 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Joint Modeling of Accents and Acoustics for Multi-Accent Speech Recognition
Feb 07, 2018
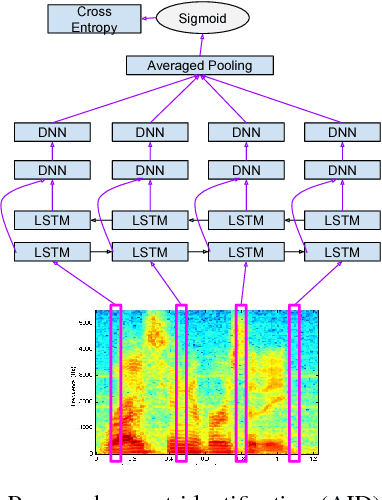
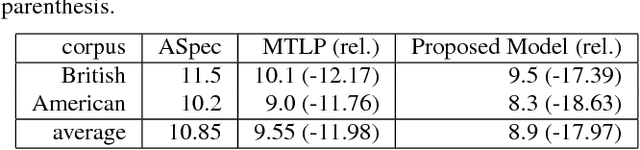
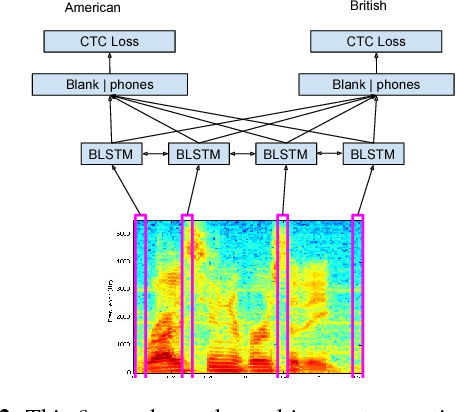

The performance of automatic speech recognition systems degrades with increasing mismatch between the training and testing scenarios. Differences in speaker accents are a significant source of such mismatch. The traditional approach to deal with multiple accents involves pooling data from several accents during training and building a single model in multi-task fashion, where tasks correspond to individual accents. In this paper, we explore an alternate model where we jointly learn an accent classifier and a multi-task acoustic model. Experiments on the American English Wall Street Journal and British English Cambridge corpora demonstrate that our joint model outperforms the strong multi-task acoustic model baseline. We obtain a 5.94% relative improvement in word error rate on British English, and 9.47% relative improvement on American English. This illustrates that jointly modeling with accent information improves acoustic model performance.
Trace norm regularization and faster inference for embedded speech recognition RNNs
Feb 06, 2018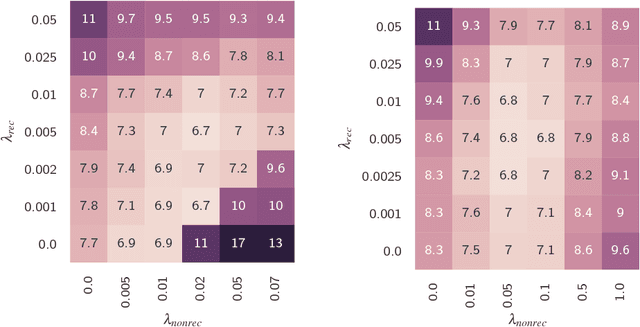

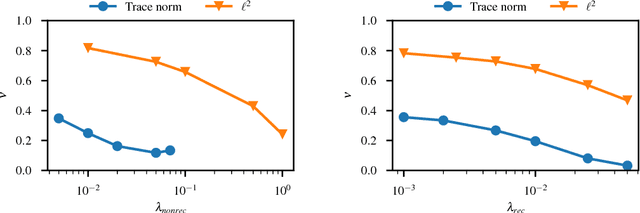
We propose and evaluate new techniques for compressing and speeding up dense matrix multiplications as found in the fully connected and recurrent layers of neural networks for embedded large vocabulary continuous speech recognition (LVCSR). For compression, we introduce and study a trace norm regularization technique for training low rank factored versions of matrix multiplications. Compared to standard low rank training, we show that our method leads to good accuracy versus number of parameter trade-offs and can be used to speed up training of large models. For speedup, we enable faster inference on ARM processors through new open sourced kernels optimized for small batch sizes, resulting in 3x to 7x speed ups over the widely used gemmlowp library. Beyond LVCSR, we expect our techniques and kernels to be more generally applicable to embedded neural networks with large fully connected or recurrent layers.
Cloud-Based Face and Speech Recognition for Access Control Applications
May 08, 2020
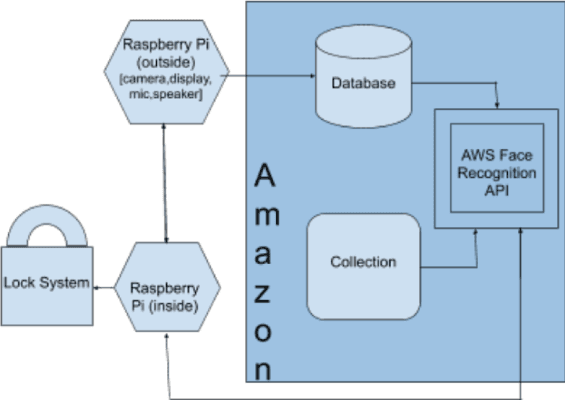
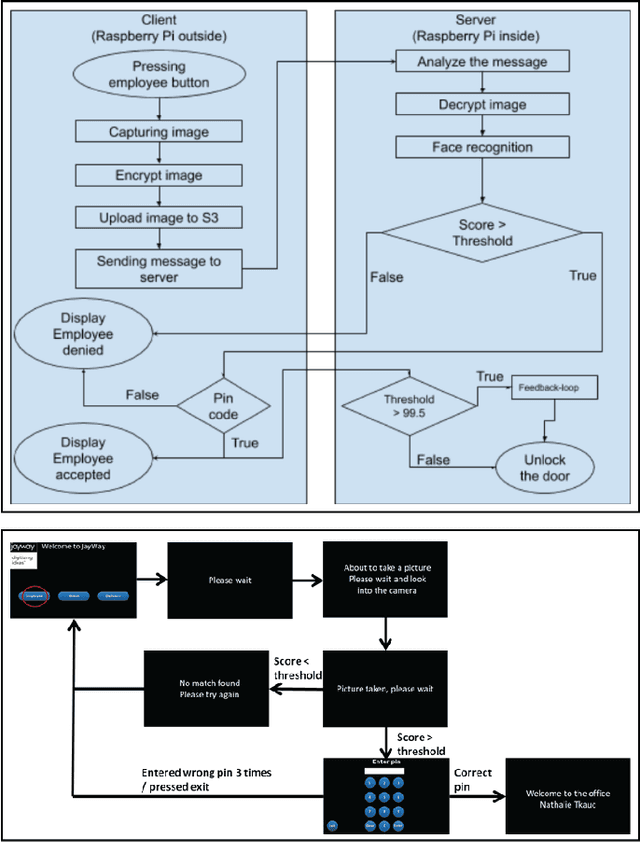
This paper describes the implementation of a system to recognize employees and visitors wanting to gain access to a physical office through face images and speech-to-text recognition. The system helps employees to unlock the entrance door via face recognition without the need of tag-keys or cards. To prevent spoofing attacks and increase security, a randomly generated code is sent to the employee, who then has to type it into the screen. On the other hand, visitors and delivery persons are provided with a speech-to-text service where they utter the name of the employee that they want to meet, and the system then sends a notification to the right employee automatically. The hardware of the system is constituted by two Raspberry Pi, a 7-inch LCD-touch display, a camera, and a sound card with a microphone and speaker. To carry out face recognition and speech-to-text conversion, the cloud-based platforms Amazon Web Services and the Google Speech-to-Text API service are used respectively. The two-step face authentication mechanism for employees provides an increased level of security and protection against spoofing attacks without the need of carrying key-tags or access cards, while disturbances by visitors or couriers are minimized by notifying their arrival to the right employee, without disturbing other co-workers by means of ring-bells.
Face-Dubbing++: Lip-Synchronous, Voice Preserving Translation of Videos
Jun 09, 2022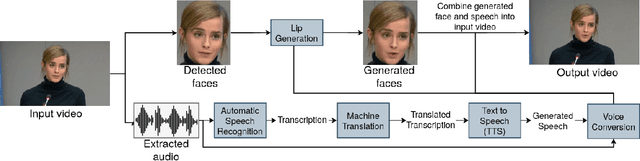
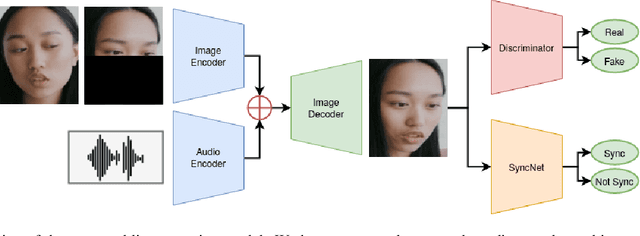
In this paper, we propose a neural end-to-end system for voice preserving, lip-synchronous translation of videos. The system is designed to combine multiple component models and produces a video of the original speaker speaking in the target language that is lip-synchronous with the target speech, yet maintains emphases in speech, voice characteristics, face video of the original speaker. The pipeline starts with automatic speech recognition including emphasis detection, followed by a translation model. The translated text is then synthesized by a Text-to-Speech model that recreates the original emphases mapped from the original sentence. The resulting synthetic voice is then mapped back to the original speakers' voice using a voice conversion model. Finally, to synchronize the lips of the speaker with the translated audio, a conditional generative adversarial network-based model generates frames of adapted lip movements with respect to the input face image as well as the output of the voice conversion model. In the end, the system combines the generated video with the converted audio to produce the final output. The result is a video of a speaker speaking in another language without actually knowing it. To evaluate our design, we present a user study of the complete system as well as separate evaluations of the single components. Since there is no available dataset to evaluate our whole system, we collect a test set and evaluate our system on this test set. The results indicate that our system is able to generate convincing videos of the original speaker speaking the target language while preserving the original speaker's characteristics. The collected dataset will be shared.
Accelerating recurrent neural network language model based online speech recognition system
Jan 30, 2018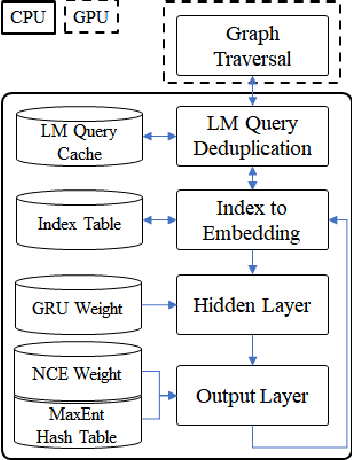
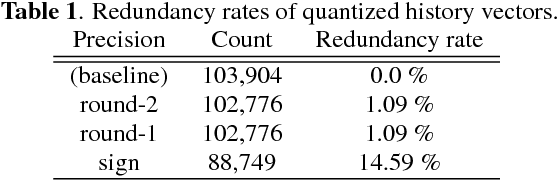
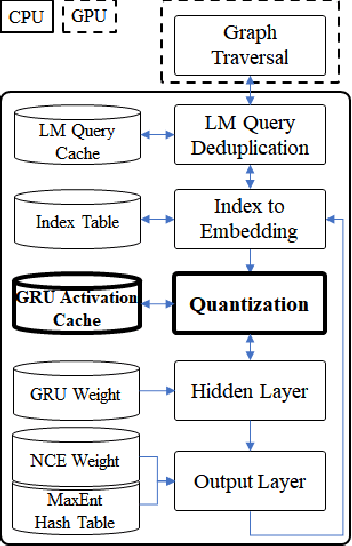
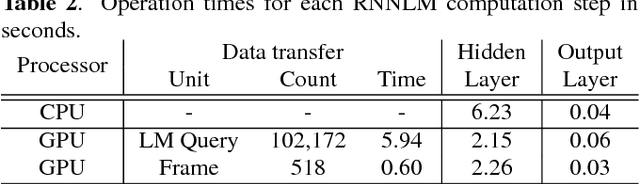
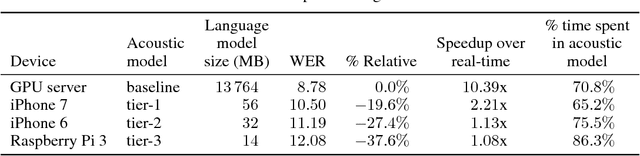
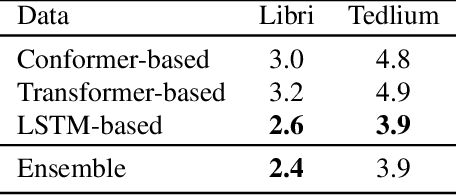
This paper presents methods to accelerate recurrent neural network based language models (RNNLMs) for online speech recognition systems. Firstly, a lossy compression of the past hidden layer outputs (history vector) with caching is introduced in order to reduce the number of LM queries. Next, RNNLM computations are deployed in a CPU-GPU hybrid manner, which computes each layer of the model on a more advantageous platform. The added overhead by data exchanges between CPU and GPU is compensated through a frame-wise batching strategy. The performance of the proposed methods evaluated on LibriSpeech test sets indicates that the reduction in history vector precision improves the average recognition speed by 1.23 times with minimum degradation in accuracy. On the other hand, the CPU-GPU hybrid parallelization enables RNNLM based real-time recognition with a four times improvement in speed.
Unsupervised Representation Learning with Future Observation Prediction for Speech Emotion Recognition
Oct 24, 2019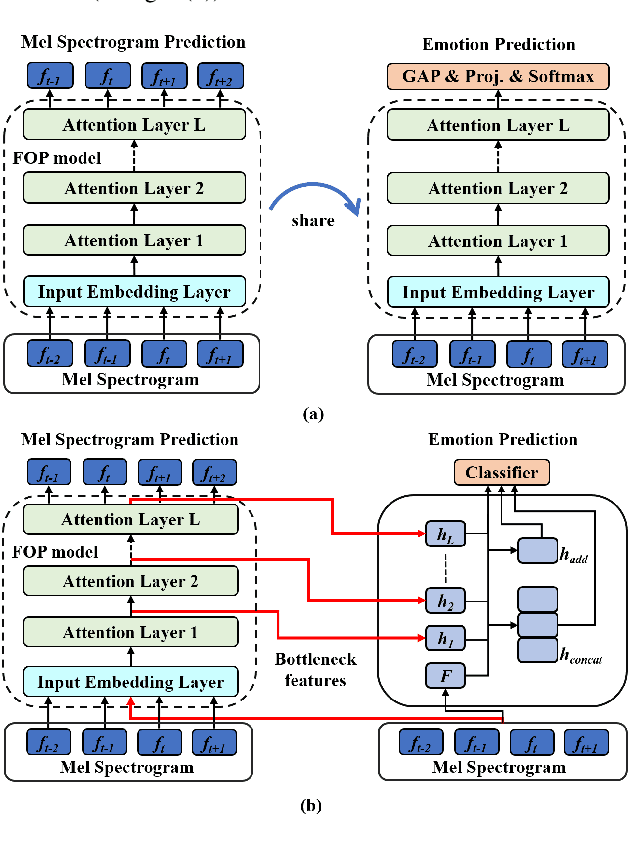

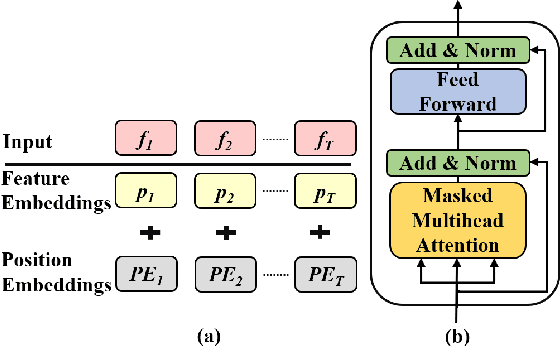
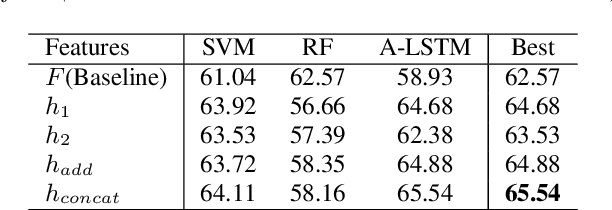
Prior works on speech emotion recognition utilize various unsupervised learning approaches to deal with low-resource samples. However, these methods pay less attention to modeling the long-term dynamic dependency, which is important for speech emotion recognition. To deal with this problem, this paper combines the unsupervised representation learning strategy -- Future Observation Prediction (FOP), with transfer learning approaches (such as Fine-tuning and Hypercolumns). To verify the effectiveness of the proposed method, we conduct experiments on the IEMOCAP database. Experimental results demonstrate that our method is superior to currently advanced unsupervised learning strategies.
Minimising Biasing Word Errors for Contextual ASR with the Tree-Constrained Pointer Generator
May 18, 2022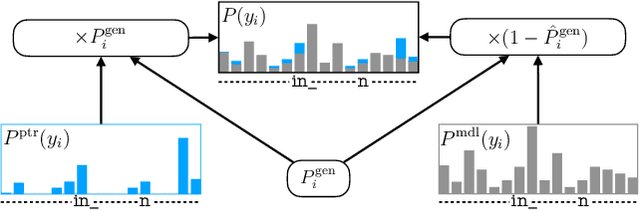
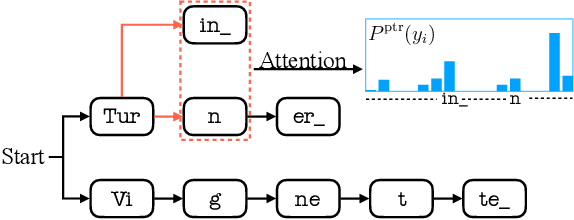
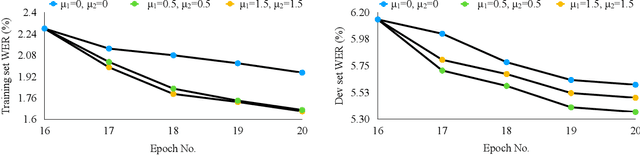
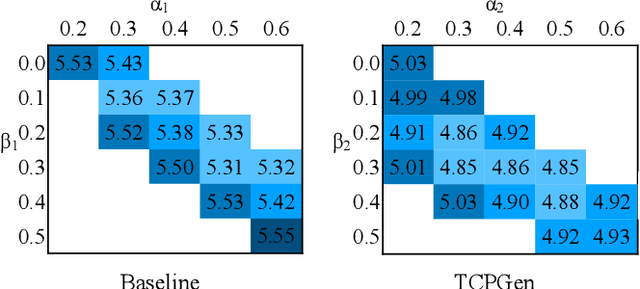
Contextual knowledge is essential for reducing speech recognition errors on high-valued long-tail words. This paper proposes a novel tree-constrained pointer generator (TCPGen) component that enables end-to-end ASR models to bias towards a list of long-tail words obtained using external contextual information. With only a small overhead in memory use and computation cost, TCPGen can structure thousands of biasing words efficiently into a symbolic prefix-tree and creates a neural shortcut between the tree and the final ASR output to facilitate the recognition of the biasing words. To enhance TCPGen, we further propose a novel minimum biasing word error (MBWE) loss that directly optimises biasing word errors during training, along with a biasing-word-driven language model discounting (BLMD) method during the test. All contextual ASR systems were evaluated on the public Librispeech audiobook corpus and the data from the dialogue state tracking challenges (DSTC) with the biasing lists extracted from the dialogue-system ontology. Consistent word error rate (WER) reductions were achieved with TCPGen, which were particularly significant on the biasing words with around 40\% relative reductions in the recognition error rates. MBWE and BLMD further improved the effectiveness of TCPGen and achieved more significant WER reductions on the biasing words. TCPGen also achieved zero-shot learning of words not in the audio training set with large WER reductions on the out-of-vocabulary words in the biasing list.
Linguistic-Acoustic Similarity Based Accent Shift for Accent Recognition
Apr 07, 2022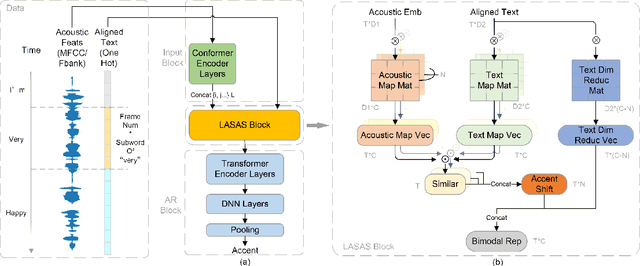
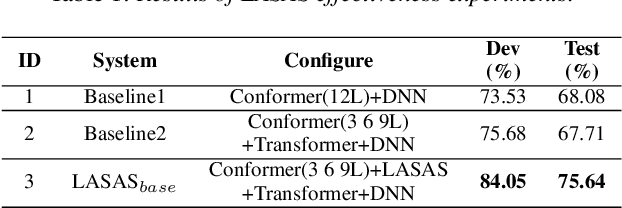
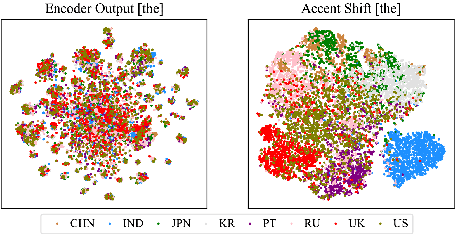
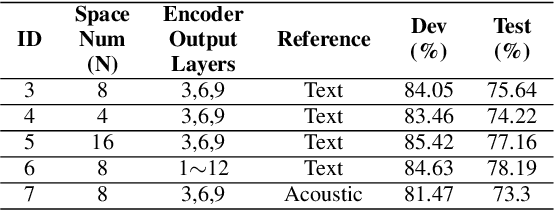
General accent recognition (AR) models tend to directly extract low-level information from spectrums, which always significantly overfit on speakers or channels. Considering accent can be regarded as a series of shifts relative to native pronunciation, distinguishing accents will be an easier task with accent shift as input. But due to the lack of native utterance as an anchor, estimating the accent shift is difficult. In this paper, we propose linguistic-acoustic similarity based accent shift (LASAS) for AR tasks. For an accent speech utterance, after mapping the corresponding text vector to multiple accent-associated spaces as anchors, its accent shift could be estimated by the similarities between the acoustic embedding and those anchors. Then, we concatenate the accent shift with a dimension-reduced text vector to obtain a linguistic-acoustic bimodal representation. Compared with pure acoustic embedding, the bimodal representation is richer and more clear by taking full advantage of both linguistic and acoustic information, which can effectively improve AR performance. Experiments on Accented English Speech Recognition Challenge (AESRC) dataset show that our method achieves 77.42% accuracy on Test set, obtaining a 6.94% relative improvement over a competitive system in the challenge.
Three-Module Modeling For End-to-End Spoken Language Understanding Using Pre-trained DNN-HMM-Based Acoustic-Phonetic Model
Apr 07, 2022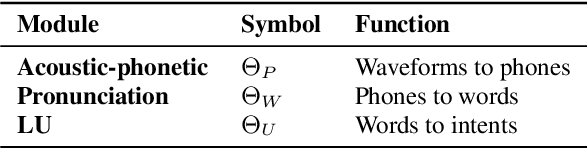
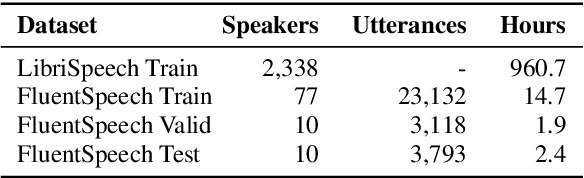
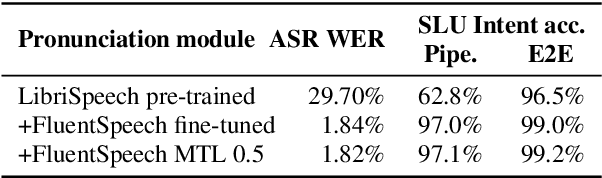

In spoken language understanding (SLU), what the user says is converted to his/her intent. Recent work on end-to-end SLU has shown that accuracy can be improved via pre-training approaches. We revisit ideas presented by Lugosch et al. using speech pre-training and three-module modeling; however, to ease construction of the end-to-end SLU model, we use as our phoneme module an open-source acoustic-phonetic model from a DNN-HMM hybrid automatic speech recognition (ASR) system instead of training one from scratch. Hence we fine-tune on speech only for the word module, and we apply multi-target learning (MTL) on the word and intent modules to jointly optimize SLU performance. MTL yields a relative reduction of 40% in intent-classification error rates (from 1.0% to 0.6%). Note that our three-module model is a streaming method. The final outcome of the proposed three-module modeling approach yields an intent accuracy of 99.4% on FluentSpeech, an intent error rate reduction of 50% compared to that of Lugosch et al. Although we focus on real-time streaming methods, we also list non-streaming methods for comparison.
A Novel Speech Feature Fusion Algorithm for Text-Independent Speaker Recognition
Dec 01, 2022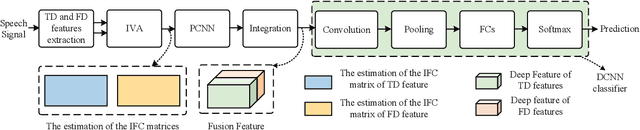
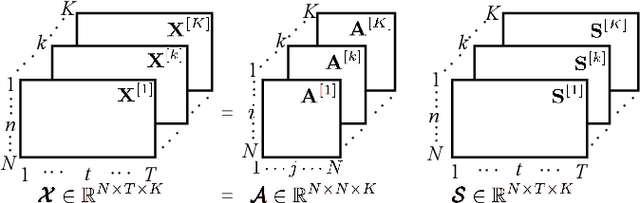
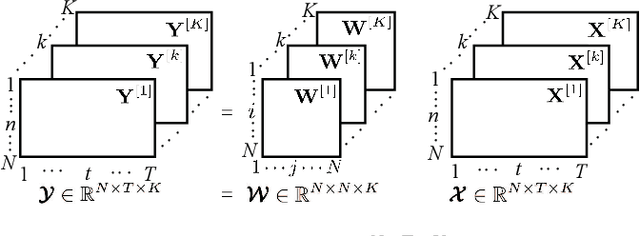
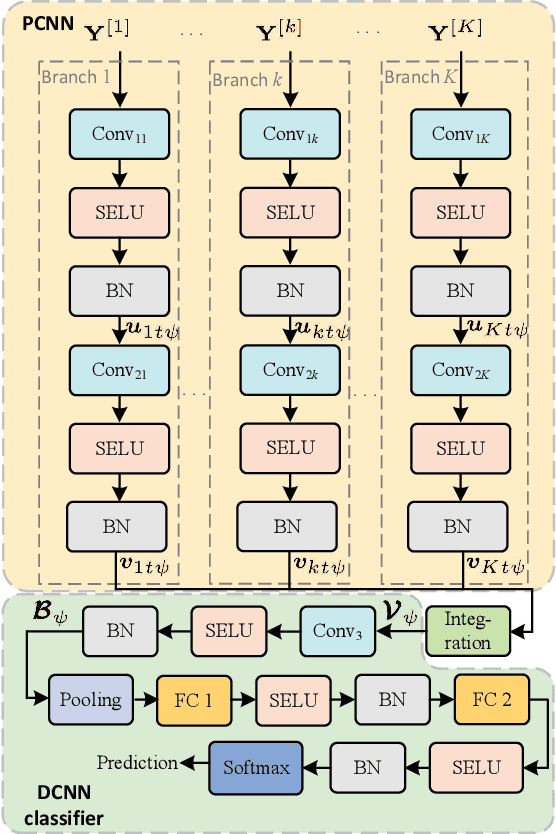
A novel speech feature fusion algorithm with independent vector analysis (IVA) and parallel convolutional neural network (PCNN) is proposed for text-independent speaker recognition. Firstly, some different feature types, such as the time domain (TD) features and the frequency domain (FD) features, can be extracted from a speaker's speech, and the TD and the FD features can be considered as the linear mixtures of independent feature components (IFCs) with an unknown mixing system. To estimate the IFCs, the TD and the FD features of the speaker's speech are concatenated to build the TD and the FD feature matrix, respectively. Then, a feature tensor of the speaker's speech is obtained by paralleling the TD and the FD feature matrix. To enhance the dependence on different feature types and remove the redundancies of the same feature type, the independent vector analysis (IVA) can be used to estimate the IFC matrices of TD and FD features with the feature tensor. The IFC matrices are utilized as the input of the PCNN to extract the deep features of the TD and FD features, respectively. The deep features can be integrated to obtain the fusion feature of the speaker's speech. Finally, the fusion feature of the speaker's speech is employed as the input of a deep convolutional neural network (DCNN) classifier for speaker recognition. The experimental results show the effectiveness and performances of the proposed speaker recognition system.