 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Vox Populi, Vox DIY: Benchmark Dataset for Crowdsourced Audio Transcription
Jul 02, 2021
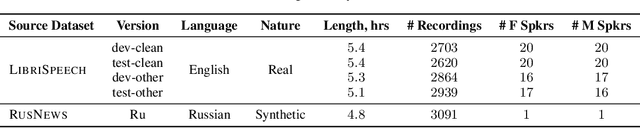
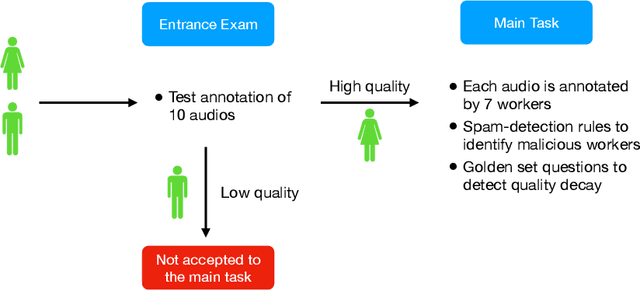
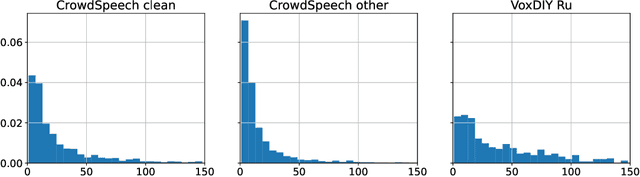
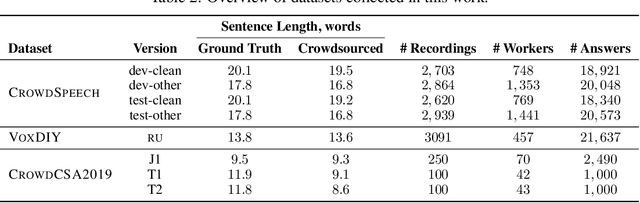
Domain-specific data is the crux of the successful transfer of machine learning systems from benchmarks to real life. Crowdsourcing has become one of the standard tools for cheap and time-efficient data collection for simple problems such as image classification: thanks in large part to advances in research on aggregation methods. However, the applicability of crowdsourcing to more complex tasks (e.g., speech recognition) remains limited due to the lack of principled aggregation methods for these modalities. The main obstacle towards designing advanced aggregation methods is the absence of training data, and in this work, we focus on bridging this gap in speech recognition. For this, we collect and release CrowdSpeech -- the first publicly available large-scale dataset of crowdsourced audio transcriptions. Evaluation of existing aggregation methods on our data shows room for improvement, suggesting that our work may entail the design of better algorithms. At a higher level, we also contribute to the more general challenge of collecting high-quality datasets using crowdsourcing: we develop a principled pipeline for constructing datasets of crowdsourced audio transcriptions in any novel domain. We show its applicability on an under-resourced language by constructing VoxDIY -- a counterpart of CrowdSpeech for the Russian language. We also release the code that allows a full replication of our data collection pipeline and share various insights on best practices of data collection via crowdsourcing.
Multi-Channel Multi-Speaker ASR Using 3D Spatial Feature
Nov 22, 2021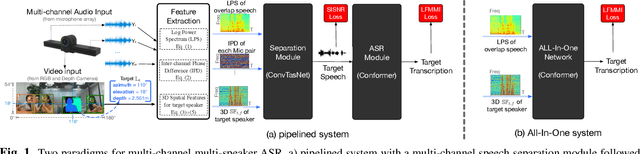

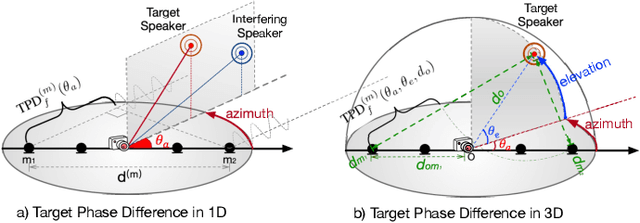
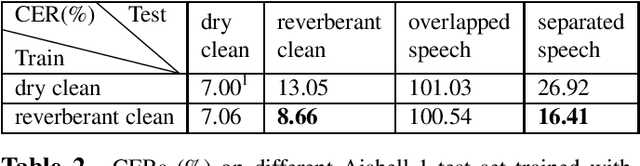
Automatic speech recognition (ASR) of multi-channel multi-speaker overlapped speech remains one of the most challenging tasks to the speech community. In this paper, we look into this challenge by utilizing the location information of target speakers in the 3D space for the first time. To explore the strength of proposed the 3D spatial feature, two paradigms are investigated. 1) a pipelined system with a multi-channel speech separation module followed by the state-of-the-art single-channel ASR module; 2) a "All-In-One" model where the 3D spatial feature is directly used as an input to ASR system without explicit separation modules. Both of them are fully differentiable and can be back-propagated end-to-end. We test them on simulated overlapped speech and real recordings. Experimental results show that 1) the proposed ALL-In-One model achieved a comparable error rate to the pipelined system while reducing the inference time by half; 2) the proposed 3D spatial feature significantly outperformed (31\% CERR) all previous works of using the 1D directional information in both paradigms.
AI Accelerator Survey and Trends
Sep 18, 2021
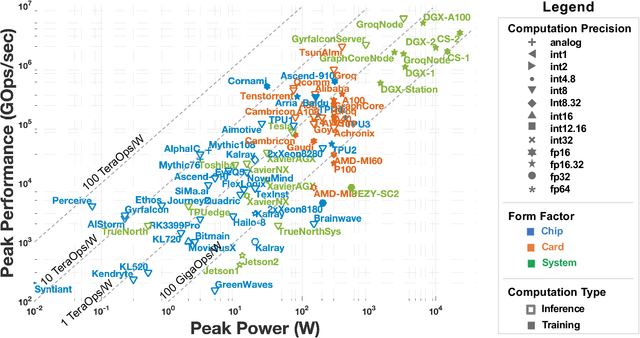
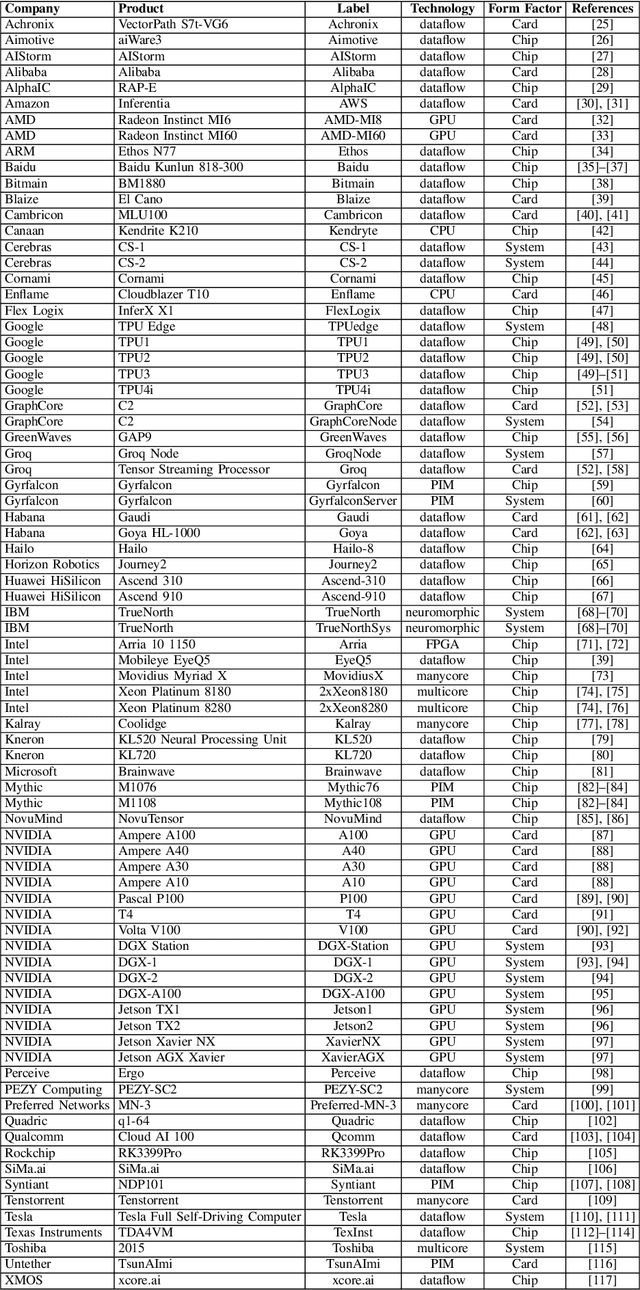
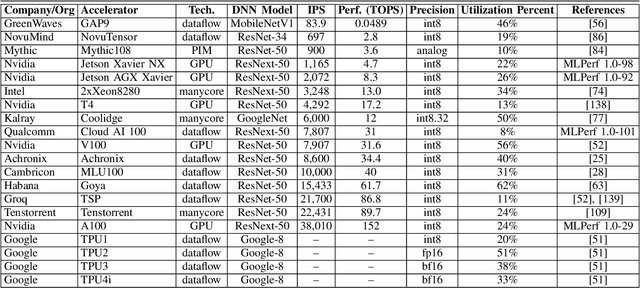
Over the past several years, new machine learning accelerators were being announced and released every month for a variety of applications from speech recognition, video object detection, assisted driving, and many data center applications. This paper updates the survey of AI accelerators and processors from past two years. This paper collects and summarizes the current commercial accelerators that have been publicly announced with peak performance and power consumption numbers. The performance and power values are plotted on a scatter graph, and a number of dimensions and observations from the trends on this plot are again discussed and analyzed. This year, we also compile a list of benchmarking performance results and compute the computational efficiency with respect to peak performance.
Scenario Aware Speech Recognition: Advancements for Apollo Fearless Steps & CHiME-4 Corpora
Sep 23, 2021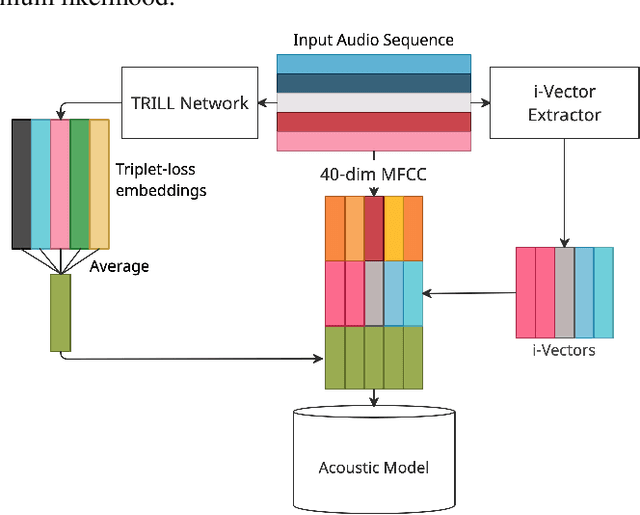
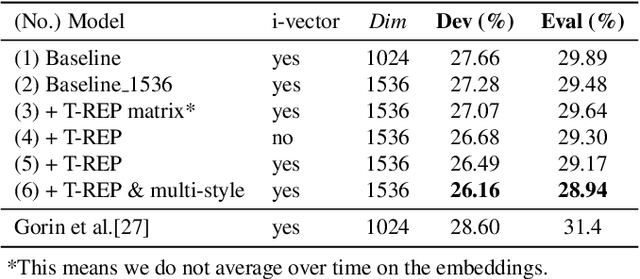
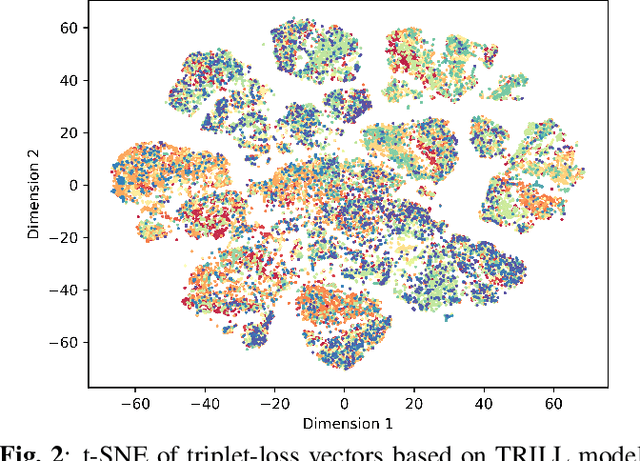

In this study, we propose to investigate triplet loss for the purpose of an alternative feature representation for ASR. We consider a general non-semantic speech representation, which is trained with a self-supervised criteria based on triplet loss called TRILL, for acoustic modeling to represent the acoustic characteristics of each audio. This strategy is then applied to the CHiME-4 corpus and CRSS-UTDallas Fearless Steps Corpus, with emphasis on the 100-hour challenge corpus which consists of 5 selected NASA Apollo-11 channels. An analysis of the extracted embeddings provides the foundation needed to characterize training utterances into distinct groups based on acoustic distinguishing properties. Moreover, we also demonstrate that triplet-loss based embedding performs better than i-Vector in acoustic modeling, confirming that the triplet loss is more effective than a speaker feature. With additional techniques such as pronunciation and silence probability modeling, plus multi-style training, we achieve a +5.42% and +3.18% relative WER improvement for the development and evaluation sets of the Fearless Steps Corpus. To explore generalization, we further test the same technique on the 1 channel track of CHiME-4 and observe a +11.90% relative WER improvement for real test data.
Differentially Private Speaker Anonymization
Feb 23, 2022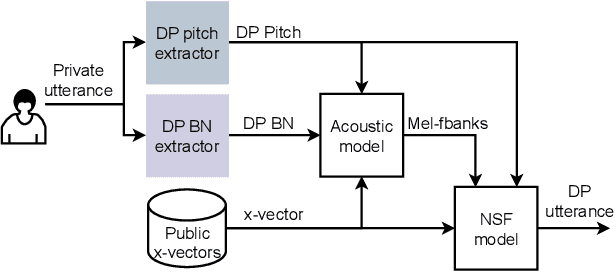
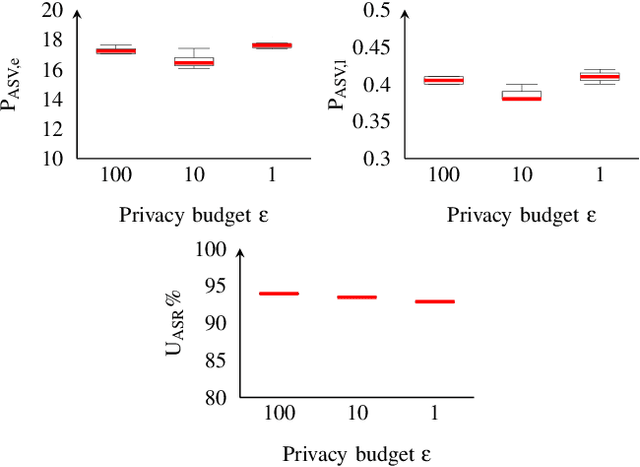
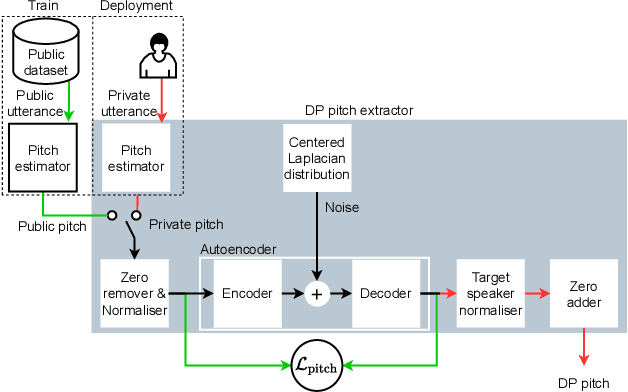
Sharing real-world speech utterances is key to the training and deployment of voice-based services. However, it also raises privacy risks as speech contains a wealth of personal data. Speaker anonymization aims to remove speaker information from a speech utterance while leaving its linguistic and prosodic attributes intact. State-of-the-art techniques operate by disentangling the speaker information (represented via a speaker embedding) from these attributes and re-synthesizing speech based on the speaker embedding of another speaker. Prior research in the privacy community has shown that anonymization often provides brittle privacy protection, even less so any provable guarantee. In this work, we show that disentanglement is indeed not perfect: linguistic and prosodic attributes still contain speaker information. We remove speaker information from these attributes by introducing differentially private feature extractors based on an autoencoder and an automatic speech recognizer, respectively, trained using noise layers. We plug these extractors in the state-of-the-art anonymization pipeline and generate, for the first time, differentially private utterances with a provable upper bound on the speaker information they contain. We evaluate empirically the privacy and utility resulting from our differentially private speaker anonymization approach on the LibriSpeech data set. Experimental results show that the generated utterances retain very high utility for automatic speech recognition training and inference, while being much better protected against strong adversaries who leverage the full knowledge of the anonymization process to try to infer the speaker identity.
Sequence-level self-learning with multiple hypotheses
Dec 10, 2021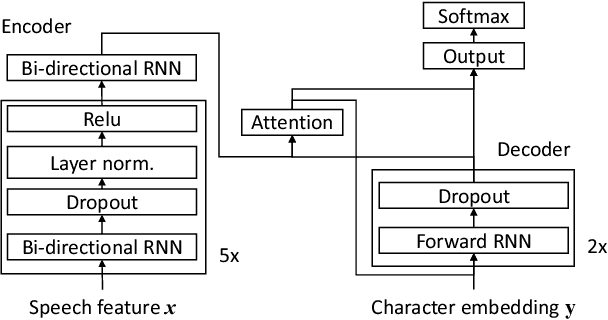
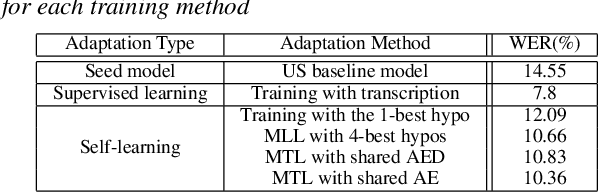
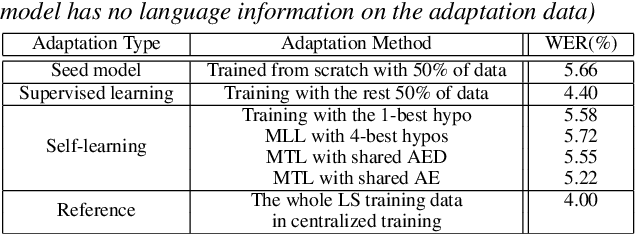
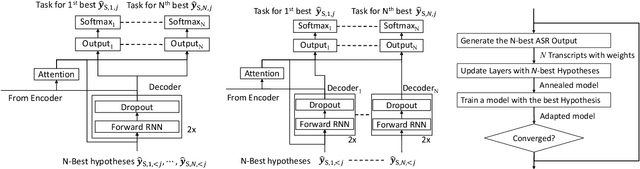
In this work, we develop new self-learning techniques with an attention-based sequence-to-sequence (seq2seq) model for automatic speech recognition (ASR). For untranscribed speech data, the hypothesis from an ASR system must be used as a label. However, the imperfect ASR result makes unsupervised learning difficult to consistently improve recognition performance especially in the case that multiple powerful teacher models are unavailable. In contrast to conventional unsupervised learning approaches, we adopt the \emph{multi-task learning} (MTL) framework where the $n$-th best ASR hypothesis is used as the label of each task. The seq2seq network is updated through the MTL framework so as to find the common representation that can cover multiple hypotheses. By doing so, the effect of the \emph{hard-decision} errors can be alleviated. We first demonstrate the effectiveness of our self-learning methods through ASR experiments in an accent adaptation task between the US and British English speech. Our experiment results show that our method can reduce the WER on the British speech data from 14.55\% to 10.36\% compared to the baseline model trained with the US English data only. Moreover, we investigate the effect of our proposed methods in a federated learning scenario.
Leveraging Acoustic and Linguistic Embeddings from Pretrained speech and language Models for Intent Classification
Feb 15, 2021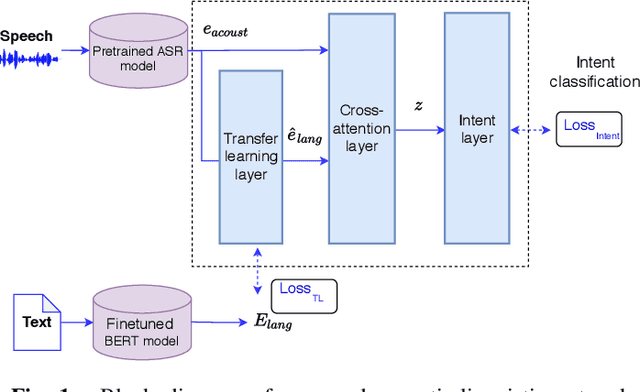
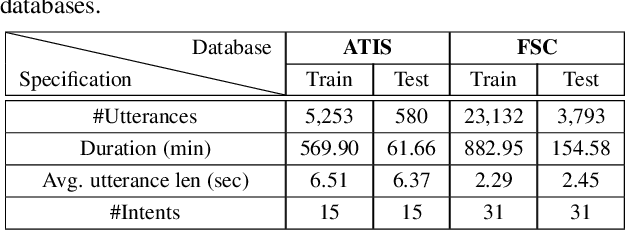
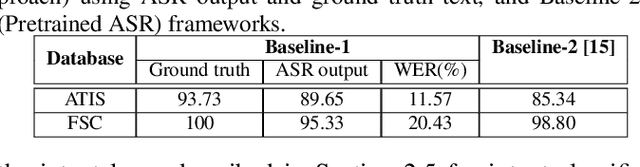
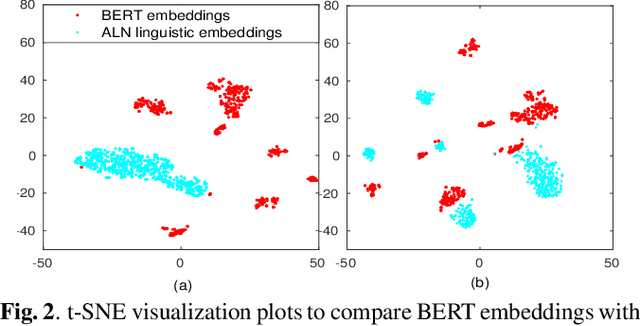
Intent classification is a task in spoken language understanding. An intent classification system is usually implemented as a pipeline process, with a speech recognition module followed by text processing that classifies the intents. There are also studies of end-to-end system that takes acoustic features as input and classifies the intents directly. Such systems don't take advantage of relevant linguistic information, and suffer from limited training data. In this work, we propose a novel intent classification framework that employs acoustic features extracted from a pretrained speech recognition system and linguistic features learned from a pretrained language model. We use knowledge distillation technique to map the acoustic embeddings towards linguistic embeddings. We perform fusion of both acoustic and linguistic embeddings through cross-attention approach to classify intents. With the proposed method, we achieve 90.86% and 99.07% accuracy on ATIS and Fluent speech corpus, respectively.
Multitask Learning with Low-Level Auxiliary Tasks for Encoder-Decoder Based Speech Recognition
Apr 19, 2017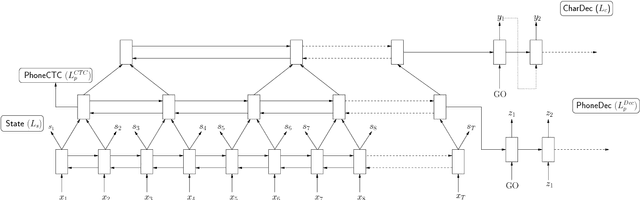
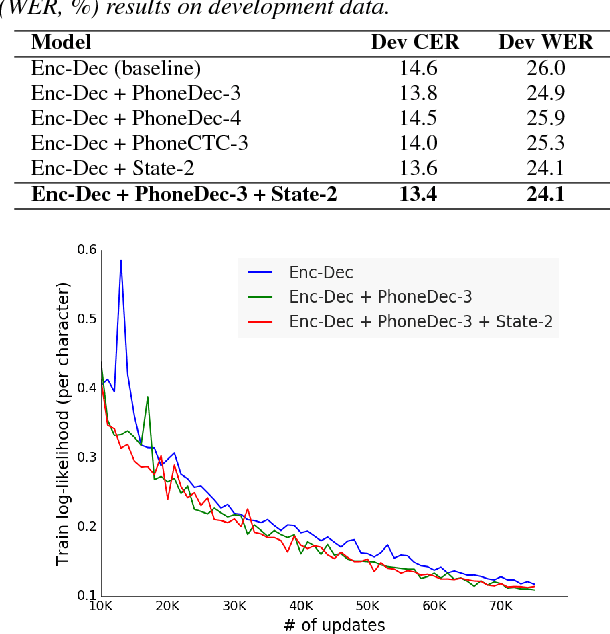
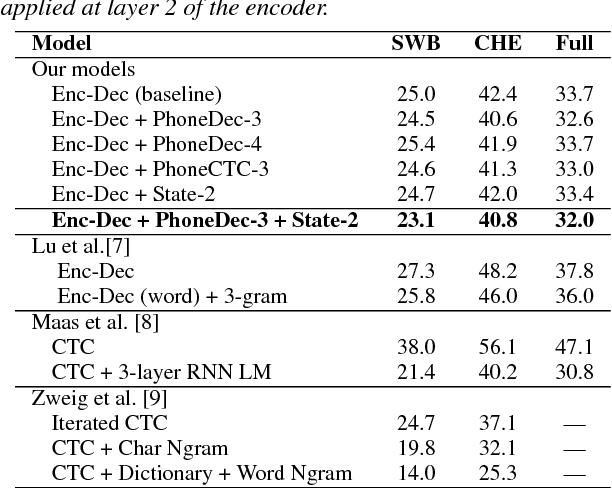
End-to-end training of deep learning-based models allows for implicit learning of intermediate representations based on the final task loss. However, the end-to-end approach ignores the useful domain knowledge encoded in explicit intermediate-level supervision. We hypothesize that using intermediate representations as auxiliary supervision at lower levels of deep networks may be a good way of combining the advantages of end-to-end training and more traditional pipeline approaches. We present experiments on conversational speech recognition where we use lower-level tasks, such as phoneme recognition, in a multitask training approach with an encoder-decoder model for direct character transcription. We compare multiple types of lower-level tasks and analyze the effects of the auxiliary tasks. Our results on the Switchboard corpus show that this approach improves recognition accuracy over a standard encoder-decoder model on the Eval2000 test set.
The HW-TSC's Offline Speech Translation Systems for IWSLT 2021 Evaluation
Aug 09, 2021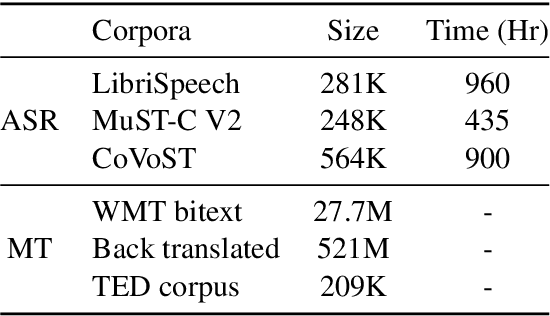
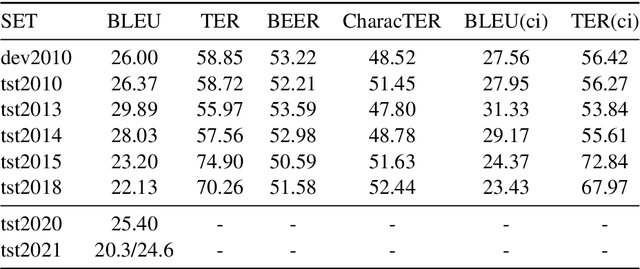
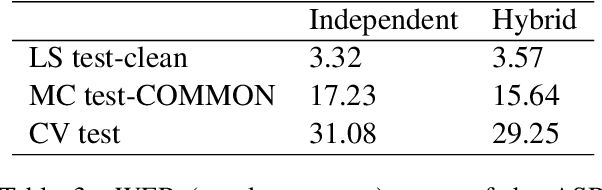
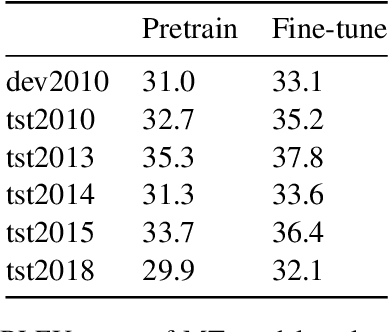
This paper describes our work in participation of the IWSLT-2021 offline speech translation task. Our system was built in a cascade form, including a speaker diarization module, an Automatic Speech Recognition (ASR) module and a Machine Translation (MT) module. We directly use the LIUM SpkDiarization tool as the diarization module. The ASR module is trained with three ASR datasets from different sources, by multi-source training, using a modified Transformer encoder. The MT module is pretrained on the large-scale WMT news translation dataset and fine-tuned on the TED corpus. Our method achieves 24.6 BLEU score on the 2021 test set.
Improved Language Identification Through Cross-Lingual Self-Supervised Learning
Aug 04, 2021
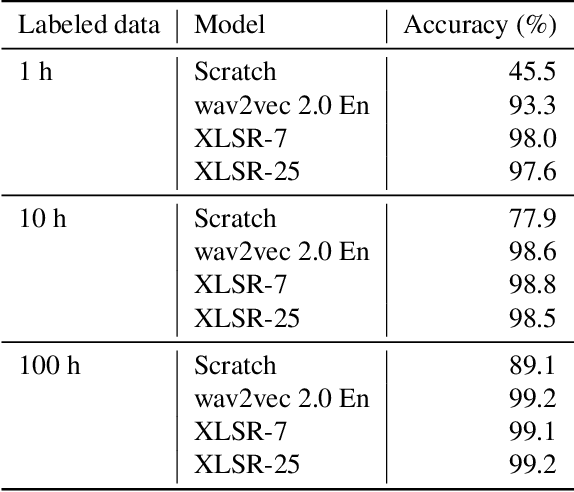
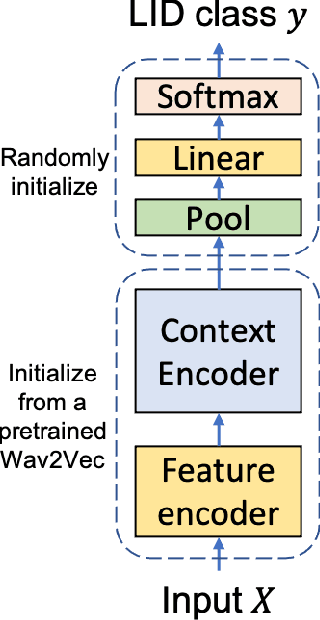
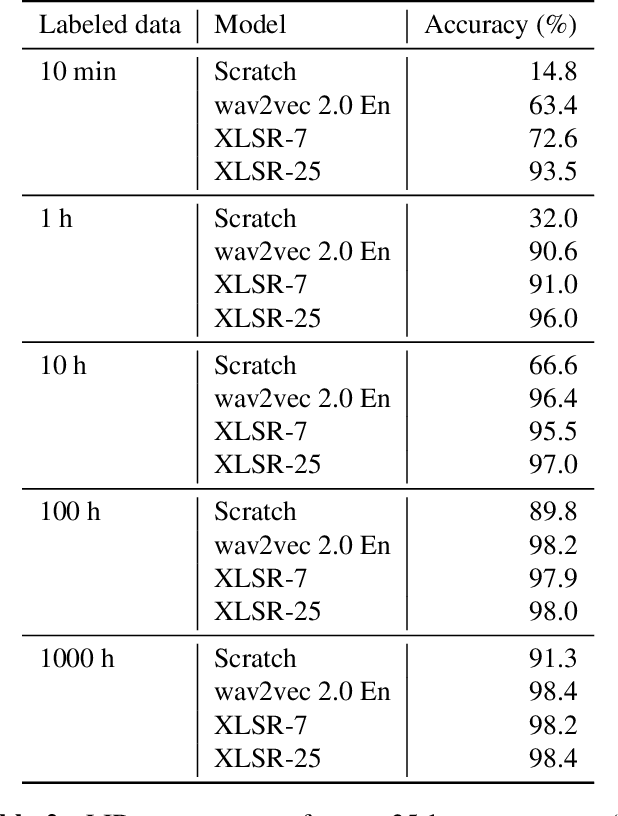
Language identification greatly impacts the success of downstream tasks such as automatic speech recognition. Recently, self-supervised speech representations learned by wav2vec 2.0 have been shown to be very effective for a range of speech tasks. We extend previous self-supervised work on language identification by experimenting with pre-trained models which were learned on real-world unconstrained speech in multiple languages and not just on English. We show that models pre-trained on many languages perform better and enable language identification systems that require very little labeled data to perform well. Results on a 25 languages setup show that with only 10 minutes of labeled data per language, a cross-lingually pre-trained model can achieve over 93% accuracy.