 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Key-Sparse Transformer with Cascaded Cross-Attention Block for Multimodal Speech Emotion Recognition
Jun 22, 2021

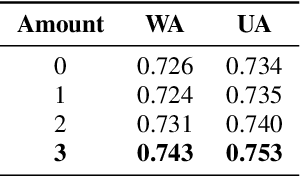
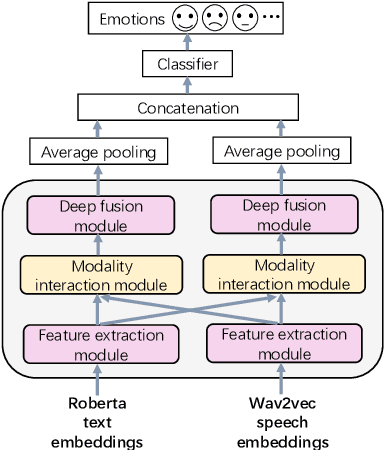
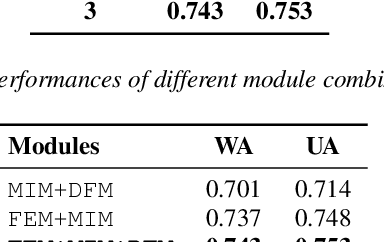
Speech emotion recognition is a challenging and important research topic that plays a critical role in human-computer interaction. Multimodal inputs can improve the performance as more emotional information is used for recognition. However, existing studies learnt all the information in the sample while only a small portion of it is about emotion. Moreover, under the multimodal framework, the interaction between different modalities is shallow and insufficient. In this paper, a keysparse Transformer is proposed for efficient SER by only focusing on emotion related information. Furthermore, a cascaded cross-attention block, which is specially designed for multimodal framework, is introduced to achieve deep interaction between different modalities. The proposed method is evaluated by IEMOCAP corpus and the experimental results show that the proposed method gives better performance than the state-of-theart approaches.
Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications
Apr 25, 2022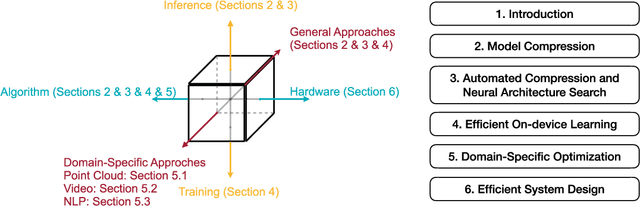
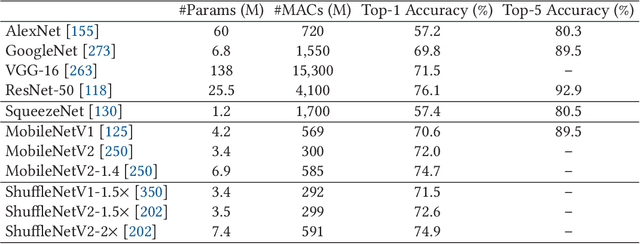
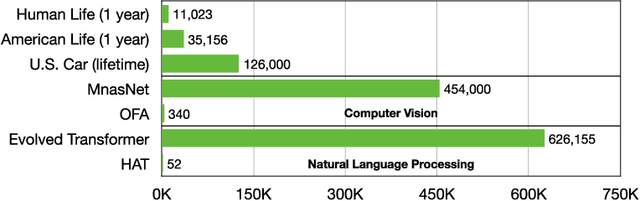
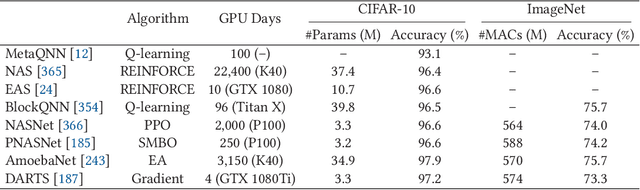
Deep neural networks (DNNs) have achieved unprecedented success in the field of artificial intelligence (AI), including computer vision, natural language processing and speech recognition. However, their superior performance comes at the considerable cost of computational complexity, which greatly hinders their applications in many resource-constrained devices, such as mobile phones and Internet of Things (IoT) devices. Therefore, methods and techniques that are able to lift the efficiency bottleneck while preserving the high accuracy of DNNs are in great demand in order to enable numerous edge AI applications. This paper provides an overview of efficient deep learning methods, systems and applications. We start from introducing popular model compression methods, including pruning, factorization, quantization as well as compact model design. To reduce the large design cost of these manual solutions, we discuss the AutoML framework for each of them, such as neural architecture search (NAS) and automated pruning and quantization. We then cover efficient on-device training to enable user customization based on the local data on mobile devices. Apart from general acceleration techniques, we also showcase several task-specific accelerations for point cloud, video and natural language processing by exploiting their spatial sparsity and temporal/token redundancy. Finally, to support all these algorithmic advancements, we introduce the efficient deep learning system design from both software and hardware perspectives.
* Journal preprint (ACM TODAES, 2021). The first seven authors contributed equally to this work and are listed in the alphabetical order
Universal speaker recognition encoders for different speech segments duration
Oct 28, 2022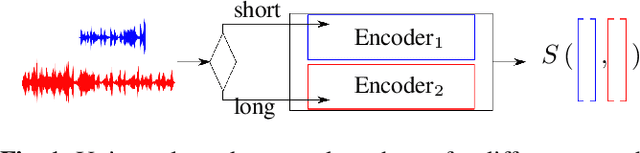
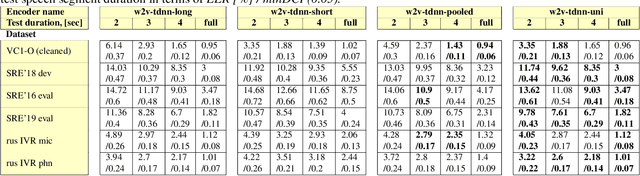
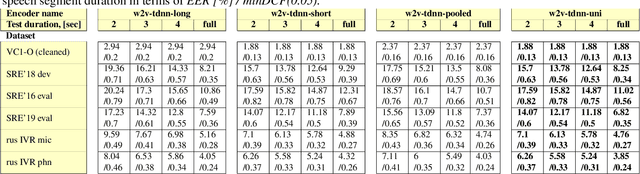
Creating universal speaker encoders which are robust for different acoustic and speech duration conditions is a big challenge today. According to our observations systems trained on short speech segments are optimal for short phrase speaker verification and systems trained on long segments are superior for long segments verification. A system trained simultaneously on pooled short and long speech segments does not give optimal verification results and usually degrades both for short and long segments. This paper addresses the problem of creating universal speaker encoders for different speech segments duration. We describe our simple recipe for training universal speaker encoder for any type of selected neural network architecture. According to our evaluation results of wav2vec-TDNN based systems obtained for NIST SRE and VoxCeleb1 benchmarks the proposed universal encoder provides speaker verification improvements in case of different enrollment and test speech segment duration. The key feature of the proposed encoder is that it has the same inference time as the selected neural network architecture.
data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language
Feb 07, 2022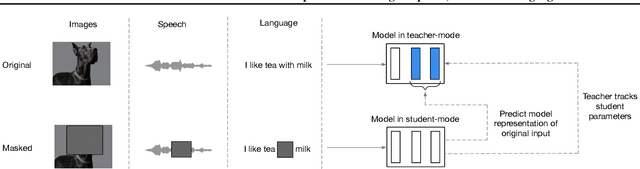
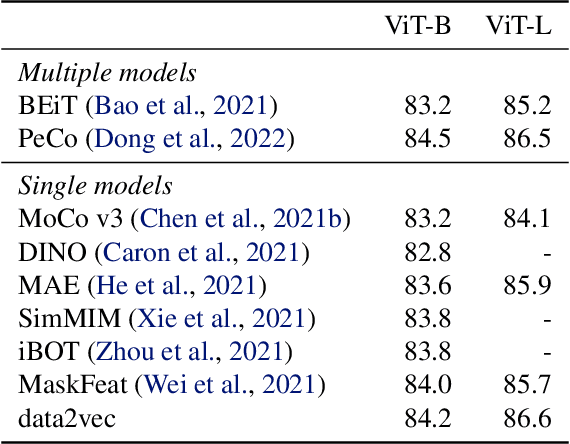
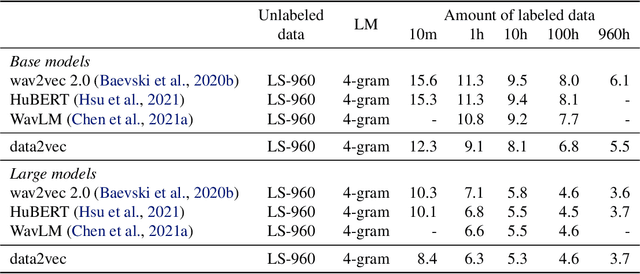
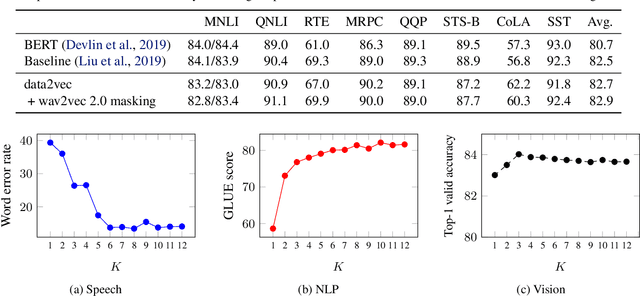
While the general idea of self-supervised learning is identical across modalities, the actual algorithms and objectives differ widely because they were developed with a single modality in mind. To get us closer to general self-supervised learning, we present data2vec, a framework that uses the same learning method for either speech, NLP or computer vision. The core idea is to predict latent representations of the full input data based on a masked view of the input in a self-distillation setup using a standard Transformer architecture. Instead of predicting modality-specific targets such as words, visual tokens or units of human speech which are local in nature, data2vec predicts contextualized latent representations that contain information from the entire input. Experiments on the major benchmarks of speech recognition, image classification, and natural language understanding demonstrate a new state of the art or competitive performance to predominant approaches.
RETURNN as a Generic Flexible Neural Toolkit with Application to Translation and Speech Recognition
May 24, 2018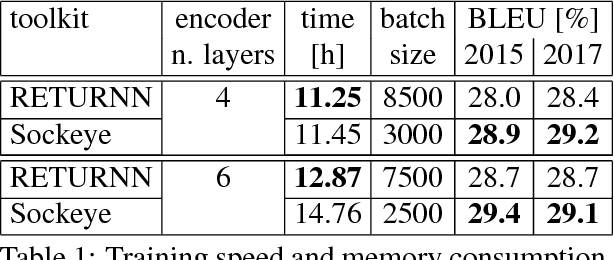
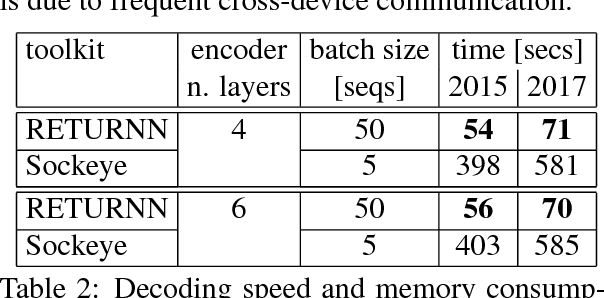
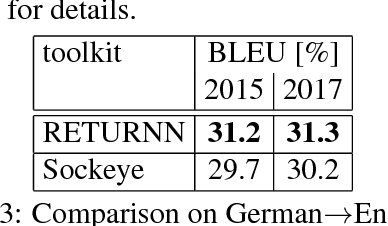
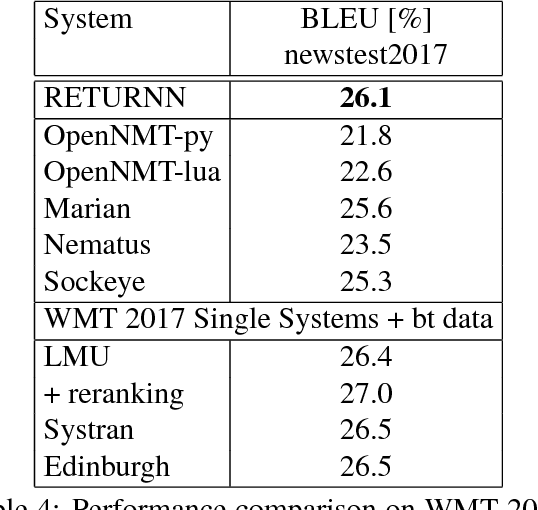
We compare the fast training and decoding speed of RETURNN of attention models for translation, due to fast CUDA LSTM kernels, and a fast pure TensorFlow beam search decoder. We show that a layer-wise pretraining scheme for recurrent attention models gives over 1% BLEU improvement absolute and it allows to train deeper recurrent encoder networks. Promising preliminary results on max. expected BLEU training are presented. We are able to train state-of-the-art models for translation and end-to-end models for speech recognition and show results on WMT 2017 and Switchboard. The flexibility of RETURNN allows a fast research feedback loop to experiment with alternative architectures, and its generality allows to use it on a wide range of applications.
QASR: QCRI Aljazeera Speech Resource -- A Large Scale Annotated Arabic Speech Corpus
Jun 24, 2021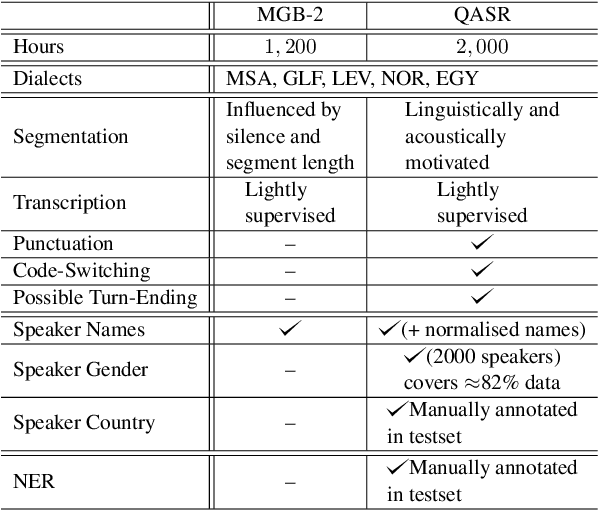

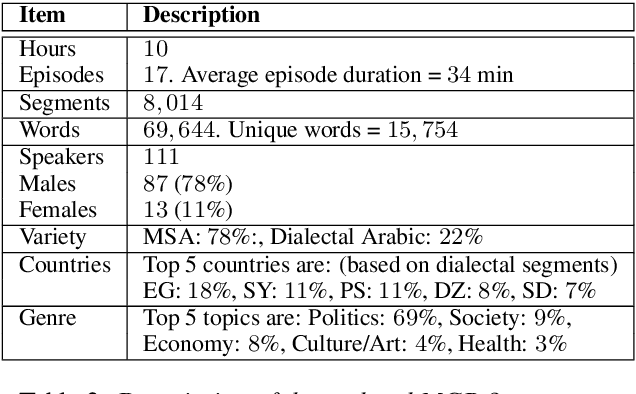
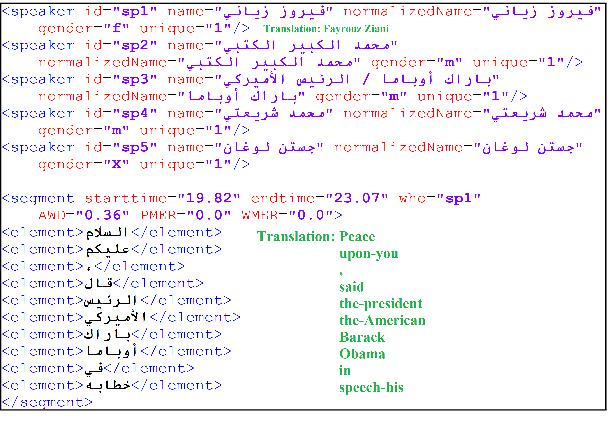
We introduce the largest transcribed Arabic speech corpus, QASR, collected from the broadcast domain. This multi-dialect speech dataset contains 2,000 hours of speech sampled at 16kHz crawled from Aljazeera news channel. The dataset is released with lightly supervised transcriptions, aligned with the audio segments. Unlike previous datasets, QASR contains linguistically motivated segmentation, punctuation, speaker information among others. QASR is suitable for training and evaluating speech recognition systems, acoustics- and/or linguistics- based Arabic dialect identification, punctuation restoration, speaker identification, speaker linking, and potentially other NLP modules for spoken data. In addition to QASR transcription, we release a dataset of 130M words to aid in designing and training a better language model. We show that end-to-end automatic speech recognition trained on QASR reports a competitive word error rate compared to the previous MGB-2 corpus. We report baseline results for downstream natural language processing tasks such as named entity recognition using speech transcript. We also report the first baseline for Arabic punctuation restoration. We make the corpus available for the research community.
Language Models with Image Descriptors are Strong Few-Shot Video-Language Learners
May 29, 2022
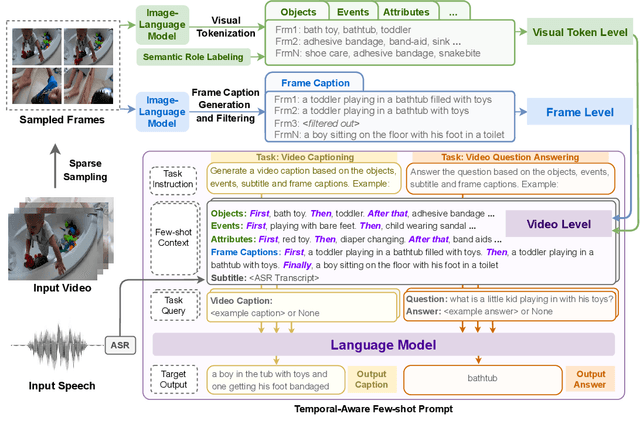
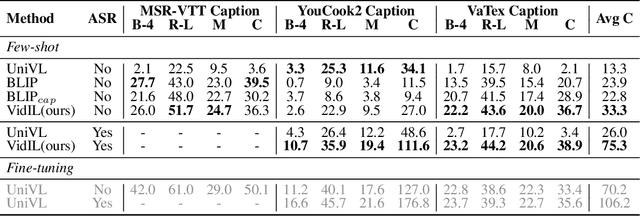

The goal of this work is to build flexible video-language models that can generalize to various video-to-text tasks from few examples, such as domain-specific captioning, question answering, and future event prediction. Existing few-shot video-language learners focus exclusively on the encoder, resulting in the absence of a video-to-text decoder to handle generative tasks. Video captioners have been pretrained on large-scale video-language datasets, but they rely heavily on finetuning and lack the ability to generate text for unseen tasks in a few-shot setting. We propose VidIL, a few-shot Video-language Learner via Image and Language models, which demonstrates strong performance on few-shot video-to-text tasks without the necessity of pretraining or finetuning on any video datasets. We use the image-language models to translate the video content into frame captions, object, attribute, and event phrases, and compose them into a temporal structure template. We then instruct a language model, with a prompt containing a few in-context examples, to generate a target output from the composed content. The flexibility of prompting allows the model to capture any form of text input, such as automatic speech recognition (ASR) transcripts. Our experiments demonstrate the power of language models in understanding videos on a wide variety of video-language tasks, including video captioning, video question answering, video caption retrieval, and video future event prediction. Especially, on video future event prediction, our few-shot model significantly outperforms state-of-the-art supervised models trained on large-scale video datasets. Code and resources are publicly available for research purposes at https://github.com/MikeWangWZHL/VidIL .
Audio-visual Multi-channel Recognition of Overlapped Speech
May 18, 2020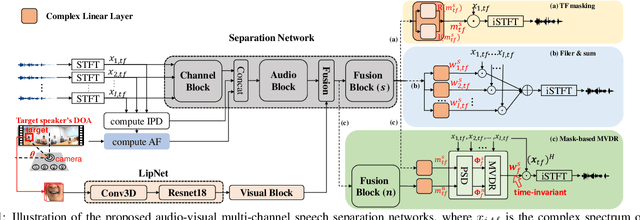
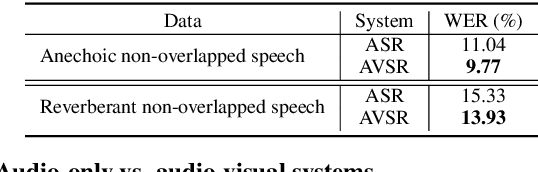
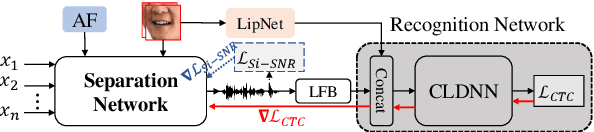

Automatic speech recognition (ASR) of overlapped speech remains a highly challenging task to date. To this end, multi-channel microphone array data are widely used in state-of-the-art ASR systems. Motivated by the invariance of visual modality to acoustic signal corruption, this paper presents an audio-visual multi-channel overlapped speech recognition system featuring tightly integrated separation front-end and recognition back-end. A series of audio-visual multi-channel speech separation front-end components based on \textit{TF masking}, \textit{filter\&sum} and \textit{mask-based MVDR} beamforming approaches were developed. To reduce the error cost mismatch between the separation and recognition components, they were jointly fine-tuned using the connectionist temporal classification (CTC) loss function, or a multi-task criterion interpolation with scale-invariant signal to noise ratio (Si-SNR) error cost. Experiments suggest that the proposed multi-channel AVSR system outperforms the baseline audio-only ASR system by up to 6.81\% (26.83\% relative) and 22.22\% (56.87\% relative) absolute word error rate (WER) reduction on overlapped speech constructed using either simulation or replaying of the lipreading sentence 2 (LRS2) dataset respectively.
Audio Visual Speech Recognition using Deep Recurrent Neural Networks
Nov 09, 2016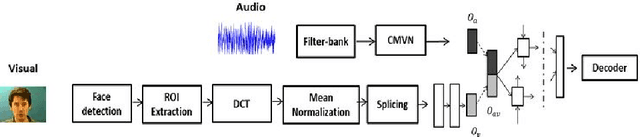
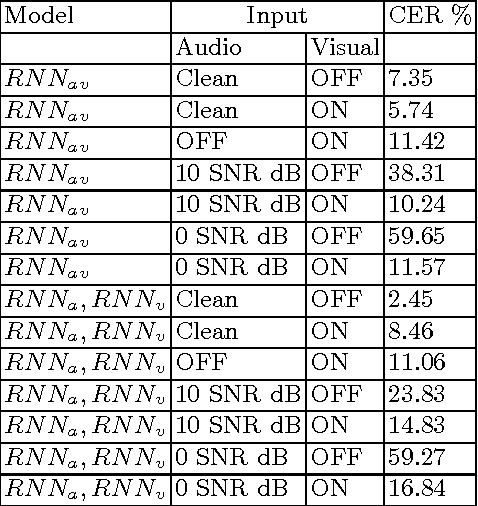
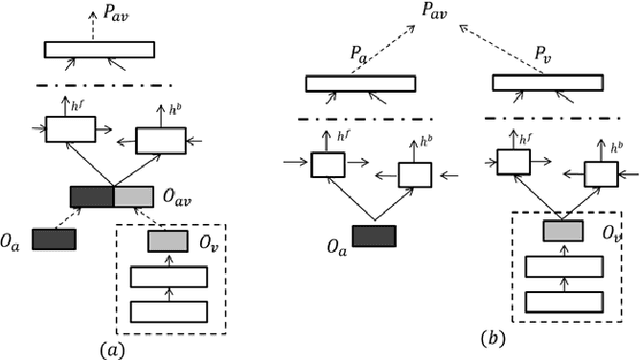
In this work, we propose a training algorithm for an audio-visual automatic speech recognition (AV-ASR) system using deep recurrent neural network (RNN).First, we train a deep RNN acoustic model with a Connectionist Temporal Classification (CTC) objective function. The frame labels obtained from the acoustic model are then used to perform a non-linear dimensionality reduction of the visual features using a deep bottleneck network. Audio and visual features are fused and used to train a fusion RNN. The use of bottleneck features for visual modality helps the model to converge properly during training. Our system is evaluated on GRID corpus. Our results show that presence of visual modality gives significant improvement in character error rate (CER) at various levels of noise even when the model is trained without noisy data. We also provide a comparison of two fusion methods: feature fusion and decision fusion.
LegoNN: Building Modular Encoder-Decoder Models
Jun 07, 2022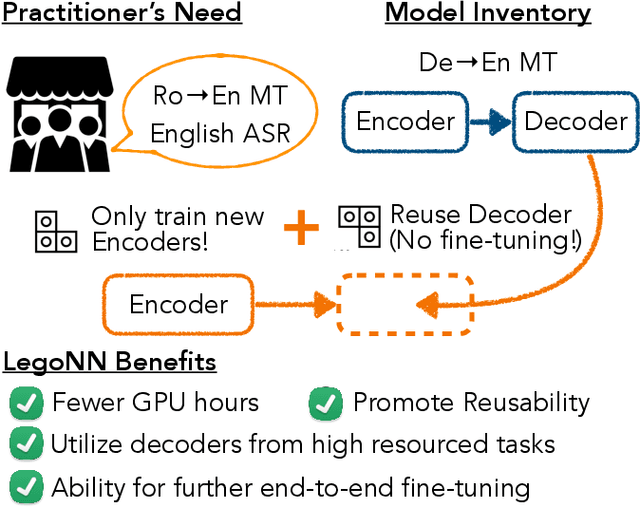
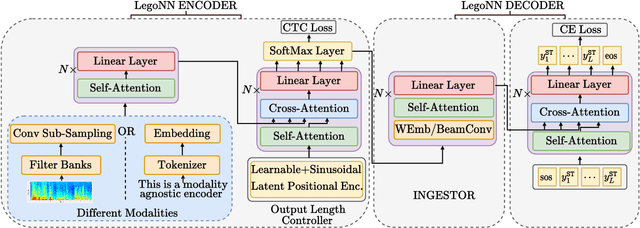
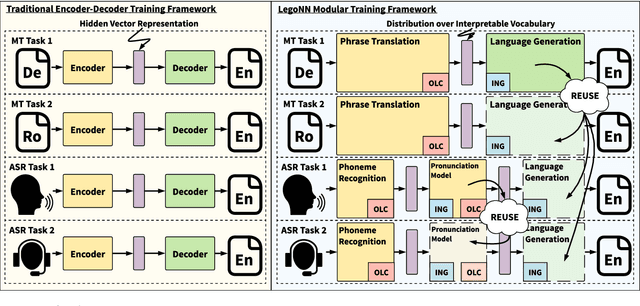
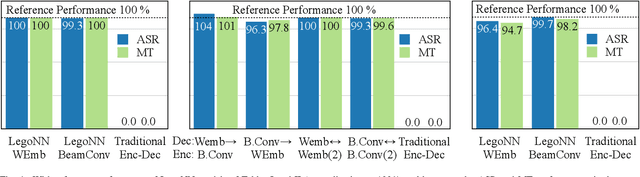
State-of-the-art encoder-decoder models (e.g. for machine translation (MT) or speech recognition (ASR)) are constructed and trained end-to-end as an atomic unit. No component of the model can be (re-)used without the others. We describe LegoNN, a procedure for building encoder-decoder architectures with decoder modules that can be reused across various MT and ASR tasks, without the need for any fine-tuning. To achieve reusability, the interface between each encoder and decoder modules is grounded to a sequence of marginal distributions over a discrete vocabulary pre-defined by the model designer. We present two approaches for ingesting these marginals; one is differentiable, allowing the flow of gradients across the entire network, and the other is gradient-isolating. To enable portability of decoder modules between MT tasks for different source languages and across other tasks like ASR, we introduce a modality agnostic encoder which consists of a length control mechanism to dynamically adapt encoders' output lengths in order to match the expected input length range of pre-trained decoders. We present several experiments to demonstrate the effectiveness of LegoNN models: a trained language generation LegoNN decoder module from German-English (De-En) MT task can be reused with no fine-tuning for the Europarl English ASR and the Romanian-English (Ro-En) MT tasks to match or beat respective baseline models. When fine-tuned towards the target task for few thousand updates, our LegoNN models improved the Ro-En MT task by 1.5 BLEU points, and achieved 12.5% relative WER reduction for the Europarl ASR task. Furthermore, to show its extensibility, we compose a LegoNN ASR model from three modules -- each has been learned within different end-to-end trained models on three different datasets -- boosting the WER reduction to 19.5%.