 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Noise robust distillation of self-supervised speech models via correlation metrics
Dec 19, 2023
Compared to large speech foundation models, small distilled models exhibit degraded noise robustness. The student's robustness can be improved by introducing noise at the inputs during pre-training. Despite this, using the standard distillation loss still yields a student with degraded performance. Thus, this paper proposes improving student robustness via distillation with correlation metrics. Teacher behavior is learned by maximizing the teacher and student cross-correlation matrix between their representations towards identity. Noise robustness is encouraged via the student's self-correlation minimization. The proposed method is agnostic of the teacher model and consistently outperforms the previous approach. This work also proposes an heuristic to weigh the importance of the two correlation terms automatically. Experiments show consistently better clean and noise generalization on Intent Classification, Keyword Spotting, and Automatic Speech Recognition tasks on SUPERB Challenge.
Advancing VAD Systems Based on Multi-Task Learning with Improved Model Structures
Dec 19, 2023In a speech recognition system, voice activity detection (VAD) is a crucial frontend module. Addressing the issues of poor noise robustness in traditional binary VAD systems based on DFSMN, the paper further proposes semantic VAD based on multi-task learning with improved models for real-time and offline systems, to meet specific application requirements. Evaluations on internal datasets show that, compared to the real-time VAD system based on DFSMN, the real-time semantic VAD system based on RWKV achieves relative decreases in CER of 7.0\%, DCF of 26.1\% and relative improvement in NRR of 19.2\%. Similarly, when compared to the offline VAD system based on DFSMN, the offline VAD system based on SAN-M demonstrates relative decreases in CER of 4.4\%, DCF of 18.6\% and relative improvement in NRR of 3.5\%.
kNN-CTC: Enhancing ASR via Retrieval of CTC Pseudo Labels
Dec 21, 2023The success of retrieval-augmented language models in various natural language processing (NLP) tasks has been constrained in automatic speech recognition (ASR) applications due to challenges in constructing fine-grained audio-text datastores. This paper presents kNN-CTC, a novel approach that overcomes these challenges by leveraging Connectionist Temporal Classification (CTC) pseudo labels to establish frame-level audio-text key-value pairs, circumventing the need for precise ground truth alignments. We further introduce a skip-blank strategy, which strategically ignores CTC blank frames, to reduce datastore size. kNN-CTC incorporates a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems, achieving significant improvements in performance. By incorporating a k-nearest neighbors retrieval mechanism into pre-trained CTC ASR systems and leveraging a fine-grained, pruned datastore, kNN-CTC consistently achieves substantial improvements in performance under various experimental settings. Our code is available at https://github.com/NKU-HLT/KNN-CTC.
Spike-Triggered Contextual Biasing for End-to-End Mandarin Speech Recognition
Oct 07, 2023The attention-based deep contextual biasing method has been demonstrated to effectively improve the recognition performance of end-to-end automatic speech recognition (ASR) systems on given contextual phrases. However, unlike shallow fusion methods that directly bias the posterior of the ASR model, deep biasing methods implicitly integrate contextual information, making it challenging to control the degree of bias. In this study, we introduce a spike-triggered deep biasing method that simultaneously supports both explicit and implicit bias. Moreover, both bias approaches exhibit significant improvements and can be cascaded with shallow fusion methods for better results. Furthermore, we propose a context sampling enhancement strategy and improve the contextual phrase filtering algorithm. Experiments on the public WenetSpeech Mandarin biased-word dataset show a 32.0% relative CER reduction compared to the baseline model, with an impressively 68.6% relative CER reduction on contextual phrases.
Whispering LLaMA: A Cross-Modal Generative Error Correction Framework for Speech Recognition
Oct 10, 2023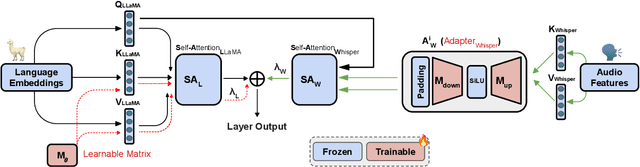
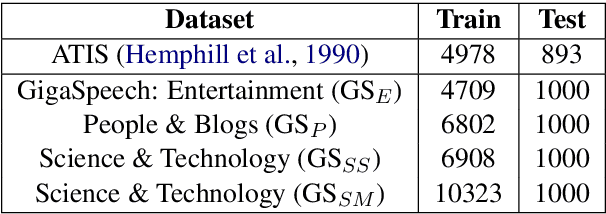
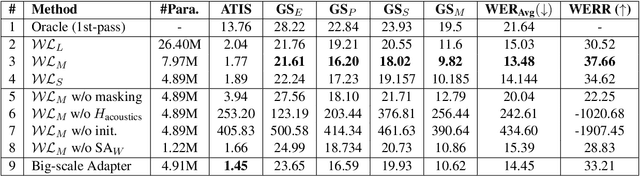
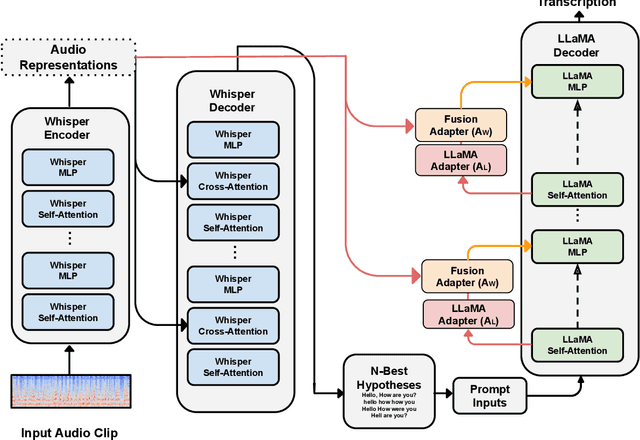
We introduce a new cross-modal fusion technique designed for generative error correction in automatic speech recognition (ASR). Our methodology leverages both acoustic information and external linguistic representations to generate accurate speech transcription contexts. This marks a step towards a fresh paradigm in generative error correction within the realm of n-best hypotheses. Unlike the existing ranking-based rescoring methods, our approach adeptly uses distinct initialization techniques and parameter-efficient algorithms to boost ASR performance derived from pre-trained speech and text models. Through evaluation across diverse ASR datasets, we evaluate the stability and reproducibility of our fusion technique, demonstrating its improved word error rate relative (WERR) performance in comparison to n-best hypotheses by relatively 37.66%. To encourage future research, we have made our code and pre-trained models open source at https://github.com/Srijith-rkr/Whispering-LLaMA.
PhasePerturbation: Speech Data Augmentation via Phase Perturbation for Automatic Speech Recognition
Dec 13, 2023Most of the current speech data augmentation methods operate on either the raw waveform or the amplitude spectrum of speech. In this paper, we propose a novel speech data augmentation method called PhasePerturbation that operates dynamically on the phase spectrum of speech. Instead of statically rotating a phase by a constant degree, PhasePerturbation utilizes three dynamic phase spectrum operations, i.e., a randomization operation, a frequency masking operation, and a temporal masking operation, to enhance the diversity of speech data. We conduct experiments on wav2vec2.0 pre-trained ASR models by fine-tuning them with the PhasePerturbation augmented TIMIT corpus. The experimental results demonstrate 10.9\% relative reduction in the word error rate (WER) compared with the baseline model fine-tuned without any augmentation operation. Furthermore, the proposed method achieves additional improvements (12.9\% and 15.9\%) in WER by complementing the Vocal Tract Length Perturbation (VTLP) and the SpecAug, which are both amplitude spectrum-based augmentation methods. The results highlight the capability of PhasePerturbation to improve the current amplitude spectrum-based augmentation methods.
Learning from Flawed Data: Weakly Supervised Automatic Speech Recognition
Sep 26, 2023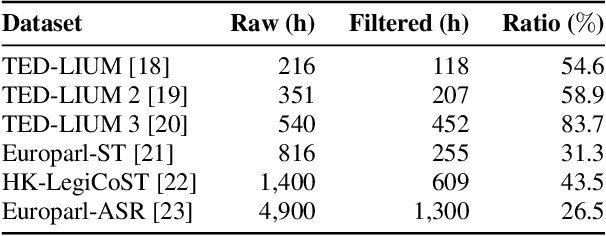
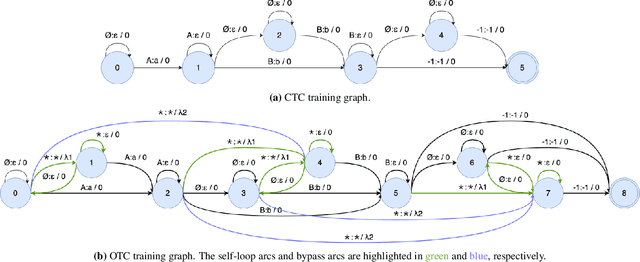
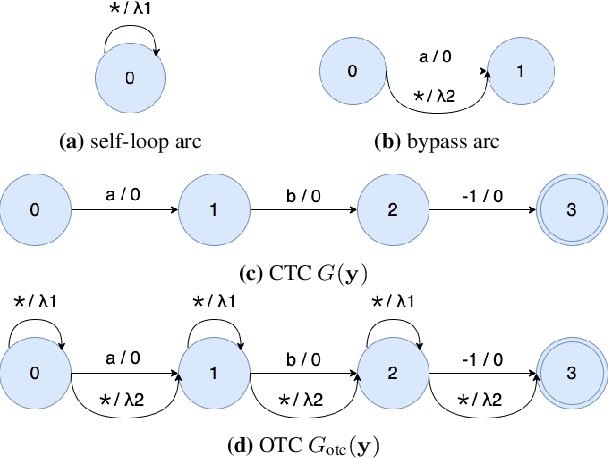

Training automatic speech recognition (ASR) systems requires large amounts of well-curated paired data. However, human annotators usually perform "non-verbatim" transcription, which can result in poorly trained models. In this paper, we propose Omni-temporal Classification (OTC), a novel training criterion that explicitly incorporates label uncertainties originating from such weak supervision. This allows the model to effectively learn speech-text alignments while accommodating errors present in the training transcripts. OTC extends the conventional CTC objective for imperfect transcripts by leveraging weighted finite state transducers. Through experiments conducted on the LibriSpeech and LibriVox datasets, we demonstrate that training ASR models with OTC avoids performance degradation even with transcripts containing up to 70% errors, a scenario where CTC models fail completely. Our implementation is available at https://github.com/k2-fsa/icefall.
Key Frame Mechanism For Efficient Conformer Based End-to-end Speech Recognition
Oct 28, 2023Recently, Conformer as a backbone network for end-to-end automatic speech recognition achieved state-of-the-art performance. The Conformer block leverages a self-attention mechanism to capture global information, along with a convolutional neural network to capture local information, resulting in improved performance. However, the Conformer-based model encounters an issue with the self-attention mechanism, as computational complexity grows quadratically with the length of the input sequence. Inspired by previous Connectionist Temporal Classification (CTC) guided blank skipping during decoding, we introduce intermediate CTC outputs as guidance into the downsampling procedure of the Conformer encoder. We define the frame with non-blank output as key frame. Specifically, we introduce the key frame-based self-attention (KFSA) mechanism, a novel method to reduce the computation of the self-attention mechanism using key frames. The structure of our proposed approach comprises two encoders. Following the initial encoder, we introduce an intermediate CTC loss function to compute the label frame, enabling us to extract the key frames and blank frames for KFSA. Furthermore, we introduce the key frame-based downsampling (KFDS) mechanism to operate on high-dimensional acoustic features directly and drop the frames corresponding to blank labels, which results in new acoustic feature sequences as input to the second encoder. By using the proposed method, which achieves comparable or higher performance than vanilla Conformer and other similar work such as Efficient Conformer. Meantime, our proposed method can discard more than 60\% useless frames during model training and inference, which will accelerate the inference speed significantly. This work code is available in {https://github.com/scufan1990/Key-Frame-Mechanism-For-Efficient-Conformer}
An analysis of large speech models-based representations for speech emotion recognition
Nov 01, 2023Large speech models-derived features have recently shown increased performance over signal-based features across multiple downstream tasks, even when the networks are not finetuned towards the target task. In this paper we show the results of an analysis of several signal- and neural models-derived features for speech emotion recognition. We use pretrained models and explore their inherent potential abstractions of emotions. Simple classification methods are used so as to not interfere or add knowledge to the task. We show that, even without finetuning, some of these large neural speech models' representations can enclose information that enables performances close to, and even beyond state-of-the-art results across six standard speech emotion recognition datasets.
Extending Whisper with prompt tuning to target-speaker ASR
Dec 13, 2023Target-speaker automatic speech recognition (ASR) aims to transcribe the desired speech of a target speaker from multi-talker overlapped utterances. Most of the existing target-speaker ASR (TS-ASR) methods involve either training from scratch or fully fine-tuning a pre-trained model, leading to significant training costs and becoming inapplicable to large foundation models. This work leverages prompt tuning, a parameter-efficient fine-tuning approach, to extend Whisper, a large-scale single-talker ASR model, to TS-ASR. Experimental results show that prompt tuning can achieve performance comparable to state-of-the-art full fine-tuning approaches while only requiring about 1% of task-specific model parameters. Notably, the original Whisper's features, such as inverse text normalization and timestamp prediction, are retained in target-speaker ASR, keeping the generated transcriptions natural and informative.