 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"speech recognition": models, code, and papers
Closing the Gap Between Time-Domain Multi-Channel Speech Enhancement on Real and Simulation Conditions
Oct 27, 2021

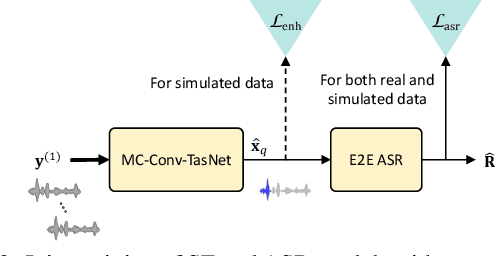
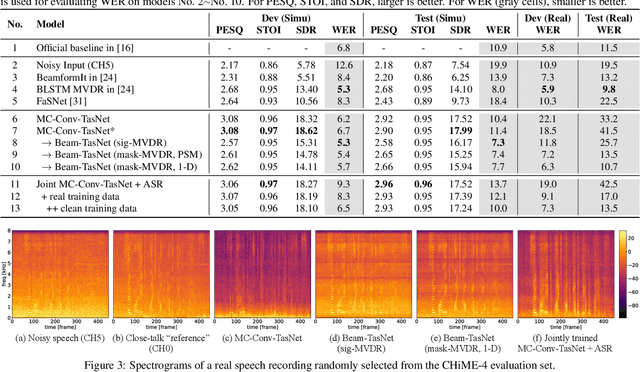
The deep learning based time-domain models, e.g. Conv-TasNet, have shown great potential in both single-channel and multi-channel speech enhancement. However, many experiments on the time-domain speech enhancement model are done in simulated conditions, and it is not well studied whether the good performance can generalize to real-world scenarios. In this paper, we aim to provide an insightful investigation of applying multi-channel Conv-TasNet based speech enhancement to both simulation and real data. Our preliminary experiments show a large performance gap between the two conditions in terms of the ASR performance. Several approaches are applied to close this gap, including the integration of multi-channel Conv-TasNet into the beamforming model with various strategies, and the joint training of speech enhancement and speech recognition models. Our experiments on the CHiME-4 corpus show that our proposed approaches can greatly reduce the speech recognition performance discrepancy between simulation and real data, while preserving the strong speech enhancement capability in the frontend.
Learning linearly separable features for speech recognition using convolutional neural networks
Apr 16, 2015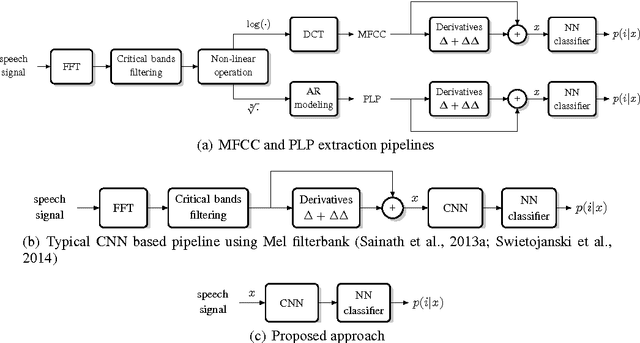
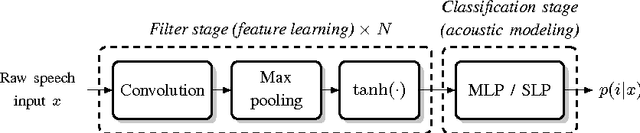
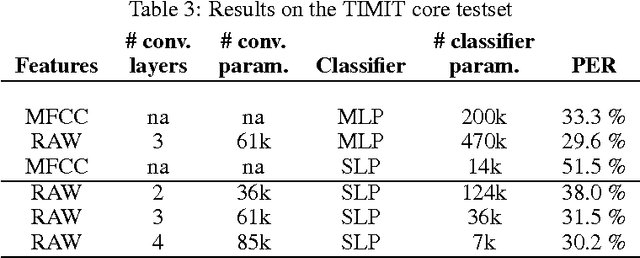
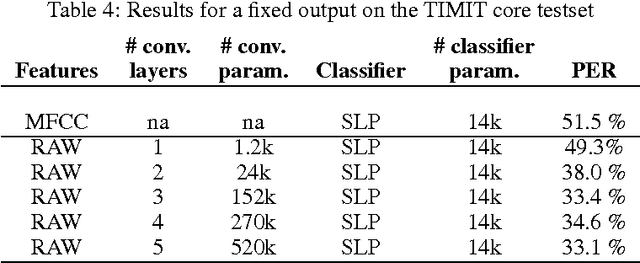
Automatic speech recognition systems usually rely on spectral-based features, such as MFCC of PLP. These features are extracted based on prior knowledge such as, speech perception or/and speech production. Recently, convolutional neural networks have been shown to be able to estimate phoneme conditional probabilities in a completely data-driven manner, i.e. using directly temporal raw speech signal as input. This system was shown to yield similar or better performance than HMM/ANN based system on phoneme recognition task and on large scale continuous speech recognition task, using less parameters. Motivated by these studies, we investigate the use of simple linear classifier in the CNN-based framework. Thus, the network learns linearly separable features from raw speech. We show that such system yields similar or better performance than MLP based system using cepstral-based features as input.
A Unified Cascaded Encoder ASR Model for Dynamic Model Sizes
Apr 20, 2022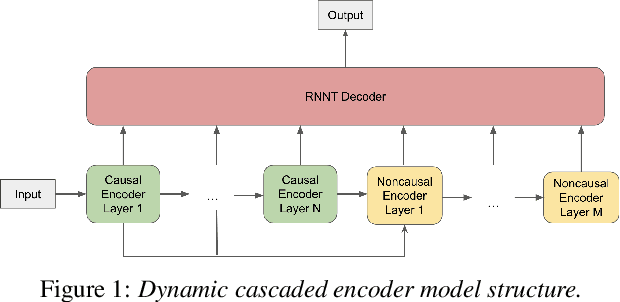
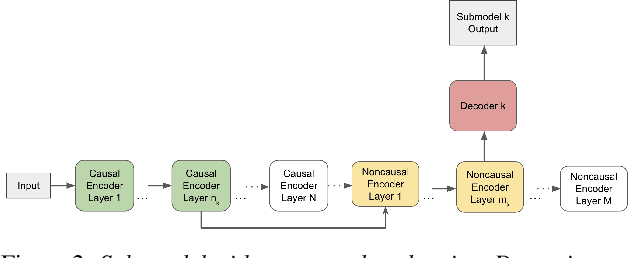
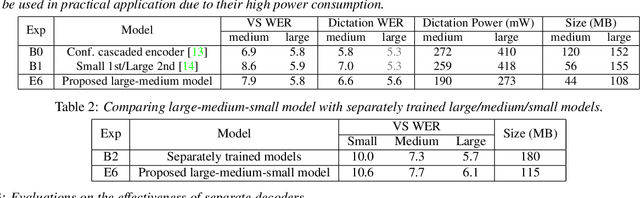
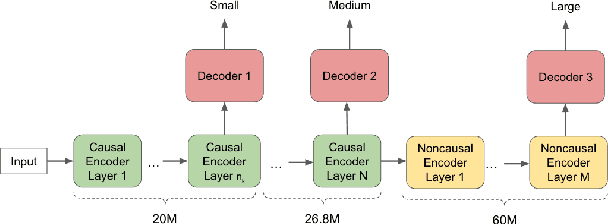
In this paper, we propose a dynamic cascaded encoder Automatic Speech Recognition (ASR) model, which unifies models for different deployment scenarios. Moreover, the model can significantly reduce model size and power consumption without loss of quality. Namely, with the dynamic cascaded encoder model, we explore three techniques to maximally boost the performance of each model size: 1) Use separate decoders for each sub-model while sharing the encoders; 2) Use funnel-pooling to improve the encoder efficiency; 3) Balance the size of causal and non-causal encoders to improve quality and fit deployment constraints. Overall, the proposed large-medium model has 30% smaller size and reduces power consumption by 33%, compared to the baseline cascaded encoder model. The triple-size model that unifies the large, medium, and small models achieves 37% total size reduction with minimal quality loss, while substantially reducing the engineering efforts of having separate models.
CMGAN: Conformer-based Metric GAN for Speech Enhancement
Mar 28, 2022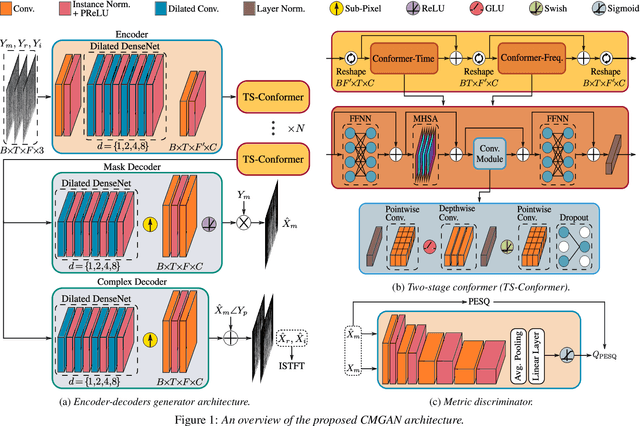
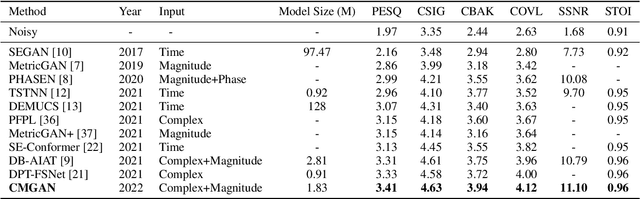
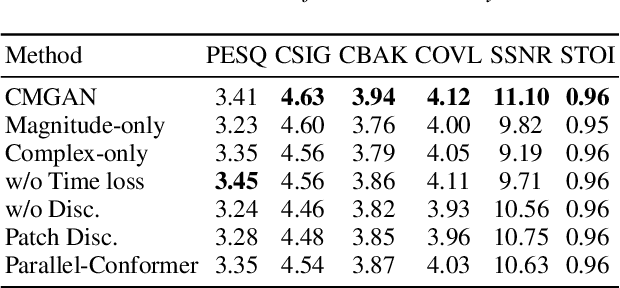
Recently, convolution-augmented transformer (Conformer) has achieved promising performance in automatic speech recognition (ASR) and time-domain speech enhancement (SE), as it can capture both local and global dependencies in the speech signal. In this paper, we propose a conformer-based metric generative adversarial network (CMGAN) for SE in the time-frequency (TF) domain. In the generator, we utilize two-stage conformer blocks to aggregate all magnitude and complex spectrogram information by modeling both time and frequency dependencies. The estimation of magnitude and complex spectrogram is decoupled in the decoder stage and then jointly incorporated to reconstruct the enhanced speech. In addition, a metric discriminator is employed to further improve the quality of the enhanced estimated speech by optimizing the generator with respect to a corresponding evaluation score. Quantitative analysis on Voice Bank+DEMAND dataset indicates the capability of CMGAN in outperforming various previous models with a margin, i.e., PESQ of 3.41 and SSNR of 11.10 dB.
Analyzing Phonetic and Graphemic Representations in End-to-End Automatic Speech Recognition
Jul 09, 2019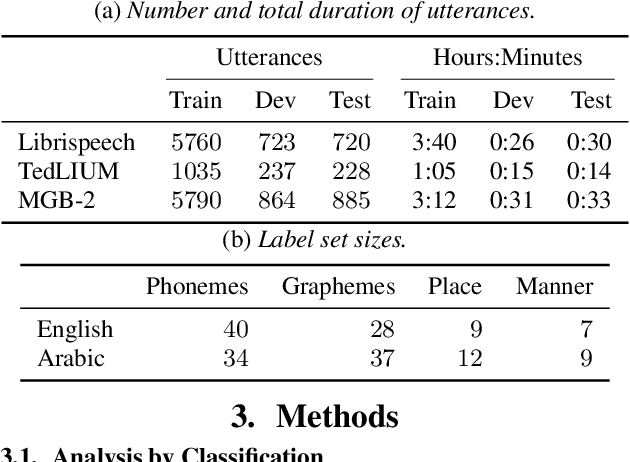
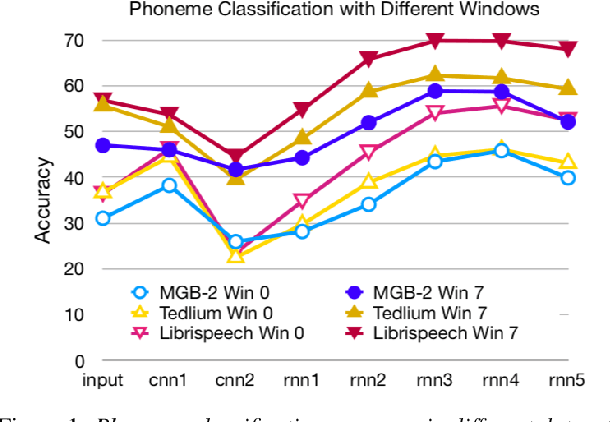

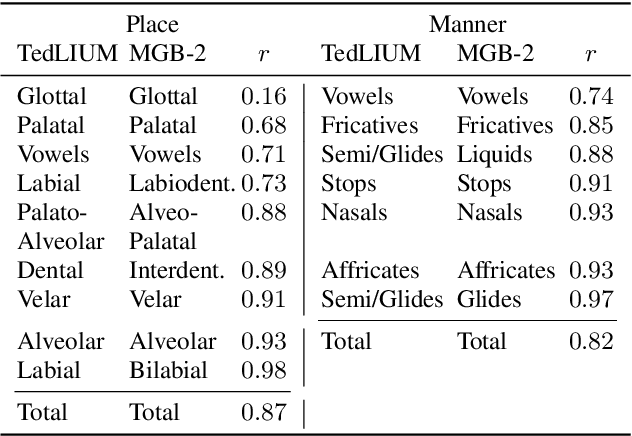
End-to-end neural network systems for automatic speech recognition (ASR) are trained from acoustic features to text transcriptions. In contrast to modular ASR systems, which contain separately-trained components for acoustic modeling, pronunciation lexicon, and language modeling, the end-to-end paradigm is both conceptually simpler and has the potential benefit of training the entire system on the end task. However, such neural network models are more opaque: it is not clear how to interpret the role of different parts of the network and what information it learns during training. In this paper, we analyze the learned internal representations in an end-to-end ASR model. We evaluate the representation quality in terms of several classification tasks, comparing phonemes and graphemes, as well as different articulatory features. We study two languages (English and Arabic) and three datasets, finding remarkable consistency in how different properties are represented in different layers of the deep neural network.
Language-Independent Speaker Anonymization Approach using Self-Supervised Pre-Trained Models
Feb 26, 2022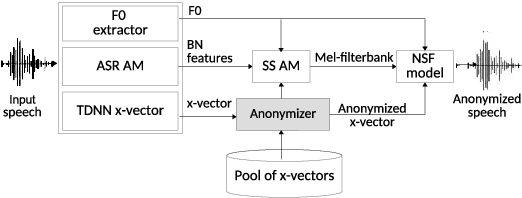
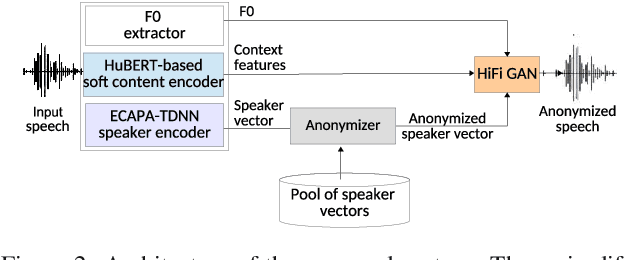

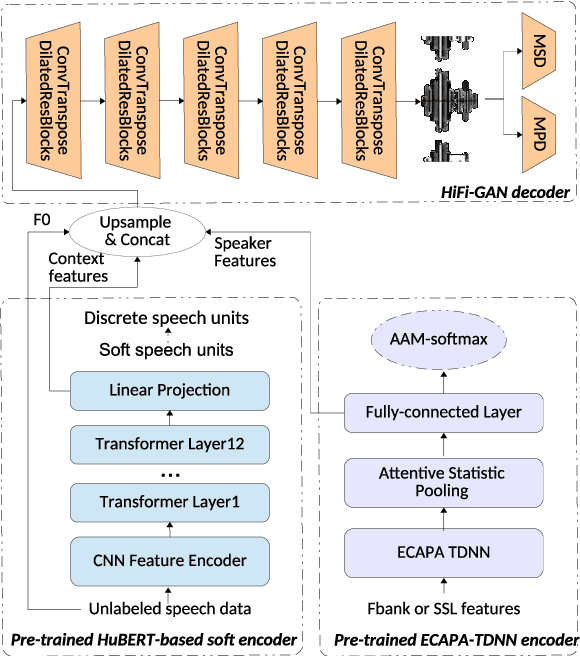
Speaker anonymization aims to protect the privacy of speakers while preserving spoken linguistic information from speech. Current mainstream neural network speaker anonymization systems are complicated, containing an F0 extractor, speaker encoder, automatic speech recognition acoustic model (ASR AM), speech synthesis acoustic model and speech waveform generation model. Moreover, as an ASR AM is language-dependent, trained on English data, it is hard to adapt it into another language. In this paper, we propose a simpler self-supervised learning (SSL)-based method for language-independent speaker anonymization without any explicit language-dependent model, which can be easily used for other languages. Extensive experiments were conducted on the VoicePrivacy Challenge 2020 datasets in English and AISHELL-3 datasets in Mandarin to demonstrate the effectiveness of our proposed SSL-based language-independent speaker anonymization method.
Distilling Knowledge Using Parallel Data for Far-field Speech Recognition
Feb 20, 2018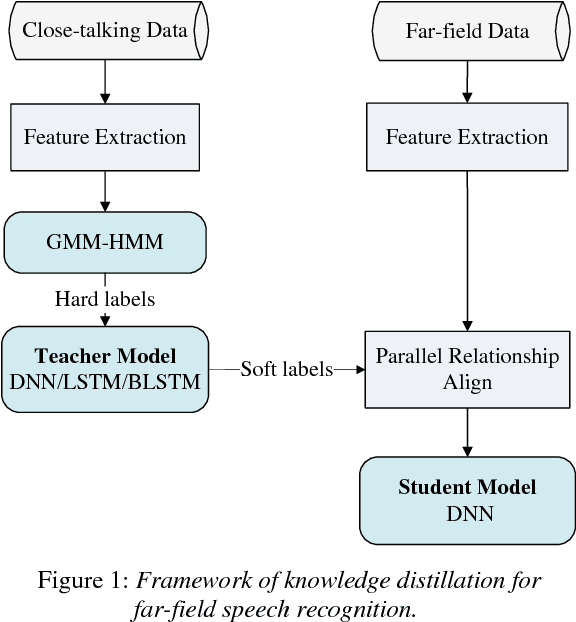

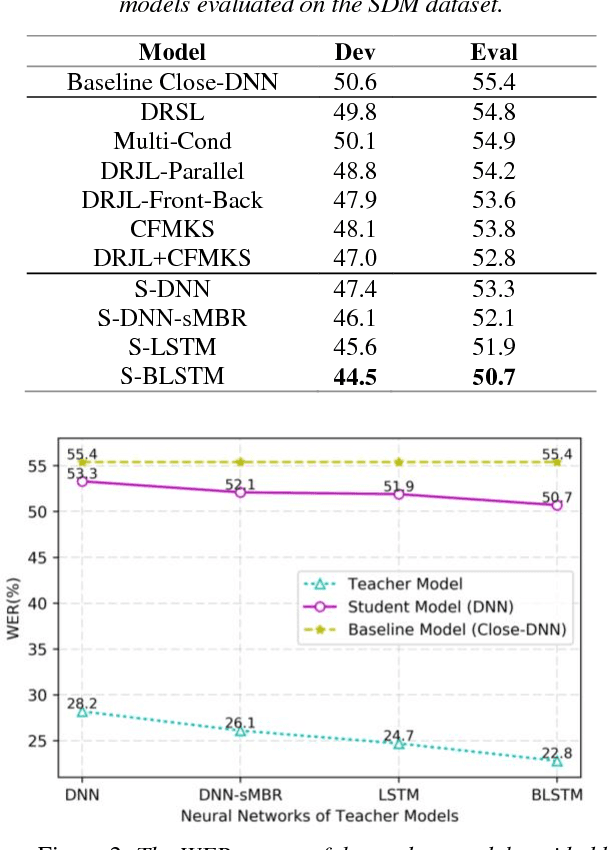
In order to improve the performance for far-field speech recognition, this paper proposes to distill knowledge from the close-talking model to the far-field model using parallel data. The close-talking model is called the teacher model. The far-field model is called the student model. The student model is trained to imitate the output distributions of the teacher model. This constraint can be realized by minimizing the Kullback-Leibler (KL) divergence between the output distribution of the student model and the teacher model. Experimental results on AMI corpus show that the best student model achieves up to 4.7% absolute word error rate (WER) reduction when compared with the conventionally-trained baseline models.
SUPERB @ SLT 2022: Challenge on Generalization and Efficiency of Self-Supervised Speech Representation Learning
Oct 16, 2022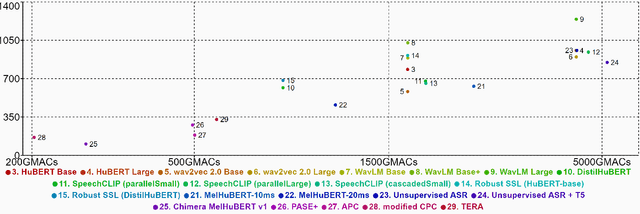
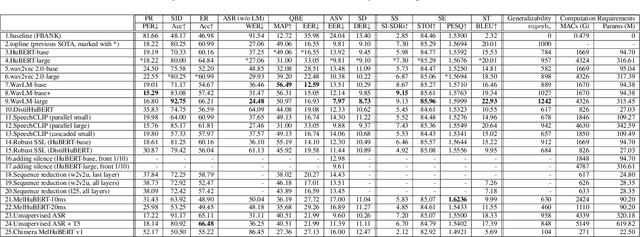
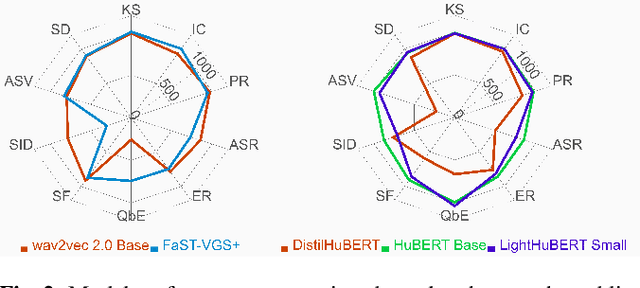
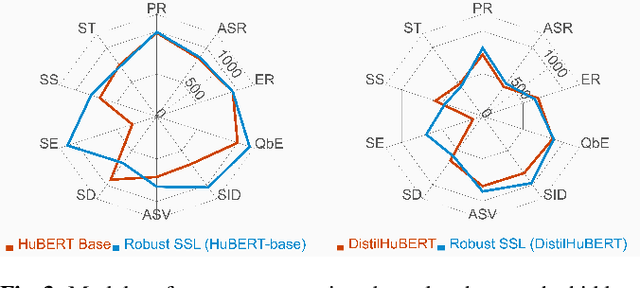
We present the SUPERB challenge at SLT 2022, which aims at learning self-supervised speech representation for better performance, generalization, and efficiency. The challenge builds upon the SUPERB benchmark and implements metrics to measure the computation requirements of self-supervised learning (SSL) representation and to evaluate its generalizability and performance across the diverse SUPERB tasks. The SUPERB benchmark provides comprehensive coverage of popular speech processing tasks, from speech and speaker recognition to audio generation and semantic understanding. As SSL has gained interest in the speech community and showed promising outcomes, we envision the challenge to uplevel the impact of SSL techniques by motivating more practical designs of techniques beyond task performance. We summarize the results of 14 submitted models in this paper. We also discuss the main findings from those submissions and the future directions of SSL research.
CUSIDE: Chunking, Simulating Future Context and Decoding for Streaming ASR
Mar 31, 2022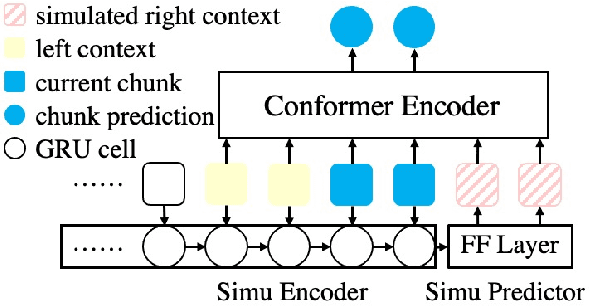
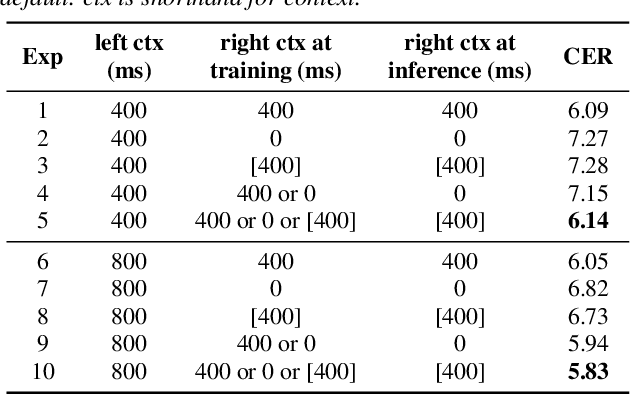
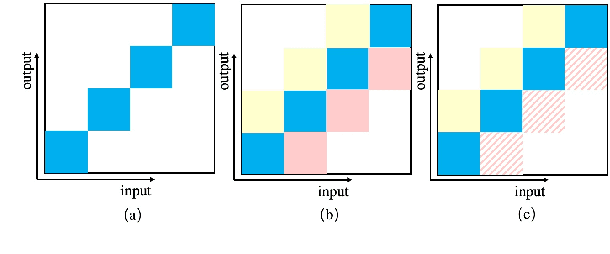

History and future contextual information are known to be important for accurate acoustic modeling. However, acquiring future context brings latency for streaming ASR. In this paper, we propose a new framework - Chunking, Simulating Future Context and Decoding (CUSIDE) for streaming speech recognition. A new simulation module is introduced to recursively simulate the future contextual frames, without waiting for future context. The simulation module is jointly trained with the ASR model using a self-supervised loss; the ASR model is optimized with the usual ASR loss, e.g., CTC-CRF as used in our experiments. Experiments show that, compared to using real future frames as right context, using simulated future context can drastically reduce latency while maintaining recognition accuracy. With CUSIDE, we obtain new state-of-the-art streaming ASR results on the AISHELL-1 dataset.
Domain Adaptation via Teacher-Student Learning for End-to-End Speech Recognition
Jan 06, 2020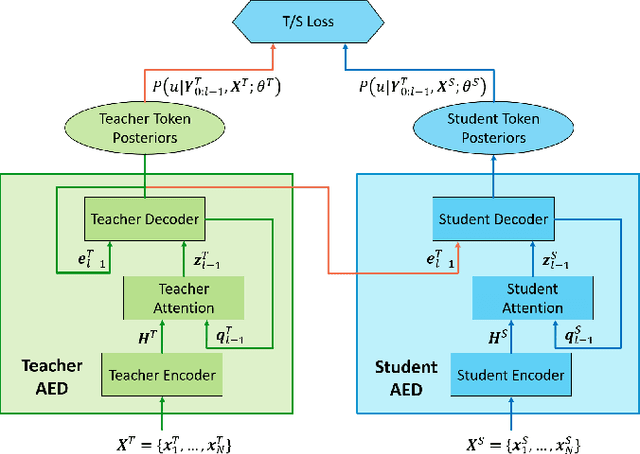
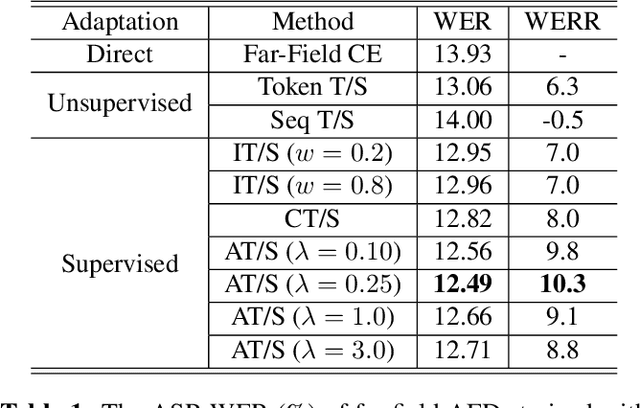
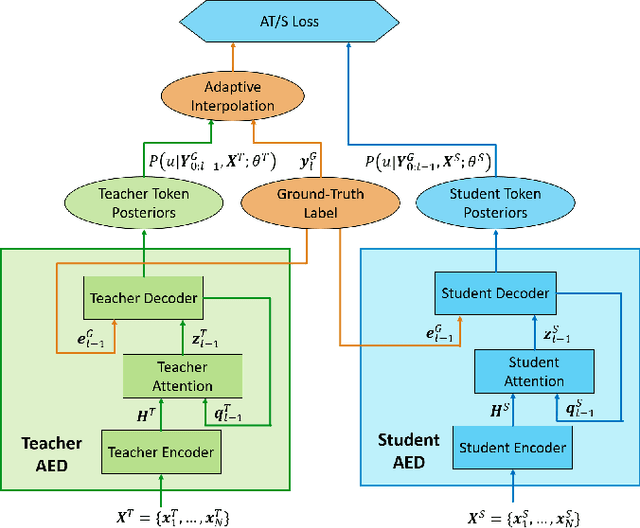
Teacher-student (T/S) has shown to be effective for domain adaptation of deep neural network acoustic models in hybrid speech recognition systems. In this work, we extend the T/S learning to large-scale unsupervised domain adaptation of an attention-based end-to-end (E2E) model through two levels of knowledge transfer: teacher's token posteriors as soft labels and one-best predictions as decoder guidance. To further improve T/S learning with the help of ground-truth labels, we propose adaptive T/S (AT/S) learning. Instead of conditionally choosing from either the teacher's soft token posteriors or the one-hot ground-truth label, in AT/S, the student always learns from both the teacher and the ground truth with a pair of adaptive weights assigned to the soft and one-hot labels quantifying the confidence on each of the knowledge sources. The confidence scores are dynamically estimated at each decoder step as a function of the soft and one-hot labels. With 3400 hours parallel close-talk and far-field Microsoft Cortana data for domain adaptation, T/S and AT/S achieve 6.3% and 10.3% relative word error rate improvement over a strong E2E model trained with the same amount of far-field data.
* 8 pages, 2 figures, ASRU 2019