 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
The CUHK-TENCENT speaker diarization system for the ICASSP 2022 multi-channel multi-party meeting transcription challenge
Feb 04, 2022
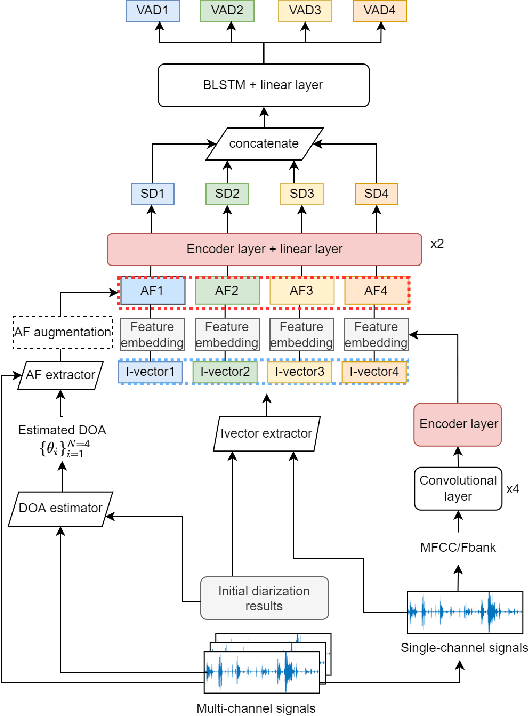
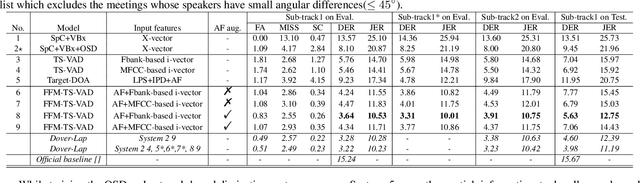
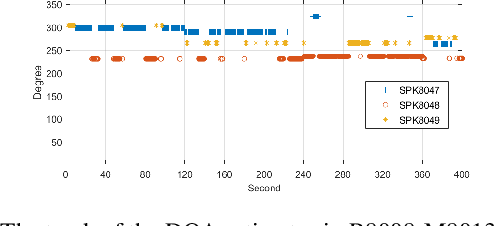
This paper describes our speaker diarization system submitted to the Multi-channel Multi-party Meeting Transcription (M2MeT) challenge, where Mandarin meeting data were recorded in multi-channel format for diarization and automatic speech recognition (ASR) tasks. In these meeting scenarios, the uncertainty of the speaker number and the high ratio of overlapped speech present great challenges for diarization. Based on the assumption that there is valuable complementary information between acoustic features, spatial-related and speaker-related features, we propose a multi-level feature fusion mechanism based target-speaker voice activity detection (FFM-TS-VAD) system to improve the performance of the conventional TS-VAD system. Furthermore, we propose a data augmentation method during training to improve the system robustness when the angular difference between two speakers is relatively small. We provide comparisons for different sub-systems we used in M2MeT challenge. Our submission is a fusion of several sub-systems and ranks second in the diarization task.
Improving Automatic Speech Recognition for Non-Native English with Transfer Learning and Language Model Decoding
Feb 10, 2022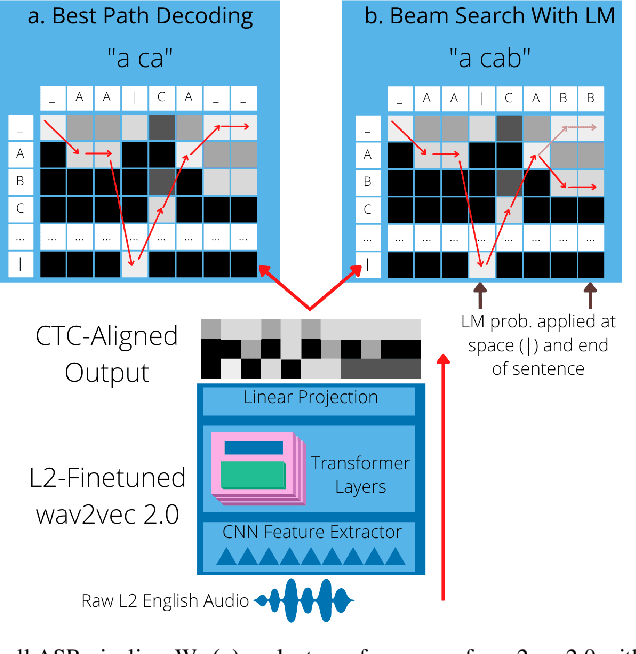

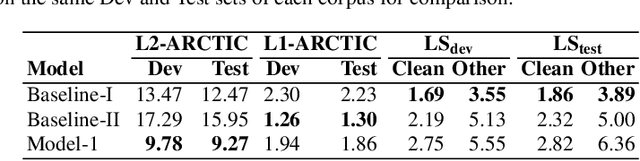
ASR systems designed for native English (L1) usually underperform on non-native English (L2). To address this performance gap, \textbf{(i)} we extend our previous work to investigate fine-tuning of a pre-trained wav2vec 2.0 model \cite{baevski2020wav2vec,xu2021self} under a rich set of L1 and L2 training conditions. We further \textbf{(ii)} incorporate language model decoding in the ASR system, along with the fine-tuning method. Quantifying gains acquired from each of these two approaches separately and an error analysis allows us to identify different sources of improvement within our models. We find that while the large self-trained wav2vec 2.0 may be internalizing sufficient decoding knowledge for clean L1 speech \cite{xu2021self}, this does not hold for L2 speech and accounts for the utility of employing language model decoding on L2 data.
Speech Recognition Front End Without Information Loss
Mar 30, 2015
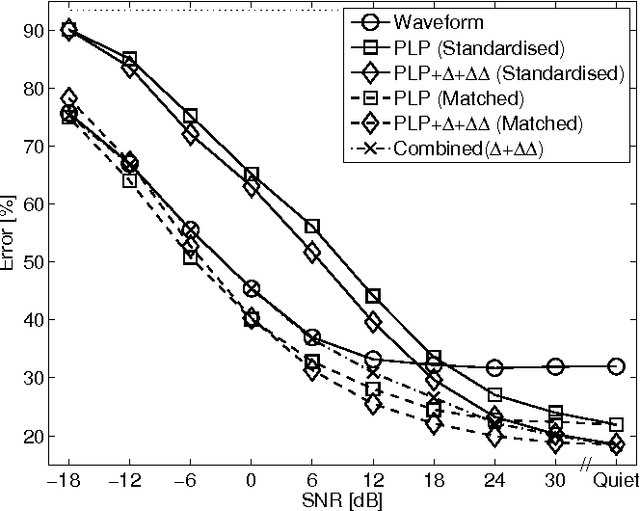
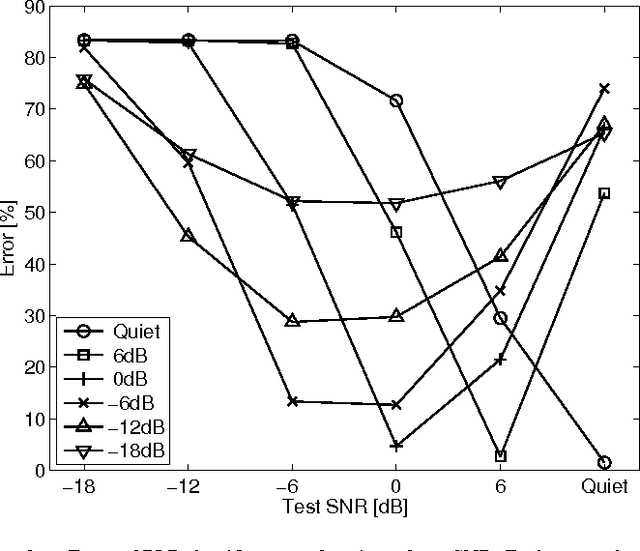
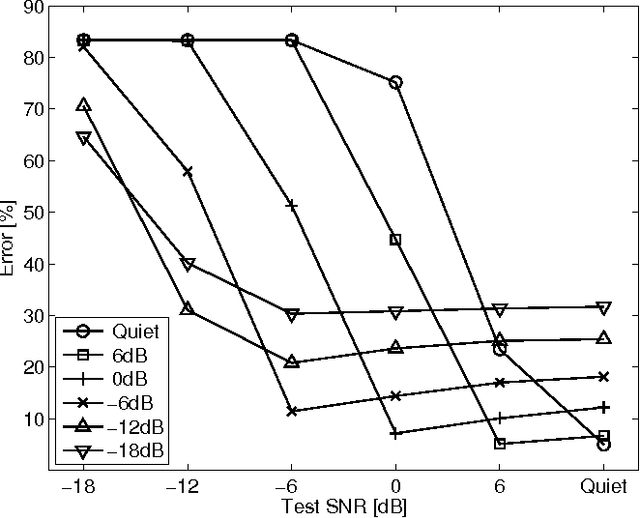
Speech representation and modelling in high-dimensional spaces of acoustic waveforms, or a linear transformation thereof, is investigated with the aim of improving the robustness of automatic speech recognition to additive noise. The motivation behind this approach is twofold: (i) the information in acoustic waveforms that is usually removed in the process of extracting low-dimensional features might aid robust recognition by virtue of structured redundancy analogous to channel coding, (ii) linear feature domains allow for exact noise adaptation, as opposed to representations that involve non-linear processing which makes noise adaptation challenging. Thus, we develop a generative framework for phoneme modelling in high-dimensional linear feature domains, and use it in phoneme classification and recognition tasks. Results show that classification and recognition in this framework perform better than analogous PLP and MFCC classifiers below 18 dB SNR. A combination of the high-dimensional and MFCC features at the likelihood level performs uniformly better than either of the individual representations across all noise levels.
Zero-shot keyword spotting for visual speech recognition in-the-wild
Jul 26, 2018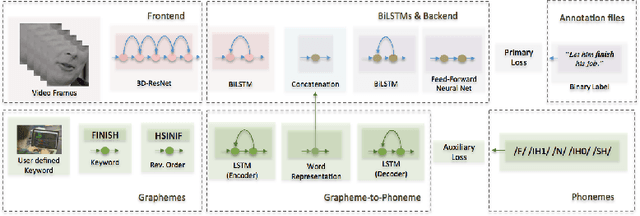
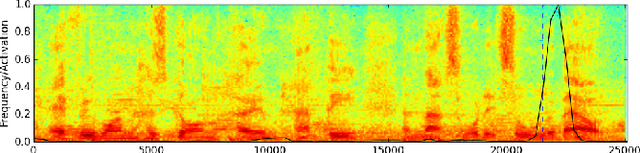
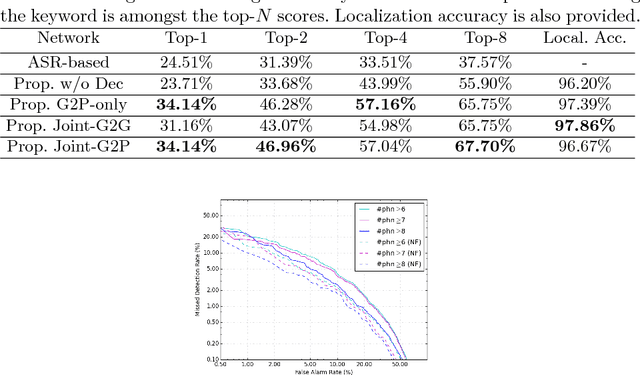
Visual keyword spotting (KWS) is the problem of estimating whether a text query occurs in a given recording using only video information. This paper focuses on visual KWS for words unseen during training, a real-world, practical setting which so far has received no attention by the community. To this end, we devise an end-to-end architecture comprising (a) a state-of-the-art visual feature extractor based on spatiotemporal Residual Networks, (b) a grapheme-to-phoneme model based on sequence-to-sequence neural networks, and (c) a stack of recurrent neural networks which learn how to correlate visual features with the keyword representation. Different to prior works on KWS, which try to learn word representations merely from sequences of graphemes (i.e. letters), we propose the use of a grapheme-to-phoneme encoder-decoder model which learns how to map words to their pronunciation. We demonstrate that our system obtains very promising visual-only KWS results on the challenging LRS2 database, for keywords unseen during training. We also show that our system outperforms a baseline which addresses KWS via automatic speech recognition (ASR), while it drastically improves over other recently proposed ASR-free KWS methods.
Synth2Aug: Cross-domain speaker recognition with TTS synthesized speech
Nov 24, 2020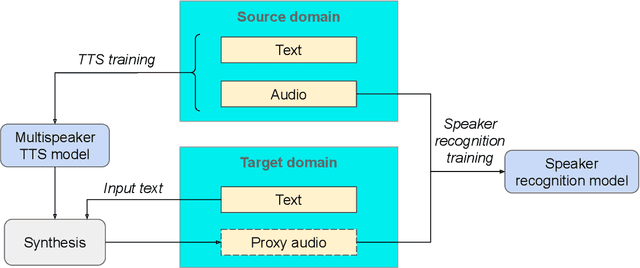
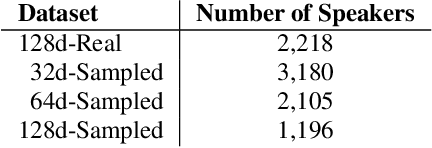
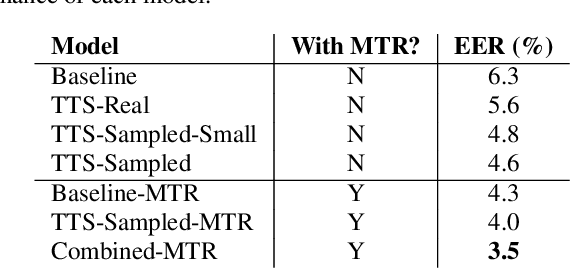
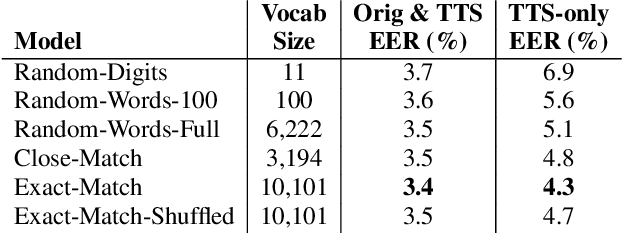
In recent years, Text-To-Speech (TTS) has been used as a data augmentation technique for speech recognition to help complement inadequacies in the training data. Correspondingly, we investigate the use of a multi-speaker TTS system to synthesize speech in support of speaker recognition. In this study we focus the analysis on tasks where a relatively small number of speakers is available for training. We observe on our datasets that TTS synthesized speech improves cross-domain speaker recognition performance and can be combined effectively with multi-style training. Additionally, we explore the effectiveness of different types of text transcripts used for TTS synthesis. Results suggest that matching the textual content of the target domain is a good practice, and if that is not feasible, a transcript with a sufficiently large vocabulary is recommended.
QSpeech: Low-Qubit Quantum Speech Application Toolkit
May 26, 2022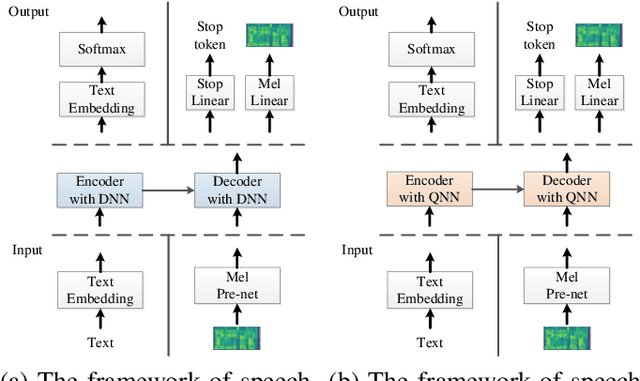
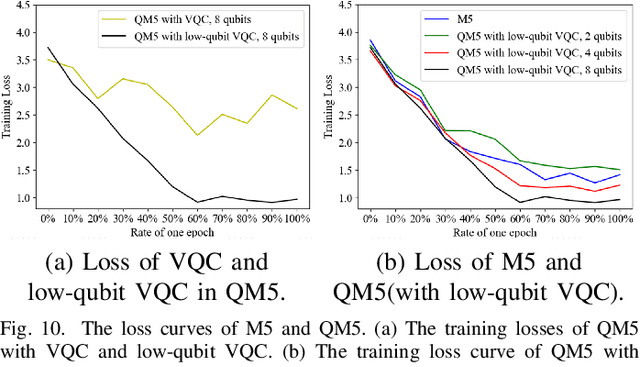
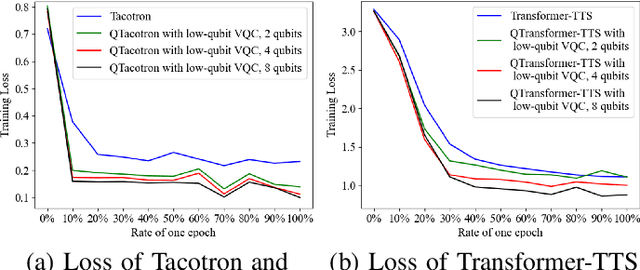
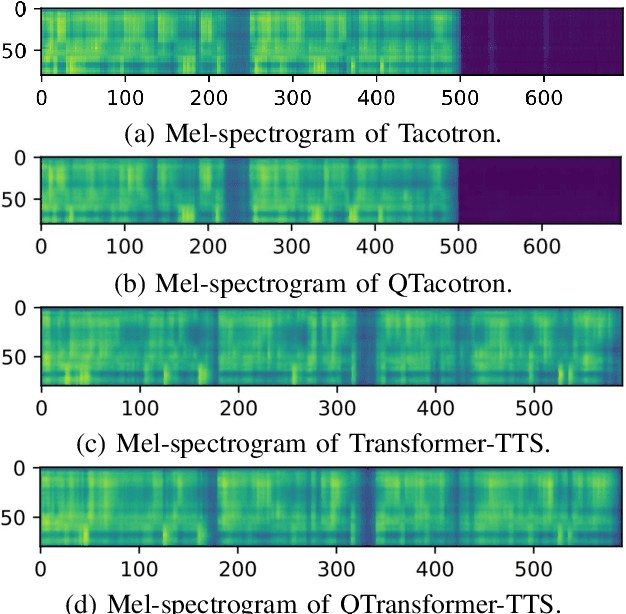
Quantum devices with low qubits are common in the Noisy Intermediate-Scale Quantum (NISQ) era. However, Quantum Neural Network (QNN) running on low-qubit quantum devices would be difficult since it is based on Variational Quantum Circuit (VQC), which requires many qubits. Therefore, it is critical to make QNN with VQC run on low-qubit quantum devices. In this study, we propose a novel VQC called the low-qubit VQC. VQC requires numerous qubits based on the input dimension; however, the low-qubit VQC with linear transformation can liberate this condition. Thus, it allows the QNN to run on low-qubit quantum devices for speech applications. Furthermore, as compared to the VQC, our proposed low-qubit VQC can stabilize the training process more. Based on the low-qubit VQC, we implement QSpeech, a library for quick prototyping of hybrid quantum-classical neural networks in the speech field. It has numerous quantum neural layers and QNN models for speech applications. Experiments on Speech Command Recognition and Text-to-Speech show that our proposed low-qubit VQC outperforms VQC and is more stable.
WERd: Using Social Text Spelling Variants for Evaluating Dialectal Speech Recognition
Sep 21, 2017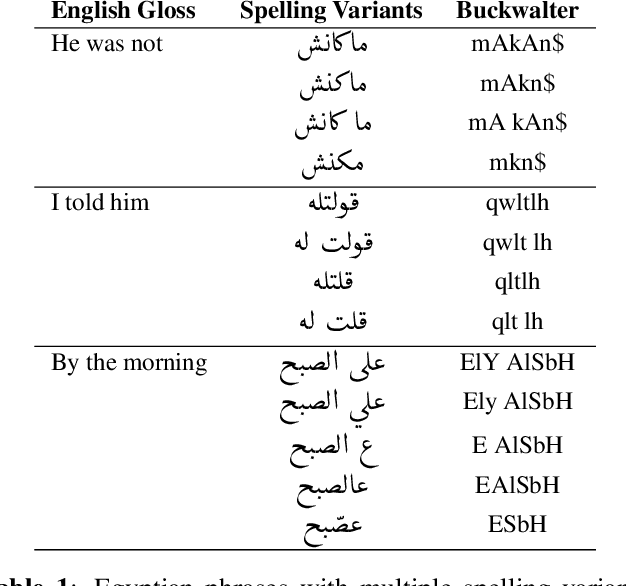
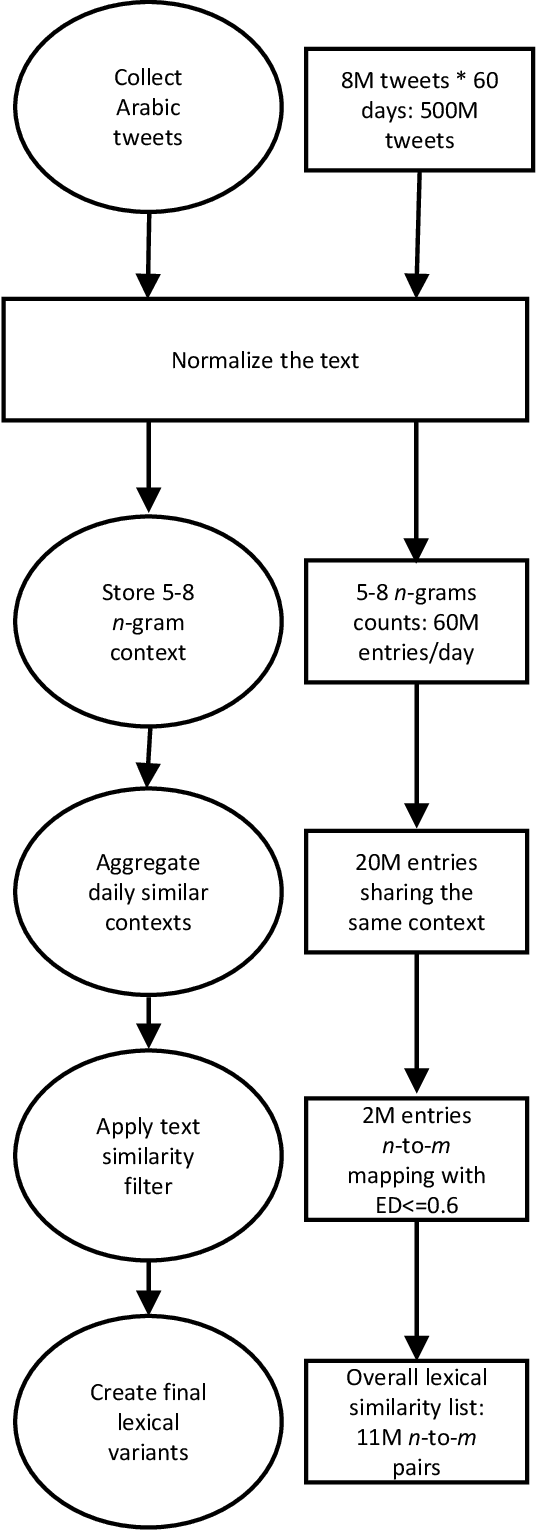
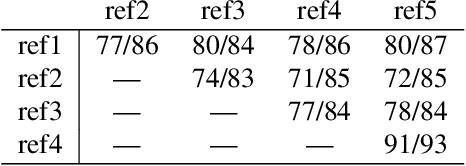
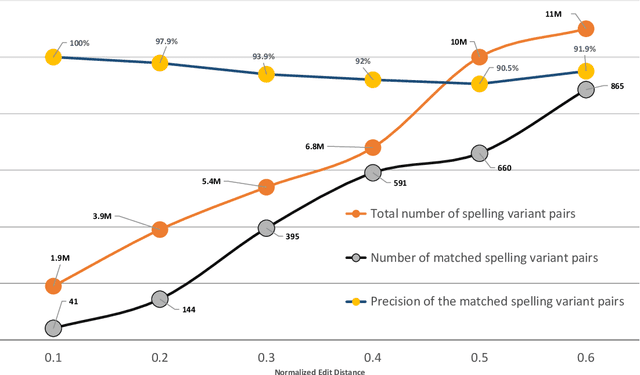
We study the problem of evaluating automatic speech recognition (ASR) systems that target dialectal speech input. A major challenge in this case is that the orthography of dialects is typically not standardized. From an ASR evaluation perspective, this means that there is no clear gold standard for the expected output, and several possible outputs could be considered correct according to different human annotators, which makes standard word error rate (WER) inadequate as an evaluation metric. Such a situation is typical for machine translation (MT), and thus we borrow ideas from an MT evaluation metric, namely TERp, an extension of translation error rate which is closely-related to WER. In particular, in the process of comparing a hypothesis to a reference, we make use of spelling variants for words and phrases, which we mine from Twitter in an unsupervised fashion. Our experiments with evaluating ASR output for Egyptian Arabic, and further manual analysis, show that the resulting WERd (i.e., WER for dialects) metric, a variant of TERp, is more adequate than WER for evaluating dialectal ASR.
Semantic-preserved Communication System for Highly Efficient Speech Transmission
May 25, 2022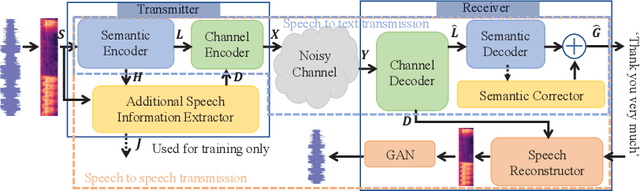
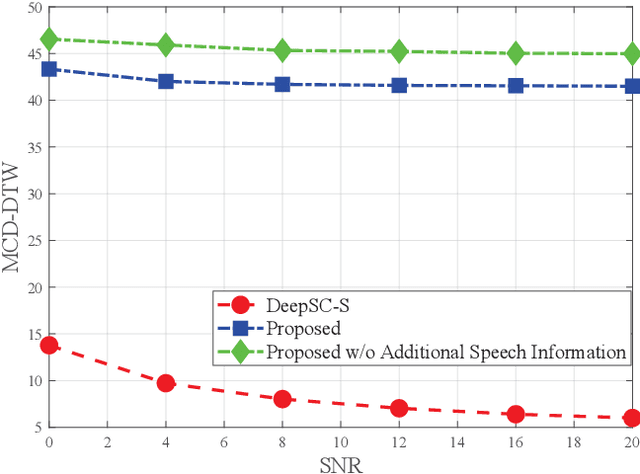
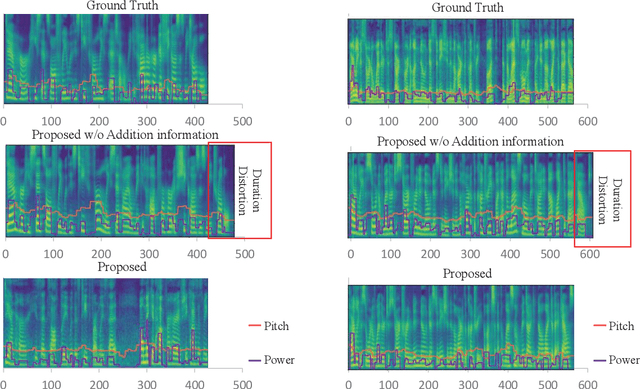
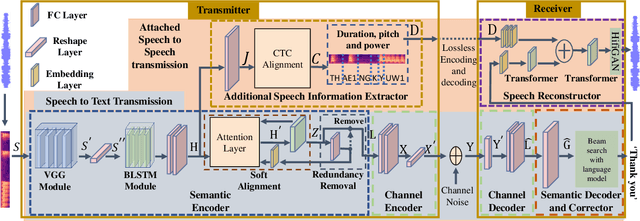
Deep learning (DL) based semantic communication methods have been explored for the efficient transmission of images, text, and speech in recent years. In contrast to traditional wireless communication methods that focus on the transmission of abstract symbols, semantic communication approaches attempt to achieve better transmission efficiency by only sending the semantic-related information of the source data. In this paper, we consider semantic-oriented speech transmission which transmits only the semantic-relevant information over the channel for the speech recognition task, and a compact additional set of semantic-irrelevant information for the speech reconstruction task. We propose a novel end-to-end DL-based transceiver which extracts and encodes the semantic information from the input speech spectrums at the transmitter and outputs the corresponding transcriptions from the decoded semantic information at the receiver. For the speech to speech transmission, we further include a CTC alignment module that extracts a small number of additional semantic-irrelevant but speech-related information for the better reconstruction of the original speech signals at the receiver. The simulation results confirm that our proposed method outperforms current methods in terms of the accuracy of the predicted text for the speech to text transmission and the quality of the recovered speech signals for the speech to speech transmission, and significantly improves transmission efficiency. More specifically, the proposed method only sends 16% of the amount of the transmitted symbols required by the existing methods while achieving about 10% reduction in WER for the speech to text transmission. For the speech to speech transmission, it results in an even more remarkable improvement in terms of transmission efficiency with only 0.2% of the amount of the transmitted symbols required by the existing method.
DUAL: Discrete Spoken Unit Adaptive Learning for Textless Spoken Question Answering
Mar 26, 2022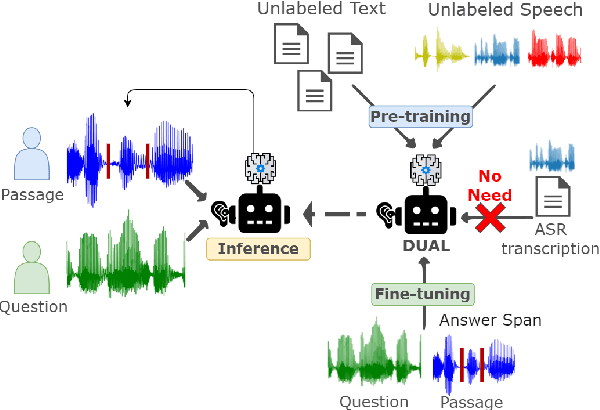
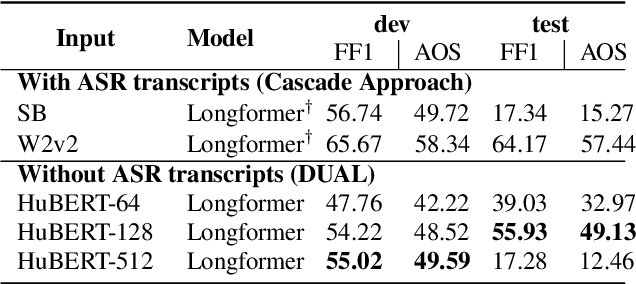
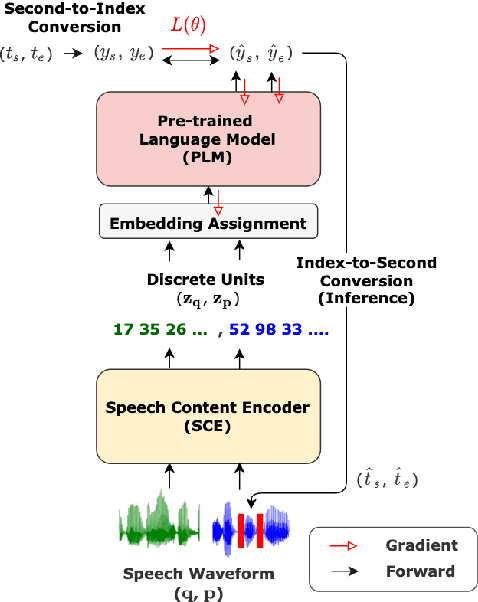
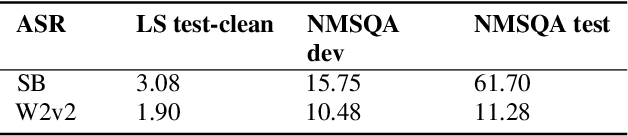
Spoken Question Answering (SQA) is to find the answer from a spoken document given a question, which is crucial for personal assistants when replying to the queries from the users. Existing SQA methods all rely on Automatic Speech Recognition (ASR) transcripts. Not only does ASR need to be trained with massive annotated data that are time and cost-prohibitive to collect for low-resourced languages, but more importantly, very often the answers to the questions include name entities or out-of-vocabulary words that cannot be recognized correctly. Also, ASR aims to minimize recognition errors equally over all words, including many function words irrelevant to the SQA task. Therefore, SQA without ASR transcripts (textless) is always highly desired, although known to be very difficult. This work proposes Discrete Spoken Unit Adaptive Learning (DUAL), leveraging unlabeled data for pre-training and fine-tuned by the SQA downstream task. The time intervals of spoken answers can be directly predicted from spoken documents. We also release a new SQA benchmark corpus, NMSQA, for data with more realistic scenarios. We empirically showed that DUAL yields results comparable to those obtained by cascading ASR and text QA model and robust to real-world data. Our code and model will be open-sourced.
WaBERT: A Low-resource End-to-end Model for Spoken Language Understanding and Speech-to-BERT Alignment
Apr 22, 2022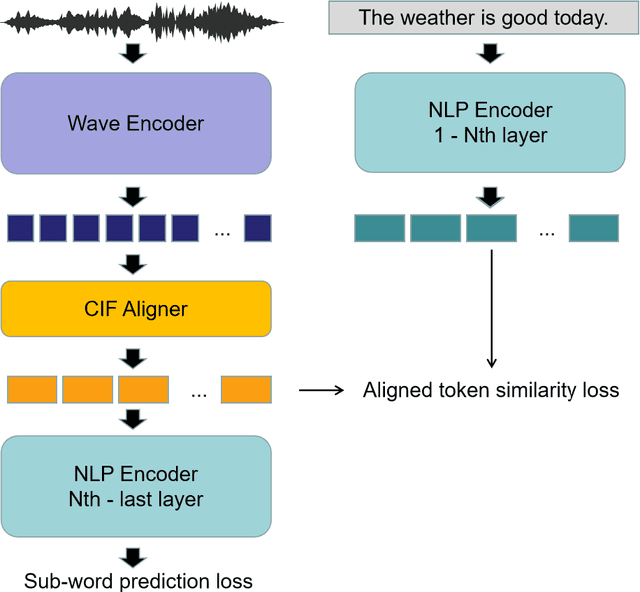


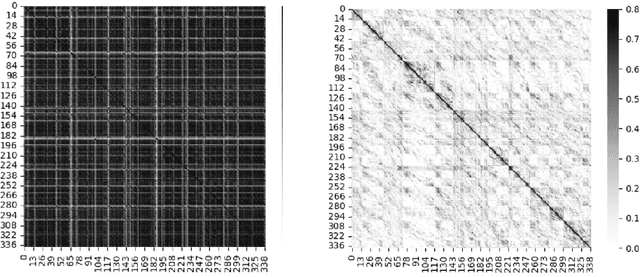
Historically lower-level tasks such as automatic speech recognition (ASR) and speaker identification are the main focus in the speech field. Interest has been growing in higher-level spoken language understanding (SLU) tasks recently, like sentiment analysis (SA). However, improving performances on SLU tasks remains a big challenge. Basically, there are two main methods for SLU tasks: (1) Two-stage method, which uses a speech model to transfer speech to text, then uses a language model to get the results of downstream tasks; (2) One-stage method, which just fine-tunes a pre-trained speech model to fit in the downstream tasks. The first method loses emotional cues such as intonation, and causes recognition errors during ASR process, and the second one lacks necessary language knowledge. In this paper, we propose the Wave BERT (WaBERT), a novel end-to-end model combining the speech model and the language model for SLU tasks. WaBERT is based on the pre-trained speech and language model, hence training from scratch is not needed. We also set most parameters of WaBERT frozen during training. By introducing WaBERT, audio-specific information and language knowledge are integrated in the short-time and low-resource training process to improve results on the dev dataset of SLUE SA tasks by 1.15% of recall score and 0.82% of F1 score. Additionally, we modify the serial Continuous Integrate-and-Fire (CIF) mechanism to achieve the monotonic alignment between the speech and text modalities.