 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Cross-lingual Transfer for Speech Processing using Acoustic Language Similarity
Nov 02, 2021
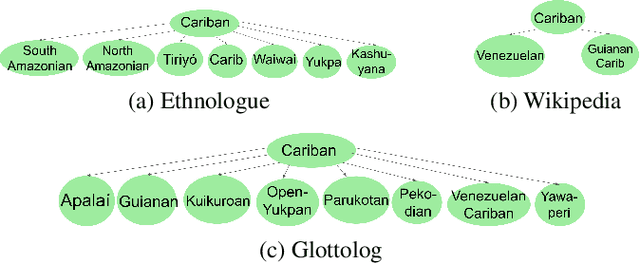
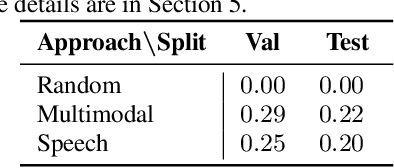
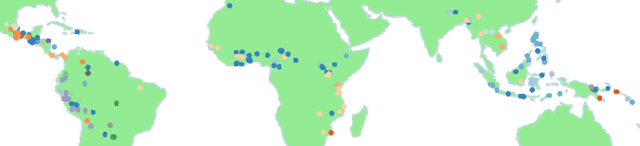
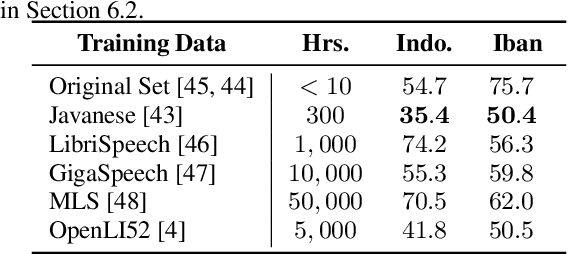
Speech processing systems currently do not support the vast majority of languages, in part due to the lack of data in low-resource languages. Cross-lingual transfer offers a compelling way to help bridge this digital divide by incorporating high-resource data into low-resource systems. Current cross-lingual algorithms have shown success in text-based tasks and speech-related tasks over some low-resource languages. However, scaling up speech systems to support hundreds of low-resource languages remains unsolved. To help bridge this gap, we propose a language similarity approach that can efficiently identify acoustic cross-lingual transfer pairs across hundreds of languages. We demonstrate the effectiveness of our approach in language family classification, speech recognition, and speech synthesis tasks.
Enhanced Robot Speech Recognition Using Biomimetic Binaural Sound Source Localization
Feb 13, 2019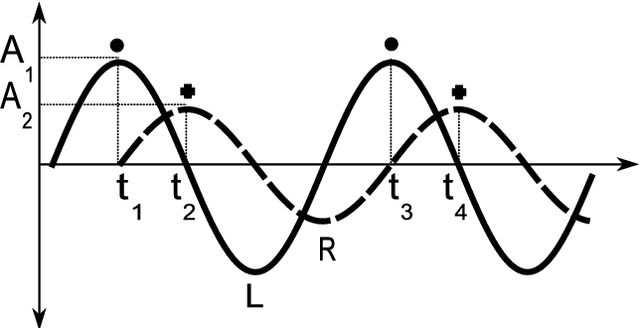
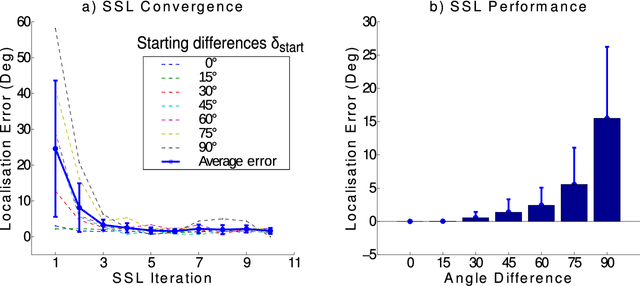
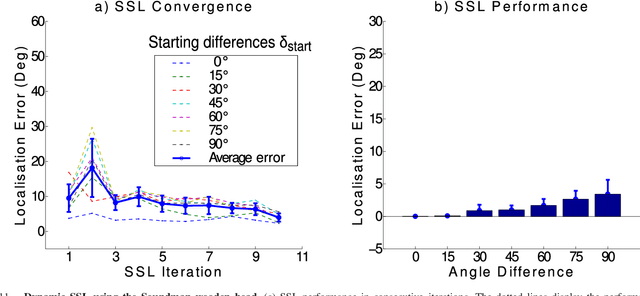
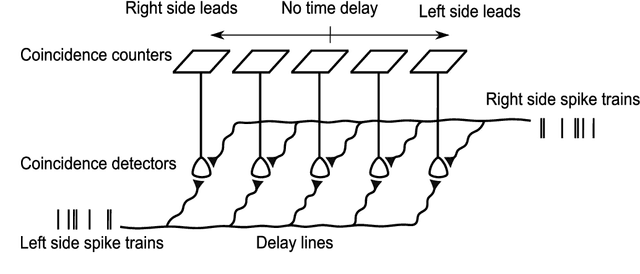
Inspired by the behavior of humans talking in noisy environments, we propose an embodied embedded cognition approach to improve automatic speech recognition (ASR) systems for robots in challenging environments, such as with ego noise, using binaural sound source localization (SSL). The approach is verified by measuring the impact of SSL with a humanoid robot head on the performance of an ASR system. More specifically, a robot orients itself toward the angle where the signal-to-noise ratio (SNR) of speech is maximized for one microphone before doing an ASR task. First, a spiking neural network inspired by the midbrain auditory system based on our previous work is applied to calculate the sound signal angle. Then, a feedforward neural network is used to handle high levels of ego noise and reverberation in the signal. Finally, the sound signal is fed into an ASR system. For ASR, we use a system developed by our group and compare its performance with and without the support from SSL. We test our SSL and ASR systems on two humanoid platforms with different structural and material properties. With our approach we halve the sentence error rate with respect to the common downmixing of both channels. Surprisingly, the ASR performance is more than two times better when the angle between the humanoid head and the sound source allows sound waves to be reflected most intensely from the pinna to the ear microphone, rather than when sound waves arrive perpendicularly to the membrane.
Streaming parallel transducer beam search with fast-slow cascaded encoders
Mar 29, 2022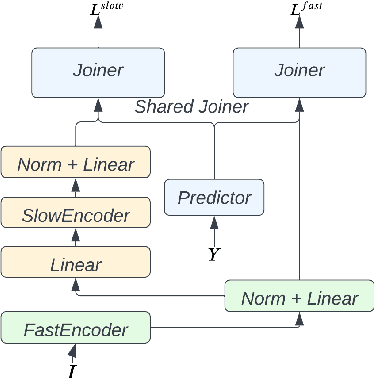
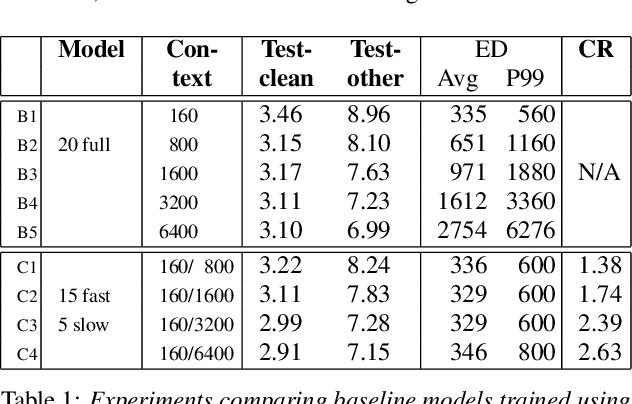
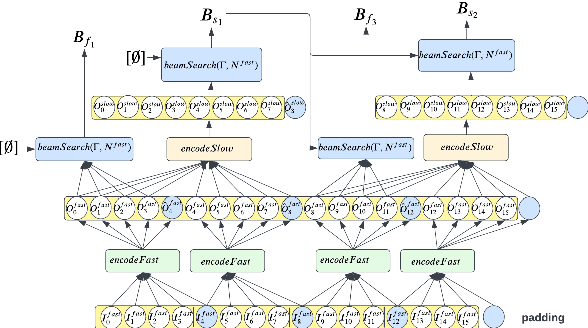
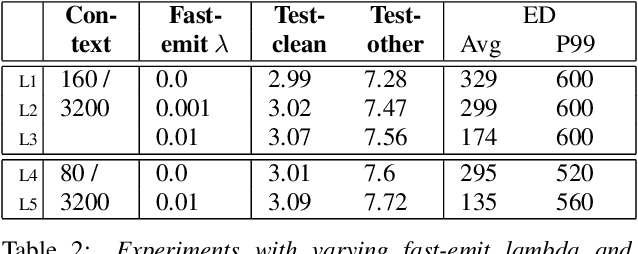
Streaming ASR with strict latency constraints is required in many speech recognition applications. In order to achieve the required latency, streaming ASR models sacrifice accuracy compared to non-streaming ASR models due to lack of future input context. Previous research has shown that streaming and non-streaming ASR for RNN Transducers can be unified by cascading causal and non-causal encoders. This work improves upon this cascaded encoders framework by leveraging two streaming non-causal encoders with variable input context sizes that can produce outputs at different audio intervals (e.g. fast and slow). We propose a novel parallel time-synchronous beam search algorithm for transducers that decodes from fast-slow encoders, where the slow encoder corrects the mistakes generated from the fast encoder. The proposed algorithm, achieves up to 20% WER reduction with a slight increase in token emission delays on the public Librispeech dataset and in-house datasets. We also explore techniques to reduce the computation by distributing processing between the fast and slow encoders. Lastly, we explore sharing the parameters in the fast encoder to reduce the memory footprint. This enables low latency processing on edge devices with low computation cost and a low memory footprint.
Spanish and English Phoneme Recognition by Training on Simulated Classroom Audio Recordings of Collaborative Learning Environments
Feb 21, 2022


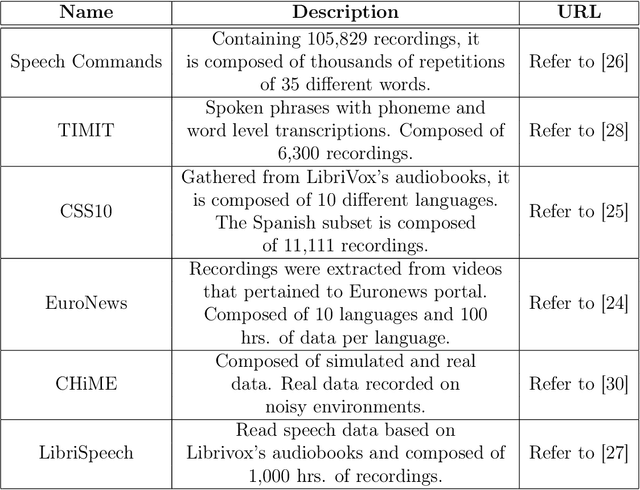
Audio recordings of collaborative learning environments contain a constant presence of cross-talk and background noise. Dynamic speech recognition between Spanish and English is required in these environments. To eliminate the standard requirement of large-scale ground truth, the thesis develops a simulated dataset by transforming audio transcriptions into phonemes and using 3D speaker geometry and data augmentation to generate an acoustic simulation of Spanish and English speech. The thesis develops a low-complexity neural network for recognizing Spanish and English phonemes (available at github.com/muelitas/keywordRec). When trained on 41 English phonemes, 0.099 PER is achieved on Speech Commands. When trained on 36 Spanish phonemes and tested on real recordings of collaborative learning environments, a 0.7208 LER is achieved. Slightly better than Google's Speech-to-text 0.7272 LER, which used anywhere from 15 to 1,635 times more parameters and trained on 300 to 27,500 hours of real data as opposed to 13 hours of simulated audios.
LightHuBERT: Lightweight and Configurable Speech Representation Learning with Once-for-All Hidden-Unit BERT
Mar 29, 2022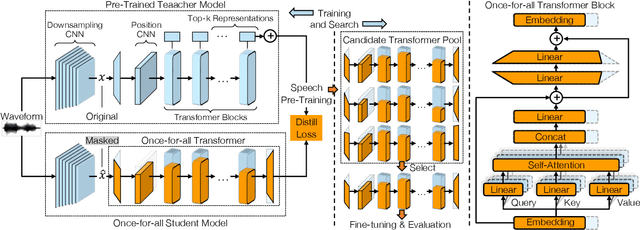
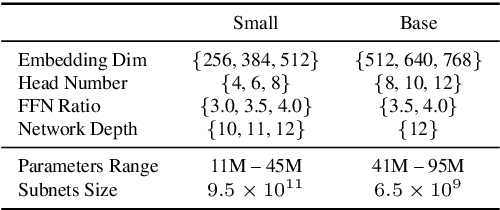

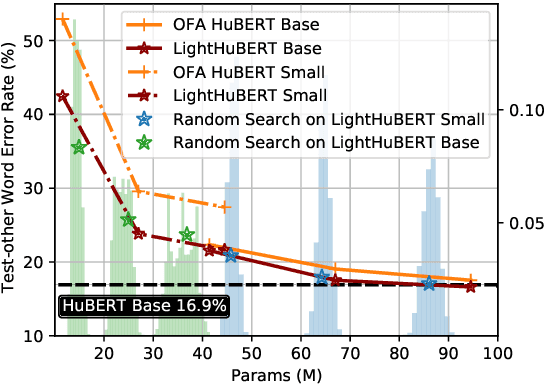
Self-supervised speech representation learning has shown promising results in various speech processing tasks. However, the pre-trained models, e.g., HuBERT, are storage-intensive Transformers, limiting their scope of applications under low-resource settings. To this end, we propose LightHuBERT, a once-for-all Transformer compression framework, to find the desired architectures automatically by pruning structured parameters. More precisely, we create a Transformer-based supernet that is nested with thousands of weight-sharing subnets and design a two-stage distillation strategy to leverage the contextualized latent representations from HuBERT. Experiments on automatic speech recognition (ASR) and the SUPERB benchmark show the proposed LightHuBERT enables over $10^9$ architectures concerning the embedding dimension, attention dimension, head number, feed-forward network ratio, and network depth. LightHuBERT outperforms the original HuBERT on ASR and five SUPERB tasks with the HuBERT size, achieves comparable performance to the teacher model in most tasks with a reduction of 29% parameters, and obtains a $3.5\times$ compression ratio in three SUPERB tasks, e.g., automatic speaker verification, keyword spotting, and intent classification, with a slight accuracy loss. The code and pre-trained models are available at https://github.com/mechanicalsea/lighthubert.
MFA-Conformer: Multi-scale Feature Aggregation Conformer for Automatic Speaker Verification
Mar 29, 2022
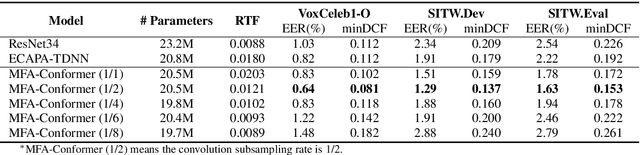
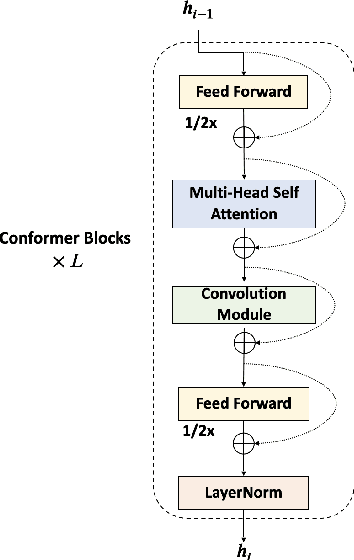
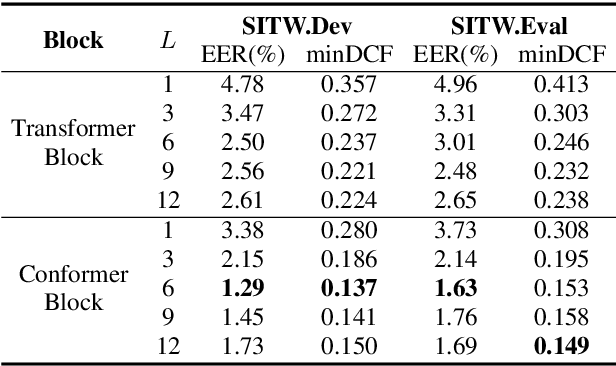
In this paper, we present Multi-scale Feature Aggregation Conformer (MFA-Conformer), an easy-to-implement, simple but effective backbone for automatic speaker verification based on the Convolution-augmented Transformer (Conformer). The architecture of the MFA-Conformer is inspired by recent state-of-the-art models in speech recognition and speaker verification. Firstly, we introduce a convolution sub-sampling layer to decrease the computational cost of the model. Secondly, we adopt Conformer blocks which combine Transformers and convolution neural networks (CNNs) to capture global and local features effectively. Finally, the output feature maps from all Conformer blocks are concatenated to aggregate multi-scale representations before final pooling. We evaluate the MFA-Conformer on the widely used benchmarks. The best system obtains 0.64%, 1.29% and 1.63% EER on VoxCeleb1-O, SITW.Dev, and SITW.Eval set, respectively. MFA-Conformer significantly outperforms the popular ECAPA-TDNN systems in both recognition performance and inference speed. Last but not the least, the ablation studies clearly demonstrate that the combination of global and local feature learning can lead to robust and accurate speaker embedding extraction. We will release the code for future works to do comparison.
Shifted Chunk Encoder for Transformer Based Streaming End-to-End ASR
Mar 29, 2022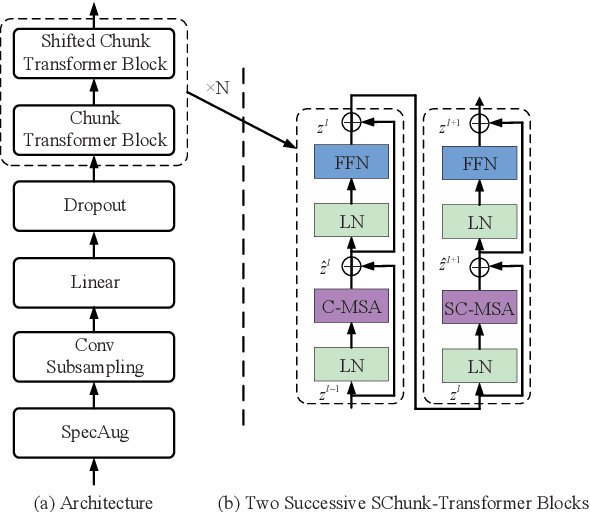
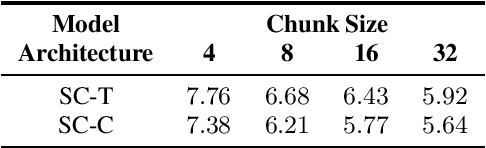
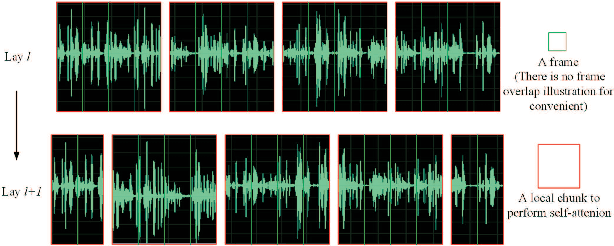

Currently, there are mainly three Transformer encoder based streaming End to End (E2E) Automatic Speech Recognition (ASR) approaches, namely time-restricted methods, chunk-wise methods, and memory based methods. However, all of them have some limitations in aspects of global context modeling, linear computational complexity, and model parallelism. In this work, we aim to build a single model to achieve the benefits of all the three aspects for streaming E2E ASR. Particularly, we propose to use a shifted chunk mechanism instead of the conventional chunk mechanism for streaming Transformer and Conformer. This shifted chunk mechanism can significantly enhance modeling power through allowing chunk self-attention to capture global context across local chunks, while keeping linear computational complexity and parallel trainable. We name the Shifted Chunk Transformer and Conformer as SChunk-Transofromer and SChunk-Conformer, respectively. And we verify their performance on the widely used AISHELL-1 benckmark. Experiments show that the SChunk-Transformer and SChunk-Conformer achieve CER 6.43% and 5.77%, respectively. That surpasses the existing chunk-wise and memory based methods by a large margin, and is competitive even compared with the state-of-the-art time-restricted methods which have quadratic computational complexity.
Influence Functions for Sequence Tagging Models
Oct 25, 2022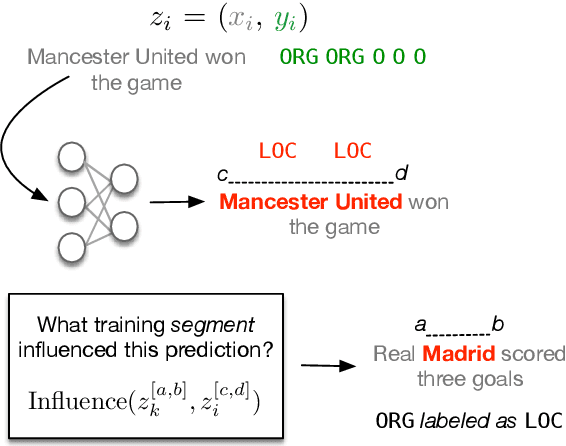
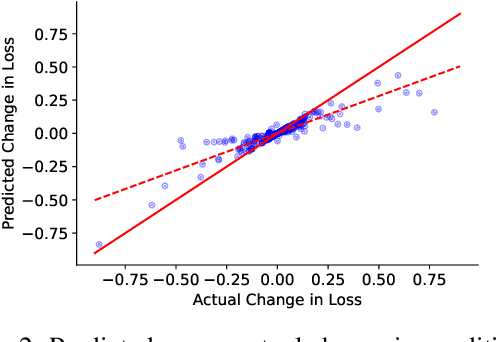

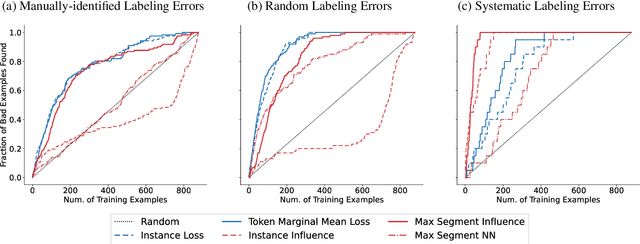
Many language tasks (e.g., Named Entity Recognition, Part-of-Speech tagging, and Semantic Role Labeling) are naturally framed as sequence tagging problems. However, there has been comparatively little work on interpretability methods for sequence tagging models. In this paper, we extend influence functions - which aim to trace predictions back to the training points that informed them - to sequence tagging tasks. We define the influence of a training instance segment as the effect that perturbing the labels within this segment has on a test segment level prediction. We provide an efficient approximation to compute this, and show that it tracks with the true segment influence, measured empirically. We show the practical utility of segment influence by using the method to identify systematic annotation errors in two named entity recognition corpora. Code to reproduce our results is available at https://github.com/successar/Segment_Influence_Functions.
Integrating HMM-Based Speech Recognition With Direct Manipulation In A Multimodal Korean Natural Language Interface
Nov 18, 1996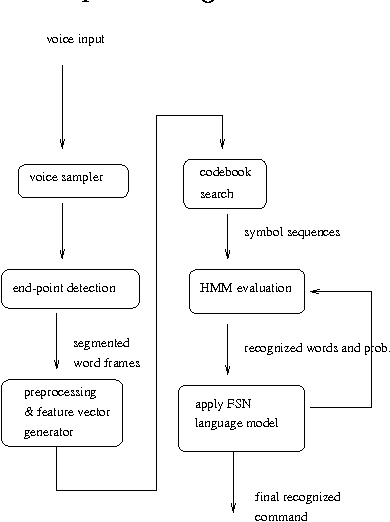
This paper presents a HMM-based speech recognition engine and its integration into direct manipulation interfaces for Korean document editor. Speech recognition can reduce typical tedious and repetitive actions which are inevitable in standard GUIs (graphic user interfaces). Our system consists of general speech recognition engine called ABrain {Auditory Brain} and speech commandable document editor called SHE {Simple Hearing Editor}. ABrain is a phoneme-based speech recognition engine which shows up to 97% of discrete command recognition rate. SHE is a EuroBridge widget-based document editor that supports speech commands as well as direct manipulation interfaces.
Enable Deep Learning on Mobile Devices: Methods, Systems, and Applications
Apr 25, 2022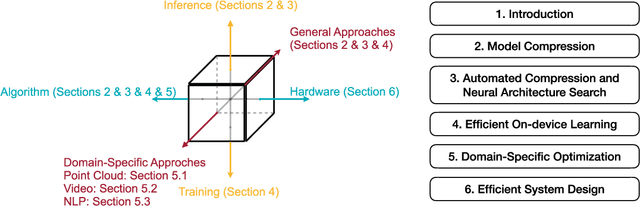
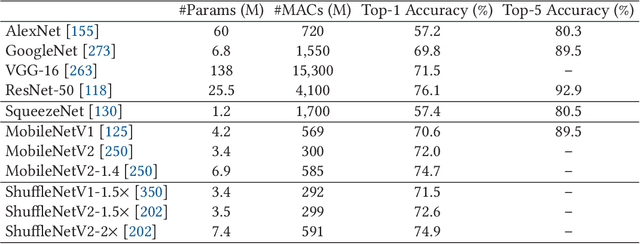
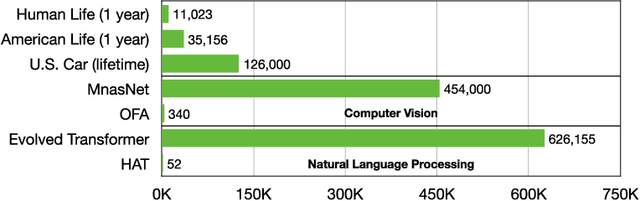
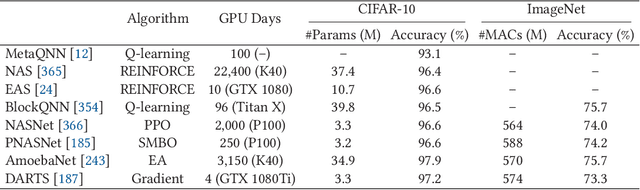
Deep neural networks (DNNs) have achieved unprecedented success in the field of artificial intelligence (AI), including computer vision, natural language processing and speech recognition. However, their superior performance comes at the considerable cost of computational complexity, which greatly hinders their applications in many resource-constrained devices, such as mobile phones and Internet of Things (IoT) devices. Therefore, methods and techniques that are able to lift the efficiency bottleneck while preserving the high accuracy of DNNs are in great demand in order to enable numerous edge AI applications. This paper provides an overview of efficient deep learning methods, systems and applications. We start from introducing popular model compression methods, including pruning, factorization, quantization as well as compact model design. To reduce the large design cost of these manual solutions, we discuss the AutoML framework for each of them, such as neural architecture search (NAS) and automated pruning and quantization. We then cover efficient on-device training to enable user customization based on the local data on mobile devices. Apart from general acceleration techniques, we also showcase several task-specific accelerations for point cloud, video and natural language processing by exploiting their spatial sparsity and temporal/token redundancy. Finally, to support all these algorithmic advancements, we introduce the efficient deep learning system design from both software and hardware perspectives.
* Journal preprint (ACM TODAES, 2021). The first seven authors contributed equally to this work and are listed in the alphabetical order