 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
TS-RIR: Translated synthetic room impulse responses for speech augmentation
Apr 03, 2021
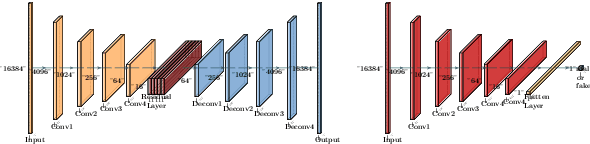
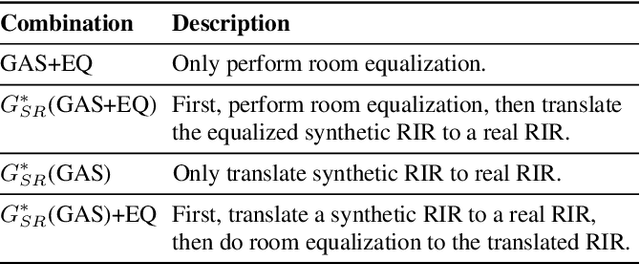
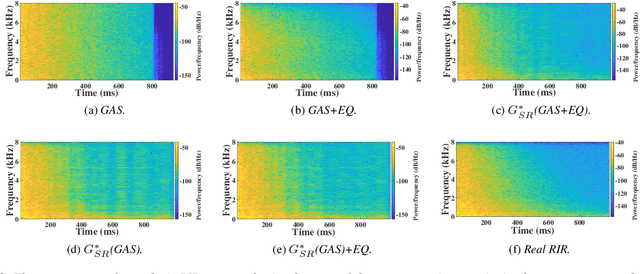
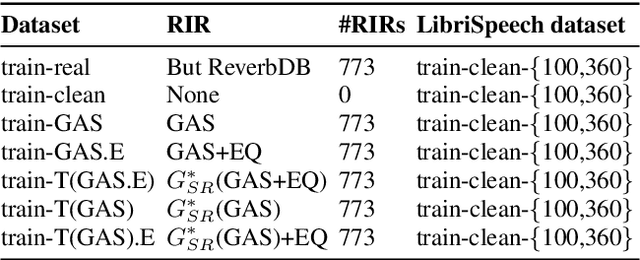
We present a method for improving the quality of synthetic room impulse responses for far-field speech recognition. We bridge the gap between the fidelity of synthetic room impulse responses (RIRs) and the real room impulse responses using our novel, TS-RIRGAN architecture. Given a synthetic RIR in the form of raw audio, we use TS-RIRGAN to translate it into a real RIR. We also perform real-world sub-band room equalization on the translated synthetic RIR. Our overall approach improves the quality of synthetic RIRs by compensating low-frequency wave effects, similar to those in real RIRs. We evaluate the performance of improved synthetic RIRs on a far-field speech dataset augmented by convolving the LibriSpeech clean speech dataset [1] with RIRs and adding background noise. We show that far-field speech augmented using our improved synthetic RIRs reduces the word error rate by up to 19.9% in Kaldi far-field automatic speech recognition benchmark [2].
Lattention: Lattice-attention in ASR rescoring
Nov 19, 2021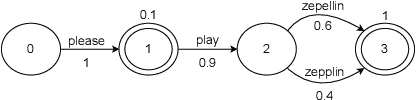
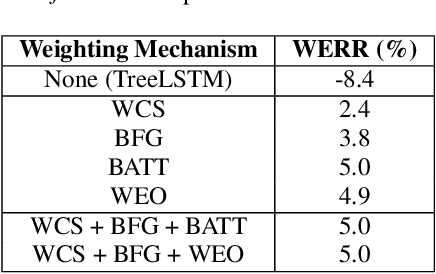
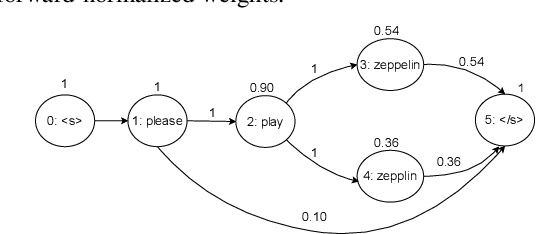
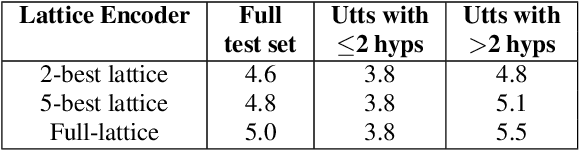
Lattices form a compact representation of multiple hypotheses generated from an automatic speech recognition system and have been shown to improve performance of downstream tasks like spoken language understanding and speech translation, compared to using one-best hypothesis. In this work, we look into the effectiveness of lattice cues for rescoring n-best lists in second-pass. We encode lattices with a recurrent network and train an attention encoder-decoder model for n-best rescoring. The rescoring model with attention to lattices achieves 4-5% relative word error rate reduction over first-pass and 6-8% with attention to both lattices and acoustic features. We show that rescoring models with attention to lattices outperform models with attention to n-best hypotheses. We also study different ways to incorporate lattice weights in the lattice encoder and demonstrate their importance for n-best rescoring.
Conformer-based Hybrid ASR System for Switchboard Dataset
Nov 05, 2021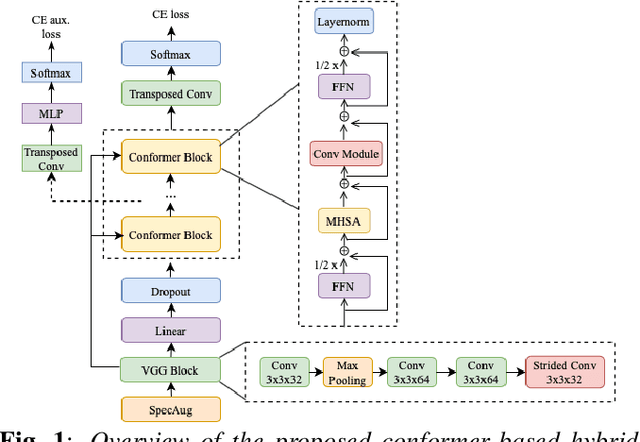
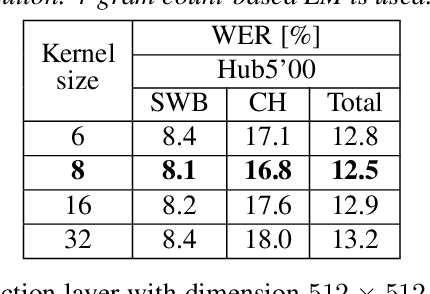
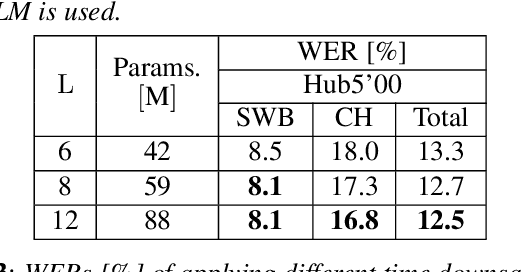
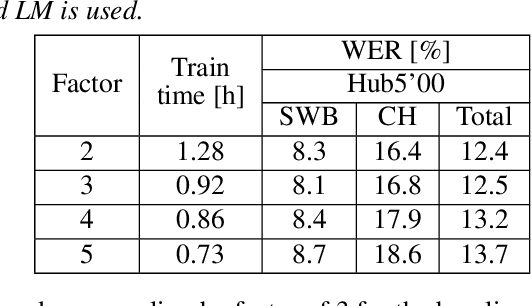
The recently proposed conformer architecture has been successfully used for end-to-end automatic speech recognition (ASR) architectures achieving state-of-the-art performance on different datasets. To our best knowledge, the impact of using conformer acoustic model for hybrid ASR is not investigated. In this paper, we present and evaluate a competitive conformer-based hybrid model training recipe. We study different training aspects and methods to improve word-error-rate as well as to increase training speed. We apply time downsampling methods for efficient training and use transposed convolutions to upsample the output sequence again. We conduct experiments on Switchboard 300h dataset and our conformer-based hybrid model achieves competitive results compared to other architectures. It generalizes very well on Hub5'01 test set and outperforms the BLSTM-based hybrid model significantly.
Highway Long Short-Term Memory RNNs for Distant Speech Recognition
Jan 11, 2016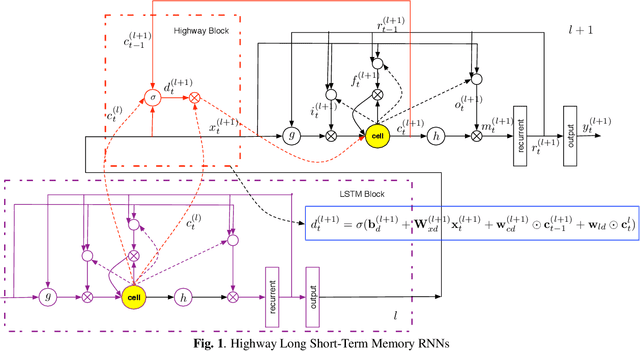
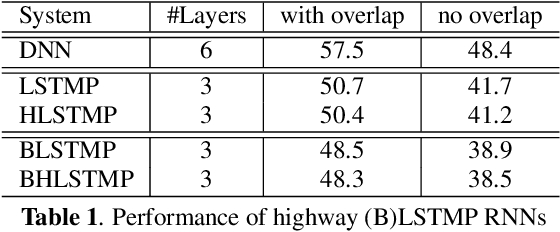
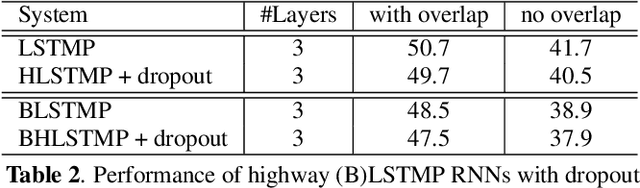
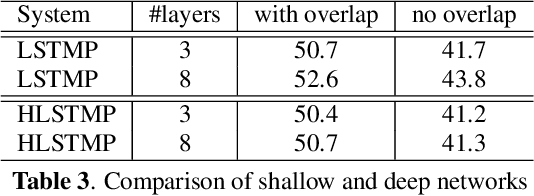
In this paper, we extend the deep long short-term memory (DLSTM) recurrent neural networks by introducing gated direct connections between memory cells in adjacent layers. These direct links, called highway connections, enable unimpeded information flow across different layers and thus alleviate the gradient vanishing problem when building deeper LSTMs. We further introduce the latency-controlled bidirectional LSTMs (BLSTMs) which can exploit the whole history while keeping the latency under control. Efficient algorithms are proposed to train these novel networks using both frame and sequence discriminative criteria. Experiments on the AMI distant speech recognition (DSR) task indicate that we can train deeper LSTMs and achieve better improvement from sequence training with highway LSTMs (HLSTMs). Our novel model obtains $43.9/47.7\%$ WER on AMI (SDM) dev and eval sets, outperforming all previous works. It beats the strong DNN and DLSTM baselines with $15.7\%$ and $5.3\%$ relative improvement respectively.
Ask2Mask: Guided Data Selection for Masked Speech Modeling
Feb 24, 2022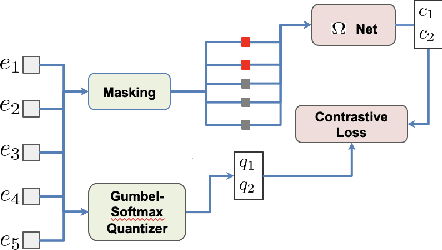
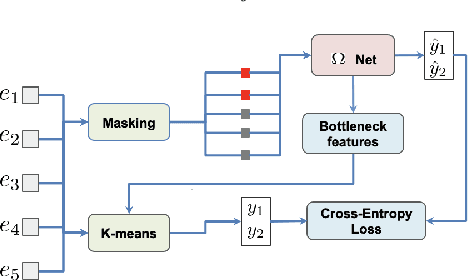
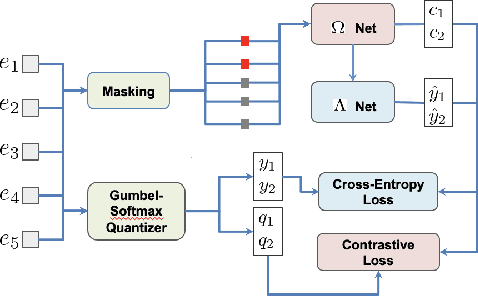
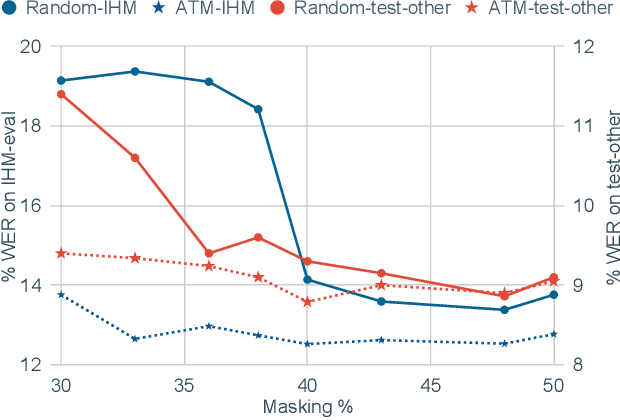
Masked speech modeling (MSM) methods such as wav2vec2 or w2v-BERT learn representations over speech frames which are randomly masked within an utterance. While these methods improve performance of Automatic Speech Recognition (ASR) systems, they have one major limitation. They treat all unsupervised speech samples with equal weight, which hinders learning as not all samples have relevant information to learn meaningful representations. In this work, we address this limitation. We propose ask2mask (ATM), a novel approach to focus on specific samples during MSM pre-training. ATM employs an external ASR model or \textit{scorer} to weight unsupervised input samples in two different ways: 1) A fine-grained data selection is performed by masking over the highly confident input frames as chosen by the scorer. This allows the model to learn meaningful representations. 2) ATM is further extended to focus at utterance-level by weighting the final MSM loss with the utterance-level confidence score. We conduct fine-tuning experiments on two well-benchmarked corpora: LibriSpeech (matching the pre-training data) and Commonvoice, TED-LIUM, AMI and CHiME-6 (not matching the pre-training data). The results substantiate the efficacy of ATM on significantly improving the recognition performance under mismatched conditions (up to 11.6\% relative over published results and upto 4.46\% relative over our internal baseline) while still yielding modest improvements under matched conditions.
power-law nonlinearity with maximally uniform distribution criterion for improved neural network training in automatic speech recognition
Dec 22, 2019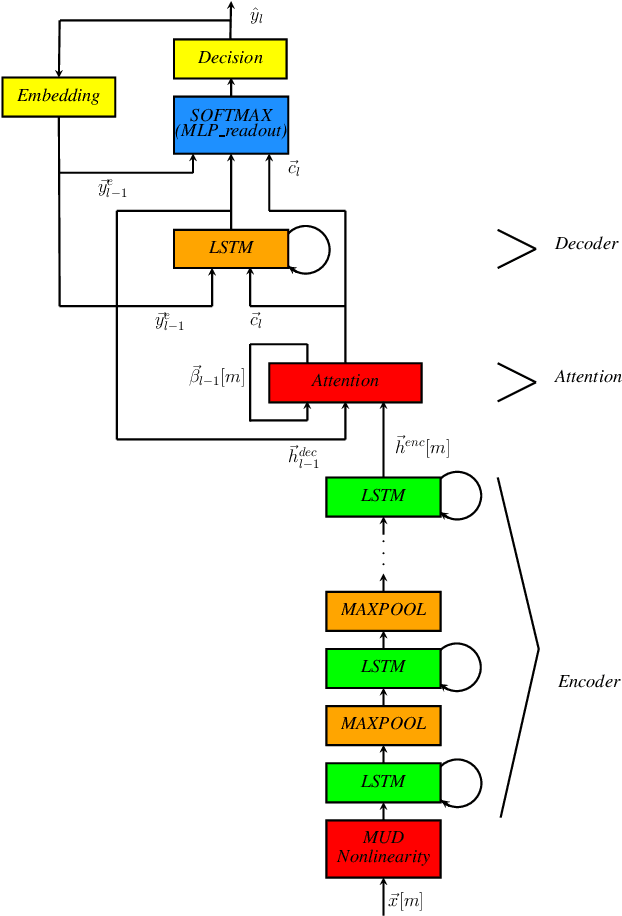
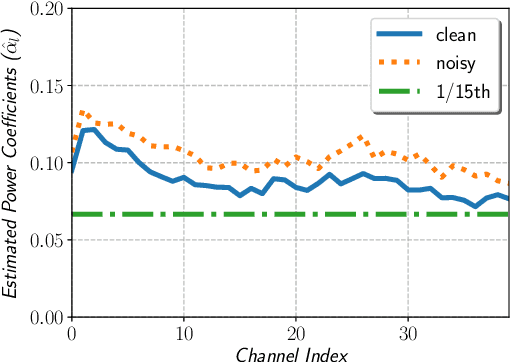
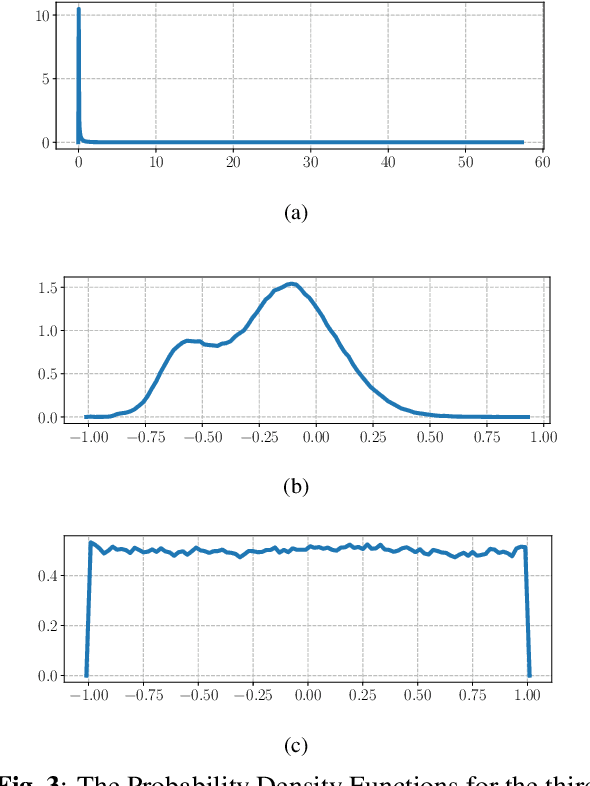
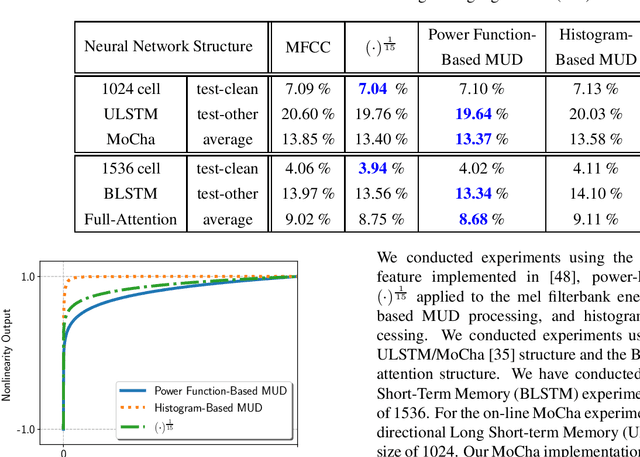
In this paper, we describe the Maximum Uniformity of Distribution (MUD) algorithm with the power-law nonlinearity. In this approach, we hypothesize that neural network training will become more stable if feature distribution is not too much skewed. We propose two different types of MUD approaches: power function-based MUD and histogram-based MUD. In these approaches, we first obtain the mel filterbank coefficients and apply nonlinearity functions for each filterbank channel. With the power function-based MUD, we apply a power-function based nonlinearity where power function coefficients are chosen to maximize the likelihood assuming that nonlinearity outputs follow the uniform distribution. With the histogram-based MUD, the empirical Cumulative Density Function (CDF) from the training database is employed to transform the original distribution into a uniform distribution. In MUD processing, we do not use any prior knowledge (e.g. logarithmic relation) about the energy of the incoming signal and the perceived intensity by a human. Experimental results using an end-to-end speech recognition system demonstrate that power-function based MUD shows better result than the conventional Mel Filterbank Cepstral Coefficients (MFCCs). On the LibriSpeech database, we could achieve 4.02 % WER on test-clean and 13.34 % WER on test-other without using any Language Models (LMs). The major contribution of this work is that we developed a new algorithm for designing the compressive nonlinearity in a data-driven way, which is much more flexible than the previous approaches and may be extended to other domains as well.
Use of Machine Learning Technique to maximize the signal over background for $H \rightarrow ττ$
Jun 27, 2021
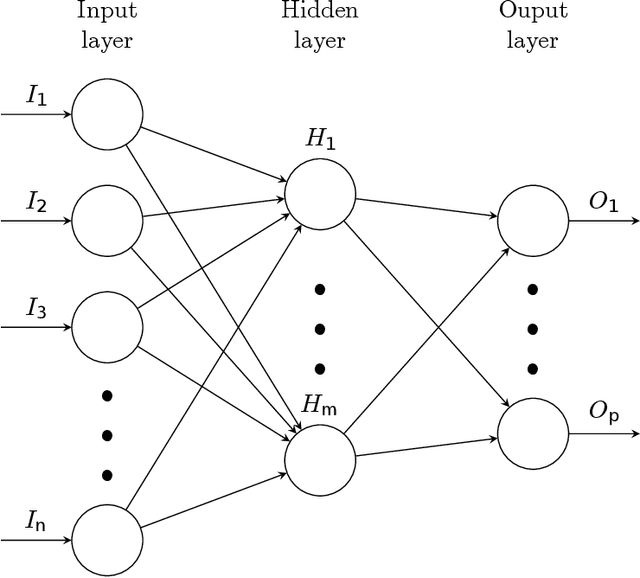
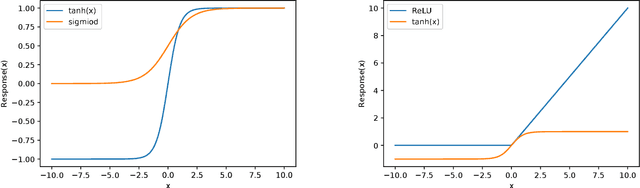
In recent years, artificial neural networks (ANNs) have won numerous contests in pattern recognition and machine learning. ANNS have been applied to problems ranging from speech recognition to prediction of protein secondary structure, classification of cancers, and gene prediction. Here, we intend to maximize the chances of finding the Higgs boson decays to two $\tau$ leptons in the pseudo dataset using a Machine Learning technique to classify the recorded events as signal or background.
Syllable-Based Sequence-to-Sequence Speech Recognition with the Transformer in Mandarin Chinese
Jun 04, 2018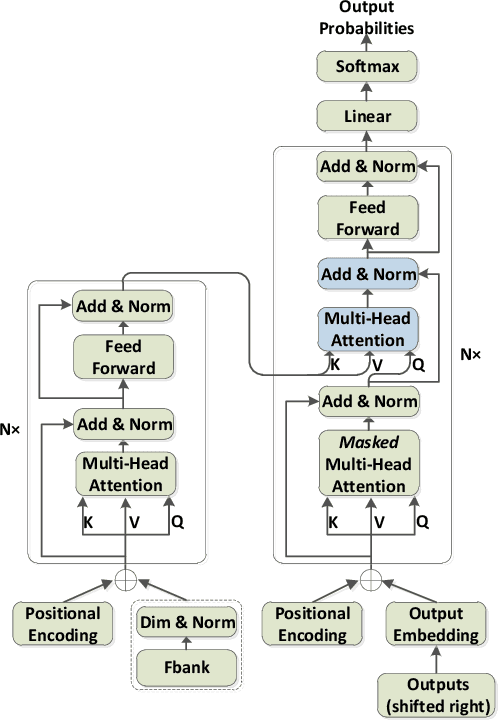



Sequence-to-sequence attention-based models have recently shown very promising results on automatic speech recognition (ASR) tasks, which integrate an acoustic, pronunciation and language model into a single neural network. In these models, the Transformer, a new sequence-to-sequence attention-based model relying entirely on self-attention without using RNNs or convolutions, achieves a new single-model state-of-the-art BLEU on neural machine translation (NMT) tasks. Since the outstanding performance of the Transformer, we extend it to speech and concentrate on it as the basic architecture of sequence-to-sequence attention-based model on Mandarin Chinese ASR tasks. Furthermore, we investigate a comparison between syllable based model and context-independent phoneme (CI-phoneme) based model with the Transformer in Mandarin Chinese. Additionally, a greedy cascading decoder with the Transformer is proposed for mapping CI-phoneme sequences and syllable sequences into word sequences. Experiments on HKUST datasets demonstrate that syllable based model with the Transformer performs better than CI-phoneme based counterpart, and achieves a character error rate (CER) of \emph{$28.77\%$}, which is competitive to the state-of-the-art CER of $28.0\%$ by the joint CTC-attention based encoder-decoder network.
Are E2E ASR models ready for an industrial usage?
Dec 09, 2021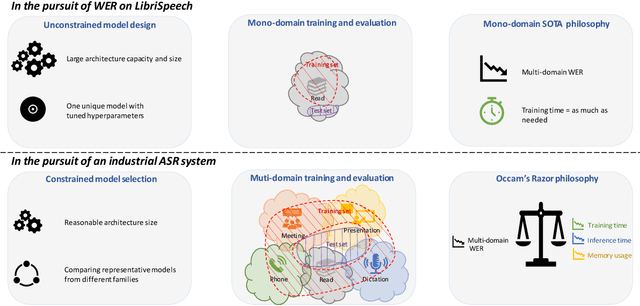
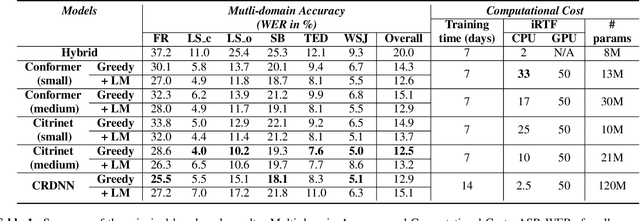
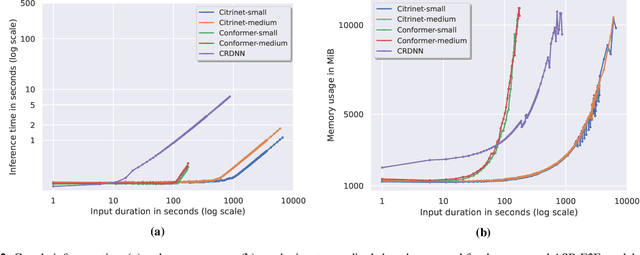
The Automated Speech Recognition (ASR) community experiences a major turning point with the rise of the fully-neural (End-to-End, E2E) approaches. At the same time, the conventional hybrid model remains the standard choice for the practical usage of ASR. According to previous studies, the adoption of E2E ASR in real-world applications was hindered by two main limitations: their ability to generalize on unseen domains and their high operational cost. In this paper, we investigate both above-mentioned drawbacks by performing a comprehensive multi-domain benchmark of several contemporary E2E models and a hybrid baseline. Our experiments demonstrate that E2E models are viable alternatives for the hybrid approach, and even outperform the baseline both in accuracy and in operational efficiency. As a result, our study shows that the generalization and complexity issues are no longer the major obstacle for industrial integration, and draws the community's attention to other potential limitations of the E2E approaches in some specific use-cases.