 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
A Highly Efficient Distributed Deep Learning System For Automatic Speech Recognition
Jul 10, 2019
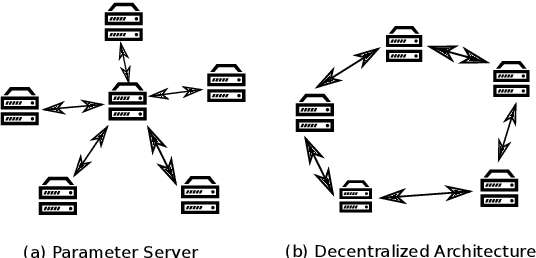

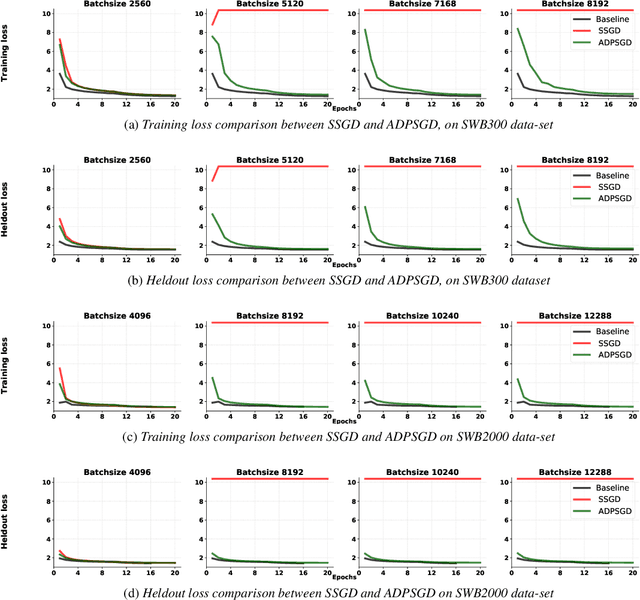
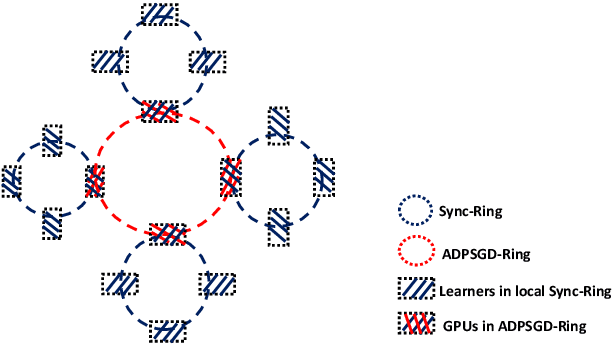
Modern Automatic Speech Recognition (ASR) systems rely on distributed deep learning to for quick training completion. To enable efficient distributed training, it is imperative that the training algorithms can converge with a large mini-batch size. In this work, we discovered that Asynchronous Decentralized Parallel Stochastic Gradient Descent (ADPSGD) can work with much larger batch size than commonly used Synchronous SGD (SSGD) algorithm. On commonly used public SWB-300 and SWB-2000 ASR datasets, ADPSGD can converge with a batch size 3X as large as the one used in SSGD, thus enable training at a much larger scale. Further, we proposed a Hierarchical-ADPSGD (H-ADPSGD) system in which learners on the same computing node construct a super learner via a fast allreduce implementation, and super learners deploy ADPSGD algorithm among themselves. On a 64 Nvidia V100 GPU cluster connected via a 100Gb/s Ethernet network, our system is able to train SWB-2000 to reach a 7.6% WER on the Hub5-2000 Switchboard (SWB) test-set and a 13.2% WER on the Call-home (CH) test-set in 5.2 hours. To the best of our knowledge, this is the fastest ASR training system that attains this level of model accuracy for SWB-2000 task to be ever reported in the literature.
Multi-encoder multi-resolution framework for end-to-end speech recognition
Nov 12, 2018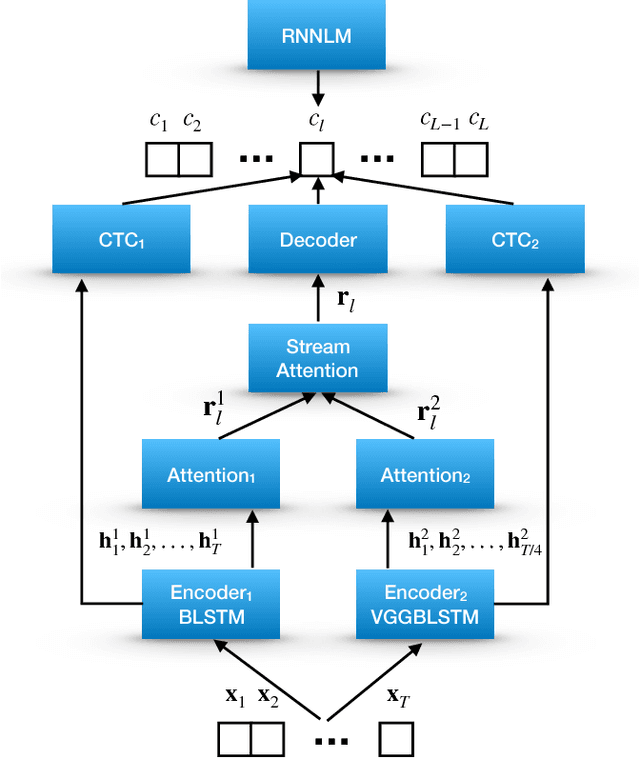
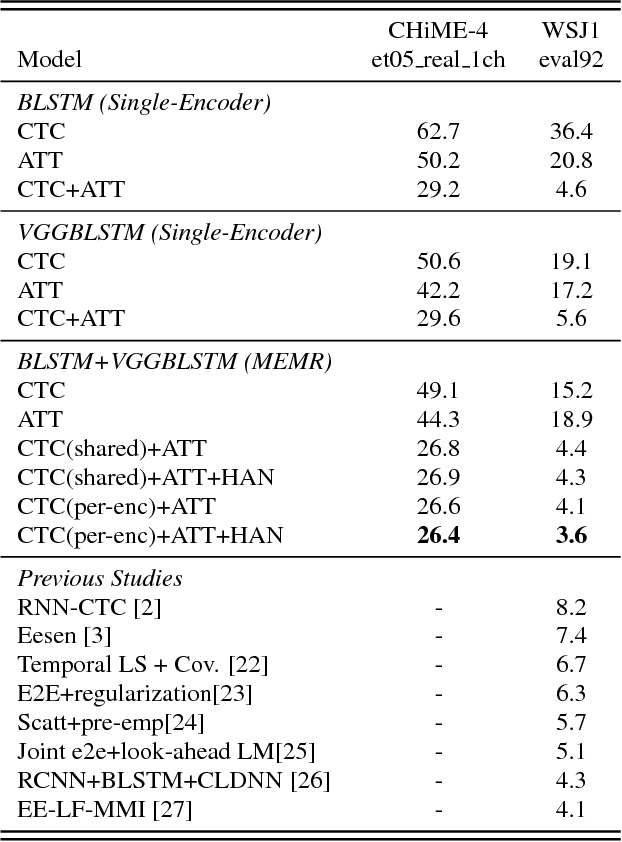
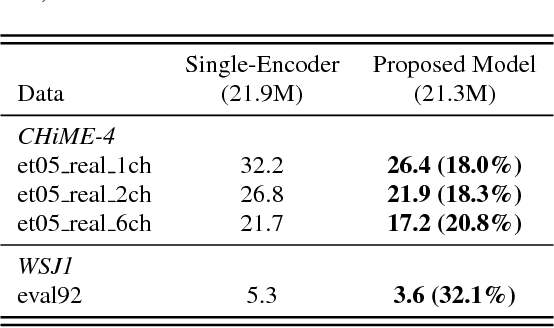

Attention-based methods and Connectionist Temporal Classification (CTC) network have been promising research directions for end-to-end Automatic Speech Recognition (ASR). The joint CTC/Attention model has achieved great success by utilizing both architectures during multi-task training and joint decoding. In this work, we present a novel Multi-Encoder Multi-Resolution (MEMR) framework based on the joint CTC/Attention model. Two heterogeneous encoders with different architectures, temporal resolutions and separate CTC networks work in parallel to extract complimentary acoustic information. A hierarchical attention mechanism is then used to combine the encoder-level information. To demonstrate the effectiveness of the proposed model, experiments are conducted on Wall Street Journal (WSJ) and CHiME-4, resulting in relative Word Error Rate (WER) reduction of 18.0-32.1%. Moreover, the proposed MEMR model achieves 3.6% WER in the WSJ eval92 test set, which is the best WER reported for an end-to-end system on this benchmark.
Liquid Structural State-Space Models
Sep 26, 2022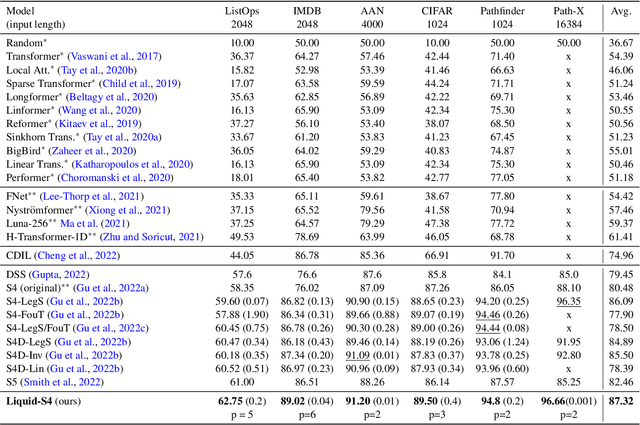
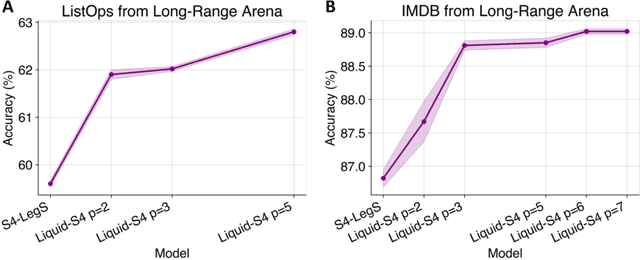
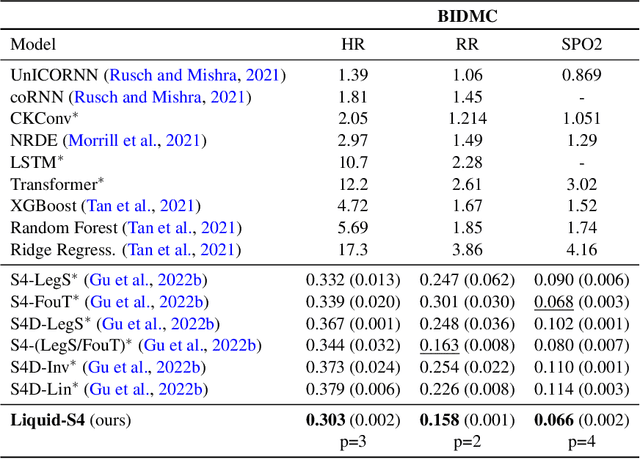
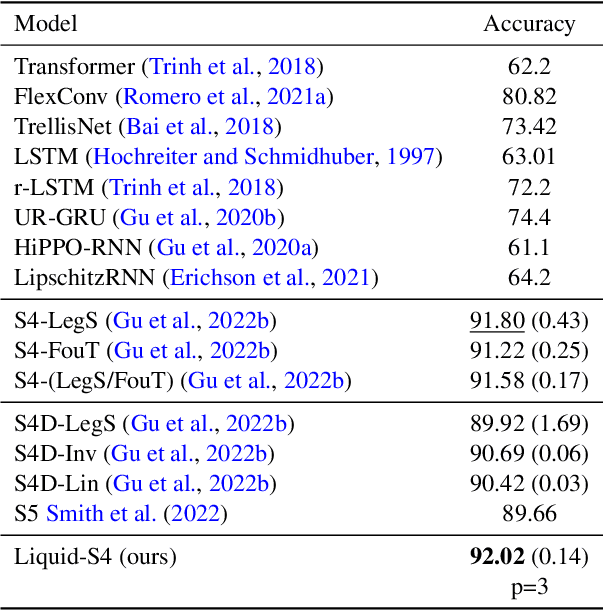
A proper parametrization of state transition matrices of linear state-space models (SSMs) followed by standard nonlinearities enables them to efficiently learn representations from sequential data, establishing the state-of-the-art on a large series of long-range sequence modeling benchmarks. In this paper, we show that we can improve further when the structural SSM such as S4 is given by a linear liquid time-constant (LTC) state-space model. LTC neural networks are causal continuous-time neural networks with an input-dependent state transition module, which makes them learn to adapt to incoming inputs at inference. We show that by using a diagonal plus low-rank decomposition of the state transition matrix introduced in S4, and a few simplifications, the LTC-based structural state-space model, dubbed Liquid-S4, achieves the new state-of-the-art generalization across sequence modeling tasks with long-term dependencies such as image, text, audio, and medical time-series, with an average performance of 87.32% on the Long-Range Arena benchmark. On the full raw Speech Command recognition, dataset Liquid-S4 achieves 96.78% accuracy with a 30% reduction in parameter counts compared to S4. The additional gain in performance is the direct result of the Liquid-S4's kernel structure that takes into account the similarities of the input sequence samples during training and inference.
Calibrate and Refine! A Novel and Agile Framework for ASR-error Robust Intent Detection
May 23, 2022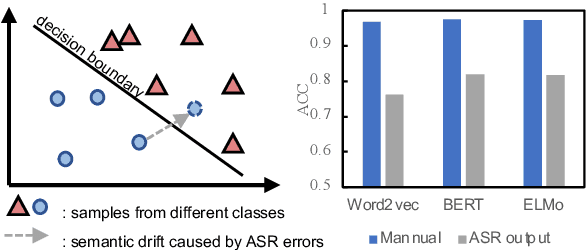
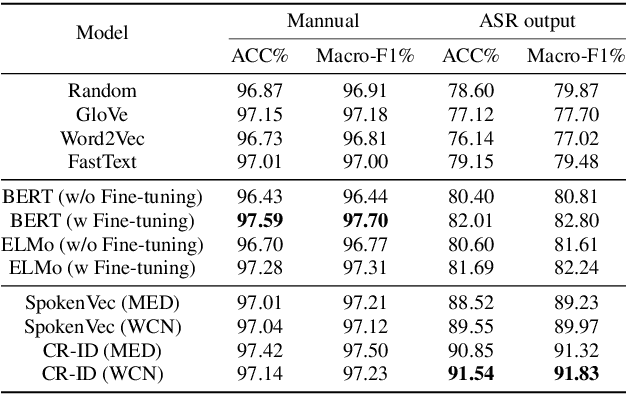
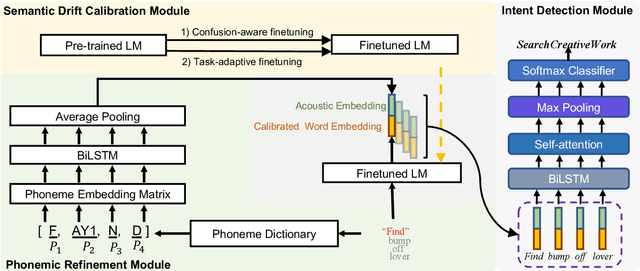
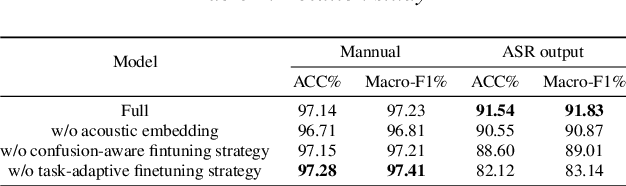
The past ten years have witnessed the rapid development of text-based intent detection, whose benchmark performances have already been taken to a remarkable level by deep learning techniques. However, automatic speech recognition (ASR) errors are inevitable in real-world applications due to the environment noise, unique speech patterns and etc, leading to sharp performance drop in state-of-the-art text-based intent detection models. Essentially, this phenomenon is caused by the semantic drift brought by ASR errors and most existing works tend to focus on designing new model structures to reduce its impact, which is at the expense of versatility and flexibility. Different from previous one-piece model, in this paper, we propose a novel and agile framework called CR-ID for ASR error robust intent detection with two plug-and-play modules, namely semantic drift calibration module (SDCM) and phonemic refinement module (PRM), which are both model-agnostic and thus could be easily integrated to any existing intent detection models without modifying their structures. Experimental results on SNIPS dataset show that, our proposed CR-ID framework achieves competitive performance and outperform all the baseline methods on ASR outputs, which verifies that CR-ID can effectively alleviate the semantic drift caused by ASR errors.
Spatio-Temporal Attention Mechanism and Knowledge Distillation for Lip Reading
Aug 07, 2021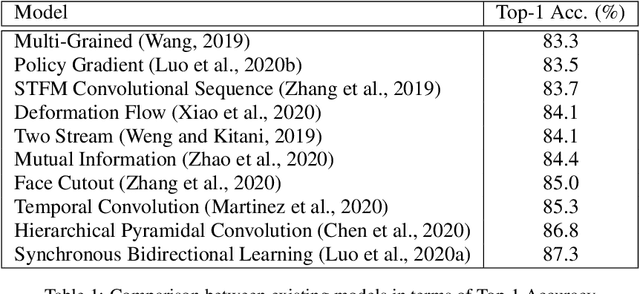
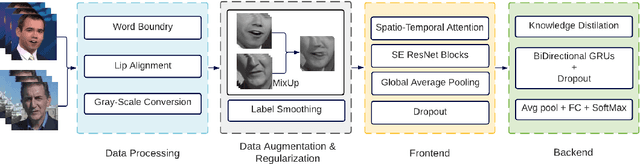
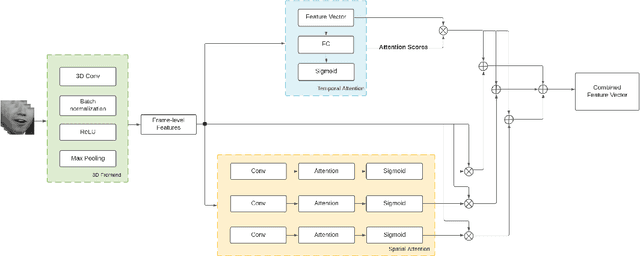

Despite the advancement in the domain of audio and audio-visual speech recognition, visual speech recognition systems are still quite under-explored due to the visual ambiguity of some phonemes. In this work, we propose a new lip-reading model that combines three contributions. First, the model front-end adopts a spatio-temporal attention mechanism to help extract the informative data from the input visual frames. Second, the model back-end utilizes a sequence-level and frame-level Knowledge Distillation (KD) techniques that allow leveraging audio data during the visual model training. Third, a data preprocessing pipeline is adopted that includes facial landmarks detection-based lip-alignment. On LRW lip-reading dataset benchmark, a noticeable accuracy improvement is demonstrated; the spatio-temporal attention, Knowledge Distillation, and lip-alignment contributions achieved 88.43%, 88.64%, and 88.37% respectively.
Latent Dirichlet Allocation Based Acoustic Data Selection for Automatic Speech Recognition
Jul 02, 2019

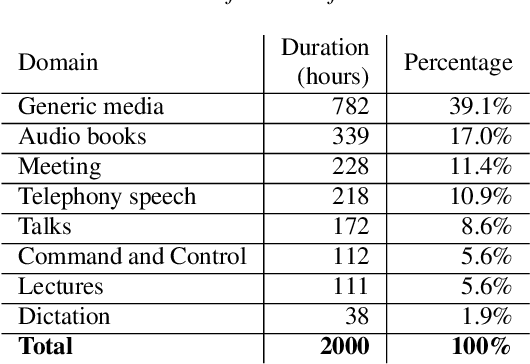
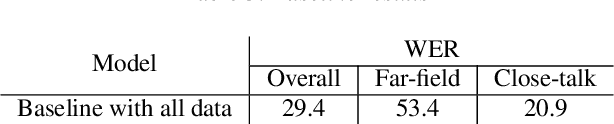
Selecting in-domain data from a large pool of diverse and out-of-domain data is a non-trivial problem. In most cases simply using all of the available data will lead to sub-optimal and in some cases even worse performance compared to carefully selecting a matching set. This is true even for data-inefficient neural models. Acoustic Latent Dirichlet Allocation (aLDA) is shown to be useful in a variety of speech technology related tasks, including domain adaptation of acoustic models for automatic speech recognition and entity labeling for information retrieval. In this paper we propose to use aLDA as a data similarity criterion in a data selection framework. Given a large pool of out-of-domain and potentially mismatched data, the task is to select the best-matching training data to a set of representative utterances sampled from a target domain. Our target data consists of around 32 hours of meeting data (both far-field and close-talk) and the pool contains 2k hours of meeting, talks, voice search, dictation, command-and-control, audio books, lectures, generic media and telephony speech data. The proposed technique for training data selection, significantly outperforms random selection, posterior-based selection as well as using all of the available data.
Recent improvements of ASR models in the face of adversarial attacks
Apr 04, 2022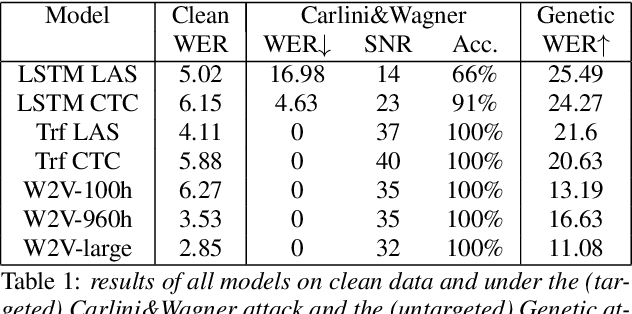
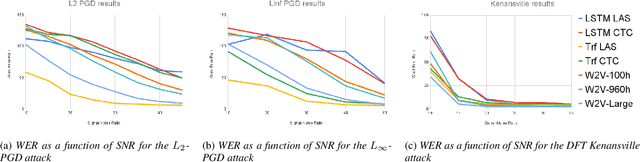
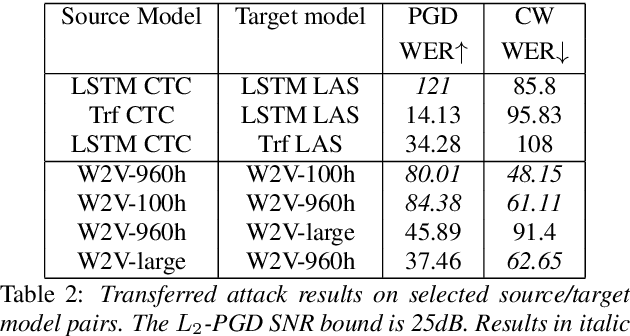
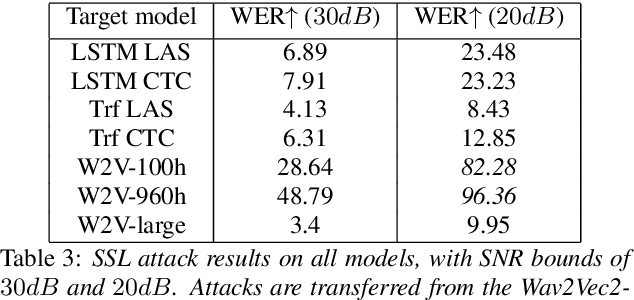
Like many other tasks involving neural networks, Speech Recognition models are vulnerable to adversarial attacks. However recent research has pointed out differences between attacks and defenses on ASR models compared to image models. Improving the robustness of ASR models requires a paradigm shift from evaluating attacks on one or a few models to a systemic approach in evaluation. We lay the ground for such research by evaluating on various architectures a representative set of adversarial attacks: targeted and untargeted, optimization and speech processing-based, white-box, black-box and targeted attacks. Our results show that the relative strengths of different attack algorithms vary considerably when changing the model architecture, and that the results of some attacks are not to be blindly trusted. They also indicate that training choices such as self-supervised pretraining can significantly impact robustness by enabling transferable perturbations. We release our source code as a package that should help future research in evaluating their attacks and defenses.
Automatic Speech Recognition and Topic Identification for Almost-Zero-Resource Languages
Jun 18, 2018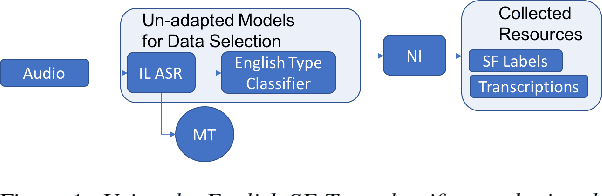
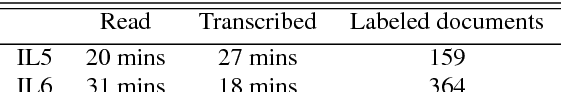
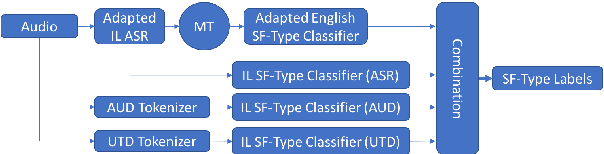
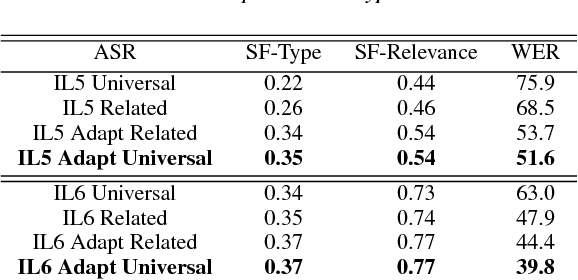
Automatic speech recognition (ASR) systems often need to be developed for extremely low-resource languages to serve end-uses such as audio content categorization and search. While universal phone recognition is natural to consider when no transcribed speech is available to train an ASR system in a language, adapting universal phone models using very small amounts (minutes rather than hours) of transcribed speech also needs to be studied, particularly with state-of-the-art DNN-based acoustic models. The DARPA LORELEI program provides a framework for such very-low-resource ASR studies, and provides an extrinsic metric for evaluating ASR performance in a humanitarian assistance, disaster relief setting. This paper presents our Kaldi-based systems for the program, which employ a universal phone modeling approach to ASR, and describes recipes for very rapid adaptation of this universal ASR system. The results we obtain significantly outperform results obtained by many competing approaches on the NIST LoReHLT 2017 Evaluation datasets.
Learning Speech Rate in Speech Recognition
Jun 02, 2015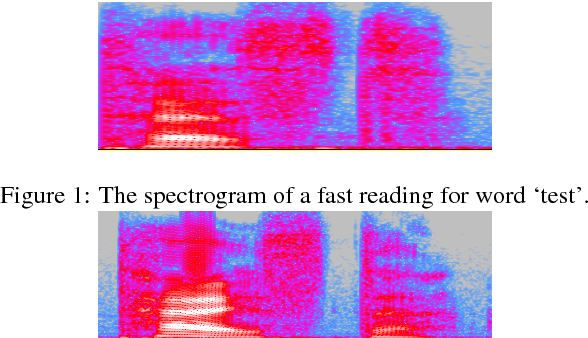


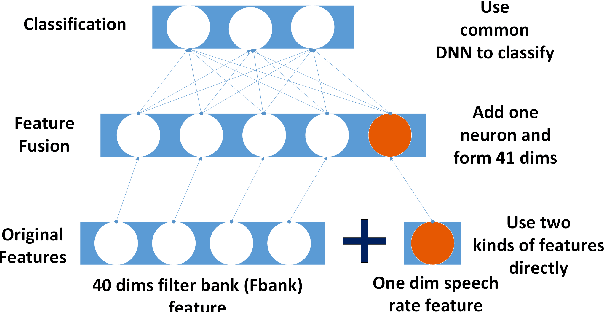
A significant performance reduction is often observed in speech recognition when the rate of speech (ROS) is too low or too high. Most of present approaches to addressing the ROS variation focus on the change of speech signals in dynamic properties caused by ROS, and accordingly modify the dynamic model, e.g., the transition probabilities of the hidden Markov model (HMM). However, an abnormal ROS changes not only the dynamic but also the static property of speech signals, and thus can not be compensated for purely by modifying the dynamic model. This paper proposes an ROS learning approach based on deep neural networks (DNN), which involves an ROS feature as the input of the DNN model and so the spectrum distortion caused by ROS can be learned and compensated for. The experimental results show that this approach can deliver better performance for too slow and too fast utterances, demonstrating our conjecture that ROS impacts both the dynamic and the static property of speech. In addition, the proposed approach can be combined with the conventional HMM transition adaptation method, offering additional performance gains.
Exploring Speech Enhancement with Generative Adversarial Networks for Robust Speech Recognition
Oct 31, 2018



We investigate the effectiveness of generative adversarial networks (GANs) for speech enhancement, in the context of improving noise robustness of automatic speech recognition (ASR) systems. Prior work demonstrates that GANs can effectively suppress additive noise in raw waveform speech signals, improving perceptual quality metrics; however this technique was not justified in the context of ASR. In this work, we conduct a detailed study to measure the effectiveness of GANs in enhancing speech contaminated by both additive and reverberant noise. Motivated by recent advances in image processing, we propose operating GANs on log-Mel filterbank spectra instead of waveforms, which requires less computation and is more robust to reverberant noise. While GAN enhancement improves the performance of a clean-trained ASR system on noisy speech, it falls short of the performance achieved by conventional multi-style training (MTR). By appending the GAN-enhanced features to the noisy inputs and retraining, we achieve a 7% WER improvement relative to the MTR system.