 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
End-to-End Neural Segmental Models for Speech Recognition
Aug 15, 2017
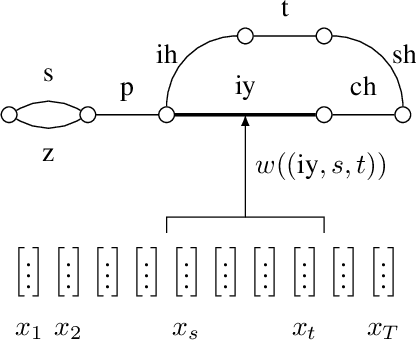
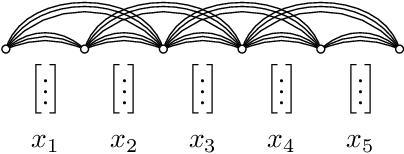
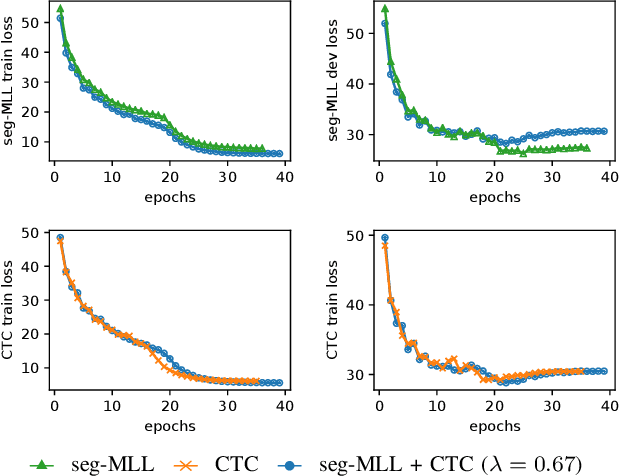
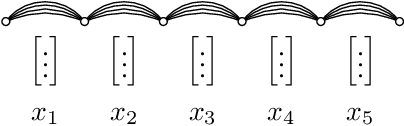
Segmental models are an alternative to frame-based models for sequence prediction, where hypothesized path weights are based on entire segment scores rather than a single frame at a time. Neural segmental models are segmental models that use neural network-based weight functions. Neural segmental models have achieved competitive results for speech recognition, and their end-to-end training has been explored in several studies. In this work, we review neural segmental models, which can be viewed as consisting of a neural network-based acoustic encoder and a finite-state transducer decoder. We study end-to-end segmental models with different weight functions, including ones based on frame-level neural classifiers and on segmental recurrent neural networks. We study how reducing the search space size impacts performance under different weight functions. We also compare several loss functions for end-to-end training. Finally, we explore training approaches, including multi-stage vs. end-to-end training and multitask training that combines segmental and frame-level losses.
Neural Architecture Search For LF-MMI Trained Time Delay Neural Networks
Jan 08, 2022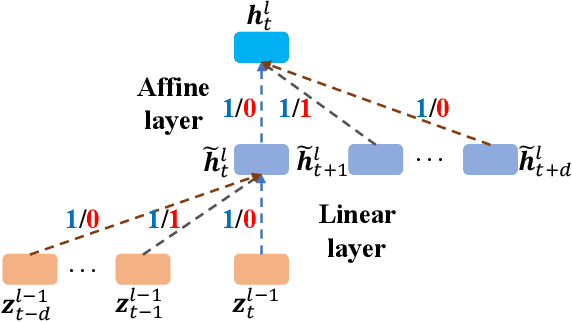
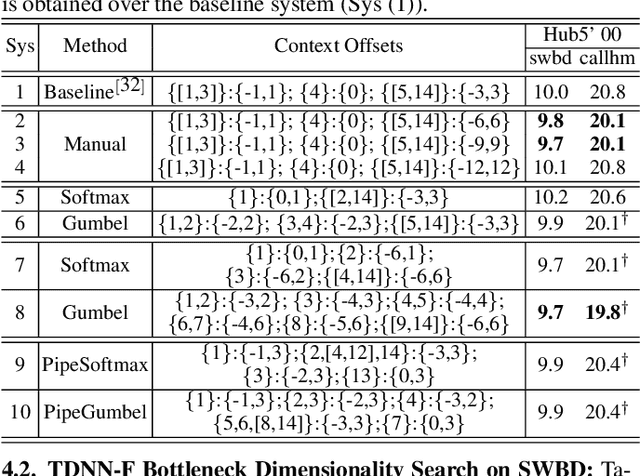
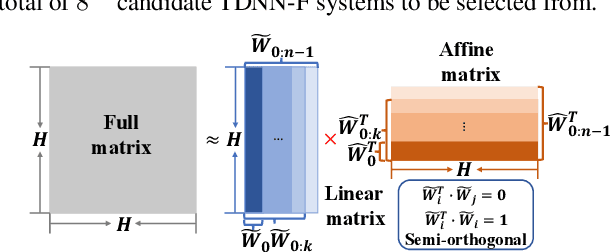
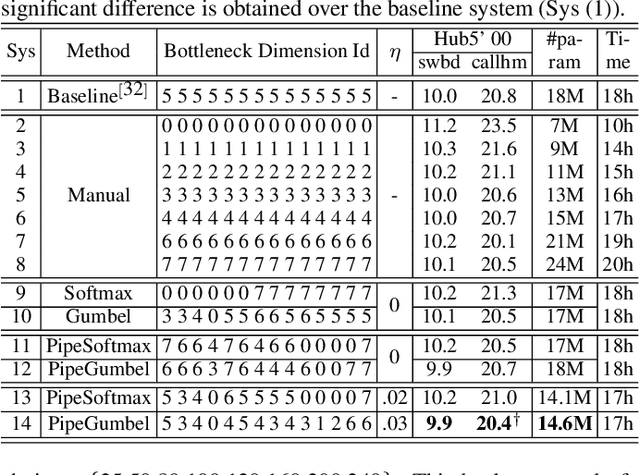
State-of-the-art automatic speech recognition (ASR) system development is data and computation intensive. The optimal design of deep neural networks (DNNs) for these systems often require expert knowledge and empirical evaluation. In this paper, a range of neural architecture search (NAS) techniques are used to automatically learn two types of hyper-parameters of factored time delay neural networks (TDNN-Fs): i) the left and right splicing context offsets; and ii) the dimensionality of the bottleneck linear projection at each hidden layer. These techniques include the differentiable neural architecture search (DARTS) method integrating architecture learning with lattice-free MMI training; Gumbel-Softmax and pipelined DARTS methods reducing the confusion over candidate architectures and improving the generalization of architecture selection; and Penalized DARTS incorporating resource constraints to balance the trade-off between performance and system complexity. Parameter sharing among TDNN-F architectures allows an efficient search over up to 7^28 different systems. Statistically significant word error rate (WER) reductions of up to 1.2% absolute and relative model size reduction of 31% were obtained over a state-of-the-art 300-hour Switchboard corpus trained baseline LF-MMI TDNN-F system featuring speed perturbation, i-Vector and learning hidden unit contribution (LHUC) based speaker adaptation as well as RNNLM rescoring. Performance contrasts on the same task against recent end-to-end systems reported in the literature suggest the best NAS auto-configured system achieves state-of-the-art WERs of 9.9% and 11.1% on the NIST Hub5' 00 and Rt03s test sets respectively with up to 96% model size reduction. Further analysis using Bayesian learning shows that the proposed NAS approaches can effectively minimize the structural redundancy in the TDNN-F systems and reduce their model parameter uncertainty. Consistent performance improvements were also obtained on a UASpeech dysarthric speech recognition task.
Analysis of Deep Clustering as Preprocessing for Automatic Speech Recognition of Sparsely Overlapping Speech
May 09, 2019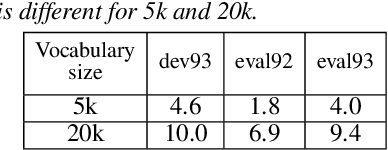
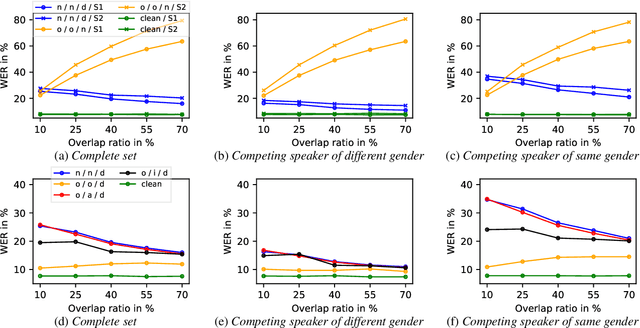
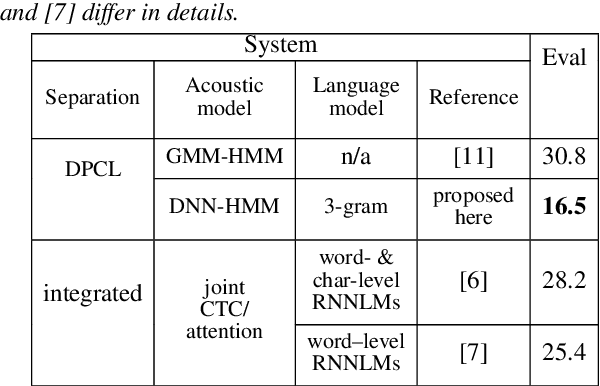
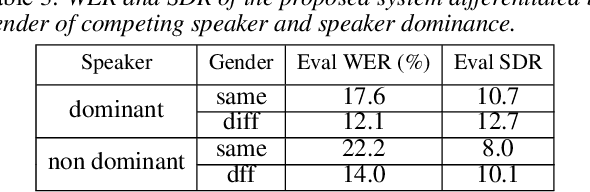
Significant performance degradation of automatic speech recognition (ASR) systems is observed when the audio signal contains cross-talk. One of the recently proposed approaches to solve the problem of multi-speaker ASR is the deep clustering (DPCL) approach. Combining DPCL with a state-of-the-art hybrid acoustic model, we obtain a word error rate (WER) of 16.5 % on the commonly used wsj0-2mix dataset, which is the best performance reported thus far to the best of our knowledge. The wsj0-2mix dataset contains simulated cross-talk where the speech of multiple speakers overlaps for almost the entire utterance. In a more realistic ASR scenario the audio signal contains significant portions of single-speaker speech and only part of the signal contains speech of multiple competing speakers. This paper investigates obstacles of applying DPCL as a preprocessing method for ASR in such a scenario of sparsely overlapping speech. To this end we present a data simulation approach, closely related to the wsj0-2mix dataset, generating sparsely overlapping speech datasets of arbitrary overlap ratio. The analysis of applying DPCL to sparsely overlapping speech is an important interim step between the fully overlapping datasets like wsj0-2mix and more realistic ASR datasets, such as CHiME-5 or AMI.
Multi-style Training for South African Call Centre Audio
Feb 15, 2022Mismatched data is a challenging problem for automatic speech recognition (ASR) systems. One of the most common techniques used to address mismatched data is multi-style training (MTR), a form of data augmentation that attempts to transform the training data to be more representative of the testing data; and to learn robust representations applicable to different conditions. This task can be very challenging if the test conditions are unknown. We explore the impact of different MTR styles on system performance when testing conditions are different from training conditions in the context of deep neural network hidden Markov model (DNN-HMM) ASR systems. A controlled environment is created using the LibriSpeech corpus, where we isolate the effect of different MTR styles on final system performance. We evaluate our findings on a South African call centre dataset that contains noisy, WAV49-encoded audio.
* 9 pages, 8 tables, Southern African Conference for Artificial Intelligence Research 2021, Part of the Communications in Computer and Information Science book series (CCIS, volume 1551, pp 111-124), Springer
Improving the Robustness of DistilHuBERT to Unseen Noisy Conditions via Data Augmentation, Curriculum Learning, and Multi-Task Enhancement
Nov 12, 2022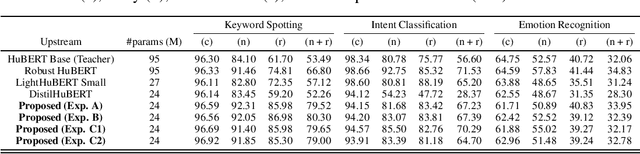
Self-supervised speech representation learning aims to extract meaningful factors from the speech signal that can later be used across different downstream tasks, such as speech and/or emotion recognition. Existing models, such as HuBERT, however, can be fairly large thus may not be suitable for edge speech applications. Moreover, realistic applications typically involve speech corrupted by noise and room reverberation, hence models need to provide representations that are robust to such environmental factors. In this study, we build on the so-called DistilHuBERT model, which distils HuBERT to a fraction of its original size, with three modifications, namely: (i) augment the training data with noise and reverberation, while the student model needs to distill the clean representations from the teacher model; (ii) introduce a curriculum learning approach where increasing levels of noise are introduced as the model trains, thus helping with convergence and with the creation of more robust representations; and (iii) introduce a multi-task learning approach where the model also reconstructs the clean waveform jointly with the distillation task, thus also acting as an enhancement step to ensure additional environment robustness to the representation. Experiments on three SUPERB tasks show the advantages of the proposed method not only relative to the original DistilHuBERT, but also to the original HuBERT, thus showing the advantages of the proposed method for ``in the wild'' edge speech applications.
Phoneme-Based Contextualization for Cross-Lingual Speech Recognition in End-to-End Models
Jul 01, 2019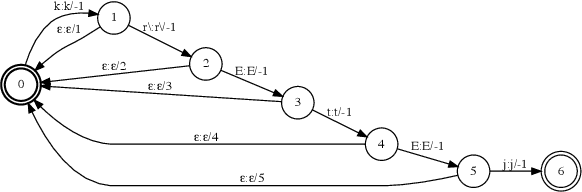


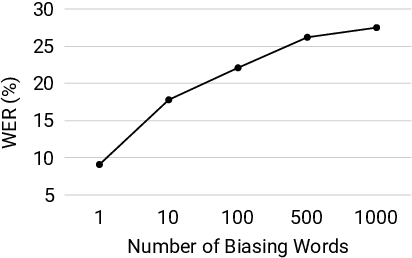
Contextual automatic speech recognition, i.e., biasing recognition towards a given context (e.g. user's playlists, or contacts), is challenging in end-to-end (E2E) models. Such models maintain a limited number of candidates during beam-search decoding, and have been found to recognize rare named entities poorly. The problem is exacerbated when biasing towards proper nouns in foreign languages, e.g., geographic location names, which are virtually unseen in training and are thus out-of-vocabulary (OOV). While grapheme or wordpiece E2E models might have a difficult time spelling OOV words, phonemes are more acoustically salient and past work has shown that E2E phoneme models can better predict such words. In this work, we propose an E2E model containing both English wordpieces and phonemes in the modeling space, and perform contextual biasing of foreign words at the phoneme level by mapping pronunciations of foreign words into similar English phonemes. In experimental evaluations, we find that the proposed approach performs 16% better than a grapheme-only biasing model, and 8% better than a wordpiece-only biasing model on a foreign place name recognition task, with only slight degradation on regular English tasks.
Multilingual Bottleneck Features for Improving ASR Performance of Code-Switched Speech in Under-Resourced Languages
Oct 31, 2020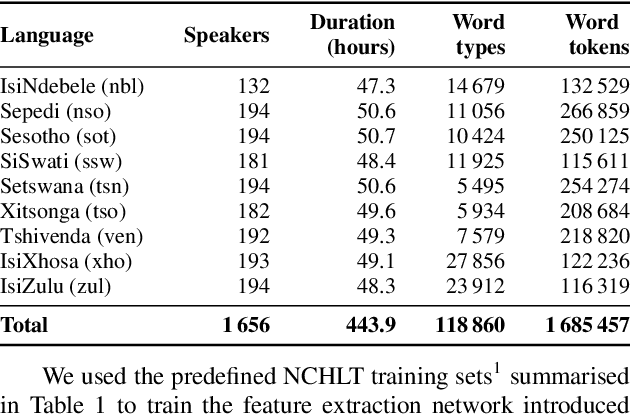
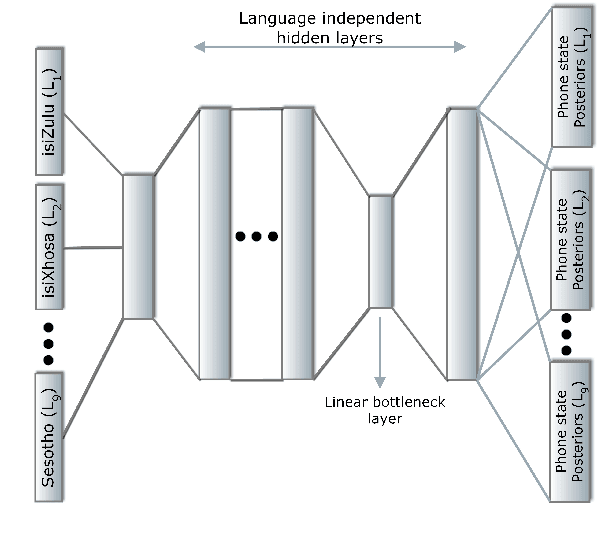
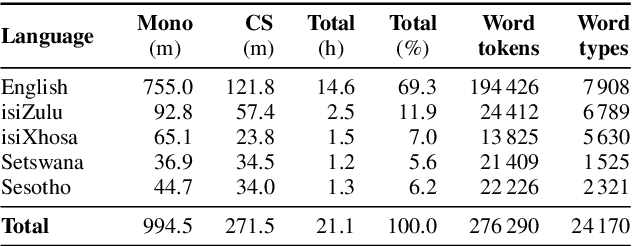
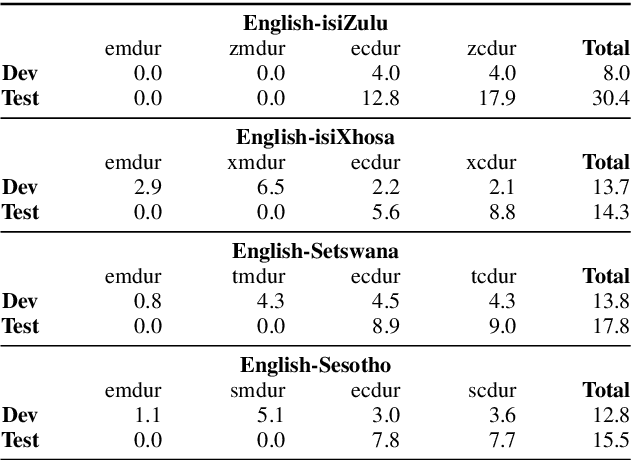
In this work, we explore the benefits of using multilingual bottleneck features (mBNF) in acoustic modelling for the automatic speech recognition of code-switched (CS) speech in African languages. The unavailability of annotated corpora in the languages of interest has always been a primary challenge when developing speech recognition systems for this severely under-resourced type of speech. Hence, it is worthwhile to investigate the potential of using speech corpora available for other better-resourced languages to improve speech recognition performance. To achieve this, we train a mBNF extractor using nine Southern Bantu languages that form part of the freely available multilingual NCHLT corpus. We append these mBNFs to the existing MFCCs, pitch features and i-vectors to train acoustic models for automatic speech recognition (ASR) in the target code-switched languages. Our results show that the inclusion of the mBNF features leads to clear performance improvements over a baseline trained without the mBNFs for code-switched English-isiZulu, English-isiXhosa, English-Sesotho and English-Setswana speech.
* In Proceedings of The First Workshop on Speech Technologies for Code-Switching in Multilingual Communities
Error Correction in ASR using Sequence-to-Sequence Models
Feb 02, 2022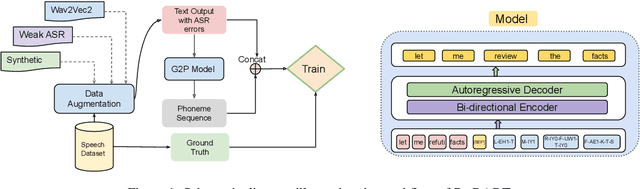


Post-editing in Automatic Speech Recognition (ASR) entails automatically correcting common and systematic errors produced by the ASR system. The outputs of an ASR system are largely prone to phonetic and spelling errors. In this paper, we propose to use a powerful pre-trained sequence-to-sequence model, BART, further adaptively trained to serve as a denoising model, to correct errors of such types. The adaptive training is performed on an augmented dataset obtained by synthetically inducing errors as well as by incorporating actual errors from an existing ASR system. We also propose a simple approach to rescore the outputs using word level alignments. Experimental results on accented speech data demonstrate that our strategy effectively rectifies a significant number of ASR errors and produces improved WER results when compared against a competitive baseline.
Understanding Audio Features via Trainable Basis Functions
Apr 25, 2022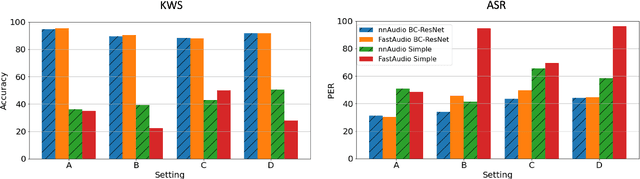

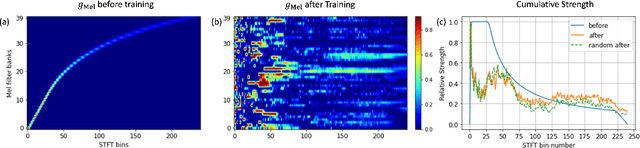
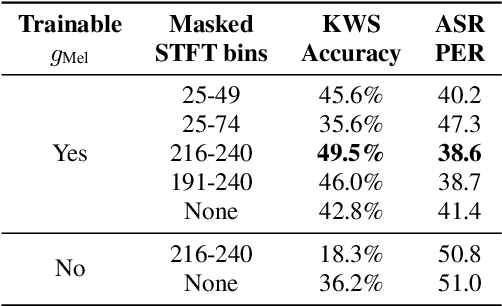
In this paper we explore the possibility of maximizing the information represented in spectrograms by making the spectrogram basis functions trainable. We experiment with two different tasks, namely keyword spotting (KWS) and automatic speech recognition (ASR). For most neural network models, the architecture and hyperparameters are typically fine-tuned and optimized in experiments. Input features, however, are often treated as fixed. In the case of audio, signals can be mainly expressed in two main ways: raw waveforms (time-domain) or spectrograms (time-frequency-domain). In addition, different spectrogram types are often used and tailored to fit different applications. In our experiments, we allow for this tailoring directly as part of the network. Our experimental results show that using trainable basis functions can boost the accuracy of Keyword Spotting (KWS) by 14.2 percentage points, and lower the Phone Error Rate (PER) by 9.5 percentage points. Although models using trainable basis functions become less effective as the model complexity increases, the trained filter shapes could still provide us with insights on which frequency bins are important for that specific task. From our experiments, we can conclude that trainable basis functions are a useful tool to boost the performance when the model complexity is limited.
Automated speech tools for helping communities process restricted-access corpora for language revival efforts
Apr 24, 2022
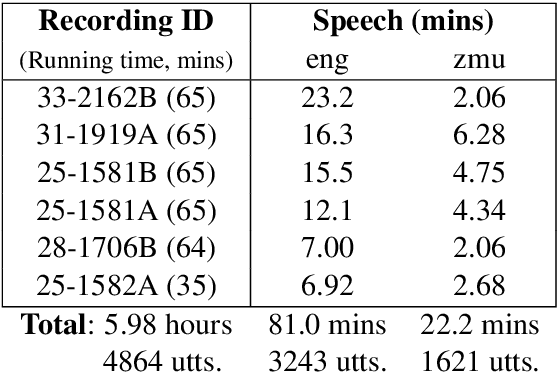
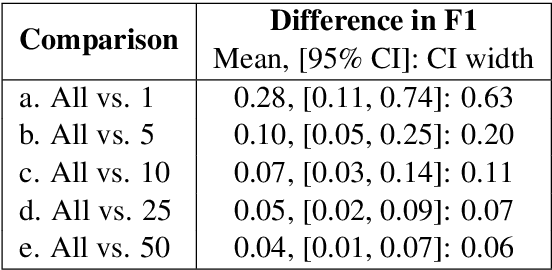
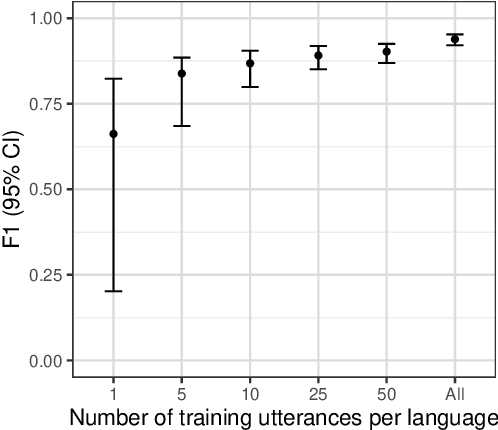
Many archival recordings of speech from endangered languages remain unannotated and inaccessible to community members and language learning programs. One bottleneck is the time-intensive nature of annotation. An even narrower bottleneck occurs for recordings with access constraints, such as language that must be vetted or filtered by authorised community members before annotation can begin. We propose a privacy-preserving workflow to widen both bottlenecks for recordings where speech in the endangered language is intermixed with a more widely-used language such as English for meta-linguistic commentary and questions (e.g. What is the word for 'tree'?). We integrate voice activity detection (VAD), spoken language identification (SLI), and automatic speech recognition (ASR) to transcribe the metalinguistic content, which an authorised person can quickly scan to triage recordings that can be annotated by people with lower levels of access. We report work-in-progress processing 136 hours archival audio containing a mix of English and Muruwari. Our collaborative work with the Muruwari custodian of the archival materials show that this workflow reduces metalanguage transcription time by 20% even given only minimal amounts of annotated training data: 10 utterances per language for SLI and for ASR at most 39 minutes, and possibly as little as 39 seconds.