 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Comparative Study on Non-Autoregressive Modelings for Speech-to-Text Generation
Oct 11, 2021

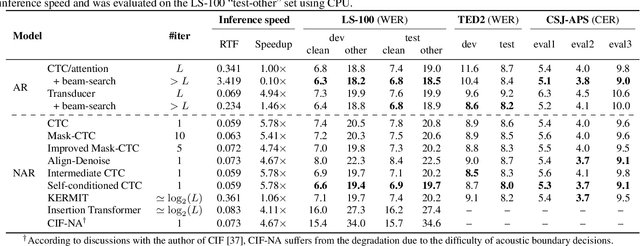
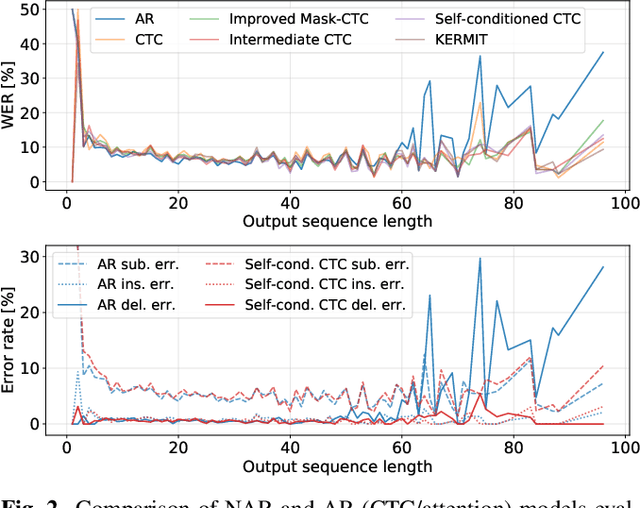
Non-autoregressive (NAR) models simultaneously generate multiple outputs in a sequence, which significantly reduces the inference speed at the cost of accuracy drop compared to autoregressive baselines. Showing great potential for real-time applications, an increasing number of NAR models have been explored in different fields to mitigate the performance gap against AR models. In this work, we conduct a comparative study of various NAR modeling methods for end-to-end automatic speech recognition (ASR). Experiments are performed in the state-of-the-art setting using ESPnet. The results on various tasks provide interesting findings for developing an understanding of NAR ASR, such as the accuracy-speed trade-off and robustness against long-form utterances. We also show that the techniques can be combined for further improvement and applied to NAR end-to-end speech translation. All the implementations are publicly available to encourage further research in NAR speech processing.
Self-supervised reinforcement learning for speaker localisation with the iCub humanoid robot
Nov 12, 2020
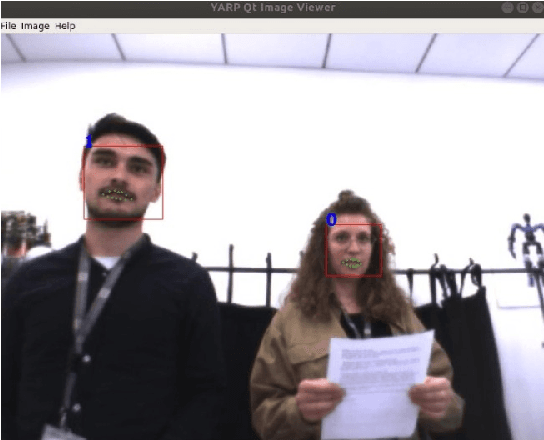
In the future robots will interact more and more with humans and will have to communicate naturally and efficiently. Automatic speech recognition systems (ASR) will play an important role in creating natural interactions and making robots better companions. Humans excel in speech recognition in noisy environments and are able to filter out noise. Looking at a person's face is one of the mechanisms that humans rely on when it comes to filtering speech in such noisy environments. Having a robot that can look toward a speaker could benefit ASR performance in challenging environments. To this aims, we propose a self-supervised reinforcement learning-based framework inspired by the early development of humans to allow the robot to autonomously create a dataset that is later used to learn to localize speakers with a deep learning network.
Lightweight dynamic filter for keyword spotting
Sep 27, 2021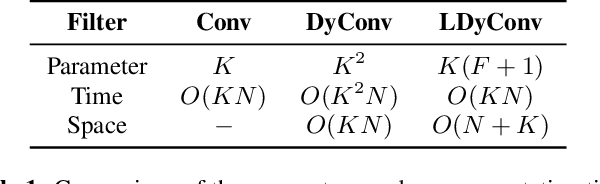
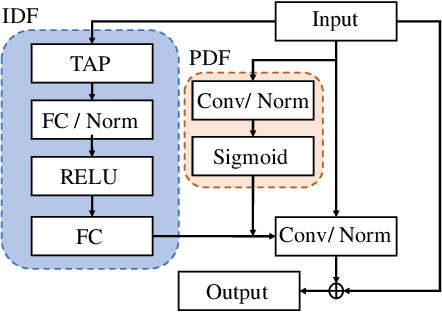
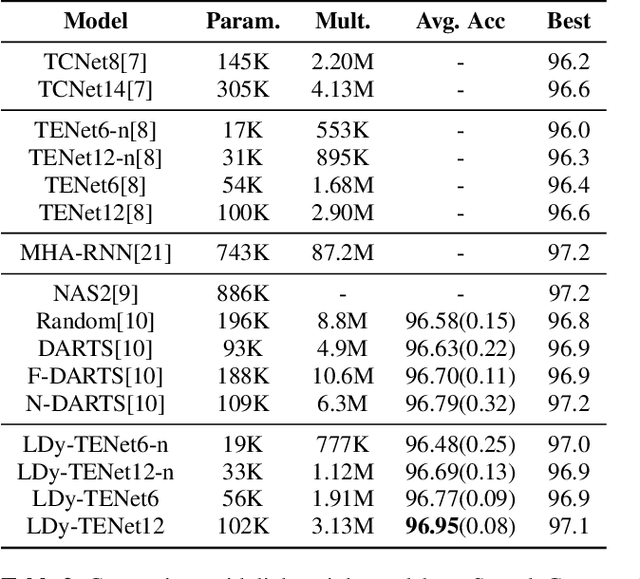
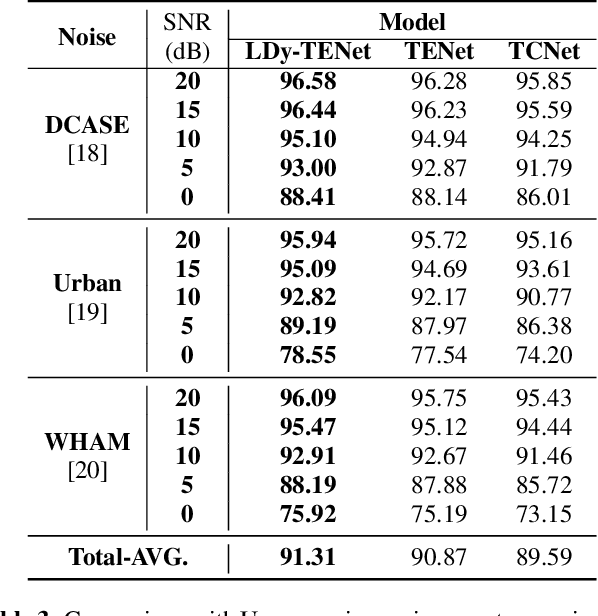
Keyword Spotting (KWS) from speech signal is widely applied for being fully hands free speech recognition. The KWS network is designed as a small footprint model to be constantly monitored. Recently, dynamic filter based models are applied in deep learning applications to enhance a system's robustness or accuracy. However, as a dynamic filter framework requires high computational cost, the usage is limited to the condition of the device. In this paper, we proposed a lightweight dynamic filter to improve the performance of KWS. Our proposed model divides dynamic filter as two branches to reduce the computational complexity. This lightweight dynamic filter is applied to the front-end of KWS to enhance the separability of the input data. The experiments show that our model is robustly working on unseen noise and small training data environment by using small computational resource.
Long Expressive Memory for Sequence Modeling
Oct 10, 2021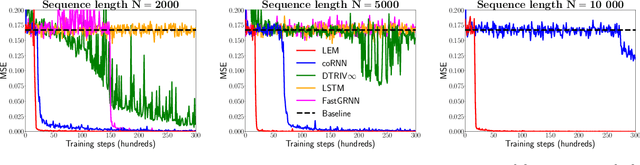
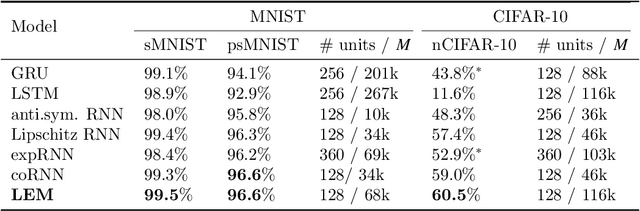
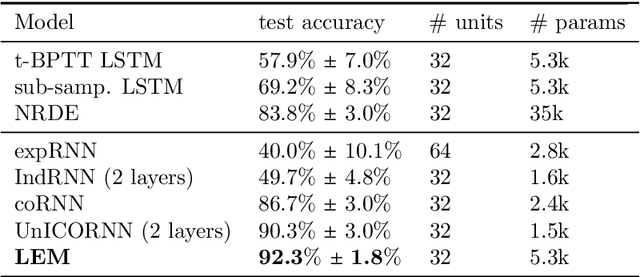
We propose a novel method called Long Expressive Memory (LEM) for learning long-term sequential dependencies. LEM is gradient-based, it can efficiently process sequential tasks with very long-term dependencies, and it is sufficiently expressive to be able to learn complicated input-output maps. To derive LEM, we consider a system of multiscale ordinary differential equations, as well as a suitable time-discretization of this system. For LEM, we derive rigorous bounds to show the mitigation of the exploding and vanishing gradients problem, a well-known challenge for gradient-based recurrent sequential learning methods. We also prove that LEM can approximate a large class of dynamical systems to high accuracy. Our empirical results, ranging from image and time-series classification through dynamical systems prediction to speech recognition and language modeling, demonstrate that LEM outperforms state-of-the-art recurrent neural networks, gated recurrent units, and long short-term memory models.
Prompt-tuning in ASR systems for efficient domain-adaptation
Oct 22, 2021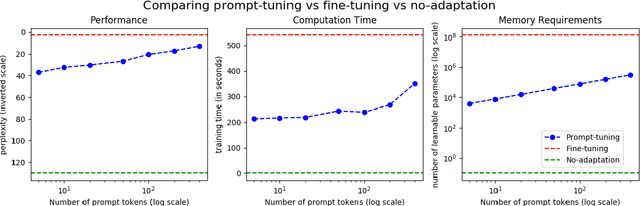
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we overcome the problem using prompt-tuning, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve much better perplexity scores over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. We replicate our findings in perplexity numbers to Word Error Rate in a domain-specific ASR system for one such domain.
SEMOUR: A Scripted Emotional Speech Repository for Urdu
May 19, 2021
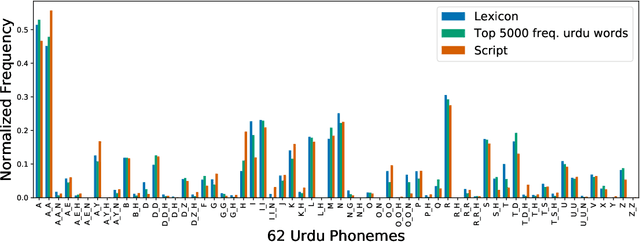
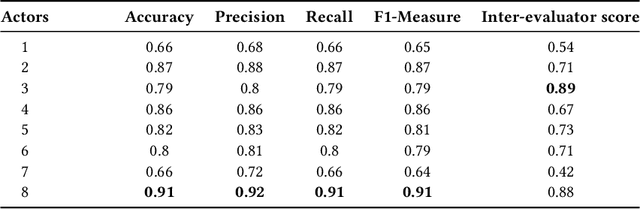
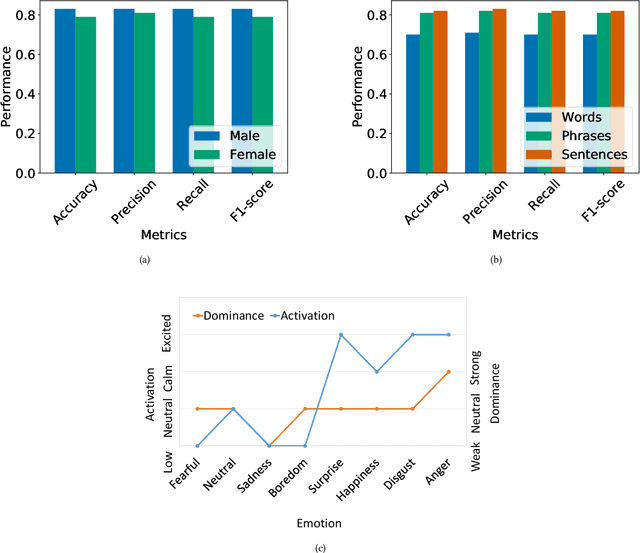
Designing reliable Speech Emotion Recognition systems is a complex task that inevitably requires sufficient data for training purposes. Such extensive datasets are currently available in only a few languages, including English, German, and Italian. In this paper, we present SEMOUR, the first scripted database of emotion-tagged speech in the Urdu language, to design an Urdu Speech Recognition System. Our gender-balanced dataset contains 15,040 unique instances recorded by eight professional actors eliciting a syntactically complex script. The dataset is phonetically balanced, and reliably exhibits a varied set of emotions as marked by the high agreement scores among human raters in experiments. We also provide various baseline speech emotion prediction scores on the database, which could be used for various applications like personalized robot assistants, diagnosis of psychological disorders, and getting feedback from a low-tech-enabled population, etc. On a random test sample, our model correctly predicts an emotion with a state-of-the-art 92% accuracy.
Large-Scale Pre-Training of End-to-End Multi-Talker ASR for Meeting Transcription with Single Distant Microphone
Apr 12, 2021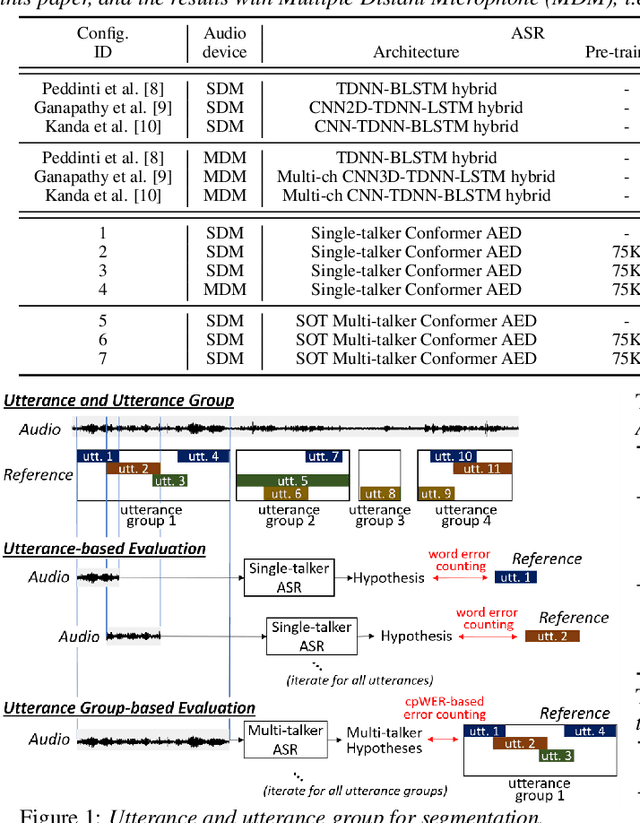


Transcribing meetings containing overlapped speech with only a single distant microphone (SDM) has been one of the most challenging problems for automatic speech recognition (ASR). While various approaches have been proposed, all previous studies on the monaural overlapped speech recognition problem were based on either simulation data or small-scale real data. In this paper, we extensively investigate a two-step approach where we first pre-train a serialized output training (SOT)-based multi-talker ASR by using large-scale simulation data and then fine-tune the model with a small amount of real meeting data. Experiments are conducted by utilizing 75 thousand (K) hours of our internal single-talker recording to simulate a total of 900K hours of multi-talker audio segments for supervised pre-training. With fine-tuning on the 70 hours of the AMI-SDM training data, our SOT ASR model achieves a word error rate (WER) of 21.2% for the AMI-SDM evaluation set while automatically counting speakers in each test segment. This result is not only significantly better than the previous state-of-the-art WER of 36.4% with oracle utterance boundary information but also better than a result by a similarly fine-tuned single-talker ASR model applied to beamformed audio.
One model to enhance them all: array geometry agnostic multi-channel personalized speech enhancement
Oct 20, 2021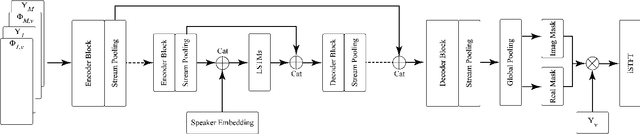
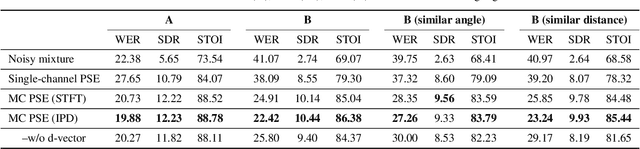
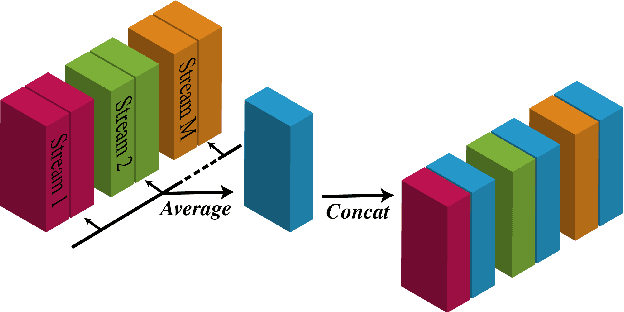
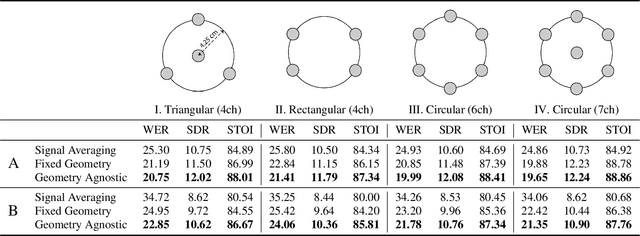
With the recent surge of video conferencing tools usage, providing high-quality speech signals and accurate captions have become essential to conduct day-to-day business or connect with friends and families. Single-channel personalized speech enhancement (PSE) methods show promising results compared with the unconditional speech enhancement (SE) methods in these scenarios due to their ability to remove interfering speech in addition to the environmental noise. In this work, we leverage spatial information afforded by microphone arrays to improve such systems' performance further. We investigate the relative importance of speaker embeddings and spatial features. Moreover, we propose a new causal array-geometry-agnostic multi-channel PSE model, which can generate a high-quality enhanced signal from arbitrary microphone geometry. Experimental results show that the proposed geometry agnostic model outperforms the model trained on a specific microphone array geometry in both speech quality and automatic speech recognition accuracy. We also demonstrate the effectiveness of the proposed approach for unseen array geometries.
Automatic Learning of Subword Dependent Model Scales
Oct 18, 2021



To improve the performance of state-of-the-art automatic speech recognition systems it is common practice to include external knowledge sources such as language models or prior corrections. This is usually done via log-linear model combination using separate scaling parameters for each model. Typically these parameters are manually optimized on some held-out data. In this work we propose to optimize these scaling parameters via automatic differentiation and stochastic gradient decent similar to the neural network model parameters. We show on the LibriSpeech (LBS) and Switchboard (SWB) corpora that the model scales for a combination of attentionbased encoder-decoder acoustic model and language model can be learned as effectively as with manual tuning. We further extend this approach to subword dependent model scales which could not be tuned manually which leads to 7% improvement on LBS and 3% on SWB. We also show that joint training of scales and model parameters is possible and gives additional 6% improvement on LBS.