 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
VOTE400(Voide Of The Elderly 400 Hours): A Speech Dataset to Study Voice Interface for Elderly-Care
Jan 20, 2021
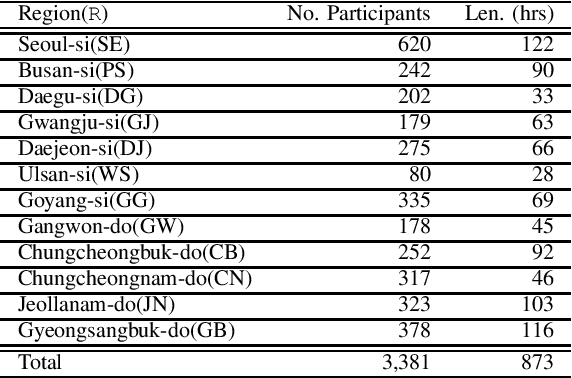
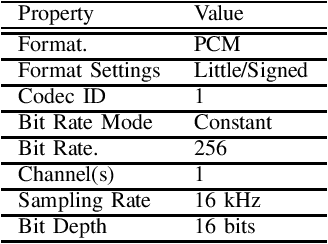
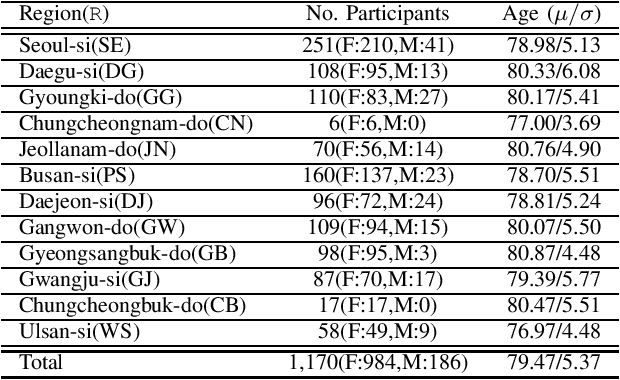
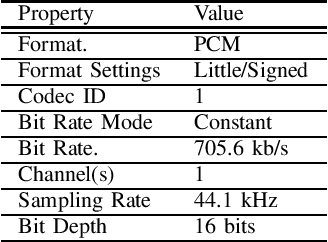
This paper introduces a large-scale Korean speech dataset, called VOTE400, that can be used for analyzing and recognizing voices of the elderly people. The dataset includes about 300 hours of continuous dialog speech and 100 hours of read speech, both recorded by the elderly people aged 65 years or over. A preliminary experiment showed that speech recognition system trained with VOTE400 can outperform conventional systems in speech recognition of elderly people's voice. This work is a multi-organizational effort led by ETRI and MINDs Lab Inc. for the purpose of advancing the speech recognition performance of the elderly-care robots.
Long Short-Term Memory based Convolutional Recurrent Neural Networks for Large Vocabulary Speech Recognition
Oct 11, 2016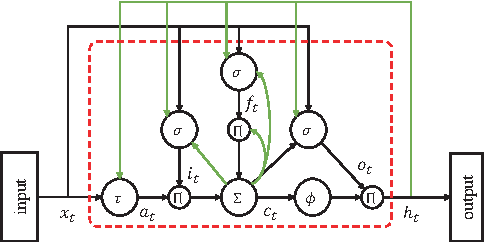

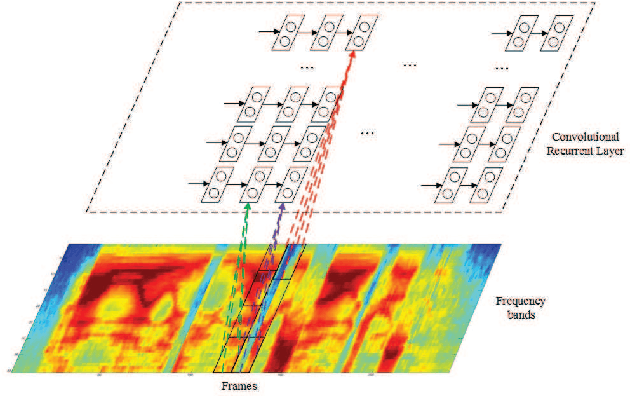
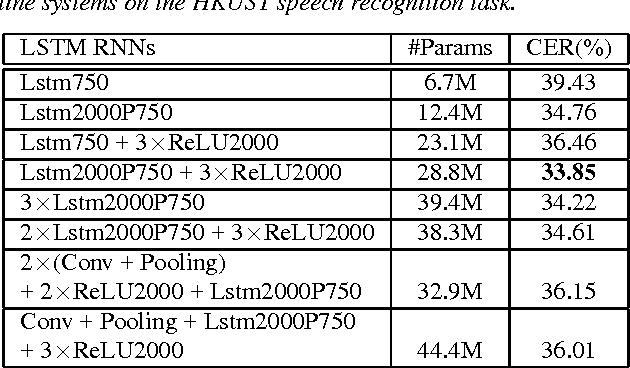
Long short-term memory (LSTM) recurrent neural networks (RNNs) have been shown to give state-of-the-art performance on many speech recognition tasks, as they are able to provide the learned dynamically changing contextual window of all sequence history. On the other hand, the convolutional neural networks (CNNs) have brought significant improvements to deep feed-forward neural networks (FFNNs), as they are able to better reduce spectral variation in the input signal. In this paper, a network architecture called as convolutional recurrent neural network (CRNN) is proposed by combining the CNN and LSTM RNN. In the proposed CRNNs, each speech frame, without adjacent context frames, is organized as a number of local feature patches along the frequency axis, and then a LSTM network is performed on each feature patch along the time axis. We train and compare FFNNs, LSTM RNNs and the proposed LSTM CRNNs at various number of configurations. Experimental results show that the LSTM CRNNs can exceed state-of-the-art speech recognition performance.
Fast and Accurate Capitalization and Punctuation for Automatic Speech Recognition Using Transformer and Chunk Merging
Aug 07, 2019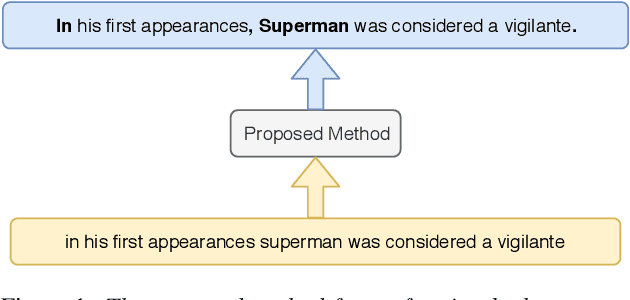
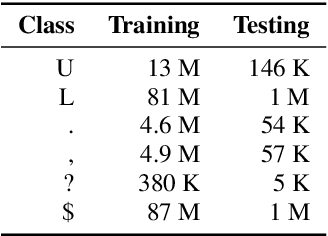
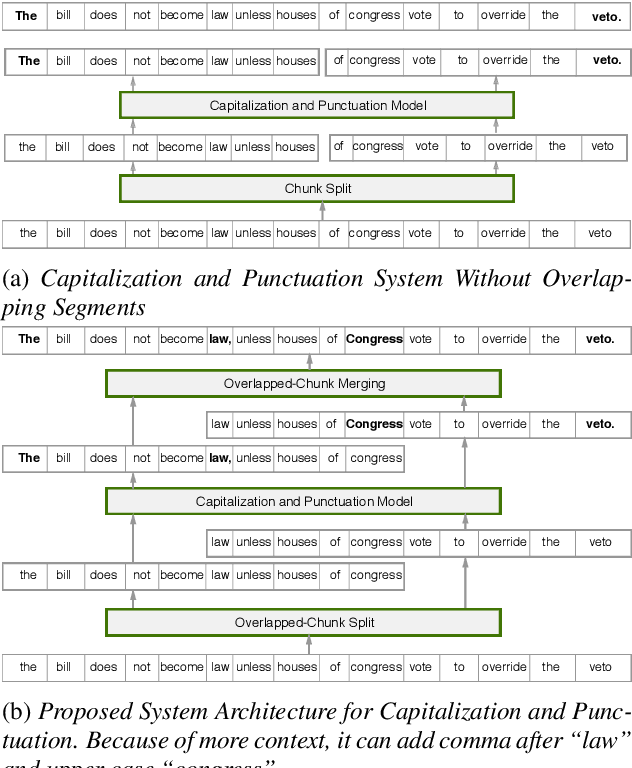
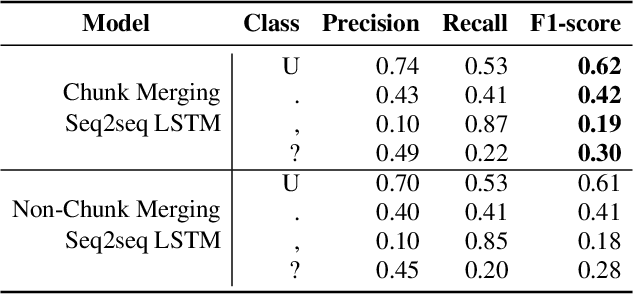
In recent years, studies on automatic speech recognition (ASR) have shown outstanding results that reach human parity on short speech segments. However, there are still difficulties in standardizing the output of ASR such as capitalization and punctuation restoration for long-speech transcription. The problems obstruct readers to understand the ASR output semantically and also cause difficulties for natural language processing models such as NER, POS and semantic parsing. In this paper, we propose a method to restore the punctuation and capitalization for long-speech ASR transcription. The method is based on Transformer models and chunk merging that allows us to (1), build a single model that performs punctuation and capitalization in one go, and (2), perform decoding in parallel while improving the prediction accuracy. Experiments on British National Corpus showed that the proposed approach outperforms existing methods in both accuracy and decoding speed.
Unsupervised Speech Recognition via Segmental Empirical Output Distribution Matching
Dec 23, 2018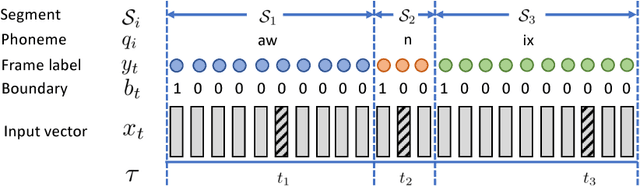
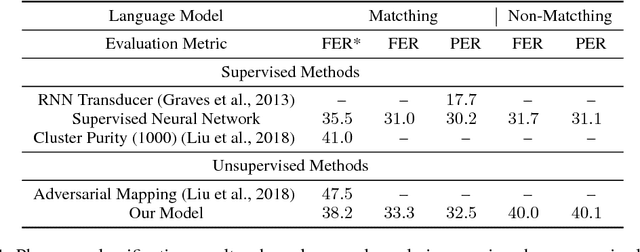
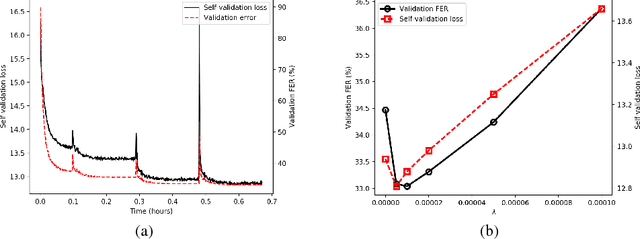
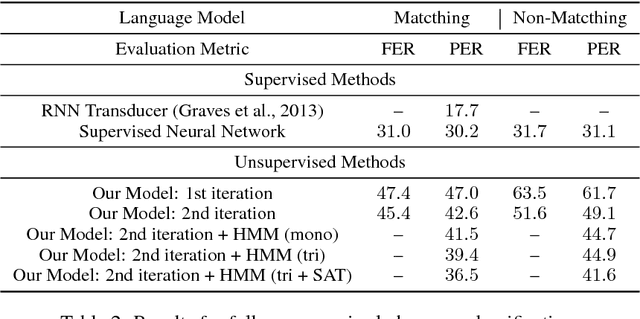
We consider the problem of training speech recognition systems without using any labeled data, under the assumption that the learner can only access to the input utterances and a phoneme language model estimated from a non-overlapping corpus. We propose a fully unsupervised learning algorithm that alternates between solving two sub-problems: (i) learn a phoneme classifier for a given set of phoneme segmentation boundaries, and (ii) refining the phoneme boundaries based on a given classifier. To solve the first sub-problem, we introduce a novel unsupervised cost function named Segmental Empirical Output Distribution Matching, which generalizes the work in (Liu et al., 2017) to segmental structures. For the second sub-problem, we develop an approximate MAP approach to refining the boundaries obtained from Wang et al. (2017). Experimental results on TIMIT dataset demonstrate the success of this fully unsupervised phoneme recognition system, which achieves a phone error rate (PER) of 41.6%. Although it is still far away from the state-of-the-art supervised systems, we show that with oracle boundaries and matching language model, the PER could be improved to 32.5%.This performance approaches the supervised system of the same model architecture, demonstrating the great potential of the proposed method.
Sequence-Level Knowledge Distillation for Model Compression of Attention-based Sequence-to-Sequence Speech Recognition
Nov 12, 2018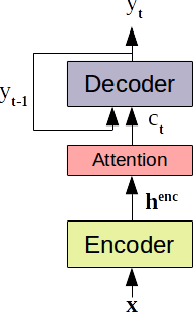

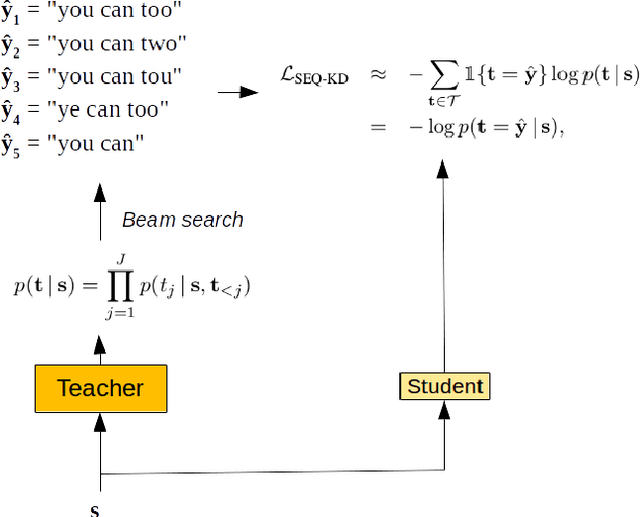
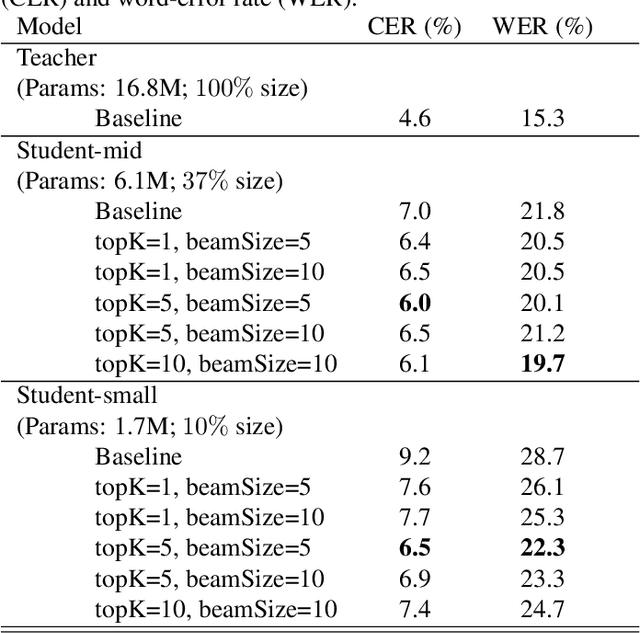
We investigate the feasibility of sequence-level knowledge distillation of Sequence-to-Sequence (Seq2Seq) models for Large Vocabulary Continuous Speech Recognition (LVSCR). We first use a pre-trained larger teacher model to generate multiple hypotheses per utterance with beam search. With the same input, we then train the student model using these hypotheses generated from the teacher as pseudo labels in place of the original ground truth labels. We evaluate our proposed method using Wall Street Journal (WSJ) corpus. It achieved up to $ 9.8 \times$ parameter reduction with accuracy loss of up to 7.0\% word-error rate (WER) increase
Speech Emotion Recognition using Semantic Information
Mar 04, 2021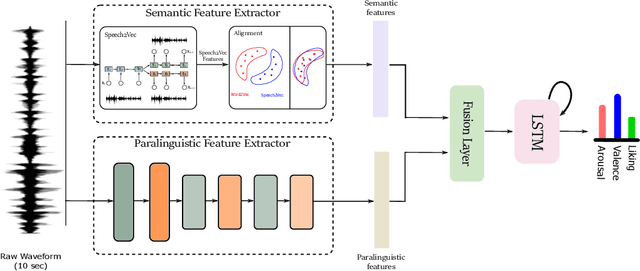

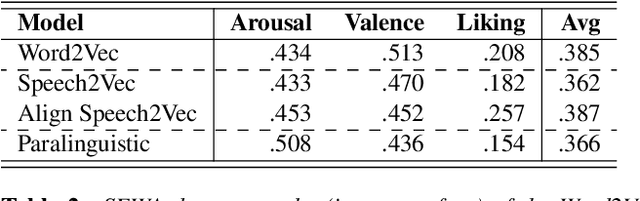

Speech emotion recognition is a crucial problem manifesting in a multitude of applications such as human computer interaction and education. Although several advancements have been made in the recent years, especially with the advent of Deep Neural Networks (DNN), most of the studies in the literature fail to consider the semantic information in the speech signal. In this paper, we propose a novel framework that can capture both the semantic and the paralinguistic information in the signal. In particular, our framework is comprised of a semantic feature extractor, that captures the semantic information, and a paralinguistic feature extractor, that captures the paralinguistic information. Both semantic and paraliguistic features are then combined to a unified representation using a novel attention mechanism. The unified feature vector is passed through a LSTM to capture the temporal dynamics in the signal, before the final prediction. To validate the effectiveness of our framework, we use the popular SEWA dataset of the AVEC challenge series and compare with the three winning papers. Our model provides state-of-the-art results in the valence and liking dimensions.
Recent improvements of ASR models in the face of adversarial attacks
Apr 04, 2022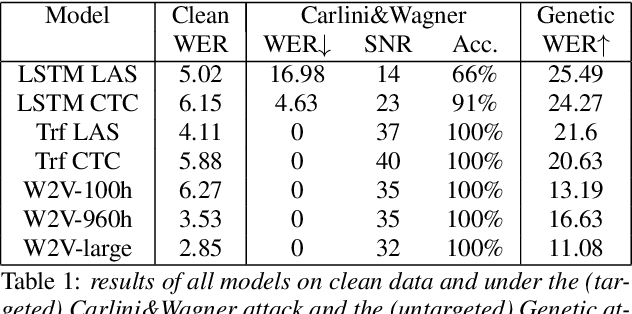
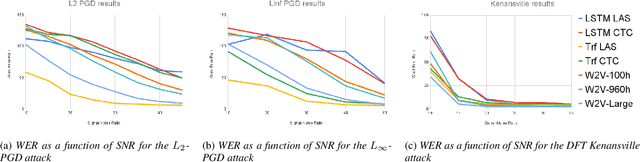
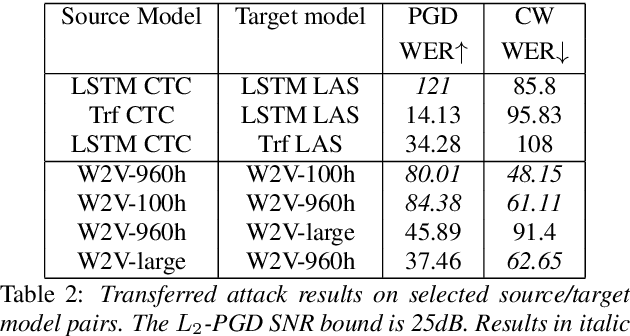
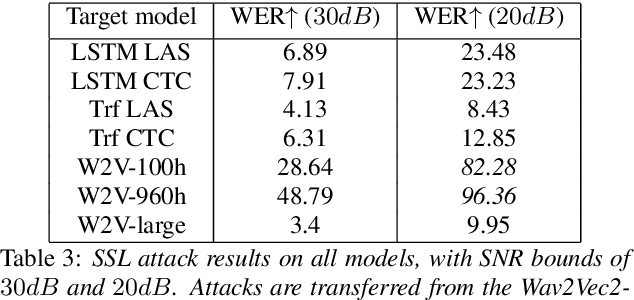
Like many other tasks involving neural networks, Speech Recognition models are vulnerable to adversarial attacks. However recent research has pointed out differences between attacks and defenses on ASR models compared to image models. Improving the robustness of ASR models requires a paradigm shift from evaluating attacks on one or a few models to a systemic approach in evaluation. We lay the ground for such research by evaluating on various architectures a representative set of adversarial attacks: targeted and untargeted, optimization and speech processing-based, white-box, black-box and targeted attacks. Our results show that the relative strengths of different attack algorithms vary considerably when changing the model architecture, and that the results of some attacks are not to be blindly trusted. They also indicate that training choices such as self-supervised pretraining can significantly impact robustness by enabling transferable perturbations. We release our source code as a package that should help future research in evaluating their attacks and defenses.
An Initialization Scheme for Meeting Separation with Spatial Mixture Models
Apr 04, 2022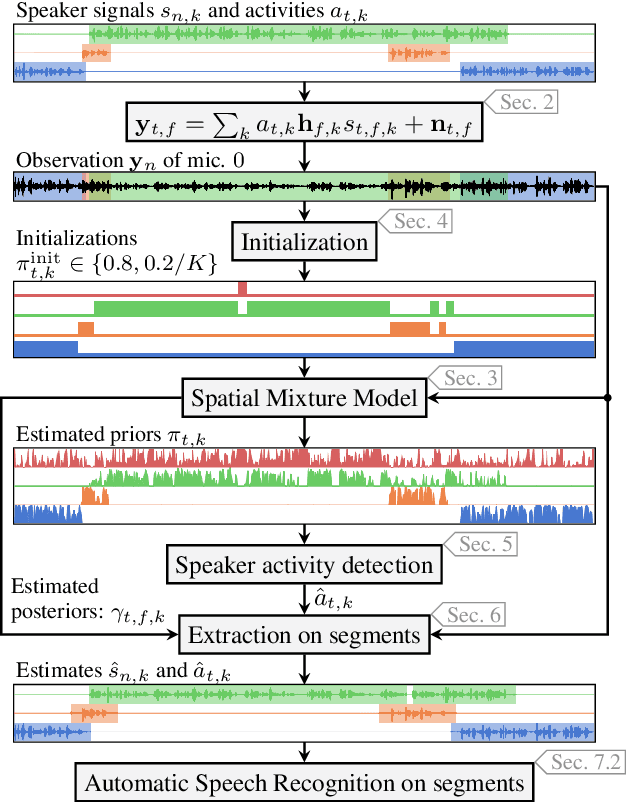
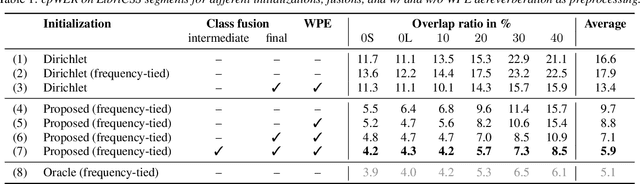
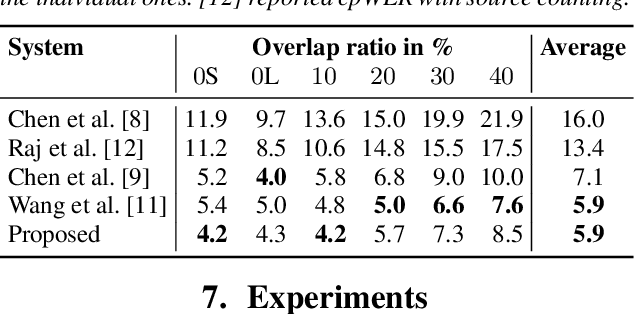
Spatial mixture model (SMM) supported acoustic beamforming has been extensively used for the separation of simultaneously active speakers. However, it has hardly been considered for the separation of meeting data, that are characterized by long recordings and only partially overlapping speech. In this contribution, we show that the fact that often only a single speaker is active can be utilized for a clever initialization of an SMM that employs time-varying class priors. In experiments on LibriCSS we show that the proposed initialization scheme achieves a significantly lower Word Error Rate (WER) on a downstream speech recognition task than a random initialization of the class probabilities by drawing from a Dirichlet distribution. With the only requirement that the number of speakers has to be known, we obtain a WER of 5.9 %, which is comparable to the best reported WER on this data set. Furthermore, the estimated speaker activity from the mixture model serves as a diarization based on spatial information.
A Conformer-based Waveform-domain Neural Acoustic Echo Canceller Optimized for ASR Accuracy
May 06, 2022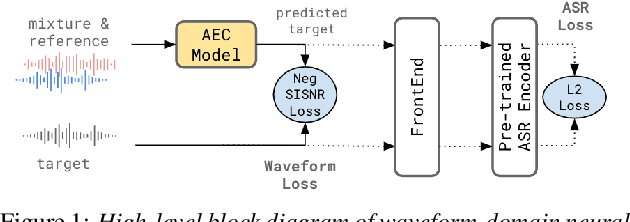
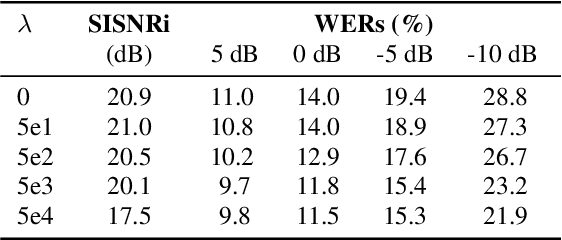
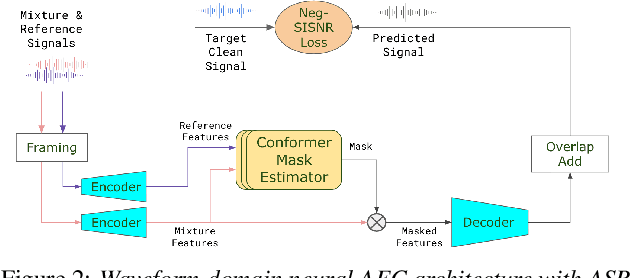
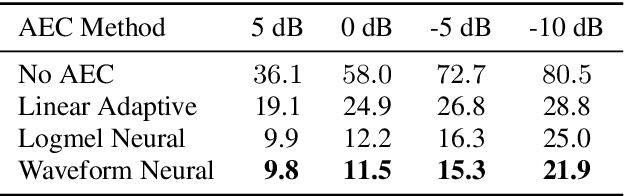
Acoustic Echo Cancellation (AEC) is essential for accurate recognition of queries spoken to a smart speaker that is playing out audio. Previous work has shown that a neural AEC model operating on log-mel spectral features (denoted "logmel" hereafter) can greatly improve Automatic Speech Recognition (ASR) accuracy when optimized with an auxiliary loss utilizing a pre-trained ASR model encoder. In this paper, we develop a conformer-based waveform-domain neural AEC model inspired by the "TasNet" architecture. The model is trained by jointly optimizing Negative Scale-Invariant SNR (SISNR) and ASR losses on a large speech dataset. On a realistic rerecorded test set, we find that cascading a linear adaptive AEC and a waveform-domain neural AEC is very effective, giving 56-59% word error rate (WER) reduction over the linear AEC alone. On this test set, the 1.6M parameter waveform-domain neural AEC also improves over a larger 6.5M parameter logmel-domain neural AEC model by 20-29% in easy to moderate conditions. By operating on smaller frames, the waveform neural model is able to perform better at smaller sizes and is better suited for applications where memory is limited.
Set-based Meta-Interpolation for Few-Task Meta-Learning
May 20, 2022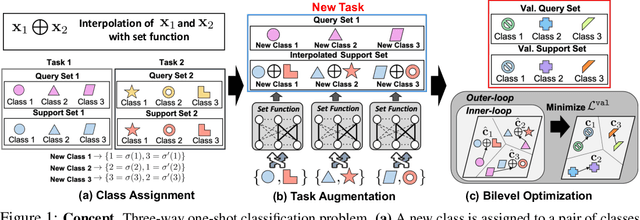
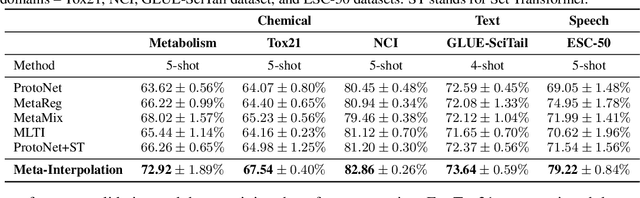
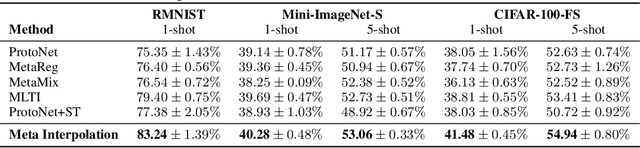
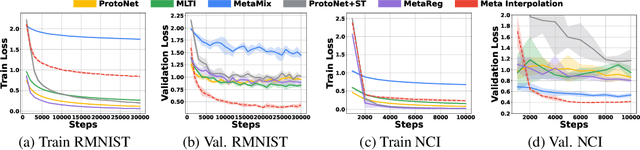
Meta-learning approaches enable machine learning systems to adapt to new tasks given few examples by leveraging knowledge from related tasks. However, a large number of meta-training tasks are still required for generalization to unseen tasks during meta-testing, which introduces a critical bottleneck for real-world problems that come with only few tasks, due to various reasons including the difficulty and cost of constructing tasks. Recently, several task augmentation methods have been proposed to tackle this issue using domain-specific knowledge to design augmentation techniques to densify the meta-training task distribution. However, such reliance on domain-specific knowledge renders these methods inapplicable to other domains. While Manifold Mixup based task augmentation methods are domain-agnostic, we empirically find them ineffective on non-image domains. To tackle these limitations, we propose a novel domain-agnostic task augmentation method, Meta-Interpolation, which utilizes expressive neural set functions to densify the meta-training task distribution using bilevel optimization. We empirically validate the efficacy of Meta-Interpolation on eight datasets spanning across various domains such as image classification, molecule property prediction, text classification and speech recognition. Experimentally, we show that Meta-Interpolation consistently outperforms all the relevant baselines. Theoretically, we prove that task interpolation with the set function regularizes the meta-learner to improve generalization.