 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
End-to-End Speech Recognition with High-Frame-Rate Features Extraction
Jul 12, 2019
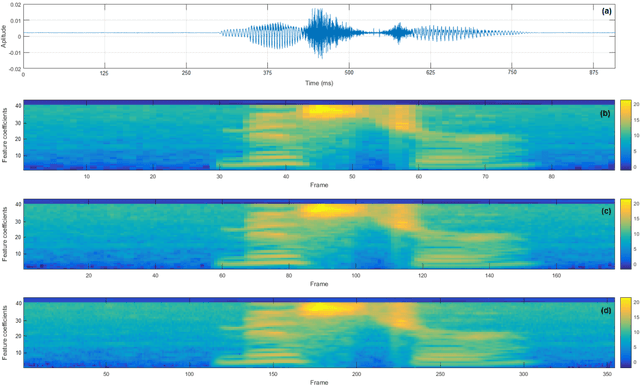
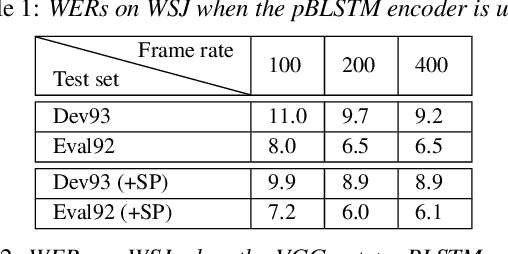
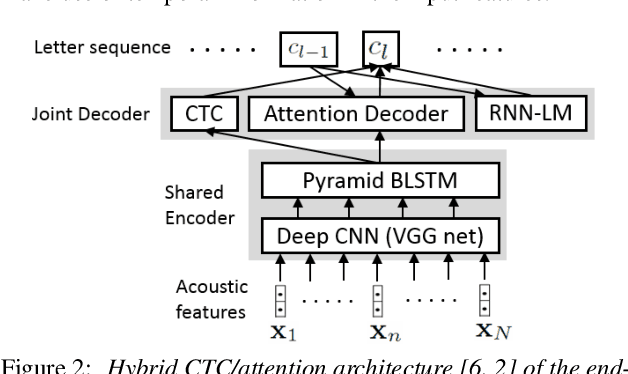
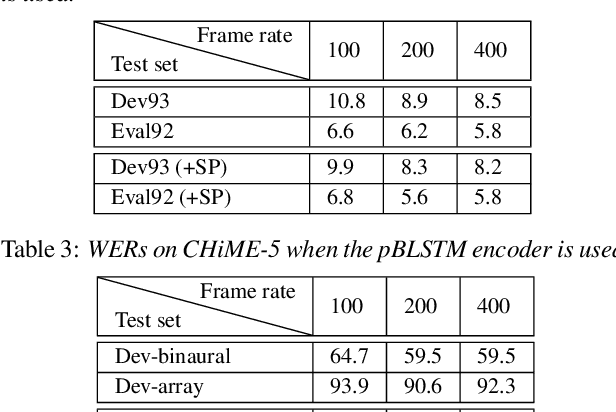
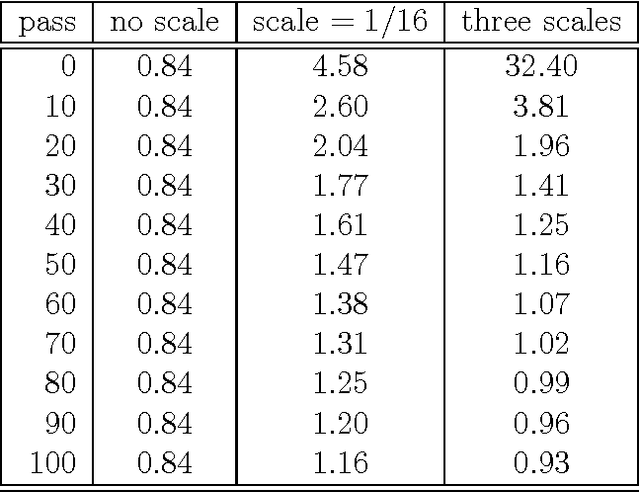
State-of-the-art end-to-end automatic speech recognition (ASR) extracts acoustic features from input speech signal every 10 ms which corresponds to a frame rate of 100 frames/second. In this report, we investigate the use of high-frame-rate features extraction in end-to-end ASR. High frame rates of 200 and 400 frames/second are used in the features extraction and provide additional information for end-to-end ASR. The effectiveness of high-frame-rate features extraction is evaluated independently and in combination with speed perturbation based data augmentation. Experiments performed on two speech corpora, Wall Street Journal (WSJ) and CHiME-5, show that using high-frame-rate features extraction yields improved performance for end-to-end ASR, both independently and in combination with speed perturbation. On WSJ corpus, the relative reduction of word error rate (WER) yielded by high-frame-rate features extraction independently and in combination with speed perturbation are up to 21.3% and 24.1%, respectively. On CHiME-5 corpus, the corresponding relative WER reductions are up to 2.8% and 7.9%, respectively, on the test data recorded by microphone arrays and up to 11.8% and 21.2%, respectively, on the test data recorded by binaural microphones.
Speech Emotion Recognition using Supervised Deep Recurrent System for Mental Health Monitoring
Aug 26, 2022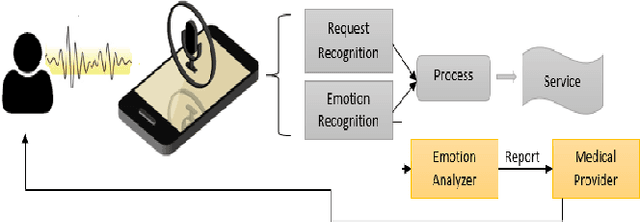
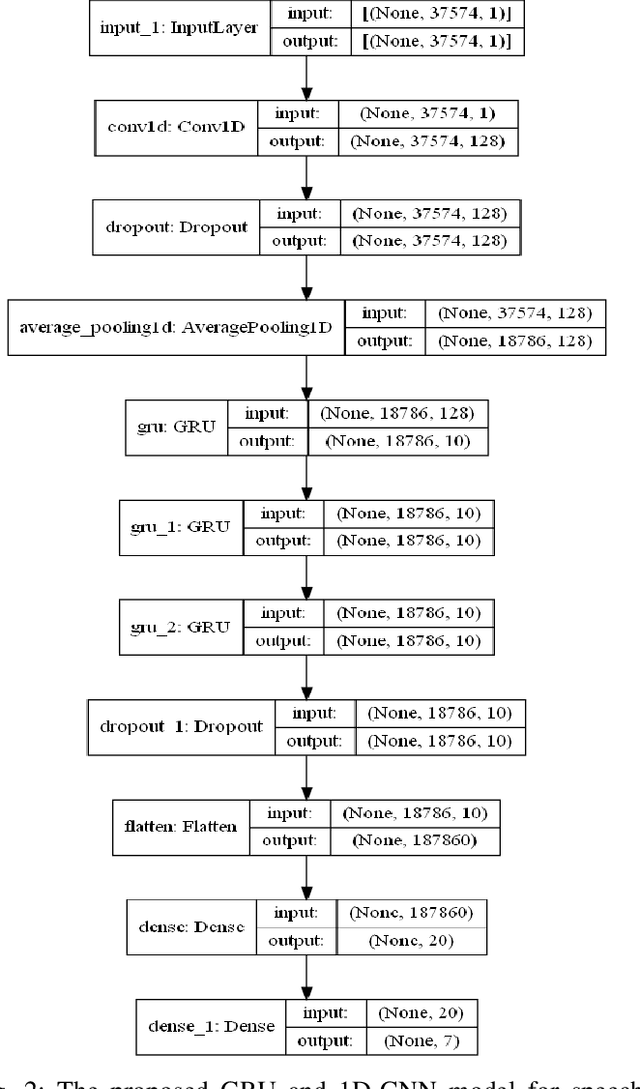
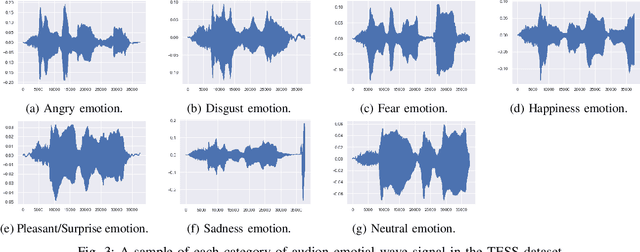
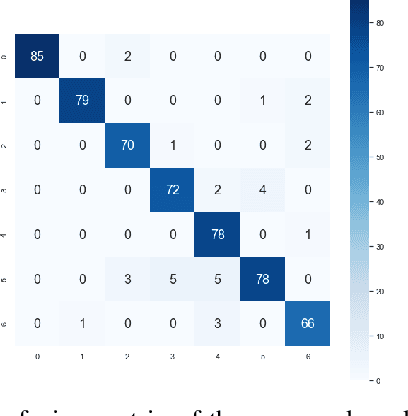
Understanding human behavior and monitoring mental health are essential to maintaining the community and society's safety. As there has been an increase in mental health problems during the COVID-19 pandemic due to uncontrolled mental health, early detection of mental issues is crucial. Nowadays, the usage of Intelligent Virtual Personal Assistants (IVA) has increased worldwide. Individuals use their voices to control these devices to fulfill requests and acquire different services. This paper proposes a novel deep learning model based on the gated recurrent neural network and convolution neural network to understand human emotion from speech to improve their IVA services and monitor their mental health.
Automatic Speech Recognition with Very Large Conversational Finnish and Estonian Vocabularies
Sep 29, 2017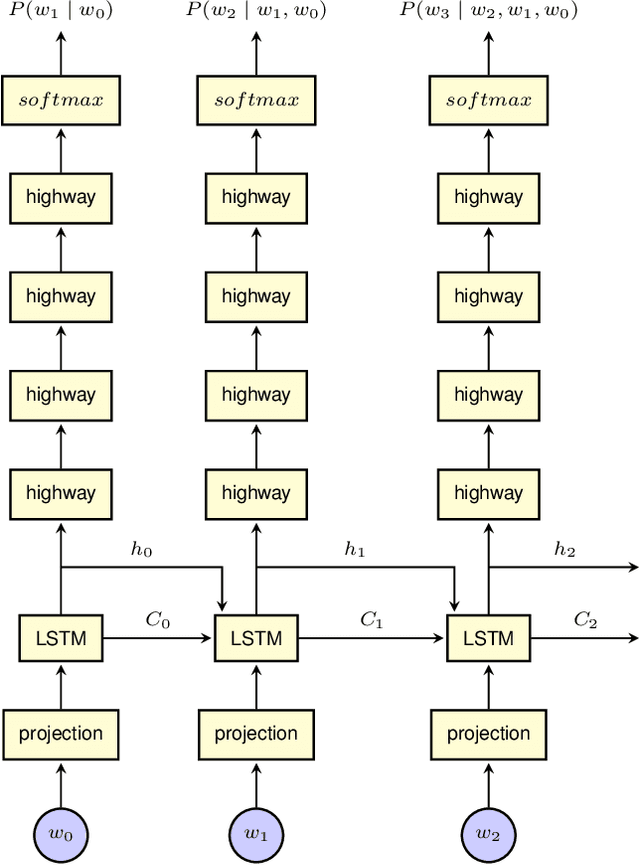

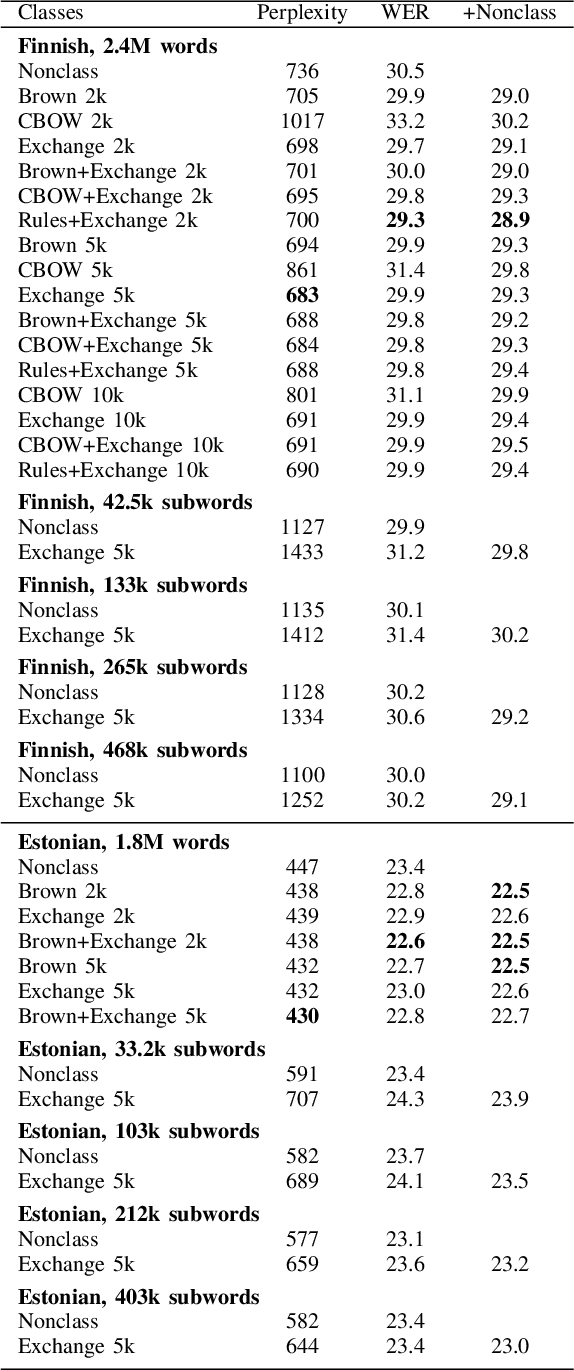
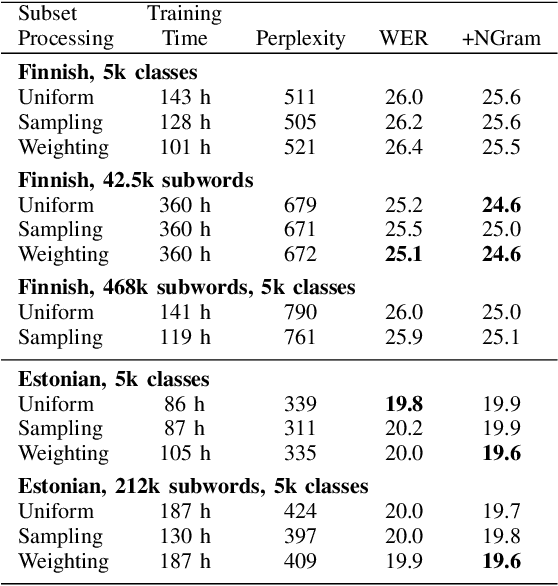
Today, the vocabulary size for language models in large vocabulary speech recognition is typically several hundreds of thousands of words. While this is already sufficient in some applications, the out-of-vocabulary words are still limiting the usability in others. In agglutinative languages the vocabulary for conversational speech should include millions of word forms to cover the spelling variations due to colloquial pronunciations, in addition to the word compounding and inflections. Very large vocabularies are also needed, for example, when the recognition of rare proper names is important.
Why has (reasonably accurate) Automatic Speech Recognition been so hard to achieve?
Feb 28, 2010

Hidden Markov models (HMMs) have been successfully applied to automatic speech recognition for more than 35 years in spite of the fact that a key HMM assumption -- the statistical independence of frames -- is obviously violated by speech data. In fact, this data/model mismatch has inspired many attempts to modify or replace HMMs with alternative models that are better able to take into account the statistical dependence of frames. However it is fair to say that in 2010 the HMM is the consensus model of choice for speech recognition and that HMMs are at the heart of both commercially available products and contemporary research systems. In this paper we present a preliminary exploration aimed at understanding how speech data depart from HMMs and what effect this departure has on the accuracy of HMM-based speech recognition. Our analysis uses standard diagnostic tools from the field of statistics -- hypothesis testing, simulation and resampling -- which are rarely used in the field of speech recognition. Our main result, obtained by novel manipulations of real and resampled data, demonstrates that real data have statistical dependency and that this dependency is responsible for significant numbers of recognition errors. We also demonstrate, using simulation and resampling, that if we `remove' the statistical dependency from data, then the resulting recognition error rates become negligible. Taken together, these results suggest that a better understanding of the structure of the statistical dependency in speech data is a crucial first step towards improving HMM-based speech recognition.
End-to-end multi-talker audio-visual ASR using an active speaker attention module
Apr 01, 2022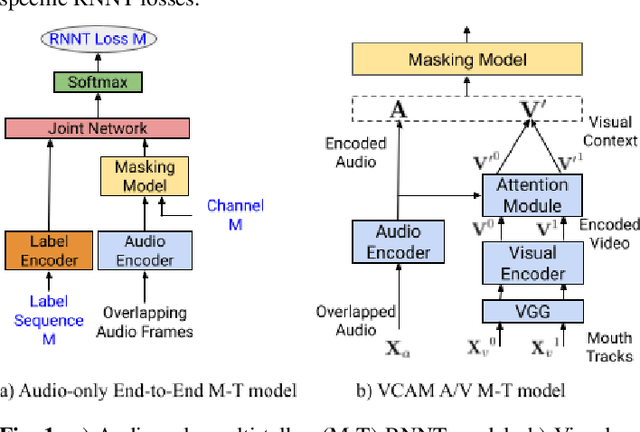
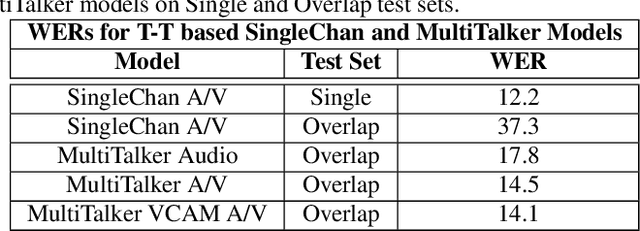
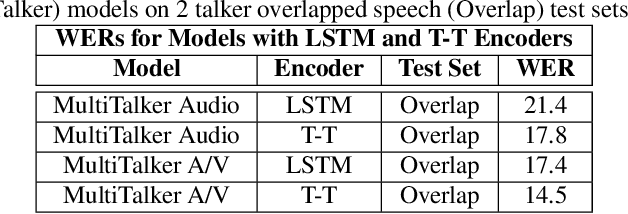
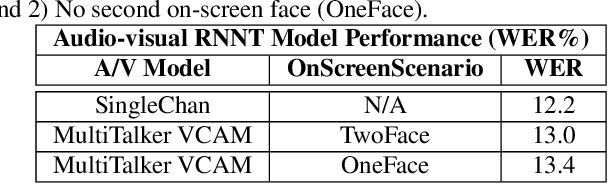
This paper presents a new approach for end-to-end audio-visual multi-talker speech recognition. The approach, referred to here as the visual context attention model (VCAM), is important because it uses the available video information to assign decoded text to one of multiple visible faces. This essentially resolves the label ambiguity issue associated with most multi-talker modeling approaches which can decode multiple label strings but cannot assign the label strings to the correct speakers. This is implemented as a transformer-transducer based end-to-end model and evaluated using a two speaker audio-visual overlapping speech dataset created from YouTube videos. It is shown in the paper that the VCAM model improves performance with respect to previously reported audio-only and audio-visual multi-talker ASR systems.
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Feb 26, 2022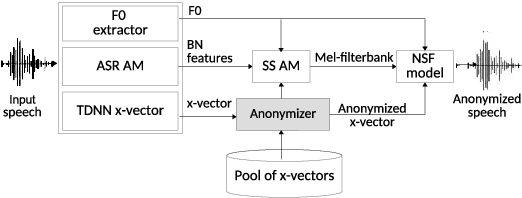
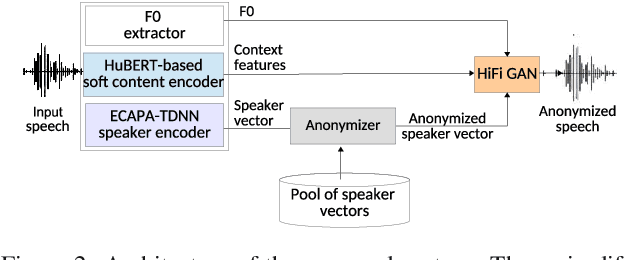

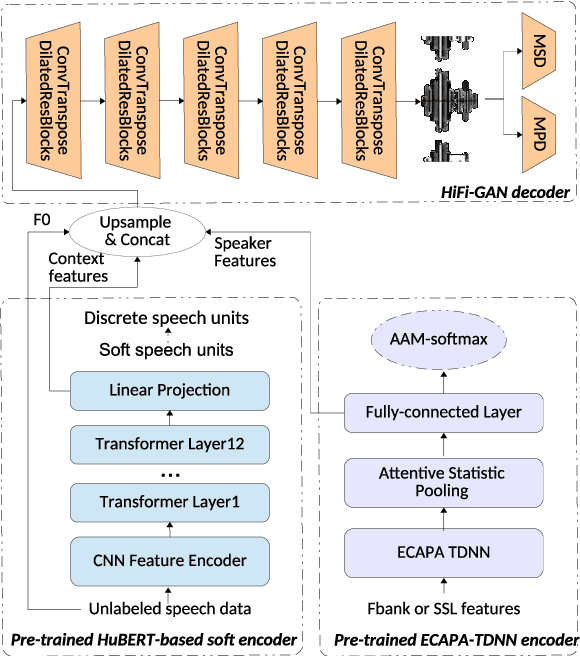
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
Transfer learning from High-Resource to Low-Resource Language Improves Speech Affect Recognition Classification Accuracy
Mar 04, 2021

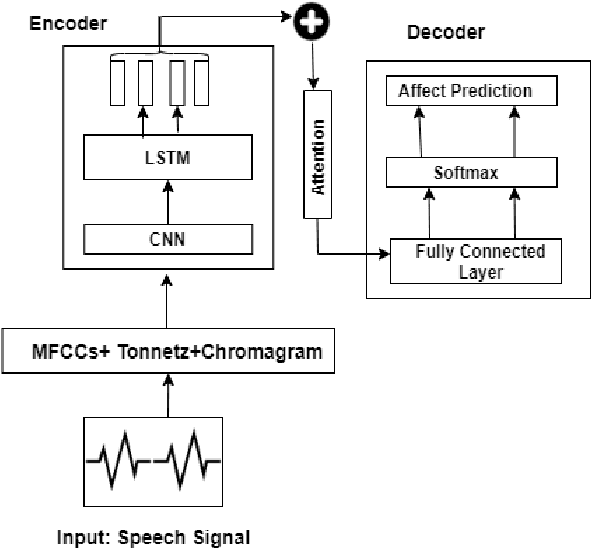
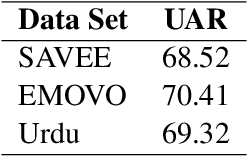
Speech Affect Recognition is a problem of extracting emotional affects from audio data. Low resource languages corpora are rear and affect recognition is a difficult task in cross-corpus settings. We present an approach in which the model is trained on high resource language and fine-tune to recognize affects in low resource language. We train the model in same corpus setting on SAVEE, EMOVO, Urdu, and IEMOCAP by achieving baseline accuracy of 60.45, 68.05, 80.34, and 56.58 percent respectively. For capturing the diversity of affects in languages cross-corpus evaluations are discussed in detail. We find that accuracy improves by adding the domain target data into the training data. Finally, we show that performance is improved for low resource language speech affect recognition by achieving the UAR OF 69.32 and 68.2 for Urdu and Italian speech affects.
Spectral feature mapping with mimic loss for robust speech recognition
Mar 26, 2018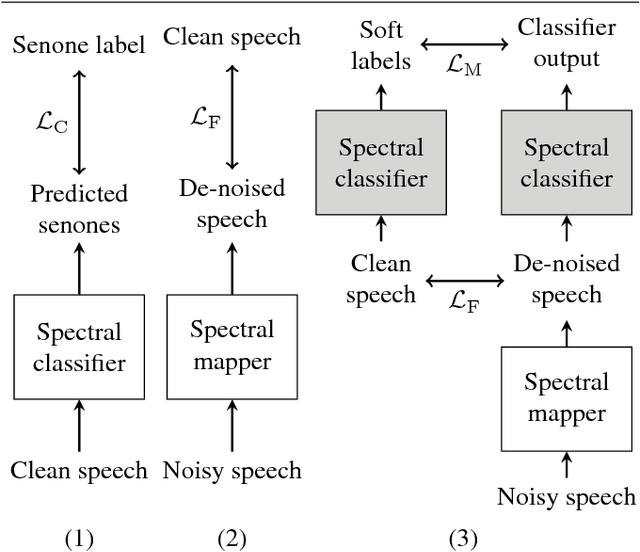
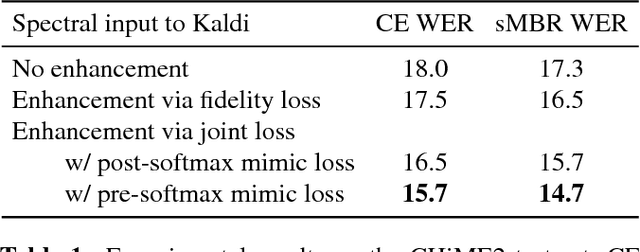
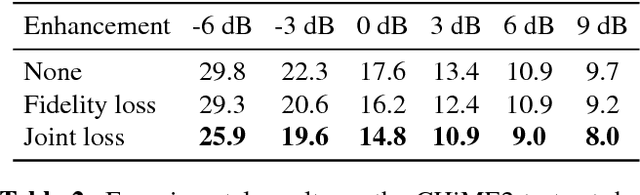
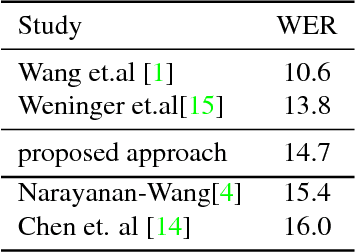
For the task of speech enhancement, local learning objectives are agnostic to phonetic structures helpful for speech recognition. We propose to add a global criterion to ensure de-noised speech is useful for downstream tasks like ASR. We first train a spectral classifier on clean speech to predict senone labels. Then, the spectral classifier is joined with our speech enhancer as a noisy speech recognizer. This model is taught to imitate the output of the spectral classifier alone on clean speech. This \textit{mimic loss} is combined with the traditional local criterion to train the speech enhancer to produce de-noised speech. Feeding the de-noised speech to an off-the-shelf Kaldi training recipe for the CHiME-2 corpus shows significant improvements in WER.
CMGAN: Conformer-based Metric GAN for Speech Enhancement
Mar 28, 2022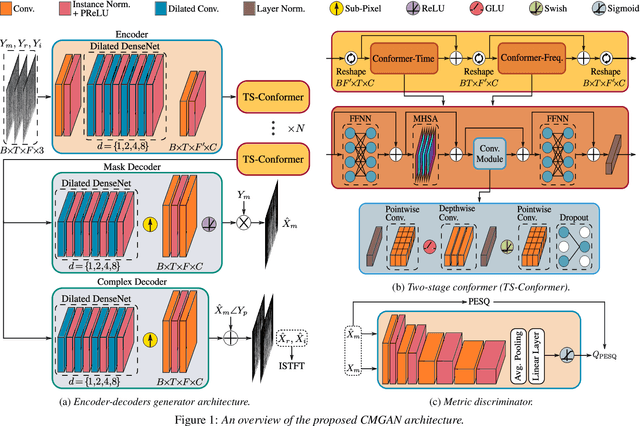
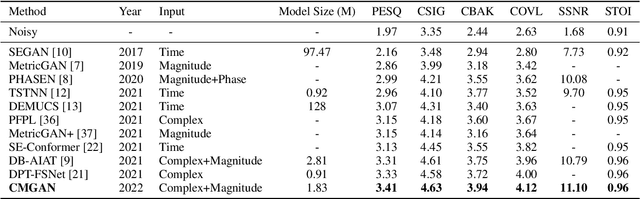
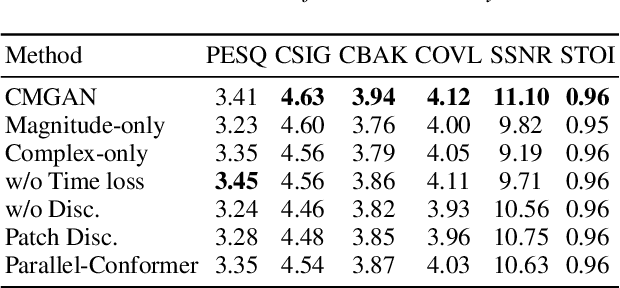
Recently, convolution-augmented transformer (Conformer) has achieved promising performance in automatic speech recognition (ASR) and time-domain speech enhancement (SE), as it can capture both local and global dependencies in the speech signal. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for SE in the time-frequency (TF) domain. In the generator, we utilize two-stage conformer blocks to aggregate all magnitude and complex spectrogram information by modeling both time and frequency dependencies. The estimation of magnitude and complex spectrogram is decoupled in the decoder stage and then jointly incorporated to reconstruct the enhanced speech. In addition, a metric discriminator is employed to further improve the quality of the enhanced estimated speech by optimizing the generator with respect to a corresponding evaluation score. Quantitative analysis on Voice Bank+DEMAND dataset indicates the capability of CMGAN in outperforming various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.