 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Simple and Effective Zero-shot Cross-lingual Phoneme Recognition
Sep 23, 2021
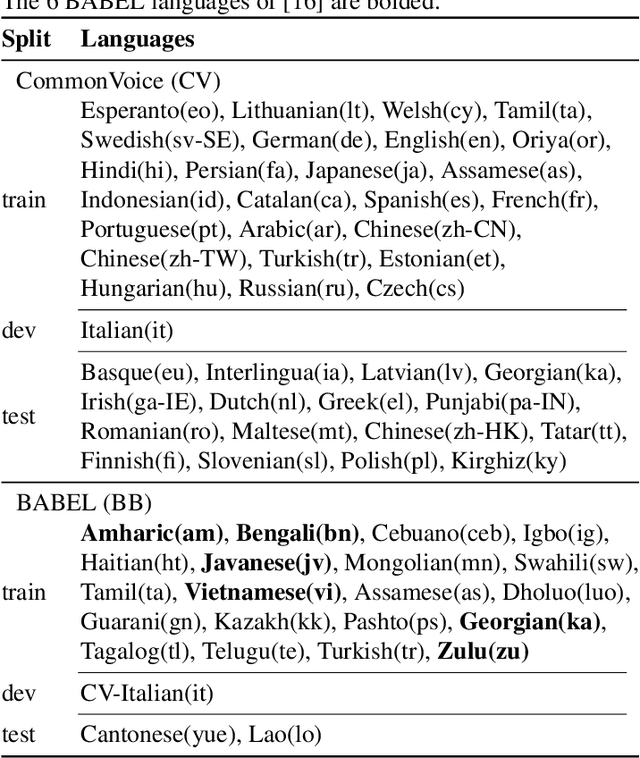

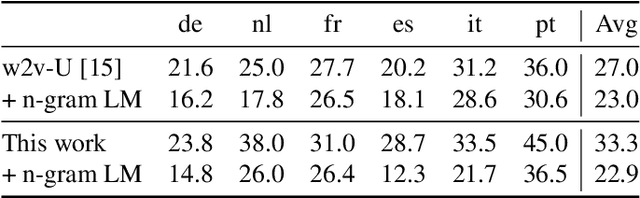
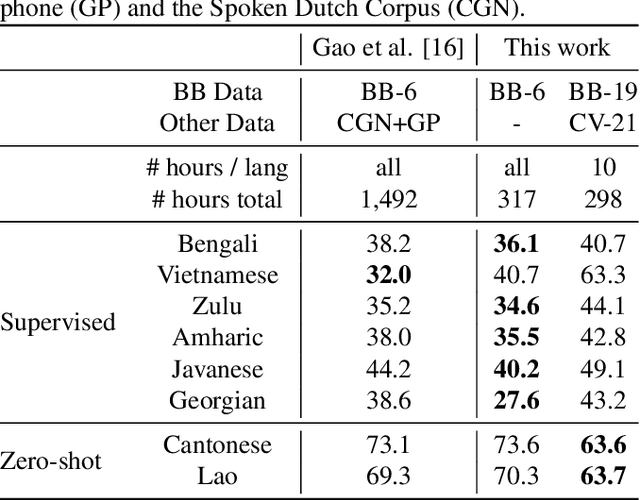
Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech recognition systems without any labeled data. However, in many cases there is labeled data available for related languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by mapping phonemes of the training languages to the target language using articulatory features. Experiments show that this simple method significantly outperforms prior work which introduced task-specific architectures and used only part of a monolingually pretrained model.
Domain Prompts: Towards memory and compute efficient domain adaptation of ASR systems
Dec 16, 2021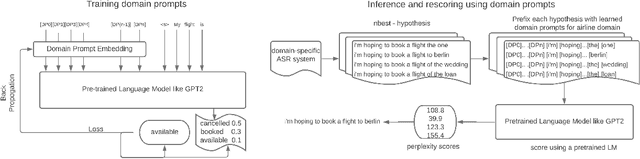

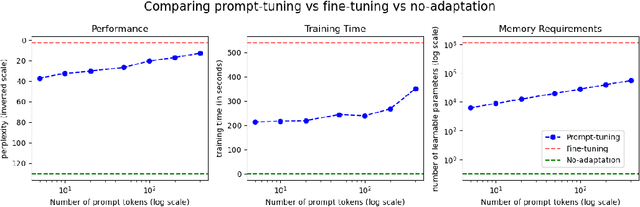
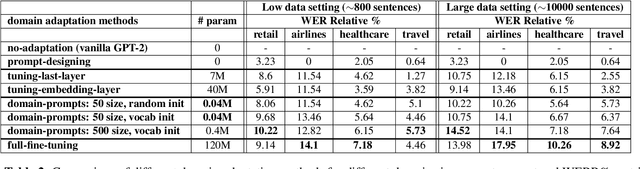
Automatic Speech Recognition (ASR) systems have found their use in numerous industrial applications in very diverse domains. Since domain-specific systems perform better than their generic counterparts on in-domain evaluation, the need for memory and compute-efficient domain adaptation is obvious. Particularly, adapting parameter-heavy transformer-based language models used for rescoring ASR hypothesis is challenging. In this work, we introduce domain-prompts, a methodology that trains a small number of domain token embedding parameters to prime a transformer-based LM to a particular domain. With just a handful of extra parameters per domain, we achieve 7-14% WER improvement over the baseline of using an unadapted LM. Despite being parameter-efficient, these improvements are comparable to those of fully-fine-tuned models with hundreds of millions of parameters. With ablations on prompt-sizes, dataset sizes, initializations and domains, we provide evidence for the benefits of using domain-prompts in ASR systems.
Predicting Affective Vocal Bursts with Finetuned wav2vec 2.0
Sep 27, 2022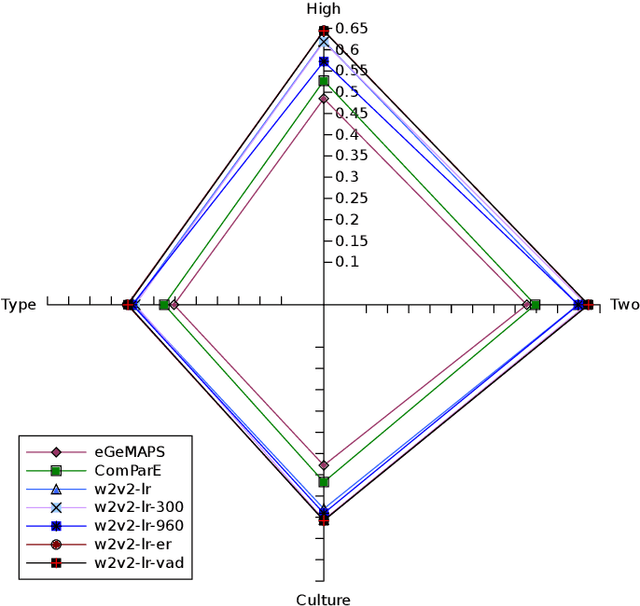


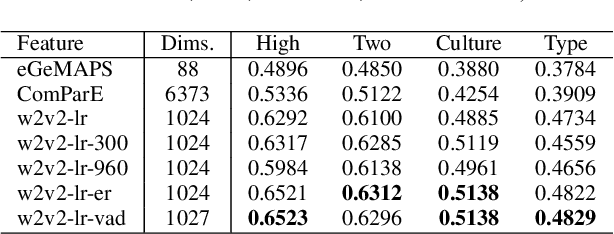
The studies of predicting affective states from human voices have relied heavily on speech. This study, indeed, explores the recognition of humans' affective state from their vocal burst, a short non-verbal vocalization. Borrowing the idea from the recent success of wav2vec 2.0, we evaluated finetuned wav2vec 2.0 models from different datasets to predict the affective state of the speaker from their vocal burst. The finetuned wav2vec 2.0 models are then trained on the vocal burst data. The results show that the finetuned wav2vec 2.0 models, particularly on an affective speech dataset, outperform the baseline model, which is handcrafted acoustic features. However, there is no large gap between the model finetuned on non-affective speech dataset and affective speech dataset.
Multilingual training set selection for ASR in under-resourced Malian languages
Aug 13, 2021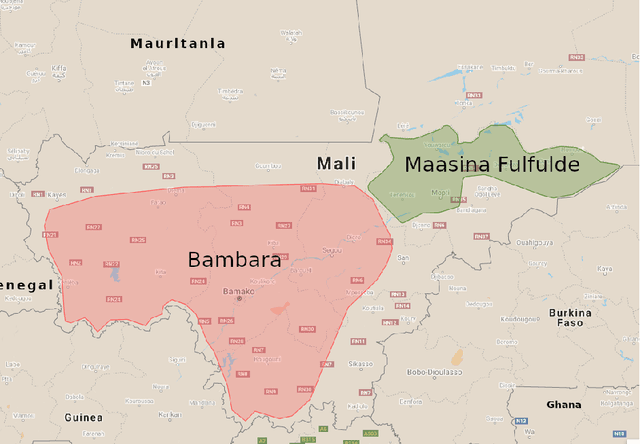

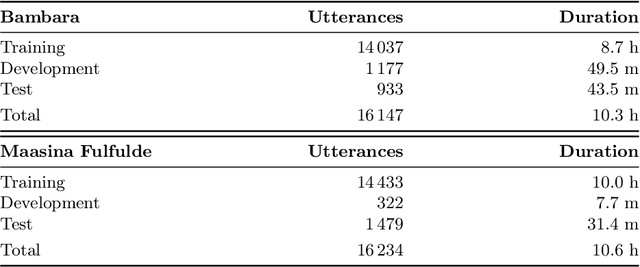
We present first speech recognition systems for the two severely under-resourced Malian languages Bambara and Maasina Fulfulde. These systems will be used by the United Nations as part of a monitoring system to inform and support humanitarian programmes in rural Africa. We have compiled datasets in Bambara and Maasina Fulfulde, but since these are very small, we take advantage of six similarly under-resourced datasets in other languages for multilingual training. We focus specifically on the best composition of the multilingual pool of speech data for multilingual training. We find that, although maximising the training pool by including all six additional languages provides improved speech recognition in both target languages, substantially better performance can be achieved by a more judicious choice. Our experiments show that the addition of just one language provides best performance. For Bambara, this additional language is Maasina Fulfulde, and its introduction leads to a relative word error rate reduction of 6.7%, as opposed to a 2.4% relative reduction achieved when pooling all six additional languages. For the case of Maasina Fulfulde, best performance was achieved when adding only Luganda, leading to a relative word error rate improvement of 9.4% as opposed to a 3.9% relative improvement when pooling all six languages. We conclude that careful selection of the out-of-language data is worthwhile for multilingual training even in highly under-resourced settings, and that the general assumption that more data is better does not always hold.
Run-and-back stitch search: novel block synchronous decoding for streaming encoder-decoder ASR
Jan 25, 2022
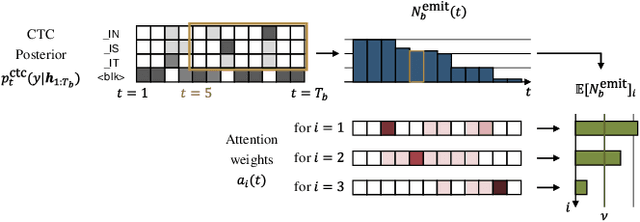
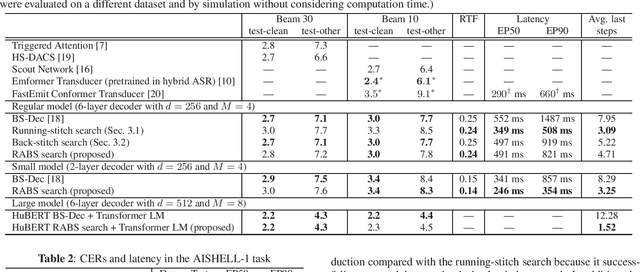
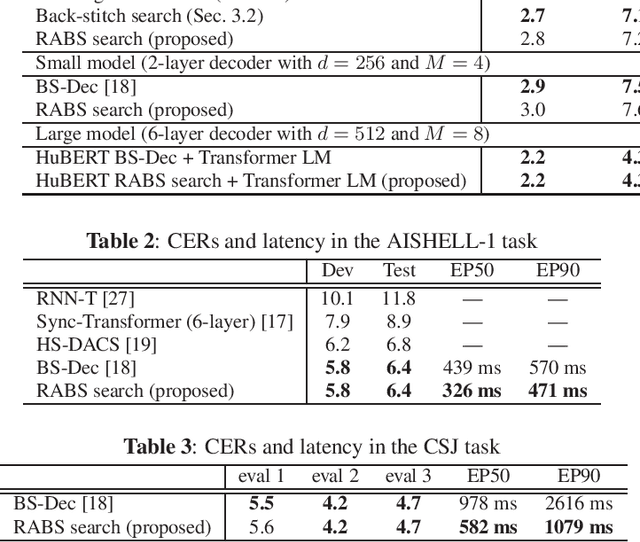
A streaming style inference of encoder-decoder automatic speech recognition (ASR) system is important for reducing latency, which is essential for interactive use cases. To this end, we propose a novel blockwise synchronous decoding algorithm with a hybrid approach that combines endpoint prediction and endpoint post-determination. In the endpoint prediction, we compute the expectation of the number of tokens that are yet to be emitted in the encoder features of the current blocks using the CTC posterior. Based on the expectation value, the decoder predicts the endpoint to realize continuous block synchronization, as a running stitch. Meanwhile, endpoint post-determination probabilistically detects backward jump of the source-target attention, which is caused by the misprediction of endpoints. Then it resumes decoding by discarding those hypotheses, as back stitch. We combine these methods into a hybrid approach, namely run-and-back stitch search, which reduces the computational cost and latency. Evaluations of various ASR tasks show the efficiency of our proposed decoding algorithm, which achieves a latency reduction, for instance in the Librispeech test set from 1487 ms to 821 ms at the 90th percentile, while maintaining a high recognition accuracy.
A Convolutional Neural Network Based Approach to Recognize Bangla Spoken Digits from Speech Signal
Nov 12, 2021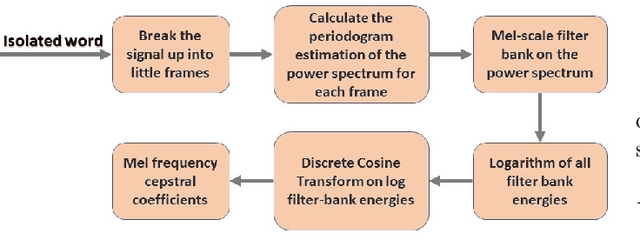
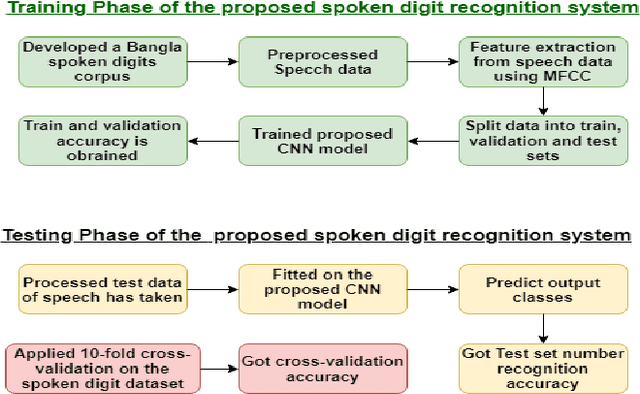
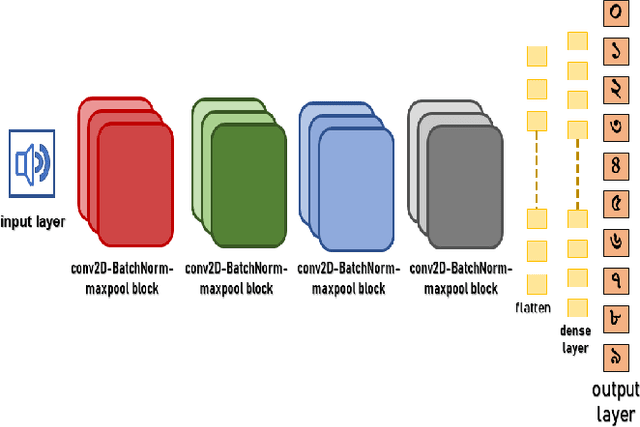
Speech recognition is a technique that converts human speech signals into text or words or in any form that can be easily understood by computers or other machines. There have been a few studies on Bangla digit recognition systems, the majority of which used small datasets with few variations in genders, ages, dialects, and other variables. Audio recordings of Bangladeshi people of various genders, ages, and dialects were used to create a large speech dataset of spoken '0-9' Bangla digits in this study. Here, 400 noisy and noise-free samples per digit have been recorded for creating the dataset. Mel Frequency Cepstrum Coefficients (MFCCs) have been utilized for extracting meaningful features from the raw speech data. Then, to detect Bangla numeral digits, Convolutional Neural Networks (CNNs) were utilized. The suggested technique recognizes '0-9' Bangla spoken digits with 97.1% accuracy throughout the whole dataset. The efficiency of the model was also assessed using 10-fold crossvalidation, which yielded a 96.7% accuracy.
End-to-End Speaker-Attributed ASR with Transformer
Apr 05, 2021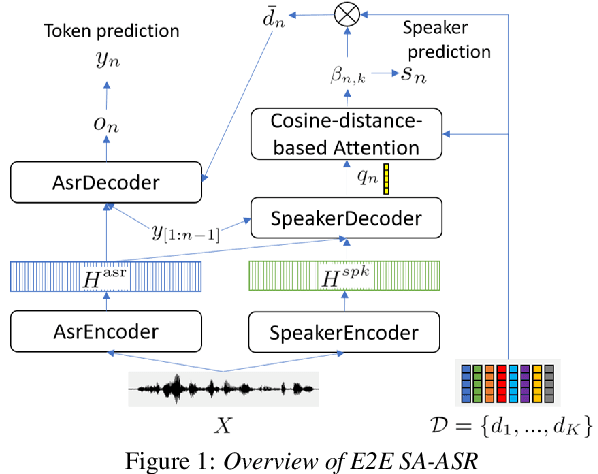
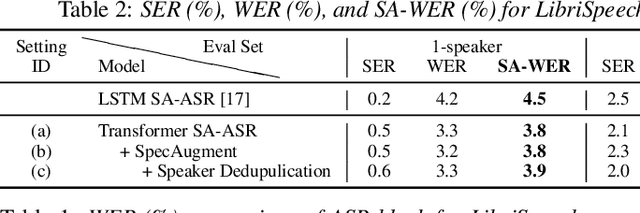
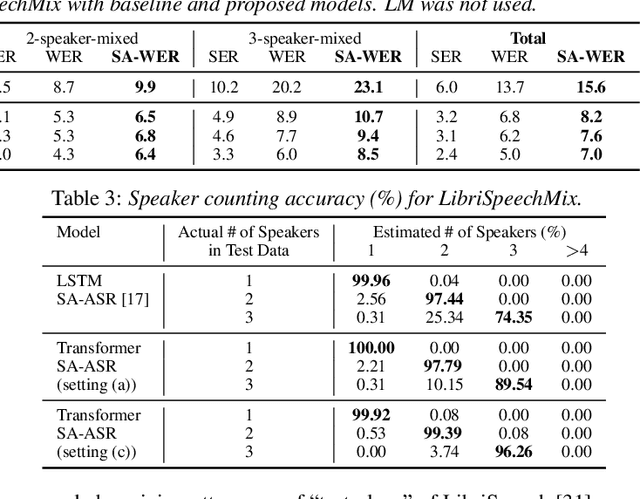
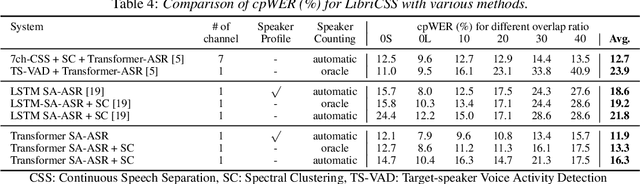
This paper presents our recent effort on end-to-end speaker-attributed automatic speech recognition, which jointly performs speaker counting, speech recognition and speaker identification for monaural multi-talker audio. Firstly, we thoroughly update the model architecture that was previously designed based on a long short-term memory (LSTM)-based attention encoder decoder by applying transformer architectures. Secondly, we propose a speaker deduplication mechanism to reduce speaker identification errors in highly overlapped regions. Experimental results on the LibriSpeechMix dataset shows that the transformer-based architecture is especially good at counting the speakers and that the proposed model reduces the speaker-attributed word error rate by 47% over the LSTM-based baseline. Furthermore, for the LibriCSS dataset, which consists of real recordings of overlapped speech, the proposed model achieves concatenated minimum-permutation word error rates of 11.9% and 16.3% with and without target speaker profiles, respectively, both of which are the state-of-the-art results for LibriCSS with the monaural setting.
Speech Recognition with Deep Recurrent Neural Networks
Mar 22, 2013
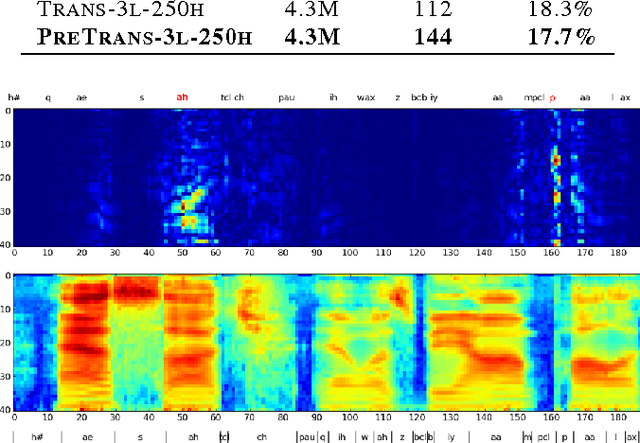
Recurrent neural networks (RNNs) are a powerful model for sequential data. End-to-end training methods such as Connectionist Temporal Classification make it possible to train RNNs for sequence labelling problems where the input-output alignment is unknown. The combination of these methods with the Long Short-term Memory RNN architecture has proved particularly fruitful, delivering state-of-the-art results in cursive handwriting recognition. However RNN performance in speech recognition has so far been disappointing, with better results returned by deep feedforward networks. This paper investigates \emph{deep recurrent neural networks}, which combine the multiple levels of representation that have proved so effective in deep networks with the flexible use of long range context that empowers RNNs. When trained end-to-end with suitable regularisation, we find that deep Long Short-term Memory RNNs achieve a test set error of 17.7% on the TIMIT phoneme recognition benchmark, which to our knowledge is the best recorded score.
Jointly Fine-Tuning "BERT-like" Self Supervised Models to Improve Multimodal Speech Emotion Recognition
Aug 15, 2020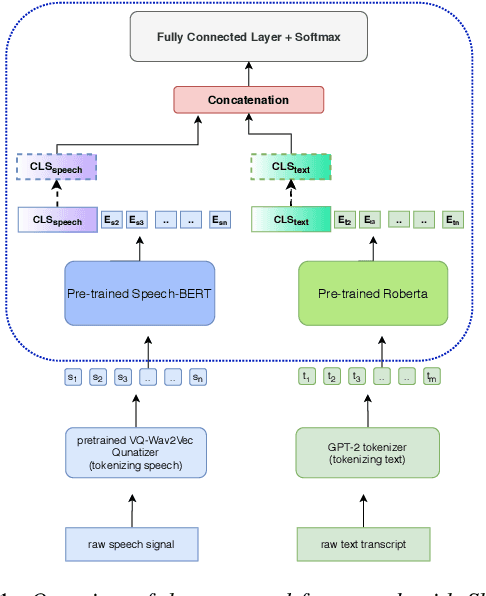
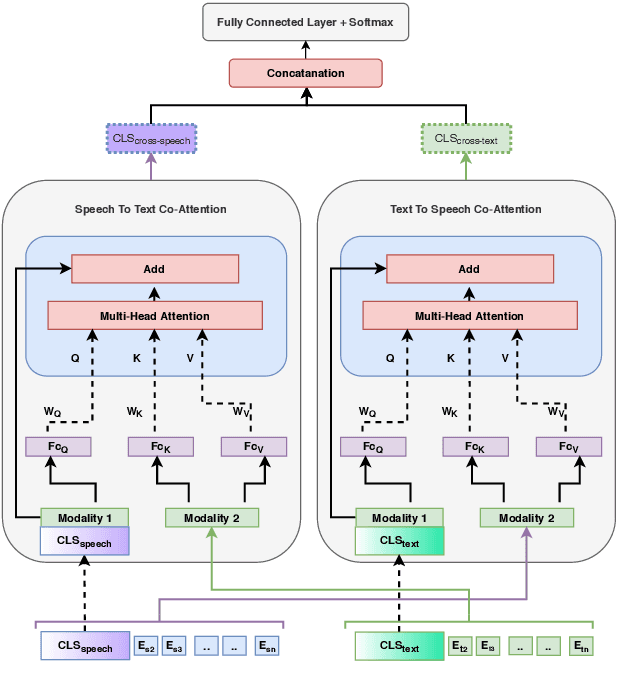
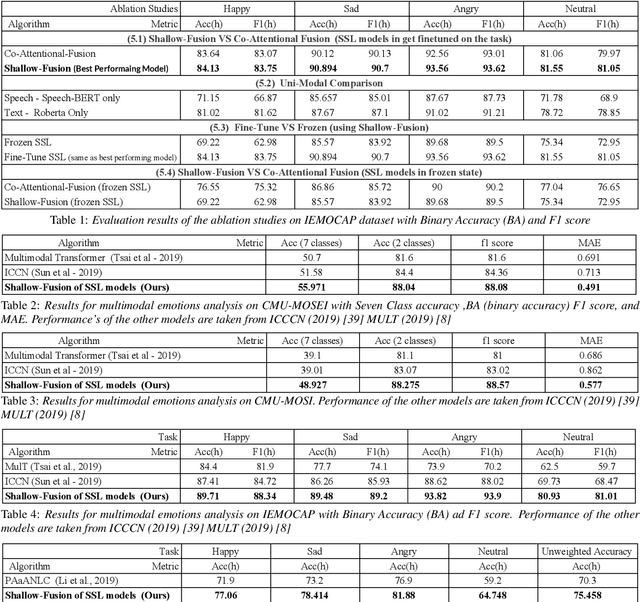
Multimodal emotion recognition from speech is an important area in affective computing. Fusing multiple data modalities and learning representations with limited amounts of labeled data is a challenging task. In this paper, we explore the use of modality-specific "BERT-like" pretrained Self Supervised Learning (SSL) architectures to represent both speech and text modalities for the task of multimodal speech emotion recognition. By conducting experiments on three publicly available datasets (IEMOCAP, CMU-MOSEI, and CMU-MOSI), we show that jointly fine-tuning "BERT-like" SSL architectures achieve state-of-the-art (SOTA) results. We also evaluate two methods of fusing speech and text modalities and show that a simple fusion mechanism can outperform more complex ones when using SSL models that have similar architectural properties to BERT.
PickNet: Real-Time Channel Selection for Ad Hoc Microphone Arrays
Jan 24, 2022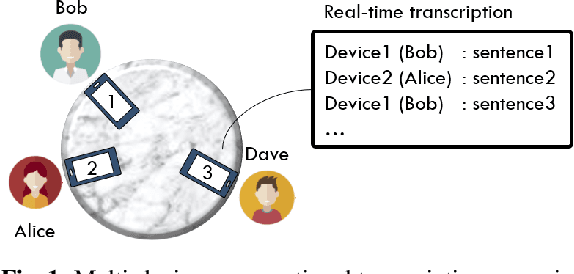
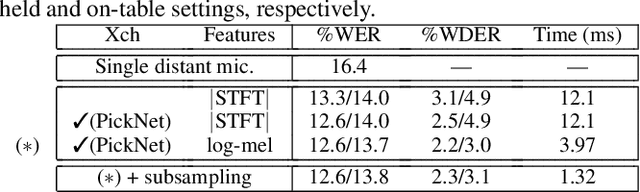
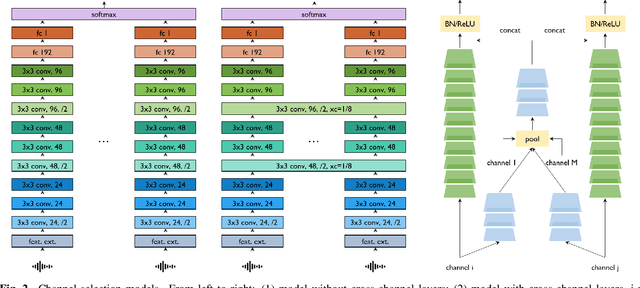
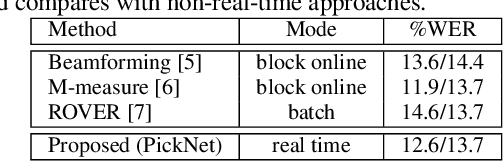
This paper proposes PickNet, a neural network model for real-time channel selection for an ad hoc microphone array consisting of multiple recording devices like cell phones. Assuming at most one person to be vocally active at each time point, PickNet identifies the device that is spatially closest to the active person for each time frame by using a short spectral patch of just hundreds of milliseconds. The model is applied to every time frame, and the short time frame signals from the selected microphones are concatenated across the frames to produce an output signal. As the personal devices are usually held close to their owners, the output signal is expected to have higher signal-to-noise and direct-to-reverberation ratios on average than the input signals. Since PickNet utilizes only limited acoustic context at each time frame, the system using the proposed model works in real time and is robust to changes in acoustic conditions. Speech recognition-based evaluation was carried out by using real conversational recordings obtained with various smartphones. The proposed model yielded significant gains in word error rate with limited computational cost over systems using a block-online beamformer and a single distant microphone.