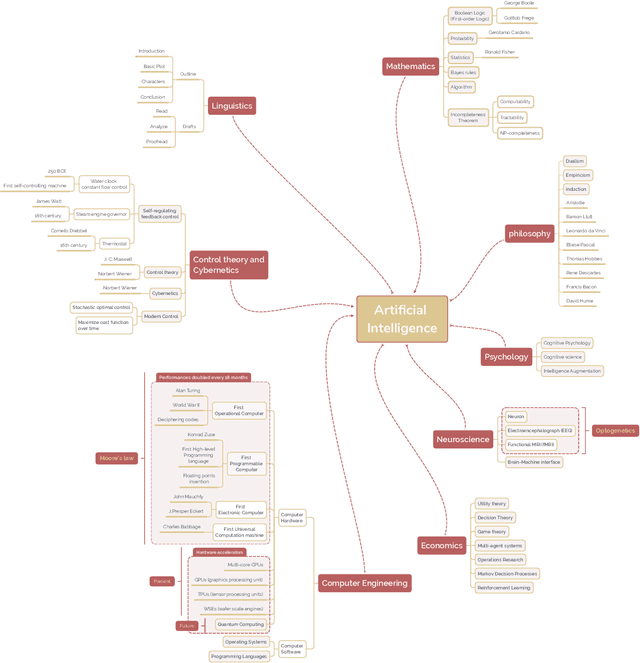
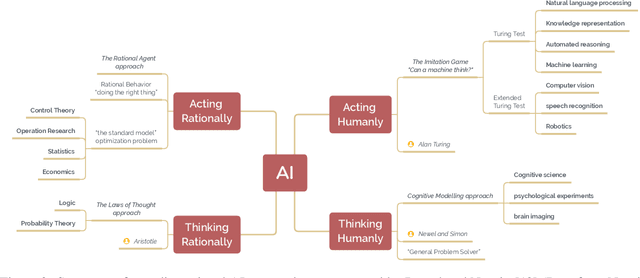
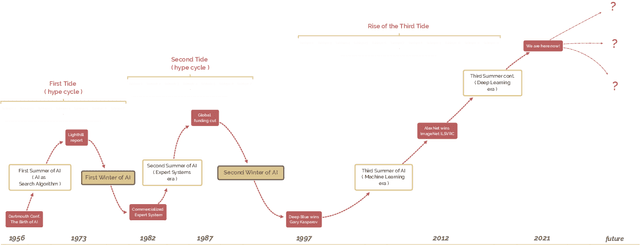

The field of artificial intelligence (AI), regarded as one of the most enigmatic areas of science, has witnessed exponential growth in the past decade including a remarkably wide array of applications, having already impacted our everyday lives. Advances in computing power and the design of sophisticated AI algorithms have enabled computers to outperform humans in a variety of tasks, especially in the areas of computer vision and speech recognition. Yet, AI's path has never been smooth, having essentially fallen apart twice in its lifetime ('winters' of AI), both after periods of popular success ('summers' of AI). We provide a brief rundown of AI's evolution over the course of decades, highlighting its crucial moments and major turning points from inception to the present. In doing so, we attempt to learn, anticipate the future, and discuss what steps may be taken to prevent another 'winter'.
Word-Free Spoken Language Understanding for Mandarin-Chinese
Jul 01, 2021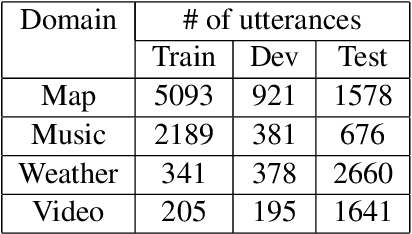
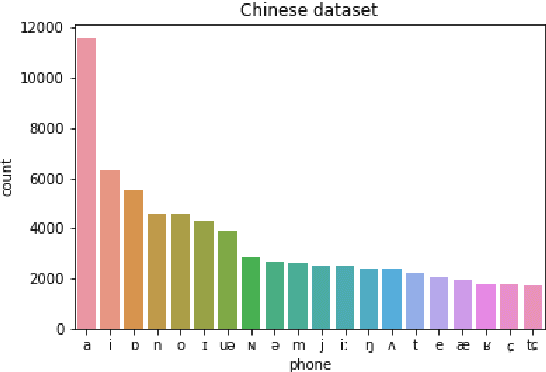
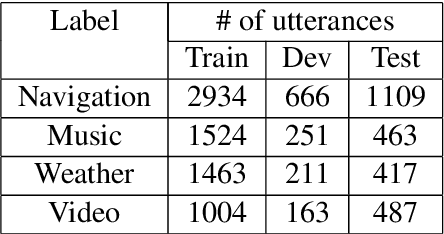
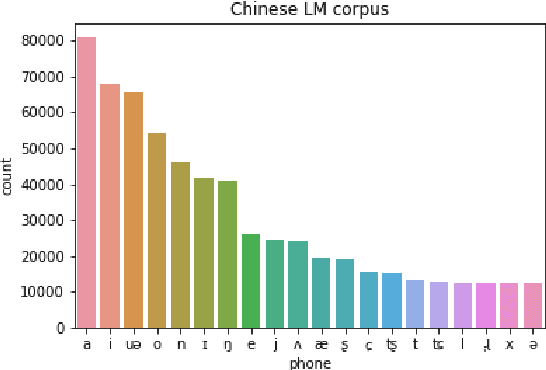
Spoken dialogue systems such as Siri and Alexa provide great convenience to people's everyday life. However, current spoken language understanding (SLU) pipelines largely depend on automatic speech recognition (ASR) modules, which require a large amount of language-specific training data. In this paper, we propose a Transformer-based SLU system that works directly on phones. This acoustic-based SLU system consists of only two blocks and does not require the presence of ASR module. The first block is a universal phone recognition system, and the second block is a Transformer-based language model for phones. We verify the effectiveness of the system on an intent classification dataset in Mandarin Chinese.
Correlation based Multi-phasal models for improved imagined speech EEG recognition
Nov 04, 2020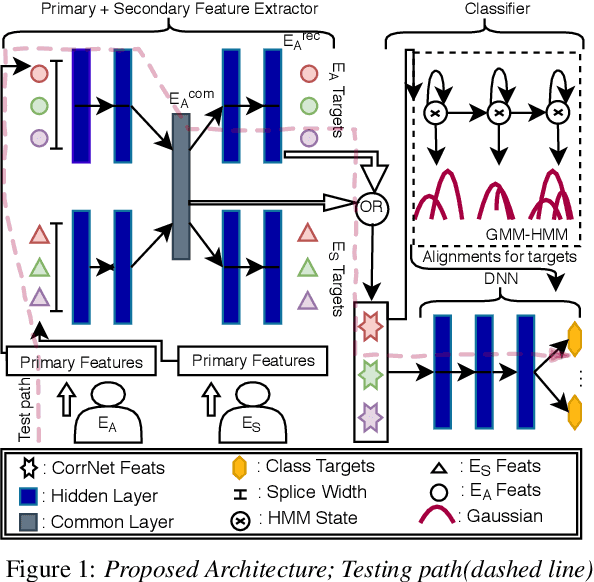
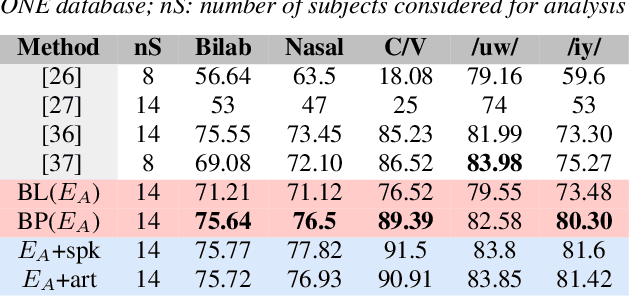
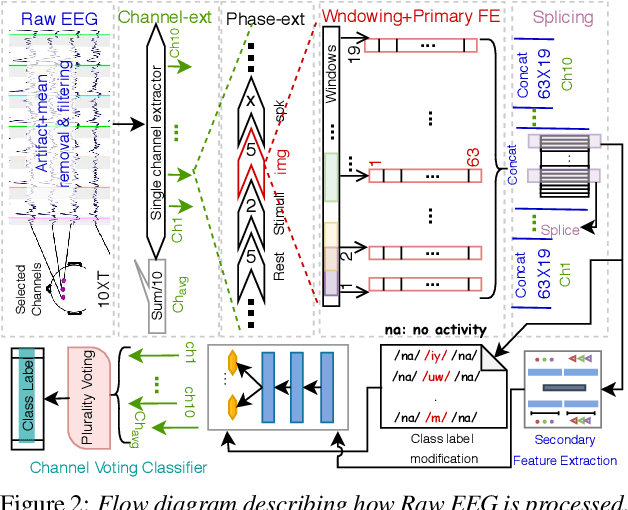
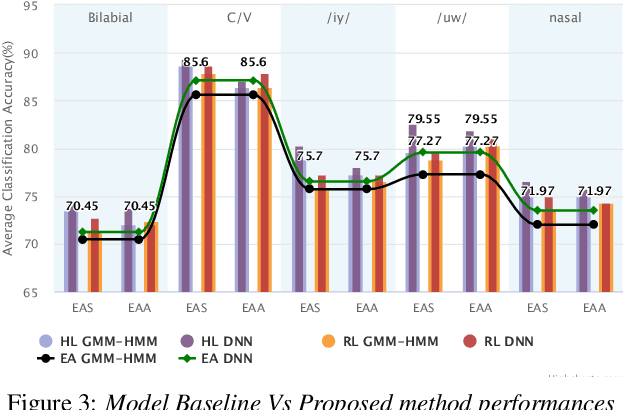
Translation of imagined speech electroencephalogram(EEG) into human understandable commands greatly facilitates the design of naturalistic brain computer interfaces. To achieve improved imagined speech unit classification, this work aims to profit from the parallel information contained in multi-phasal EEG data recorded while speaking, imagining and performing articulatory movements corresponding to specific speech units. A bi-phase common representation learning module using neural networks is designed to model the correlation and reproducibility between an analysis phase and a support phase. The trained Correlation Network is then employed to extract discriminative features of the analysis phase. These features are further classified into five binary phonological categories using machine learning models such as Gaussian mixture based hidden Markov model and deep neural networks. The proposed approach further handles the non-availability of multi-phasal data during decoding. Topographic visualizations along with result-based inferences suggest that the multi-phasal correlation modelling approach proposed in the paper enhances imagined-speech EEG recognition performance.
Learning from Past Mistakes: Improving Automatic Speech Recognition Output via Noisy-Clean Phrase Context Modeling
Feb 07, 2018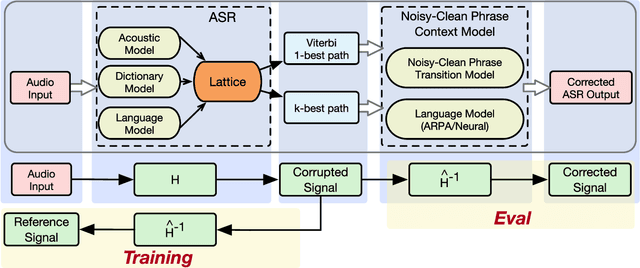

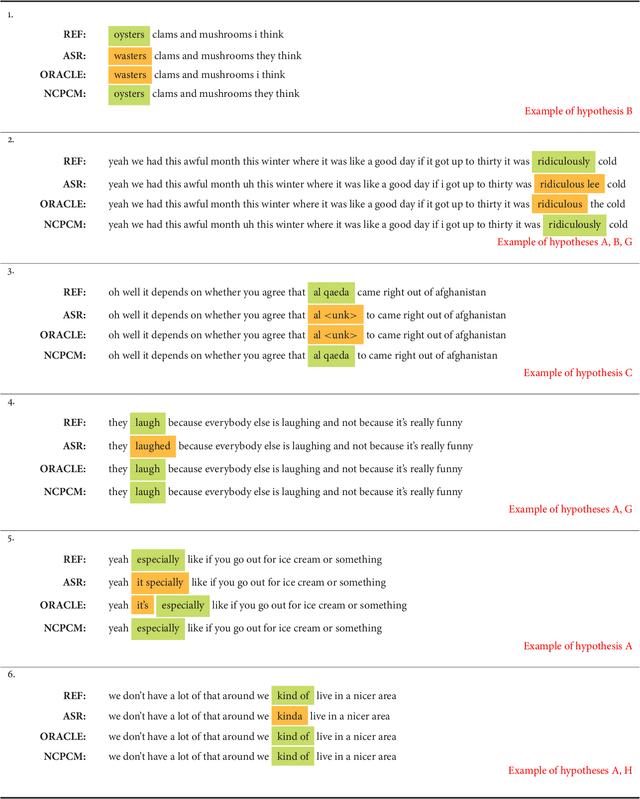
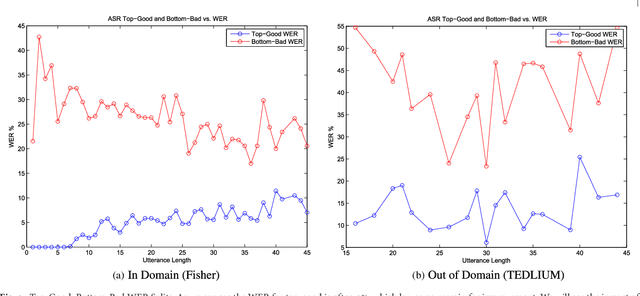
Automatic speech recognition (ASR) systems lack joint optimization during decoding over the acoustic, lexical and language models; for instance the ASR will often prune words due to acoustics using short-term context, prior to rescoring with long-term context. In this work we model the automated speech transcription process as a noisy transformation channel and propose an error correction system that can learn from the aggregate errors of all the independent modules constituting the ASR. The proposed system can exploit long-term context using a neural network language model and can better choose between existing ASR output possibilities as well as re-introduce previously pruned and unseen (out-of-vocabulary) phrases. The system provides significant corrections under poorly performing ASR conditions without degrading any accurate transcriptions. The proposed system can thus be independently optimized and post-process the output of even a highly optimized ASR. We show that the system consistently provides improvements over the baseline ASR. We also show that it performs better when used on out-of-domain and mismatched test data and under high-error ASR conditions. Finally, an extensive analysis of the type of errors corrected by our system is presented.
Token-Level Supervised Contrastive Learning for Punctuation Restoration
Jul 19, 2021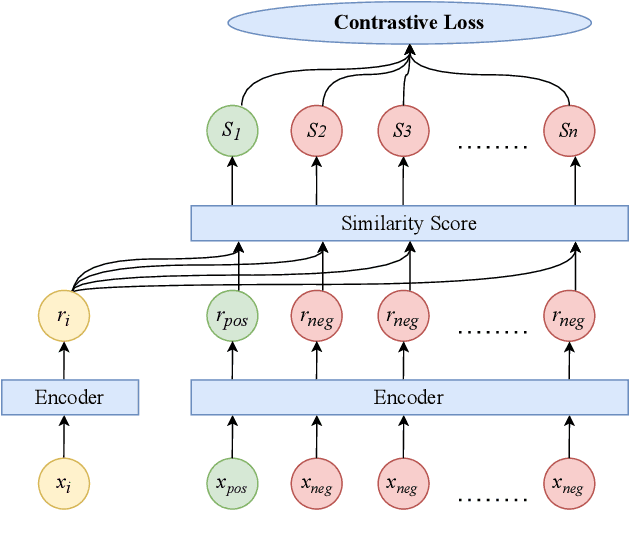
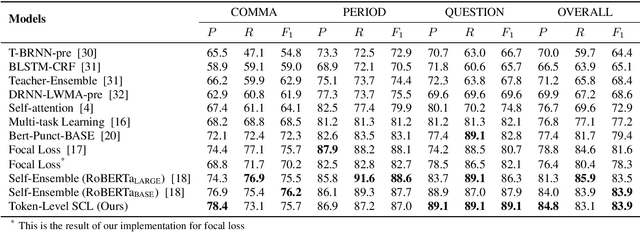
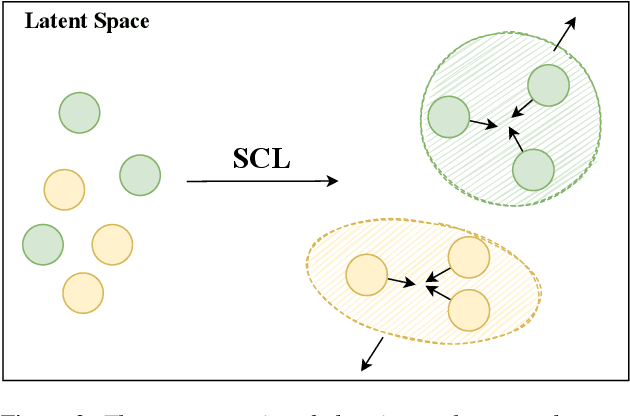

Punctuation is critical in understanding natural language text. Currently, most automatic speech recognition (ASR) systems do not generate punctuation, which affects the performance of downstream tasks, such as intent detection and slot filling. This gives rise to the need for punctuation restoration. Recent work in punctuation restoration heavily utilizes pre-trained language models without considering data imbalance when predicting punctuation classes. In this work, we address this problem by proposing a token-level supervised contrastive learning method that aims at maximizing the distance of representation of different punctuation marks in the embedding space. The result shows that training with token-level supervised contrastive learning obtains up to 3.2% absolute F1 improvement on the test set.
Noisy-to-Noisy Voice Conversion Framework with Denoising Model
Sep 22, 2021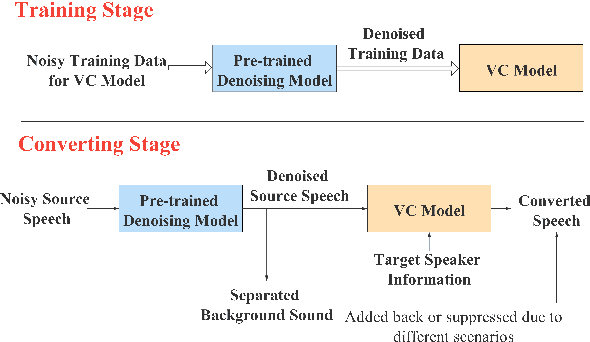
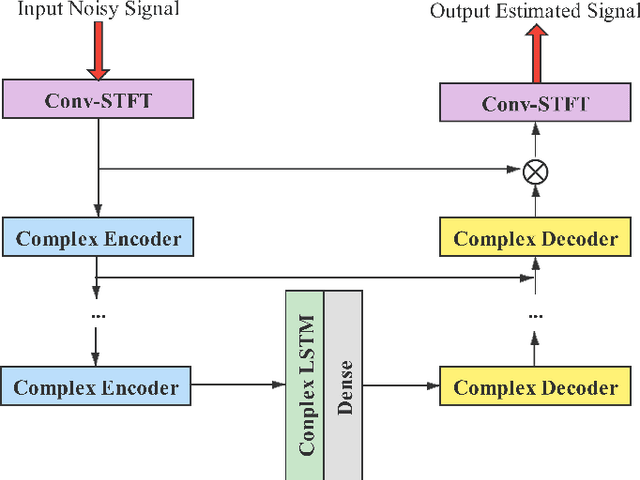
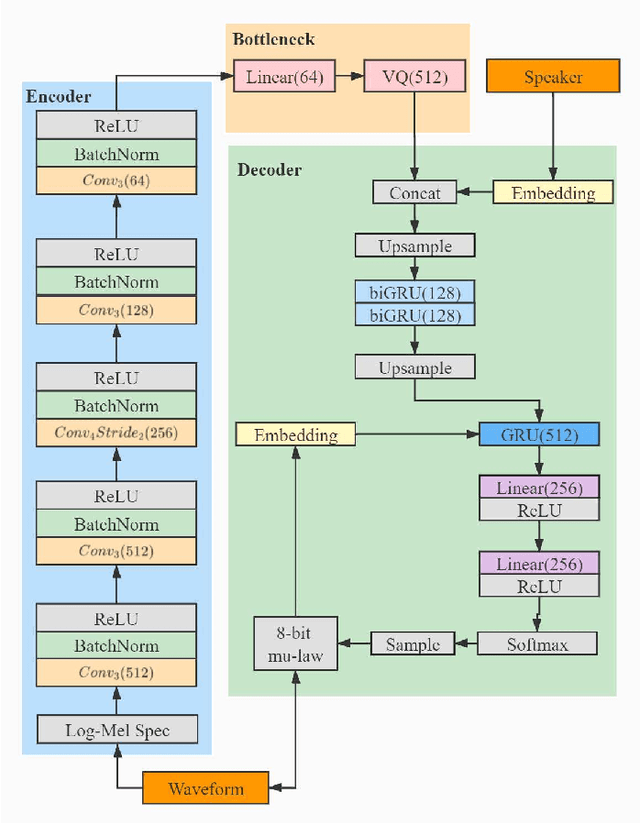
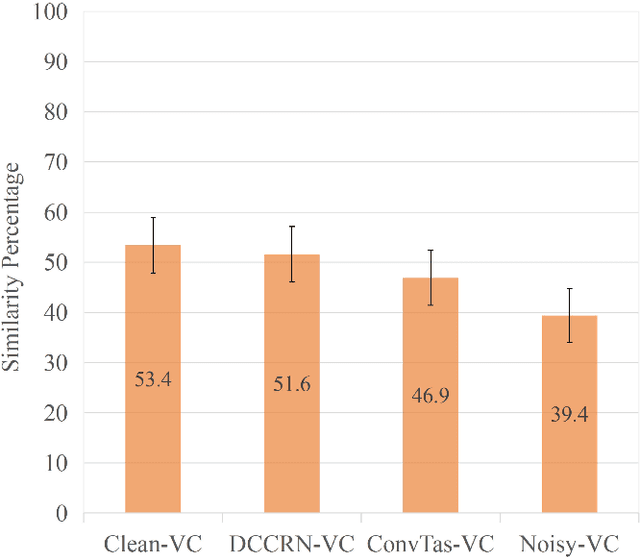
In a conventional voice conversion (VC) framework, a VC model is often trained with a clean dataset consisting of speech data carefully recorded and selected by minimizing background interference. However, collecting such a high-quality dataset is expensive and time-consuming. Leveraging crowd-sourced speech data in training is more economical. Moreover, for some real-world VC scenarios such as VC in video and VC-based data augmentation for speech recognition systems, the background sounds themselves are also informative and need to be maintained. In this paper, to explore VC with the flexibility of handling background sounds, we propose a noisy-to-noisy (N2N) VC framework composed of a denoising module and a VC module. With the proposed framework, we can convert the speaker's identity while preserving the background sounds. Both objective and subjective evaluations are conducted, and the results reveal the effectiveness of the proposed framework.