 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Improving Punctuation Restoration for Speech Transcripts via External Data
Oct 01, 2021
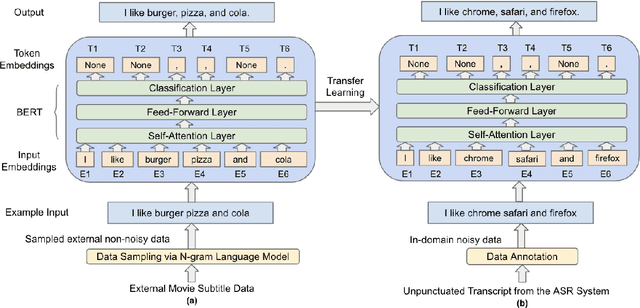

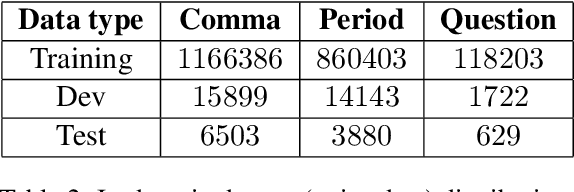

Automatic Speech Recognition (ASR) systems generally do not produce punctuated transcripts. To make transcripts more readable and follow the expected input format for downstream language models, it is necessary to add punctuation marks. In this paper, we tackle the punctuation restoration problem specifically for the noisy text (e.g., phone conversation scenarios). To leverage the available written text datasets, we introduce a data sampling technique based on an n-gram language model to sample more training data that are similar to our in-domain data. Moreover, we propose a two-stage fine-tuning approach that utilizes the sampled external data as well as our in-domain dataset for models based on BERT. Extensive experiments show that the proposed approach outperforms the baseline with an improvement of 1:12% F1 score.
Wav2Vec2.0 on the Edge: Performance Evaluation
Feb 12, 2022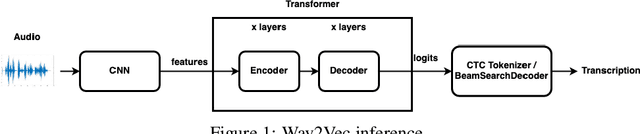


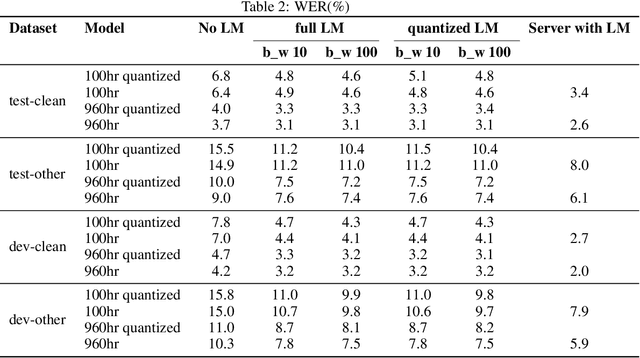
Wav2Vec2.0 is a state-of-the-art model which learns speech representations through unlabeled speech data, aka, self supervised learning. The pretrained model is then fine tuned on small amounts of labeled data to use it for speech-to-text and machine translation tasks. Wav2Vec 2.0 is a transformative solution for low resource languages as it is mainly developed using unlabeled audio data. Getting large amounts of labeled data is resource intensive and especially challenging to do for low resource languages such as Swahilli, Tatar, etc. Furthermore, Wav2Vec2.0 word-error-rate(WER) matches or surpasses the very recent supervised learning algorithms while using 100x less labeled data. Given its importance and enormous potential in enabling speech based tasks on world's 7000 languages, it is key to evaluate the accuracy, latency and efficiency of this model on low resource and low power edge devices and investigate the feasibility of using it in such devices for private, secure and reliable speech based tasks. On-device speech tasks preclude sending audio data to the server hence inherently providing privacy, reduced latency and enhanced reliability. In this paper, Wav2Vec2.0 model's accuracy and latency has been evaluated on Raspberry Pi along with the KenLM language model for speech recognition tasks. How to tune certain parameters to achieve desired level of WER rate and latency while meeting the CPU, memory and energy budgets of the product has been discussed.
Towards Identity Preserving Normal to Dysarthric Voice Conversion
Oct 15, 2021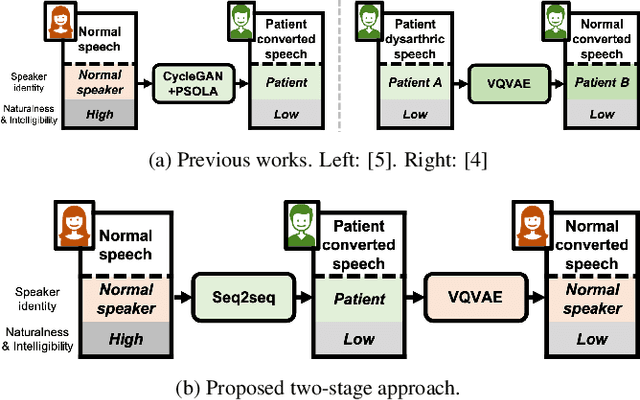
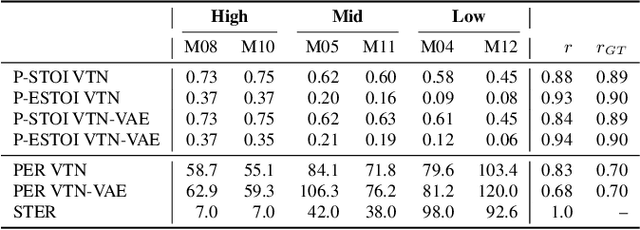

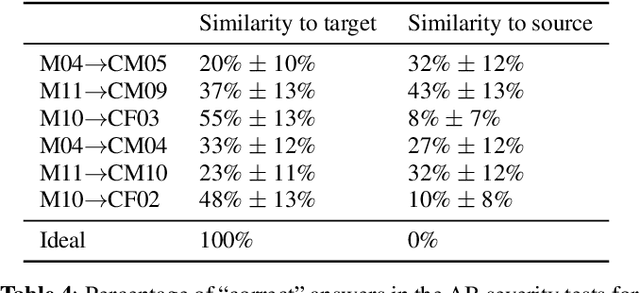
We present a voice conversion framework that converts normal speech into dysarthric speech while preserving the speaker identity. Such a framework is essential for (1) clinical decision making processes and alleviation of patient stress, (2) data augmentation for dysarthric speech recognition. This is an especially challenging task since the converted samples should capture the severity of dysarthric speech while being highly natural and possessing the speaker identity of the normal speaker. To this end, we adopted a two-stage framework, which consists of a sequence-to-sequence model and a nonparallel frame-wise model. Objective and subjective evaluations were conducted on the UASpeech dataset, and results showed that the method was able to yield reasonable naturalness and capture severity aspects of the pathological speech. On the other hand, the similarity to the normal source speaker's voice was limited and requires further improvements.
End-to-end Continuous Speech Recognition using Attention-based Recurrent NN: First Results
Dec 04, 2014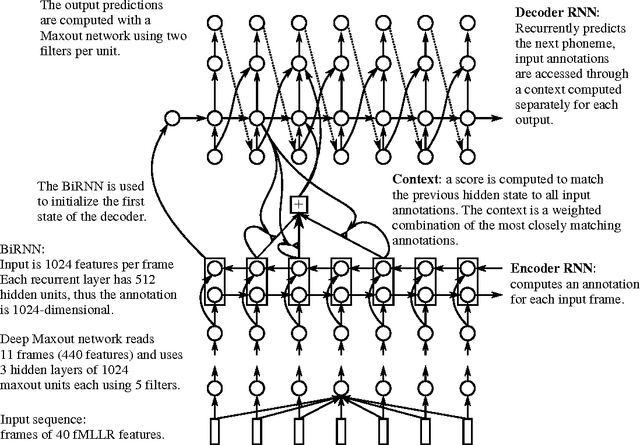
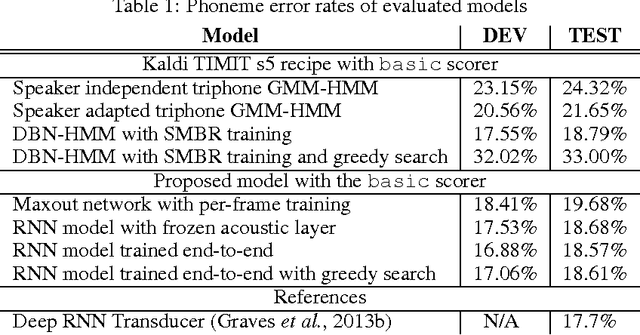
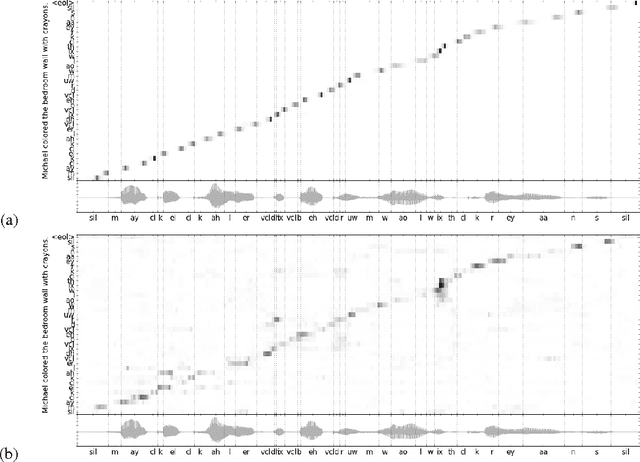
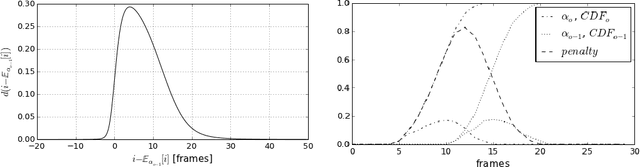
We replace the Hidden Markov Model (HMM) which is traditionally used in in continuous speech recognition with a bi-directional recurrent neural network encoder coupled to a recurrent neural network decoder that directly emits a stream of phonemes. The alignment between the input and output sequences is established using an attention mechanism: the decoder emits each symbol based on a context created with a subset of input symbols elected by the attention mechanism. We report initial results demonstrating that this new approach achieves phoneme error rates that are comparable to the state-of-the-art HMM-based decoders, on the TIMIT dataset.
Bayesian Transformer Language Models for Speech Recognition
Feb 09, 2021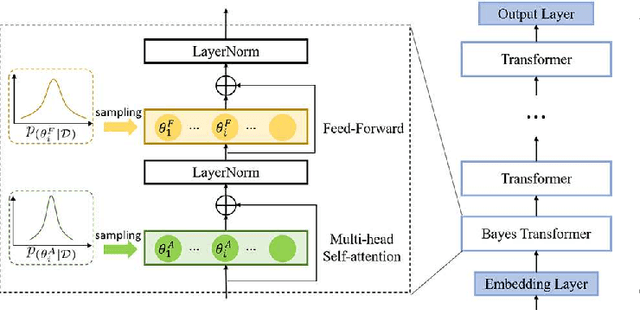
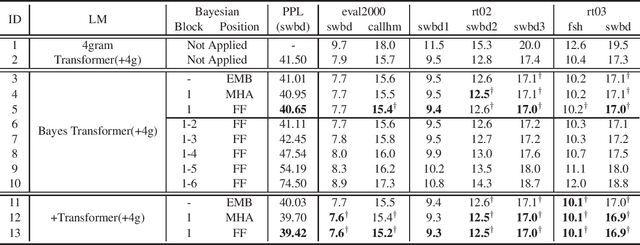
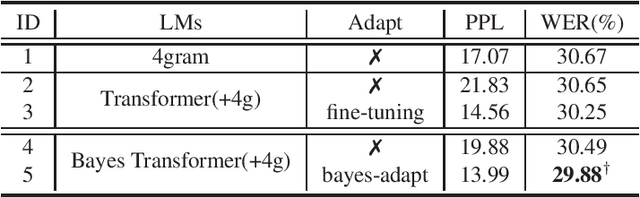
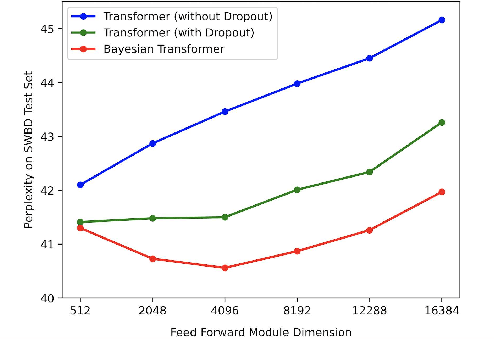
State-of-the-art neural language models (LMs) represented by Transformers are highly complex. Their use of fixed, deterministic parameter estimates fail to account for model uncertainty and lead to over-fitting and poor generalization when given limited training data. In order to address these issues, this paper proposes a full Bayesian learning framework for Transformer LM estimation. Efficient variational inference based approaches are used to estimate the latent parameter posterior distributions associated with different parts of the Transformer model architecture including multi-head self-attention, feed forward and embedding layers. Statistically significant word error rate (WER) reductions up to 0.5\% absolute (3.18\% relative) and consistent perplexity gains were obtained over the baseline Transformer LMs on state-of-the-art Switchboard corpus trained LF-MMI factored TDNN systems with i-Vector speaker adaptation. Performance improvements were also obtained on a cross domain LM adaptation task requiring porting a Transformer LM trained on the Switchboard and Fisher data to a low-resource DementiaBank elderly speech corpus.
Residual Adapters for Parameter-Efficient ASR Adaptation to Atypical and Accented Speech
Sep 14, 2021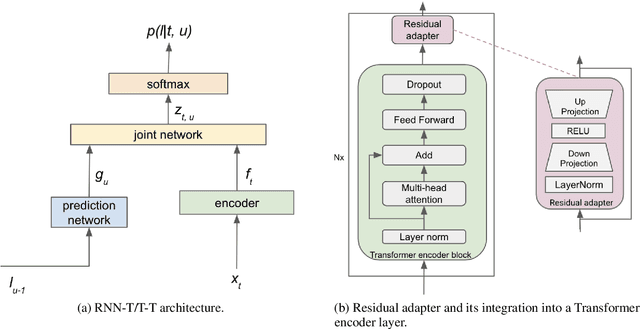
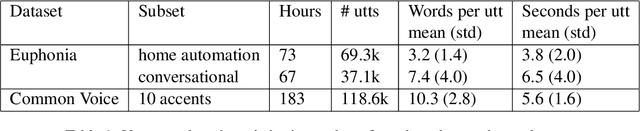
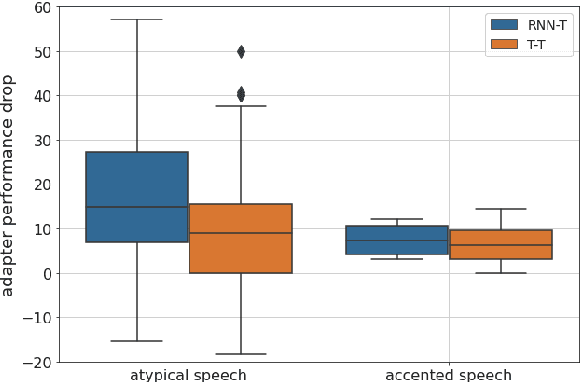
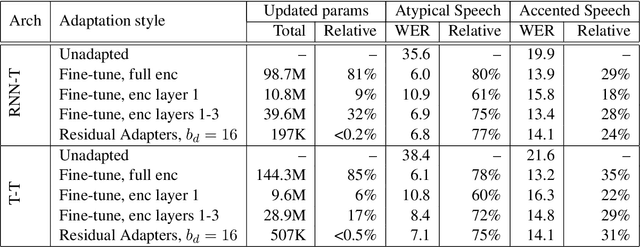
Automatic Speech Recognition (ASR) systems are often optimized to work best for speakers with canonical speech patterns. Unfortunately, these systems perform poorly when tested on atypical speech and heavily accented speech. It has previously been shown that personalization through model fine-tuning substantially improves performance. However, maintaining such large models per speaker is costly and difficult to scale. We show that by adding a relatively small number of extra parameters to the encoder layers via so-called residual adapter, we can achieve similar adaptation gains compared to model fine-tuning, while only updating a tiny fraction (less than 0.5%) of the model parameters. We demonstrate this on two speech adaptation tasks (atypical and accented speech) and for two state-of-the-art ASR architectures.
Continuous Speech Separation with Recurrent Selective Attention Network
Oct 28, 2021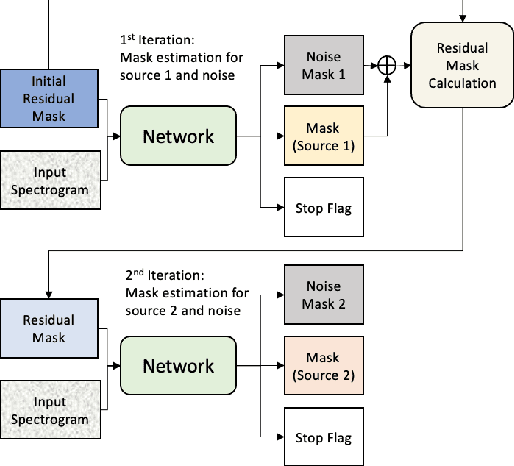
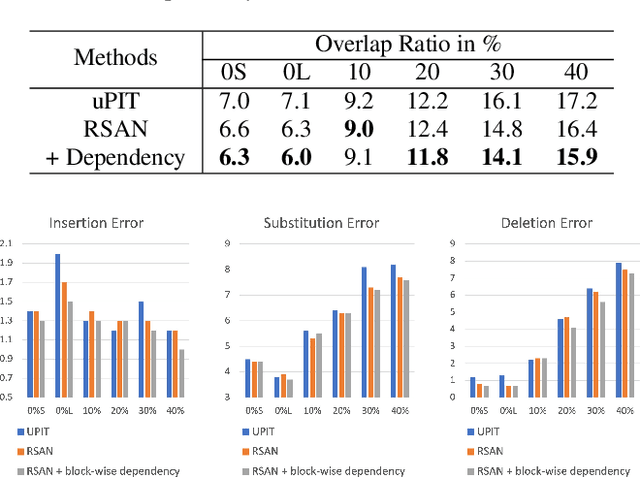
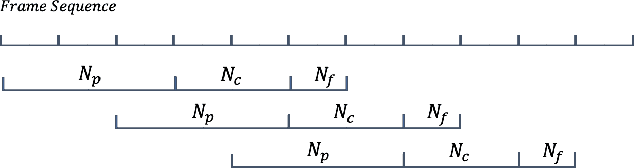
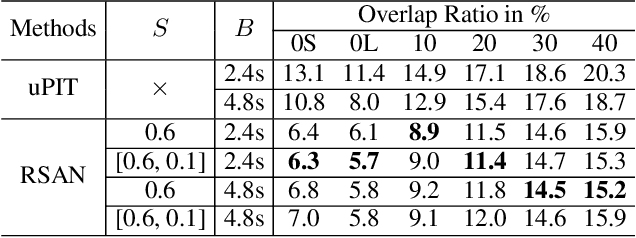
While permutation invariant training (PIT) based continuous speech separation (CSS) significantly improves the conversation transcription accuracy, it often suffers from speech leakages and failures in separation at "hot spot" regions because it has a fixed number of output channels. In this paper, we propose to apply recurrent selective attention network (RSAN) to CSS, which generates a variable number of output channels based on active speaker counting. In addition, we propose a novel block-wise dependency extension of RSAN by introducing dependencies between adjacent processing blocks in the CSS framework. It enables the network to utilize the separation results from the previous blocks to facilitate the current block processing. Experimental results on the LibriCSS dataset show that the RSAN-based CSS (RSAN-CSS) network consistently improves the speech recognition accuracy over PIT-based models. The proposed block-wise dependency modeling further boosts the performance of RSAN-CSS.
SVLDL: Improved Speaker Age Estimation Using Selective Variance Label Distribution Learning
Oct 18, 2022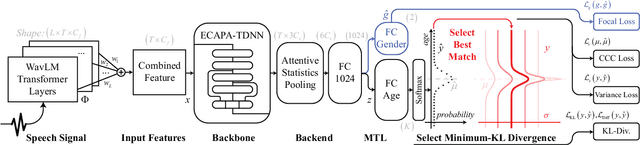
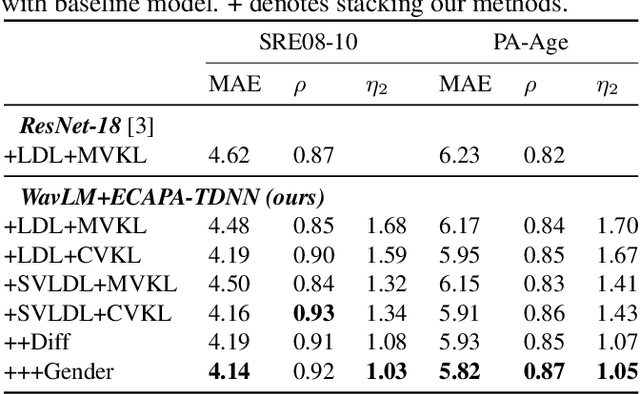
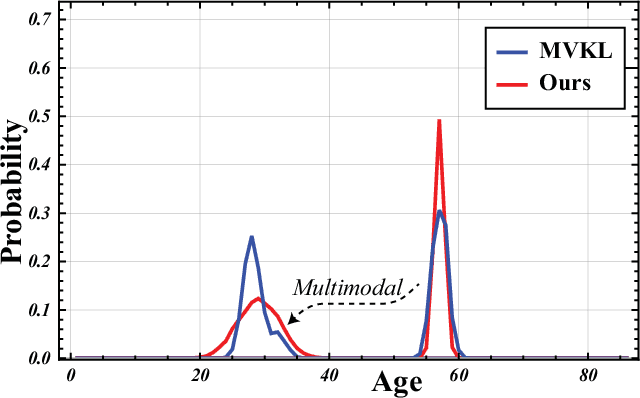

Estimating age from a single speech is a classic and challenging topic. Although Label Distribution Learning (LDL) can represent adjacent indistinguishable ages well, the uncertainty of the age estimate for each utterance varies from person to person, i.e., the variance of the age distribution is different. To address this issue, we propose selective variance label distribution learning (SVLDL) method to adapt the variance of different age distributions. Furthermore, the model uses WavLM as the speech feature extractor and adds the auxiliary task of gender recognition to further improve the performance. Two tricks are applied on the loss function to enhance the robustness of the age estimation and improve the quality of the fitted age distribution. Extensive experiments show that the model achieves state-of-the-art performance on all aspects of the NIST SRE08-10 and a real-world datasets.
LightSeq2: Accelerated Training for Transformer-based Models on GPUs
Oct 27, 2021

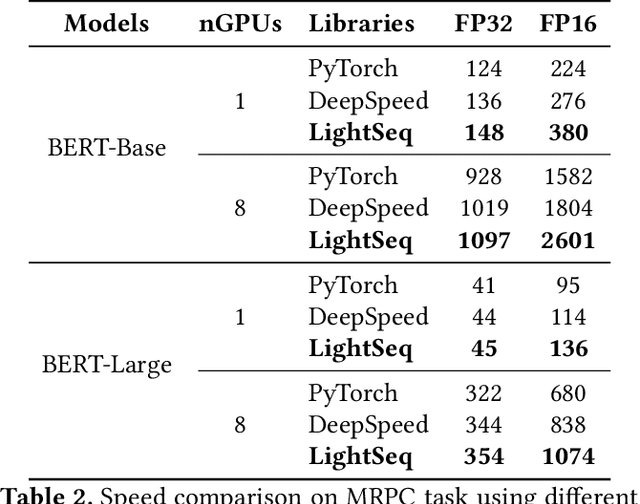
Transformer-based models have proven to be powerful in many natural language, computer vision, and speech recognition applications. It is expensive to train these types of models due to unfixed input length, complex computation, and large numbers of parameters. Existing systems either only focus on efficient inference or optimize only BERT-like encoder models. In this paper, we present LightSeq2, a system for efficient training of Transformer-based models on GPUs. We propose a series of GPU optimization techniques tailored to computation flow and memory access patterns of neural layers in Transformers. LightSeq2 supports a variety of network architectures, including BERT (encoder-only), GPT (decoder-only), and Transformer (encoder-decoder). Our experiments on GPUs with varying models and datasets show that LightSeq2 is 1.4-3.5x faster than previous systems. In particular, it gains 308% training speedup compared with existing systems on a large public machine translation benchmark (WMT14 English-German).
SpliceOut: A Simple and Efficient Audio Augmentation Method
Oct 13, 2021
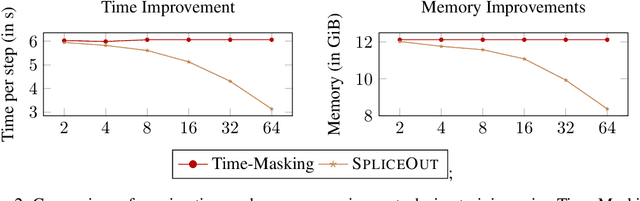
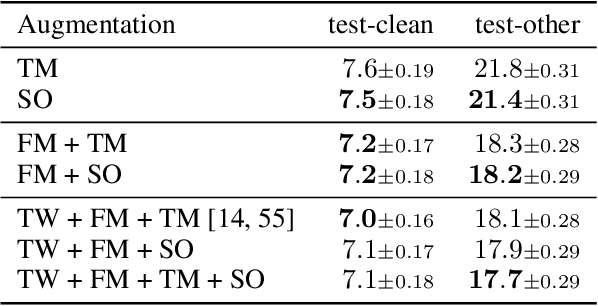
Time masking has become a de facto augmentation technique for speech and audio tasks, including automatic speech recognition (ASR) and audio classification, most notably as a part of SpecAugment. In this work, we propose SpliceOut, a simple modification to time masking which makes it computationally more efficient. SpliceOut performs comparably to (and sometimes outperforms) SpecAugment on a wide variety of speech and audio tasks, including ASR for seven different languages using varying amounts of training data, as well as on speech translation, sound and music classification, thus establishing itself as a broadly applicable audio augmentation method. SpliceOut also provides additional gains when used in conjunction with other augmentation techniques. Apart from the fully-supervised setting, we also demonstrate that SpliceOut can complement unsupervised representation learning with performance gains in the semi-supervised and self-supervised settings.