 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Deep Long Short-Term Memory Adaptive Beamforming Networks For Multichannel Robust Speech Recognition
Nov 21, 2017
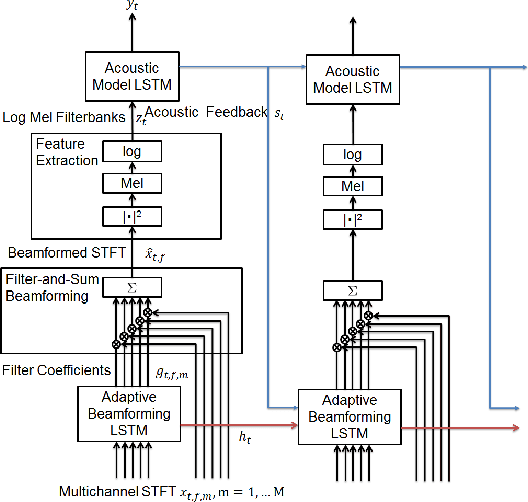
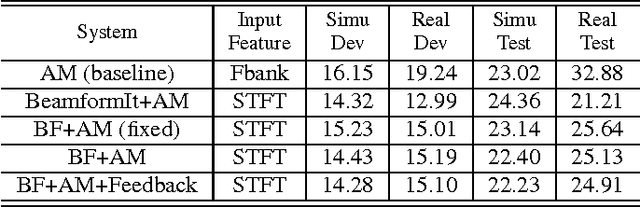
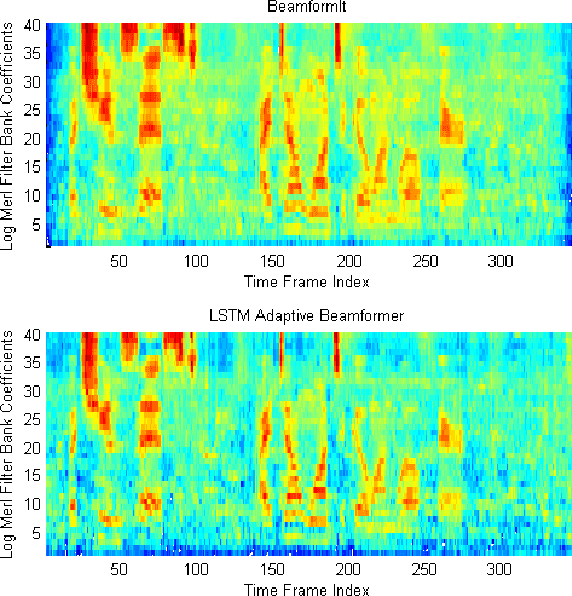
Far-field speech recognition in noisy and reverberant conditions remains a challenging problem despite recent deep learning breakthroughs. This problem is commonly addressed by acquiring a speech signal from multiple microphones and performing beamforming over them. In this paper, we propose to use a recurrent neural network with long short-term memory (LSTM) architecture to adaptively estimate real-time beamforming filter coefficients to cope with non-stationary environmental noise and dynamic nature of source and microphones positions which results in a set of timevarying room impulse responses. The LSTM adaptive beamformer is jointly trained with a deep LSTM acoustic model to predict senone labels. Further, we use hidden units in the deep LSTM acoustic model to assist in predicting the beamforming filter coefficients. The proposed system achieves 7.97% absolute gain over baseline systems with no beamforming on CHiME-3 real evaluation set.
* in 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
SDS-200: A Swiss German Speech to Standard German Text Corpus
May 19, 2022
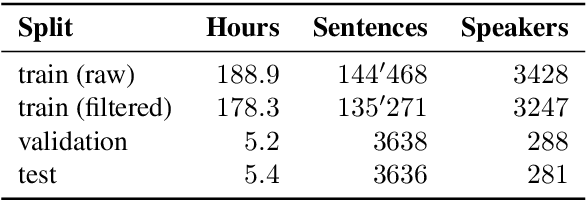
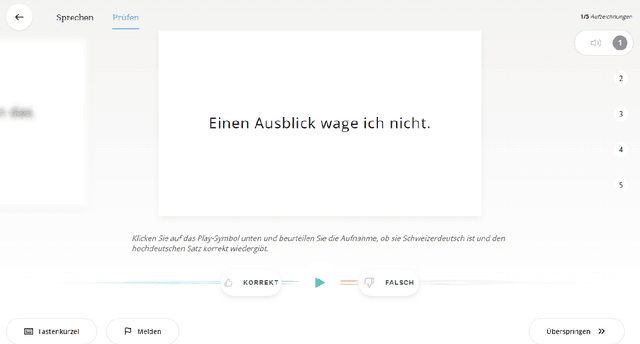
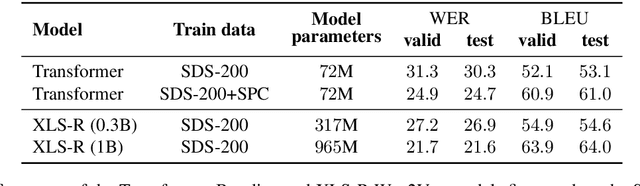
We present SDS-200, a corpus of Swiss German dialectal speech with Standard German text translations, annotated with dialect, age, and gender information of the speakers. The dataset allows for training speech translation, dialect recognition, and speech synthesis systems, among others. The data was collected using a web recording tool that is open to the public. Each participant was given a text in Standard German and asked to translate it to their Swiss German dialect before recording it. To increase the corpus quality, recordings were validated by other participants. The data consists of 200 hours of speech by around 4000 different speakers and covers a large part of the Swiss-German dialect landscape. We release SDS-200 alongside a baseline speech translation model, which achieves a word error rate (WER) of 30.3 and a BLEU score of 53.1 on the SDS-200 test set. Furthermore, we use SDS-200 to fine-tune a pre-trained XLS-R model, achieving 21.6 WER and 64.0 BLEU.
Improving RNN-T ASR Performance with Date-Time and Location Awareness
Jun 11, 2021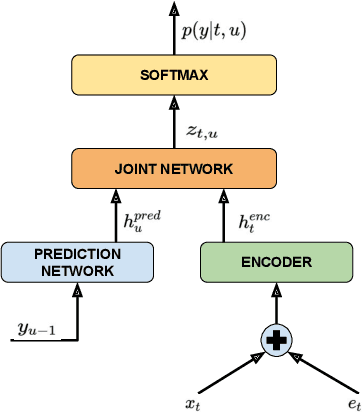
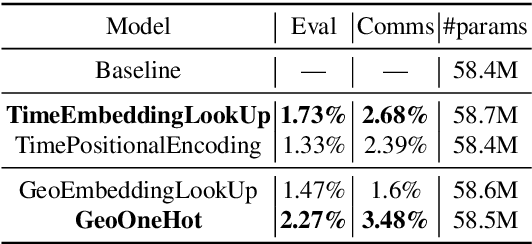
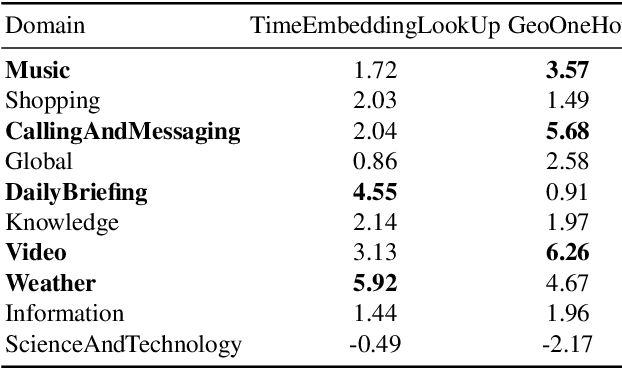

In this paper, we explore the benefits of incorporating context into a Recurrent Neural Network (RNN-T) based Automatic Speech Recognition (ASR) model to improve the speech recognition for virtual assistants. Specifically, we use meta information extracted from the time at which the utterance is spoken and the approximate location information to make ASR context aware. We show that these contextual information, when used individually, improves overall performance by as much as 3.48% relative to the baseline and when the contexts are combined, the model learns complementary features and the recognition improves by 4.62%. On specific domains, these contextual signals show improvements as high as 11.5%, without any significant degradation on others. We ran experiments with models trained on data of sizes 30K hours and 10K hours. We show that the scale of improvement with the 10K hours dataset is much higher than the one obtained with 30K hours dataset. Our results indicate that with limited data to train the ASR model, contextual signals can improve the performance significantly.
Generalizing RNN-Transducer to Out-Domain Audio via Sparse Self-Attention Layers
Aug 22, 2021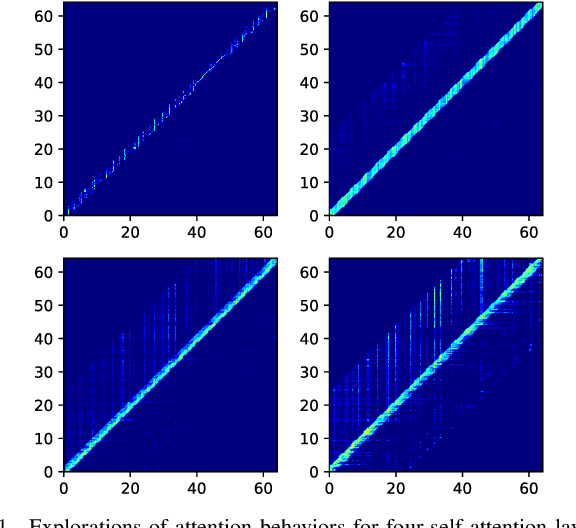
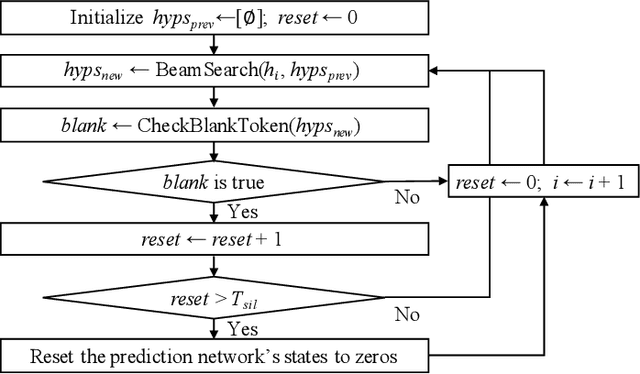
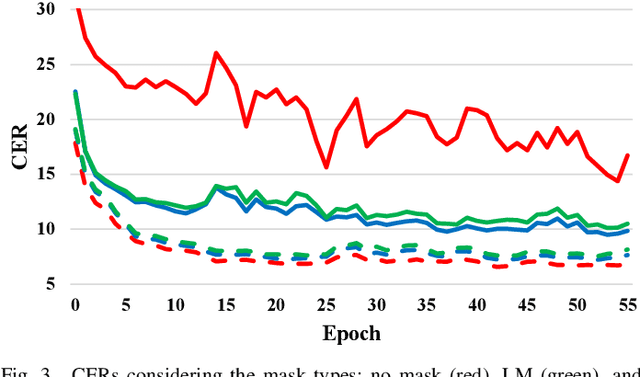

Recurrent neural network transducers (RNN-T) are a promising end-to-end speech recognition framework that transduces input acoustic frames into a character sequence. The state-of-the-art encoder network for RNN-T is the Conformer, which can effectively model the local-global context information via its convolution and self-attention layers. Although Conformer RNN-T has shown outstanding performance (measured by word error rate (WER) in general), most studies have been verified in the setting where the train and test data are drawn from the same domain. The domain mismatch problem for Conformer RNN-T has not been intensively investigated yet, which is an important issue for the product-level speech recognition system. In this study, we identified that fully connected self-attention layers in the Conformer caused high deletion errors, specifically in the long-form out-domain utterances. To address this problem, we introduce sparse self-attention layers for Conformer-based encoder networks, which can exploit local and generalized global information by pruning most of the in-domain fitted global connections. Further, we propose a state reset method for the generalization of the prediction network to cope with long-form utterances. Applying proposed methods to an out-domain test, we obtained 24.6\% and 6.5\% relative character error rate (CER) reduction compared to the fully connected and local self-attention layer-based Conformers, respectively.
End-to-End Attention-based Large Vocabulary Speech Recognition
Mar 14, 2016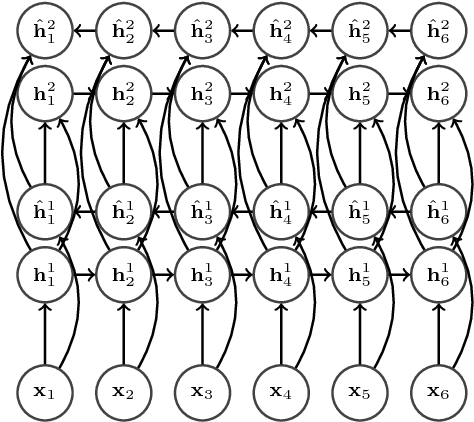
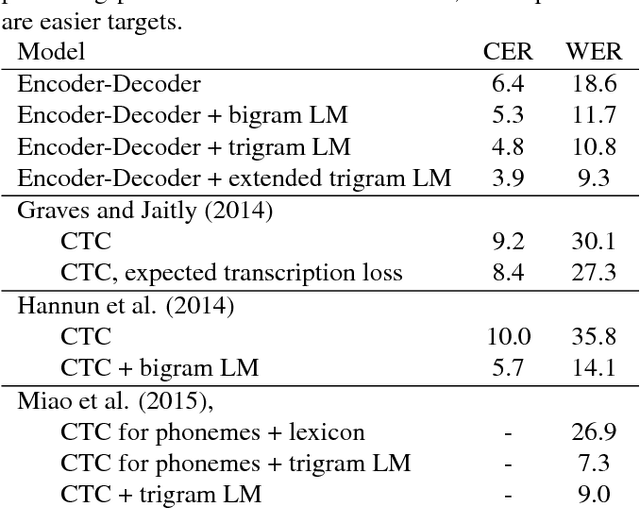
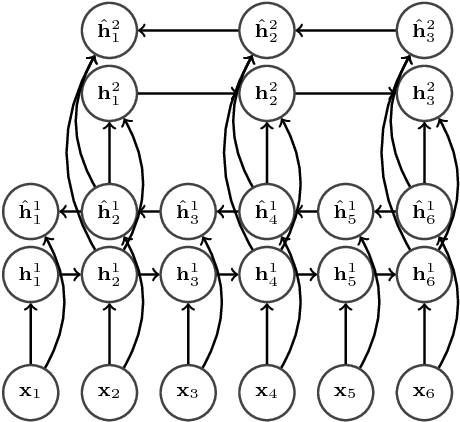
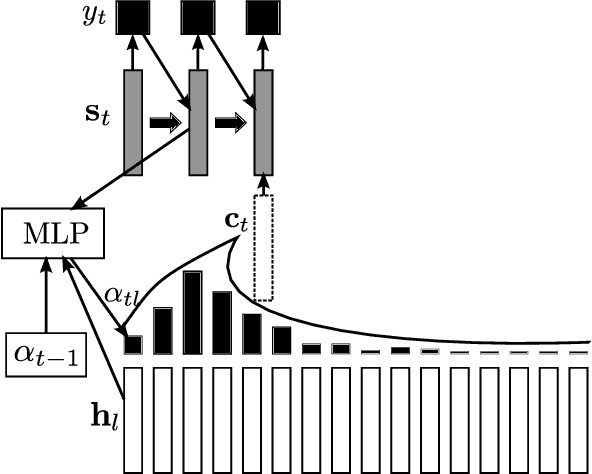
Many of the current state-of-the-art Large Vocabulary Continuous Speech Recognition Systems (LVCSR) are hybrids of neural networks and Hidden Markov Models (HMMs). Most of these systems contain separate components that deal with the acoustic modelling, language modelling and sequence decoding. We investigate a more direct approach in which the HMM is replaced with a Recurrent Neural Network (RNN) that performs sequence prediction directly at the character level. Alignment between the input features and the desired character sequence is learned automatically by an attention mechanism built into the RNN. For each predicted character, the attention mechanism scans the input sequence and chooses relevant frames. We propose two methods to speed up this operation: limiting the scan to a subset of most promising frames and pooling over time the information contained in neighboring frames, thereby reducing source sequence length. Integrating an n-gram language model into the decoding process yields recognition accuracies similar to other HMM-free RNN-based approaches.
Speech Recognition Oriented Vowel Classification Using Temporal Radial Basis Functions
Dec 19, 2009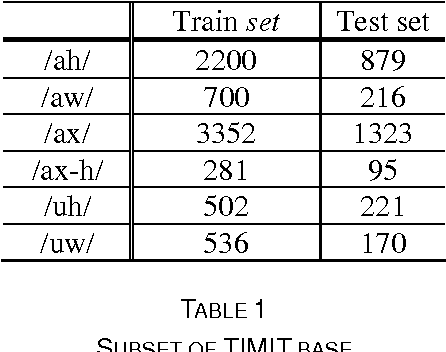
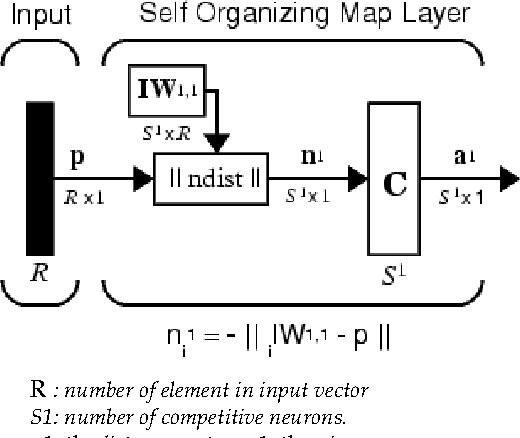
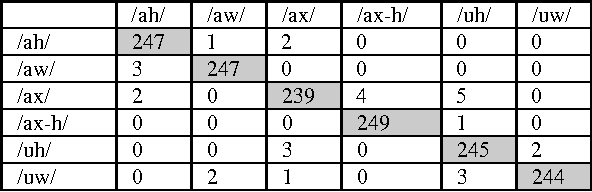
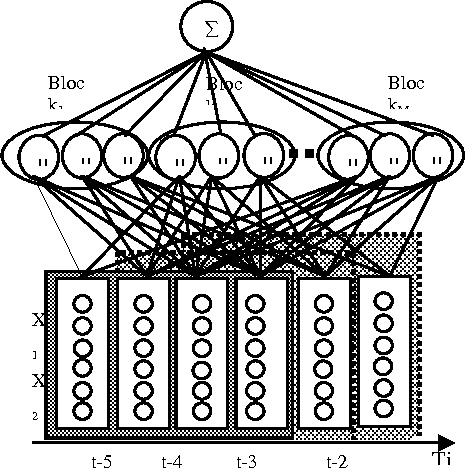
The recent resurgence of interest in spatio-temporal neural network as speech recognition tool motivates the present investigation. In this paper an approach was developed based on temporal radial basis function "TRBF" looking to many advantages: few parameters, speed convergence and time invariance. This application aims to identify vowels taken from natural speech samples from the Timit corpus of American speech. We report a recognition accuracy of 98.06 percent in training and 90.13 in test on a subset of 6 vowel phonemes, with the possibility to expend the vowel sets in future.
Distillation-Resistant Watermarking for Model Protection in NLP
Oct 07, 2022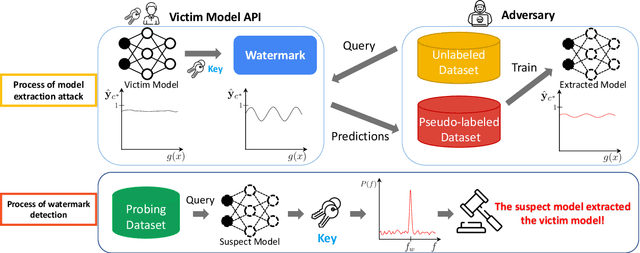
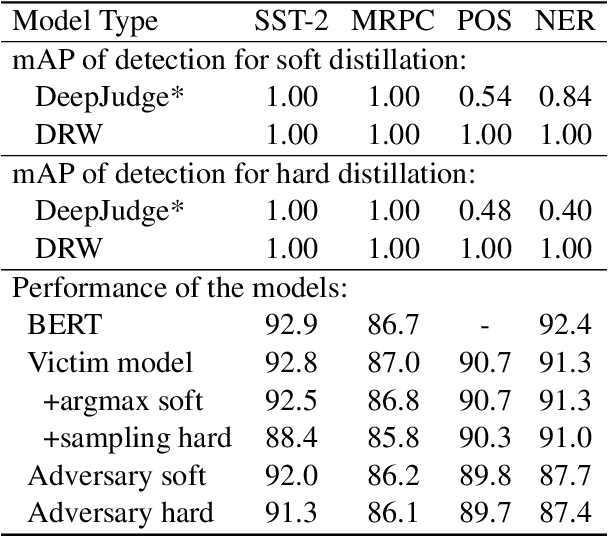
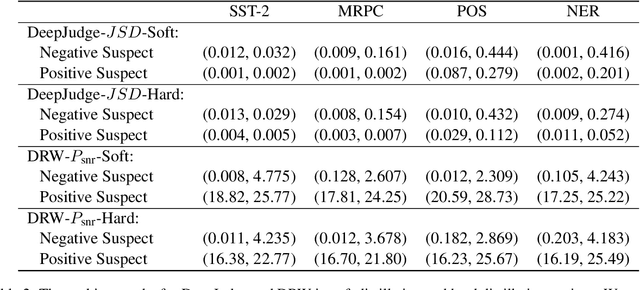
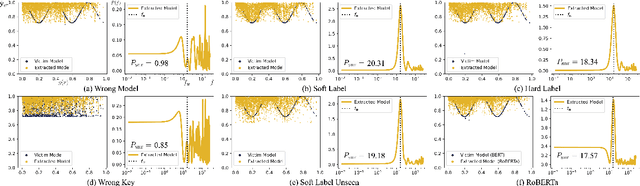
How can we protect the intellectual property of trained NLP models? Modern NLP models are prone to stealing by querying and distilling from their publicly exposed APIs. However, existing protection methods such as watermarking only work for images but are not applicable to text. We propose Distillation-Resistant Watermarking (DRW), a novel technique to protect NLP models from being stolen via distillation. DRW protects a model by injecting watermarks into the victim's prediction probability corresponding to a secret key and is able to detect such a key by probing a suspect model. We prove that a protected model still retains the original accuracy within a certain bound. We evaluate DRW on a diverse set of NLP tasks including text classification, part-of-speech tagging, and named entity recognition. Experiments show that DRW protects the original model and detects stealing suspects at 100% mean average precision for all four tasks while the prior method fails on two.
Internal language model estimation through explicit context vector learning for attention-based encoder-decoder ASR
Jan 26, 2022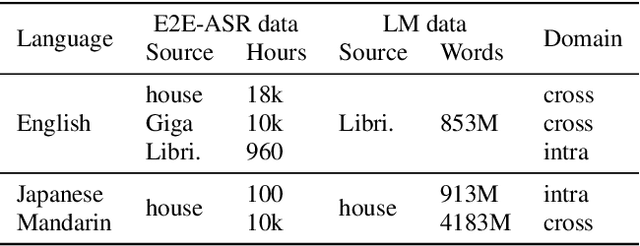
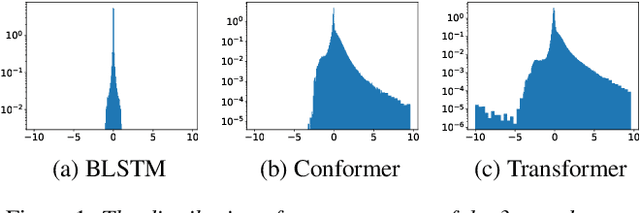
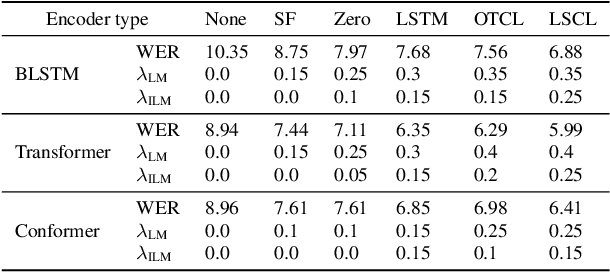

An end-to-end (E2E) speech recognition model implicitly learns a biased internal language model (ILM) during training. To fused an external LM during inference, the scores produced by the biased ILM need to be estimated and subtracted. In this paper we propose two novel approaches to estimate the biased ILM based on Listen-Attend-Spell (LAS) models. The simpler method is to replace the context vector of the LAS decoder at every time step with a learnable vector. The other more advanced method is to use a simple feed-forward network to directly map query vectors to context vectors, making the generation of the context vectors independent of the LAS encoder. Both the learnable vector and the mapping network are trained on the transcriptions of the training data to minimize the perplexity while all the other parameters of the LAS model is fixed. Experiments show that the ILMs estimated by the proposed methods achieve the lowest perplexity. In addition, they also significantly outperform the shallow fusion method and two previously proposed Internal Language Model Estimation (ILME) approaches on multiple datasets.
Large Scale Language Modeling in Automatic Speech Recognition
Oct 31, 2012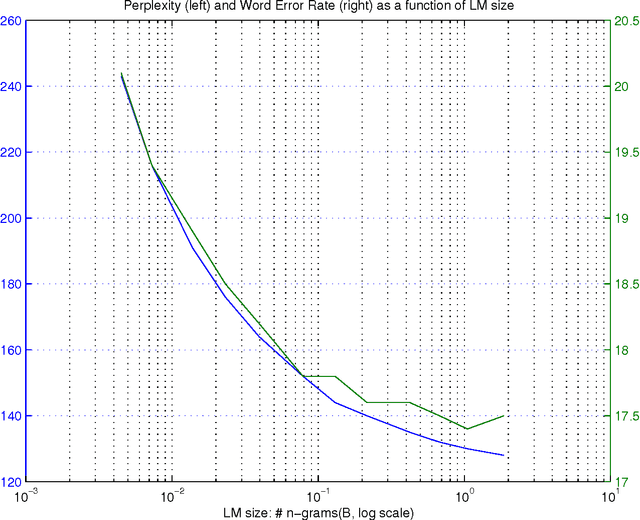
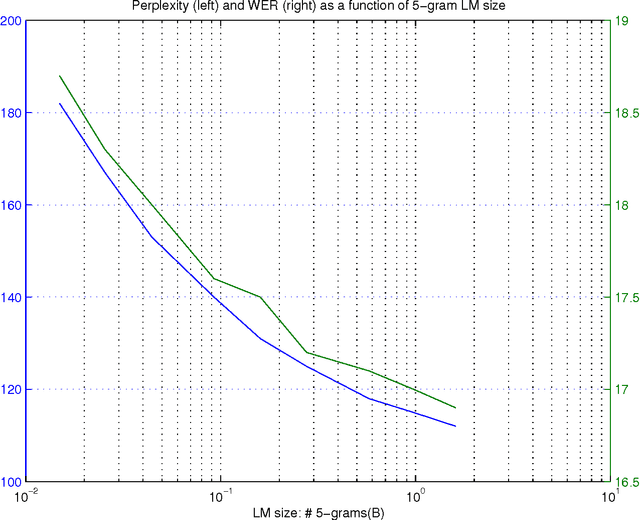


Large language models have been proven quite beneficial for a variety of automatic speech recognition tasks in Google. We summarize results on Voice Search and a few YouTube speech transcription tasks to highlight the impact that one can expect from increasing both the amount of training data, and the size of the language model estimated from such data. Depending on the task, availability and amount of training data used, language model size and amount of work and care put into integrating them in the lattice rescoring step we observe reductions in word error rate between 6% and 10% relative, for systems on a wide range of operating points between 17% and 52% word error rate.
Prediction of speech intelligibility with DNN-based performance measures
Mar 17, 2022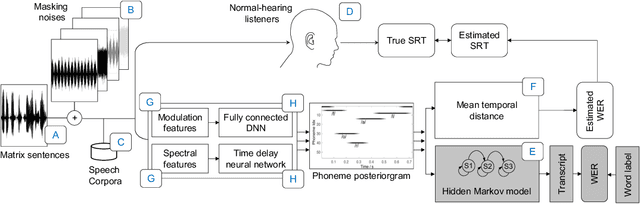


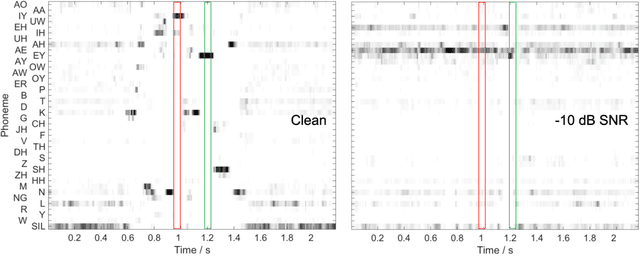
This paper presents a speech intelligibility model based on automatic speech recognition (ASR), combining phoneme probabilities from deep neural networks (DNN) and a performance measure that estimates the word error rate from these probabilities. This model does not require the clean speech reference nor the word labels during testing as the ASR decoding step, which finds the most likely sequence of words given phoneme posterior probabilities, is omitted. The model is evaluated via the root-mean-squared error between the predicted and observed speech reception thresholds from eight normal-hearing listeners. The recognition task consists of identifying noisy words from a German matrix sentence test. The speech material was mixed with eight noise maskers covering different modulation types, from speech-shaped stationary noise to a single-talker masker. The prediction performance is compared to five established models and an ASR-model using word labels. Two combinations of features and networks were tested. Both include temporal information either at the feature level (amplitude modulation filterbanks and a feed-forward network) or captured by the architecture (mel-spectrograms and a time-delay deep neural network, TDNN). The TDNN model is on par with the DNN while reducing the number of parameters by a factor of 37; this optimization allows parallel streams on dedicated hearing aid hardware as a forward-pass can be computed within the 10ms of each frame. The proposed model performs almost as well as the label-based model and produces more accurate predictions than the baseline models.