 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Shallow Fusion of Weighted Finite-State Transducer and Language Model for Text Normalization
Mar 29, 2022

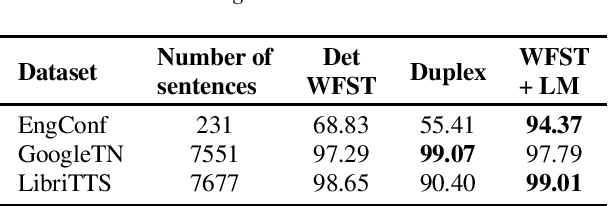
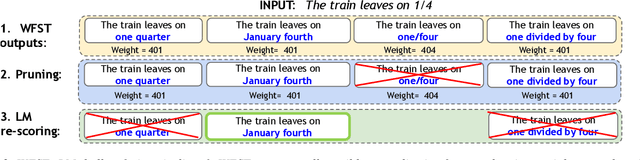

Text normalization (TN) systems in production are largely rule-based using weighted finite-state transducers (WFST). However, WFST-based systems struggle with ambiguous input when the normalized form is context-dependent. On the other hand, neural text normalization systems can take context into account but they suffer from unrecoverable errors and require labeled normalization datasets, which are hard to collect. We propose a new hybrid approach that combines the benefits of rule-based and neural systems. First, a non-deterministic WFST outputs all normalization candidates, and then a neural language model picks the best one -- similar to shallow fusion for automatic speech recognition. While the WFST prevents unrecoverable errors, the language model resolves contextual ambiguity. The approach is easy to extend and we show it is effective. It achieves comparable or better results than existing state-of-the-art TN models.
Improved Regularization Techniques for End-to-End Speech Recognition
Dec 19, 2017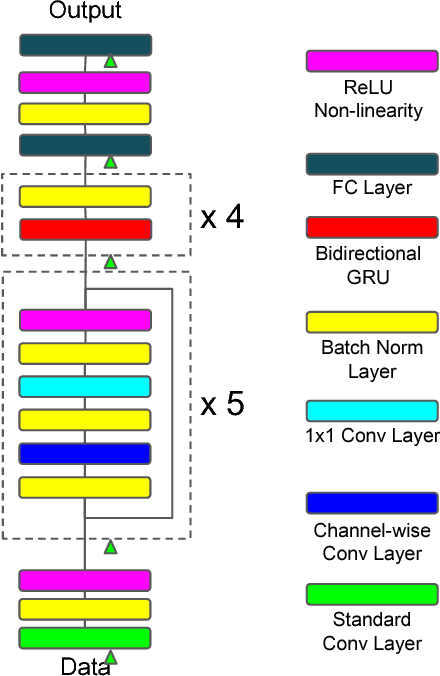
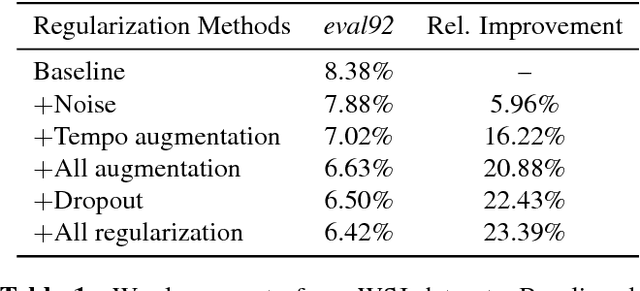

Regularization is important for end-to-end speech models, since the models are highly flexible and easy to overfit. Data augmentation and dropout has been important for improving end-to-end models in other domains. However, they are relatively under explored for end-to-end speech models. Therefore, we investigate the effectiveness of both methods for end-to-end trainable, deep speech recognition models. We augment audio data through random perturbations of tempo, pitch, volume, temporal alignment, and adding random noise.We further investigate the effect of dropout when applied to the inputs of all layers of the network. We show that the combination of data augmentation and dropout give a relative performance improvement on both Wall Street Journal (WSJ) and LibriSpeech dataset of over 20%. Our model performance is also competitive with other end-to-end speech models on both datasets.
Is Attention always needed? A Case Study on Language Identification from Speech
Oct 05, 2021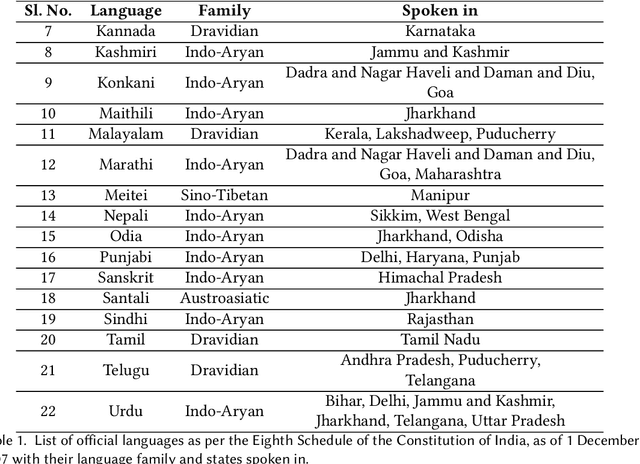
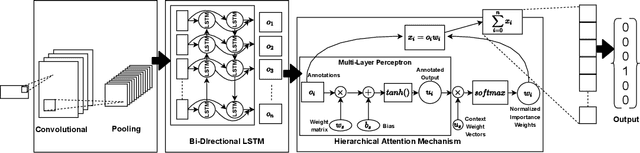
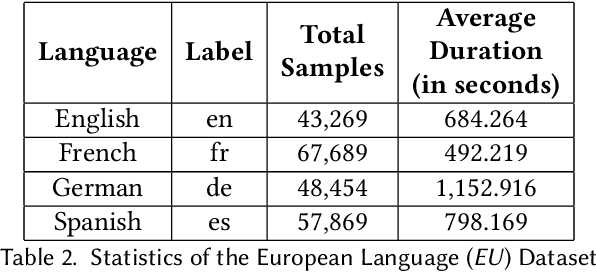
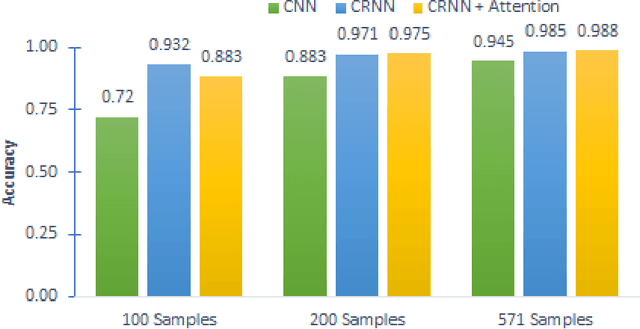
Language Identification (LID), a recommended initial step to Automatic Speech Recognition (ASR), is used to detect a spoken language from audio specimens. In state-of-the-art systems capable of multilingual speech processing, however, users have to explicitly set one or more languages before using them. LID, therefore, plays a very important role in situations where ASR based systems cannot parse the uttered language in multilingual contexts causing failure in speech recognition. We propose an attention based convolutional recurrent neural network (CRNN with Attention) that works on Mel-frequency Cepstral Coefficient (MFCC) features of audio specimens. Additionally, we reproduce some state-of-the-art approaches, namely Convolutional Neural Network (CNN) and Convolutional Recurrent Neural Network (CRNN), and compare them to our proposed method. We performed extensive evaluation on thirteen different Indian languages and our model achieves classification accuracy over 98%. Our LID model is robust to noise and provides 91.2% accuracy in a noisy scenario. The proposed model is easily extensible to new languages.
M2MeT: The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Challenge
Oct 14, 2021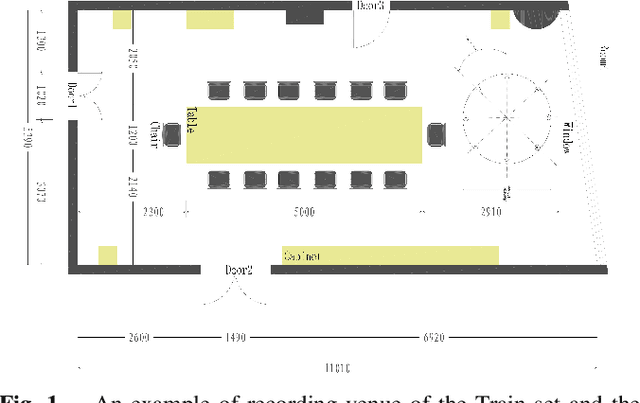
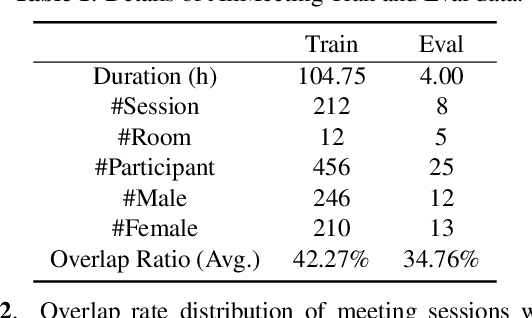
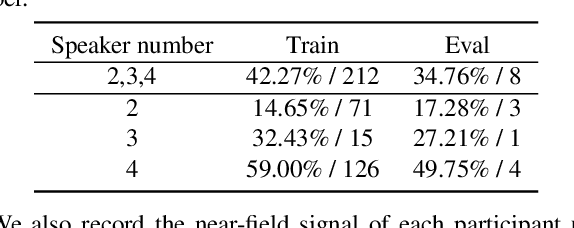
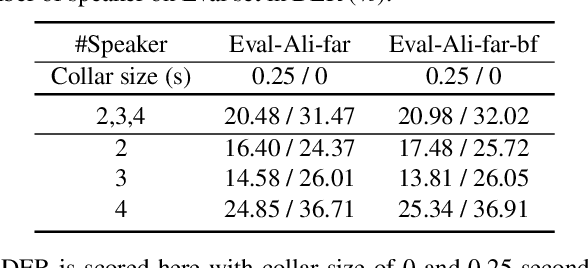
Recent development of speech signal processing, such as speech recognition, speaker diarization, etc., has inspired numerous applications of speech technologies. The meeting scenario is one of the most valuable and, at the same time, most challenging scenarios for speech technologies. Speaker diarization and multi-speaker automatic speech recognition in meeting scenarios have attracted increasing attention. However, the lack of large public real meeting data has been a major obstacle for advancement of the field. Therefore, we release the \emph{AliMeeting} corpus, which consists of 120 hours of real recorded Mandarin meeting data, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. Moreover, we will launch the Multi-channel Multi-party Meeting Transcription Challenge (M2MeT), as an ICASSP2022 Signal Processing Grand Challenge. The challenge consists of two tracks, namely speaker diarization and multi-speaker ASR. In this paper we provide a detailed introduction of the dateset, rules, evaluation methods and baseline systems, aiming to further promote reproducible research in this field.
Sequence-based Multi-lingual Low Resource Speech Recognition
Mar 06, 2018
Techniques for multi-lingual and cross-lingual speech recognition can help in low resource scenarios, to bootstrap systems and enable analysis of new languages and domains. End-to-end approaches, in particular sequence-based techniques, are attractive because of their simplicity and elegance. While it is possible to integrate traditional multi-lingual bottleneck feature extractors as front-ends, we show that end-to-end multi-lingual training of sequence models is effective on context independent models trained using Connectionist Temporal Classification (CTC) loss. We show that our model improves performance on Babel languages by over 6% absolute in terms of word/phoneme error rate when compared to mono-lingual systems built in the same setting for these languages. We also show that the trained model can be adapted cross-lingually to an unseen language using just 25% of the target data. We show that training on multiple languages is important for very low resource cross-lingual target scenarios, but not for multi-lingual testing scenarios. Here, it appears beneficial to include large well prepared datasets.
Representation learning through cross-modal conditional teacher-student training for speech emotion recognition
Nov 30, 2021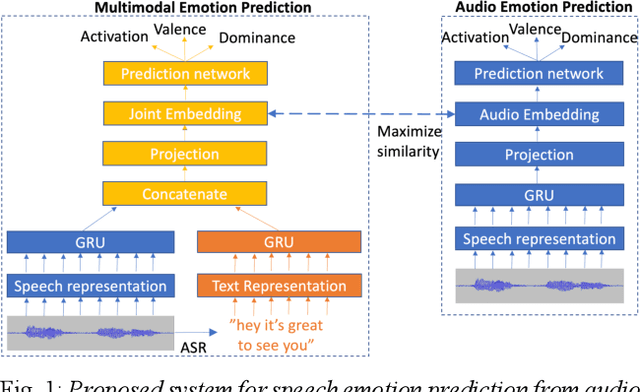
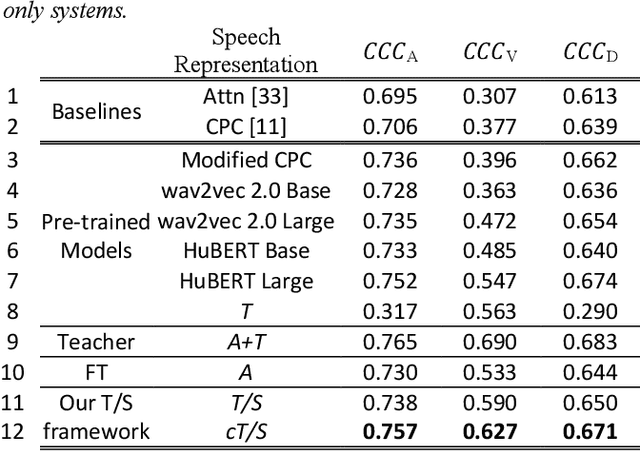
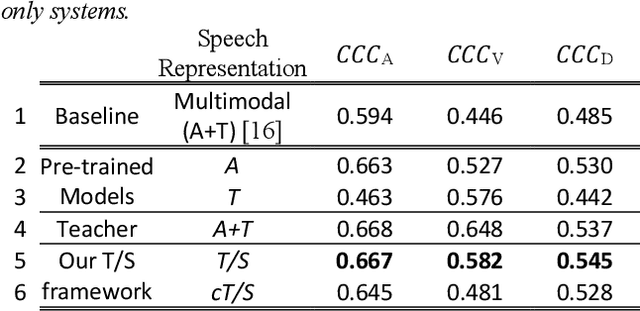
Generic pre-trained speech and text representations promise to reduce the need for large labeled datasets on specific speech and language tasks. However, it is not clear how to effectively adapt these representations for speech emotion recognition. Recent public benchmarks show the efficacy of several popular self-supervised speech representations for emotion classification. In this study, we show that the primary difference between the top-performing representations is in predicting valence while the differences in predicting activation and dominance dimensions are less pronounced. However, we show that even the best-performing HuBERT representation underperforms on valence prediction compared to a multimodal model that also incorporates text representation. We address this shortcoming by injecting lexical information into the speech representation using the multimodal model as a teacher. To improve the efficacy of our approach, we propose a novel estimate of the quality of the emotion predictions, to condition teacher-student training. We report new audio-only state-of-the-art concordance correlation coefficient (CCC) values of 0.757, 0.627, 0.671 for activation, valence and dominance predictions, respectively, on the MSP-Podcast corpus, and also state-of-the-art values of 0.667, 0.582, 0.545 on the IEMOCAP corpus.
High-Accuracy and Low-Latency Speech Recognition with Two-Head Contextual Layer Trajectory LSTM Model
Mar 17, 2020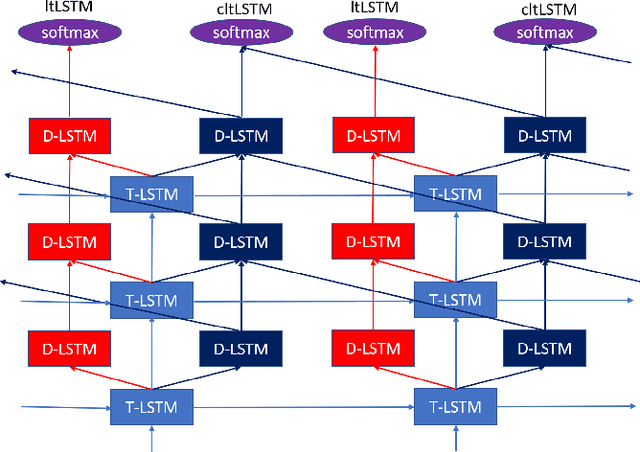
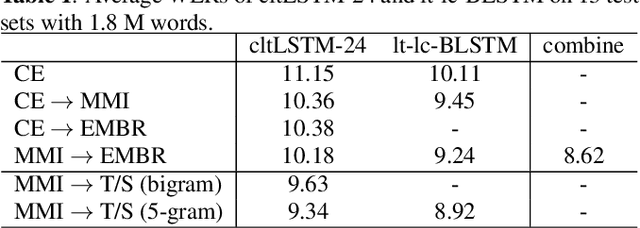
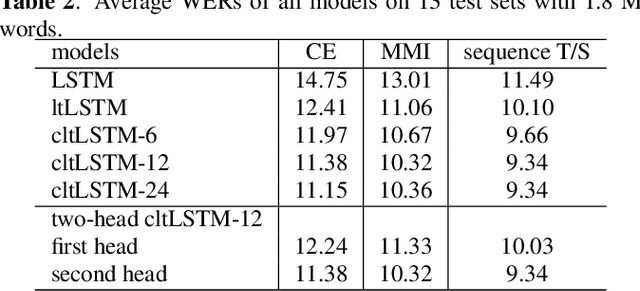
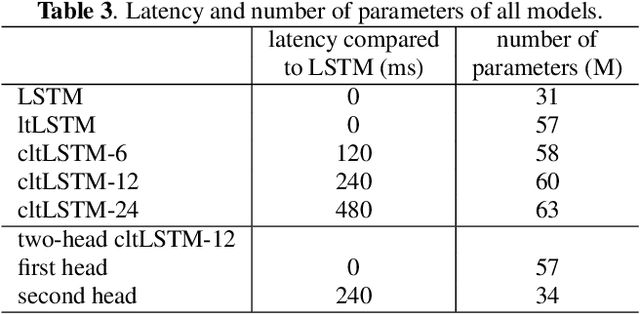
While the community keeps promoting end-to-end models over conventional hybrid models, which usually are long short-term memory (LSTM) models trained with a cross entropy criterion followed by a sequence discriminative training criterion, we argue that such conventional hybrid models can still be significantly improved. In this paper, we detail our recent efforts to improve conventional hybrid LSTM acoustic models for high-accuracy and low-latency automatic speech recognition. To achieve high accuracy, we use a contextual layer trajectory LSTM (cltLSTM), which decouples the temporal modeling and target classification tasks, and incorporates future context frames to get more information for accurate acoustic modeling. We further improve the training strategy with sequence-level teacher-student learning. To obtain low latency, we design a two-head cltLSTM, in which one head has zero latency and the other head has a small latency, compared to an LSTM. When trained with Microsoft's 65 thousand hours of anonymized training data and evaluated with test sets with 1.8 million words, the proposed two-head cltLSTM model with the proposed training strategy yields a 28.2\% relative WER reduction over the conventional LSTM acoustic model, with a similar perceived latency.
Summary On The ICASSP 2022 Multi-Channel Multi-Party Meeting Transcription Grand Challenge
Feb 08, 2022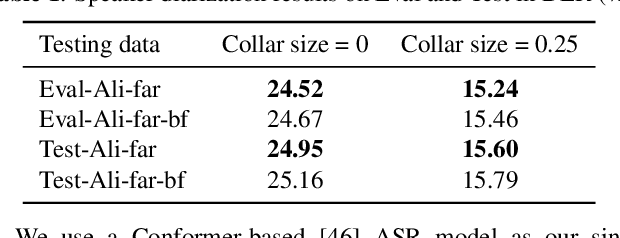
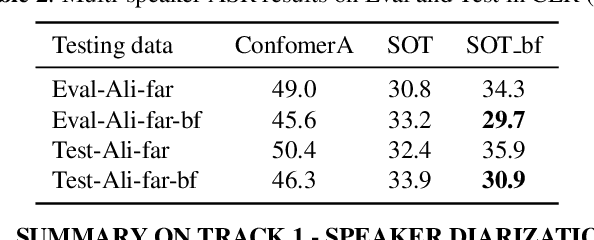
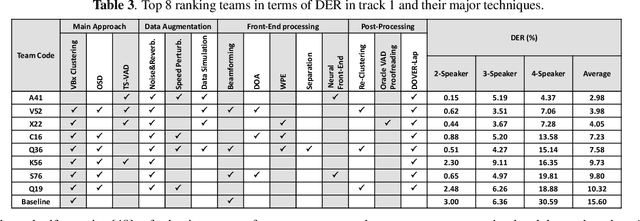
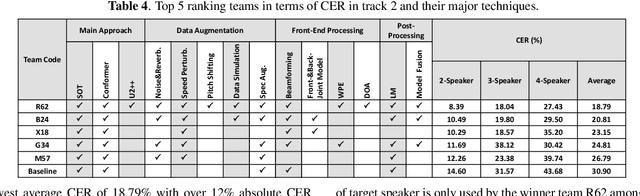
The ICASSP 2022 Multi-channel Multi-party Meeting Transcription Grand Challenge (M2MeT) focuses on one of the most valuable and the most challenging scenarios of speech technologies. The M2MeT challenge has particularly set up two tracks, speaker diarization (track 1) and multi-speaker automatic speech recognition (ASR) (track 2). Along with the challenge, we released 120 hours of real-recorded Mandarin meeting speech data with manual annotation, including far-field data collected by 8-channel microphone array as well as near-field data collected by each participants' headset microphone. We briefly describe the released dataset, track setups, baselines and summarize the challenge results and major techniques used in the submissions.
Towards speech-to-text translation without speech recognition
Feb 13, 2017
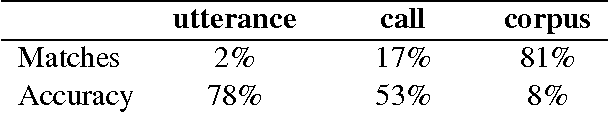

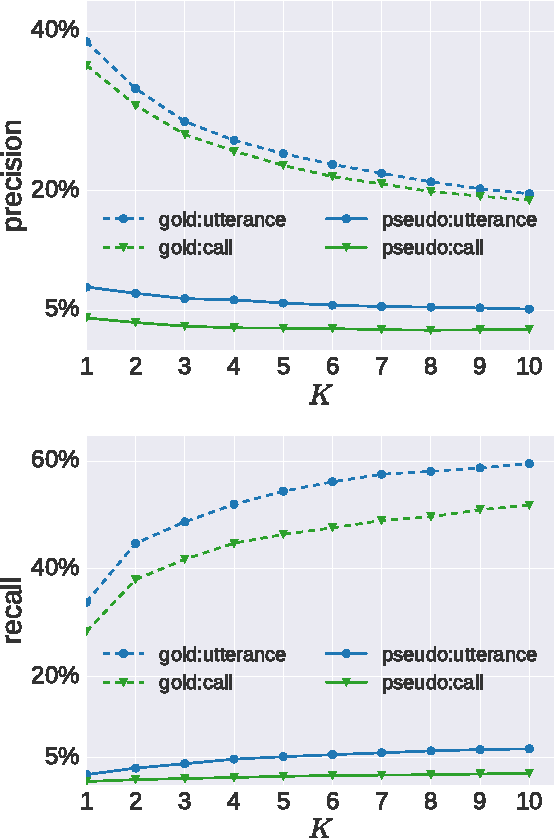
We explore the problem of translating speech to text in low-resource scenarios where neither automatic speech recognition (ASR) nor machine translation (MT) are available, but we have training data in the form of audio paired with text translations. We present the first system for this problem applied to a realistic multi-speaker dataset, the CALLHOME Spanish-English speech translation corpus. Our approach uses unsupervised term discovery (UTD) to cluster repeated patterns in the audio, creating a pseudotext, which we pair with translations to create a parallel text and train a simple bag-of-words MT model. We identify the challenges faced by the system, finding that the difficulty of cross-speaker UTD results in low recall, but that our system is still able to correctly translate some content words in test data.
Integrating Source-channel and Attention-based Sequence-to-sequence Models for Speech Recognition
Sep 14, 2019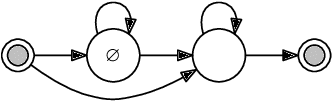
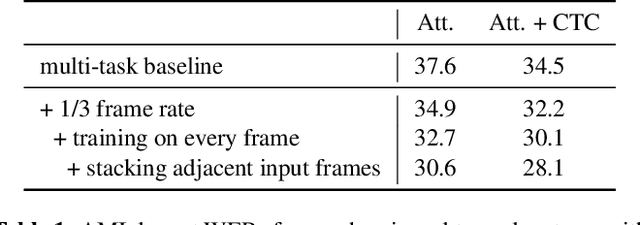
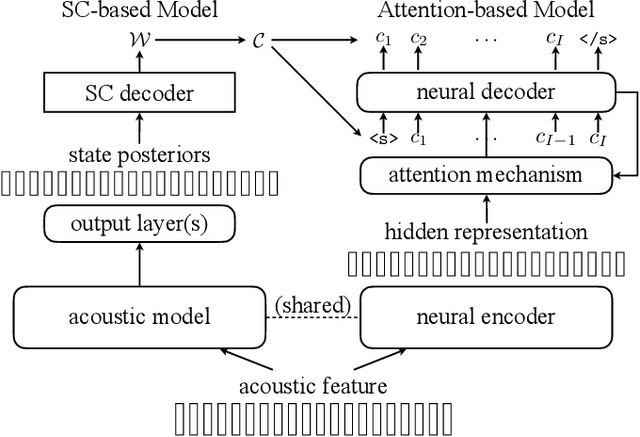

This paper proposes a novel automatic speech recognition (ASR) framework called Integrated Source-Channel and Attention (ISCA) that combines the advantages of traditional systems based on the noisy source-channel model (SC) and end-to-end style systems using attention-based sequence-to-sequence models. The traditional SC system framework includes hidden Markov models and connectionist temporal classification (CTC) based acoustic models, language models (LMs), and a decoding procedure based on a lexicon, whereas the end-to-end style attention-based system jointly models the whole process with a single model. By rescoring the hypotheses produced by traditional systems using end-to-end style systems based on an extended noisy source-channel model, ISCA allows structured knowledge to be easily incorporated via the SC-based model while exploiting the complementarity of the attention-based model. Experiments on the AMI meeting corpus show that ISCA is able to give a relative word error rate reduction up to 21% over an individual system, and by 13% over an alternative method which also involves combining CTC and attention-based models.