 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Imperio: Robust Over-the-Air Adversarial Examples for Automatic Speech Recognition Systems
Sep 09, 2019
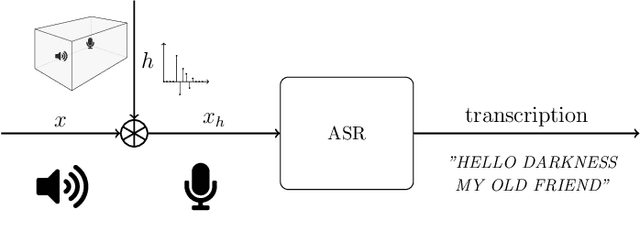
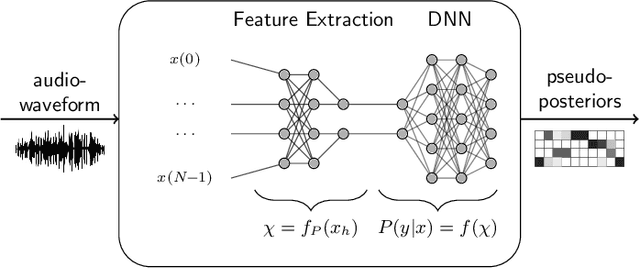
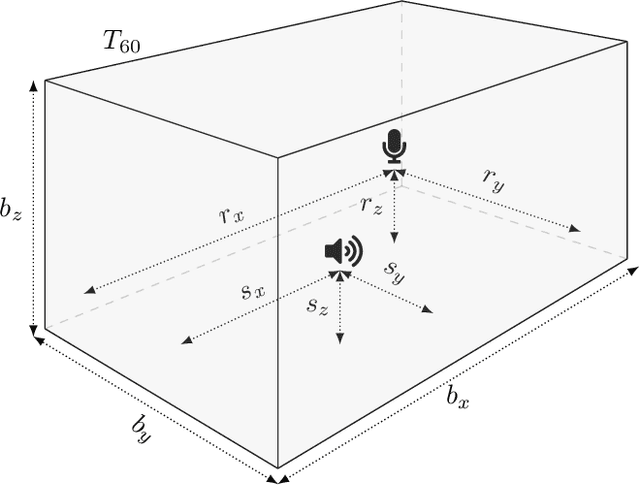
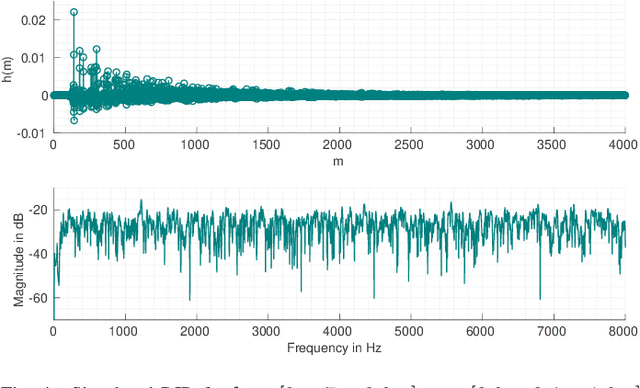
Automatic speech recognition (ASR) systems are possible to fool via targeted adversarial examples. These can induce the ASR to produce arbitrary transcriptions in response to any type of audio signal, be it speech, environmental sounds, or music. However, in general, those adversarial examples did not work in a real-world setup, where the examples are played over the air but have to be fed into the ASR system directly. In some cases, where the adversarial examples could be successfully played over the air, the attacks require precise information about the room where the attack takes place in order to tailor the adversarial examples to a specific setup and are not transferable to other rooms. Other attacks, which are robust in an over-the-air attack, are either handcrafted examples or human listeners can easily recognize the target transcription, once they have been alerted to its content. In this paper, we demonstrate the first generic algorithm that produces adversarial examples which remain robust in an over-the-air attack such that the ASR system transcribes the target transcription after actually being replayed. For the proposed algorithm, guessing a rough approximation of the room characteristics is enough and no actual access to the room is required. We use the ASR system Kaldi to demonstrate the attack and employ a room-impulse-response simulator to harden the adversarial examples against varying room characteristics. Further, the algorithm can also utilize psychoacoustics to hide changes of the original audio signal below the human thresholds of hearing. We show that the adversarial examples work for varying room setups, but also can be tailored to specific room setups. As a result, an attacker can optimize adversarial examples for any target transcription and to arbitrary rooms. Additionally, the adversarial examples remain transferable to varying rooms with a high probability.
End-to-end Adaptation with Backpropagation through WFST for On-device Speech Recognition System
May 17, 2019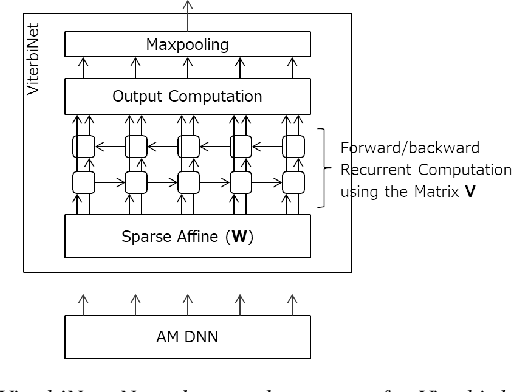
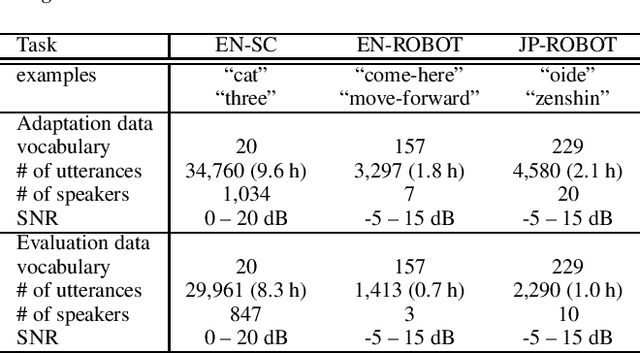
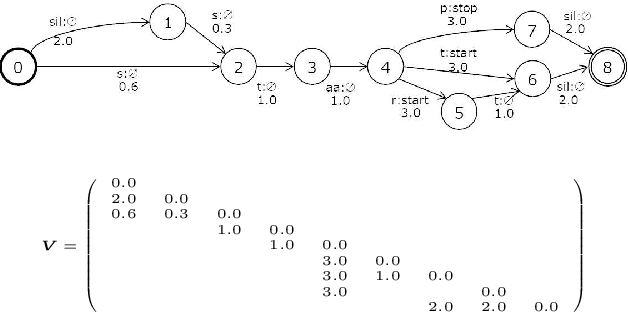
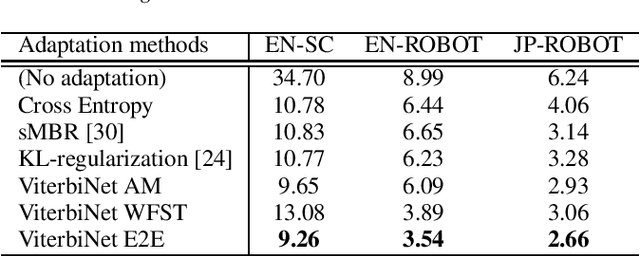
An on-device DNN-HMM speech recognition system efficiently works with a limited vocabulary in the presence of a variety of predictable noise. In such a case, vocabulary and environment adaptation is highly effective. In this paper, we propose a novel method of end-to-end (E2E) adaptation, which adjusts not only an acoustic model (AM) but also a weighted finite-state transducer (WFST). We convert a pretrained WFST to a trainable neural network and adapt the system to target environments/vocabulary by E2E joint training with an AM. We replicate Viterbi decoding with forward--backward neural network computation, which is similar to recurrent neural networks (RNNs). By pooling output score sequences, a vocabulary posterior for each utterance is obtained and used for discriminative loss computation. Experiments using 2--10 hours of English/Japanese adaptation datasets indicate that the fine-tuning of only WFSTs and that of only AMs are both comparable to a state-of-the-art adaptation method, and E2E joint training of the two components achieves the best recognition performance. We also adapt each language system to the other language using the adaptation data, and the results show that the proposed method also works well for language adaptations.
T-NGA: Temporal Network Grafting Algorithm for Learning to Process Spiking Audio Sensor Events
Feb 07, 2022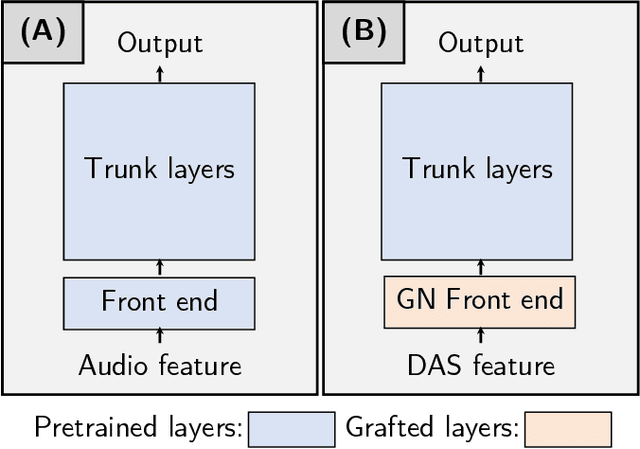
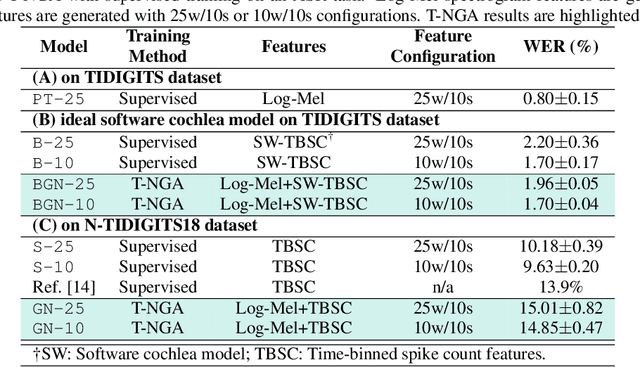
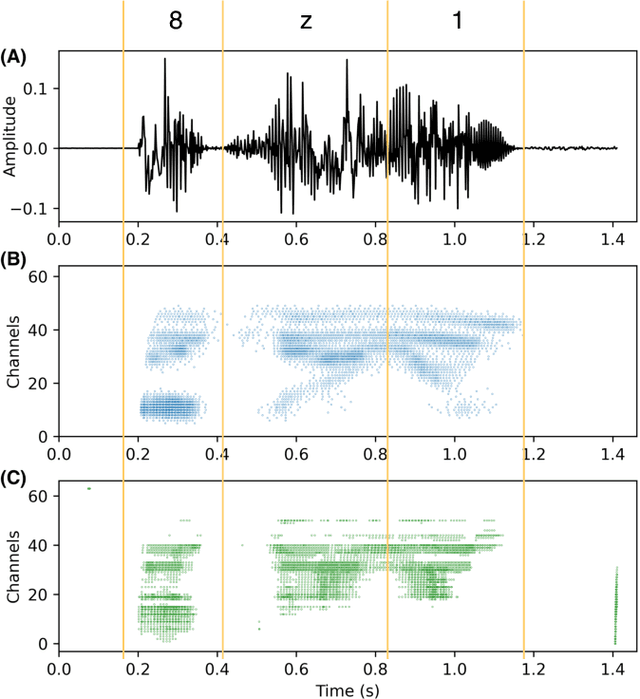

Spiking silicon cochlea sensors encode sound as an asynchronous stream of spikes from different frequency channels. The lack of labeled training datasets for spiking cochleas makes it difficult to train deep neural networks on the outputs of these sensors. This work proposes a self-supervised method called Temporal Network Grafting Algorithm (T-NGA), which grafts a recurrent network pretrained on spectrogram features so that the network works with the cochlea event features. T-NGA training requires only temporally aligned audio spectrograms and event features. Our experiments show that the accuracy of the grafted network was similar to the accuracy of a supervised network trained from scratch on a speech recognition task using events from a software spiking cochlea model. Despite the circuit non-idealities of the spiking silicon cochlea, the grafted network accuracy on the silicon cochlea spike recordings was only about 5% lower than the supervised network accuracy using the N-TIDIGITS18 dataset. T-NGA can train networks to process spiking audio sensor events in the absence of large labeled spike datasets.
Residual Convolutional CTC Networks for Automatic Speech Recognition
Feb 24, 2017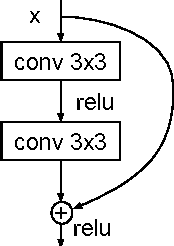

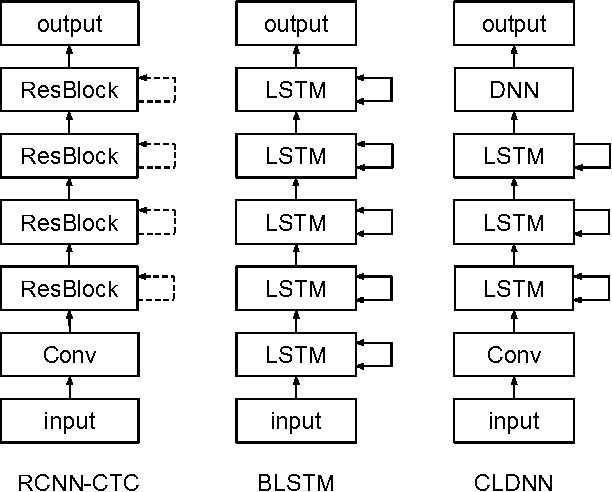
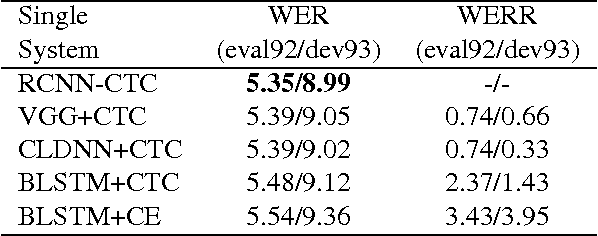
Deep learning approaches have been widely used in Automatic Speech Recognition (ASR) and they have achieved a significant accuracy improvement. Especially, Convolutional Neural Networks (CNNs) have been revisited in ASR recently. However, most CNNs used in existing work have less than 10 layers which may not be deep enough to capture all human speech signal information. In this paper, we propose a novel deep and wide CNN architecture denoted as RCNN-CTC, which has residual connections and Connectionist Temporal Classification (CTC) loss function. RCNN-CTC is an end-to-end system which can exploit temporal and spectral structures of speech signals simultaneously. Furthermore, we introduce a CTC-based system combination, which is different from the conventional frame-wise senone-based one. The basic subsystems adopted in the combination are different types and thus mutually complementary to each other. Experimental results show that our proposed single system RCNN-CTC can achieve the lowest word error rate (WER) on WSJ and Tencent Chat data sets, compared to several widely used neural network systems in ASR. In addition, the proposed system combination can offer a further error reduction on these two data sets, resulting in relative WER reductions of $14.91\%$ and $6.52\%$ on WSJ dev93 and Tencent Chat data sets respectively.
ViDA-MAN: Visual Dialog with Digital Humans
Oct 26, 2021
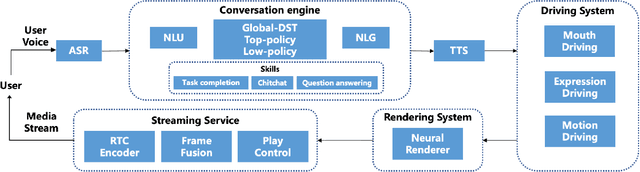
We demonstrate ViDA-MAN, a digital-human agent for multi-modal interaction, which offers realtime audio-visual responses to instant speech inquiries. Compared to traditional text or voice-based system, ViDA-MAN offers human-like interactions (e.g, vivid voice, natural facial expression and body gestures). Given a speech request, the demonstration is able to response with high quality videos in sub-second latency. To deliver immersive user experience, ViDA-MAN seamlessly integrates multi-modal techniques including Acoustic Speech Recognition (ASR), multi-turn dialog, Text To Speech (TTS), talking heads video generation. Backed with large knowledge base, ViDA-MAN is able to chat with users on a number of topics including chit-chat, weather, device control, News recommendations, booking hotels, as well as answering questions via structured knowledge.
Deep transfer learning for partial differential equations under conditional shift with DeepONet
Apr 20, 2022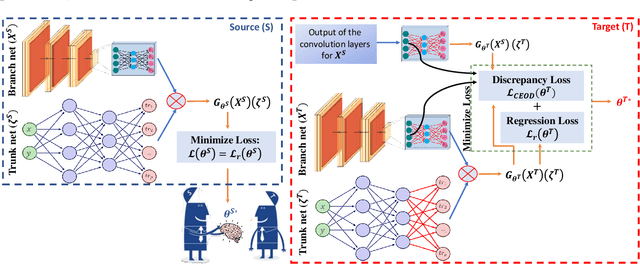
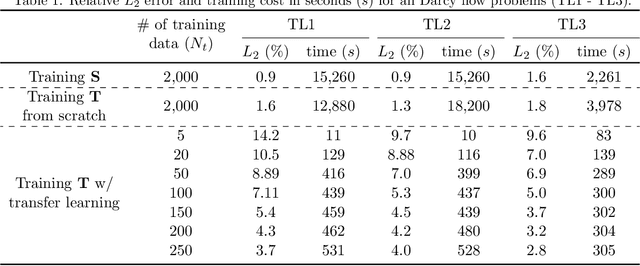
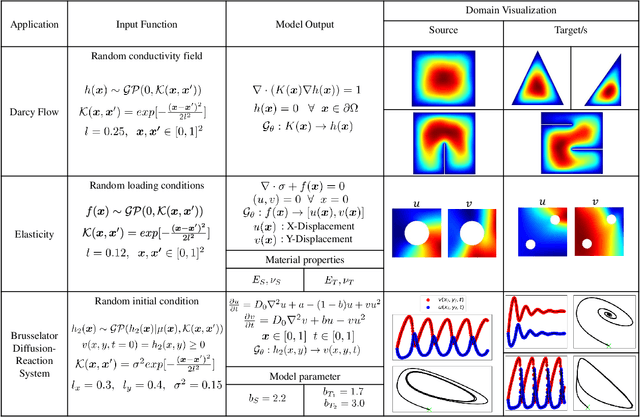
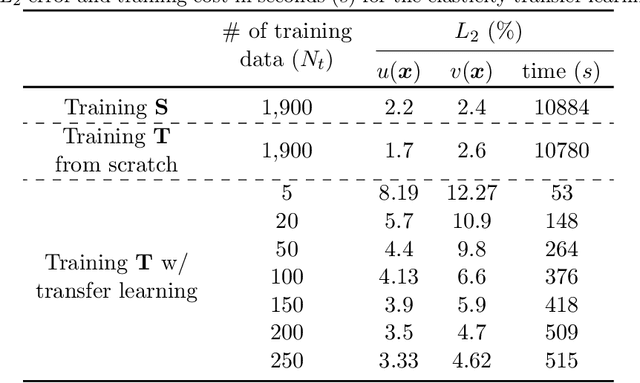
Traditional machine learning algorithms are designed to learn in isolation, i.e. address single tasks. The core idea of transfer learning (TL) is that knowledge gained in learning to perform one task (source) can be leveraged to improve learning performance in a related, but different, task (target). TL leverages and transfers previously acquired knowledge to address the expense of data acquisition and labeling, potential computational power limitations, and the dataset distribution mismatches. Although significant progress has been made in the fields of image processing, speech recognition, and natural language processing (for classification and regression) for TL, little work has been done in the field of scientific machine learning for functional regression and uncertainty quantification in partial differential equations. In this work, we propose a novel TL framework for task-specific learning under conditional shift with a deep operator network (DeepONet). Inspired by the conditional embedding operator theory, we measure the statistical distance between the source domain and the target feature domain by embedding conditional distributions onto a reproducing kernel Hilbert space. Task-specific operator learning is accomplished by fine-tuning task-specific layers of the target DeepONet using a hybrid loss function that allows for the matching of individual target samples while also preserving the global properties of the conditional distribution of target data. We demonstrate the advantages of our approach for various TL scenarios involving nonlinear PDEs under conditional shift. Our results include geometry domain adaptation and show that the proposed TL framework enables fast and efficient multi-task operator learning, despite significant differences between the source and target domains.
Streaming Multi-Talker ASR with Token-Level Serialized Output Training
Feb 05, 2022
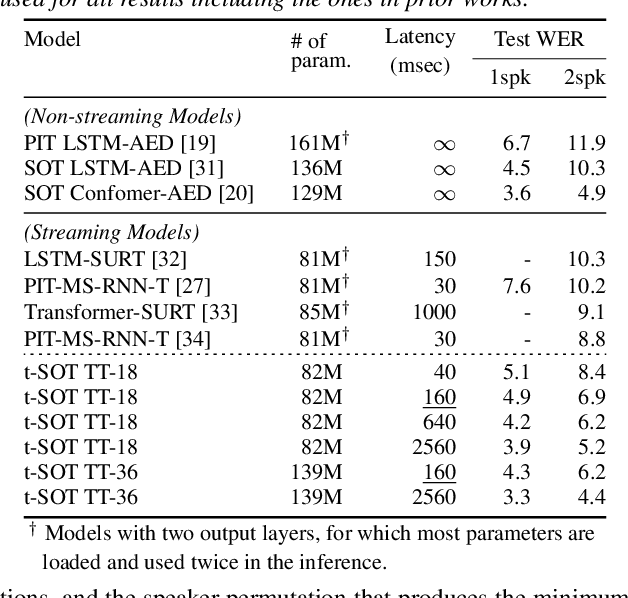
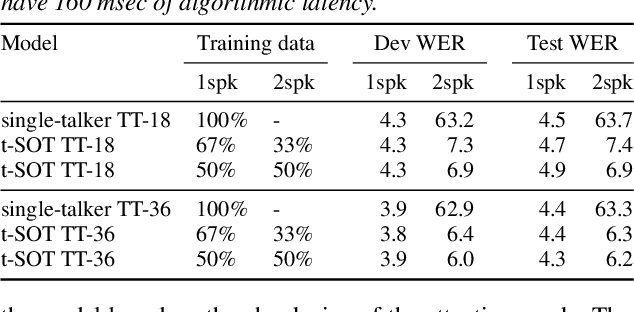
This paper proposes a token-level serialized output training (t-SOT), a novel framework for streaming multi-talker automatic speech recognition (ASR). Unlike existing streaming multi-talker ASR models using multiple output layers, the t-SOT model has only a single output layer that generates recognition tokens (e.g., words, subwords) of multiple speakers in chronological order based on their emission times. A special token that indicates the change of "virtual" output channels is introduced to keep track of the overlapping utterances. Compared to the prior streaming multi-talker ASR models, the t-SOT model has the advantages of less inference cost and a simpler model architecture. Moreover, in our experiments with LibriSpeechMix and LibriCSS datasets, the t-SOT-based transformer transducer model achieves the state-of-the-art word error rates by a significant margin to the prior results. For non-overlapping speech, the t-SOT model is on par with a single-talker ASR model in terms of both accuracy and computational cost, opening the door for deploying one model for both single- and multi-talker scenarios.
Accent Recognition with Hybrid Phonetic Features
May 05, 2021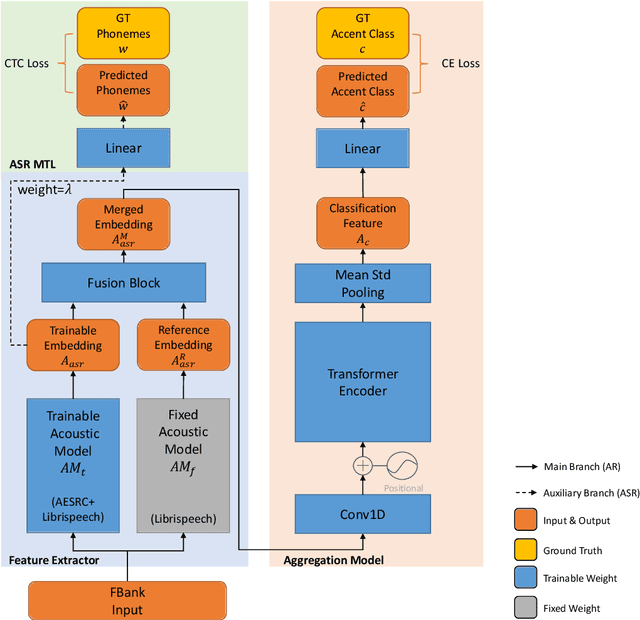

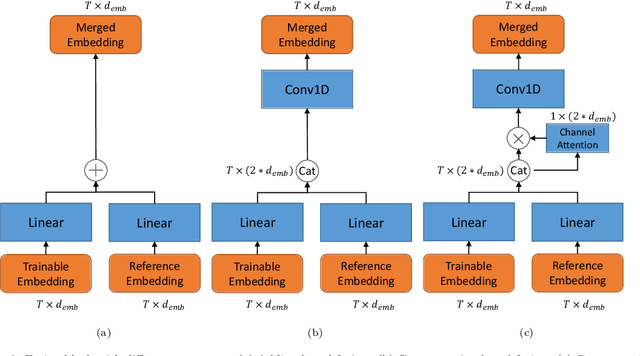
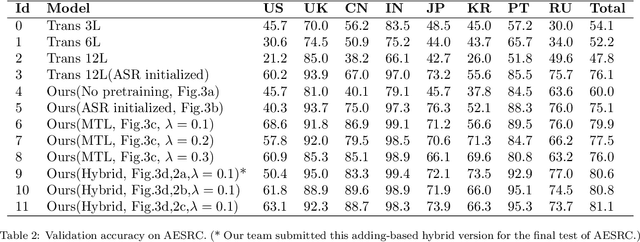
The performance of voice-controlled systems is usually influenced by accented speech. To make these systems more robust, the frontend accent recognition (AR) technologies have received increased attention in recent years. As accent is a high-level abstract feature that has a profound relationship with the language knowledge, AR is more challenging than other language-agnostic audio classification tasks. In this paper, we use an auxiliary automatic speech recognition (ASR) task to extract language-related phonetic features. Furthermore, we propose a hybrid structure that incorporates the embeddings of both a fixed acoustic model and a trainable acoustic model, making the language-related acoustic feature more robust. We conduct several experiments on the Accented English Speech Recognition Challenge (AESRC) 2020 dataset. The results demonstrate that our approach can obtain a 6.57% relative improvement on the validation set. We also get a 7.28% relative improvement on the final test set for this competition, showing the merits of the proposed method.
Revisiting the Boundary between ASR and NLU in the Age of Conversational Dialog Systems
Dec 10, 2021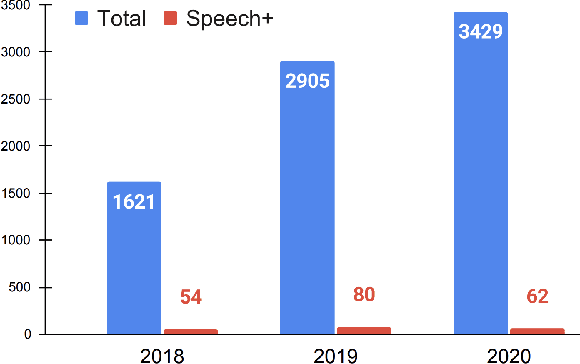

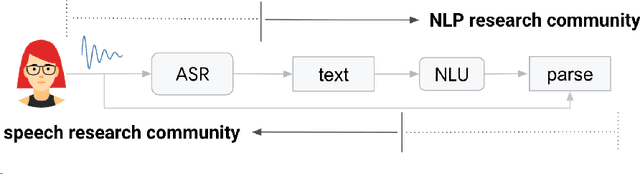
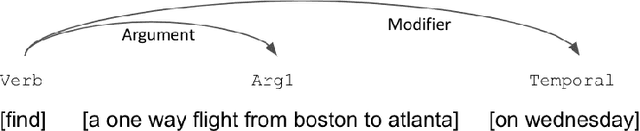
As more users across the world are interacting with dialog agents in their daily life, there is a need for better speech understanding that calls for renewed attention to the dynamics between research in automatic speech recognition (ASR) and natural language understanding (NLU). We briefly review these research areas and lay out the current relationship between them. In light of the observations we make in this paper, we argue that (1) NLU should be cognizant of the presence of ASR models being used upstream in a dialog system's pipeline, (2) ASR should be able to learn from errors found in NLU, (3) there is a need for end-to-end datasets that provide semantic annotations on spoken input, (4) there should be stronger collaboration between ASR and NLU research communities.
Late reverberation suppression using U-nets
Oct 05, 2021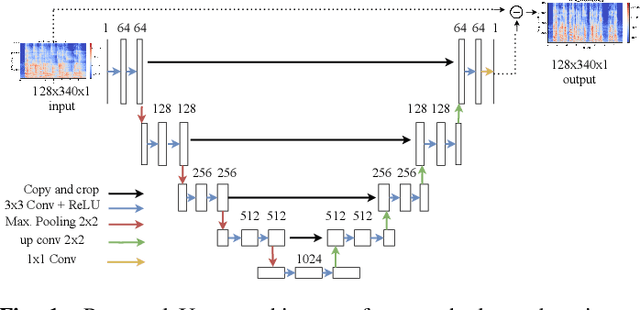
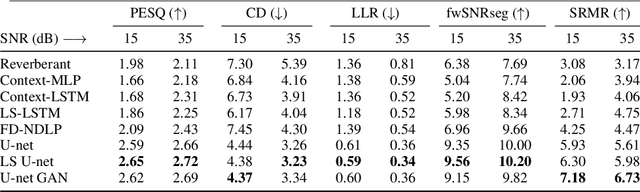
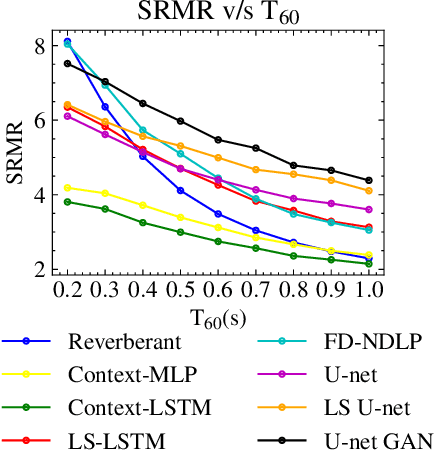
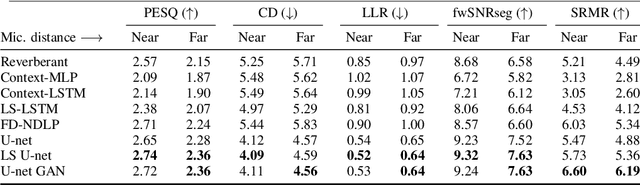
In real-world settings, speech signals are almost always affected by reverberation produced by the working environment; these corrupted signals need to be \emph{dereverberated} prior to performing, e.g., speech recognition, speech-to-text conversion, compression, or general audio enhancement. In this paper, we propose a supervised dereverberation technique using \emph{U-nets with skip connections}, which are fully-convolutional encoder-decoder networks with layers arranged in the form of an "U" and connections that "skip" some layers. Building on this architecture, we address speech dereverberation through the lens of Late Reverberation Suppression (LS). Via experiments on synthetic and real-world data with different noise levels and reverberation settings, we show that our proposed method termed "LS U-net" improves quality, intelligibility and other performance metrics compared to the original U-net method and it is on par with the state-of-the-art GAN-based approaches.