 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Conversational Speech Recognition by Learning Audio-textual Cross-modal Contextual Representation
Oct 22, 2023
Automatic Speech Recognition (ASR) in conversational settings presents unique challenges, including extracting relevant contextual information from previous conversational turns. Due to irrelevant content, error propagation, and redundancy, existing methods struggle to extract longer and more effective contexts. To address this issue, we introduce a novel Conversational ASR system, extending the Conformer encoder-decoder model with cross-modal conversational representation. Our approach leverages a cross-modal extractor that combines pre-trained speech and text models through a specialized encoder and a modal-level mask input. This enables the extraction of richer historical speech context without explicit error propagation. We also incorporate conditional latent variational modules to learn conversational level attributes such as role preference and topic coherence. By introducing both cross-modal and conversational representations into the decoder, our model retains context over longer sentences without information loss, achieving relative accuracy improvements of 8.8% and 23% on Mandarin conversation datasets HKUST and MagicData-RAMC, respectively, compared to the standard Conformer model.
TorchAudio 2.1: Advancing speech recognition, self-supervised learning, and audio processing components for PyTorch
Oct 27, 2023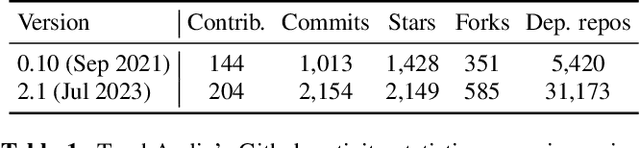


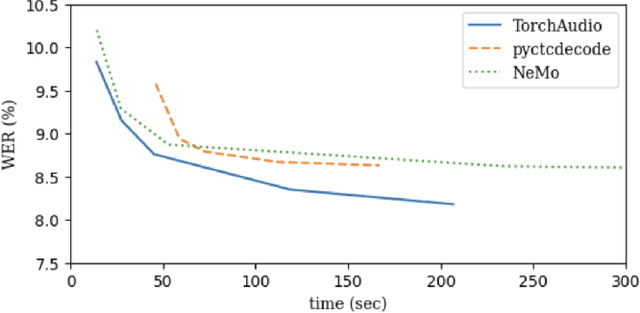
TorchAudio is an open-source audio and speech processing library built for PyTorch. It aims to accelerate the research and development of audio and speech technologies by providing well-designed, easy-to-use, and performant PyTorch components. Its contributors routinely engage with users to understand their needs and fulfill them by developing impactful features. Here, we survey TorchAudio's development principles and contents and highlight key features we include in its latest version (2.1): self-supervised learning pre-trained pipelines and training recipes, high-performance CTC decoders, speech recognition models and training recipes, advanced media I/O capabilities, and tools for performing forced alignment, multi-channel speech enhancement, and reference-less speech assessment. For a selection of these features, through empirical studies, we demonstrate their efficacy and show that they achieve competitive or state-of-the-art performance.
Decoupling and Interacting Multi-Task Learning Network for Joint Speech and Accent Recognition
Nov 17, 2023Accents, as variations from standard pronunciation, pose significant challenges for speech recognition systems. Although joint automatic speech recognition (ASR) and accent recognition (AR) training has been proven effective in handling multi-accent scenarios, current multi-task ASR-AR approaches overlook the granularity differences between tasks. Fine-grained units capture pronunciation-related accent characteristics, while coarse-grained units are better for learning linguistic information. Moreover, an explicit interaction of two tasks can also provide complementary information and improve the performance of each other, but it is rarely used by existing approaches. In this paper, we propose a novel Decoupling and Interacting Multi-task Network (DIMNet) for joint speech and accent recognition, which is comprised of a connectionist temporal classification (CTC) branch, an AR branch, an ASR branch, and a bottom feature encoder. Specifically, AR and ASR are first decoupled by separated branches and two-granular modeling units to learn task-specific representations. The AR branch is from our previously proposed linguistic-acoustic bimodal AR model and the ASR branch is an encoder-decoder based Conformer model. Then, for the task interaction, the CTC branch provides aligned text for the AR task, while accent embeddings extracted from our AR model are incorporated into the ASR branch's encoder and decoder. Finally, during ASR inference, a cross-granular rescoring method is introduced to fuse the complementary information from the CTC and attention decoder after the decoupling. Our experiments on English and Chinese datasets demonstrate the effectiveness of the proposed model, which achieves 21.45%/28.53% AR accuracy relative improvement and 32.33%/14.55% ASR error rate relative reduction over a published standard baseline, respectively.
TemporalAugmenter: An Ensemble Recurrent Based Deep Learning Approach for Signal Classification
Jan 13, 2024Ensemble modeling has been widely used to solve complex problems as it helps to improve overall performance and generalization. In this paper, we propose a novel TemporalAugmenter approach based on ensemble modeling for augmenting the temporal information capturing for long-term and short-term dependencies in data integration of two variations of recurrent neural networks in two learning streams to obtain the maximum possible temporal extraction. Thus, the proposed model augments the extraction of temporal dependencies. In addition, the proposed approach reduces the preprocessing and prior stages of feature extraction, which reduces the required energy to process the models built upon the proposed TemporalAugmenter approach, contributing towards green AI. Moreover, the proposed model can be simply integrated into various domains including industrial, medical, and human-computer interaction applications. Our proposed approach empirically evaluated the speech emotion recognition, electrocardiogram signal, and signal quality examination tasks as three different signals with varying complexity and different temporal dependency features.
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 14, 2023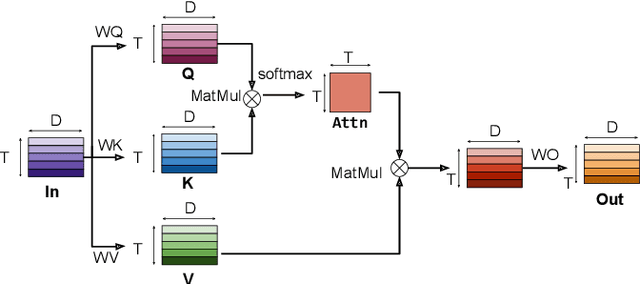
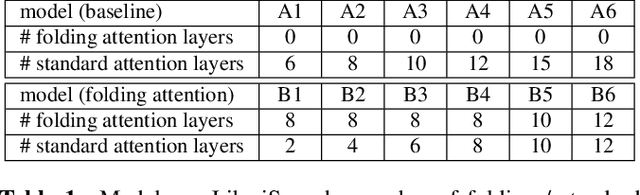
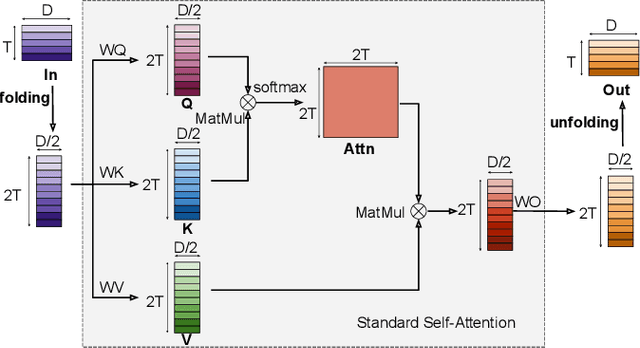
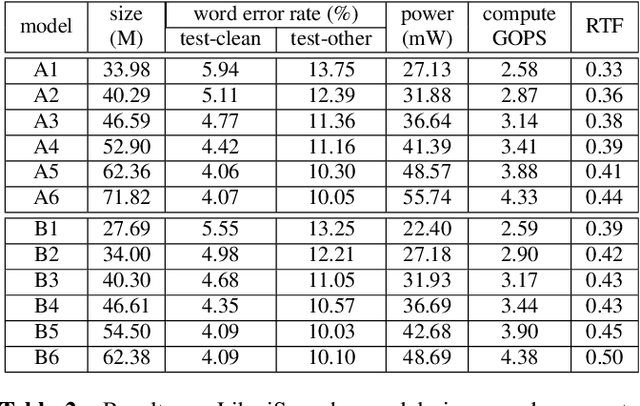
Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
Generative Context-aware Fine-tuning of Self-supervised Speech Models
Dec 15, 2023When performing tasks like automatic speech recognition or spoken language understanding for a given utterance, access to preceding text or audio provides contextual information can improve performance. Considering the recent advances in generative large language models (LLM), we hypothesize that an LLM could generate useful context information using the preceding text. With appropriate prompts, LLM could generate a prediction of the next sentence or abstractive text like titles or topics. In this paper, we study the use of LLM-generated context information and propose an approach to distill the generated information during fine-tuning of self-supervised speech models, which we refer to as generative context-aware fine-tuning. This approach allows the fine-tuned model to make improved predictions without access to the true surrounding segments or to the LLM at inference time, while requiring only a very small additional context module. We evaluate the proposed approach using the SLUE and Libri-light benchmarks for several downstream tasks: automatic speech recognition, named entity recognition, and sentiment analysis. The results show that generative context-aware fine-tuning outperforms a context injection fine-tuning approach that accesses the ground-truth previous text, and is competitive with a generative context injection fine-tuning approach that requires the LLM at inference time.
Neural Language Model Pruning for Automatic Speech Recognition
Oct 05, 2023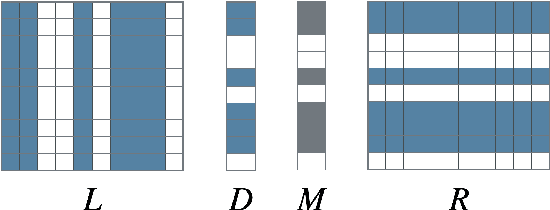
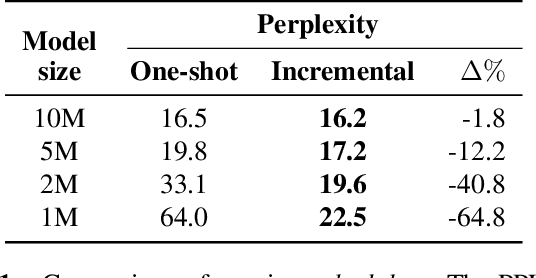
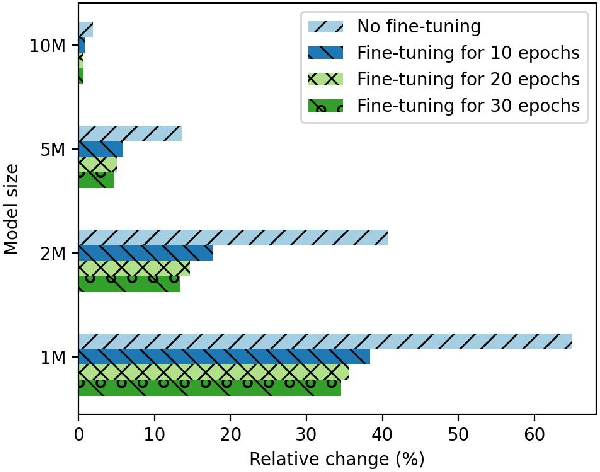
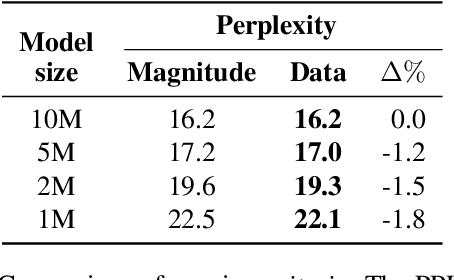
We study model pruning methods applied to Transformer-based neural network language models for automatic speech recognition. We explore three aspects of the pruning frame work, namely criterion, method and scheduler, analyzing their contribution in terms of accuracy and inference speed. To the best of our knowledge, such in-depth analyses on large-scale recognition systems has not been reported in the literature. In addition, we propose a variant of low-rank approximation suitable for incrementally compressing models, and delivering multiple models with varied target sizes. Among other results, we show that a) data-driven pruning outperforms magnitude-driven in several scenarios; b) incremental pruning achieves higher accuracy compared to one-shot pruning, especially when targeting smaller sizes; and c) low-rank approximation presents the best trade-off between size reduction and inference speed-up for moderate compression.
Towards Domain-Specific Cross-Corpus Speech Emotion Recognition Approach
Dec 11, 2023Cross-corpus speech emotion recognition (SER) poses a challenge due to feature distribution mismatch, potentially degrading the performance of established SER methods. In this paper, we tackle this challenge by proposing a novel transfer subspace learning method called acoustic knowledgeguided transfer linear regression (AKTLR). Unlike existing approaches, which often overlook domain-specific knowledge related to SER and simply treat cross-corpus SER as a generic transfer learning task, our AKTLR method is built upon a well-designed acoustic knowledge-guided dual sparsity constraint mechanism. This mechanism emphasizes the potential of minimalistic acoustic parameter feature sets to alleviate classifier overadaptation, which is empirically validated acoustic knowledge in SER, enabling superior generalization in cross-corpus SER tasks compared to using large feature sets. Through this mechanism, we extend a simple transfer linear regression model to AKTLR. This extension harnesses its full capability to seek emotiondiscriminative and corpus-invariant features from established acoustic parameter feature sets used for describing speech signals across two scales: contributive acoustic parameter groups and constituent elements within each contributive group. Our proposed method is evaluated through extensive cross-corpus SER experiments on three widely-used speech emotion corpora: EmoDB, eNTERFACE, and CASIA. The results confirm the effectiveness and superior performance of our method, outperforming recent state-of-the-art transfer subspace learning and deep transfer learning-based cross-corpus SER methods. Furthermore, our work provides experimental evidence supporting the feasibility and superiority of incorporating domain-specific knowledge into the transfer learning model to address cross-corpus SER tasks.
Zipformer: A faster and better encoder for automatic speech recognition
Oct 17, 2023The Conformer has become the most popular encoder model for automatic speech recognition (ASR). It adds convolution modules to a transformer to learn both local and global dependencies. In this work we describe a faster, more memory-efficient, and better-performing transformer, called Zipformer. Modeling changes include: 1) a U-Net-like encoder structure where middle stacks operate at lower frame rates; 2) reorganized block structure with more modules, within which we re-use attention weights for efficiency; 3) a modified form of LayerNorm called BiasNorm allows us to retain some length information; 4) new activation functions SwooshR and SwooshL work better than Swish. We also propose a new optimizer, called ScaledAdam, which scales the update by each tensor's current scale to keep the relative change about the same, and also explictly learns the parameter scale. It achieves faster convergence and better performance than Adam. Extensive experiments on LibriSpeech, Aishell-1, and WenetSpeech datasets demonstrate the effectiveness of our proposed Zipformer over other state-of-the-art ASR models. Our code is publicly available at https://github.com/k2-fsa/icefall.
SALM: Speech-augmented Language Model with In-context Learning for Speech Recognition and Translation
Oct 13, 2023We present a novel Speech Augmented Language Model (SALM) with {\em multitask} and {\em in-context} learning capabilities. SALM comprises a frozen text LLM, a audio encoder, a modality adapter module, and LoRA layers to accommodate speech input and associated task instructions. The unified SALM not only achieves performance on par with task-specific Conformer baselines for Automatic Speech Recognition (ASR) and Speech Translation (AST), but also exhibits zero-shot in-context learning capabilities, demonstrated through keyword-boosting task for ASR and AST. Moreover, {\em speech supervised in-context training} is proposed to bridge the gap between LLM training and downstream speech tasks, which further boosts the in-context learning ability of speech-to-text models. Proposed model is open-sourced via NeMo toolkit.