 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Whither the Priors for (Vocal) Interactivity?
Mar 16, 2022
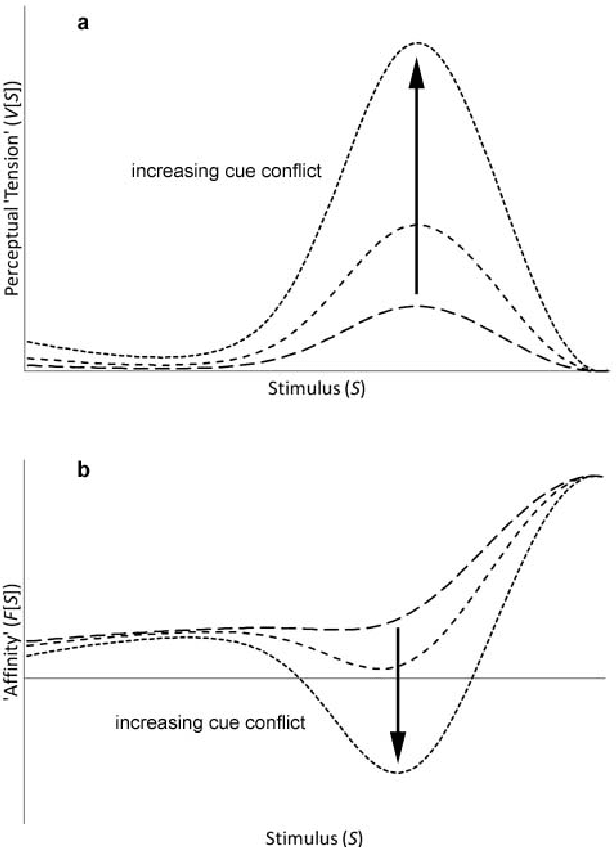
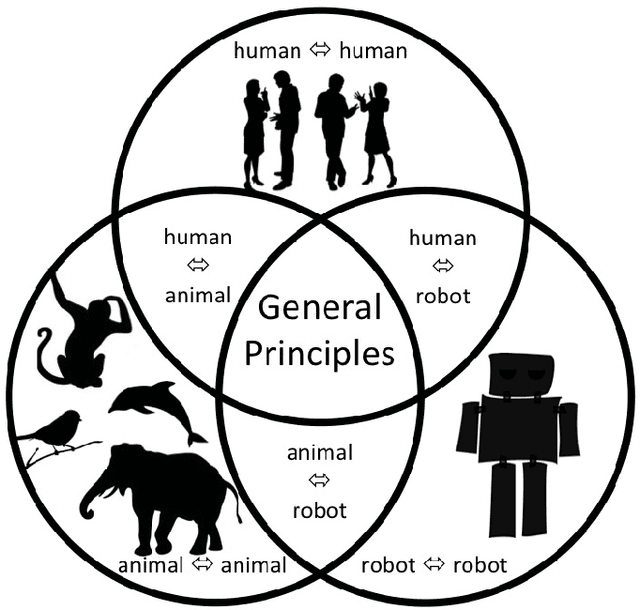
Voice-based communication is often cited as one of the most `natural' ways in which humans and robots might interact, and the recent availability of accurate automatic speech recognition and intelligible speech synthesis has enabled researchers to integrate advanced off-the-shelf spoken language technology components into their robot platforms. Despite this, the resulting interactions are anything but `natural'. It transpires that simply giving a robot a voice doesn't mean that a user will know how (or when) to talk to it, and the resulting `conversations' tend to be stilted, one-sided and short. On the surface, these difficulties might appear to be fairly trivial consequences of users' unfamiliarity with robots (and \emph{vice versa}), and that any problems would be mitigated by long-term use by the human, coupled with `deep learning' by the robot. However, it is argued here that such communication failures are indicative of a deeper malaise: a fundamental lack of basic principles -- \emph{priors} -- underpinning not only speech-based interaction in particular, but (vocal) interactivity in general. This is evidenced not only by the fact that contemporary spoken language systems already require training data sets that are orders-of-magnitude greater than that experienced by a young child, but also by the lack of design principles for creating effective communicative human-robot interaction. This short position paper identifies some of the key areas where theoretical insights might help overcome these shortfalls.
A Multi Purpose and Large Scale Speech Corpus in Persian and English for Speaker and Speech Recognition: the DeepMine Database
Dec 08, 2019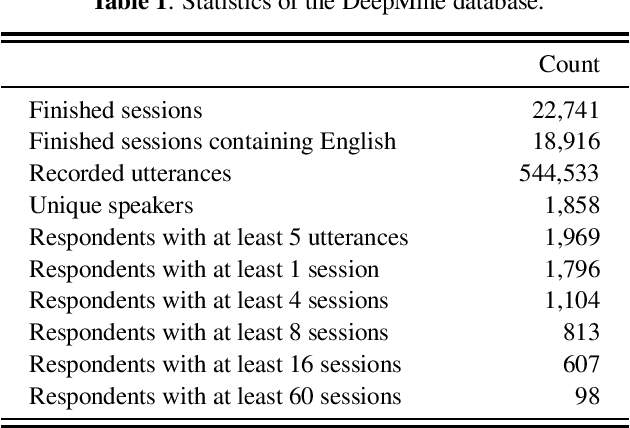

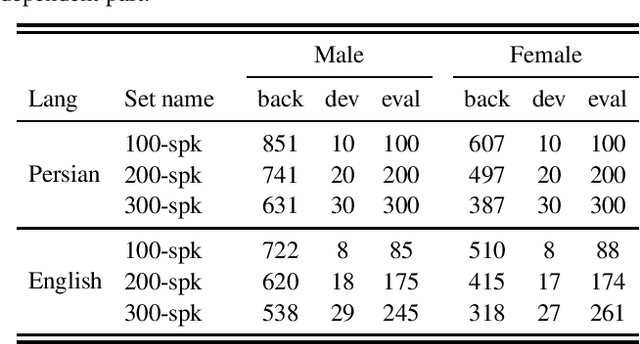
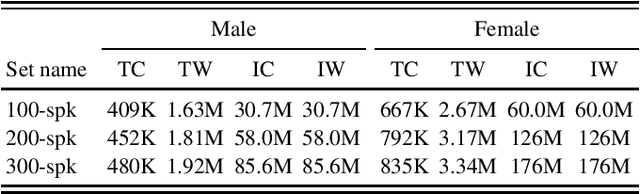
DeepMine is a speech database in Persian and English designed to build and evaluate text-dependent, text-prompted, and text-independent speaker verification, as well as Persian speech recognition systems. It contains more than 1850 speakers and 540 thousand recordings overall, more than 480 hours of speech are transcribed. It is the first public large-scale speaker verification database in Persian, the largest public text-dependent and text-prompted speaker verification database in English, and the largest public evaluation dataset for text-independent speaker verification. It has a good coverage of age, gender, and accents. We provide several evaluation protocols for each part of the database to allow for research on different aspects of speaker verification. We also provide the results of several experiments that can be considered as baselines: HMM-based i-vectors for text-dependent speaker verification, and HMM-based as well as state-of-the-art deep neural network based ASR. We demonstrate that the database can serve for training robust ASR models.
Integrating Text Inputs For Training and Adapting RNN Transducer ASR Models
Feb 26, 2022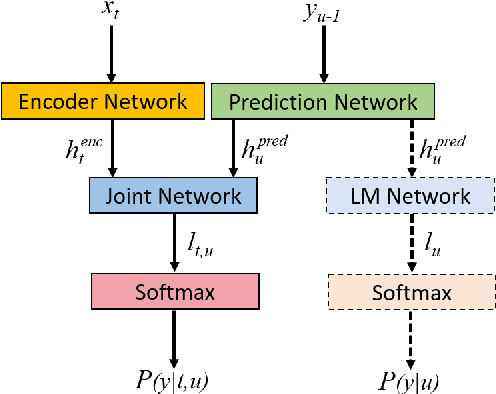
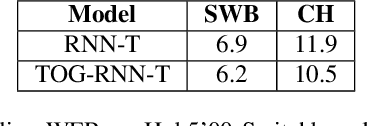
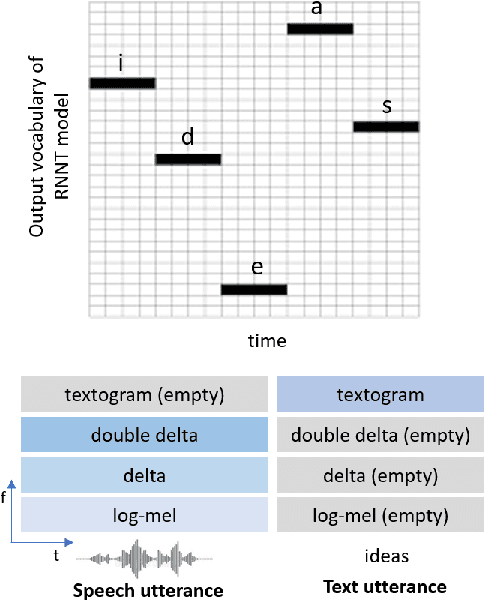
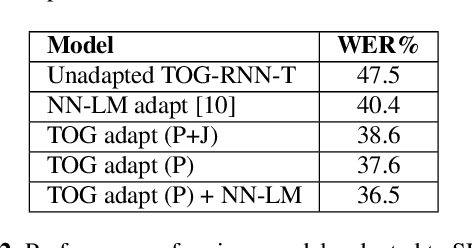
Compared to hybrid automatic speech recognition (ASR) systems that use a modular architecture in which each component can be independently adapted to a new domain, recent end-to-end (E2E) ASR system are harder to customize due to their all-neural monolithic construction. In this paper, we propose a novel text representation and training framework for E2E ASR models. With this approach, we show that a trained RNN Transducer (RNN-T) model's internal LM component can be effectively adapted with text-only data. An RNN-T model trained using both speech and text inputs improves over a baseline model trained on just speech with close to 13% word error rate (WER) reduction on the Switchboard and CallHome test sets of the NIST Hub5 2000 evaluation. The usefulness of the proposed approach is further demonstrated by customizing this general purpose RNN-T model to three separate datasets. We observe 20-45% relative word error rate (WER) reduction in these settings with this novel LM style customization technique using only unpaired text data from the new domains.
SoK: The Faults in our ASRs: An Overview of Attacks against Automatic Speech Recognition and Speaker Identification Systems
Jul 21, 2020
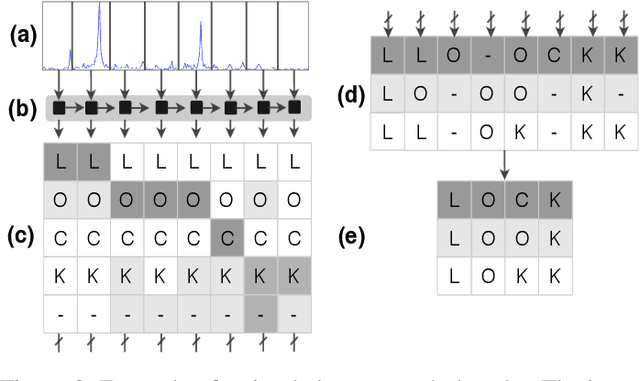
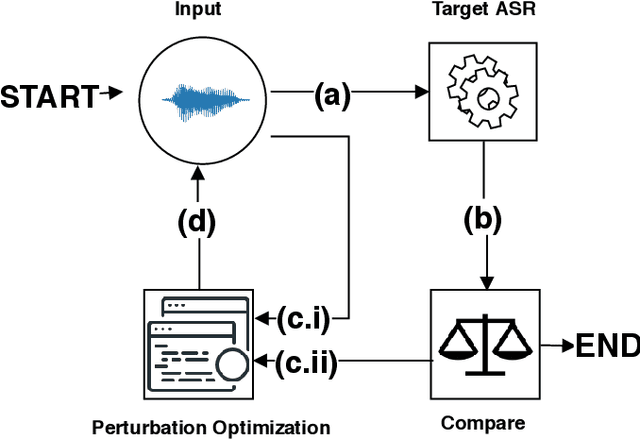
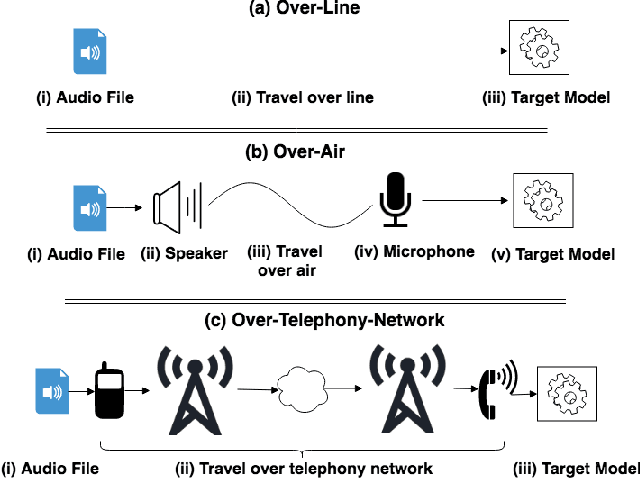
Speech and speaker recognition systems are employed in a variety of applications, from personal assistants to telephony surveillance and biometric authentication. The wide deployment of these systems has been made possible by the improved accuracy in neural networks. Like other systems based on neural networks, recent research has demonstrated that speech and speaker recognition systems are vulnerable to attacks using manipulated inputs. However, as we demonstrate in this paper, the end-to-end architecture of speech and speaker systems and the nature of their inputs make attacks and defenses against them substantially different than those in the image space. We demonstrate this first by systematizing existing research in this space and providing a taxonomy through which the community can evaluate future work. We then demonstrate experimentally that attacks against these models almost universally fail to transfer. In so doing, we argue that substantial additional work is required to provide adequate mitigations in this space.
Tied Probabilistic Linear Discriminant Analysis for Speech Recognition
Nov 04, 2014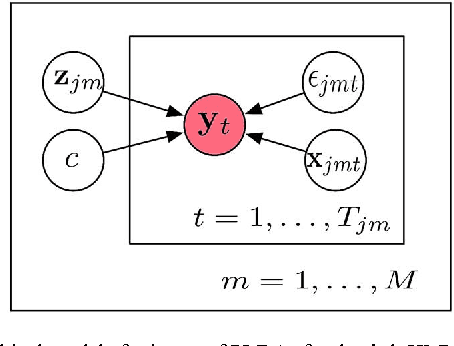
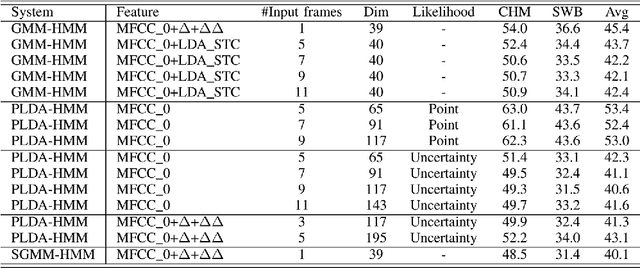
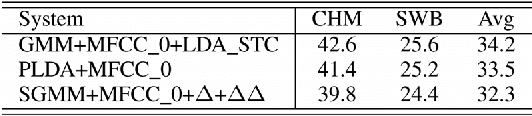
Acoustic models using probabilistic linear discriminant analysis (PLDA) capture the correlations within feature vectors using subspaces which do not vastly expand the model. This allows high dimensional and correlated feature spaces to be used, without requiring the estimation of multiple high dimension covariance matrices. In this letter we extend the recently presented PLDA mixture model for speech recognition through a tied PLDA approach, which is better able to control the model size to avoid overfitting. We carried out experiments using the Switchboard corpus, with both mel frequency cepstral coefficient features and bottleneck feature derived from a deep neural network. Reductions in word error rate were obtained by using tied PLDA, compared with the PLDA mixture model, subspace Gaussian mixture models, and deep neural networks.
State-of-the-Art Speech Recognition Using Multi-Stream Self-Attention With Dilated 1D Convolutions
Oct 01, 2019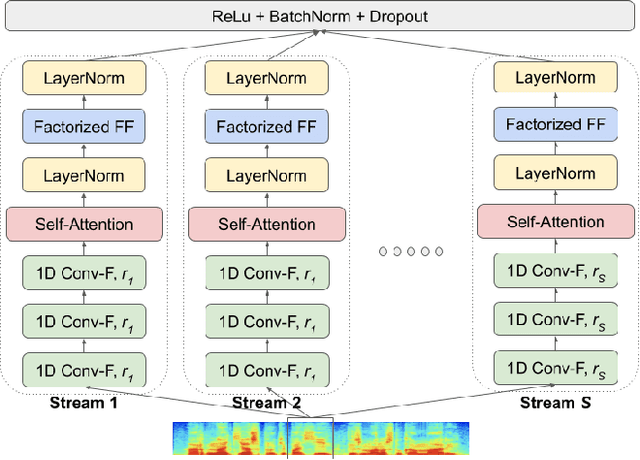
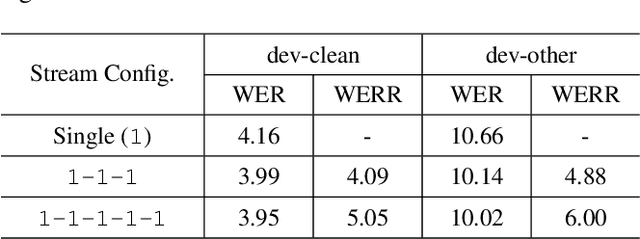
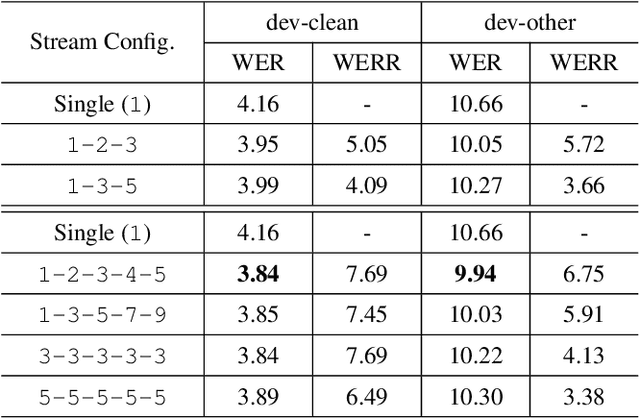
Self-attention has been a huge success for many downstream tasks in NLP, which led to exploration of applying self-attention to speech problems as well. The efficacy of self-attention in speech applications, however, seems not fully blown yet since it is challenging to handle highly correlated speech frames in the context of self-attention. In this paper we propose a new neural network model architecture, namely multi-stream self-attention, to address the issue thus make the self-attention mechanism more effective for speech recognition. The proposed model architecture consists of parallel streams of self-attention encoders, and each stream has layers of 1D convolutions with dilated kernels whose dilation rates are unique given stream, followed by a self-attention layer. The self-attention mechanism in each stream pays attention to only one resolution of input speech frames and the attentive computation can be more efficient. In a later stage, outputs from all the streams are concatenated then linearly projected to the final embedding. By stacking the proposed multi-stream self-attention encoder blocks and rescoring the resultant lattices with neural network language models, we achieve the word error rate of 2.2% on the test-clean dataset of the LibriSpeech corpus, the best number reported thus far on the dataset.
OLR 2021 Challenge: Datasets, Rules and Baselines
Jul 23, 2021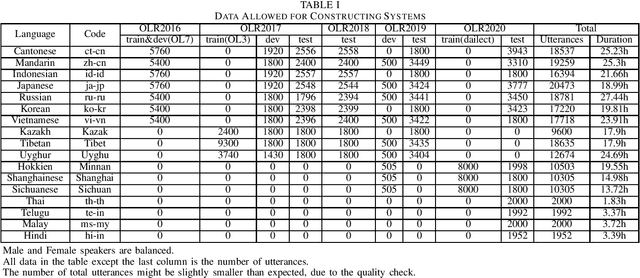

This paper introduces the sixth Oriental Language Recognition (OLR) 2021 Challenge, which intends to improve the performance of language recognition systems and speech recognition systems within multilingual scenarios. The data profile, four tasks, two baselines, and the evaluation principles are introduced in this paper. In addition to the Language Identification (LID) tasks, multilingual Automatic Speech Recognition (ASR) tasks are introduced to OLR 2021 Challenge for the first time. The challenge this year focuses on more practical and challenging problems, with four tasks: (1) constrained LID, (2) unconstrained LID, (3) constrained multilingual ASR, (4) unconstrained multilingual ASR. Baselines for LID tasks and multilingual ASR tasks are provided, respectively. The LID baseline system is an extended TDNN x-vector model constructed with Pytorch. A transformer-based end-to-end model is provided as the multilingual ASR baseline system. These recipes will be online published, and available for participants to construct their own LID or ASR systems. The baseline results demonstrate that those tasks are rather challenging and deserve more effort to achieve better performance.
Twitter Dataset on the Russo-Ukrainian War
Apr 07, 2022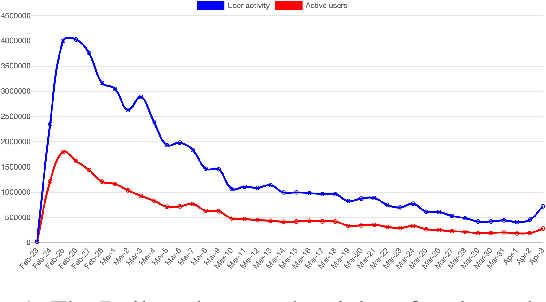
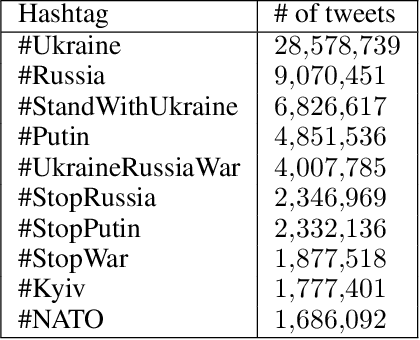
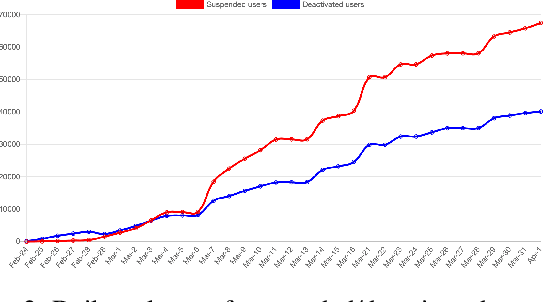
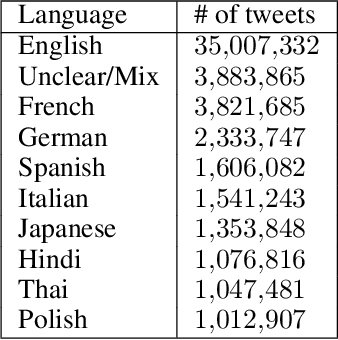
On 24 February 2022, Russia invaded Ukraine, also known now as Russo-Ukrainian War. We have initiated an ongoing dataset acquisition from Twitter API. Until the day this paper was written the dataset has reached the amount of 57.3 million tweets, originating from 7.7 million users. We apply an initial volume and sentiment analysis, while the dataset can be used to further exploratory investigation towards topic analysis, hate speech, propaganda recognition, or even show potential malicious entities like botnets.
Where are we in semantic concept extraction for Spoken Language Understanding?
Jun 24, 2021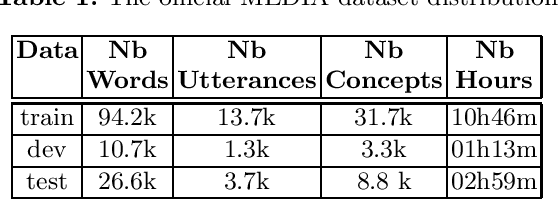


Spoken language understanding (SLU) topic has seen a lot of progress these last three years, with the emergence of end-to-end neural approaches. Spoken language understanding refers to natural language processing tasks related to semantic extraction from speech signal, like named entity recognition from speech or slot filling task in a context of human-machine dialogue. Classically, SLU tasks were processed through a cascade approach that consists in applying, firstly, an automatic speech recognition process, followed by a natural language processing module applied to the automatic transcriptions. These three last years, end-to-end neural approaches, based on deep neural networks, have been proposed in order to directly extract the semantics from speech signal, by using a single neural model. More recent works on self-supervised training with unlabeled data open new perspectives in term of performance for automatic speech recognition and natural language processing. In this paper, we present a brief overview of the recent advances on the French MEDIA benchmark dataset for SLU, with or without the use of additional data. We also present our last results that significantly outperform the current state-of-the-art with a Concept Error Rate (CER) of 11.2%, instead of 13.6% for the last state-of-the-art system presented this year.