 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
MUST: A Multilingual Student-Teacher Learning approach for low-resource speech recognition
Oct 29, 2023
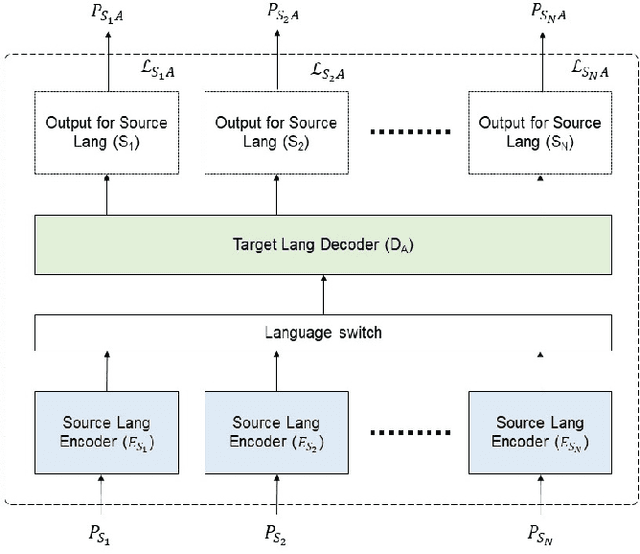
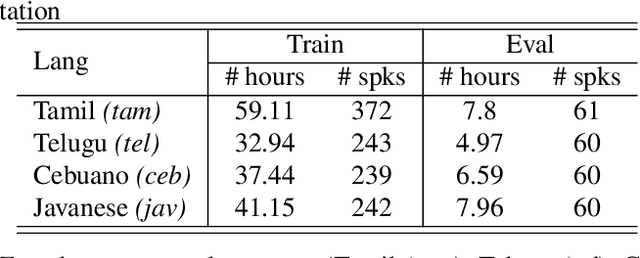
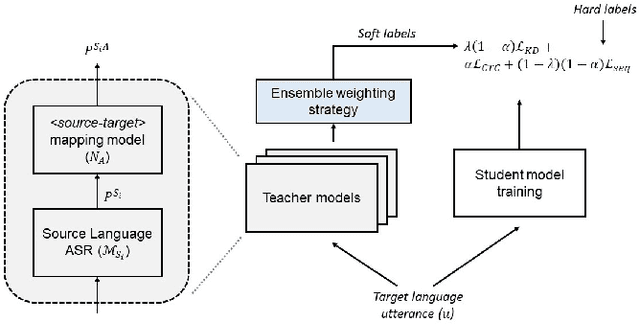
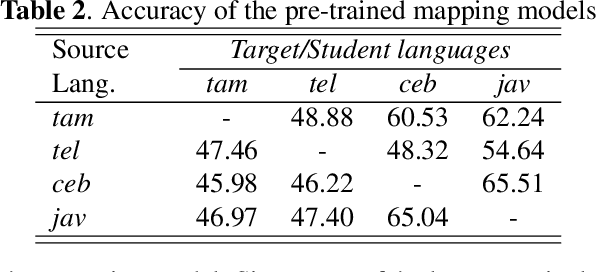
Student-teacher learning or knowledge distillation (KD) has been previously used to address data scarcity issue for training of speech recognition (ASR) systems. However, a limitation of KD training is that the student model classes must be a proper or improper subset of the teacher model classes. It prevents distillation from even acoustically similar languages if the character sets are not same. In this work, the aforementioned limitation is addressed by proposing a MUltilingual Student-Teacher (MUST) learning which exploits a posteriors mapping approach. A pre-trained mapping model is used to map posteriors from a teacher language to the student language ASR. These mapped posteriors are used as soft labels for KD learning. Various teacher ensemble schemes are experimented to train an ASR model for low-resource languages. A model trained with MUST learning reduces relative character error rate (CER) up to 9.5% in comparison with a baseline monolingual ASR.
Leveraged Mel spectrograms using Harmonic and Percussive Components in Speech Emotion Recognition
Dec 18, 2023Speech Emotion Recognition (SER) affective technology enables the intelligent embedded devices to interact with sensitivity. Similarly, call centre employees recognise customers' emotions from their pitch, energy, and tone of voice so as to modify their speech for a high-quality interaction with customers. This work explores, for the first time, the effects of the harmonic and percussive components of Mel spectrograms in SER. We attempt to leverage the Mel spectrogram by decomposing distinguishable acoustic features for exploitation in our proposed architecture, which includes a novel feature map generator algorithm, a CNN-based network feature extractor and a multi-layer perceptron (MLP) classifier. This study specifically focuses on effective data augmentation techniques for building an enriched hybrid-based feature map. This process results in a function that outputs a 2D image so that it can be used as input data for a pre-trained CNN-VGG16 feature extractor. Furthermore, we also investigate other acoustic features such as MFCCs, chromagram, spectral contrast, and the tonnetz to assess our proposed framework. A test accuracy of 92.79% on the Berlin EMO-DB database is achieved. Our result is higher than previous works using CNN-VGG16.
* 12 pages
Voxtlm: unified decoder-only models for consolidating speech recognition/synthesis and speech/text continuation tasks
Sep 18, 2023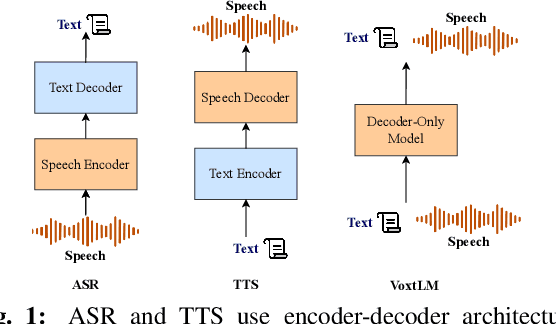

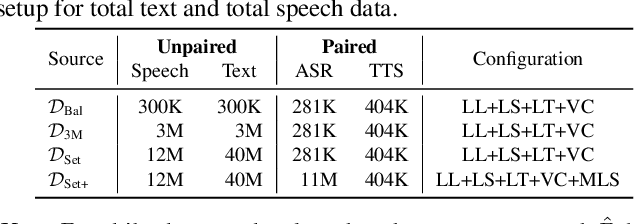

We propose a decoder-only language model, \textit{VoxtLM}, that can perform four tasks: speech recognition, speech synthesis, text generation, and speech continuation. VoxtLM integrates text vocabulary with discrete speech tokens from self-supervised speech features and uses special tokens to enable multitask learning. Compared to a single-task model, VoxtLM exhibits a significant improvement in speech synthesis, with improvements in both speech intelligibility from 28.9 to 5.6 and objective quality from 2.68 to 3.90. VoxtLM also improves speech generation and speech recognition performance over the single-task counterpart. VoxtLM is trained with publicly available data and training recipes and model checkpoints will be open-sourced to make fully reproducible work.
On the Effectiveness of ASR Representations in Real-world Noisy Speech Emotion Recognition
Nov 14, 2023This paper proposes an efficient attempt to noisy speech emotion recognition (NSER). Conventional NSER approaches have proven effective in mitigating the impact of artificial noise sources, such as white Gaussian noise, but are limited to non-stationary noises in real-world environments due to their complexity and uncertainty. To overcome this limitation, we introduce a new method for NSER by adopting the automatic speech recognition (ASR) model as a noise-robust feature extractor to eliminate non-vocal information in noisy speech. We first obtain intermediate layer information from the ASR model as a feature representation for emotional speech and then apply this representation for the downstream NSER task. Our experimental results show that 1) the proposed method achieves better NSER performance compared with the conventional noise reduction method, 2) outperforms self-supervised learning approaches, and 3) even outperforms text-based approaches using ASR transcription or the ground truth transcription of noisy speech.
VoxArabica: A Robust Dialect-Aware Arabic Speech Recognition System
Oct 27, 2023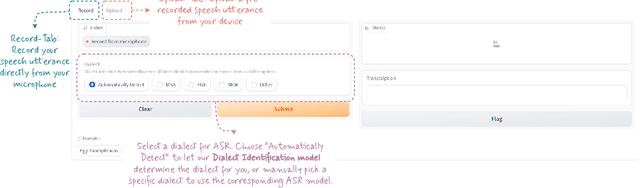

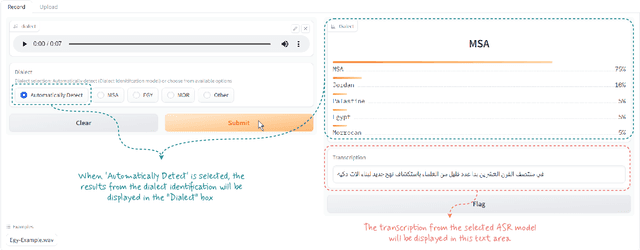
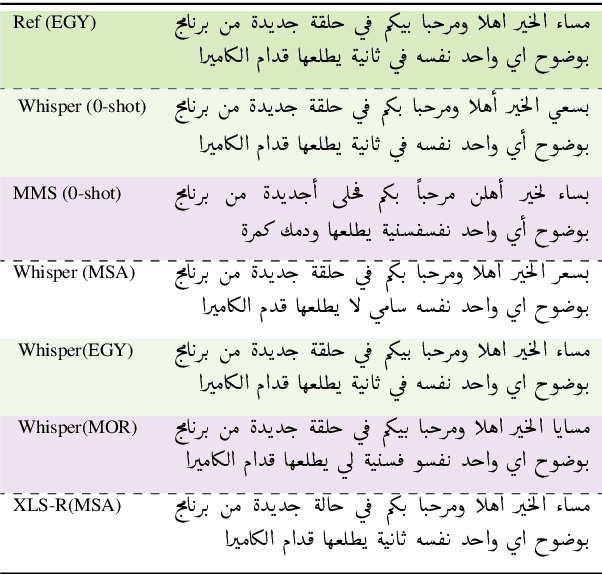
Arabic is a complex language with many varieties and dialects spoken by over 450 millions all around the world. Due to the linguistic diversity and variations, it is challenging to build a robust and generalized ASR system for Arabic. In this work, we address this gap by developing and demoing a system, dubbed VoxArabica, for dialect identification (DID) as well as automatic speech recognition (ASR) of Arabic. We train a wide range of models such as HuBERT (DID), Whisper, and XLS-R (ASR) in a supervised setting for Arabic DID and ASR tasks. Our DID models are trained to identify 17 different dialects in addition to MSA. We finetune our ASR models on MSA, Egyptian, Moroccan, and mixed data. Additionally, for the remaining dialects in ASR, we provide the option to choose various models such as Whisper and MMS in a zero-shot setting. We integrate these models into a single web interface with diverse features such as audio recording, file upload, model selection, and the option to raise flags for incorrect outputs. Overall, we believe VoxArabica will be useful for a wide range of audiences concerned with Arabic research. Our system is currently running at https://cdce-206-12-100-168.ngrok.io/.
TeLeS: Temporal Lexeme Similarity Score to Estimate Confidence in End-to-End ASR
Jan 06, 2024Confidence estimation of predictions from an End-to-End (E2E) Automatic Speech Recognition (ASR) model benefits ASR's downstream and upstream tasks. Class-probability-based confidence scores do not accurately represent the quality of overconfident ASR predictions. An ancillary Confidence Estimation Model (CEM) calibrates the predictions. State-of-the-art (SOTA) solutions use binary target scores for CEM training. However, the binary labels do not reveal the granular information of predicted words, such as temporal alignment between reference and hypothesis and whether the predicted word is entirely incorrect or contains spelling errors. Addressing this issue, we propose a novel Temporal-Lexeme Similarity (TeLeS) confidence score to train CEM. To address the data imbalance of target scores while training CEM, we use shrinkage loss to focus on hard-to-learn data points and minimise the impact of easily learned data points. We conduct experiments with ASR models trained in three languages, namely Hindi, Tamil, and Kannada, with varying training data sizes. Experiments show that TeLeS generalises well across domains. To demonstrate the applicability of the proposed method, we formulate a TeLeS-based Acquisition (TeLeS-A) function for sampling uncertainty in active learning. We observe a significant reduction in the Word Error Rate (WER) as compared to SOTA methods.
The GUA-Speech System Description for CNVSRC Challenge 2023
Dec 12, 2023This study describes our system for Task 1 Single-speaker Visual Speech Recognition (VSR) fixed track in the Chinese Continuous Visual Speech Recognition Challenge (CNVSRC) 2023. Specifically, we use intermediate connectionist temporal classification (Inter CTC) residual modules to relax the conditional independence assumption of CTC in our model. Then we use a bi-transformer decoder to enable the model to capture both past and future contextual information. In addition, we use Chinese characters as the modeling units to improve the recognition accuracy of our model. Finally, we use a recurrent neural network language model (RNNLM) for shallow fusion in the inference stage. Experiments show that our system achieves a character error rate (CER) of 38.09% on the Eval set which reaches a relative CER reduction of 21.63% over the official baseline, and obtains a second place in the challenge.
Folding Attention: Memory and Power Optimization for On-Device Transformer-based Streaming Speech Recognition
Sep 21, 2023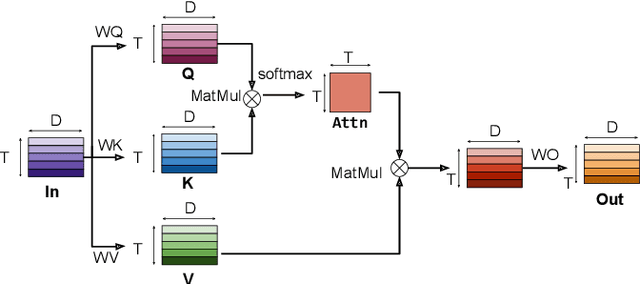
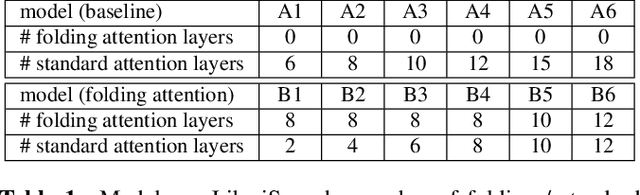
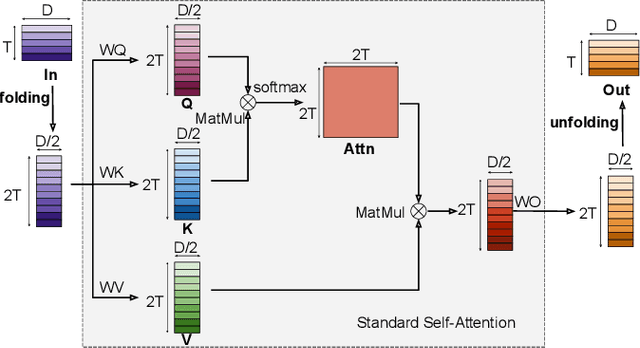
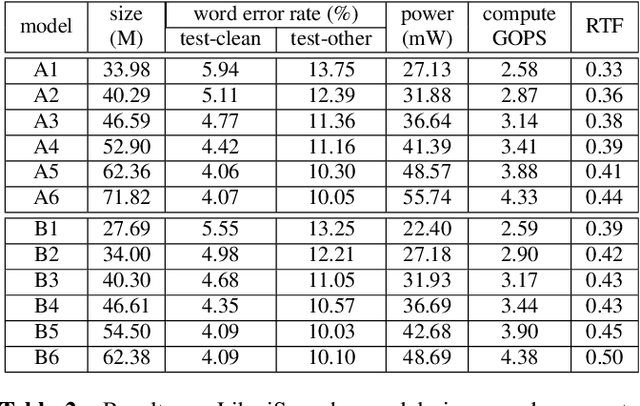
Transformer-based models excel in speech recognition. Existing efforts to optimize Transformer inference, typically for long-context applications, center on simplifying attention score calculations. However, streaming speech recognition models usually process a limited number of tokens each time, making attention score calculation less of a bottleneck. Instead, the bottleneck lies in the linear projection layers of multi-head attention and feedforward networks, constituting a substantial portion of the model size and contributing significantly to computation, memory, and power usage. To address this bottleneck, we propose folding attention, a technique targeting these linear layers, significantly reducing model size and improving memory and power efficiency. Experiments on on-device Transformer-based streaming speech recognition models show that folding attention reduces model size (and corresponding memory consumption) by up to 24% and power consumption by up to 23%, all without compromising model accuracy or computation overhead.
Correction Focused Language Model Training for Speech Recognition
Oct 17, 2023Language models (LMs) have been commonly adopted to boost the performance of automatic speech recognition (ASR) particularly in domain adaptation tasks. Conventional way of LM training treats all the words in corpora equally, resulting in suboptimal improvements in ASR performance. In this work, we introduce a novel correction focused LM training approach which aims to prioritize ASR fallible words. The word-level ASR fallibility score, representing the likelihood of ASR mis-recognition, is defined and shaped as a prior word distribution to guide the LM training. To enable correction focused training with text-only corpora, large language models (LLMs) are employed as fallibility score predictors and text generators through multi-task fine-tuning. Experimental results for domain adaptation tasks demonstrate the effectiveness of our proposed method. Compared with conventional LMs, correction focused training achieves up to relatively 5.5% word error rate (WER) reduction in sufficient text scenarios. In insufficient text scenarios, LM training with LLM-generated text achieves up to relatively 13% WER reduction, while correction focused training further obtains up to relatively 6% WER reduction.
Ms-senet: Enhancing Speech Emotion Recognition Through Multi-scale Feature Fusion With Squeeze-and-excitation Blocks
Dec 19, 2023Speech Emotion Recognition (SER) has become a growing focus of research in human-computer interaction. Spatiotemporal features play a crucial role in SER, yet current research lacks comprehensive spatiotemporal feature learning. This paper focuses on addressing this gap by proposing a novel approach. In this paper, we employ Convolutional Neural Network (CNN) with varying kernel sizes for spatial and temporal feature extraction. Additionally, we introduce Squeeze-and-Excitation (SE) modules to capture and fuse multi-scale features, facilitating effective information fusion for improved emotion recognition and a deeper understanding of the temporal evolution of speech emotion. Moreover, we employ skip connections and Spatial Dropout (SD) layers to prevent overfitting and increase the model's depth. Our method outperforms the previous state-of-the-art method, achieving an average UAR and WAR improvement of 1.62% and 1.32%, respectively, across six benchmark SER datasets. Further experiments demonstrated that our method can fully extract spatiotemporal features in low-resource conditions.