 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Residual Adapters for Parameter-Efficient ASR Adaptation to Atypical and Accented Speech
Sep 14, 2021
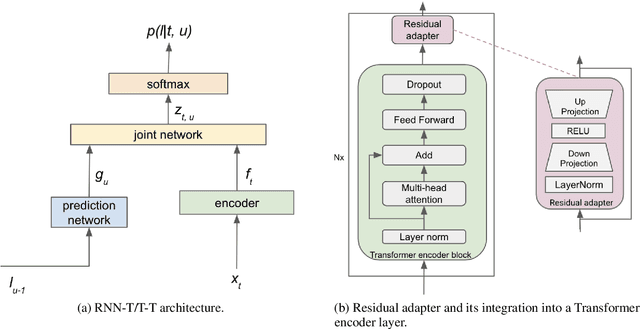
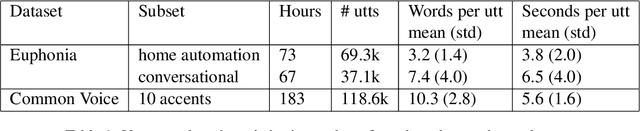
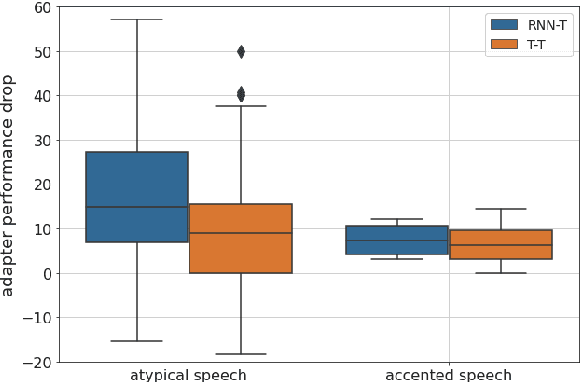
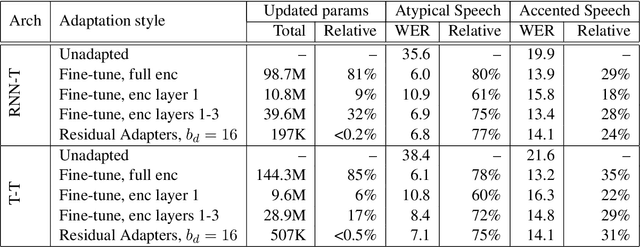
Automatic Speech Recognition (ASR) systems are often optimized to work best for speakers with canonical speech patterns. Unfortunately, these systems perform poorly when tested on atypical speech and heavily accented speech. It has previously been shown that personalization through model fine-tuning substantially improves performance. However, maintaining such large models per speaker is costly and difficult to scale. We show that by adding a relatively small number of extra parameters to the encoder layers via so-called residual adapter, we can achieve similar adaptation gains compared to model fine-tuning, while only updating a tiny fraction (less than 0.5%) of the model parameters. We demonstrate this on two speech adaptation tasks (atypical and accented speech) and for two state-of-the-art ASR architectures.
Continuous Speech Separation with Recurrent Selective Attention Network
Oct 28, 2021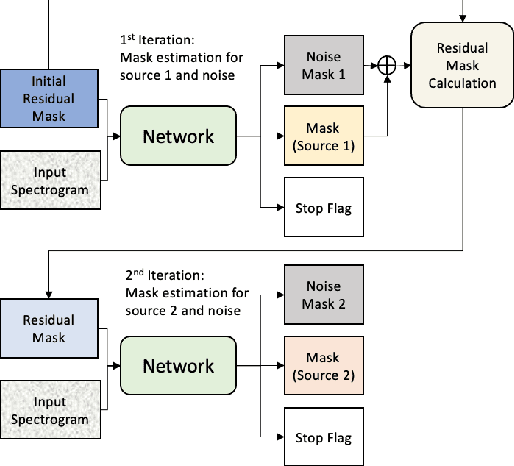
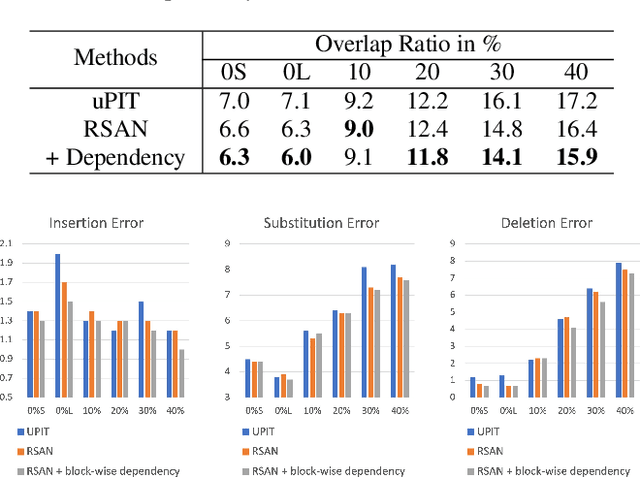
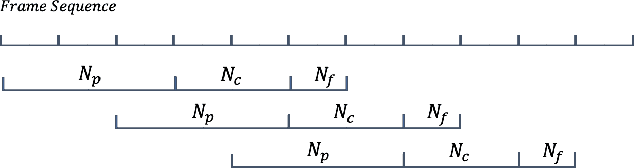
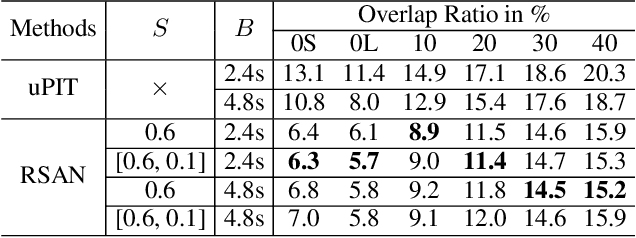
While permutation invariant training (PIT) based continuous speech separation (CSS) significantly improves the conversation transcription accuracy, it often suffers from speech leakages and failures in separation at "hot spot" regions because it has a fixed number of output channels. In this paper, we propose to apply recurrent selective attention network (RSAN) to CSS, which generates a variable number of output channels based on active speaker counting. In addition, we propose a novel block-wise dependency extension of RSAN by introducing dependencies between adjacent processing blocks in the CSS framework. It enables the network to utilize the separation results from the previous blocks to facilitate the current block processing. Experimental results on the LibriCSS dataset show that the RSAN-based CSS (RSAN-CSS) network consistently improves the speech recognition accuracy over PIT-based models. The proposed block-wise dependency modeling further boosts the performance of RSAN-CSS.
Wav2Vec2.0 on the Edge: Performance Evaluation
Feb 12, 2022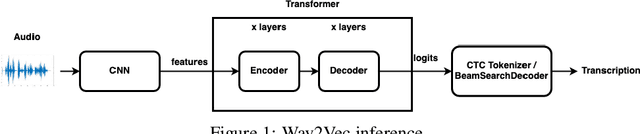


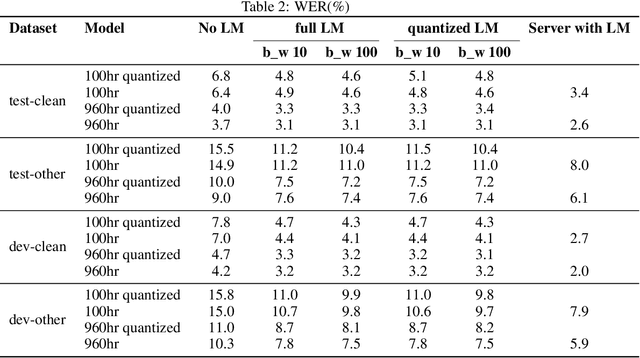
Wav2Vec2.0 is a state-of-the-art model which learns speech representations through unlabeled speech data, aka, self supervised learning. The pretrained model is then fine tuned on small amounts of labeled data to use it for speech-to-text and machine translation tasks. Wav2Vec 2.0 is a transformative solution for low resource languages as it is mainly developed using unlabeled audio data. Getting large amounts of labeled data is resource intensive and especially challenging to do for low resource languages such as Swahilli, Tatar, etc. Furthermore, Wav2Vec2.0 word-error-rate(WER) matches or surpasses the very recent supervised learning algorithms while using 100x less labeled data. Given its importance and enormous potential in enabling speech based tasks on world's 7000 languages, it is key to evaluate the accuracy, latency and efficiency of this model on low resource and low power edge devices and investigate the feasibility of using it in such devices for private, secure and reliable speech based tasks. On-device speech tasks preclude sending audio data to the server hence inherently providing privacy, reduced latency and enhanced reliability. In this paper, Wav2Vec2.0 model's accuracy and latency has been evaluated on Raspberry Pi along with the KenLM language model for speech recognition tasks. How to tune certain parameters to achieve desired level of WER rate and latency while meeting the CPU, memory and energy budgets of the product has been discussed.
SpliceOut: A Simple and Efficient Audio Augmentation Method
Oct 13, 2021
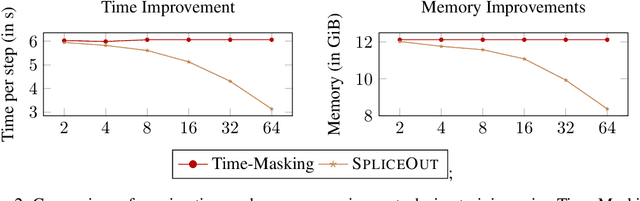
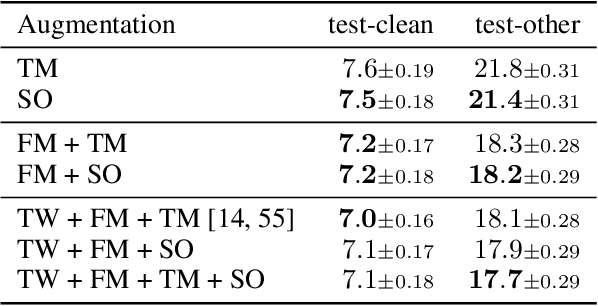
Time masking has become a de facto augmentation technique for speech and audio tasks, including automatic speech recognition (ASR) and audio classification, most notably as a part of SpecAugment. In this work, we propose SpliceOut, a simple modification to time masking which makes it computationally more efficient. SpliceOut performs comparably to (and sometimes outperforms) SpecAugment on a wide variety of speech and audio tasks, including ASR for seven different languages using varying amounts of training data, as well as on speech translation, sound and music classification, thus establishing itself as a broadly applicable audio augmentation method. SpliceOut also provides additional gains when used in conjunction with other augmentation techniques. Apart from the fully-supervised setting, we also demonstrate that SpliceOut can complement unsupervised representation learning with performance gains in the semi-supervised and self-supervised settings.
LightSeq2: Accelerated Training for Transformer-based Models on GPUs
Oct 27, 2021

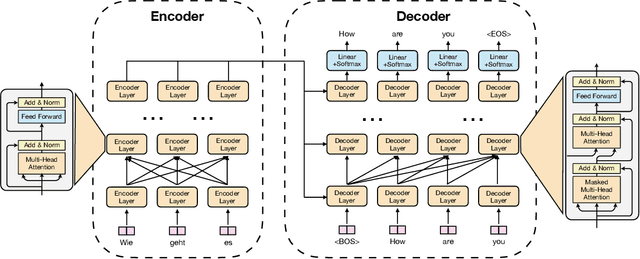
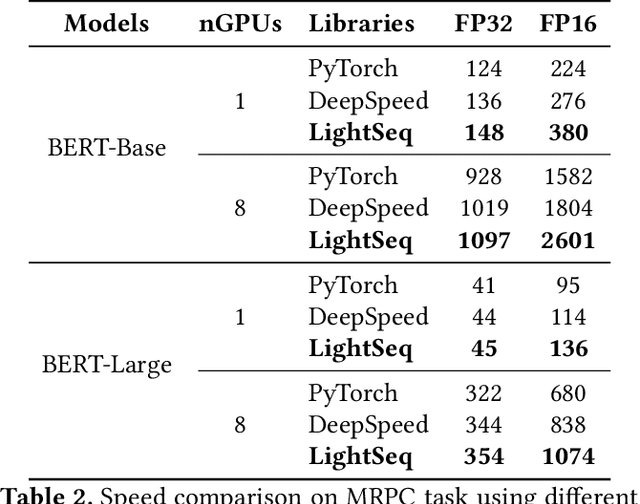
Transformer-based models have proven to be powerful in many natural language, computer vision, and speech recognition applications. It is expensive to train these types of models due to unfixed input length, complex computation, and large numbers of parameters. Existing systems either only focus on efficient inference or optimize only BERT-like encoder models. In this paper, we present LightSeq2, a system for efficient training of Transformer-based models on GPUs. We propose a series of GPU optimization techniques tailored to computation flow and memory access patterns of neural layers in Transformers. LightSeq2 supports a variety of network architectures, including BERT (encoder-only), GPT (decoder-only), and Transformer (encoder-decoder). Our experiments on GPUs with varying models and datasets show that LightSeq2 is 1.4-3.5x faster than previous systems. In particular, it gains 308% training speedup compared with existing systems on a large public machine translation benchmark (WMT14 English-German).
Neural Dependency Coding inspired Multimodal Fusion
Sep 28, 2021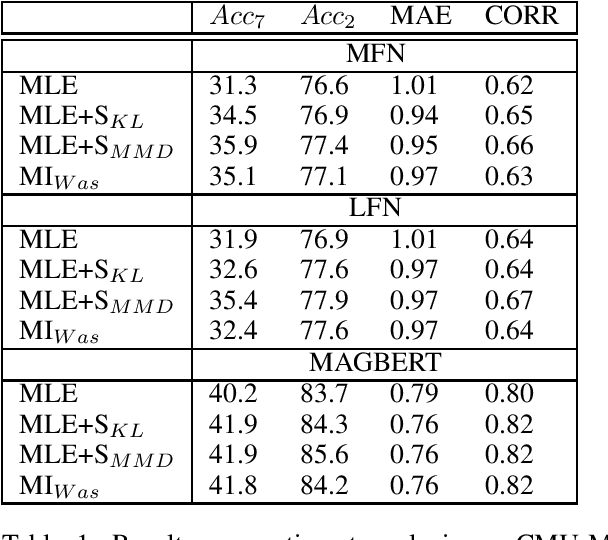
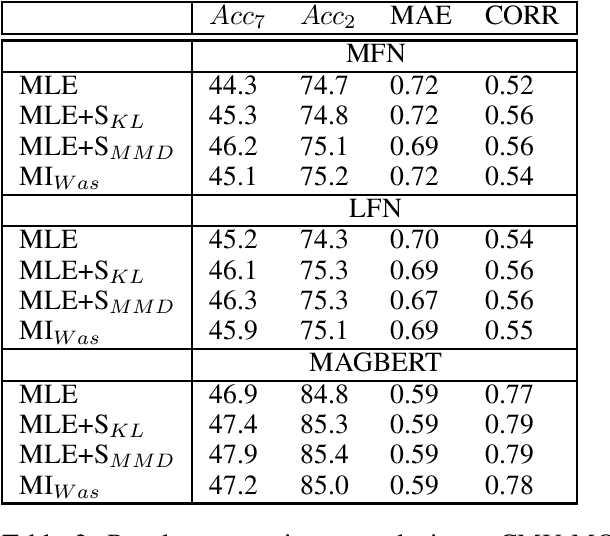
Information integration from different modalities is an active area of research. Human beings and, in general, biological neural systems are quite adept at using a multitude of signals from different sensory perceptive fields to interact with the environment and each other. Recent work in deep fusion models via neural networks has led to substantial improvements over unimodal approaches in areas like speech recognition, emotion recognition and analysis, captioning and image description. However, such research has mostly focused on architectural changes allowing for fusion of different modalities while keeping the model complexity manageable. Inspired by recent neuroscience ideas about multisensory integration and processing, we investigate the effect of synergy maximizing loss functions. Experiments on multimodal sentiment analysis tasks: CMU-MOSI and CMU-MOSEI with different models show that our approach provides a consistent performance boost.
Spatial Diffuseness Features for DNN-Based Speech Recognition in Noisy and Reverberant Environments
Feb 16, 2015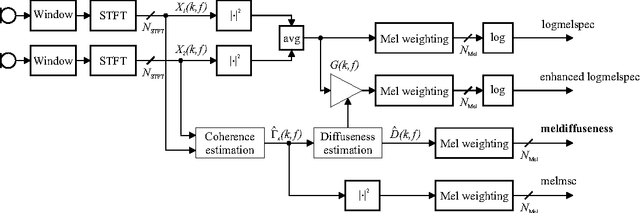

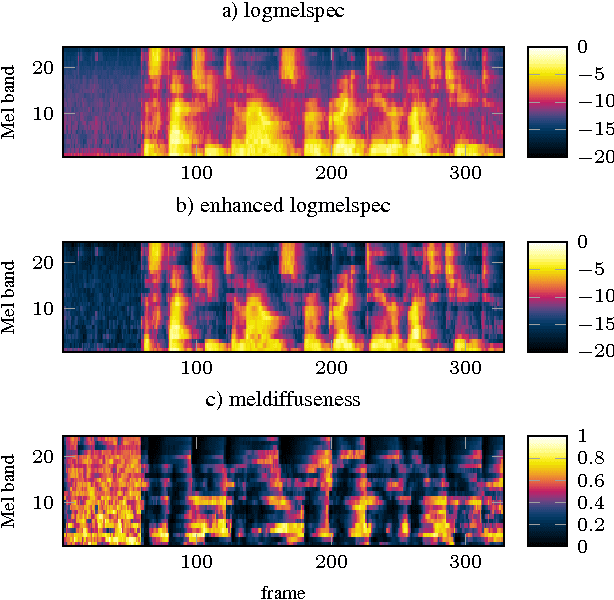
We propose a spatial diffuseness feature for deep neural network (DNN)-based automatic speech recognition to improve recognition accuracy in reverberant and noisy environments. The feature is computed in real-time from multiple microphone signals without requiring knowledge or estimation of the direction of arrival, and represents the relative amount of diffuse noise in each time and frequency bin. It is shown that using the diffuseness feature as an additional input to a DNN-based acoustic model leads to a reduced word error rate for the REVERB challenge corpus, both compared to logmelspec features extracted from noisy signals, and features enhanced by spectral subtraction.
Subject Envelope based Multitype Reconstruction Algorithm of Speech Samples of Parkinson's Disease
Aug 23, 2021



The risk of Parkinson's disease (PD) is extremely serious, and PD speech recognition is an effective method of diagnosis nowadays. However, due to the influence of the disease stage, corpus, and other factors on data collection, the ability of every samples within one subject to reflect the status of PD vary. No samples are useless totally, and not samples are 100% perfect. This characteristic means that it is not suitable just to remove some samples or keep some samples. It is necessary to consider the sample transformation for obtaining high quality new samples. Unfortunately, existing PD speech recognition methods focus mainly on feature learning and classifier design rather than sample learning, and few methods consider the sample transformation. To solve the problem above, a PD speech sample transformation algorithm based on multitype reconstruction operators is proposed in this paper. The algorithm is divided into four major steps. Three types of reconstruction operators are designed in the algorithm: types A, B and C. Concerning the type A operator, the original dataset is directly reconstructed by designing a linear transformation to obtain the first dataset. The type B operator is designed for clustering and linear transformation of the dataset to obtain the second new dataset. The third operator, namely, the type C operator, reconstructs the dataset by clustering and convolution to obtain the third dataset. Finally, the base classifier is trained based on the three new datasets, and then the classification results are fused by decision weighting. In the experimental section, two representative PD speech datasets are used for verification. The results show that the proposed algorithm is effective. Compared with other algorithms, the proposed algorithm achieves apparent improvements in terms of classification accuracy.
Lhotse: a speech data representation library for the modern deep learning ecosystem
Oct 25, 2021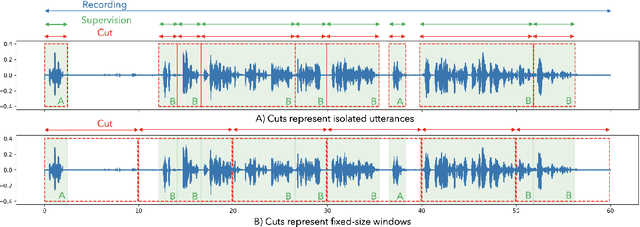
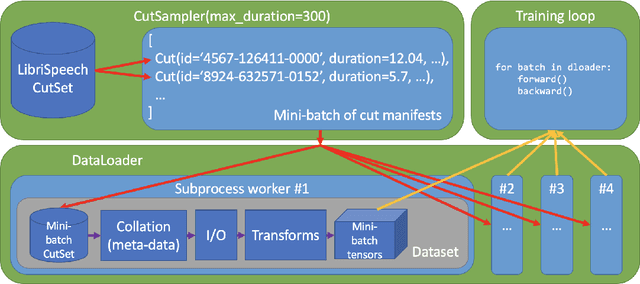
Speech data is notoriously difficult to work with due to a variety of codecs, lengths of recordings, and meta-data formats. We present Lhotse, a speech data representation library that draws upon lessons learned from Kaldi speech recognition toolkit and brings its concepts into the modern deep learning ecosystem. Lhotse provides a common JSON description format with corresponding Python classes and data preparation recipes for over 30 popular speech corpora. Various datasets can be easily combined together and re-purposed for different tasks. The library handles multi-channel recordings, long recordings, local and cloud storage, lazy and on-the-fly operations amongst other features. We introduce Cut and CutSet concepts, which simplify common data wrangling tasks for audio and help incorporate acoustic context of speech utterances. Finally, we show how Lhotse leverages PyTorch data API abstractions and adopts them to handle speech data for deep learning.
Deep Speech: Scaling up end-to-end speech recognition
Dec 19, 2014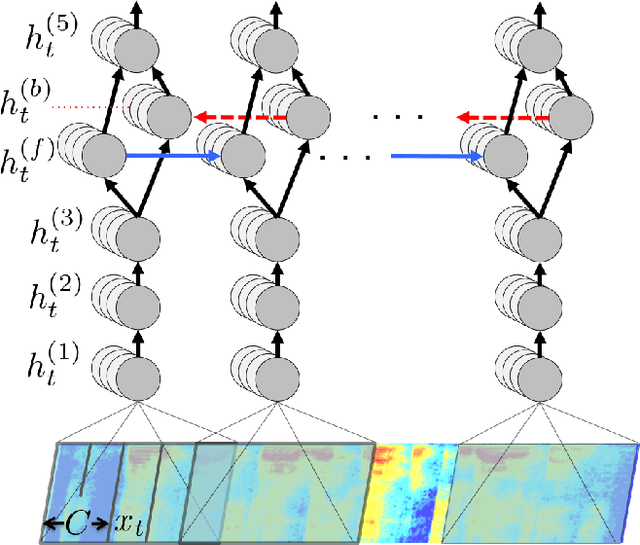

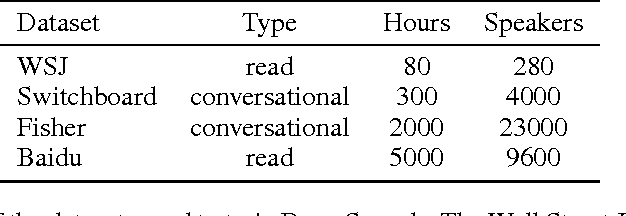

We present a state-of-the-art speech recognition system developed using end-to-end deep learning. Our architecture is significantly simpler than traditional speech systems, which rely on laboriously engineered processing pipelines; these traditional systems also tend to perform poorly when used in noisy environments. In contrast, our system does not need hand-designed components to model background noise, reverberation, or speaker variation, but instead directly learns a function that is robust to such effects. We do not need a phoneme dictionary, nor even the concept of a "phoneme." Key to our approach is a well-optimized RNN training system that uses multiple GPUs, as well as a set of novel data synthesis techniques that allow us to efficiently obtain a large amount of varied data for training. Our system, called Deep Speech, outperforms previously published results on the widely studied Switchboard Hub5'00, achieving 16.0% error on the full test set. Deep Speech also handles challenging noisy environments better than widely used, state-of-the-art commercial speech systems.