 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Accent Recognition with Hybrid Phonetic Features
May 05, 2021
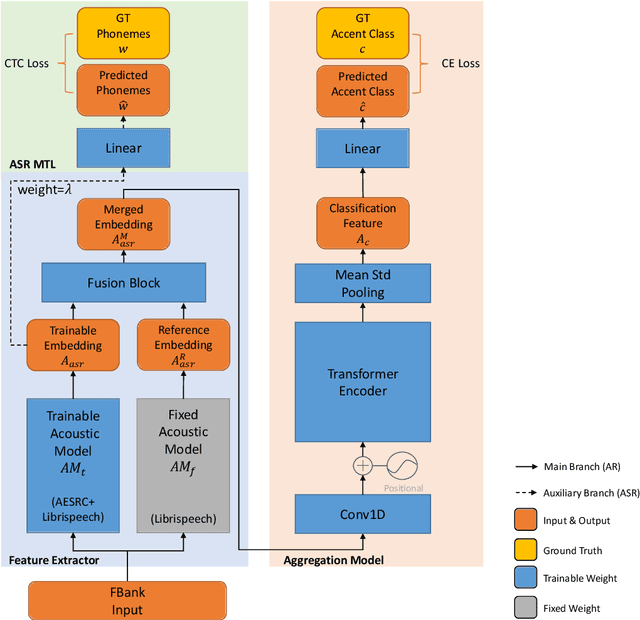

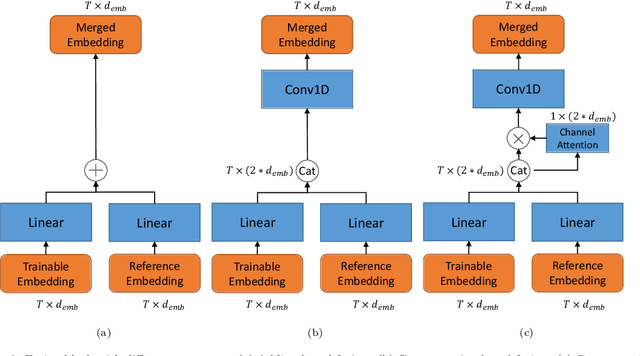
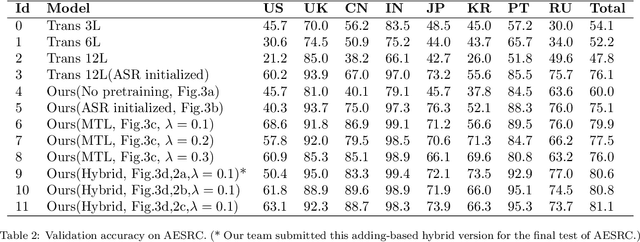
The performance of voice-controlled systems is usually influenced by accented speech. To make these systems more robust, the frontend accent recognition (AR) technologies have received increased attention in recent years. As accent is a high-level abstract feature that has a profound relationship with the language knowledge, AR is more challenging than other language-agnostic audio classification tasks. In this paper, we use an auxiliary automatic speech recognition (ASR) task to extract language-related phonetic features. Furthermore, we propose a hybrid structure that incorporates the embeddings of both a fixed acoustic model and a trainable acoustic model, making the language-related acoustic feature more robust. We conduct several experiments on the Accented English Speech Recognition Challenge (AESRC) 2020 dataset. The results demonstrate that our approach can obtain a 6.57% relative improvement on the validation set. We also get a 7.28% relative improvement on the final test set for this competition, showing the merits of the proposed method.
T-NGA: Temporal Network Grafting Algorithm for Learning to Process Spiking Audio Sensor Events
Feb 07, 2022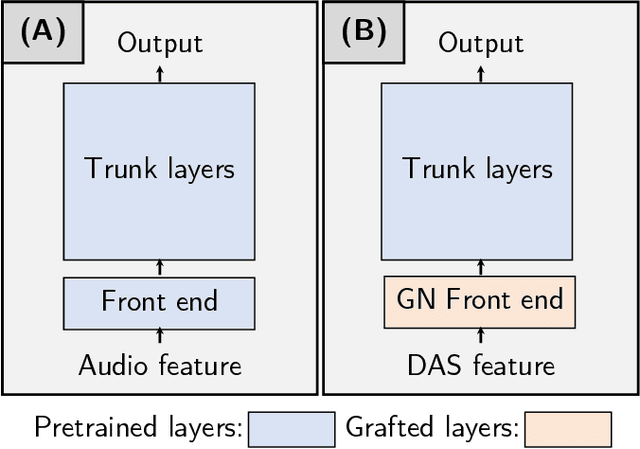
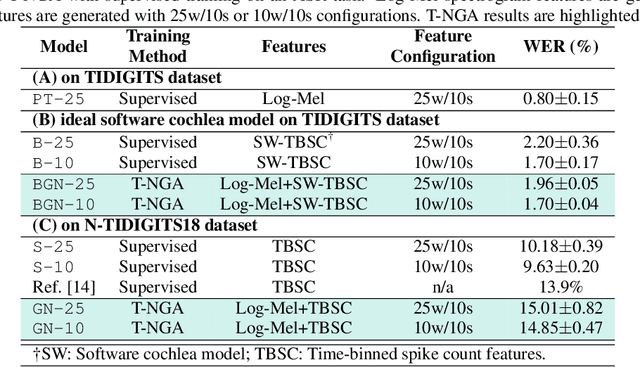
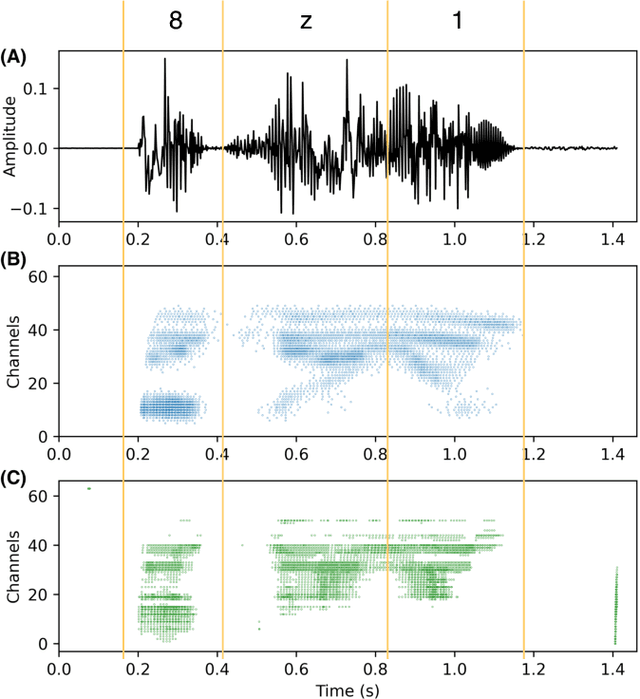

Spiking silicon cochlea sensors encode sound as an asynchronous stream of spikes from different frequency channels. The lack of labeled training datasets for spiking cochleas makes it difficult to train deep neural networks on the outputs of these sensors. This work proposes a self-supervised method called Temporal Network Grafting Algorithm (T-NGA), which grafts a recurrent network pretrained on spectrogram features so that the network works with the cochlea event features. T-NGA training requires only temporally aligned audio spectrograms and event features. Our experiments show that the accuracy of the grafted network was similar to the accuracy of a supervised network trained from scratch on a speech recognition task using events from a software spiking cochlea model. Despite the circuit non-idealities of the spiking silicon cochlea, the grafted network accuracy on the silicon cochlea spike recordings was only about 5% lower than the supervised network accuracy using the N-TIDIGITS18 dataset. T-NGA can train networks to process spiking audio sensor events in the absence of large labeled spike datasets.
Dynamic Layer Normalization for Adaptive Neural Acoustic Modeling in Speech Recognition
Jul 19, 2017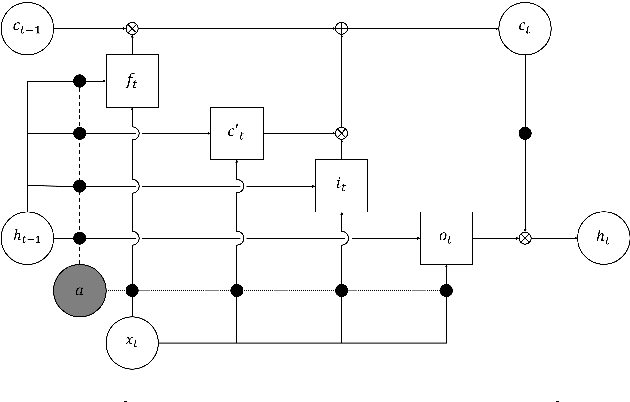
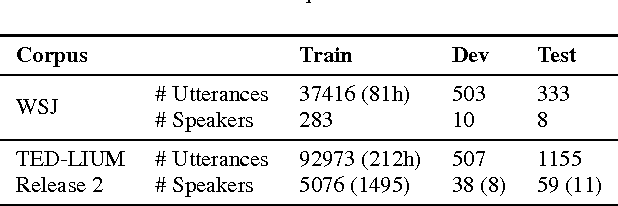
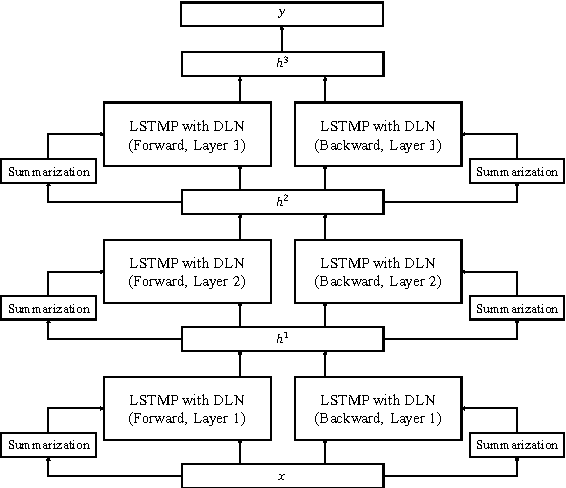
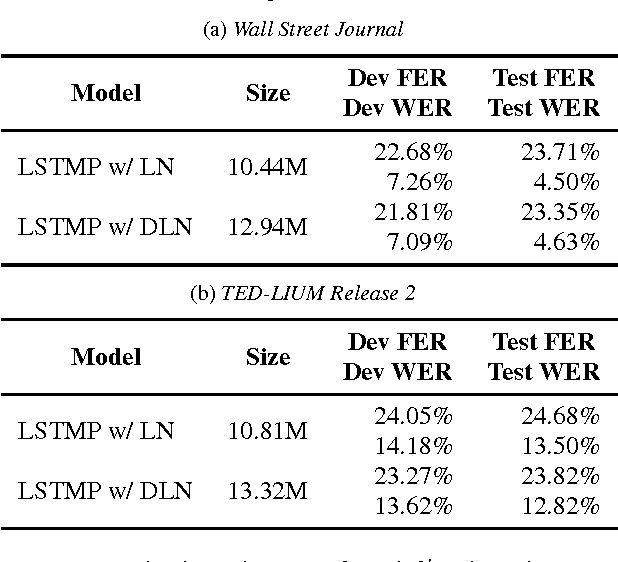
Layer normalization is a recently introduced technique for normalizing the activities of neurons in deep neural networks to improve the training speed and stability. In this paper, we introduce a new layer normalization technique called Dynamic Layer Normalization (DLN) for adaptive neural acoustic modeling in speech recognition. By dynamically generating the scaling and shifting parameters in layer normalization, DLN adapts neural acoustic models to the acoustic variability arising from various factors such as speakers, channel noises, and environments. Unlike other adaptive acoustic models, our proposed approach does not require additional adaptation data or speaker information such as i-vectors. Moreover, the model size is fixed as it dynamically generates adaptation parameters. We apply our proposed DLN to deep bidirectional LSTM acoustic models and evaluate them on two benchmark datasets for large vocabulary ASR experiments: WSJ and TED-LIUM release 2. The experimental results show that our DLN improves neural acoustic models in terms of transcription accuracy by dynamically adapting to various speakers and environments.
ViDA-MAN: Visual Dialog with Digital Humans
Oct 26, 2021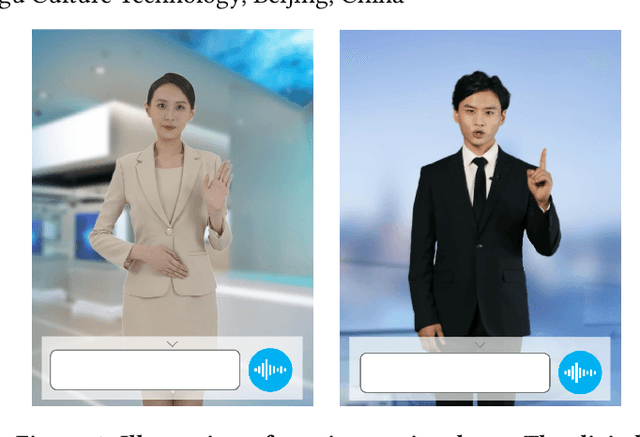
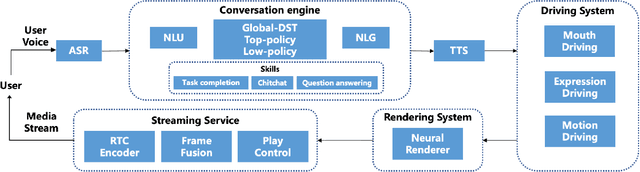
We demonstrate ViDA-MAN, a digital-human agent for multi-modal interaction, which offers realtime audio-visual responses to instant speech inquiries. Compared to traditional text or voice-based system, ViDA-MAN offers human-like interactions (e.g, vivid voice, natural facial expression and body gestures). Given a speech request, the demonstration is able to response with high quality videos in sub-second latency. To deliver immersive user experience, ViDA-MAN seamlessly integrates multi-modal techniques including Acoustic Speech Recognition (ASR), multi-turn dialog, Text To Speech (TTS), talking heads video generation. Backed with large knowledge base, ViDA-MAN is able to chat with users on a number of topics including chit-chat, weather, device control, News recommendations, booking hotels, as well as answering questions via structured knowledge.
Multitask vocal burst modeling with ResNets and pre-trained paralinguistic Conformers
Jun 24, 2022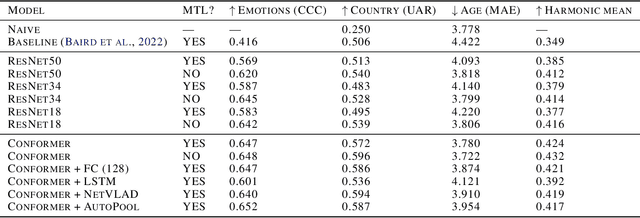
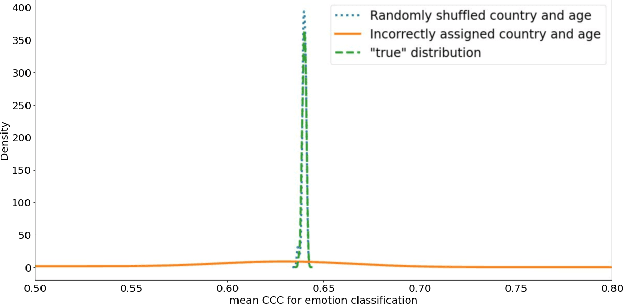
This technical report presents the modeling approaches used in our submission to the ICML Expressive Vocalizations Workshop & Competition multitask track (ExVo-MultiTask). We first applied image classification models of various sizes on mel-spectrogram representations of the vocal bursts, as is standard in sound event detection literature. Results from these models show an increase of 21.24% over the baseline system with respect to the harmonic mean of the task metrics, and comprise our team's main submission to the MultiTask track. We then sought to characterize the headroom in the MultiTask track by applying a large pre-trained Conformer model that previously achieved state-of-the-art results on paralinguistic tasks like speech emotion recognition and mask detection. We additionally investigated the relationship between the sub-tasks of emotional expression, country of origin, and age prediction, and discovered that the best performing models are trained as single-task models, questioning whether the problem truly benefits from a multitask setting.
Optimizing expected word error rate via sampling for speech recognition
Jun 08, 2017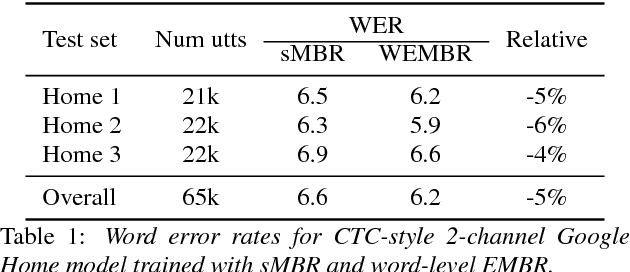
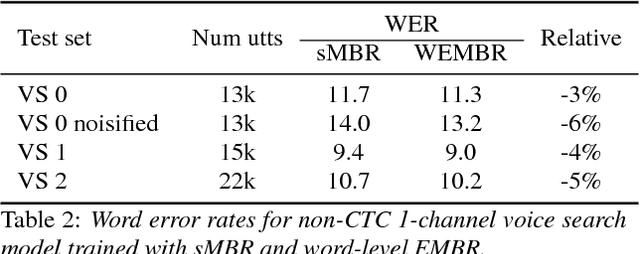
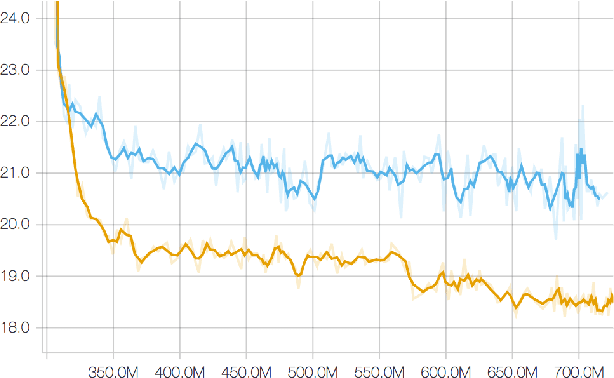
State-level minimum Bayes risk (sMBR) training has become the de facto standard for sequence-level training of speech recognition acoustic models. It has an elegant formulation using the expectation semiring, and gives large improvements in word error rate (WER) over models trained solely using cross-entropy (CE) or connectionist temporal classification (CTC). sMBR training optimizes the expected number of frames at which the reference and hypothesized acoustic states differ. It may be preferable to optimize the expected WER, but WER does not interact well with the expectation semiring, and previous approaches based on computing expected WER exactly involve expanding the lattices used during training. In this paper we show how to perform optimization of the expected WER by sampling paths from the lattices used during conventional sMBR training. The gradient of the expected WER is itself an expectation, and so may be approximated using Monte Carlo sampling. We show experimentally that optimizing WER during acoustic model training gives 5% relative improvement in WER over a well-tuned sMBR baseline on a 2-channel query recognition task (Google Home).
Late reverberation suppression using U-nets
Oct 05, 2021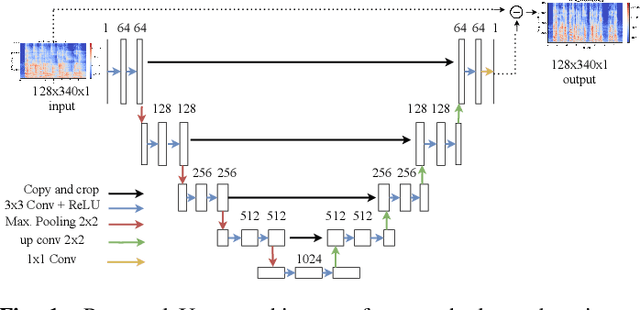
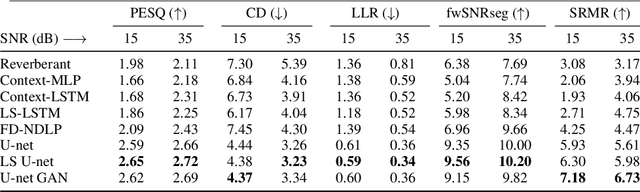
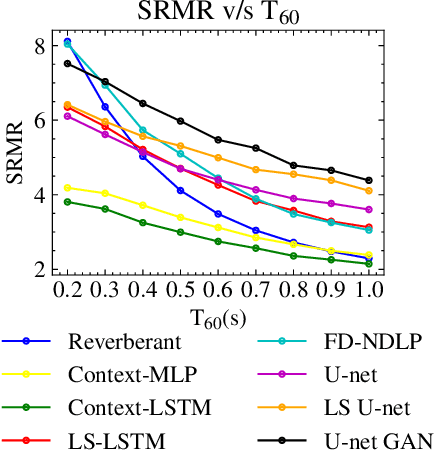
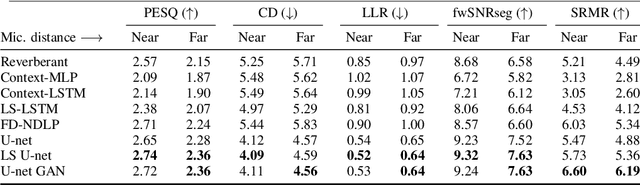
In real-world settings, speech signals are almost always affected by reverberation produced by the working environment; these corrupted signals need to be \emph{dereverberated} prior to performing, e.g., speech recognition, speech-to-text conversion, compression, or general audio enhancement. In this paper, we propose a supervised dereverberation technique using \emph{U-nets with skip connections}, which are fully-convolutional encoder-decoder networks with layers arranged in the form of an "U" and connections that "skip" some layers. Building on this architecture, we address speech dereverberation through the lens of Late Reverberation Suppression (LS). Via experiments on synthetic and real-world data with different noise levels and reverberation settings, we show that our proposed method termed "LS U-net" improves quality, intelligibility and other performance metrics compared to the original U-net method and it is on par with the state-of-the-art GAN-based approaches.
Senone-aware Adversarial Multi-task Training for Unsupervised Child to Adult Speech Adaptation
Feb 23, 2021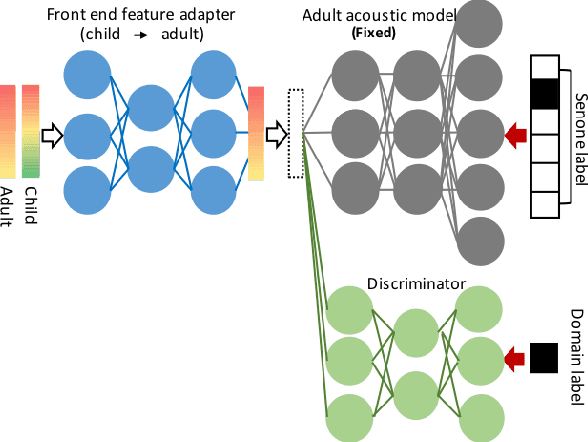
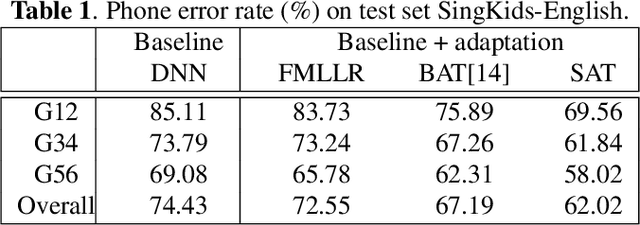
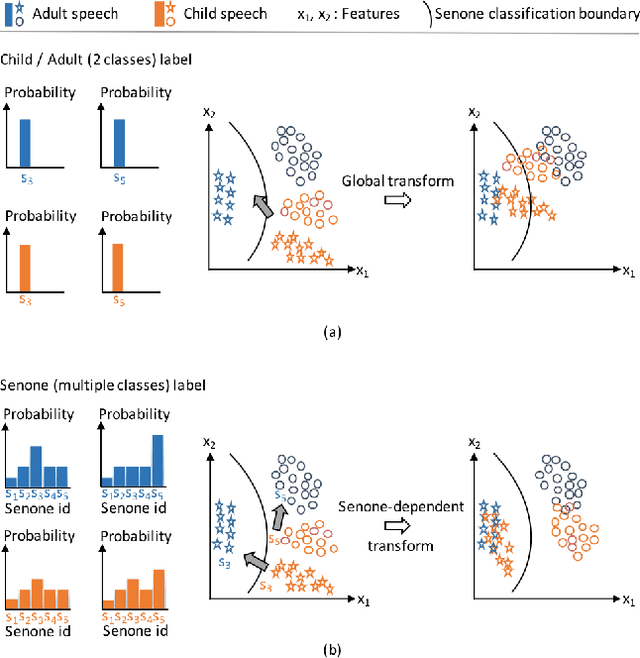
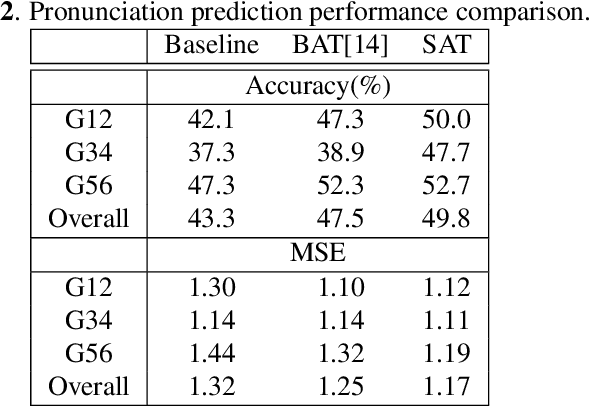
Acoustic modeling for child speech is challenging due to the high acoustic variability caused by physiological differences in the vocal tract. The dearth of publicly available datasets makes the task more challenging. In this work, we propose a feature adaptation approach by exploiting adversarial multi-task training to minimize acoustic mismatch at the senone (tied triphone states) level between adult and child speech and leverage large amounts of transcribed adult speech. We validate the proposed method on three tasks: child speech recognition, child pronunciation assessment, and child fluency score prediction. Empirical results indicate that our proposed approach consistently outperforms competitive baselines, achieving 7.7% relative error reduction on speech recognition and up to 25.2% relative gains on the evaluation tasks.
Revisiting the Boundary between ASR and NLU in the Age of Conversational Dialog Systems
Dec 10, 2021

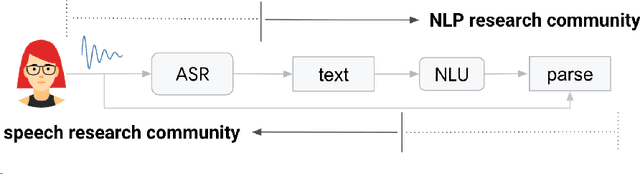
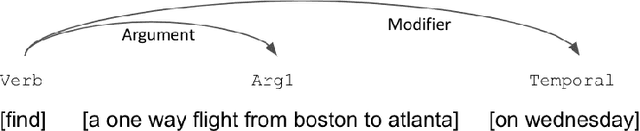
As more users across the world are interacting with dialog agents in their daily life, there is a need for better speech understanding that calls for renewed attention to the dynamics between research in automatic speech recognition (ASR) and natural language understanding (NLU). We briefly review these research areas and lay out the current relationship between them. In light of the observations we make in this paper, we argue that (1) NLU should be cognizant of the presence of ASR models being used upstream in a dialog system's pipeline, (2) ASR should be able to learn from errors found in NLU, (3) there is a need for end-to-end datasets that provide semantic annotations on spoken input, (4) there should be stronger collaboration between ASR and NLU research communities.
CLSRIL-23: Cross Lingual Speech Representations for Indic Languages
Jul 15, 2021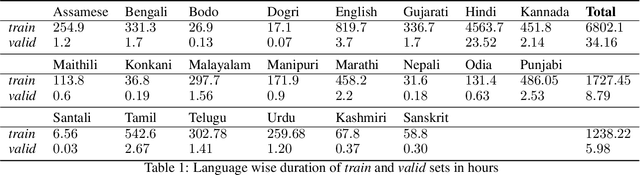
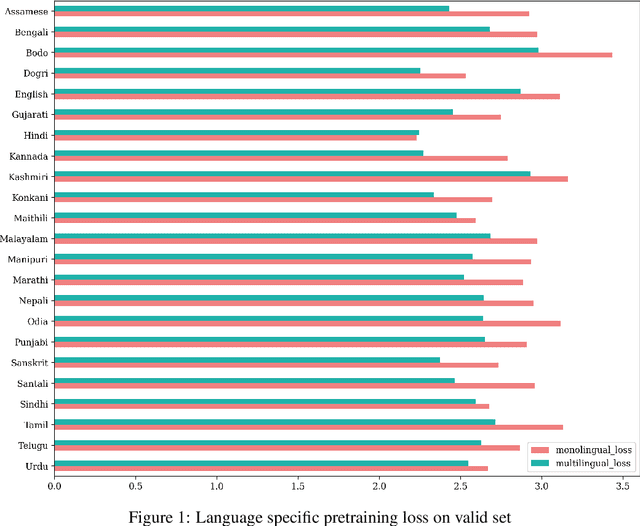
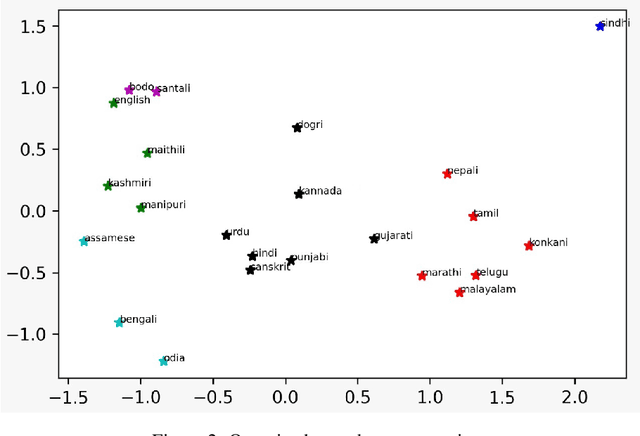

We present a CLSRIL-23, a self supervised learning based audio pre-trained model which learns cross lingual speech representations from raw audio across 23 Indic languages. It is built on top of wav2vec 2.0 which is solved by training a contrastive task over masked latent speech representations and jointly learns the quantization of latents shared across all languages. We compare the language wise loss during pretraining to compare effects of monolingual and multilingual pretraining. Performance on some downstream fine-tuning tasks for speech recognition is also compared and our experiments show that multilingual pretraining outperforms monolingual training, in terms of learning speech representations which encodes phonetic similarity of languages and also in terms of performance on down stream tasks. A decrease of 5% is observed in WER and 9.5% in CER when a multilingual pretrained model is used for finetuning in Hindi. All the code models are also open sourced. CLSRIL-23 is a model trained on $23$ languages and almost 10,000 hours of audio data to facilitate research in speech recognition for Indic languages. We hope that new state of the art systems will be created using the self supervised approach, especially for low resources Indic languages.