 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
M2MeT: The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
Oct 14, 2021
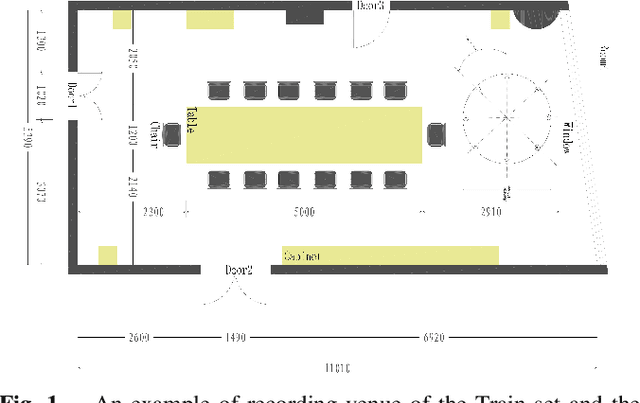
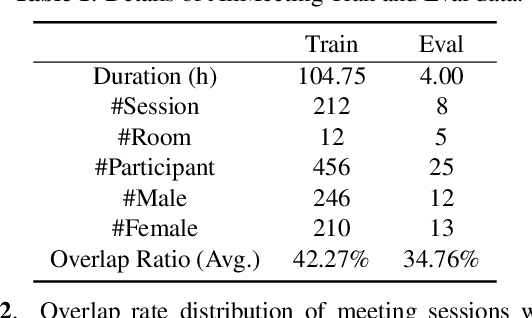
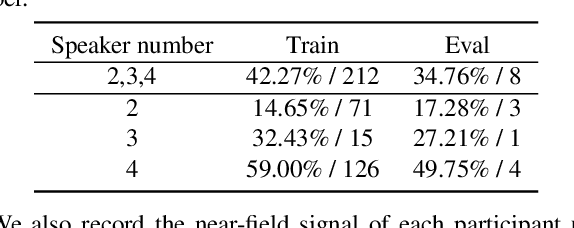
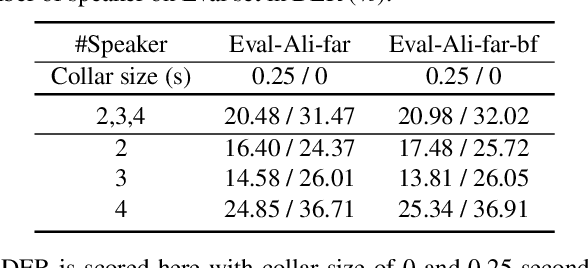
Recent development of speech signal processing, such as speech recognition, speaker diarization, etc., has inspired numerous applications of speech technologies. The meeting scenario is one of the most valuable and, at the same time, most challenging scenarios for speech technologies. Speaker diarization and multi-speaker automatic speech recognition in meeting scenarios have attracted increasing attention. However, the lack of large public real meeting data has been a major obstacle for advancement of the field. Therefore, we release the \emph{AliMeeting} corpus, which consists of 120 hours of real recorded Mandarin meeting data, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. Moreover, we will launch the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT), as an ICASSP2022 Signal Processing Grand Challenge. The challenge consists of two tracks, namely speaker diarization and multi-speaker ASR. In this paper we provide a detailed introduction of the dateset, rules, evaluation methods and baseline systems, aiming to further promote reproducible research in this field.
High-Accuracy and Low-Latency Speech Recognition with Two-Head Contextual Layer Trajectory LSTM Model
Mar 17, 2020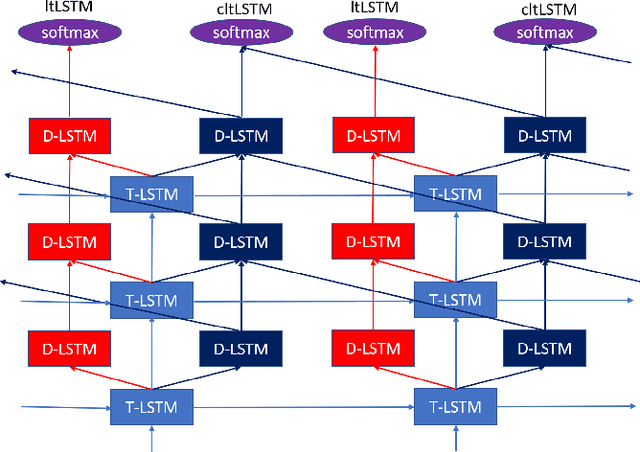
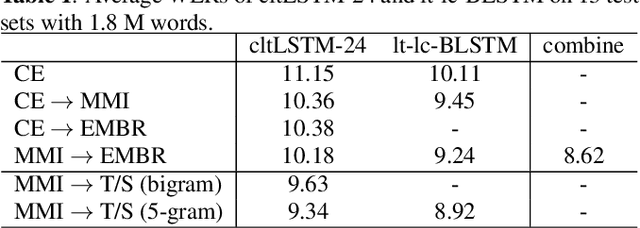
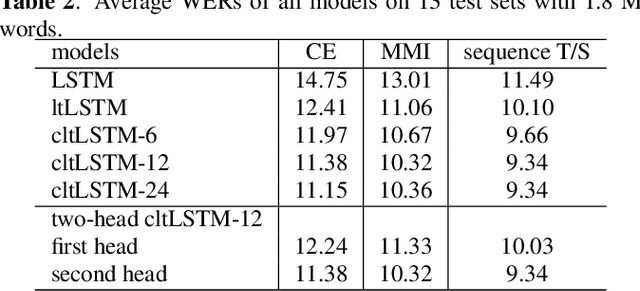
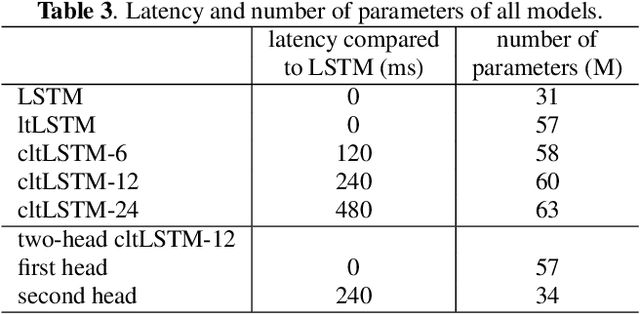
While the community keeps promoting end-to-end models over conventional hybrid models, which usually are long short-term memory (LSTM) models trained with a cross entropy criterion followed by a sequence discriminative training criterion, we argue that such conventional hybrid models can still be significantly improved. In this paper, we detail our recent efforts to improve conventional hybrid LSTM acoustic models for high-accuracy and low-latency automatic speech recognition. To achieve high accuracy, we use a contextual layer trajectory LSTM (cltLSTM), which decouples the temporal modeling and target classification tasks, and incorporates future context frames to get more information for accurate acoustic modeling. We further improve the training strategy with sequence-level teacher-student learning. To obtain low latency, we design a two-head cltLSTM, in which one head has zero latency and the other head has a small latency, compared to an LSTM. When trained with Microsoft's 65 thousand hours of anonymized training data and evaluated with test sets with 1.8 million words, the proposed two-head cltLSTM model with the proposed training strategy yields a 28.2\% relative WER reduction over the conventional LSTM acoustic model, with a similar perceived latency.
Towards speech-to-text translation without speech recognition
Feb 13, 2017
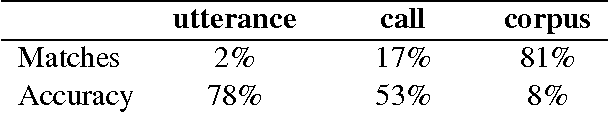

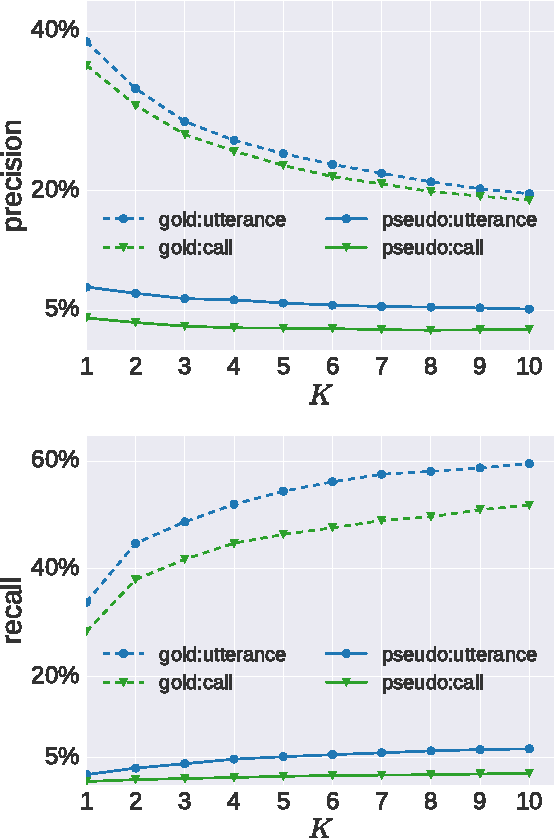
We explore the problem of translating speech to text in low-resource scenarios where neither automatic speech recognition (ASR) nor machine translation (MT) are available, but we have training data in the form of audio paired with text translations. We present the first system for this problem applied to a realistic multi-speaker dataset, the CALLHOME Spanish-English speech translation corpus. Our approach uses unsupervised term discovery (UTD) to cluster repeated patterns in the audio, creating a pseudotext, which we pair with translations to create a parallel text and train a simple bag-of-words MT model. We identify the challenges faced by the system, finding that the difficulty of cross-speaker UTD results in low recall, but that our system is still able to correctly translate some content words in test data.
Representation learning through cross-modal conditional teacher-student training for speech emotion recognition
Nov 30, 2021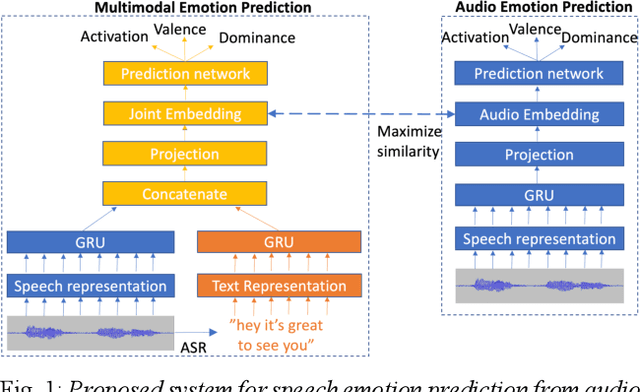
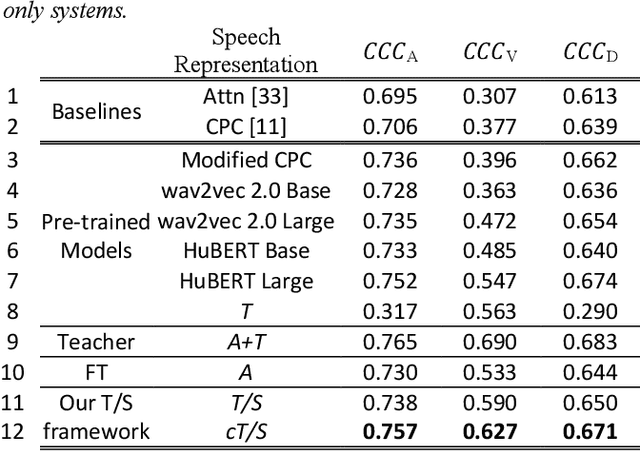
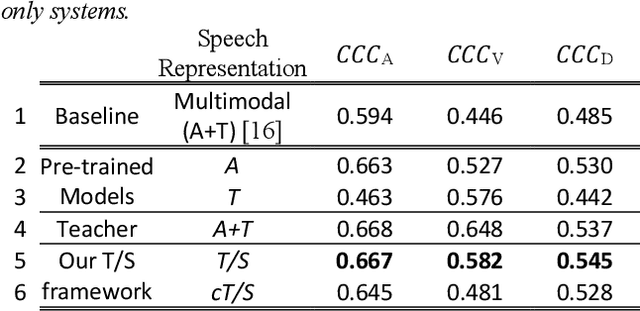
Generic pre-trained speech and text representations promise to reduce the need for large labeled datasets on specific speech and language tasks. However, it is not clear how to effectively adapt these representations for speech emotion recognition. Recent public benchmarks show the efficacy of several popular self-supervised speech representations for emotion classification. In this study, we show that the primary difference between the top-performing representations is in predicting valence while the differences in predicting activation and dominance dimensions are less pronounced. However, we show that even the best-performing HuBERT representation underperforms on valence prediction compared to a multimodal model that also incorporates text representation. We address this shortcoming by injecting lexical information into the speech representation using the multimodal model as a teacher. To improve the efficacy of our approach, we propose a novel estimate of the quality of the emotion predictions, to condition teacher-student training. We report new audio-only state-of-the-art concordance correlation coefficient (CCC) values of 0.757, 0.627, 0.671 for activation, valence and dominance predictions, respectively, on the MSP-Podcast corpus, and also state-of-the-art values of 0.667, 0.582, 0.545 on the IEMOCAP corpus.
Integrating Source-channel and Attention-based Sequence-to-sequence Models for Speech Recognition
Sep 14, 2019
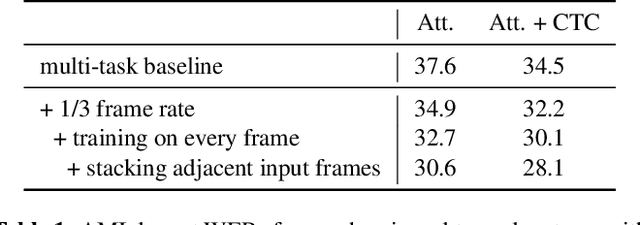
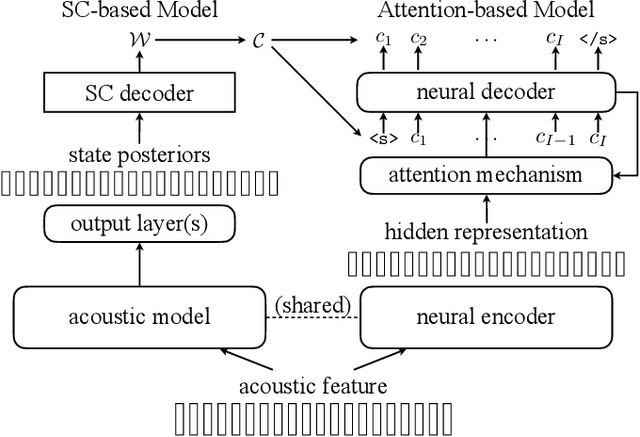

This paper proposes a novel automatic speech recognition (ASR) framework called Integrated Source-Channel and Attention (ISCA) that combines the advantages of traditional systems based on the noisy source-channel model (SC) and end-to-end style systems using attention-based sequence-to-sequence models. The traditional SC system framework includes hidden Markov models and connectionist temporal classification (CTC) based acoustic models, language models (LMs), and a decoding procedure based on a lexicon, whereas the end-to-end style attention-based system jointly models the whole process with a single model. By rescoring the hypotheses produced by traditional systems using end-to-end style systems based on an extended noisy source-channel model, ISCA allows structured knowledge to be easily incorporated via the SC-based model while exploiting the complementarity of the attention-based model. Experiments on the AMI meeting corpus show that ISCA is able to give a relative word error rate reduction up to 21% over an individual system, and by 13% over an alternative method which also involves combining CTC and attention-based models.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022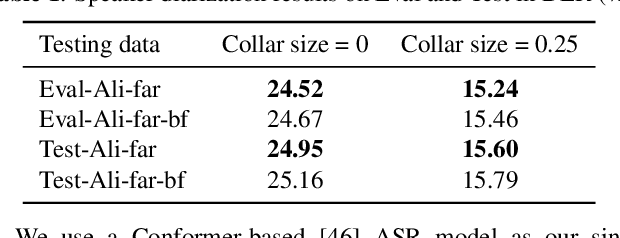
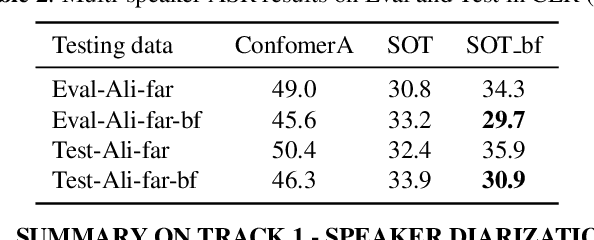
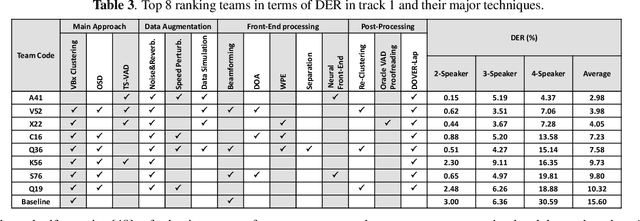
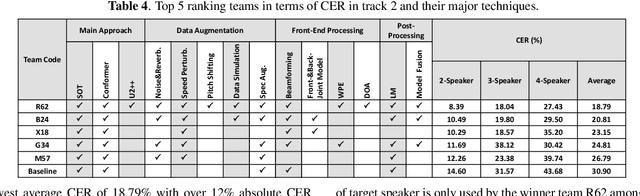
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
To Reverse the Gradient or Not: An Empirical Comparison of Adversarial and Multi-task Learning in Speech Recognition
Dec 13, 2018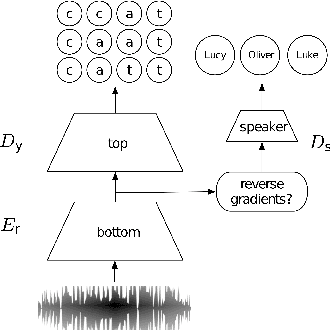
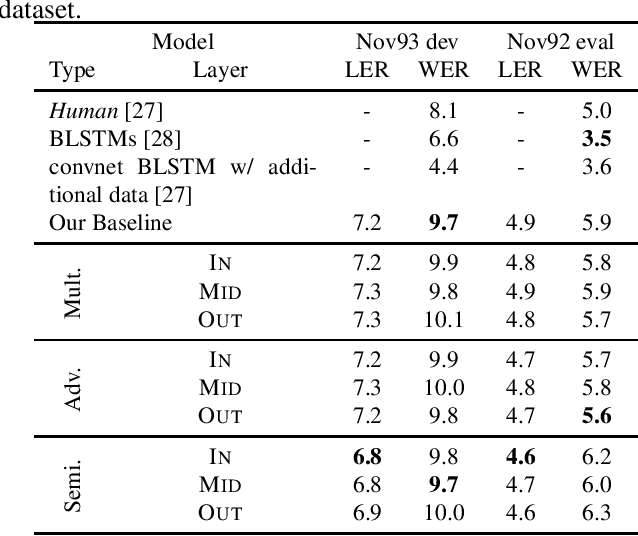
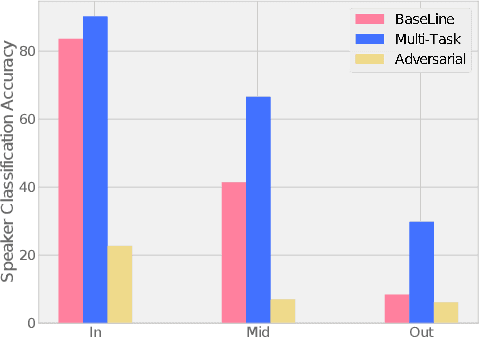
Transcribed datasets typically contain speaker identity for each instance in the data. We investigate two ways to incorporate this information during training: Multi-Task Learning and Adversarial Learning. In multi-task learning, the goal is speaker prediction; we expect a performance improvement with this joint training if the two tasks of speech recognition and speaker recognition share a common set of underlying features. In contrast, adversarial learning is a means to learn representations invariant to the speaker. We then expect better performance if this learnt invariance helps generalizing to new speakers. While the two approaches seem natural in the context of speech recognition, they are incompatible because they correspond to opposite gradients back-propagated to the model. In order to better understand the effect of these approaches in terms of error rates, we compare both strategies in controlled settings. Moreover, we explore the use of additional untranscribed data in a semi-supervised, adversarial learning manner to improve error rates. Our results show that deep models trained on big datasets already develop invariant representations to speakers without any auxiliary loss. When considering adversarial learning and multi-task learning, the impact on the acoustic model seems minor. However, models trained in a semi-supervised manner can improve error-rates.
GigaSpeech: An Evolving, Multi-domain ASR Corpus with 10,000 Hours of Transcribed Audio
Jun 13, 2021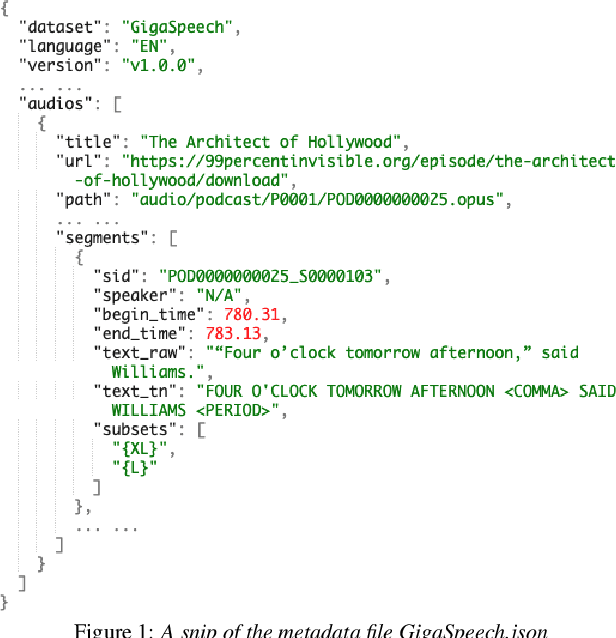
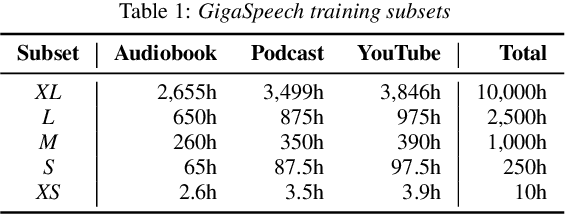
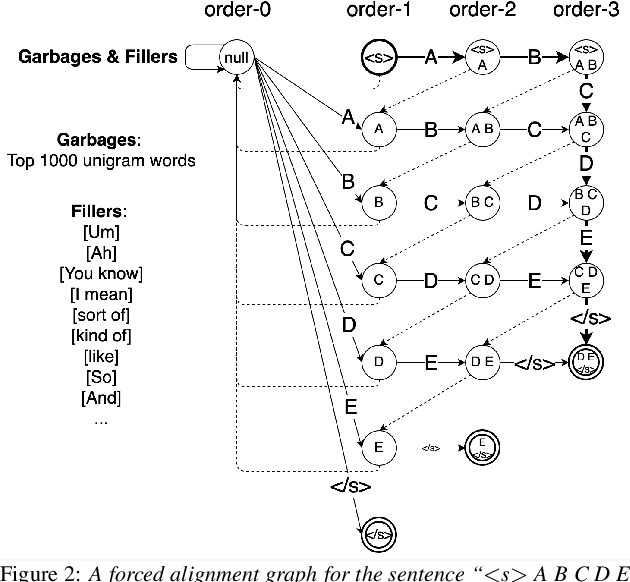
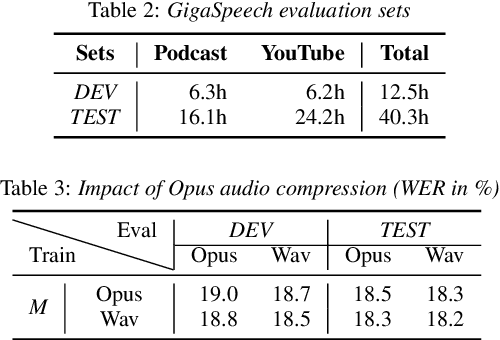
This paper introduces GigaSpeech, an evolving, multi-domain English speech recognition corpus with 10,000 hours of high quality labeled audio suitable for supervised training, and 40,000 hours of total audio suitable for semi-supervised and unsupervised training. Around 40,000 hours of transcribed audio is first collected from audiobooks, podcasts and YouTube, covering both read and spontaneous speaking styles, and a variety of topics, such as arts, science, sports, etc. A new forced alignment and segmentation pipeline is proposed to create sentence segments suitable for speech recognition training, and to filter out segments with low-quality transcription. For system training, GigaSpeech provides five subsets of different sizes, 10h, 250h, 1000h, 2500h, and 10000h. For our 10,000-hour XL training subset, we cap the word error rate at 4% during the filtering/validation stage, and for all our other smaller training subsets, we cap it at 0%. The DEV and TEST evaluation sets, on the other hand, are re-processed by professional human transcribers to ensure high transcription quality. Baseline systems are provided for popular speech recognition toolkits, namely Athena, ESPnet, Kaldi and Pika.
Hybrid CTC-Attention based End-to-End Speech Recognition using Subword Units
Sep 06, 2018
In this paper, we present an end-to-end automatic speech recognition system, which successfully employs subword units in a hybrid CTC-Attention based system. The subword units are obtained by the byte-pair encoding (BPE) compression algorithm. Compared to using words as modeling units, using characters or subword units does not suffer from the out-of-vocabulary (OOV) problem. Furthermore, using subword units further offers a capability in modeling longer context than using characters. We evaluate different systems over the LibriSpeech 1000h dataset. The subword-based hybrid CTC-Attention system obtains 6.8% word error rate (WER) on the test_clean subset without any dictionary or external language model. This represents a significant improvement (a 12.8% WER relative reduction) over the character-based hybrid CTC-Attention system.
Punctuation Restoration
Feb 19, 2022
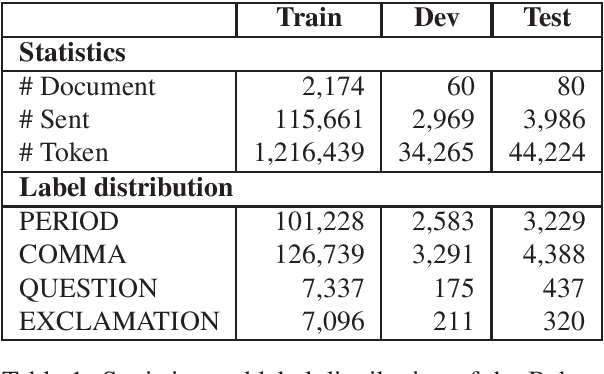


Given the increasing number of livestreaming videos, automatic speech recognition and post-processing for livestreaming video transcripts are crucial for efficient data management as well as knowledge mining. A key step in this process is punctuation restoration which restores fundamental text structures such as phrase and sentence boundaries from the video transcripts. This work presents a new human-annotated corpus, called BehancePR, for punctuation restoration in livestreaming video transcripts. Our experiments on BehancePR demonstrate the challenges of punctuation restoration for this domain. Furthermore, we show that popular natural language processing toolkits are incapable of detecting sentence boundary on non-punctuated transcripts of livestreaming videos, calling for more research effort to develop robust models for this area.