 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Automatic Speech Recognition Using Template Model for Man-Machine Interface
May 09, 2013
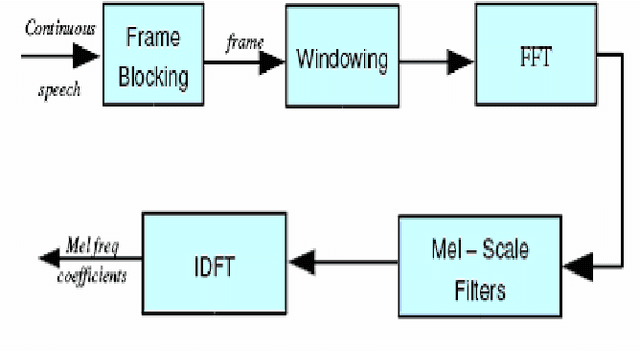
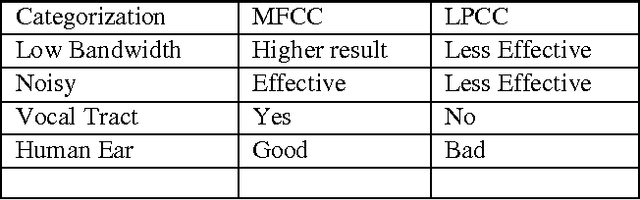
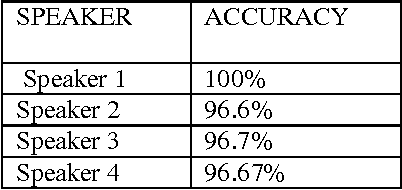
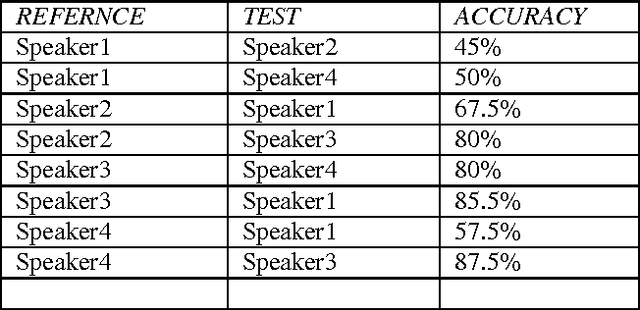
Speech is a natural form of communication for human beings, and computers with the ability to understand speech and speak with a human voice are expected to contribute to the development of more natural man-machine interfaces. Computers with this kind of ability are gradually becoming a reality, through the evolution of speech recognition technologies. Speech is being an important mode of interaction with computers. In this paper Feature extraction is implemented using well-known Mel-Frequency Cepstral Coefficients (MFCC).Pattern matching is done using Dynamic time warping (DTW) algorithm.
Understanding Audio Features via Trainable Basis Functions
Apr 25, 2022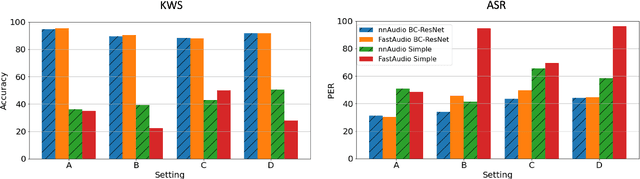

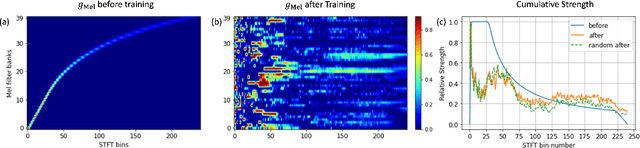
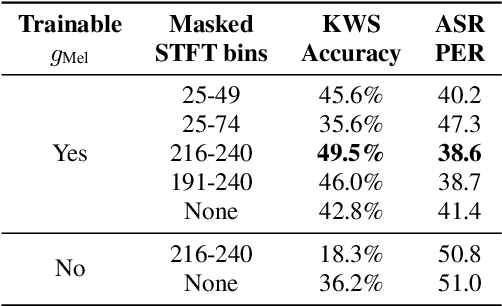
In this paper we explore the possibility of maximizing the information represented in spectrograms by making the spectrogram basis functions trainable. We experiment with two different tasks, namely keyword spotting (KWS) and automatic speech recognition (ASR). For most neural network models, the architecture and hyperparameters are typically fine-tuned and optimized in experiments. Input features, however, are often treated as fixed. In the case of audio, signals can be mainly expressed in two main ways: raw waveforms (time-domain) or spectrograms (time-frequency-domain). In addition, different spectrogram types are often used and tailored to fit different applications. In our experiments, we allow for this tailoring directly as part of the network. Our experimental results show that using trainable basis functions can boost the accuracy of Keyword Spotting (KWS) by 14.2 percentage points, and lower the Phone Error Rate (PER) by 9.5 percentage points. Although models using trainable basis functions become less effective as the model complexity increases, the trained filter shapes could still provide us with insights on which frequency bins are important for that specific task. From our experiments, we can conclude that trainable basis functions are a useful tool to boost the performance when the model complexity is limited.
Domain Expansion in DNN-based Acoustic Models for Robust Speech Recognition
Oct 01, 2019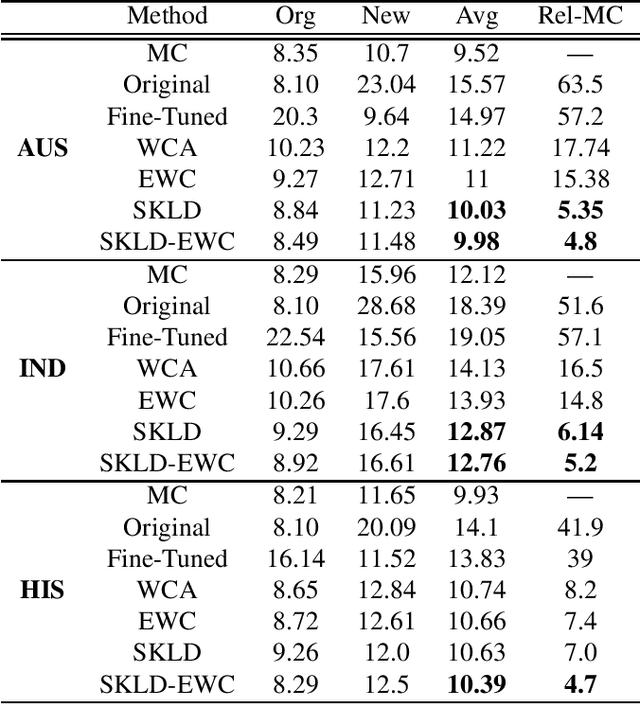

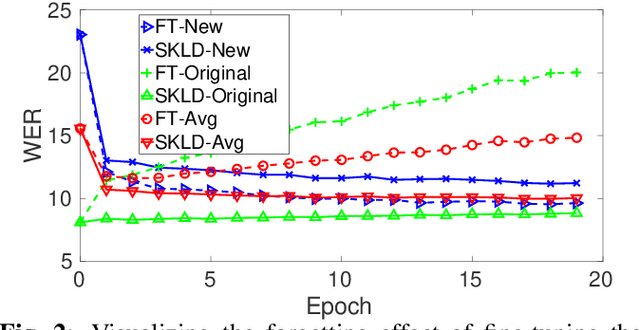
Training acoustic models with sequentially incoming data -- while both leveraging new data and avoiding the forgetting effect-- is an essential obstacle to achieving human intelligence level in speech recognition. An obvious approach to leverage data from a new domain (e.g., new accented speech) is to first generate a comprehensive dataset of all domains, by combining all available data, and then use this dataset to retrain the acoustic models. However, as the amount of training data grows, storing and retraining on such a large-scale dataset becomes practically impossible. To deal with this problem, in this study, we study several domain expansion techniques which exploit only the data of the new domain to build a stronger model for all domains. These techniques are aimed at learning the new domain with a minimal forgetting effect (i.e., they maintain original model performance). These techniques modify the adaptation procedure by imposing new constraints including (1) weight constraint adaptation (WCA): keeping the model parameters close to the original model parameters; (2) elastic weight consolidation (EWC): slowing down training for parameters that are important for previously established domains; (3) soft KL-divergence (SKLD): restricting the KL-divergence between the original and the adapted model output distributions; and (4) hybrid SKLD-EWC: incorporating both SKLD and EWC constraints. We evaluate these techniques in an accent adaptation task in which we adapt a deep neural network (DNN) acoustic model trained with native English to three different English accents: Australian, Hispanic, and Indian. The experimental results show that SKLD significantly outperforms EWC, and EWC works better than WCA. The hybrid SKLD-EWC technique results in the best overall performance.
Automated speech tools for helping communities process restricted-access corpora for language revival efforts
Apr 24, 2022
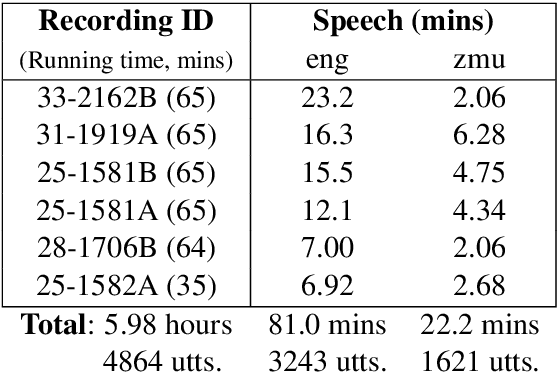
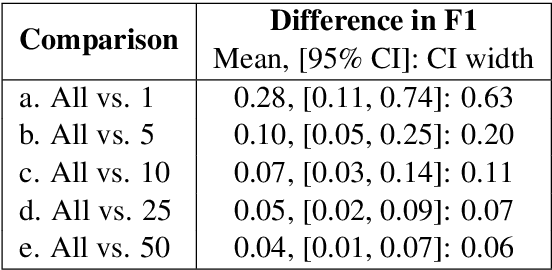
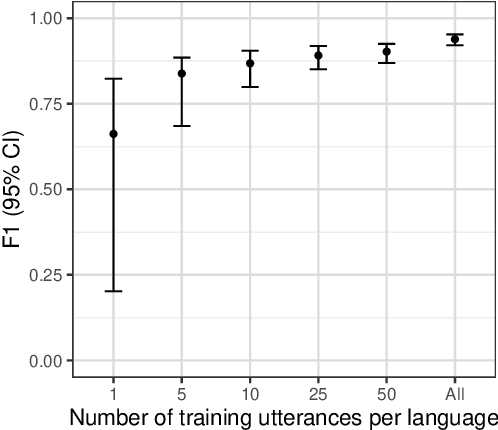
Many archival recordings of speech from endangered languages remain unannotated and inaccessible to community members and language learning programs. One bottleneck is the time-intensive nature of annotation. An even narrower bottleneck occurs for recordings with access constraints, such as language that must be vetted or filtered by authorised community members before annotation can begin. We propose a privacy-preserving workflow to widen both bottlenecks for recordings where speech in the endangered language is intermixed with a more widely-used language such as English for meta-linguistic commentary and questions (e.g. What is the word for 'tree'?). We integrate voice activity detection (VAD), spoken language identification (SLI), and automatic speech recognition (ASR) to transcribe the metalinguistic content, which an authorised person can quickly scan to triage recordings that can be annotated by people with lower levels of access. We report work-in-progress processing 136 hours archival audio containing a mix of English and Muruwari. Our collaborative work with the Muruwari custodian of the archival materials show that this workflow reduces metalanguage transcription time by 20% even given only minimal amounts of annotated training data: 10 utterances per language for SLI and for ASR at most 39 minutes, and possibly as little as 39 seconds.
Cloud-Based Face and Speech Recognition for Access Control Applications
Apr 23, 2020
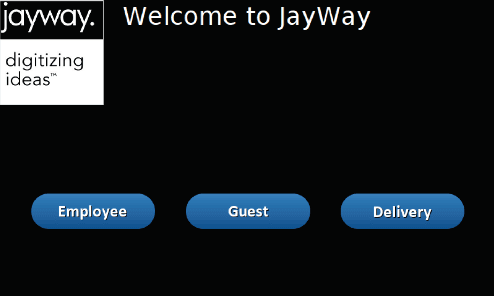
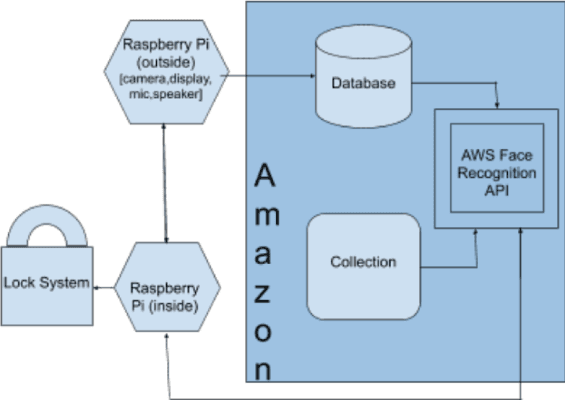
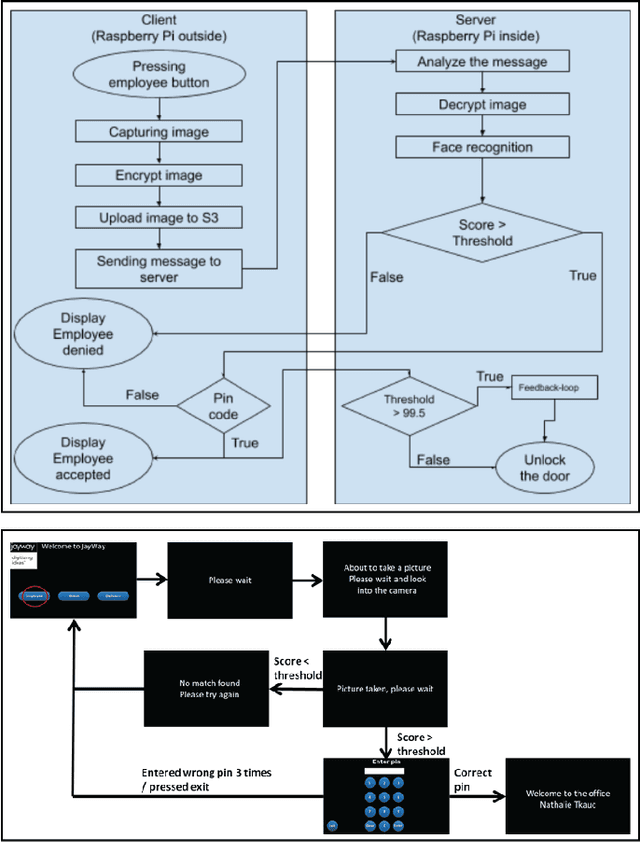
This paper describes the implementation of a system to recognize employees and visitors wanting to gain access to a physical office through face images and speech-to-text recognition. The system helps employees to unlock the entrance door via face recognition without the need of tag-keys or cards. To prevent spoofing attacks and increase security, a randomly generated code is sent to the employee, who then has to type it into the screen. On the other hand, visitors and delivery persons are provided with a speech-to-text service where they utter the name of the employee that they want to meet, and the system then sends a notification to the right employee automatically. The hardware of the system is constituted by two Raspberry Pi, a 7-inch LCD-touch display, a camera, and a sound card with a microphone and speaker. To carry out face recognition and speech-to-text conversion, the cloud-based platforms Amazon Web Services and the Google Speech-to-Text API service are used respectively. The two-step face authentication mechanism for employees provides an increased level of security and protection against spoofing attacks without the need of carrying key-tags or access cards, while disturbances by visitors or couriers are minimized by notifying their arrival to the right employee, without disturbing other co-workers by means of ring-bells.
Research on several key technologies in practical speech emotion recognition
Sep 27, 2017In this dissertation the practical speech emotion recognition technology is studied, including several cognitive related emotion types, namely fidgetiness, confidence and tiredness. The high quality of naturalistic emotional speech data is the basis of this research. The following techniques are used for inducing practical emotional speech: cognitive task, computer game, noise stimulation, sleep deprivation and movie clips. A practical speech emotion recognition system is studied based on Gaussian mixture model. A two-class classifier set is adopted for performance improvement under the small sample case. Considering the context information in continuous emotional speech, a Gaussian mixture model embedded with Markov networks is proposed. A further study is carried out for system robustness analysis. First, noise reduction algorithm based on auditory masking properties is fist introduced to the practical speech emotion recognition. Second, to deal with the complicated unknown emotion types under real situation, an emotion recognition method with rejection ability is proposed, which enhanced the system compatibility against unknown emotion samples. Third, coping with the difficulties brought by a large number of unknown speakers, an emotional feature normalization method based on speaker-sensitive feature clustering is proposed. Fourth, by adding the electrocardiogram channel, a bi-modal emotion recognition system based on speech signals and electrocardiogram signals is first introduced. The speech emotion recognition methods studied in this dissertation may be extended into the cross-language speech emotion recognition and the whispered speech emotion recognition.
Attention-Based Models for Speech Recognition
Jun 24, 2015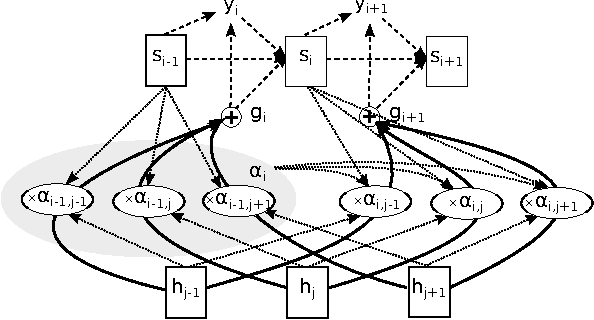

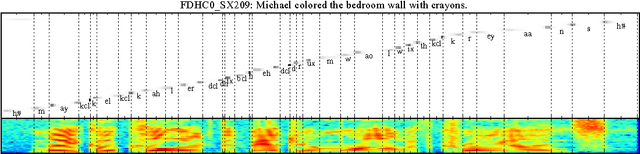
Recurrent sequence generators conditioned on input data through an attention mechanism have recently shown very good performance on a range of tasks in- cluding machine translation, handwriting synthesis and image caption gen- eration. We extend the attention-mechanism with features needed for speech recognition. We show that while an adaptation of the model used for machine translation in reaches a competitive 18.7% phoneme error rate (PER) on the TIMIT phoneme recognition task, it can only be applied to utterances which are roughly as long as the ones it was trained on. We offer a qualitative explanation of this failure and propose a novel and generic method of adding location-awareness to the attention mechanism to alleviate this issue. The new method yields a model that is robust to long inputs and achieves 18% PER in single utterances and 20% in 10-times longer (repeated) utterances. Finally, we propose a change to the at- tention mechanism that prevents it from concentrating too much on single frames, which further reduces PER to 17.6% level.
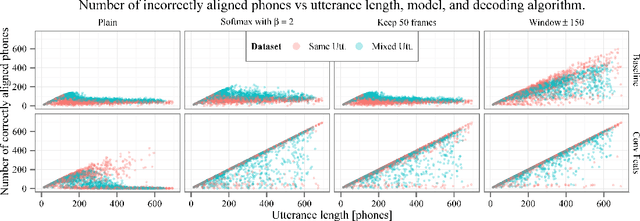
End-To-End Speech Recognition Using A High Rank LSTM-CTC Based Model
Mar 12, 2019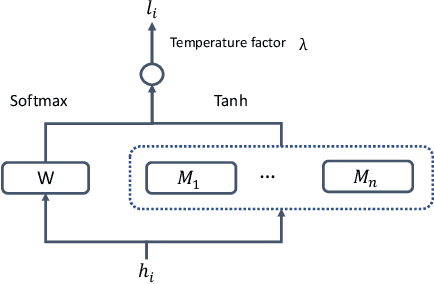
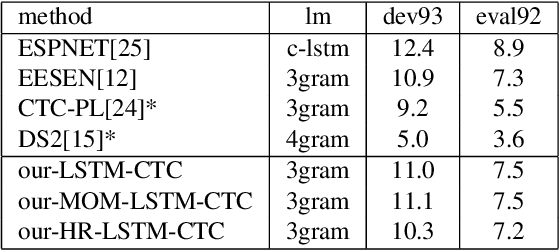
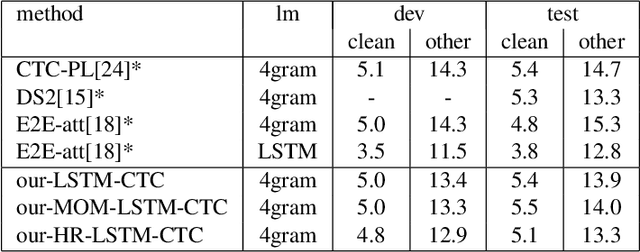
Long Short Term Memory Connectionist Temporal Classification (LSTM-CTC) based end-to-end models are widely used in speech recognition due to its simplicity in training and efficiency in decoding. In conventional LSTM-CTC based models, a bottleneck projection matrix maps the hidden feature vectors obtained from LSTM to softmax output layer. In this paper, we propose to use a high rank projection layer to replace the projection matrix. The output from the high rank projection layer is a weighted combination of vectors that are projected from the hidden feature vectors via different projection matrices and non-linear activation function. The high rank projection layer is able to improve the expressiveness of LSTM-CTC models. The experimental results show that on Wall Street Journal (WSJ) corpus and LibriSpeech data set, the proposed method achieves 4%-6% relative word error rate (WER) reduction over the baseline CTC system. They outperform other published CTC based end-to-end (E2E) models under the condition that no external data or data augmentation is applied. Code has been made available at https://github.com/mobvoi/lstm_ctc.
Ensemble of Jointly Trained Deep Neural Network-Based Acoustic Models for Reverberant Speech Recognition
Aug 17, 2016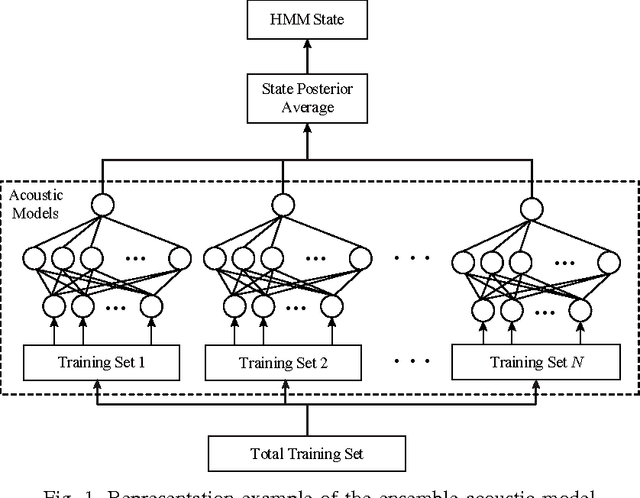
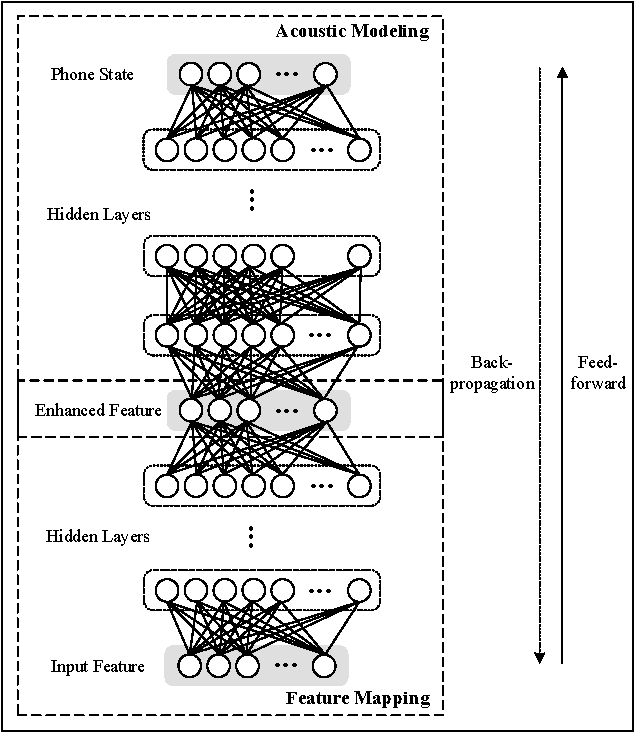
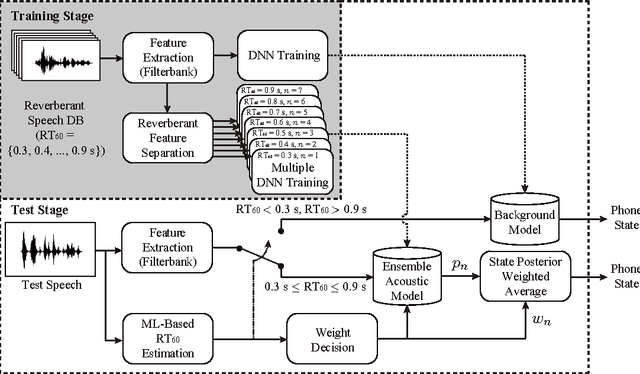
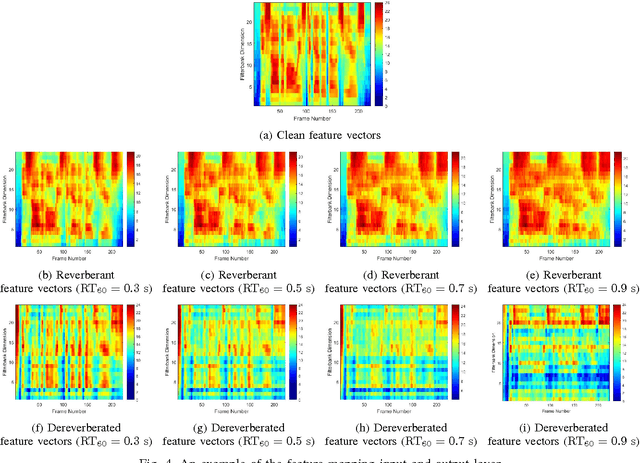
Distant speech recognition is a challenge, particularly due to the corruption of speech signals by reverberation caused by large distances between the speaker and microphone. In order to cope with a wide range of reverberations in real-world situations, we present novel approaches for acoustic modeling including an ensemble of deep neural networks (DNNs) and an ensemble of jointly trained DNNs. First, multiple DNNs are established, each of which corresponds to a different reverberation time 60 (RT60) in a setup step. Also, each model in the ensemble of DNN acoustic models is further jointly trained, including both feature mapping and acoustic modeling, where the feature mapping is designed for the dereverberation as a front-end. In a testing phase, the two most likely DNNs are chosen from the DNN ensemble using maximum a posteriori (MAP) probabilities, computed in an online fashion by using maximum likelihood (ML)-based blind RT60 estimation and then the posterior probability outputs from two DNNs are combined using the ML-based weights as a simple average. Extensive experiments demonstrate that the proposed approach leads to substantial improvements in speech recognition accuracy over the conventional DNN baseline systems under diverse reverberant conditions.
Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos
Jun 09, 2022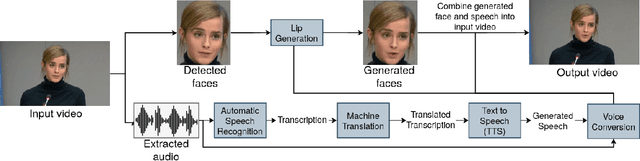
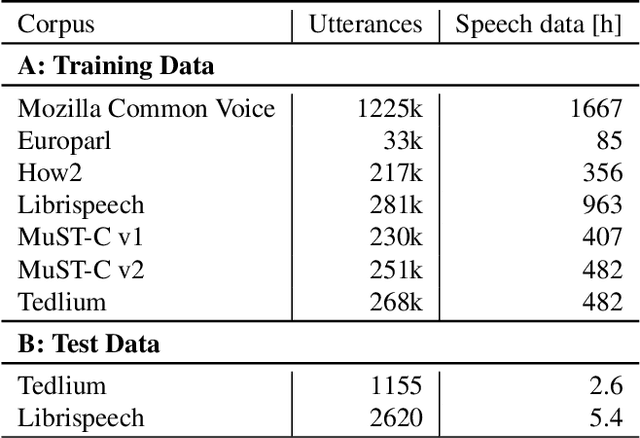
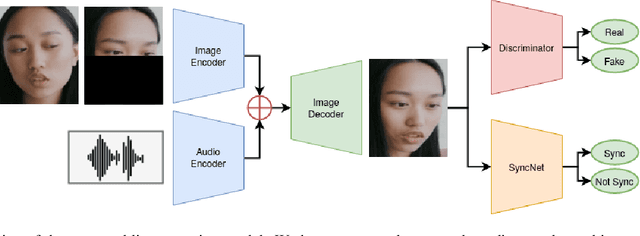
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.